【MySQL】交叉连接、自然连接和内连接查询
一、引入
实际开发中往往需要针对两张甚至更多张数据表进行操作,而这多张表之间需要使用主键和外键关联在一起,然后使用连接查询来查询多张表中满足要求的数据记录。一条SQL语句查询多个表,得到一个结果,包含多个表的数据。效率高。
多种连接查询的类型:
- cross
- natural
- using
- on
二、交叉连接(cross join)
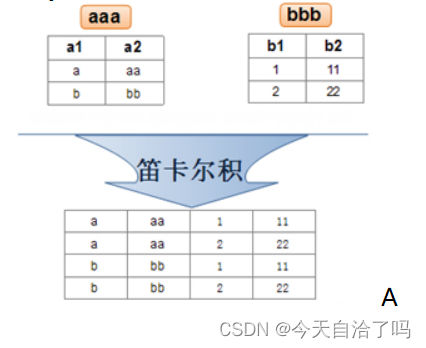
交叉连接(CROSS JOIN)是对两个或者多个表进行笛卡儿积操作,所谓笛卡儿积就是关系代数里的一个概念,表示两个表中的每一行数据任意组合的结果。比如:有两个表,左表有m条数据记录,x个字段,右表有n条数据记录,y个字段,则执行交叉连接后将返回m*n条数据记录,x+y个字段。笛卡儿积示意图如图所示。
我希望查找员工编号、员工姓名、部门编号和部门名称这4个字段的数据,在员工表emp中可以查询到员工编号、员工姓名、部门编号的数据,在部门表dept中可以查询到字段部门名称的数据,如果想同时查找这些数据,需要使用多表查询语法,交叉连接cross join:
查询员工表emp:
select * from emp; 
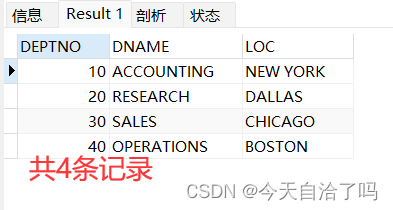
查询部门表dept:
select * from dept;
一条SQL查询两个表:
select * from emp cross join dept;
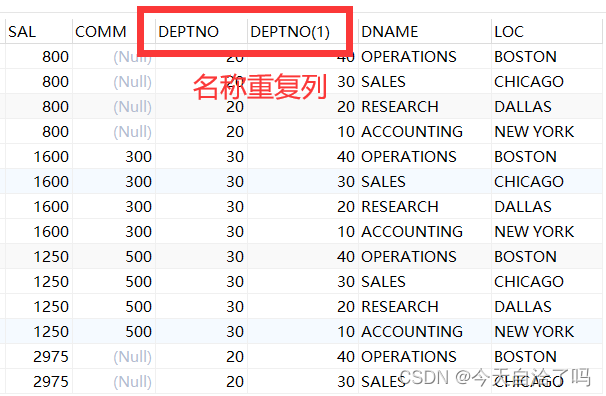
表emp14条记录,表dept4条记录,交叉连接查询后,14*4=56条记录,交叉连接就是对这两个表进行笛卡尔乘积操作,笛卡尔乘积没有实际意义,但是有理论意义。
关于交叉连接的写法,MySQL中可以省略cross,Oracle中不可以省略不写,上条SQL等价于:
select * from emp join dept;三、自然连接(natural join)
交叉连接会查询到许多冗余数据,比如在员工表emp和部门表dept中,让主键和外键关联起来的外键deptno,没有匹配到一起,造成数据冗余:
使用自然连接,可以自动匹配所有的同名列,让同名列只在查询中展示一次,提高查询效率,
select * from emp natural join dept;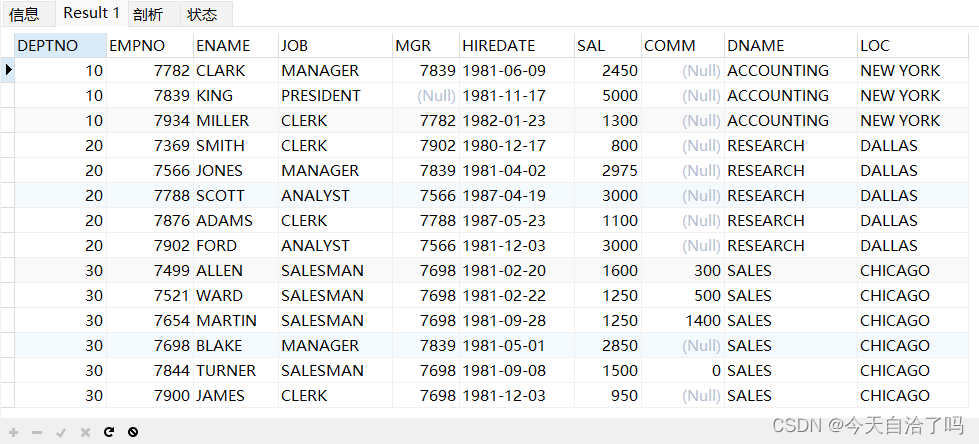
可以指定查询的部分字段:
select empno,ename,deptno,dname from emp natural join dept;
当查询一个字段时,系统会分别从两个关联的表中查找,因此效率较低,为解决这个问题,我们可以在查询目标字段时,指定表名,格式为表名.字段名
select emp.empno,emp.ename,emp.deptno,dept.dname from emp natural join dept;查询结果和上述一致,但是查询效率得到了提升。
此时,如果表名过长,查询的SQL也会过长,在查询时,我们可以为表起别名:
select e.empno,e.ename,d.dname,d.deptno
from emp e
natural join dept d;
四、内连接
使用natural join 的缺点:会自动匹配表中所有的同名列,但是有的时候我们希望只匹配部分同名列,那么我们可以使用using子句,这属于内连接(inner join)
select *
from emp as e
inner join dept as d
using(deptno);using子句的缺点:关联的字段,必须是同名的
解决方法:使用内连接中的on子句
select *
from emp e
inner join dept d
on (e.deptno = d.deptno);
五、总结
多表查询的类型有:
- 交叉连接 cross join
- 自然连接 natural join
- 内连接 - using子句
- 内连接 - on子句
综合来看:内连接 - on子句的使用频率最高。
六、补充
select *
from emp e
inner join dept d
on (e.deptno = d.deptno)
where sal > 3500;条件:
1、筛选条件 where having
2、连接条件 on/using/natural
在SQL99语法当中,筛选条件和连接条件是分开的。