TDengine 部署与使用----时序数据库
官网
通过 Docker 快速体验 TDengine | TDengine 文档 | 涛思数据
docker安装
拉取最新docker镜像
docker pull tdengine/tdengine:latest

然后执行
docker run -d -p 6030:6030 -p 6041:6041 -p 6043-6049:6043-6049 -p 6043-6049:6043-6049/udp tdengine/tdengine

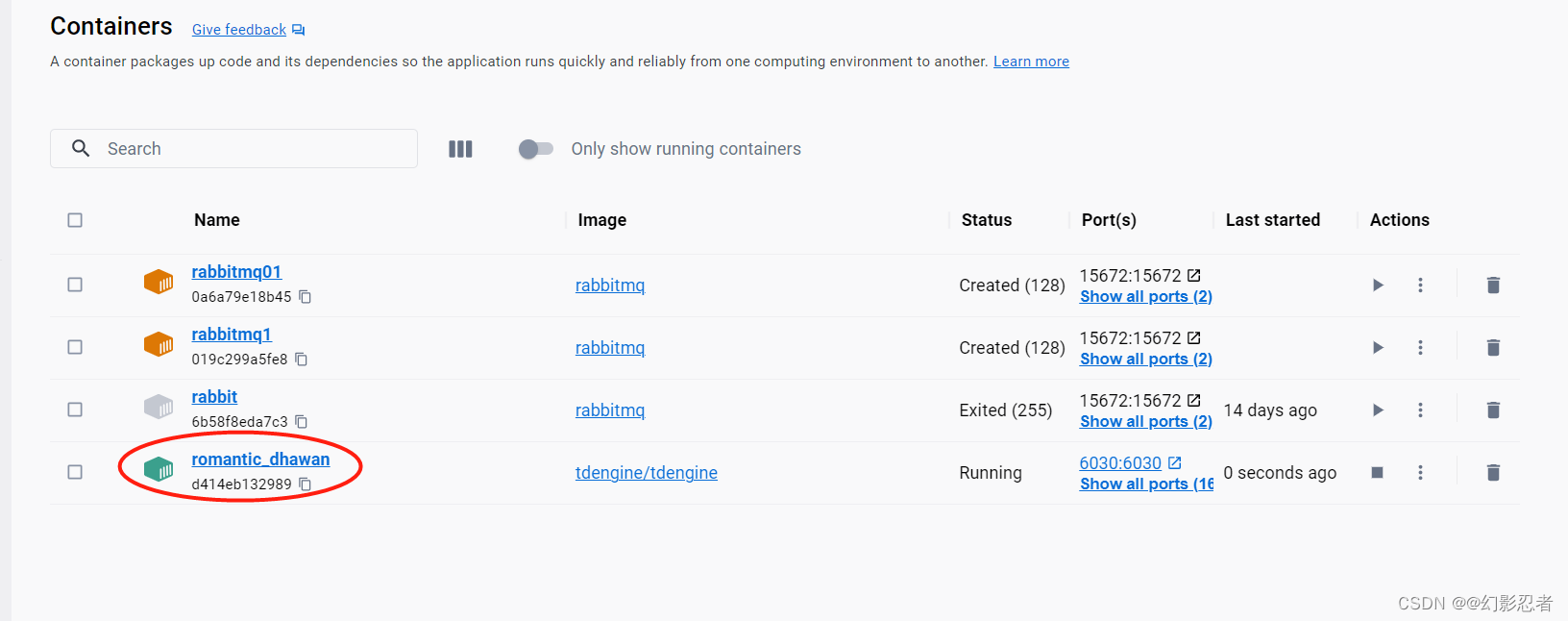
查看容器是否启动 docker ps

进入容器 docker exec -it <container name> bash

docker查看
创建库、表操作

安装客户端驱动 taosc

安装完成后,启动cmd;

创建数据库

上述语句将创建一个名为 power 的库,这个库的数据将保留 365 天(超过 365 天将被自动删除),每 10 天一个数据文件,每个 VNode 的写入内存池的大小为 16 MB,对该数据库入会写 WAL 但不执行 FSYNC.
切换数据库

将当前连接里操作的库换为 power,否则对具体表操作前,需要使用“库名.表名”来指定库的名字。
建超级表:
CREATE STABLE meters (ts timestamp, current float, voltage int, phase float) TAGS (location binary(64), groupId int);
创建超级表时,需要提供表名(示例中为 meters),表结构 Schema,即数据列的定义。第一列必须为时间戳(示例中为 ts),其他列为采集的物理量(示例中为 current, voltage, phase),数据类型可以为整型、浮点型、字符串等。除此之外,还需要提供标签的 Schema (示例中为 location, groupId),标签的数据类型可以为整型、浮点型、字符串等。采集点的静态属性往往可以作为标签,比如采集点的地理位置、设备型号、设备组 ID、管理员 ID 等等。标签的 Schema 可以事后增加、删除、修改
创建表
TDengine 对每个数据采集点需要独立建表。与标准的关系型数据库一样,一张表有表名,Schema,但除此之外,还可以带有一到多个标签。创建时,需要使用超级表做模板,同时指定标签的具体值。以 表 1 中的智能电表为例,可以使用如下的 SQL 命令建表:
CREATE TABLE d1001 USING meters TAGS ("California.SanFrancisco", 2);其中 d1001 是表名,meters 是超级表的表名,后面紧跟标签 Location 的具体标签值为 "California.SanFrancisco",标签 groupId 的具体标签值为 2。虽然在创建表时,需要指定标签值,但可以事后修改。详细细则请见 TDengine SQL 的表管理 章节。
TDengine 建议将数据采集点的全局唯一 ID 作为表名(比如设备序列号)。但对于有的场景,并没有唯一的 ID,可以将多个 ID 组合成一个唯一的 ID。不建议将具有唯一性的 ID 作为标签值。
自动建表
在某些特殊场景中,用户在写数据时并不确定某个数据采集点的表是否存在,此时可在写入数据时使用自动建表语法来创建不存在的表,若该表已存在则不会建立新表且后面的 USING 语句被忽略。比如:
INSERT INTO d1001 USING meters TAGS ("California.SanFrancisco", 2) VALUES (NOW, 10.2, 219, 0.32);
上述 SQL 语句将记录(NOW, 10.2, 219, 0.32)插入表 d1001。如果表 d1001 还未创建,则使用超级表 meters 做模板自动创建,同时打上标签值 "California.SanFrancisco", 2。
多列模型 vs 单列模型
TDengine 支持多列模型,只要物理量是一个数据采集点同时采集的(时间戳一致),这些量就可以作为不同列放在一张超级表里。但还有一种极限的设计,单列模型,每个采集的物理量都单独建表,因此每种类型的物理量都单独建立一超级表。比如电流、电压、相位,就建三张超级表。
TDengine 建议尽可能采用多列模型,因为插入效率以及存储效率更高。但对于有些场景,一个采集点的采集量的种类经常变化,这个时候,如果采用多列模型,就需要频繁修改超级表的结构定义,让应用变的复杂,这个时候,采用单列模型会显得更简单。
对数据表操作
插入
INSERT INTO d1001 VALUES (NOW, 10.2, 219, 0.32);

查询
