从 Web 开发到数据科学:全栈基础技术总结
在当今的技术领域,Web 开发与数据科学的结合日益紧密。无论是构建交互式网页,还是从网络中爬取数据并进行分析可视化,掌握相关基础技术都是关键。本文基于系列 PPT 内容,系统总结从 Web 前端开发、网络爬虫到数据库、数据科学工具的核心知识,助力快速入门全栈技术体系。
一、Web 前端开发基础
Web 前端是用户直接交互的界面,核心由 HTML、CSS、JavaScript 三大技术构成,三者分别负责页面结构、样式美化和交互逻辑。
1. HTML:页面的骨架
HTML(超文本标记语言)是描述网页的标记语言,非编程语言,主要通过标签定义页面结构。
核心概念:
- 超文本:支持图片、音频等多媒体,以及超级链接(
<a>标签)。 - 标签:分为双标签(如
<html></html>)和单标签(如<br/>),标签可嵌套形成层级结构。
- 超文本:支持图片、音频等多媒体,以及超级链接(
常用标签:
- 标题:
<h1>-<h6>(一级到六级标题,字体大小递减)。 - 段落与换行:
<p>(段落)、<br/>(换行)。 - 链接:
<a href="url">文本</a>(跳转至指定 URL)。 - 图片:
<img src="路径" alt="替代文本">(显示图片,alt在图片加载失败时显示)。 - 列表:有序列表
<ol><li></li></ol>、无序列表<ul><li></li></ul>。 - 表单:用于收集用户输入,核心标签为
<form>,包含输入框(<input>)、下拉菜单(<select>)等。
- 标题:
2. CSS:页面的美化
CSS(层叠样式表)用于控制 HTML 元素的外观和布局,实现 “样式与结构分离”。
引入方式:
- 内联式:在标签的
style属性中定义(如<p style="color: red;">文本</p>)。 - 嵌入式:在
<head>中用<style>标签定义(作用于当前页面)。 - 外联式:单独创建
.css文件,通过<link rel="stylesheet" href="路径">引入(可复用,推荐)。
- 内联式:在标签的
选择器:定位需要美化的元素
- 标签选择器:直接使用标签名(如
p { color: blue; })。 - 类选择器:用
.class名(如.highlight { background: yellow; })。 - ID 选择器:用
#id名(如#title { font-size: 20px; },ID 唯一)。
- 标签选择器:直接使用标签名(如
核心样式:
- 字体:
font-family(字体)、font-size(大小)、color(颜色)。 - 布局:
width/height(宽高)、margin(外边距)、padding(内边距)、border(边框)。 - 盒子模型:HTML 元素默认视为 “盒子”,由内容(content)、内边距、边框、外边距组成,是布局的核心。
- 字体:
3. JavaScript:页面的交互
JavaScript 是运行在浏览器中的脚本语言,负责实现页面动态效果和交互逻辑。
特点:弱类型(变量类型由赋值决定)、解释执行、基于对象、跨平台。
引入方式:
- 行内式:在标签事件属性中定义(如
<button onclick="alert('Hello')">点击</button>)。 - 嵌入式:在
<script>标签中编写(作用于当前页面)。 - 外联式:通过
<script src="路径"></script>引入外部.js文件。
- 行内式:在标签事件属性中定义(如
核心语法:
- 变量:用
var声明(如var x = 10; x = "hello";)。 - 函数:
function 函数名(参数) { 逻辑 }(如function add(a,b) { return a+b; })。 - 流程控制:
if-else、switch(选择结构);for、while(循环结构)。 - 事件:如
onclick(点击)、onmouseover(鼠标悬停),用于响应用户操作。
- 变量:用
二、网络爬虫:数据获取的利器
网络爬虫是按规则自动抓取网页信息的程序,广泛用于数据采集、搜索引擎等场景。
1. 爬虫基础
