云计算-多服务集群部署实战指南:从JumpServer到Kafka、ZooKeeper 集群部署实操流程
简介
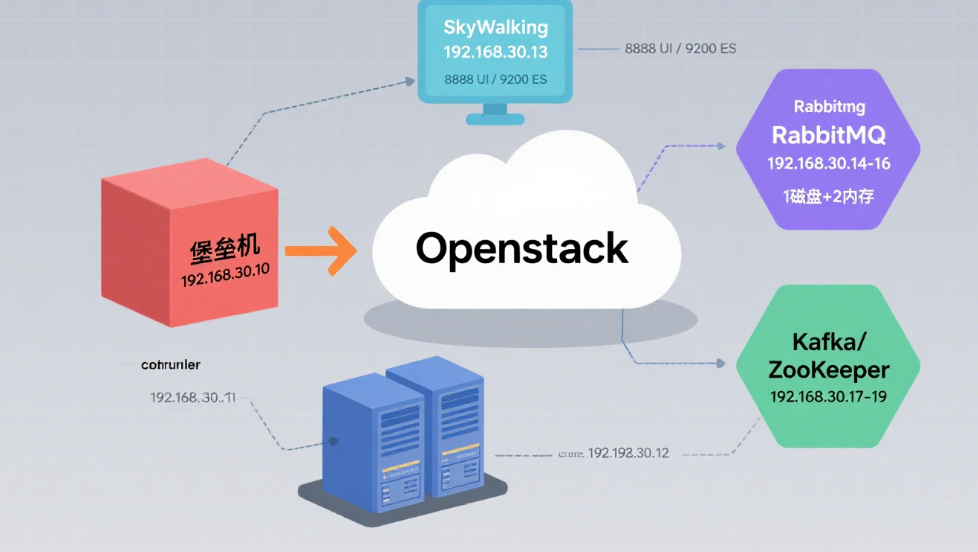
围绕企业级服务部署与集群搭建,基于 OpenStack 私有云平台,介绍了一系列关键服务的实操过程。内容涵盖使用 CentOS7 系统部署 JumpServer 堡垒机并对接 controller 与 compute 节点,构建 RabbitMQ 集群(含磁盘节点与内存节点配置)、Kafka 集群及 ZooKeeper 集群等。每个服务的部署步骤清晰,包括环境配置、软件安装、参数调整及验证方法,快速掌握多类服务与集群的搭建技巧。
1.应用部署:堡垒机部署
使用提供的 OpenStack 平台下创建实例,使用提供的软件包安装 JumpServer 堡垒机服务,并配置使用该堡垒机对接自己安装的 controller 和 compute 节点。软件包:jumpserver.tar.gz
[root@jumpserver ~]# hostnamectl set-hostname jumpServer[root@jumpserver ~]# vi /etc/hosts
192.168.30.10 jumpServer
192.168.30.20 controller
192.168.30.30 compute[root@jumpserver ~]# setenforce 0[root@jumpserver ~]# sed -i s#SELINUX=enforcing#SELINUX=disabled# /etc/selinux/config[root@jumpserver ~]# iptables -F[root@jumpserver ~]# iptables -X[root@jumpserver ~]# iptables -Z[root@jumpserver ~]# /usr/sbin/iptables-save[root@jumpserver ~]# tar -zxvf jumpserver.tar.gz -C /opt/1.#配置源[root@jumpserver ~]# mv /etc/yum.repos.d/* /home/[root@jumpserver ~]# vi /etc/yum.repos.d/jumpserver.repo [jumpserver]name=jumpserverbaseurl=file:///opt/jumpserver-repogpgcheck=0enabled=1[root@jumpserver ~]# yum repolist2.#安装依赖环境[root@jumpserver ~]# yum install python2 -y3.#安装ocker[root@jumpserver ~]# cp /opt/docker/* /usr/bin/[root@jumpserver ~]# chmod 775 /usr/bin/docker*[root@jumpserver ~]# cp -rf /opt/docker.service /etc/systemd/system/[root@jumpserver ~]# chmod 755 /etc/systemd/system/docker.service[root@jumpserver ~]# systemctl daemon-reload[root@jumpserver ~]# systemctl enable docker --now[root@jumpserver ~]# docker --versionDocker version 18.06.3-ce, build d7080c1[root@jumpserver ~]# docker-compose --versiondocker-compose version 1.27.4, build 405241924.#安装jumpserver#加载镜像[root@jumpserver ~]# cd /opt/images/[root@jumpserver images]# sh load.sh#创建jumpsersver服务组建目录[root@jumpserver images]# mkdir -p /opt/jumpserver/{core,koko,lion,mysql,nginx,redis}[root@jumpserver images]# cp -rf /opt/config /opt/jumpserver/启动前清理:docker rm -f $(docker ps -aq)启动: 如未启动,多启动几次 [root@jumpserver images]# cd /opt/compose/[root@jumpserver compose]# source /opt/static.env[root@jumpserver compose]# sh up.sh 使用谷歌浏览器访问http://192.168.30.10对接controller与compute(admin/admin)设置中文字符资产管理---管理用户---创建----远程连接用户名称:rootroot,000000资产管理---系统用户---创建----SSHweb,root,81,000000资产列表----创建controller----IP:192.168.30.20 ----Linux----22---管理用户:root---节点:/Defaultcontroller----IP:192.168.30.30 ----Linux----22---管理用户:root---节点:/Default刷新创建资产授权规则:权限管理----资产授权cloud server----用户----用户组----资产----节点----系统用户测试连接:(刷新)右上角----管理员---用户界面等待几分钟-------5分钟左右自动连接上Web终端---选择我的资产---Default---controller---连接单机controller,连接主机成功
2.部署RabbitMQ集群
使用OpenStack私有云平台,创建三个centos7.5系统的云主机rabbitmq1、rabbitmq2和rabbitmq3,使用附件\私有云附件\RabbitMQ目录下的软件包安装RabbitMQ服务,安装完毕后,搭建RabbitMQ集群,并打开RabbitMQ服务的图形化监控页面插件。集群使用普通集群模式,其中rabbitmq1做磁盘节点,rabbitmq2和rabbitmq3做内存节点。
创建三个节点,分别为mq1,mq2,mq3修改hosts文件,改名 (三个节点)Vi /ect/hosts关闭防火墙,selinux (三个节点)systemctl stop firewalldsetenforce 0getenforce配置好yum源,然后安装yum install -y rabbitmq-server[root@mq1 bin]# rabbitmq-plugins enable rabbitmq_management #启用管理服务[root@mq2 bin]# rabbitmq-plugins enable rabbitmq_management #启用管理服务[root@mq3 bin]# rabbitmq-plugins enable rabbitmq_management #启用管理服务[root@ mq1 ~]# systemctl start rabbitmq-server[root@ mq1 ~]#scp -rp /var/lib/rabbitmq/.erlang.cookie mq2:/var/lib/rabbitmq/[root@ mq1 ~]#scp -rp /var/lib/rabbitmq/.erlang.cookie mq3:/var/lib/rabbitmq/[root@ mq2 ~]#chown rabbitmq:rabbitmq /var/lib/rabbitmq/.erlang.cookie[root@ mq3 ~]#chown rabbitmq:rabbitmq /var/lib/rabbitmq/.erlang.cookie重启rabbitmq服务(二个节点)[root@mq2 bin]# systemctl restart rabbitmq-server[root@mq3 bin]# systemctl restart rabbitmq-servermq2加入集群[root@mq2 bin]# rabbitmqctl stop_app #停止Stopping rabbit application on node rabbit@mq2[root@mq2 bin]# rabbitmqctl join_cluster --ram rabbit@mq1 ###将mq2连接到mq1,成为一个集群Clustering node rabbit@mq2 with rabbit@mq1[root@mq2 bin]# rabbitmqctl start_app #启动检查集群状态 [root@mq2 bin]# rabbitmqctl cluster_statusmq3加入集群[root@mq3 bin]# rabbitmqctl stop_app #停止Stopping rabbit application on node rabbit@mq3[root@mq3 bin]# rabbitmqctl join_cluster --ram rabbit@mq1 ###将mq3连接到mq1,成为一个集群Clustering node rabbit@mq3 with rabbit@mq1[root@mq3 bin]# rabbitmqctl start_app #启动检查集群状态[root@mq3 bin]# rabbitmqctl cluster_status打开浏览器访问http://192.168.200.7:15672/用户名:guest 密码:guest
3.部署zookeep集群与kafka集群
penstack创建三台 云主机,使用 提供的软件包,将这三台云主机构建为 kafka 集群。软件包gpmall-single.tar.gz
