open-webui源码分析1—文件上传
open-webui上传文件涉及文件存储、文件数据存储和向量库存储,结合代码进行分析。
第一:分析env.py文件,看看数据存储在哪里
#OPEN_WEBUI_DIR为env.py文件所在目录,在容器中为/app/backenc/open_webui
OPEN_WEBUI_DIR = Path(__file__).parent
#BACKEND_DIR为后端代码所在目录,在容器中为/app/backend
BACKEND_DIR = OPEN_WEBUI_DIR.parent # the path containing this file#BASE_DIR为应用所在目录,在容器中为/app
BASE_DIR = BACKEND_DIR.parent # the path containing the backend/#DATA_DIR 为数据存储目录,在容器中为/app/backenc/data
DATA_DIR = Path(os.getenv("DATA_DIR", BACKEND_DIR / "data")).resolve()
#DATABASE_URL为数据库URL,表明数据库文件为/app/backend/data/webui.db,缺省使用sqlite
DATABASE_URL = os.environ.get("DATABASE_URL", f"sqlite:///{DATA_DIR}/webui.db")#UPLOAD_DIR为文件上传后保存的目录,在容器中为/app/backend/data/uploads目录
UPLOAD_DIR = DATA_DIR / "uploads"
UPLOAD_DIR.mkdir(parents=True, exist_ok=True)#VECTOR_DB确定使用哪类向量库,缺省使用chroma向量库
VECTOR_DB = os.environ.get("VECTOR_DB", "chroma")
#CHROMA_DATA_PATH为向量库存储目录,在容器中为/app/backend/data/vector_db
CHROMA_DATA_PATH = f"{DATA_DIR}/vector_db"
从数据库目录/app/data下拿到webui.db文件,用DB Browser for SQLite打开,找到file表,展开后表结构如下:
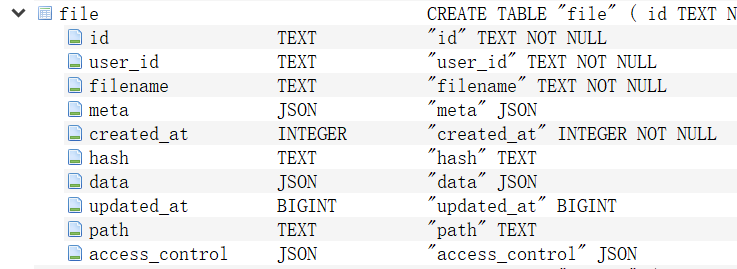
其中:
id:文件唯一标识
user_id:用户唯一标识
filename:上传文件名
meta:元数据
created_at:入库时间
hash:文件摘要
data:文件内容
updated_at:更新时间
path:文件存储路径
access_control:访问控制信息。为空,不必关心
第二:流程分析
首先分析入口方法upload_file(……)函数。
'''
整体流程:
1)调用os.path.basename获取文件名,再把文件名分成名称+扩展名
2)对扩展名进行检查,是否是系统允许的扩展名,如果不是则报错
3)uuid+文件名生成新的文件名
4)设置文件标签: tags = {
"OpenWebUI-User-Email": user.email,
"OpenWebUI-User-Id": user.id,
"OpenWebUI-User-Name": user.name,
"OpenWebUI-File-Id": id,
}
5)保存文件。把文件保存到/app/backend/data/uploads,并返回文件体和文件路径
6)文件数据入库,保存到file表中
7)调用process_file函数进行文件分块和加载到向量库
8)根据文件id查询文件表,获取完整的文件信息后返回到前端'''
@router.post("/", response_model=FileModelResponse)
def upload_file(
request: Request,
file: UploadFile = File(...), #上传文件
metadata: Optional[dict | str] = Form(None), #当前为空,不必关心
process: bool = Query(True), #当前True
internal: bool = False, #当前为False
user=Depends(get_verified_user),#登录用户信息
):'''
以下代码处理metadata,把metadata转换成json对象,然后赋值给file_metadata
因为请求参数中metadata为空,所以不会进行处理
'''
if isinstance(metadata, str):
try:
metadata = json.loads(metadata)
……
file_metadata = metadata if metadata else {}try:
'''
以下代码根据上传文件后缀检查是否为合法文件。缺省对文件后缀没有限制,所以不 会进入检查分支
''''
unsanitized_filename = file.filename
filename = os.path.basename(unsanitized_filename)file_extension = os.path.splitext(filename)[1]
# Remove the leading dot from the file extension
file_extension = file_extension[1:] if file_extension else ""'''
internal为Fasle,但环境变量ALLOWED_FILE_EXTENSIONS并未设置,
所以不进入if分支,实际使用时可根据需要设置允许的文件类型
'''
if (not internal) and request.app.state.config.ALLOWED_FILE_EXTENSIONS:
request.app.state.config.ALLOWED_FILE_EXTENSIONS = [
ext for ext in request.app.state.config.ALLOWED_FILE_EXTENSIONS if ext
