redis原理篇--Dict
Dict数据结构

一、Redis字典的核心组件
Redis字典由三部分构成:
dictht(哈希表):存储桶数组与元数据dictEntry(哈希节点):存储键值对dict(字典主体):包含双哈希表(用于渐进式重哈希)和类型函数
二、哈希表结构 dictht(Dict HashTable)
typedef struct dictht {dictEntry **table; // 桶数组指针unsigned long size; // 哈希表总槽位数(桶大小)unsigned long sizemask; // 掩码(size-1)unsigned long used; // entry的数量
} dictht;
字段详解:
dictEntry **table- 核心存储结构:指向指针数组(entry数组)的指针
- 数组元素为
dictEntry*类型(链表头指针)
size- 哈希表的大小(总是2^n)
- 通过
_dictNextPower函数动态扩容(如4→8→16)
sizemask- 核心优化设计:值为
size-1 - 作用:替代取模运算
index = hash & sizemask
- 核心优化设计:值为
used- 当前有效节点数量(非空桶计数)
- 缩容条件:
used/size < 0.1
这里的 used即标识entry数量的字段可能比哈希表大小字段更大,因为可能计算出同样的hash值,所以value就放在同一个位置
三、哈希节点 dictEntry
typedef struct dictEntry {void *key; // 键指针union { // 联合值域(节约内存)void *val; // 通用值指针uint64_t u64; // 无符号64位整数int64_t s64; // 有符号64位整数double d; // 双精度浮点} v;struct dictEntry *next; // 冲突链表指针
} dictEntry;
字段详解:
void *key- 键的指针(支持任意数据类型)
- 实际存储类型取决于Redis对象系统(SDS/INET等)
- 通过
dictType中的哈希函数计算索引
值联合体
