【LLM微调】
目录
- LLM简介
- LLM的训练方式
- Transformer架构
- tokenizer方式
- 三种不同attenbtion
- Layer Normalization
- decoder输出
- LLM Fine-tuning
- 几种微调方式
- adaptor tuning(适配器微调)
- perfix tuning
- Lora
- 参考资料
- 相关文章
LLM简介
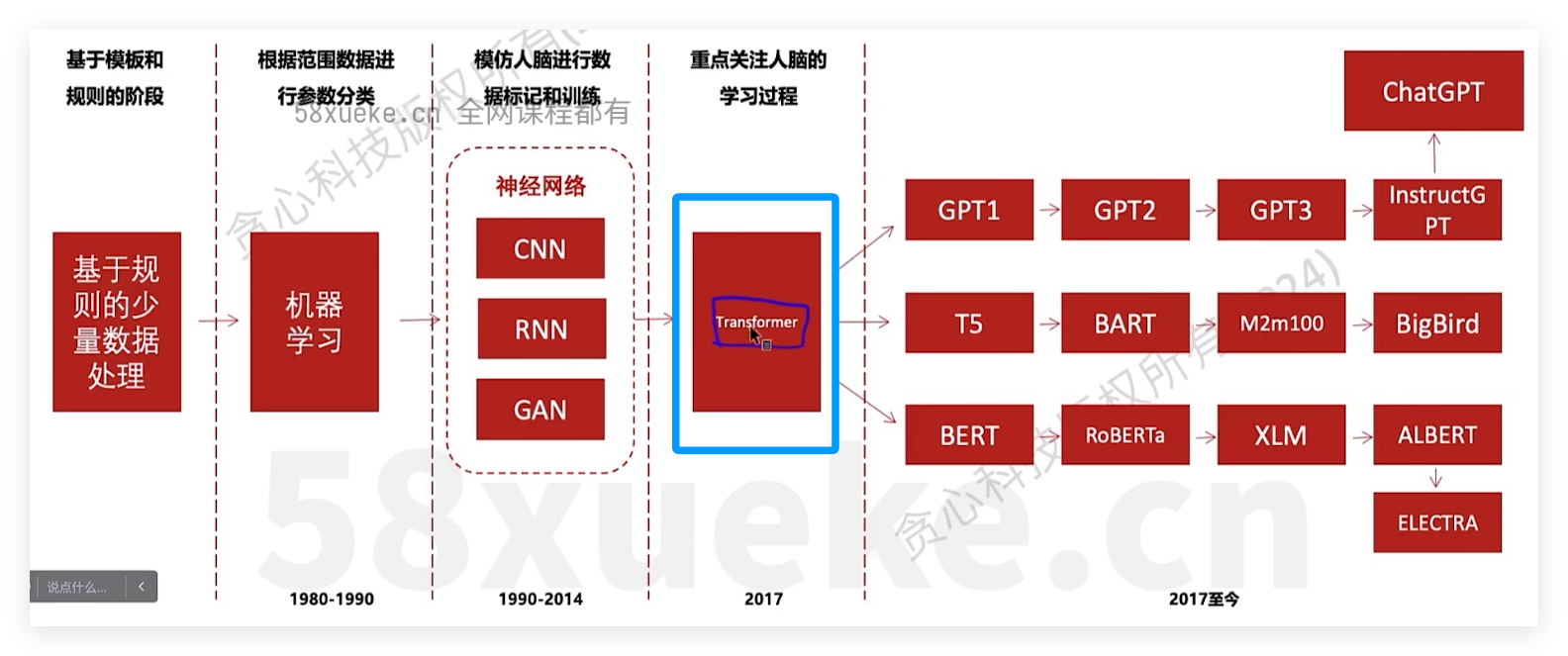
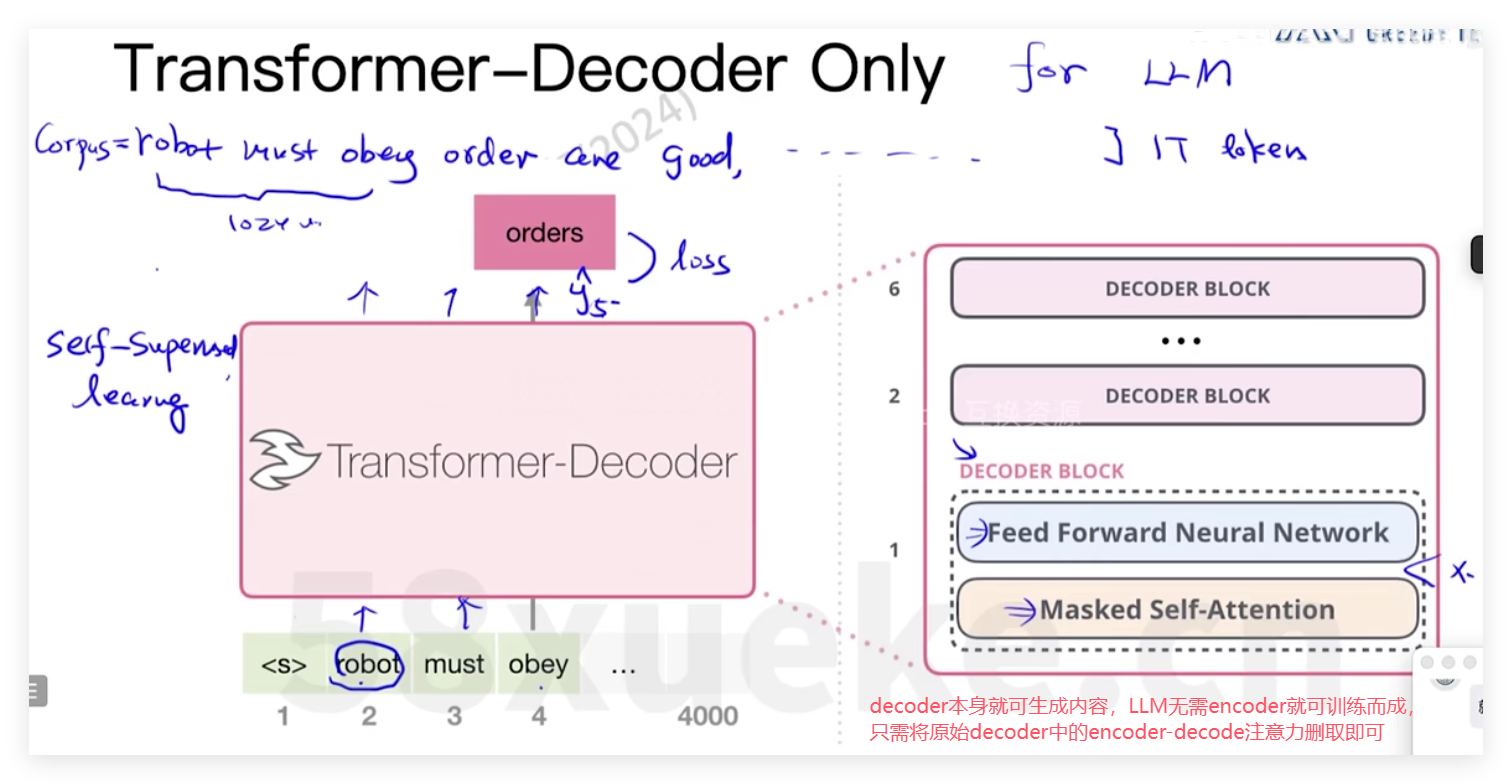
