SSD目标检测
数据集以及锚框的处理
数据集:
图像:(batch_size , channel , height , width)
bounding box: (batch_size , m , 5)
m: 图像中可能出现的最多边界框的数目
5: 第一个数据为边界框对应的种类,对于少于m个边界框的图像,为了保持数据的统一,需要填充非法边界框,此时将其标为-1,并在后面计算中舍弃。剩余四个数据为边界框的左上角和右下角坐标。
在训练数据中标注锚框:
在训练集中,我们将每个锚框视为一个训练样本。
首先,在图片中使用不同的方法生成大量锚框。接着使用数据集中的真实边界框与锚框的交并比来为每一个锚框标记类别和偏移量。
SSD模型
模型结构:
首先,使用基本网络块从图像中抽取特征,再逐步将其使用卷积和池化将特征图宽高减半,最终使用全局最大池将高度和宽度都降到1。
锚框构造:
我们对每一个特征图的每一个像素生成不同宽高比的锚框。当特征图尺寸越小,映射到原图的锚框越大,这样我们可以搜素不同大小的物体。
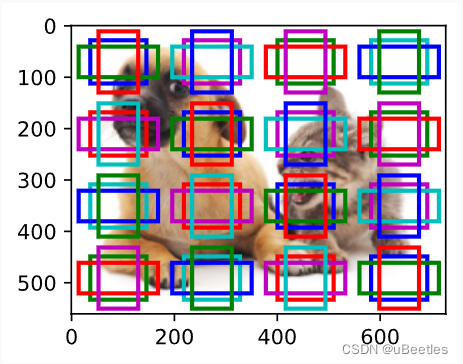
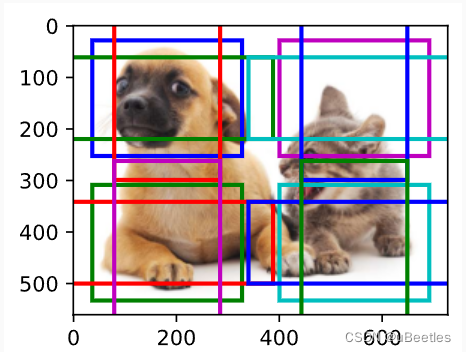
锚框的种类和偏移量预测:
对于种类和偏移量的预测使用不同通道来表示:
具体来说对于一个2x2的特征图假设每一个像素生成3个锚框,对于这个特征图一共有12个锚框。假设我们一共要预测3个种类,我们使用卷积生成 12x(3+1)(+1是指将锚框标注为背景) 个通道的2x2结果。例如第一个通道的第一个像素表示为特征图第一个像素生成的第一个锚框预测为第一个种类的概率。
相同的我们对偏移量的预测一共生成12x4个通道来表示预测结果。
最终网络如下所示:
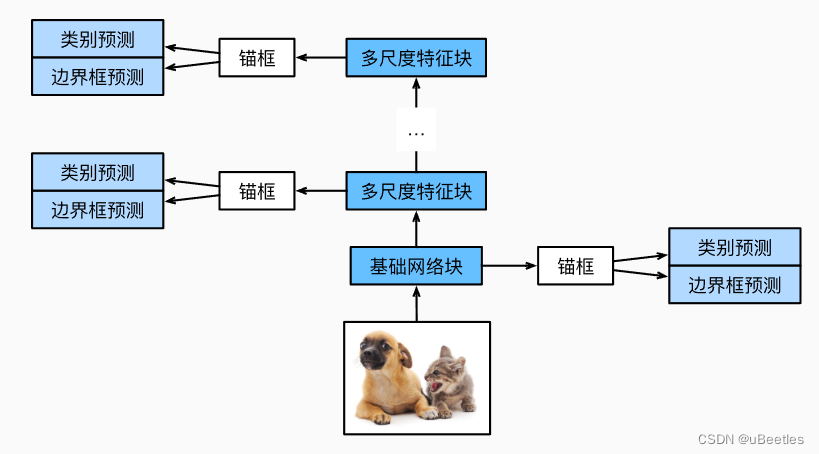
我们使用交叉熵损失函数来对每一个锚框的预测种类和真实值求loss,对于每一个锚框的偏移量使用L1范数损失来求其loss。