v- 创新设计:共用内存空间(每次只用一种类型)
val:通用对象指针(如RedisObject)u64/s64:直接存储整数(避免内存碎片)d:直接存储浮点数(如ZSET的score)- 典型内存优化:8字节空间覆盖所有类型
struct dictEntry *next- 冲突解决方案:单向链表
- 头插法添加新节点(O(1)复杂度)
- 链表长度>64触发树化(在rehash时转换)
Dict添加键值对过程
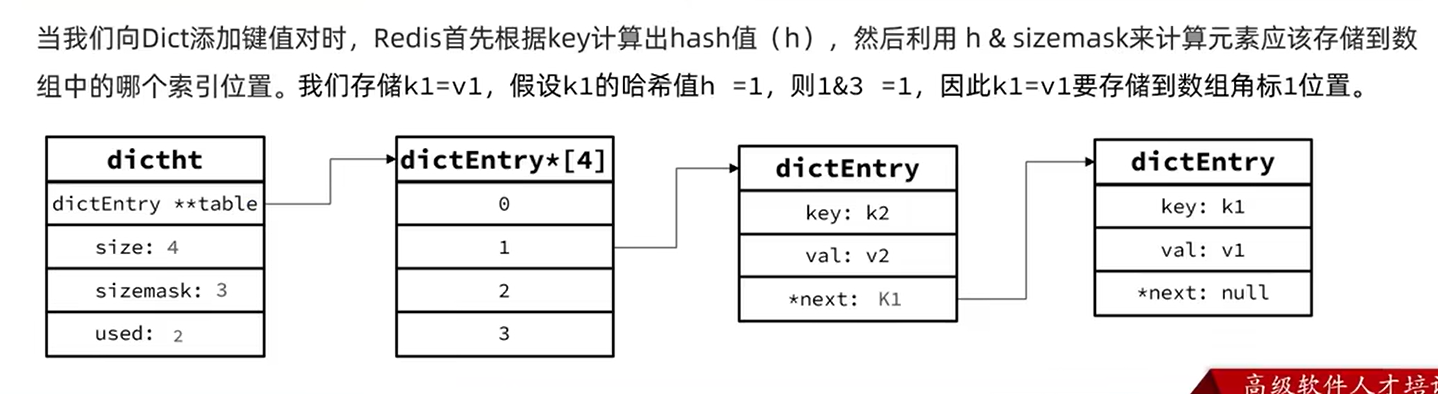
步骤1:计算哈希值与索引
// 示例:添加键值对 k1:v1
hash = dict->type->hashFunction(k1); // 计算键k1的SipHash值
index = hash & dict->ht[0].sizemask; // 图中sizemask=3
步骤2:解决哈希冲突
- 创建新entry:
entry = zmalloc(sizeof(dictEntry)); entry->key = k1; entry->v.val = v1; - 头插法链入:
entry->next = dict->ht[0].table[index]; // 原table[1]指向k2节点,新entry指向k2
步骤3:更新哈希表状态
dict->ht[0].table[index] = entry; // 桶指针指向新插入的entry
dict->ht[0].used++; // used计数+1(used从1→2)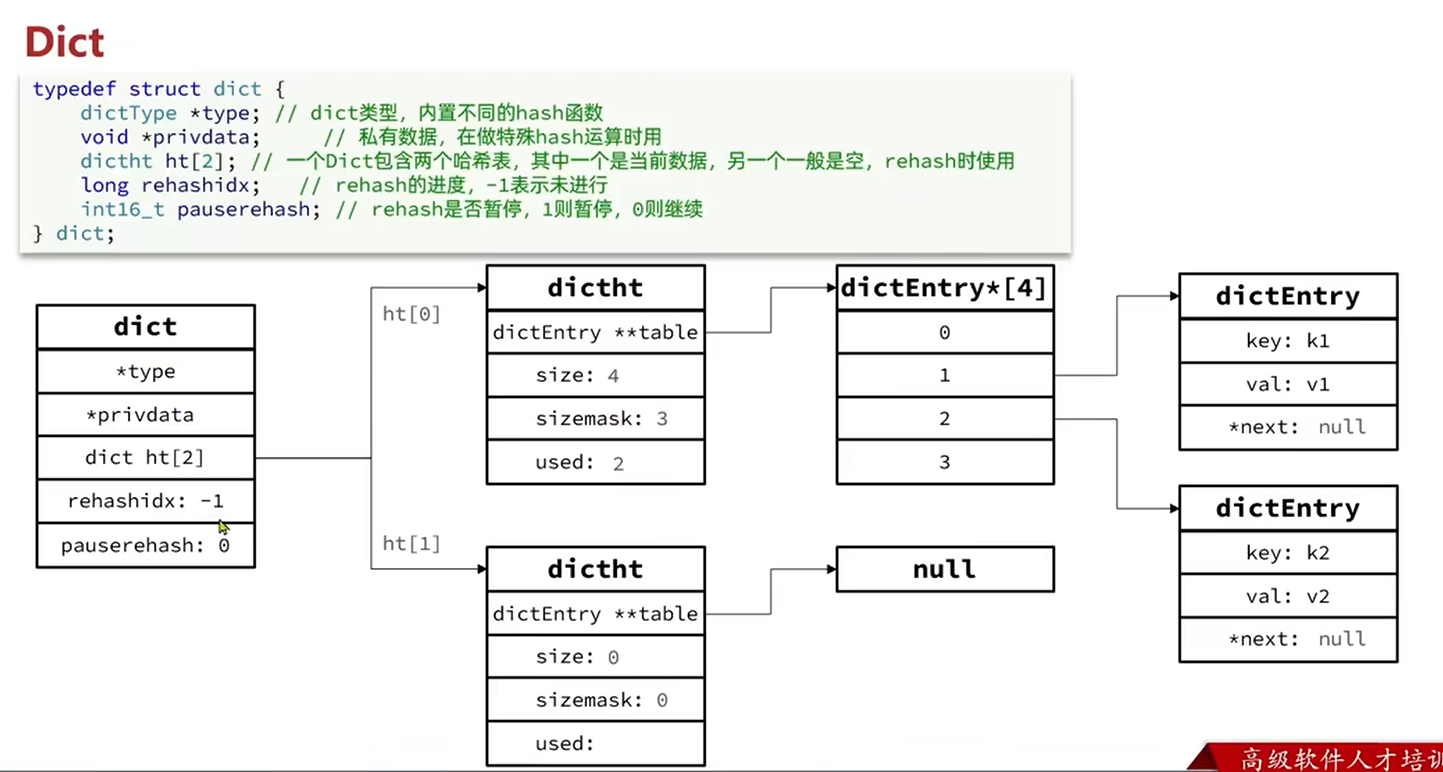
Dict数据结构中,默认使用Dict中的第一个哈希表作为数据的存储,图片中
ht[0]被初始化为一个dictht结构体(table数组大小为4,存储两个键值对k1:v1和k2:v2)。ht[1]为null,所有字段(table、size等)为空或0,表明当前未进行rehash。
Dict的扩容

每次扩容时都是扩容都是扩容到2**n,并且是第一个大于等于used+1的2**n
条件一:LoadFactor ≥ 1 且无后台进程运行
if (d->ht[0].used >= d->ht[0].size && dict_can_resize) // 等效于"LoadFactor≥1"
