Redis一站式指南一:从MySQL事务到Redis持久化及事务实现
一、MySQL 事务四个核心特性
- 原子性:事务中的操作要么全部成功,要么全部失败,不存在部分完成的情况。
- 一致性:事务执行前后,数据库的完整性约束没有被破坏。
- 持久性:事务一旦提交,其结果就是永久性的,不会因为系统故障等原因而丢失。这里的持久性和数据持久化存储的概念相关,数据存储在硬盘上通常被认为是持久的,存储在内存中则相对不持久,因为重启进程或主机后数据可能丢失。
- 隔离性:多个事务并发执行时,一个事务的执行不能被其他事务干扰。
举一个栗子~
1. 原子性(Atomicity)
例子:银行转账
操作:A向B转账100元,需执行两步:
A账户减100元
B账户加100元
原子性体现:若第二步失败(如B账户异常),第一步也会被回滚,A账户不会扣款。事务要么全部成功(A减B加),要么全部失败(余额不变)。
2. 一致性(Consistency)
例子:账户余额约束
约束:银行账户余额不能为负数。
一致性体现:若A账户仅有50元却要转出100元,事务会因违反约束而失败,数据库状态保持不变(A仍为50元),确保数据逻辑一致。
3. 持久性(Durability)
例子:转账成功后的系统崩溃
操作:转账事务已提交(A减100,B加100)。
持久性体现:即使提交后系统立即崩溃,重启后数据仍保持转账后的状态(A和B的余额已更新),不会回滚到旧值。
4. 隔离性(Isolation)
例子:并发转账的脏读问题
场景:
事务1:A向B转100元(A减100,未提交)
事务2:读取A的余额(若允许脏读,事务2会看到A的临时中间状态,如已减100但未提交)
隔离性体现:通过隔离级别(如READ COMMITTED),事务2只能读到已提交的数据(A的原始余额),避免中间状态干扰。
二.*Redis实现持久性
