日本做a的小视频在线观看网站2345浏览器网址
目录
摘要
17 DBSCAN 聚类算法
17.1 本章工作任务
17.2 本章技能目标
17.3 本章简介
17.4 编程实战
17.5 本章总结
17.6 本章作业
本章已完结!!!
摘要
本章实现的工作是:首先导入100位学生的数学成绩、英语成绩,然后建立 DBSCAN 模型,配置模型参数,对样本数据进行聚类,得到学生聚类后的类别数和每个学生的标签值,最后将聚类结果可视化。
本章掌握的技能是:1、使用 DBSCAN 函数实现数据聚类。2、使用 matplotlib 库实现数据的可视化,绘制图形。
17 DBSCAN 聚类算法
17.1 本章工作任务
采用 DBSCAN 聚类算法编写程序,依据100名学生的数学成绩、英语成绩对学生进行聚类。1、算法的输入是:100位学生的数学成绩、英语成绩。2、DBSCAN 求解前需要配置的模型参数是:半径和最小样本数。3、算法的结果是:学生聚类后的标签值、不同标签值的个数。
17.2 本章技能目标
掌握 DBSCAN 聚类算法原理。
掌握 DBSCAN 算法启动前的配置方法。
使用 DBSCAN 算法实现聚类。
掌握 DBSCAN 聚类结果可视化的方法。
17.3 本章简介
DBSCAN 算法是指:一种基于数据空间密度的聚类算法,该算法将样本空间内具有足够密度的样本点聚成一类,聚类前不需要指定聚类数量,算法会基于数据密度分布特点推断出聚类数量。例如,如果样本点A属于类别C1,且在样本点A周围半径为epsilon的空间中,其他样本点的数量M大于算法运行前配置的最小样本点数量minPoints,则认为M个样本点与样本点A都属于类别C1。
DBSCAN 算法可以解决的实际应用问题是:已知体育课上自由活动 的学生坐标,用 DBSCAN 算法对这些学生进行聚类,聚类后的同一类学生呈现出共同特征。已知一个班上所有学生的数学成绩、英语成绩,用 DBSCAN 算法对学生成绩聚类,得到理科生、文科生、综合生3种学生类别。
本章的重点是:DBSCAN 算法的理解和使用。
17.4 编程实战
步骤1 引入外部包。引入numpy包、matplotlib.pyplot包,pandas包,将它们分别命名为np,plt,pd。引入os模块,引入sklearn系列包,其中sklearn.cluster是密度聚类包,sklearn.preprocessing是预处理数据包。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import os
from sklearn.cluster import DBSCAN
from sklearn import metrics
from sklearn.preprocessing import StandardScaler步骤2 将当前文件所在目录的路径设置为Python的当前工作目录。
thisFilePath = os.path.abspath('.')
os.chdir(thisFilePath)
os.getcwd()输出结果:
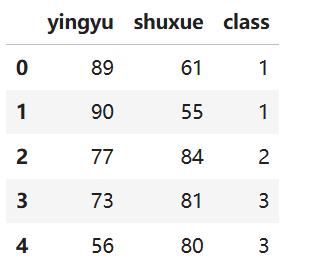
'D:\\MyPythonFiles’步骤3 pd.read_csv 函数用于读取存储学生成绩的文件,usecols 参数用于选取文件中指定的数据列,type 函数用于返回文件的类型,head 函数用于查看数据前5行。
clusterData = pd.read_csv('mydata.csv', usecols = ['yingyu', 'shuxue', 'class'])
type(clusterData)
clusterData.head(5)输出结果:
步骤4 提取训练集。提取前2列数据并转换为矩阵(数据结构为mat),提取前3列(列号为2)数据并转换为数组(数据结构为ndarray)。其中,iloc 函数有两个参数,分别是行号和列号。