设计目的
平衡内存效率和性能:当平均每个桶至少存储一个元素时(LoadFactor=1),冲突概率显著增加。此时扩容可降低冲突率,但需考虑系统负载。后台进程限制原因
保护持久化操作:- 执行
BGSAVE或BGREWRITEAOF时,Redis使用写时复制(Copy-on-Write) 机制 - 若此时扩容(分配新哈希表),会触发大量内存页复制
- 可能耗尽内存或造成性能抖动(图示代码注释明确提到此保护逻辑)
- 执行
条件二:LoadFactor > 5
// dict_force_resize_ratio 在源码中定义为5
if (d->ht[0].used/d->ht[0].size > dict_force_resize_ratio)
设计目的
紧急避险机制:
当哈希冲突极度严重时(平均每个桶链长超过5),即使有后台进程运行也强制扩容,避免查询性能雪崩(链表遍历从O(1)退化为O(n))。临界值选择依据
- 经验值:桶链超过5个节点,查找效率明显下降(实测性能衰减曲线)
- 内存容忍上限:5倍空间浪费是可承受极限(例:16个桶存80个元素)
Dict的收缩

收缩大小为第一个大于等于used的2**n,此时的size远比used大,之所以是大于等于要保证实际
当删除元素后,Redis 会调用 htNeedsResize(dict) 检查是否满足收缩条件:
size = dictSlots(dict); // 哈希表总槽位数
used = dictSize(dict); // 已使用槽位数(键值对数量)
if (size > DICT_HT_INITIAL_SIZE && (used * 100 / size < HASHTABLE_MIN_FILL)) { // 默认HASHTABLE_MIN_FILL=10return 1; // 需要收缩
}
条件解读:
- 哈希表大小超过初始值(
DICT_HT_INITIAL_SIZE,默认为4) - 负载因子 < 10%(即已用槽位数不足总槽位的10%)
- 特殊保护:若
used < 4,强制按4计算,避免过度收缩
收缩执行流程
1. 调用入口
删除元素后触发检查:
// t_hash.c