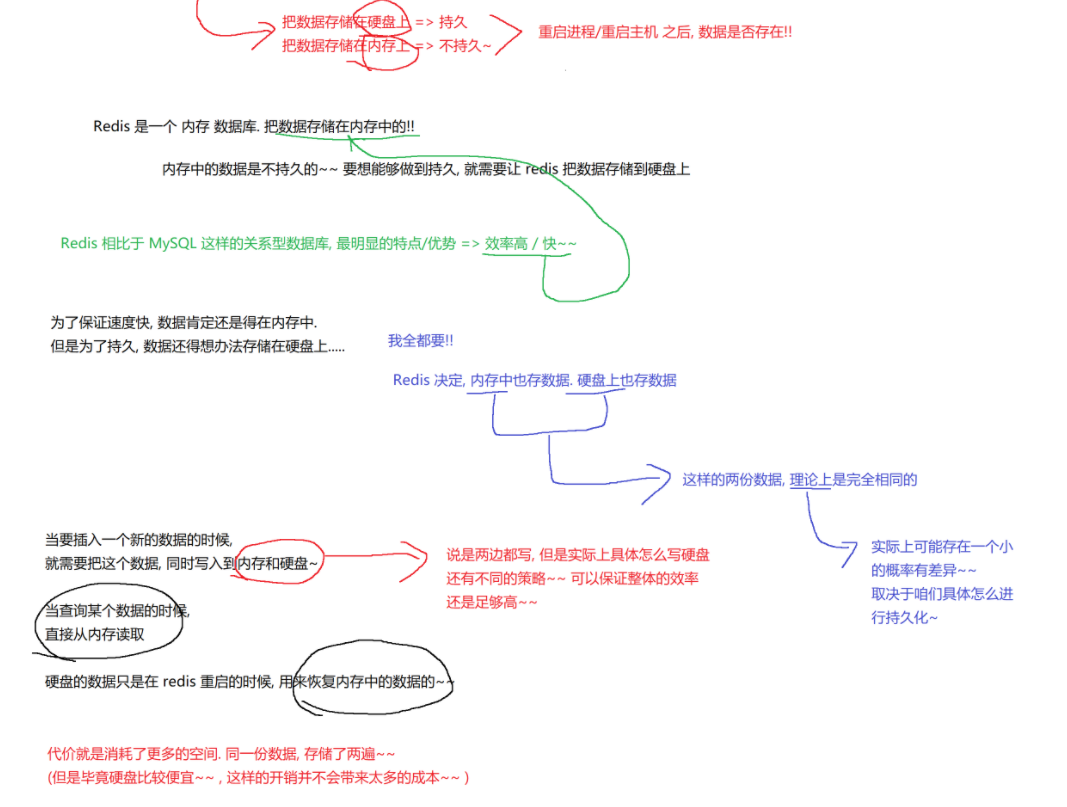
2.1Redis作为内存数据库的特点
Redis 相比 MySQL 等关系型数据库,最明显的优势是效率高、速度快。
优点:主要数据存储在内存中 => 访问效率高/速度快
缺点:内存数据不持久 => 进程/主机重启后数据会丢失
Redis 是内存数据库,数据存储在内存中,内存数据不持久,所以需要将数据存储到硬盘以实现持久化。
为了兼顾速度和持久化,Redis 采用内存和硬盘都存储数据的策略。插入新数据时同时写入内存和硬盘,查询数据时直接从内存读取,硬盘数据主要用于 Redis 重启时恢复内存数据。这种方式虽然消耗更多空间,但硬盘成本较低,整体开销可接受。
2.2Redis两种持久化策略
1.RDB(Redis DataBase)
概念:RDB 是 Redis 的一种持久化方式,定期将 Redis 内存中的所有数据写入硬盘,生成一个 “快照” 文件。Redis 重启时可根据该快照恢复内存数据。