- LLM都是基于transformer发展起来,归功于transformer的长文本关系检索能力,通过attention可捕捉输入序列中的各token之间关系,可用于生成LLM
- 主要由以下三种LLM,其中又以decoder-only为主流
| 架构 | 代表模型 | 关键特征 |
|---|---|---|
| Decoder-Only(纯自回归) | GPT 系列、Llama、Baichuan、Qwen、Falcon、Mistral | 只做「从左到右」生成,适合对话/续写 |
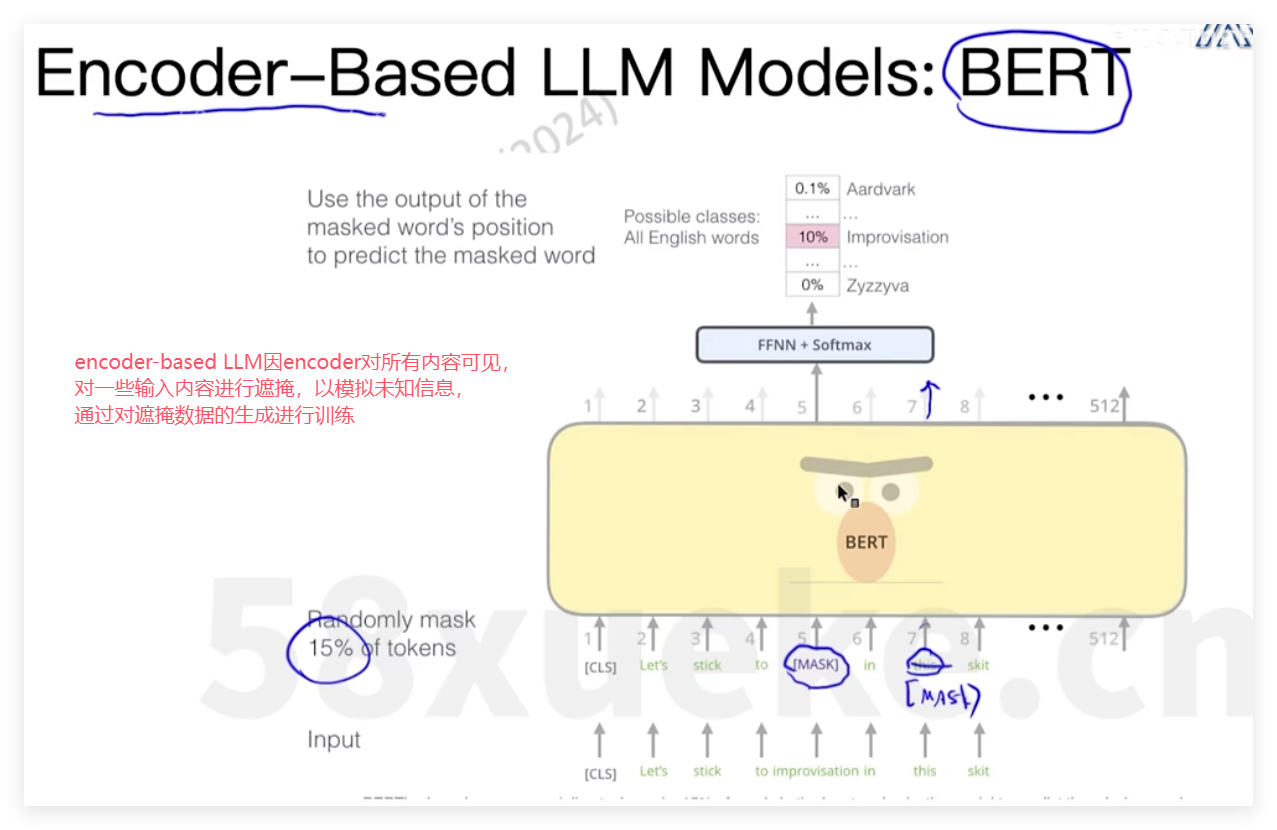