if (dictDelete(dict, field) == C_OK) {if (htNeedsResize(o->ptr)) dictResize(o->ptr); // 满足条件则执行收缩
}
2. 计算目标大小
// dictResize() 逻辑
minimal = dict->ht[0].used; // 当前实际元素数量
if (minimal < DICT_HT_INITIAL_SIZE)minimal = DICT_HT_INITIAL_SIZE; // 最小收缩到初始大小
return dictExpand(dict, minimal);可以看到这里不论是收缩还是扩容最后都调用了dictExpand方法 下面是该源码
int dictExpand(dict *d, unsigned long size) {return _dictExpand(d, size, NULL);
}/* * 扩展或收缩字典的哈希表* * @param d: 目标字典指针* @param size: 期望的新哈希表大小* @param malloc_failed: 内存分配失败标志(输出参数)* @return: 操作状态(DICT_OK 或 DICT_ERR)*/
int _dictExpand(dict *d, unsigned long size, int* malloc_failed) {// 初始化内存分配失败标志if (malloc_failed) *malloc_failed = 0;/* * 有效性检查:* 1. 如果字典正在 rehash 中,禁止扩展* 2. 如果当前元素数量大于目标大小,禁止收缩,这里的size就是目标扩容大小*/if (dictIsRehashing(d) || d->ht[0].used > size)return DICT_ERR;dictht n; /* 新哈希表 */// 计算新的size(调整为大于等于size的最小2的幂)unsigned long realsize = _dictNextPower(size);/* 如果新size与当前size相同,无需操作 */if (realsize == d->ht[0].size) return