举个栗子~
就像警察勘察犯罪现场时会拍照记录,然后根据拍照的记录来还原案发现场,(RDB快照文件)就像警察勘察犯罪现场时的拍照记录,里边存放的是二进制数据,如果redis服务器重启了,内存上的数据自然是没有了,但是可以根据RDB快照文件”还原“数据,就又可以读取上一次保存的数据了
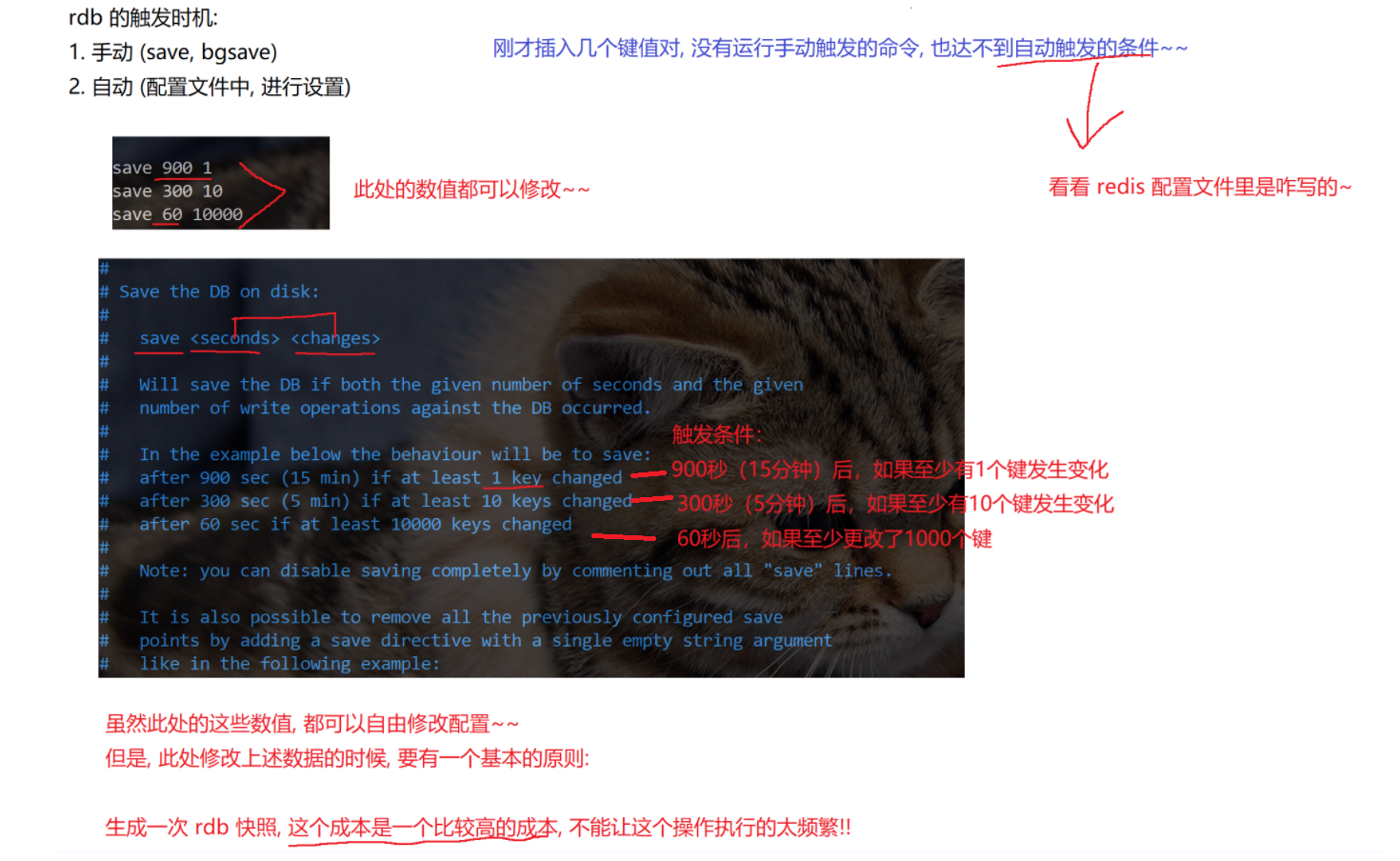
触发方式:
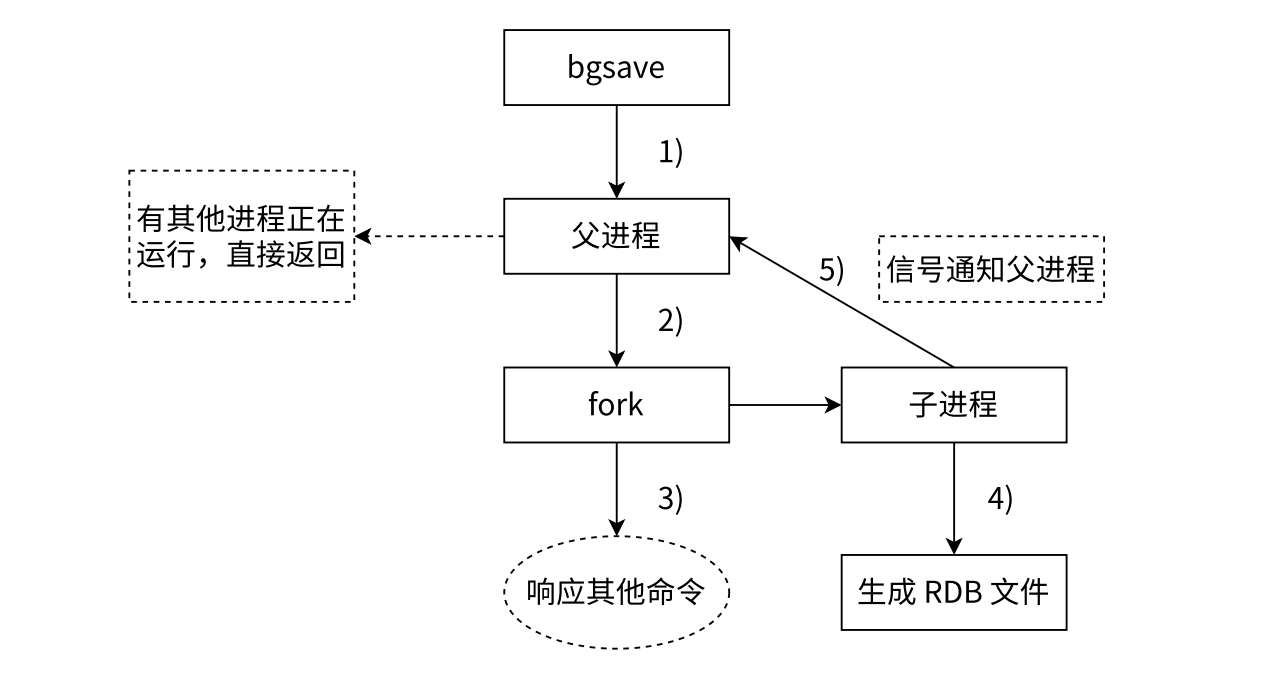
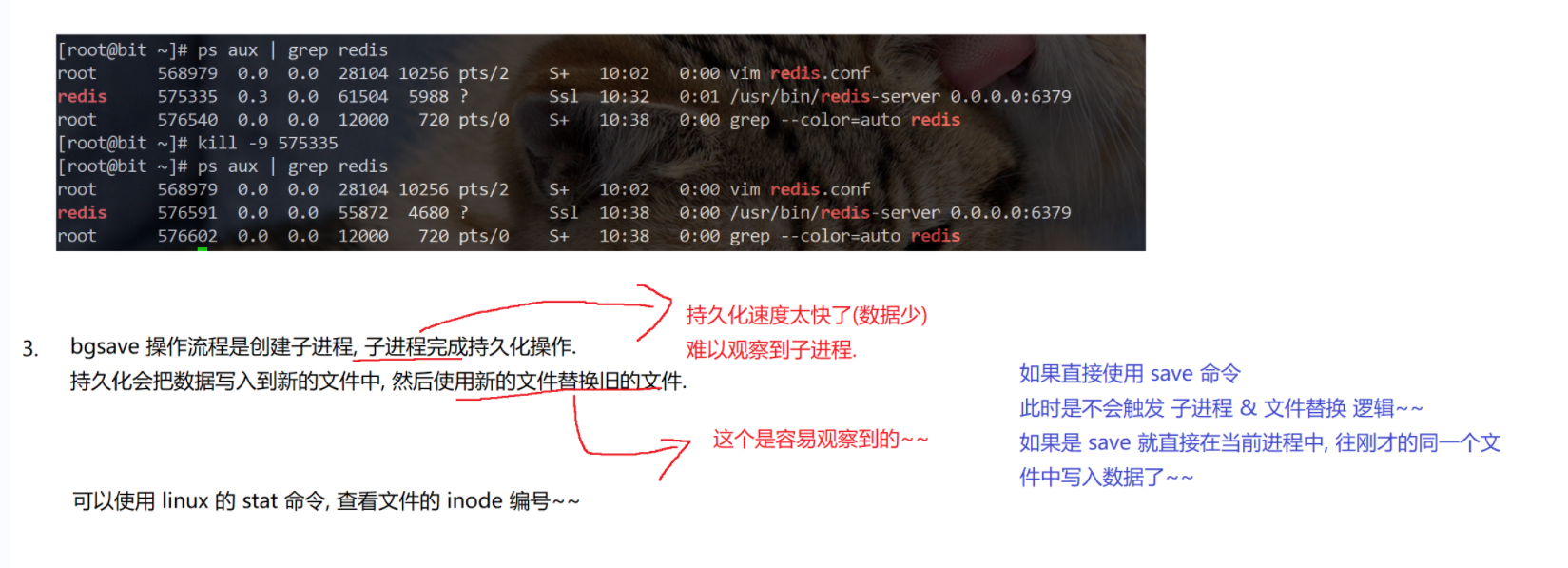
- 手动触发:执行bgsave命令,Redis 创建子进程进行快照生成,不影响其他客户端请求。数据量小时生成速度快,数据量大时可能需要一定时间。若不手动执行bgsave,正常关闭 Redis(如shutdown命令)时会自动生成 RDB 快照,异常关闭(如kill -9或服务器掉电)则可能导致内存中未保存到快照的数据丢失。