DB_matrix = np.mat(clusterData.iloc[:, 0:2])
DB_labels_true = np.array(clusterData.iloc[:, 2])
步骤5 建立 DBSCAN 模型进行聚类,给每个样本产生聚类标签。
DB_model = DBSCAN(eps = 6, min_samples = 10).fit(DB_matrix)
DB_labels = DB_model.labels_core_samples_mask = np.zeros_like(DB_labels, dtype=bool)
core_samples_mask[DB_model.core_sample_indices_] = TrueDB_n_clusters_ = len(set(DB_labels)) - (1 if -1 in DB_labels else 0)步骤6 显示聚类后不同类别的总数量。
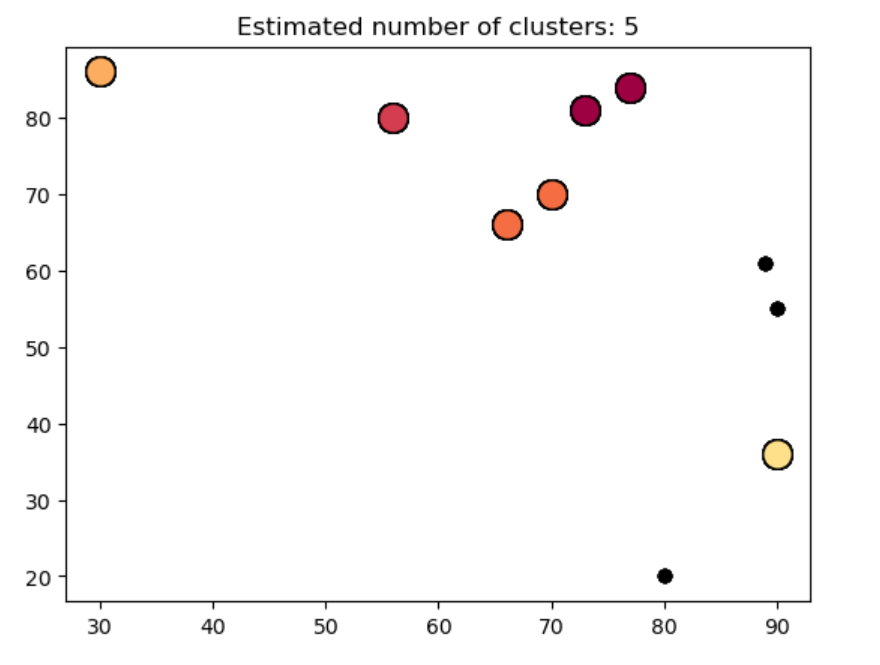
print("一共分为:%d" % DB_n_clusters_, "类")输出结果:一共分为:5类步骤7 将聚类结果可视化。
import matplotlib.pyplot as pltunique_DB_labels = set(DB_labels)
colors = [plt.cm.Spectral(each) for each in np.linspace(0,0.5,len(unique_DB_labels))]for k, col in zip(unique_DB_labels, colors):if k == -1:col = [0, 0, 0, 1]class_member_mask = (DB_labels == k)xy = DB_matrix[class_member_mask & core_samples_mask]plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor = tuple(col),markeredgecolor = 'k', markersize = 14)xy = DB_matrix[class_member_mask & ~core_samples_mask]plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor = tuple(col),markeredgecolor = 'k', markersize = 6)
plt.title('Estimated number of clusters: %d' % DB_n_clusters_)
plt.show()输出结果:
步骤8 对比样本的原始分类标签值与聚类算法预测的标签值。
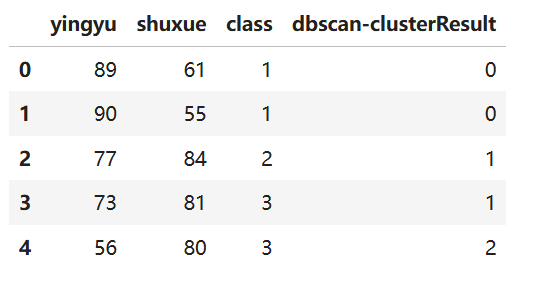
dbscan_labels = pd.DataFrame(DB_labels, index=clusterData.index, columns = ['dbscan-clusterResult'])
clusterData_merge = pd.merge(clusterData, dbscan_labels + 1, right_index = True, left_index = True)clusterData_merge.head(5) 输出结果:
17.5 本章总结
本章实现的工作是:首先导入100位学生的数学成绩、英语成绩,然后建立 DBSCAN 模型,配置模型参数,对样本数据进行聚类,得到学生聚类后的类别数和每个学生的标签值,最后将聚类结果可视化。
本章掌握的技能是:1、使用 DBSCAN 函数实现数据聚类。2、使用 matplotlib 库实现数据的可视化,绘制图形。
17.6 本章作业
实现本章的案例,即导入样本数据,实现 DBSCAN 模型的建模和数据可视化。