DICT_ERR;/* 分配新哈希表并初始化所有指针为NULL */n.size = realsize;n.sizemask = realsize-1; // 掩码用于快速计算索引/* * 内存分配策略:* - 如果允许内存分配失败(malloc_failed != NULL),使用尝试分配* - 否则使用强制分配(失败会panic)*/if (malloc_failed) {n.table = ztrycalloc(realsize*sizeof(dictEntry*));*malloc_failed = n.table == NULL; // 设置分配失败标志if (*malloc_failed)return DICT_ERR;} else {n.table = zcalloc(realsize*sizeof(dictEntry*));}n.used = 0; // 初始化已用槽位数为0/* * 首次初始化处理(非rehash场景):* 当ht[0]为空时,直接使用新哈希表作为主表*/if (d->ht[0].table == NULL) {d->ht[0] = n;return DICT_OK;}/* * 准备渐进式rehash:* 1. 将新哈希表放入ht* 2. 设置rehashidx=0标记开始rehash* (图片中dictResize()最终会调用此逻辑)*/d->ht[1] = n;d->rehashidx = 0; // 从索引0开始迁移数据return DICT_OK;
}
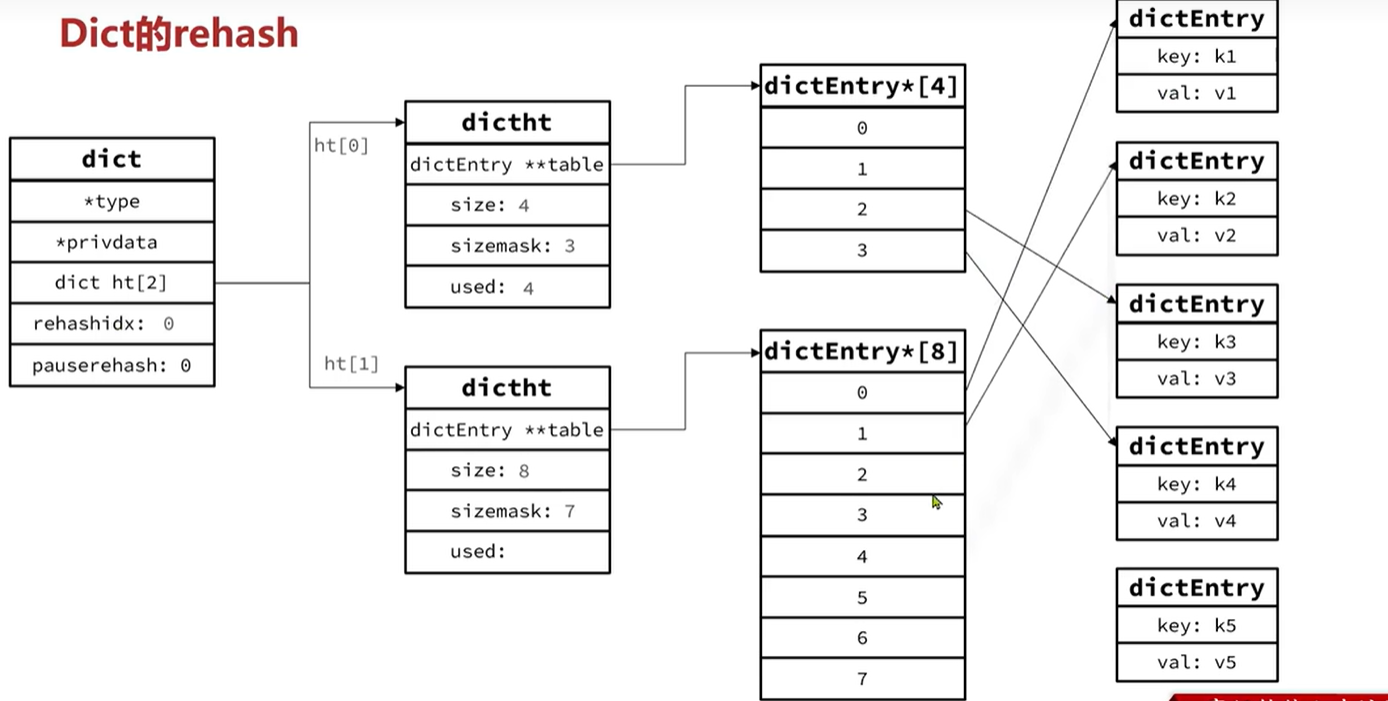
如图会更具当前的used来去判断此时的dictEntry的大小 并且为二的n次方,迁移的时候会将dictEntry从原本的地方一个一个迁移过来,全部迁移完过后ht[0]的table指针会指向新的dictEntry,ht[1]指向null
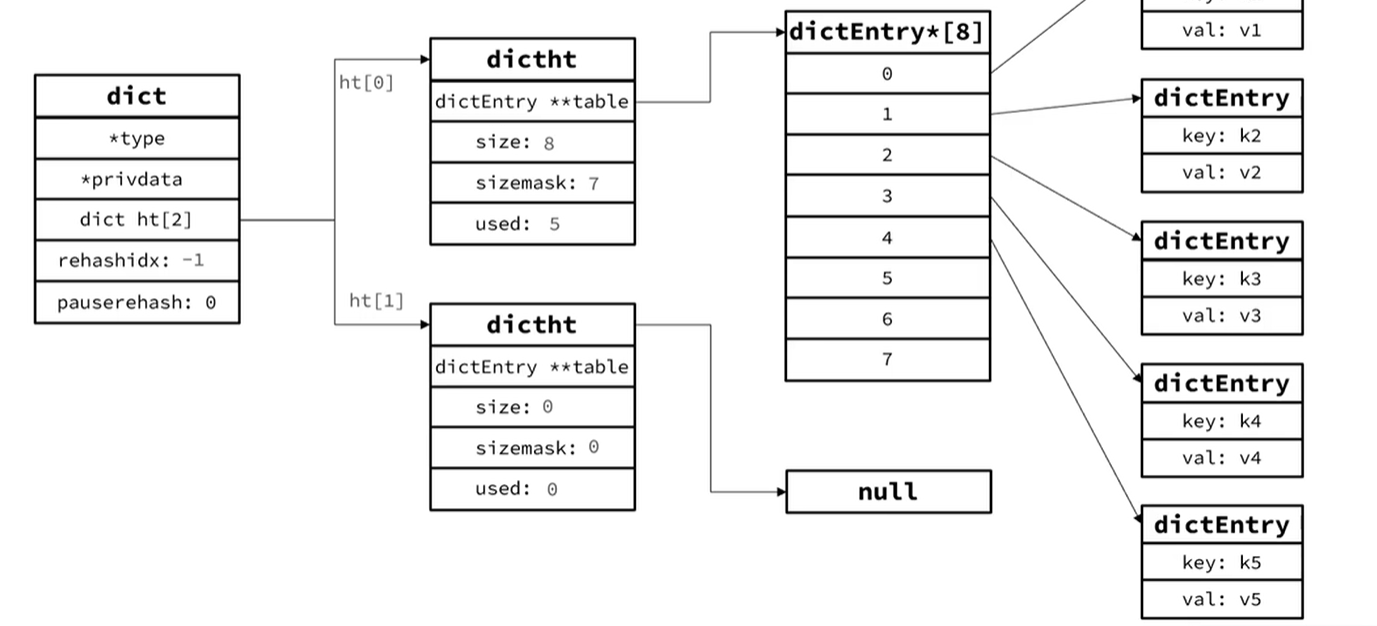
但是如果说一次性完成的话 如果Dict中包含的数据太多了,可能会导致主线程阻塞 因此DIct的rehash是多次完成的,如果是查询和修改那么ht[0]的dictEntry和ht[1]的dictEntry都需要去查询