- 自动触发:在 Redis 配置文件中设置触发条件,如每隔一段时间或数据发生一定次数修改时触发。文件特点:RDB 文件是二进制压缩文件,存放在 Redis 工作目录(可在配置文件设置),默认文件名为dump.rdb。生成新快照时会先写入临时文件,完成后替换旧的 RDB 文件,始终只有一个 RDB 文件。
注意事项:生成 RDB 快照成本较高,不能太频繁,否则可能影响性能。这会导致快照数据与实时数据存在偏差。如果 RDB 文件损坏,Redis 可能无法启动或加载数据出错,Redis 提供了redis-check-rdb工具用于检查 RDB 文件格式。

2.AOF(Append Only File)
概念:AOF 是另一种持久化方式,与 RDB 的对比,AOF 可以实现实时备份,数据完整性更高,但文件体积通常比 RDB 大。以日志形式记录每个写操作,Redis 重启时通过重放这些操作来恢复数据。
举一个栗子~
类似vscode编译器上敲代码,对代码有修改就马上保存,而不需要有些编译器需要“ctrl+s”进行保存
以电脑硬盘存储 “学习资料” 为例,硬盘是较易损坏的部件,为防止资料丢失,可使用移动硬盘定期或实时备份,类比 RDB 的定期备份和 AOF 的实时备份。
2.2.1RDB
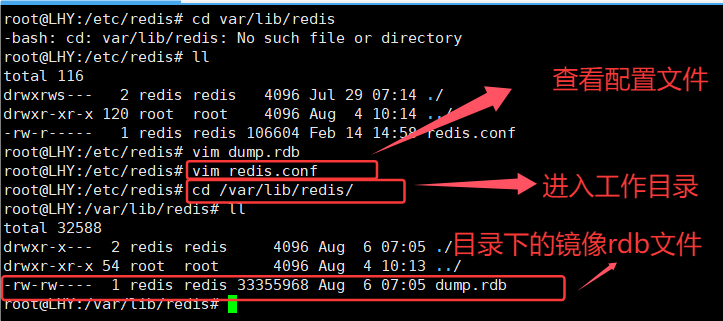
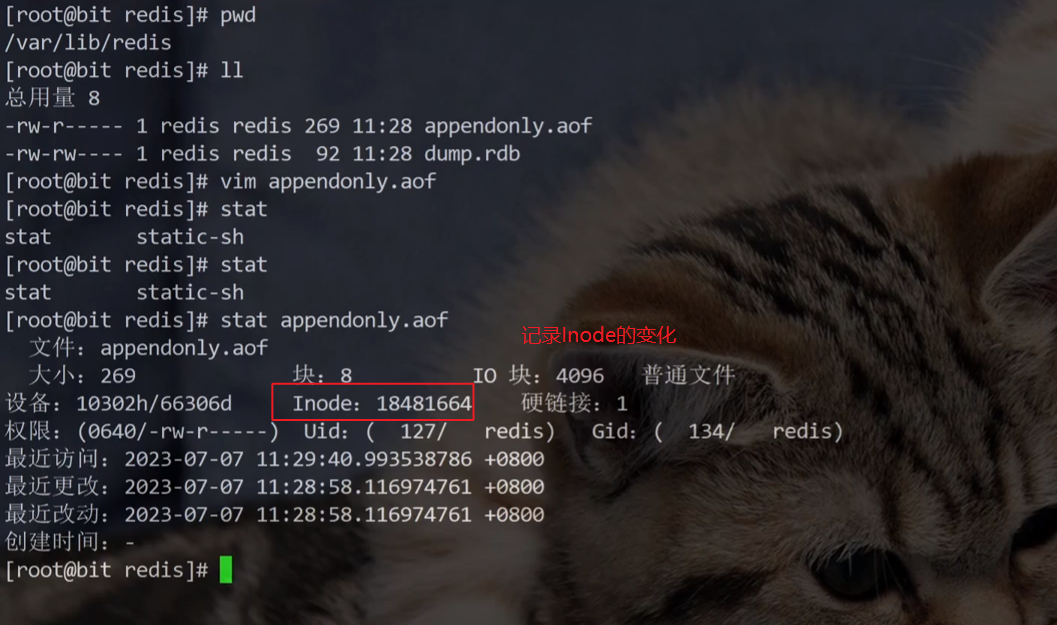
Redis生成的RDB文件默认存放在配置文件中指定的工作目录下,比如/var/lib/redis目录中。这个dump.rdb文件是RDB机制生成的二进制镜像文件,采用压缩格式存储内存数据,虽然节省了存储空间但会消耗一定CPU资源。