]if file_extension not in request.app.state.config.ALLOWED_FILE_EXTENSIONS:
raise HTTPException(
status_code=status.HTTP_400_BAD_REQUEST,
detail=ERROR_MESSAGES.DEFAULT(
f"File type {file_extension} is not allowed"
),
)'''
以下代码完成文件信息入库
'''
id = str(uuid.uuid4())
name = filename#把文件名前加上{uuid}前缀,作为存储在本地的文件名
filename = f"{id}_{filename}"#
tags = {
"OpenWebUI-User-Email": user.email,
"OpenWebUI-User-Id": user.id,
"OpenWebUI-User-Name": user.name,
"OpenWebUI-File-Id": id,
}'''
调用Storage.upload_file保存文件,缺省为本地,文件保存到
容器/app/backend/data/uploads目录下,文件名为{uuid}_{原始文件名}
'''
contents, file_path = Storage.upload_file(file.file, filename, tags)'''
Files.insert_new_file存储文件信息到数据库file表中。
id:uuid
filename:原始文件名
path:文件本地存储路径;
meta为文件元数据,其中:
name:原始文件名
content_type:文件类型
size:文件大小
data:上传文件请求中携带的元数据,当前为空
'''
file_item = Files.insert_new_file(
user.id,
FileForm(
**{
"id": id,
"filename": name,
"path": file_path,
"meta": {
"name": name,
"content_type": file.content_type,
"size": len(contents),
"data": file_metadata,
},
}
),
)'''
因为process为True,所以进入如下分支。完成文件分块并向量化存储,
然后根据id从数据库查询文件数据后返回。
暂不分析视音频文件处理,重点关注文档处理
'''
if process:
try:
if file.content_type:
if file.content_type.startswith("audio/") or file.content_type in {
"video/webm"
}: #针对音视频文件的处理,暂不分析。
file_path = Storage.get_file(file_path)
result = transcribe(request, file_path, file_metadata)process_file(
request,
ProcessFileForm(file_id=id, content=result.get("text", "")),
user=user,
)
elif (not file.content_type.startswith(("image/", "video/"))) or (
request.app.state.config.CONTENT_EXTRACTION_ENGINE == "external"
): #重点分析针对文档文件的分块和向量化处理
process_file(request, ProcessFileForm(file_id=id), user=user)
else: #格式为止文件的处理。暂不分析。
log.info(
f"File type {file.content_type} is not provided, but trying to process anyway"
)
process_file(request, ProcessFileForm(file_id=id), user=user)file_item = Files.get_file_by_id(id=id) #根据文件唯一标识查询file表获取文件数据
except Exception as e:
…… #无关主流程
if file_item:
return file_item #返回文件数据
else:
raise HTTPException(
status_code=status.HTTP_400_BAD_REQUEST,
detail=ERROR_MESSAGES.DEFAULT("Error uploading file"),
)except Exception as e:
…… #无关主流程
下面重点分析process_file(……)函数。
'''
整体流程:
1)从数据库获取文件信息
2)生成向量库存储集合名
3)创建loader并加载文档
4)拼接生成文件内容并入库
5)文档分块并保存到向量库
6)把集合名保存到文件表meta字段
'''
@router.post("/process/file")
def process_file(
request: Request,
form_data: ProcessFileForm,
user=Depends(get_verified_user),
):try:
file = Files.get_file_by_id(form_data.file_id) #从数据库查询得到文件信息collection_name = form_data.collection_name #提取集合名字,当前为空
if collection_name is None:
collection_name = f"file-{file.id}" #生成集合名if form_data.content: #因为form_data中没有content,所以不进入本分支
……
#因为form_data中的collection_name为空,所以不进入以下分支
elif form_data.collection_name:
……
else: #第一次上传文件走该分支
file_path = file.path
if file_path:
file_path = Storage.get_file(file_path)‘'''以下创建loader,加载各种外部文档处理库API配置信息,包括
DATALAB MARKER API,DOCLING API , TIKA API、OCR API等
缺省全部为空,不必关注
'''
loader = Loader(……
)'''
针对PDF文件使用PyPDFLoade,针对word文件使用Docx2txtLoader ,
具体参见 _get_loader(self, filename: str, file_content_type: str, file_path: str)
'''
docs = loader.load(
file.filename, file.meta.get("content_type"), file_path
)#生成Document列表
docs = [
Document(
page_content=doc.page_content,
metadata={
**doc.metadata, #加载后每页的元数据
"name": file.filename, #原文件名
"created_by": file.user_id, #文件所属用户id
"file_id": file.id, #文件唯一标识
"source": file.filename, #原文件名
},
)
for doc in docs
]else: #filepath为空,不会进入本分支,不必关注
……
#拼接所有文档内容为text_content
text_content = " ".join([doc.page_content for doc in docs])
#更新file表data字段,内容为{'content':text_content}
Files.update_file_data_by_id(
file.id,
{"content": text_content},
)#计算文件内容摘要,并更新文件表hash字段
hash = calculate_sha256_string(text_content)
Files.update_file_hash_by_id(file.id, hash)#缺省进入如下分支,进行分块并存储到向量库
if not request.app.state.config.BYPASS_EMBEDDING_AND_RETRIEVAL:
try:
result = save_docs_to_vector_db(
request,
docs=docs,
collection_name=collection_name,
metadata={
"file_id": file.id,
"name": file.filename,
"hash": hash,
},
add=(True if form_data.collection_name else False),
user=user,
)if result:
#更新file表meta字段,在其中追加collection_name信息
Files.update_file_metadata_by_id(
file.id,
{
"collection_name": collection_name,
},
)return {
"status": True,
"collection_name": collection_name,
"filename": file.filename,
"content": text_content,
}
except Exception as e:
raise e
else:
return {
"status": True,
"collection_name": None,
"filename": file.filename,
"content": text_content,
}
下面重点分析save_docs_to_vector_db(……)函数。
'''
整体流程:
1)根据hash查重,确保不存在重复内容的分块
2)选择分块器,可以是RecursiveCharacterTextSplitter,或者TokenTextSplitter
3)对文档列表进行分块,更新元数据列表,并把元数据库中的日期字段转换为字符串
4)创建嵌入函数,对分段后的内容进行嵌入处理,把嵌入后的所有内容插入向量库
'''
def save_docs_to_vector_db(
request: Request,
docs,
collection_name,
metadata: Optional[dict] = None,
overwrite: bool = False,
split: bool = True,
add: bool = False,
user=None,
) -> bool:
if metadata and "hash" in metadata:#因为metadata中有hash,索引进入本分支
#查重,如果存在重复则报错
result = VECTOR_DB_CLIENT.query(
collection_name=collection_name,
filter={"hash": metadata["hash"]},
)if result is not None:
existing_doc_ids = result.ids[0]
if existing_doc_ids:
log.info(f"Document with hash {metadata['hash']} already exists")
raise ValueError(ERROR_MESSAGES.DUPLICATE_CONTENT)if split: #split为True,所以要分块
#缺省使用RecursiveCharacterTextSplitter
if request.app.state.config.TEXT_SPLITTER in ["", "character"]:
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=request.app.state.config.CHUNK_SIZE,
chunk_overlap=request.app.state.config.CHUNK_OVERLAP,
add_start_index=True,
)#如果词元分块,则使用TokenTextSplitter
elif request.app.state.config.TEXT_SPLITTER == "token":
text_splitter = TokenTextSplitter(
encoding_name=str(request.app.state.config.TIKTOKEN_ENCODING_NAME),
chunk_size=request.app.state.config.CHUNK_SIZE,
chunk_overlap=request.app.state.config.CHUNK_OVERLAP,
add_start_index=True,
)
else:
raise ValueError(ERROR_MESSAGES.DEFAULT("Invalid text splitter"))#进行分块
docs = text_splitter.split_documents(docs)
if len(docs) == 0:
raise ValueError(ERROR_MESSAGES.EMPTY_CONTENT)#生成文档内容列表
texts = [doc.page_content for doc in docs]
#生成元数据列表,追加参数中的metadata和embedding_config内容
metadatas = [
{
**doc.metadata,
**(metadata if metadata else {}),
"embedding_config": json.dumps(
{
"engine": request.app.state.config.RAG_EMBEDDING_ENGINE,
"model": request.app.state.config.RAG_EMBEDDING_MODEL,
}
),
}
for doc in docs
]#把元数据库中日期字段转换为字符串,从而提高向量库的查询效率
for metadata in metadatas:
for key, value in metadata.items():
if (
isinstance(value, datetime)
or isinstance(value, list)
or isinstance(value, dict)
):
metadata[key] = str(value)#集合是否存在,如果存在则判断是否允许覆盖,或者是否允许追加
try:
if VECTOR_DB_CLIENT.has_collection(collection_name=collection_name):
log.info(f"collection {collection_name} already exists")if overwrite:
VECTOR_DB_CLIENT.delete_collection(collection_name=collection_name)
log.info(f"deleting existing collection {collection_name}")
elif add is False:
log.info(
f"collection {collection_name} already exists, overwrite is False and add is False"
)
return True#创建嵌入函数
embedding_function = get_embedding_function(
request.app.state.config.RAG_EMBEDDING_ENGINE,
request.app.state.config.RAG_EMBEDDING_MODEL,
request.app.state.ef,
(
request.app.state.config.RAG_OPENAI_API_BASE_URL
if request.app.state.config.RAG_EMBEDDING_ENGINE == "openai"
else (
request.app.state.config.RAG_OLLAMA_BASE_URL
if request.app.state.config.RAG_EMBEDDING_ENGINE == "ollama"
else request.app.state.config.RAG_AZURE_OPENAI_BASE_URL
)
),
(
request.app.state.config.RAG_OPENAI_API_KEY
if request.app.state.config.RAG_EMBEDDING_ENGINE == "openai"
else (
request.app.state.config.RAG_OLLAMA_API_KEY
if request.app.state.config.RAG_EMBEDDING_ENGINE == "ollama"
else request.app.state.config.RAG_AZURE_OPENAI_API_KEY
)
),
request.app.state.config.RAG_EMBEDDING_BATCH_SIZE,
azure_api_version=(
request.app.state.config.RAG_AZURE_OPENAI_API_VERSION
if request.app.state.config.RAG_EMBEDDING_ENGINE == "azure_openai"
else None
),
)#对分块后的内容进行嵌入处理
embeddings = embedding_function(
list(map(lambda x: x.replace("\n", " "), texts)),
prefix=RAG_EMBEDDING_CONTENT_PREFIX,
user=user,
)#嵌入内容插入向量库
VECTOR_DB_CLIENT.insert(
collection_name=collection_name,
items=items,
)return True
……