#配置基础环境tar -zxvf gpmall-single.tar.gz -C /opt/vi /etc/yum.repos.d/local.repo-----------------[gpmall]name=gpmallbaseurl=ftp://192.168.30.10/gpmall-single/gpmall-repogpgcheck=0enabled=1#centos可以使用openstack的yum[centos]name=centosbaseurl=ftp://192.168.30.10/centosgpgcheck=0enabled=1-----------------#搭建zookeepertar -zxvf zookeeper-3.4.14.tar.gz -C /usr/local/cd /usr/local/zookeeper-3.4.14/conf/mv zoo_sample.cfg zoo.cfgvi zoo.cfg#修改dataDir=/usr/local/zookeeper-3.4.14/data#添加server.0=192.168.30.10:2888:3888server.1=192.168.30.20:2888:3888server.2=192.168.30.30:2888:3888------------------------------------------#在zookeeper中创建data目录mkdir /usr/local/zookeeper-3.4.14/data/vi /usr/local/zookeeper-3.4.14/data/myid#添加 0#传送至其他两台云主机scp -r /usr/local/zookeeper-3.4.14/ t2:/usr/local/scp -r /usr/local/zookeeper-3.4.14/ t3:/usr/local/#修改其他两台的myid 1、2#启动集群(三个节点都启动)cd /usr/local/zookeeper-3.4.14./bin/zkServer.sh start#验证创建myid文件
在3台机器dataDir目录(此处为/tmp/zookeeper)下,分别创建一个myid文件,文件内容分别只有一行,其内容为1,2,3。即文件中只有一个数字,这个数字即为上面zoo.cfg配置文件中指定的值。ZooKeeper是根据该文件来决定ZooKeeper集群各个机器的身份分配。
---------------------[root@node1 ~]# mkdir /tmp/zookeeper
[root@node1 ~]# echo 1 > /tmp/zookeeper/myid
[root@node2 ~]# mkdir /tmp/zookeeper
[root@node2 ~]# echo 2 > /tmp/zookeeper/myid
[root@node3 ~]# mkdir /tmp/zookeeper
[root@node3 ~]# echo 3 > /tmp/zookeeper/myid
[root@node1 ~]# ssh.sh "./zookeeper-3.4.14/bin/zkServer.sh start"[root@t1 zookeeper-3.4.14]# ./bin/zkServer.sh statusZooKeeper JMX enabled by defaultUsing config: /usr/local/zookeeper-3.4.14/bin/../conf/zoo.cfgMode: follower[root@t2 zookeeper-3.4.14]# ./bin/zkServer.sh statusZooKeeper JMX enabled by defaultUsing config: /usr/local/zookeeper-3.4.14/bin/../conf/zoo.cfgMode: leader[root@t3 zookeeper-3.4.14]# ./bin/zkServer.sh statusZooKeeper JMX enabled by defaultUsing config: /usr/local/zookeeper-3.4.14/bin/../conf/zoo.cfgMode: follower
#搭建kafka
tar -zxvf kafka_2.11-1.1.1.tgz -C /usr/local/
cd usr/local/kafka_2.11-1.1.1
vi config/server.properties
----------------
broker.id=0
listeners=PLAINTEXT://192.168.30.10:9092
zookeeper.connect=192.168.30.10,192.168.30.20,192.168.30.30:2181
----------------
#t2
broker.id=1
listeners=PLAINTEXT://192.168.30.20:9092
zookeeper.connect=192.168.30.10,192.168.30.20,192.168.30.30:2181
----------------
#t3
broker.id=2
listeners=PLAINTEXT://192.168.30.30:9092
zookeeper.connect=192.168.30.10,192.168.30.20,192.168.30.30:2181
----------------
#命令解析:
broker.id:每台机器不能一样。
zookeeper.connect:因为有3台ZooKeeper服务器,所以在这里zookeeper.connect设置为3台。
listeners:在配置集群的时候,必须设置,不然以后的操作会报找不到leader的错误。
#启动(三个节点)
[root@zookeeper1 bin]# ./kafka-server-start.sh -daemon ../config/server.properties
[root@zookeeper1 bin]# jps
11825 Kafka
11418 QuorumPeerMain
12191 Jps