- 概念:又称网页蜘蛛,通过 URL 遍历网页,提取目标数据(如文本、图片、链接等)。
- 分类:
- 通用爬虫:爬取整个网络(如搜索引擎)。
- 聚焦爬虫:只爬取与特定主题相关的页面。
- 增量爬虫:仅爬取更新或新增的页面。
- 流程:发起请求→获取响应→解析数据→存储数据。
2. 核心技术与工具
HTTP 协议:爬虫的基础,通过
GET/POST等方法与服务器交互。GET:参数拼接在 URL 后(如https://xxx?key=value),适合简单数据请求。POST:参数在请求体中,适合传输敏感数据(如登录信息)。
Requests 库:Python 中常用的 HTTP 请求库,简化爬虫开发。
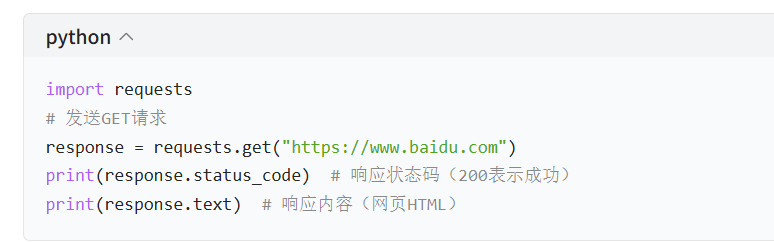
解析工具:
- XPath:通过路径表达式定位 XML/HTML 元素(如
//div[@class="content"]/p/text()提取指定 div 下的文本)。 - BeautifulSoup:解析 HTML/XML,提供简单的 API 提取数据(如
soup.find("div", class_="content").text)。
- XPath:通过路径表达式定位 XML/HTML 元素(如
模拟登录:通过 Cookies 或 Session 保持登录状态,处理需要权限的页面。
3. 案例:爬取网页数据
以爬取大学排名为例,流程如下:
- 用
requests获取网页 HTML; - 用 XPath 解析出学校名称、总分等数据;
- 用
csv库将数据保存到文件。
三、MySQL:数据存储的核心
MySQL 是开源的关系型数据库管理系统,用于高效存储和管理结构化数据。
1. 基础概念
- 数据库:存储数据的仓库,由多个表组成。
- 表:由行(记录)和列(字段)组成,如 “学生表” 包含 “学号、姓名、年龄” 等字段。
- SQL:操作数据库的语言,包括数据定义(DDL)、数据操纵(DML)、查询(DQL)等。
2. 核心操作
DDL(数据定义):创建 / 修改 / 删除数据库和表。

四、数据科学工具:从处理到可视化
数据科学工具用于对数据进行清洗、分析和可视化,常用库包括 NumPy、Pandas、Matplotlib、Seaborn。
1. NumPy:数值计算基础
NumPy 提供高效的多维数组(ndarray)和数学函数,是数据科学的基础库。
- 核心功能:
- 数组创建:
np.array([1,2,3])(一维)、np.zeros((2,3))(全 0 二维数组)。 - 数组操作:重塑(
reshape)、切片(arr[1:3, :2])、广播(不同形状数组运算)。 - 数学函数:求和(
np.sum)、均值(np.mean)、矩阵运算等。
- 数组创建:
2. Pandas:数据分析利器
Pandas 基于 NumPy,提供Series(一维)和DataFrame(二维)数据结构,适合处理表格数据。
- 核心功能:
- 数据读取:
pd.read_csv("data.csv")(读取 CSV 文件)、pd.read_excel("data.xlsx")(读取 Excel)。 - 数据清洗:处理缺失值(
dropna删除缺失行、fillna填充缺失值)、去重(drop_duplicates)。 - 数据分析:分组(
groupby)、聚合(sum/mean)、合并(merge)等。 五、综合应用:技术链串联
从 Web 到数据科学的典型流程:
- 用爬虫(Requests+XPath)从网页抓取数据;
- 用Pandas清洗、处理数据;
- 用Matplotlib/Seaborn可视化分析结果;
- 用MySQL存储结构化数据;
- 用Web 技术(HTML+CSS+JS)展示分析结果。
总结
本文涵盖 Web 前端、爬虫、数据库、数据科学工具的核心知识,是入门全栈技术的基础。实际应用中,需结合具体场景灵活组合这些技术:如需构建数据展示平台,可通过爬虫获取数据,经 Pandas 分析后,用 MySQL 存储,最后用 Web 技术呈现;如需做数据分析,可直接用 Pandas 处理本地数据,再用可视化工具生成图表。
掌握这些技术,能为后续深入学习人工智能、大数据等领域打下坚实基础。
- 数据读取: