kafka集群搭建
1.本次搭建涉及3台centos7主机,防火墙与selinux服务均关闭
2.主机参数如下表所示
| name | IP | port | service |
| A | 10.1.60.112 | 2128、2888、3888、9092 | kafka、zookeeper |
| B | 10.1.60.114 | 2128、2888、3888、9092 | kafka、zookeeper |
| C | 10.1.60.115 | 2128、2888、3888、9092 | kafka、zookeeper |
3.部署zookeeper高可用集群服务
要求不高的话其实可以不单独部署也行,kafka中也有带zookeeper,如何配置也会在压测文章中说明一下 ,因为压测需要一台kafka机器执行脚本
参考:zookeeper集群搭建_Apex Predator的博客-CSDN博客
4.创建kafka存放目录(三台主机均需执行下面每个步骤的操作命令)
mkdir /etc/kafka
5.从kafka官网下载安装包
我这里下载了3.3.1版本的kafka,放到kafka目录中,需要其它版本可以从下面的地址里自行下载
下载地址:Apache Kafka
6.解压安装包并更改名称
tar -zxvf /etc/kafka/kafka_2.12-3.3.1.tgz
mv /etc/kafka/kafka_2.12-3.3.1 /etc/kafka/kafka
![]()
7. 编辑kafka配置文件(三个节点只有配置文件的前三项配置不一样,根据注释配置即可)
vi /etc/kafka/kafka/conf/server.properties
broker.id=0 #注意每个kafka节点的配置文件的此项配置不能相同,必须配置不同的id,可以随意配置数字
listeners=PLAINTEXT://10.1.60.112:9092 #ip地址填写每个节点主机对应的ip地址,这个参数指定了 Kafka 服务器监听的地址和端口
advertised.listeners=PLAINTEXT://10.1.60.112:9092 #ip地址填写每个节点主机对应的ip地址,这个参数指定了 Kafka 服务器向外部客户端公开的地址和端口。由于 Kafka 可能运行在一个内部网络中,客户端无法直接访问 Kafka 服务器的地址和端口,因此需要将 Kafka 服务器的地址和端口映射到外部网络中的一个地址和端口
num.network.threads=3 #网络处理线程数,一般有几个节点就配置几个线程
num.io.threads=4 #I/O处理的线程数,根据cpu核心配置,一般配置核心数量的2-3倍
socket.send.buffer.bytes=102400 #这个参数指定了 Kafka 生产者和服务器之间网络 socket 连接的发送缓冲区大小(以字节为单位),如果生产者发送消息的速度比服务器处理消息的速度快,那么这个缓冲区可能会被填满,从而导致生产者阻塞等待缓冲区空间,适当增加能提高性能,需要根据消息大小和并发量等因素配置
socket.receive.buffer.bytes=102400 #这个参数指定了 Kafka 生产者和服务器之间网络 socket 连接的接收缓冲区大小(以字节为单位)。如果服务器发送消息的速度比生产者处理消息的速度快,那么这个缓冲区可能会被填满,从而导致生产者无法及时接收消息,适当增加能提高性能
socket.request.max.bytes=104857600 #个参数指定了 Kafka 生产者和服务器之间网络 socket 连接的最大请求大小(以字节为单位)。如果生产者发送的请求超过这个大小,那么服务器可能会拒绝处理这个请求
log.dirs=/etc/kafka/kafka/log #消息持久化的存放目录,所有tpoic的分区数据文件都在此目录下
num.recovery.threads.per.data.dir=1 #数据目录用来日志恢复的线程数目,默认为1
num.partitions=1 #创建topic时的默认分区数,默认为1
offsets.topic.replication.factor=3 #kafka集群中自动创建名称为__consumer_offsets的topic的副本数量,默认为1,配置为1的话集群不能高可用,一个节点挂掉会导致整个集群不可用
log.retention.hours=72 #消息的最大持久化时间,默认为168小时,超过后自动删除
zookeeper.connect=10.1.60.112:2181,10.1.60.114:2181,10.1.60.115:2181 #设置zookeeper集群的连接端口8.创建配置文件中的数据存放目录
mkdir /etc/kafka/kafka/log
9.启动kafka服务
/etc/kafka/kafka/bin/kafka-server-start.sh -daemon /etc/kafka/kafka/config/server.properties
启动后可以查看一下日志是否有错误输出
tail -f /etc/kafka/kafka/logs/kafkaServer.out
查看kafka端口是否正常监听
netstat -tlpn |grep 9092

查看kafka是否存在kafka服务
ps -ef |grep kafka

10.测试
创建一个topic(kafka为集群模式,在任意节点下执行即可)
/etc/kafka/kafka/bin/kafka-topics.sh --create --bootstrap-server 10.1.60.112:9092 --replication-factor 3 --partitions 6 --topic test
查看创建的topic信息
/etc/kafka/kafka/bin/kafka-topics.sh --describe --bootstrap-server 10.1.60.114:9092 --topic test
 可以看到创建的topic分区将leader平均的分配到了不同的节点上,每个分区的副本也在每个节点都有存在
可以看到创建的topic分区将leader平均的分配到了不同的节点上,每个分区的副本也在每个节点都有存在
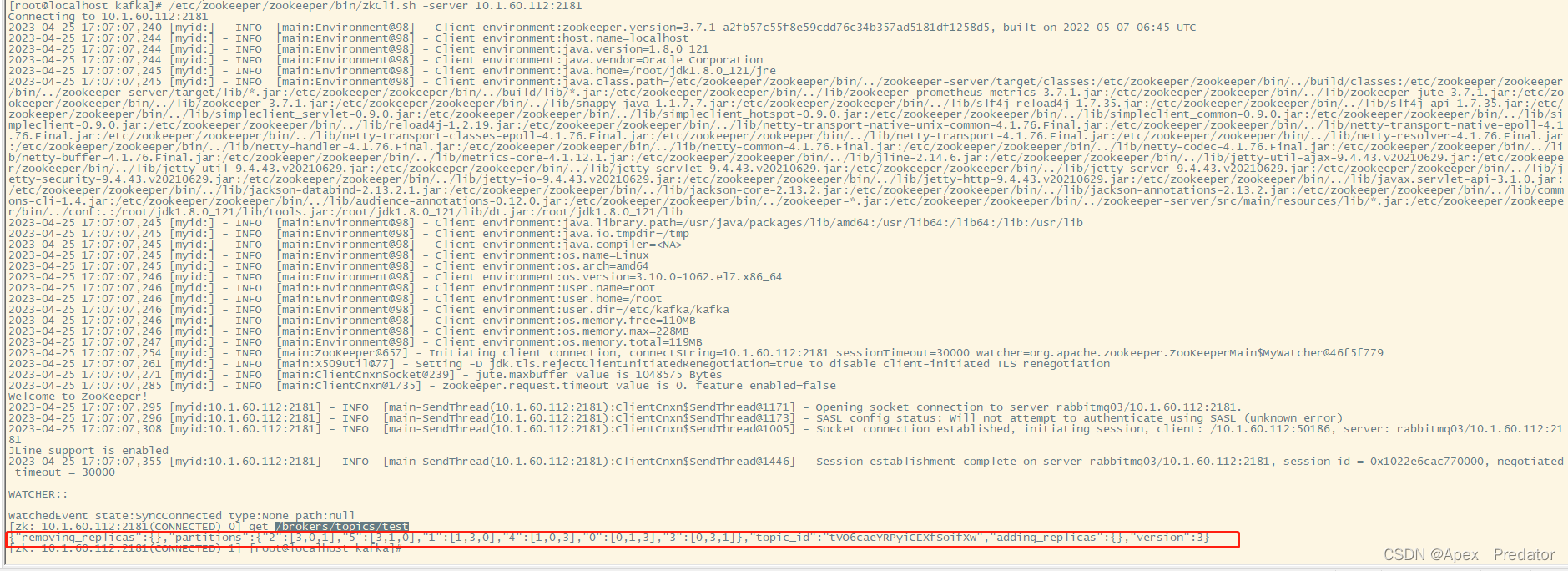
也可以通过zookeeper查看(zookeeper为集群模式,在任意节点下执行即可)
/etc/zookeeper/zookeeper/bin/zkCli.sh -server 10.1.60.112:2181
get /brokers/topics/test
查看每个节点的log数据目录下,也都生成了topic分区的数据目录
ls /etc/kafka/kafka/log