| Encoder-Only(纯自编码) | BERT、RoBERTa、DeBERTa | 双向上下文,适合理解类任务(分类、NER) |
| Encoder-Decoder(序列到序列) | T5、UL2、BART、Flan-T5、GLM | 兼顾理解与生成,适合翻译、摘要、问答 |

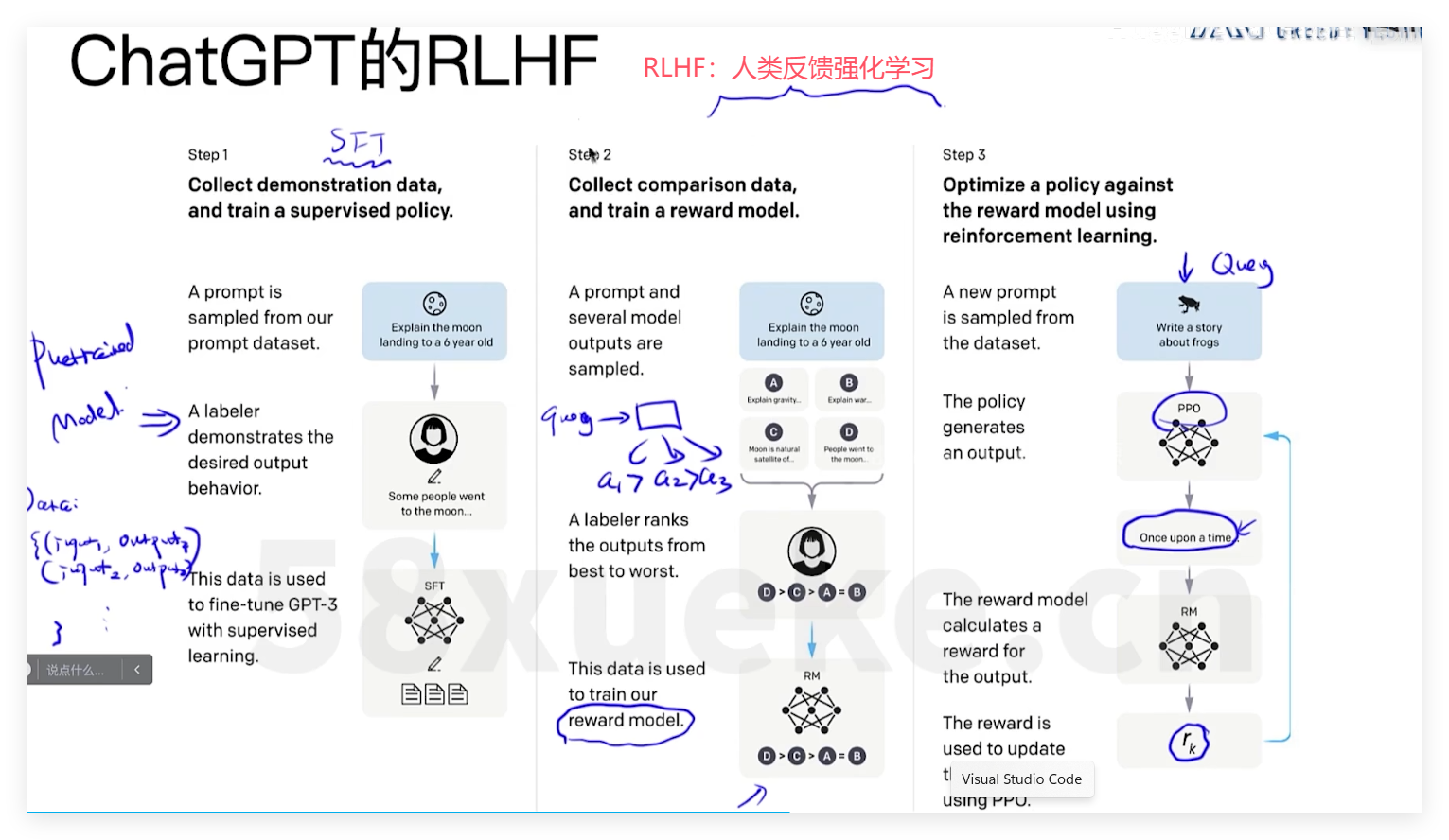
以RLHF(人类反馈强化学习)而来的chatGPT
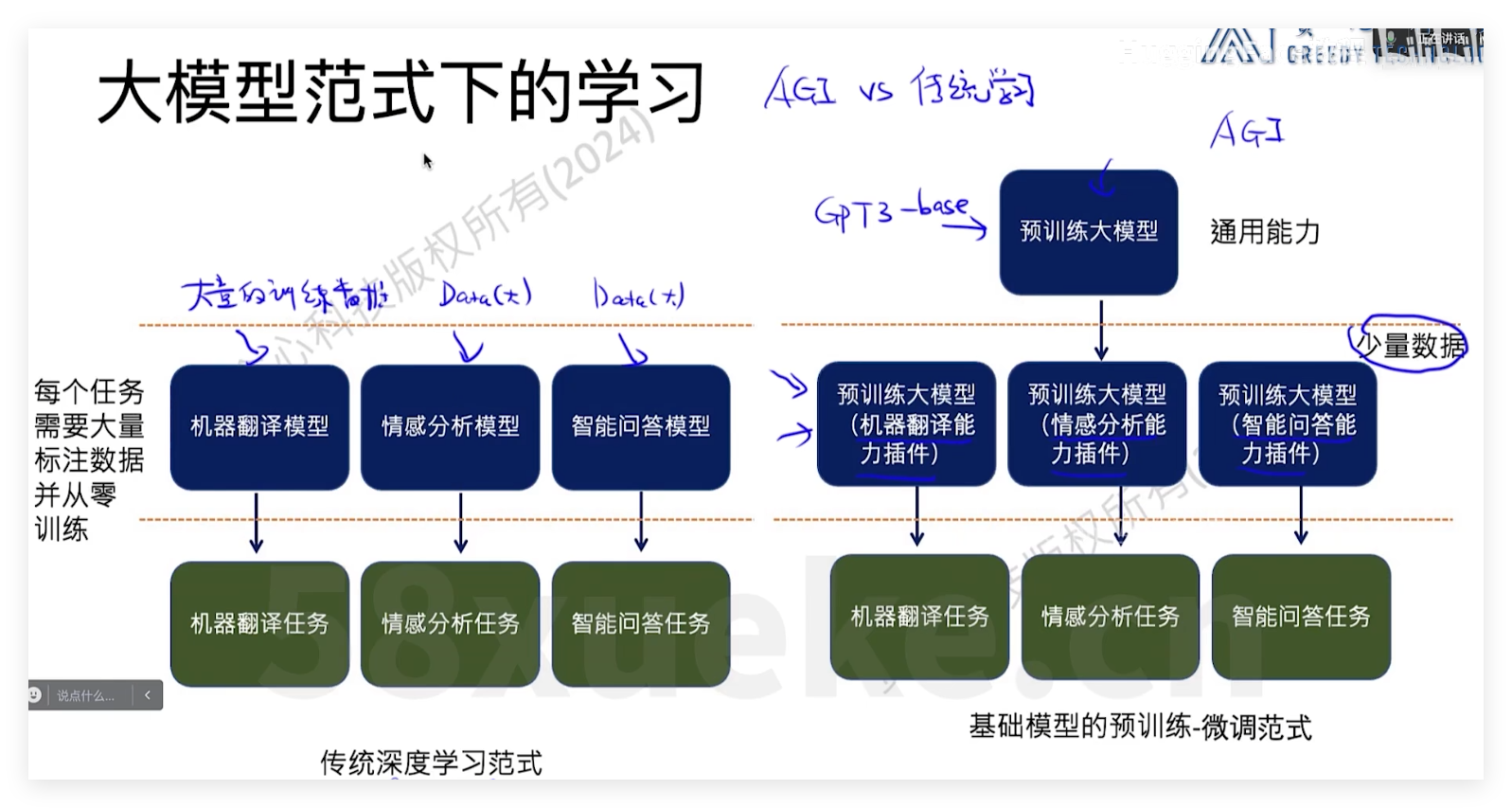
LLM的训练方式

Transformer架构
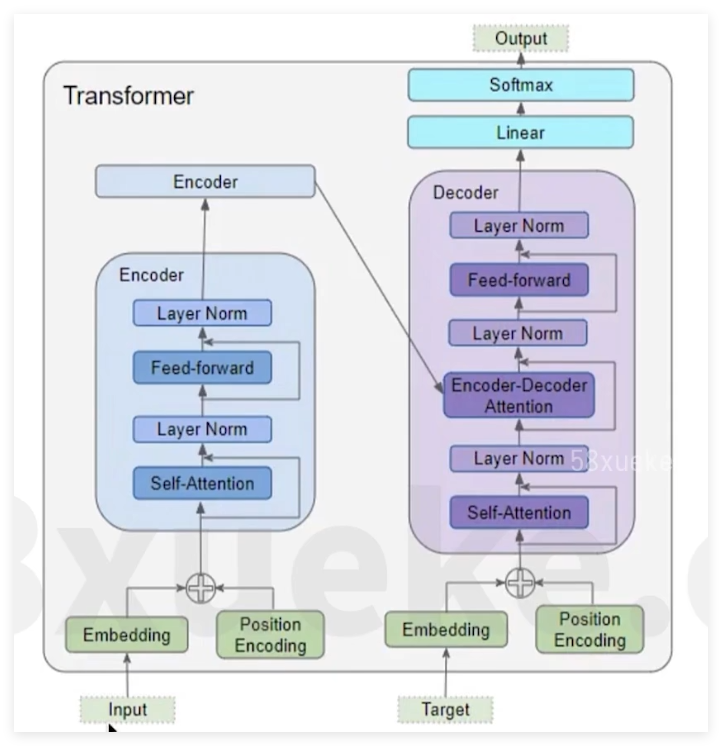
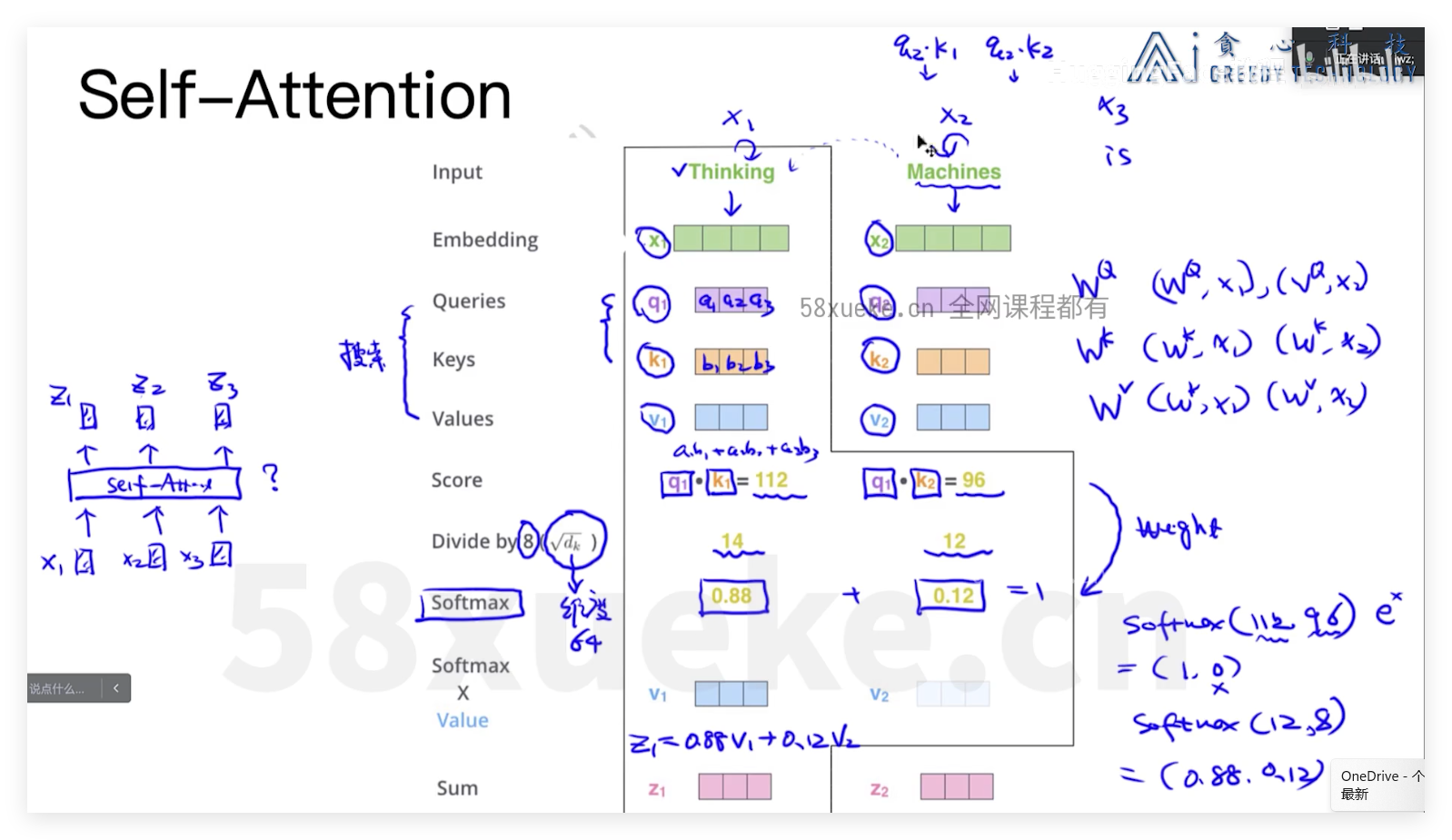
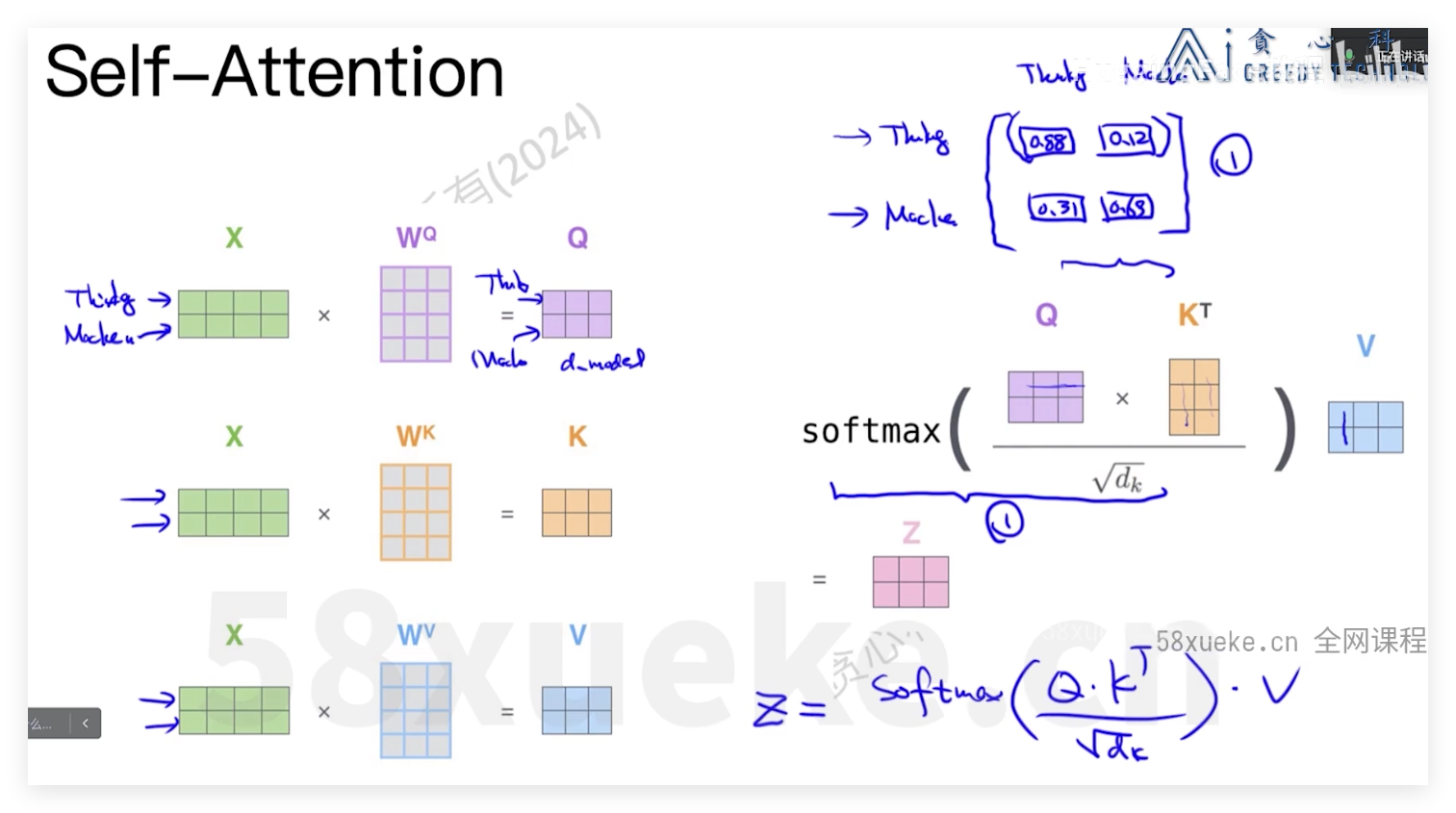
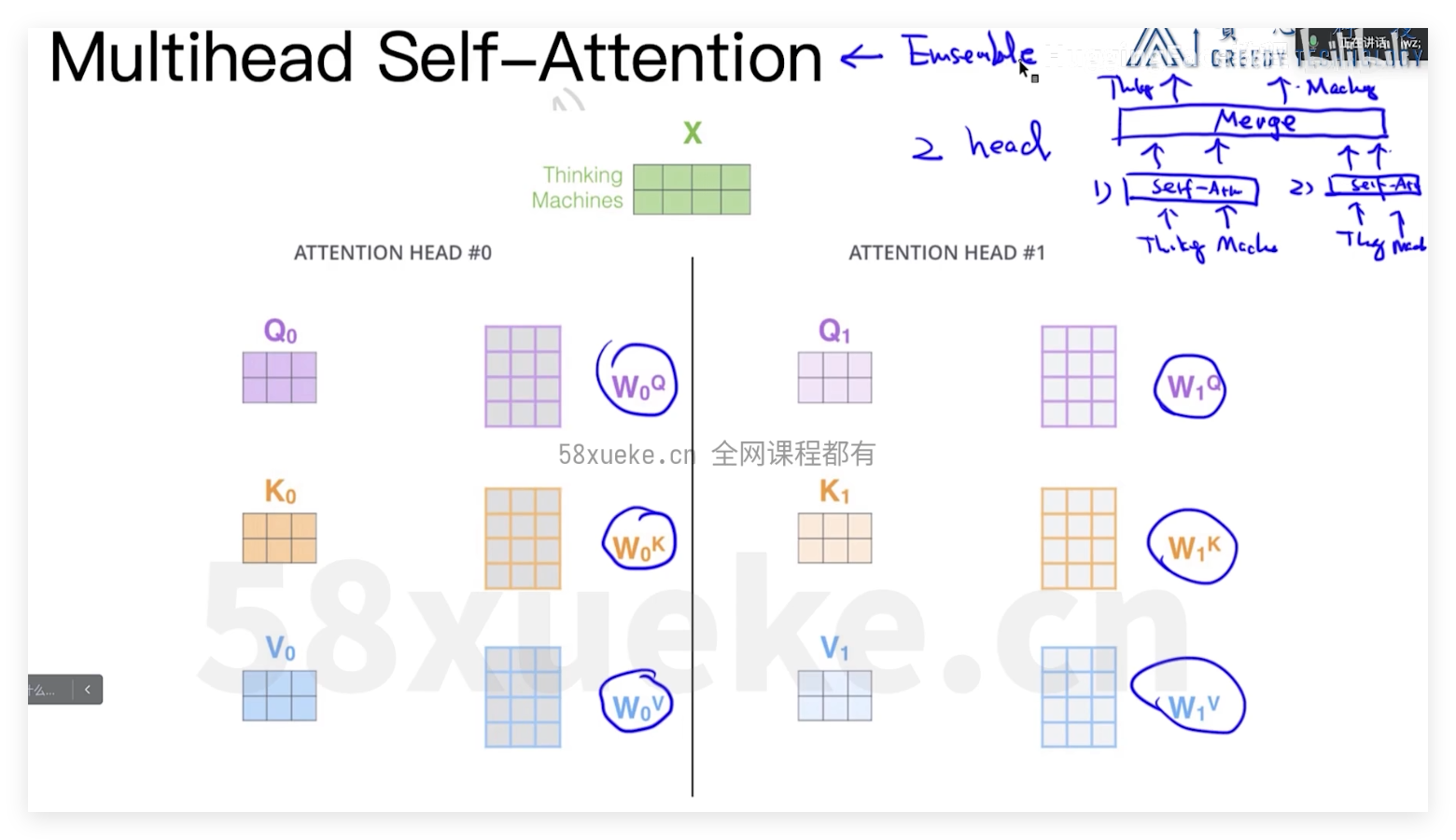
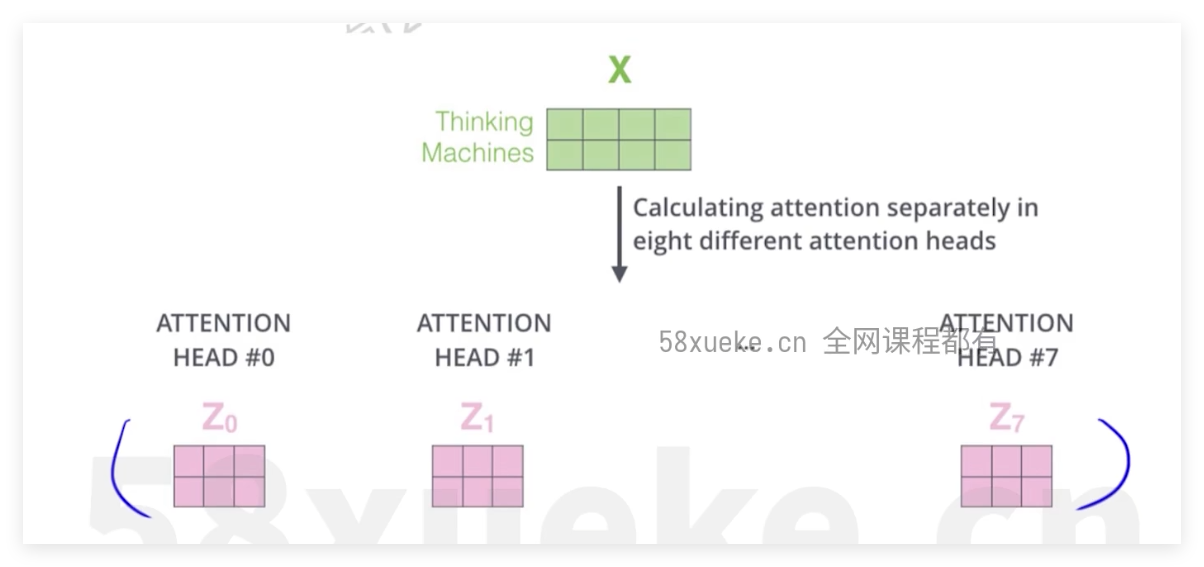
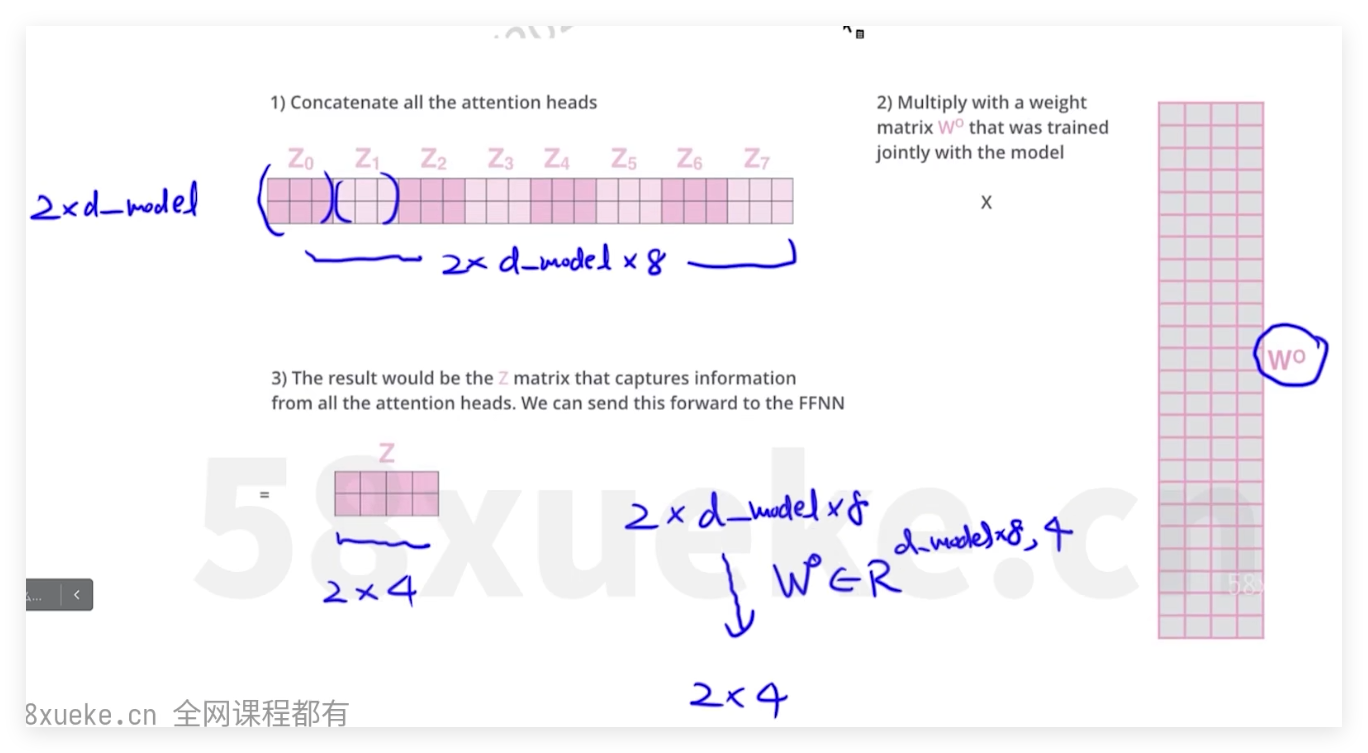
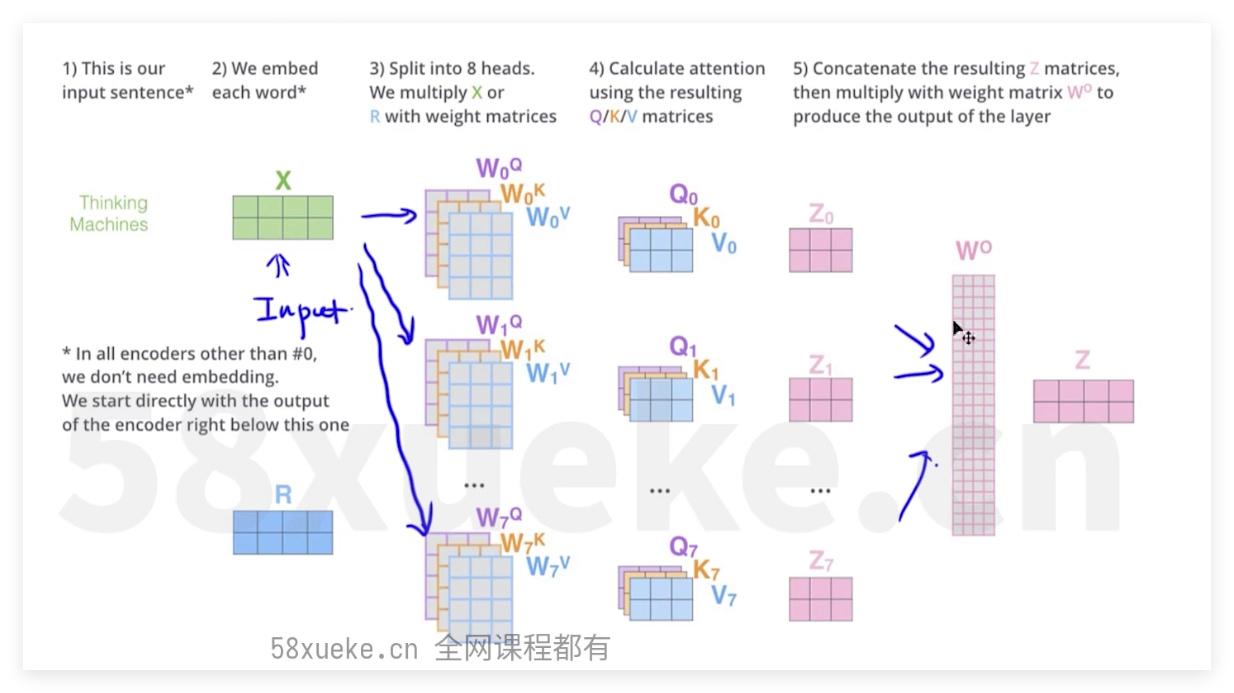
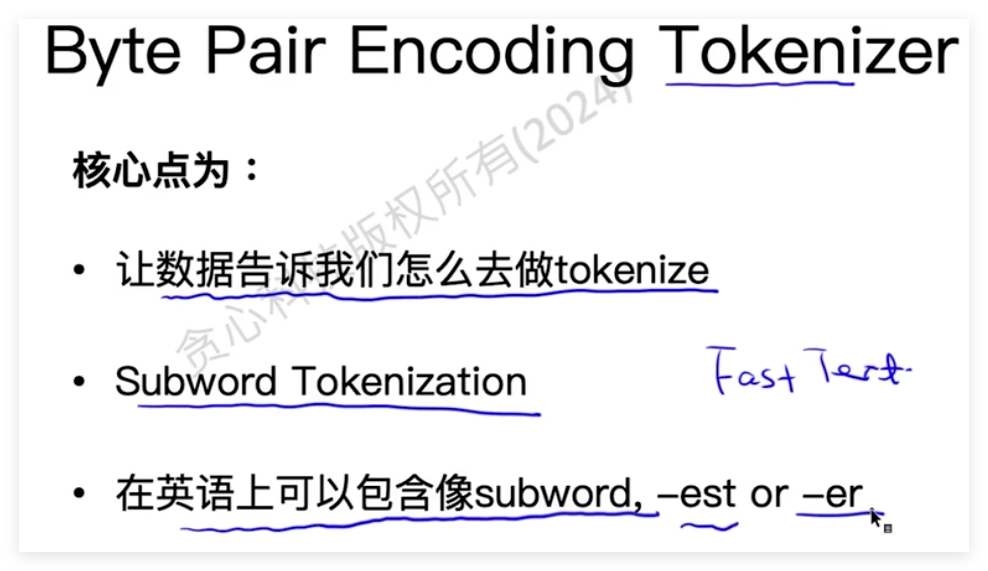
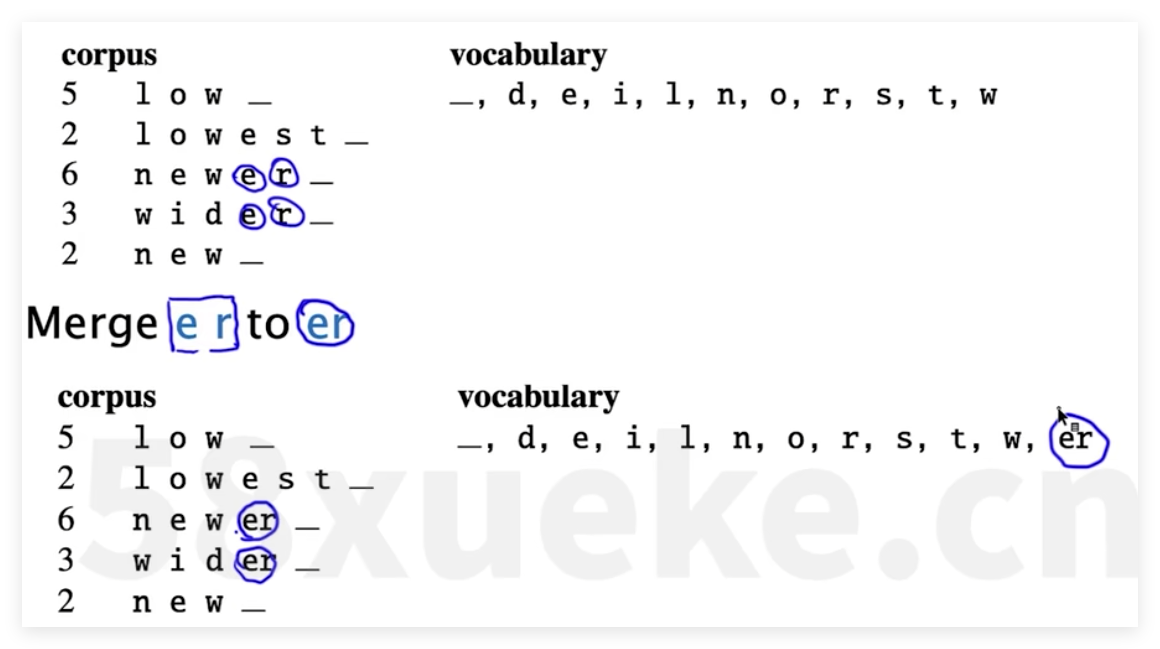
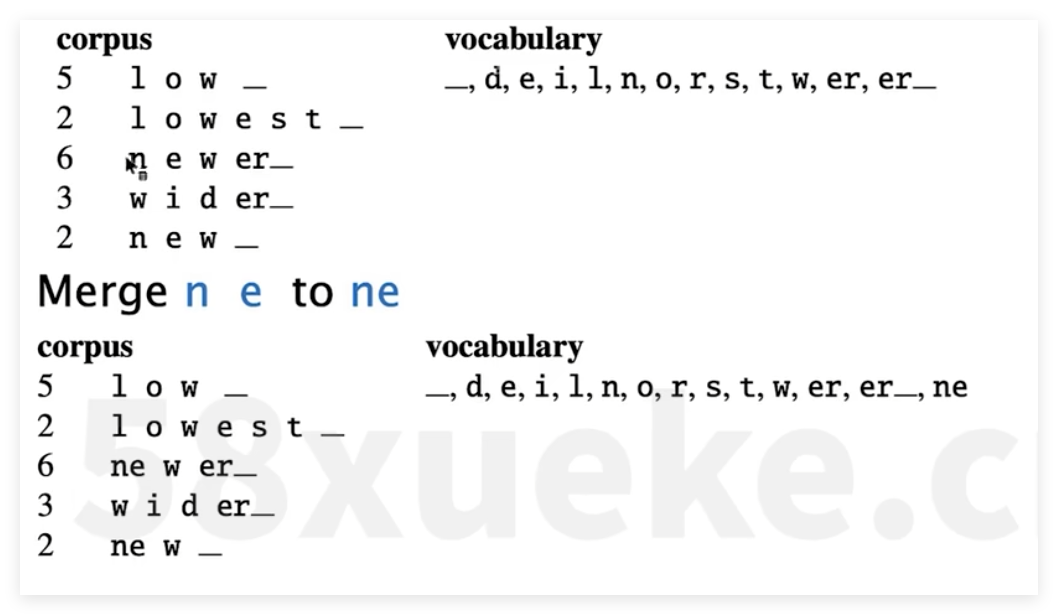
tokenizer方式





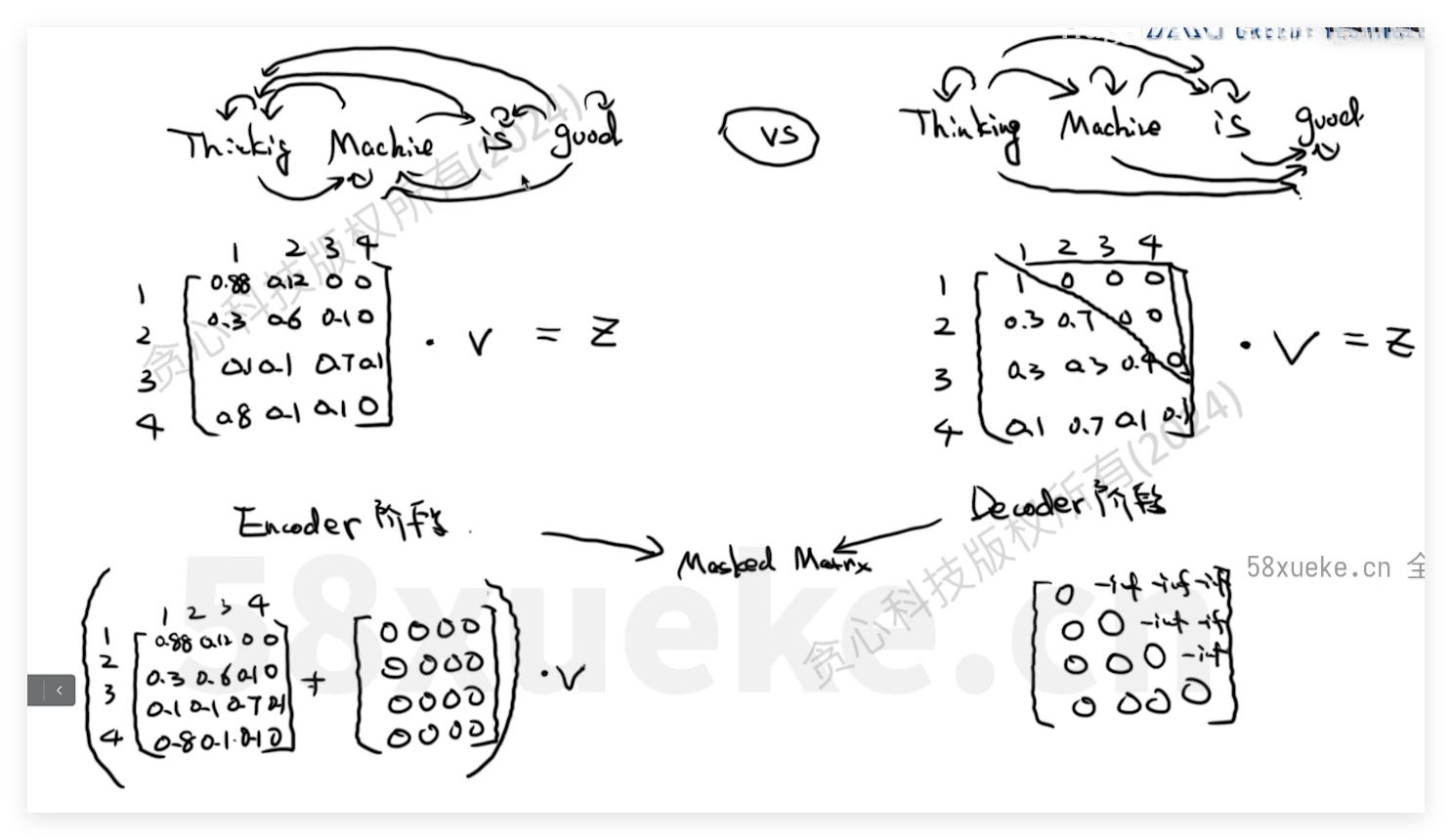
三种不同attenbtion



Layer Normalization

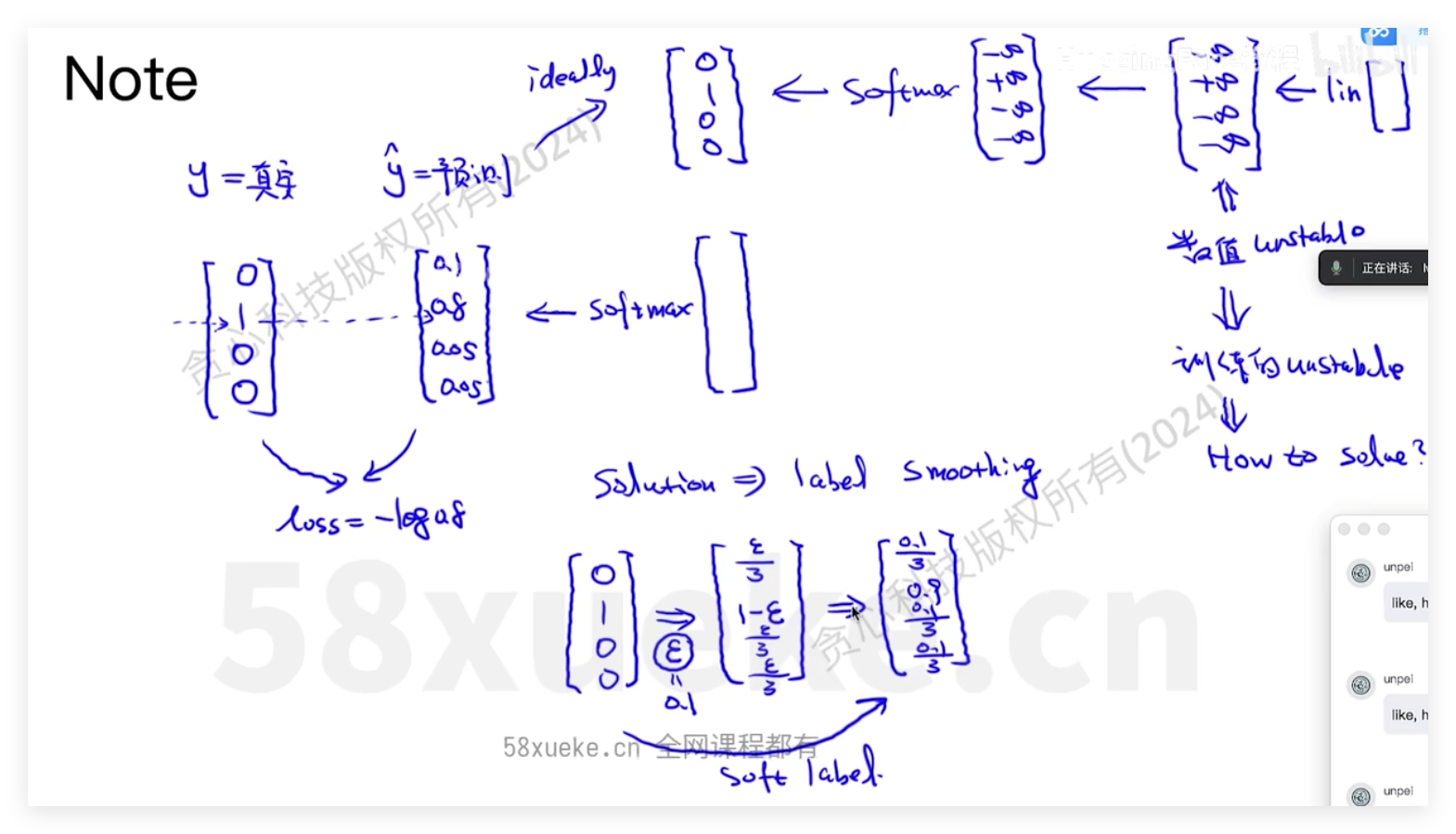
decoder输出

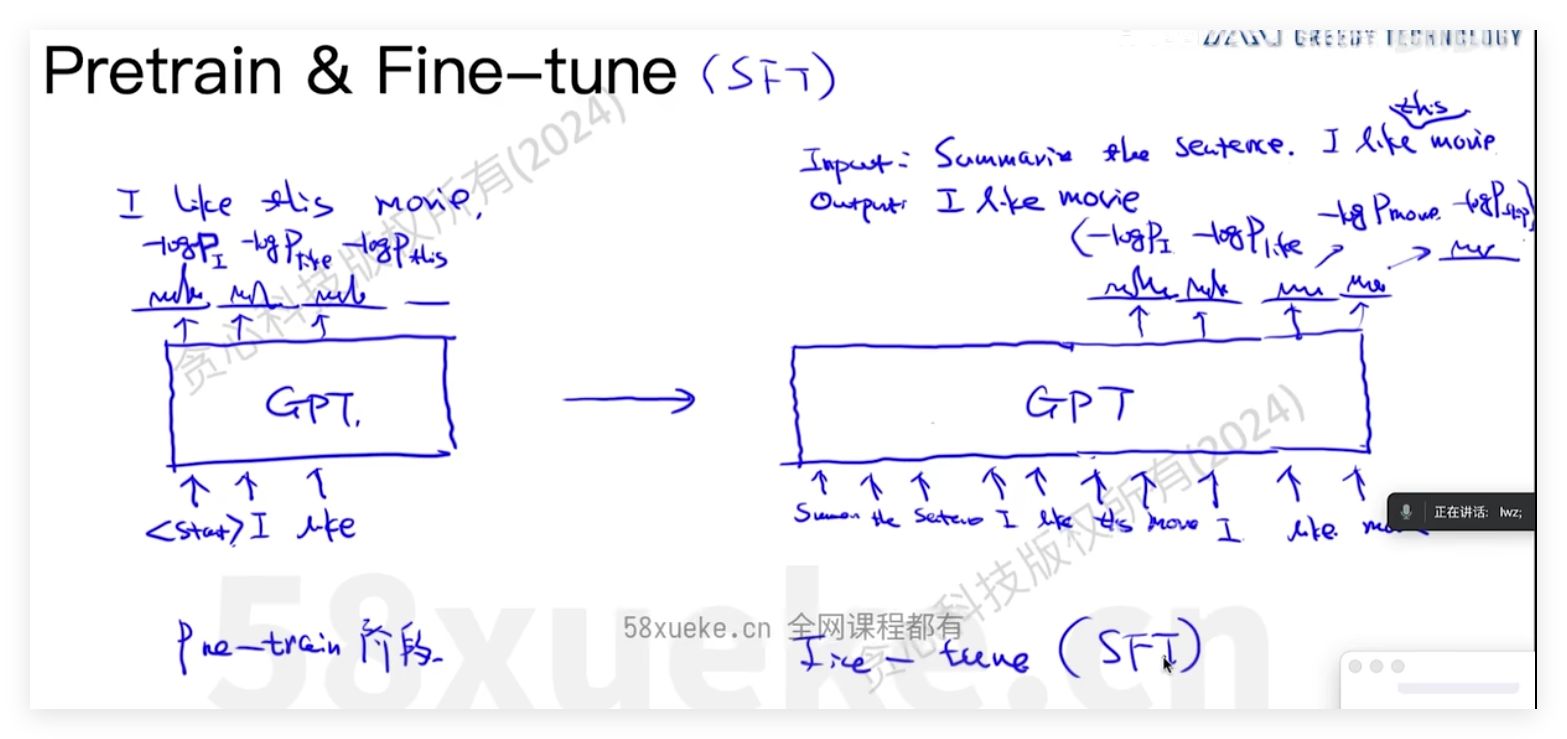
Absolute Position Embedding可视化
LLM Fine-tuning

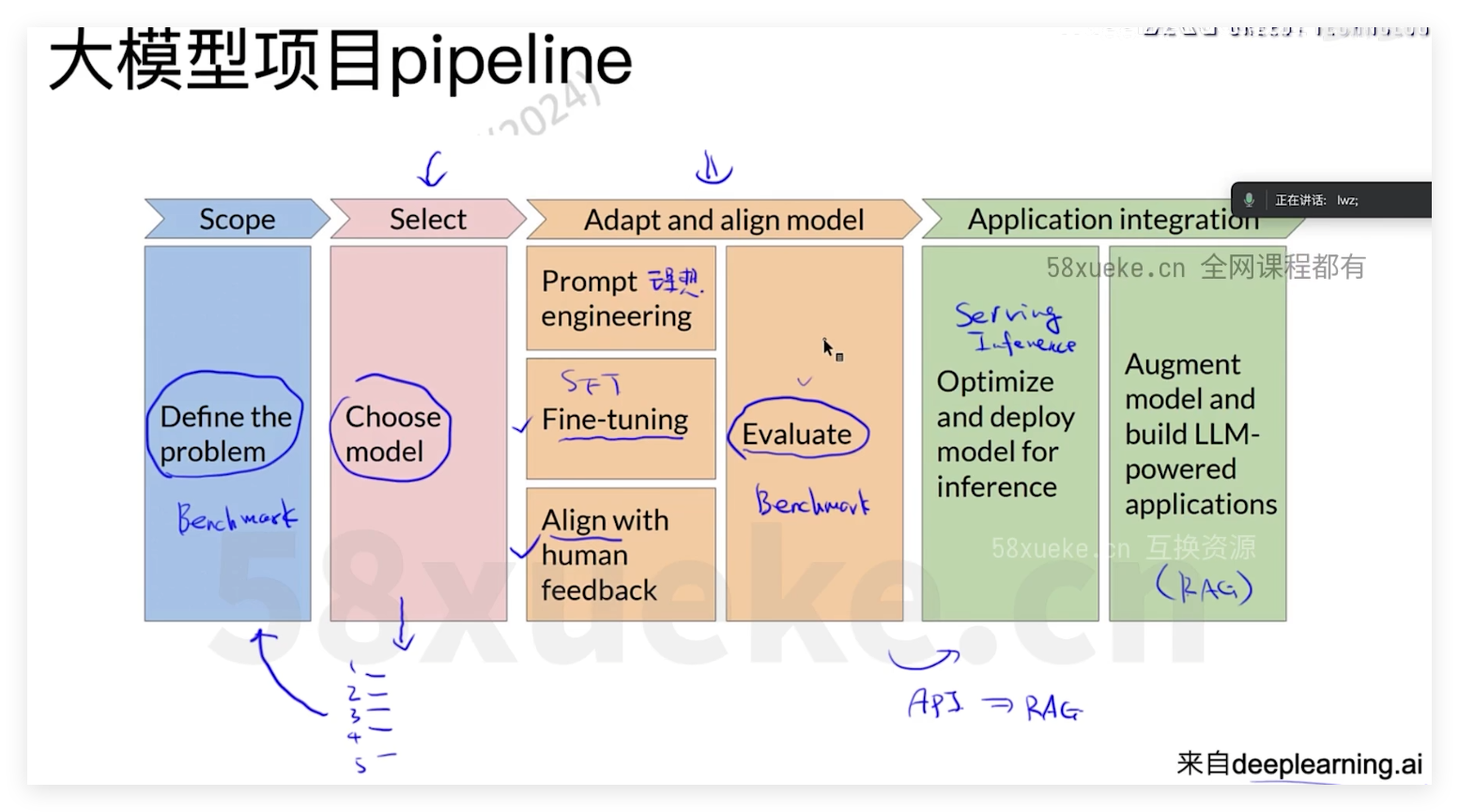
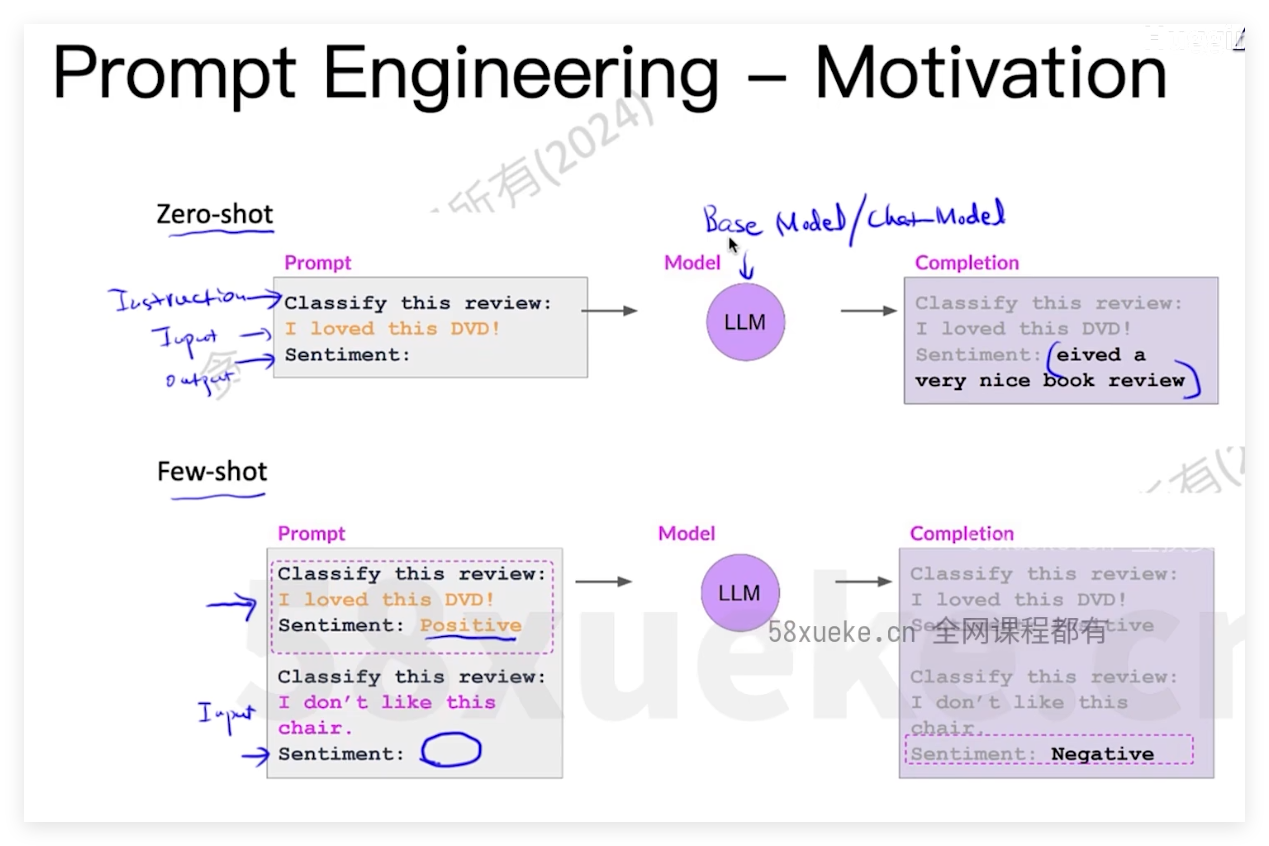
prompt:使用zero-shot或few-shot对input进行补充,但过多的example会造成输入tokens数增加、过拟合等问题



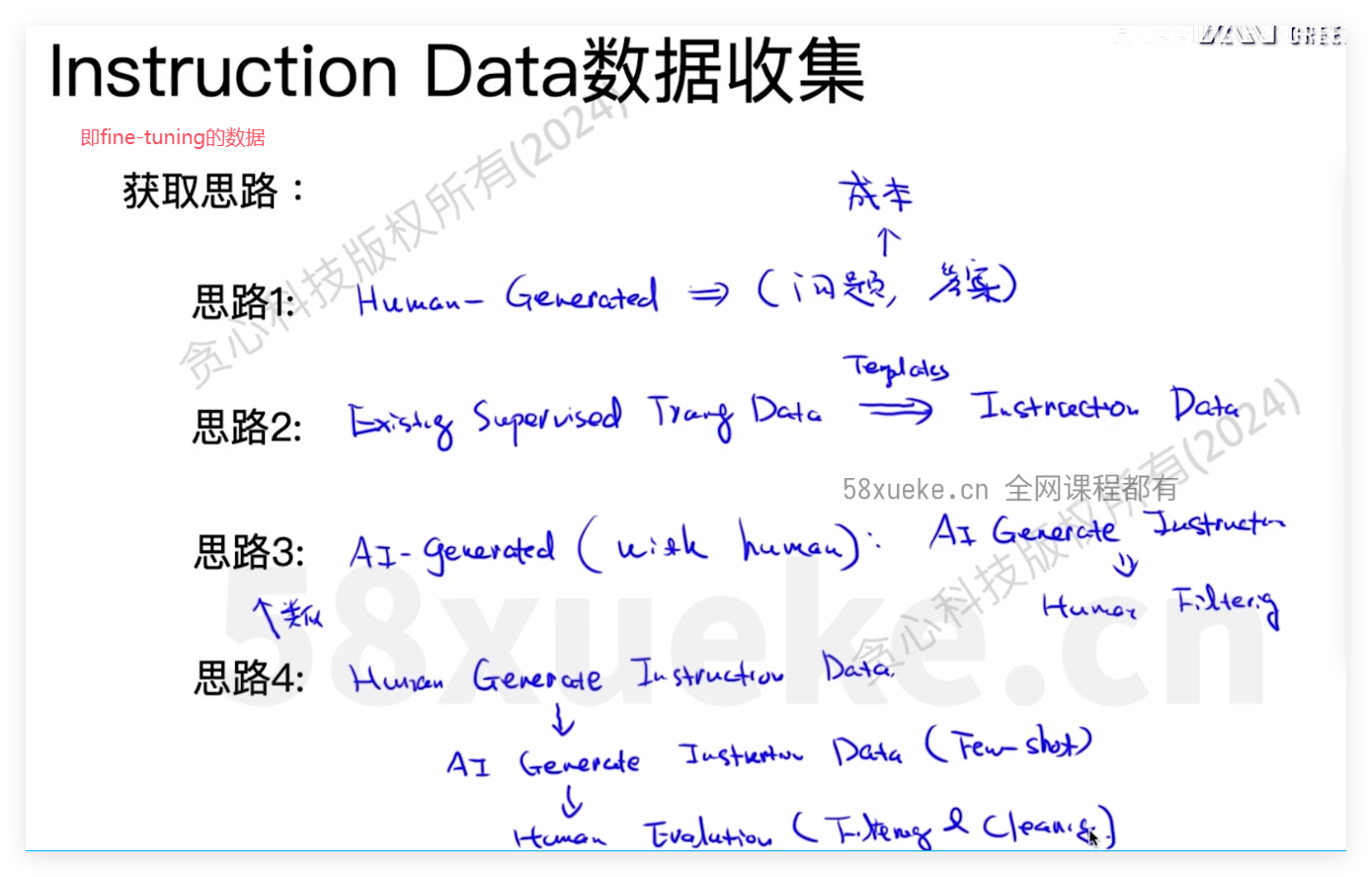
几种微调方式
adaptor tuning(适配器微调)
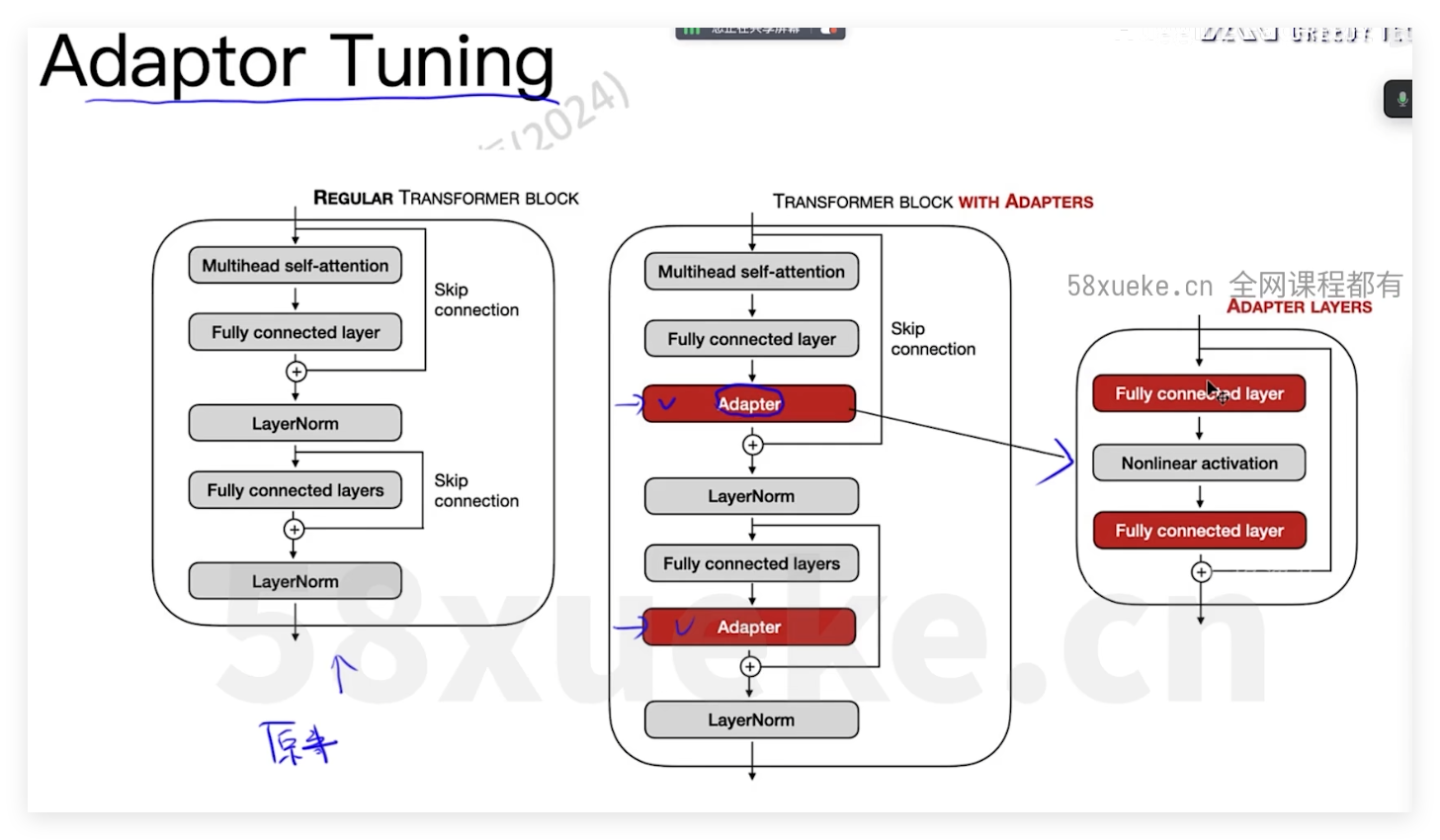
时间成本上升
perfix tuning
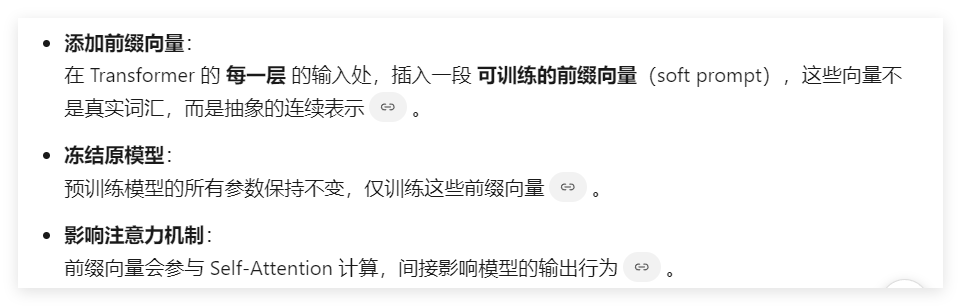
| 特性 | Prefix Tuning | Prompt Tuning |
|---|---|---|
| 插入位置 | Transformer 每一层 | 输入层(embedding 层) |
| 控制粒度 | 更细粒度(多层) | 粗粒度(单层) |
| 参数量 | 略高(每层都要加前缀) | 更低(只加一次) |
