每日学术速递5.8
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.Personalize Segment Anything Model with One Shot

标题:一键个性化细分任何模型
作者:Renrui Zhang, Zhengkai Jiang, Ziyu Guo, Shilin Yan, Junting Pan, Hao Dong, Peng Gao, Hongsheng Li
文章链接:https://arxiv.org/abs/2305.03048
项目代码:https://github.com/ZrrSkywalker/Personalize-SAM
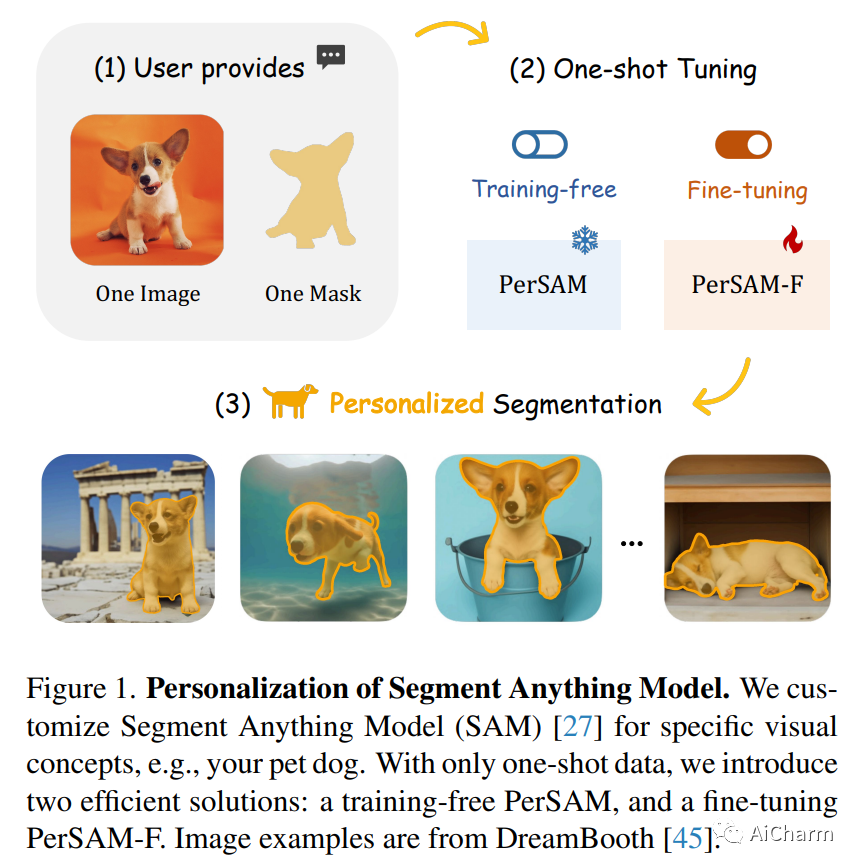






摘要:
在大数据预训练的驱动下,Segment Anything Model (SAM) 已被证明是一个强大且可提示的框架,彻底改变了分割模型。尽管具有普遍性,但在没有人工提示的情况下为特定视觉概念定制 SAM 仍在探索中,例如,在不同的图像中自动分割您的宠物狗。在本文中,我们提出了一种用于 SAM 的免训练个性化方法,称为 PerSAM。只给定一张带有参考掩码的图像,PerSAM 首先通过一个位置先验定位目标概念,然后通过三种技术在其他图像或视频中将其分割:目标引导注意、目标语义提示和级联后细化。通过这种方式,我们无需任何培训即可有效地将 SAM 用于私人用途。为了进一步减轻掩模歧义,我们提出了一种有效的单次微调变体 PerSAM-F。冻结整个 SAM,我们为多尺度掩码引入了两个可学习的权重,仅在 10 秒内训练 2 个参数以提高性能。为了证明我们的功效,我们构建了一个新的分割数据集 PerSeg,用于个性化评估,并测试我们的视频对象分割方法具有竞争力的性能。此外,我们的方法还可以增强 DreamBooth 以个性化用于文本到图像生成的稳定扩散,从而丢弃背景干扰以实现更好的目标外观学习。代码在此 https URL 上发布
2.FormNetV2: Multimodal Graph Contrastive Learning for Form Document Information Extraction(ACL 2023)

标题:FormNetV2:用于表单文档信息提取的多模态图对比学习
作者:Chen-Yu Lee, Chun-Liang Li, Hao Zhang, Timothy Dozat, Vincent Perot, Guolong Su, Xiang Zhang
文章链接:https://arxiv.org/abs/2305.02549
项目代码:https://huggingface.co/papers/2305.02549




摘要:
最近出现的自我监督预训练技术导致在表格文档理解中使用多模态学习的激增。然而,将掩码语言建模扩展到其他模态的现有方法需要仔细的多任务调整、复杂的重建目标设计或额外的预训练数据。在 FormNetV2 中,我们引入了一种集中式多模态图对比学习策略,以在一次损失中统一所有模态的自我监督预训练。图对比目标最大化多模态表示的一致性,为所有模态提供自然的相互作用,无需特殊定制。此外,我们提取边界框内的图像特征,边界框连接一对由图形边缘连接的标记,捕获更有针对性的视觉线索,而无需加载复杂且单独预训练的图像嵌入器。FormNetV2 以更紧凑的模型尺寸在 FUNSD、CORD、SROIE 和支付基准上建立了新的最先进性能。
Subjects: cs.CL
3.Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision

标题:在最少的人工监督下从头开始进行语言模型的原则驱动自对齐
作者:Zhiqing Sun, Yikang Shen, Qinhong Zhou, Hongxin Zhang, Zhenfang Chen, David Cox, Yiming Yang, Chuang Gan
文章链接:https://arxiv.org/abs/2305.03047
项目代码:https://mitibmdemos.draco.res.ibm.com/dromedary



摘要:
最近的 AI 助理代理,例如 ChatGPT,主要依靠带有人工注释的监督微调 (SFT) 和来自人类反馈的强化学习 (RLHF) 来使大型语言模型 (LLM) 的输出与人类意图保持一致,确保它们是乐于助人、合乎道德且可靠。然而,由于获得人工监督的高成本以及质量、可靠性、多样性、自我一致性和不良偏见等相关问题,这种依赖性会极大地限制 AI 助手的真正潜力。为了应对这些挑战,我们提出了一种称为 SELF-ALIGN 的新方法,它结合了原则驱动的推理和 LLM 的生成能力,以在最少的人工监督下实现 AI 代理的自对齐。我们的方法包括四个阶段:首先,我们使用 LLM 生成合成提示,并使用主题引导方法来增加提示的多样性;其次,我们使用一小组人工编写的人工智能模型原则来遵循,并通过从(原则应用的)演示中进行上下文学习来指导法学硕士,以对用户的查询产生有用的、合乎道德的和可靠的响应;第三,我们使用高质量的自对齐响应对原始 LLM 进行微调,以便生成的模型可以直接为每个查询生成理想的响应,而无需原则集和演示;最后,我们提供了一个改进步骤来解决过于简短或间接响应的问题。将 SELF-ALIGN 应用于 LLaMA-65b 基础语言模型,我们开发了一个名为 Dromedary 的 AI 助手。少于 300 行人工注释(包括 < 200 个种子提示、16 个通用原则和 5 个用于上下文学习的示例)。在具有各种设置的基准数据集上,Dromedary 的性能显着超过了几个最先进的 AI 系统,包括 Text-Davinci-003 和 Alpaca。
更多Ai资讯:公主号AiCharm