Speech and Language Processing-之N-gram语言模型
正如一句老话所说,预测是困难的,尤其是预测未来。但是,如何预测一些看起来容易得多的事情,比如某人接下来要说的几句话后面可能跟着哪个单词。
![]()
希望你们大多数人都能总结出一个很可能的词是in,或者可能是over,但可能不是fridge或the。在下面的部分中,我们将通过引入为每个可能的下一个单词分配概率的模型来形式化这种直觉。同样的模型也将用于为整个句子分配概率。例如,这样的模型可以预测以下序列在文本中出现的概率要高得多。

什么是N-gram 呢?下面咱们直接开始讲例子:

上面的一个问题如何解决呢,其中最简单的一种办法就是使用频率计算,在我们看到历史h句子中,有多少次它后面跟着单词w。也就是说,你有大量的语料,然后你找出所有的句子h,然后你再找出h后面跟着the的句子,此时,后面的句子数目除以前面的句子数目,就是概率p(w|h)。有了足够大的语料库,比如web,我们可以计算这些计数,并从前面公式中估计概率。虽然这种直接从计数中估计概率的方法在很多情况下都很有效,但事实证明,在大多数情况下,即使是网络也不够大,无法给我们很好的估计。这是因为语言是创造性的;新的句子一直在被创造出来,我们并不总是能够计算出整个句子。
类似地,如果我们想知道整个单词序列的联合概率,比如它的水是如此透明,我们可以问“out of all possible sequences of five words, how many of them are its water is so transparent?”我们必须得到它的水是如此透明的计数,然后除以所有可能的五个单词序列的计数之和。估计起来似乎太多了!

如上,这段写的非常经典,就不翻译了,自己看英文,写的非常凝练,其实就是记号的写法还有计算公式。

这段依旧写的很经典,就是说,之前我为了判断h后面the的概率,我需要把h里面所有的概率累加起来,这样的话计算量太大,为了避免这个问题,直接把h前面的头去掉,用that代替h,也就是1-gram。

上面的技术讲的有些理论,下面上几个例子和代码:
当我们处理文本数据时,n-gram是一种常见的技术,它可以将文本切分成连续的n个词或字符序列,并对这些序列进行分析。例如,在一个句子中提取所有的2-gram(或bigram):
原始文本:I love natural language processing. 提取2-gram:[(I,love), (love,natural), (natural,language), (language,processing)]
在python中,我们可以使用NLTK库来实现ngram的计算。以下是一个简单的代码示例,使用unigram、bigram和trigram从给定的文本中提取ngram:
import nltktext = "I love natural language processing."# 将文本转换为tokens
tokens = nltk.word_tokenize(text)# 创建unigrams
unigrams = list(nltk.ngrams(tokens, 1))
print("Unigrams:", unigrams)# 创建bigrams
bigrams = list(nltk.ngrams(tokens, 2))
print("Bigrams:", bigrams)# 创建trigrams
trigrams = list(nltk.ngrams(tokens, 3))
print("Trigrams:", trigrams)

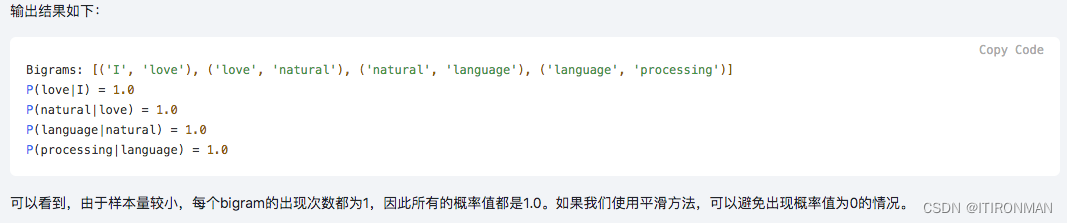
来一个概率计算的例子:
import nltktext = "I love natural language processing."# 将文本转换为tokens
tokens = nltk.word_tokenize(text)# 创建bigrams
bigrams = list(nltk.ngrams(tokens, 2))
print("Bigrams:", bigrams)# 建立词汇表
vocab = set(tokens)# 统计每个bigram的出现次数
freq_dist = nltk.FreqDist(bigrams)# 计算概率(使用最大似然估计)
for bg in bigrams:prob = freq_dist[bg] / freq_dist[bg[0]]print("P({}|{}) = {}".format(bg[1], bg[0], prob))