| 实现复杂度 | 较高 | 较简单 |
| 性能表现 | 通常优于 Prompt Tuning | 对复杂任务可能不足 |
PrefixTuning:难优化、随着token的添加性能不会持续提
高,占用窗口
Lora
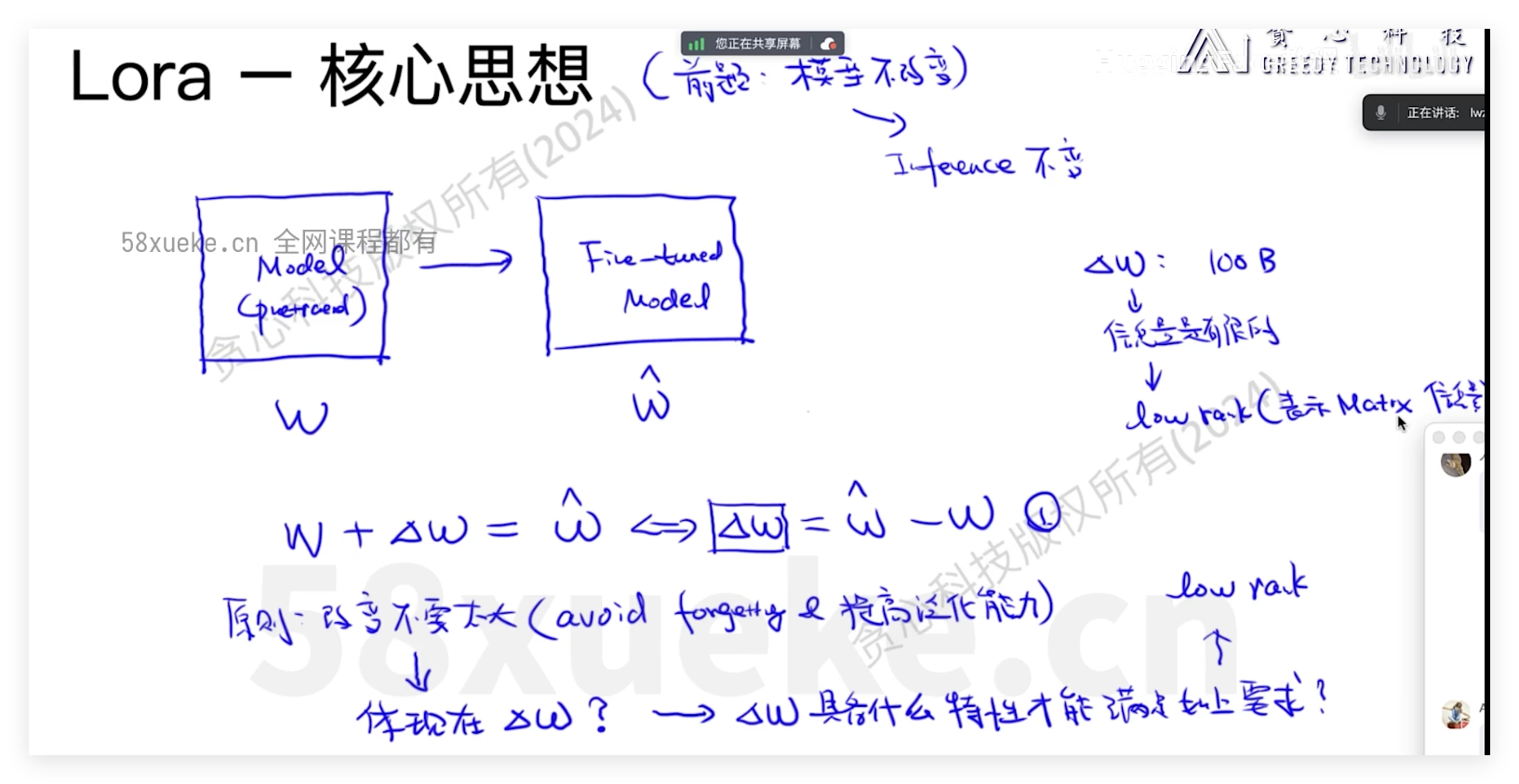
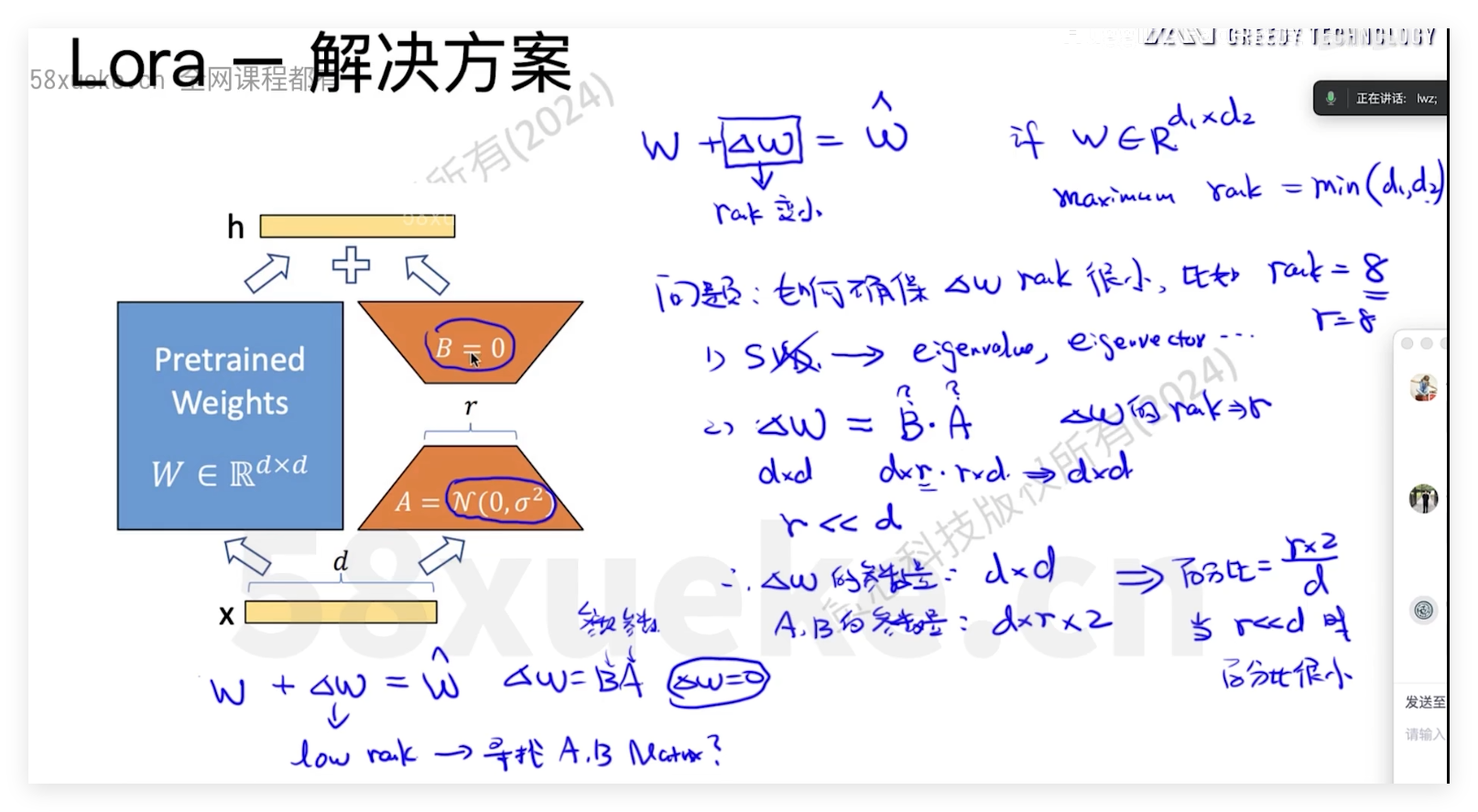

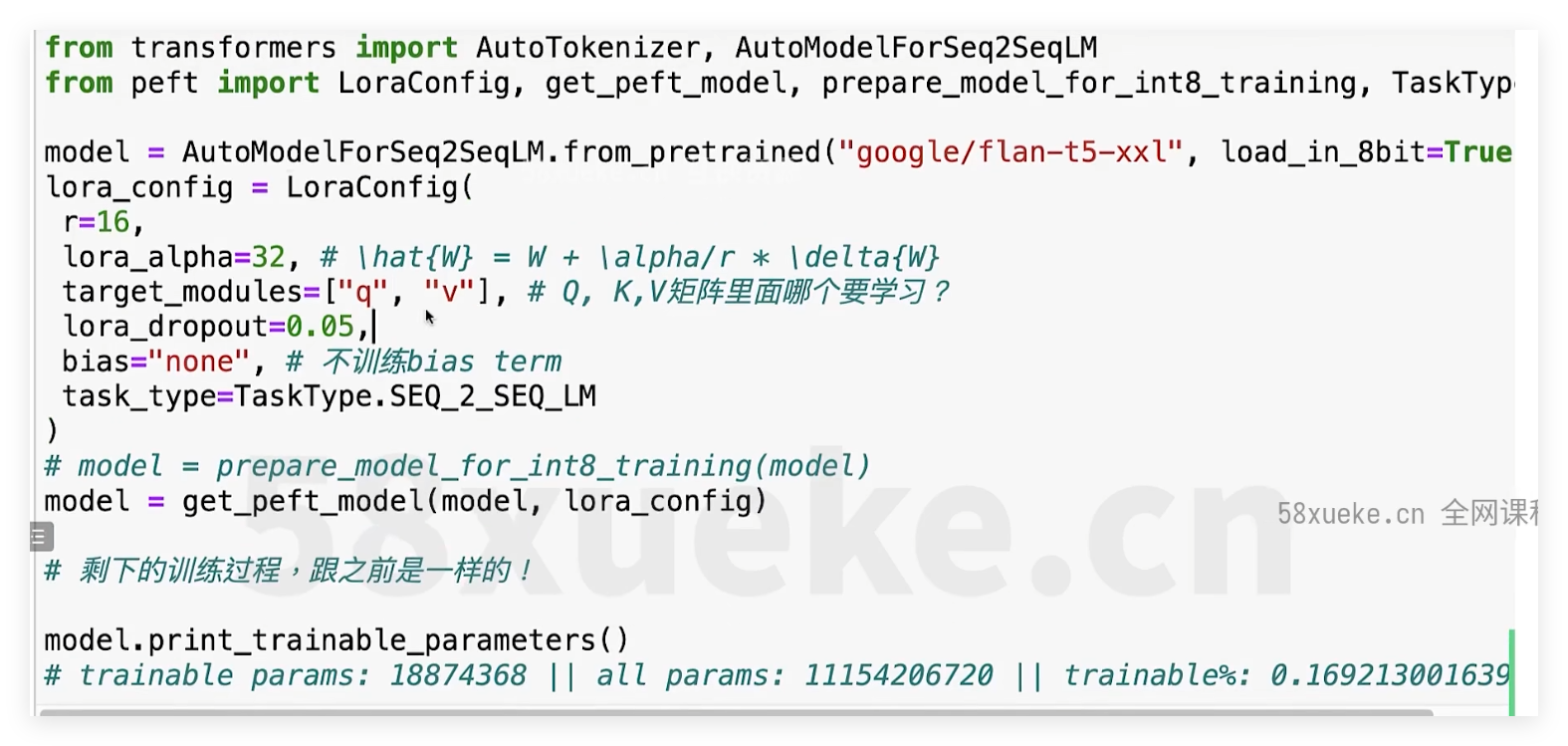
PEFT-lora
some fine-tuning methods
参考资料
bilibili微调
相关文章