多模态之clip
论文:Learning Transferable Visual Models From Natural Language Supervision
Github:https://github.com/OpenAI/CLIP
OpenAI出品
论文通过网络爬取4亿(image, text)对,使用对比学习的方法训练得到clip(Contrastive Language-Image Pre-training)模型。模型可以实现图片和文本的编码,同时还可以zero-shot直接迁移进下游其他任务。在模型上一共尝试了8个模型,从resnet到ViT,最小模型和最大模型之间的计算量相差约100倍,迁移学习的效果基本和模型大小成正相关。尝试了30个数据集,都能和之前的有监督的模型效果差不多甚至更好。
网络结构:
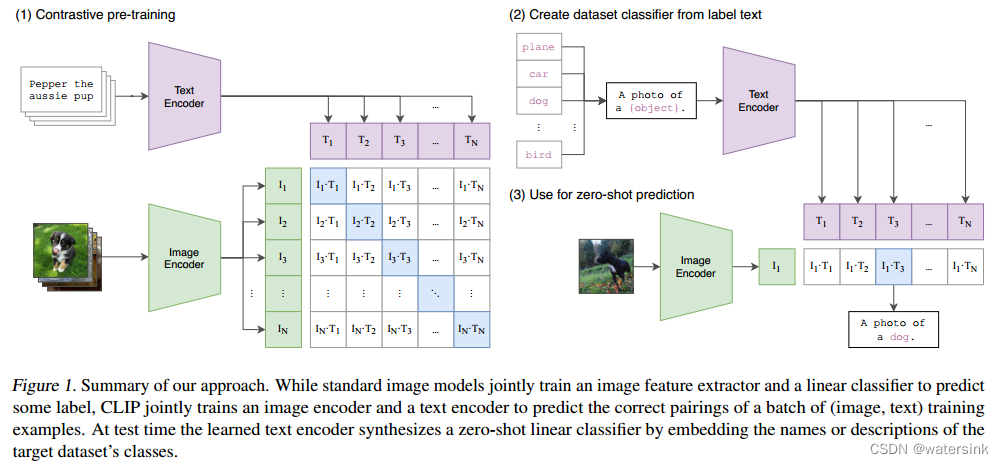
Clip模型基于双塔结构的网络设计。分别基于2个主干网络实现对于文本和图片的编码,分别输出文本的特征向量(T1,T2……TN)和图片的特征向量(I1,I2……IN)。最终两个特征向量做矩阵运算共得到N个类内特征,N2-N个类间特征。通过对比损失函数,增大N个类内特征之间的cos距离,减小N2-N个类间特征的cos距离。
图片编码的主干网络一共设计了5种ResNet系列(ResNet-50, ResNet-101,RN50x4, RN50x16, RN50x64,)和3种ViT系列(ViT-B/32, a ViT-B/16, and a ViT-L/14)。
其中ResNet在原生基础上做了略微改动,主要改动包括增加了抗锯齿的2*2pooling,将网络最后的全局池化替换为attention池化。
ViT的改动主要是增加了一共额外的归一化层来结合patch块和位置position编码。同时使用了稍微不同的初始化策略。
文本的主干网络主要使用Transformer网络。网络包含63M参数,12层网络深度,512的网络宽度,8个注意力机制头。包含49152个单词长度,句子最大长度为76。
训练细节:
(1)在训练过程中,文本的主干网络和图片的主干网络都没使用类似ImageNet的预训练权重做初始化,全部都是随机初始化的。
(2)仅仅使用线性投影,将文本和图片的特征向量投影到embedding空间。
(3)Clip的(image, text)对都是一一配对的,一个图片只对应一个句子,所以这里也没有像一个图片对应多个句子,可以对句子进行随机采样操作。
(4)图片的数据增强方式只有resize和随机crop操作。
(5)softmax中的温度参数T是模型训练得到的,T初始化为0.07,超过100将被截断。

蓝色:基于transformer的语言模型,0样本迁移能力最差,训练速度最慢。
橙色:词袋模型,0样本迁移能力居中,训练速度比transformer语言模型快了3倍。
绿色:clip模型,0样本迁移能力最好,通过类内类间对比训练的方式,训练速度比transformer语言模型快了4倍。
损失函数:

有两个输入,一个是图片,一个是文本,图片的维度是[n,h,w,c],文本的维度是[n,l],l是指序列长度,然后送入到各自的encoder提取特征,image encoder可以是ResNet也可以是Vision Transformer,text encoder可以是CBOW,也可以是Text Transformer,得到对应的特征之后,再经过一个投射层(即W_i和W_t),投射层的意义是学习如何从单模态变成多模态,投射完之后再做l2 norm,就得到了最终的用来对比的特征I_e和T_e,现在有n个图像的特征,和n个文本的特征,接下来就是算consine similarity,算的相似度就是最后要分类的logits,最后logits和ground truth做交叉熵loss,正样本是对角线上的元素,logits的维度是[n,n],ground truth label是np.arange(n),算两个loss,一个是image的,一个是text的,最后把两个loss加起来就平均。这个操作在对比学习中是很常见的,都是用的这种对称式的目标函数。
实验结果:

相比基于有监督模式训练的ResNet-50模型,clip模型在大部分数据集上具有更好的0样本迁移能力。但是有些数据集上表现却不如监督训练的模型,比如细分类任务(判断车的款式、花的种类、车的种类)、计数任务、距离计算任务。
Clip模型本质是分类模型,只能在有限的几个文本选项中做选择,而不像caption任务可以输出任意的文本。
Clip模型训练数据都是网络爬取的,缺乏数据的过滤和筛选,会存在社会歧视问题。
Clip模型从zero-shot任务迁移到few-shot任务,会出现反常的掉点。
Clip模型在电脑字体的ocr场景识别效果很好,迁移到手写数字场景效果却较差。