Redis服务器默认开启RDB持久化功能,这个二进制文件可以用vim查看但绝对不能随意修改,因为一旦破坏文件格式就会导致Redis重启时加载数据失败。Redis提供了专门的rdb文件检查工具redis-check-rdb。虽然我们不会主动修改rdb文件,但仍可能因网络传输等操作意外损坏文件,导致Redis服务器无法启动。
所以每次执行RDB持久化时,Redis会先将快照数据写入临时文件,生成完毕后再删除旧rdb文件并将临时文件重命名为dump.rdb,确保始终只有一个rdb文件存在。

bgsave命令:
可在.conf配置文件中查看的rdb镜像文件的位置,然后再vim打开看看(二进制数据)
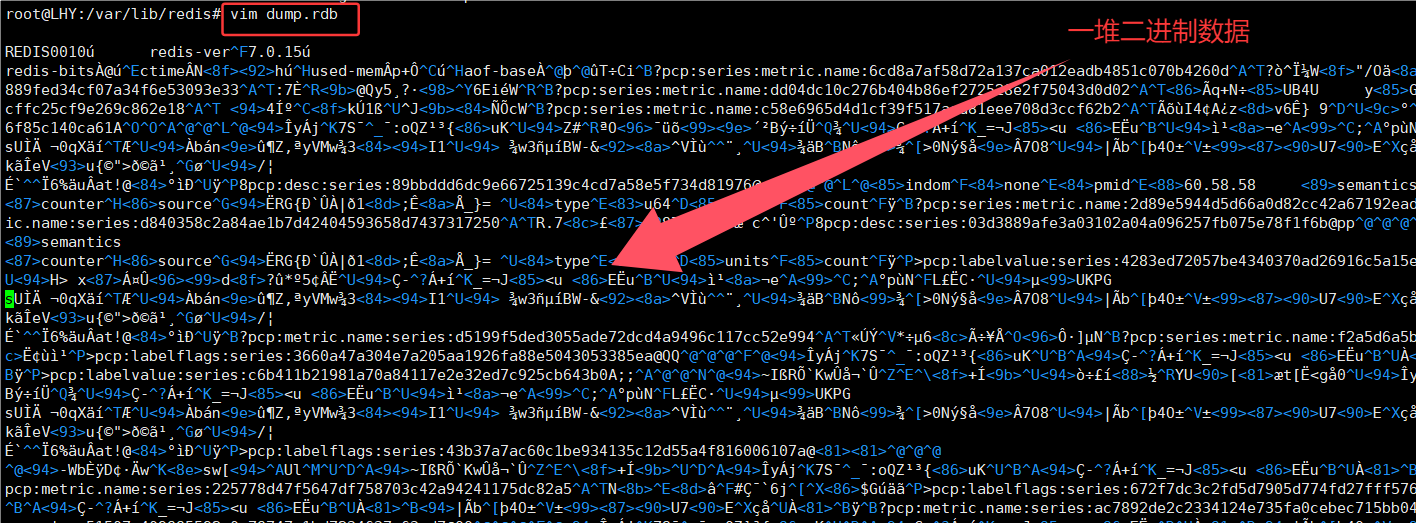
为了演示,我flushall了
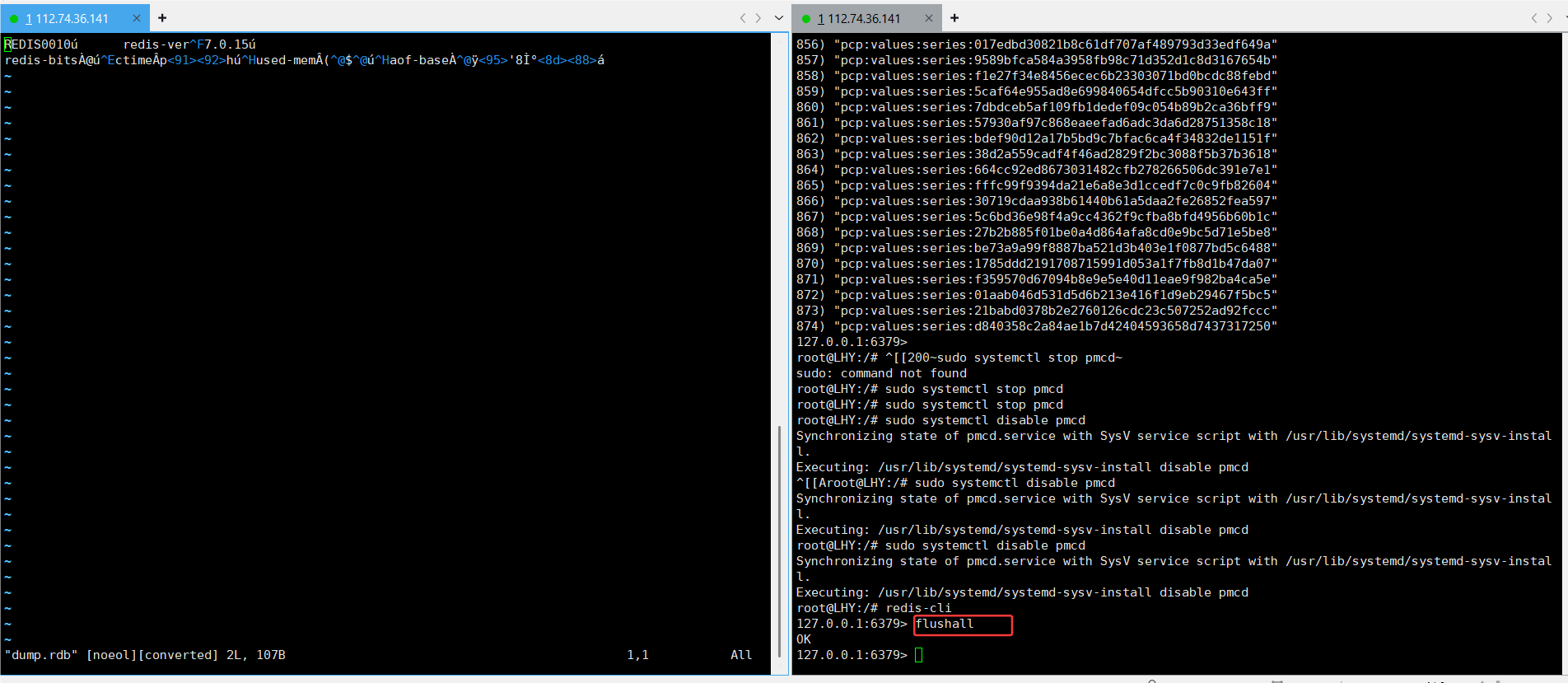
插入了几条数据,但是文件感觉没啥变化
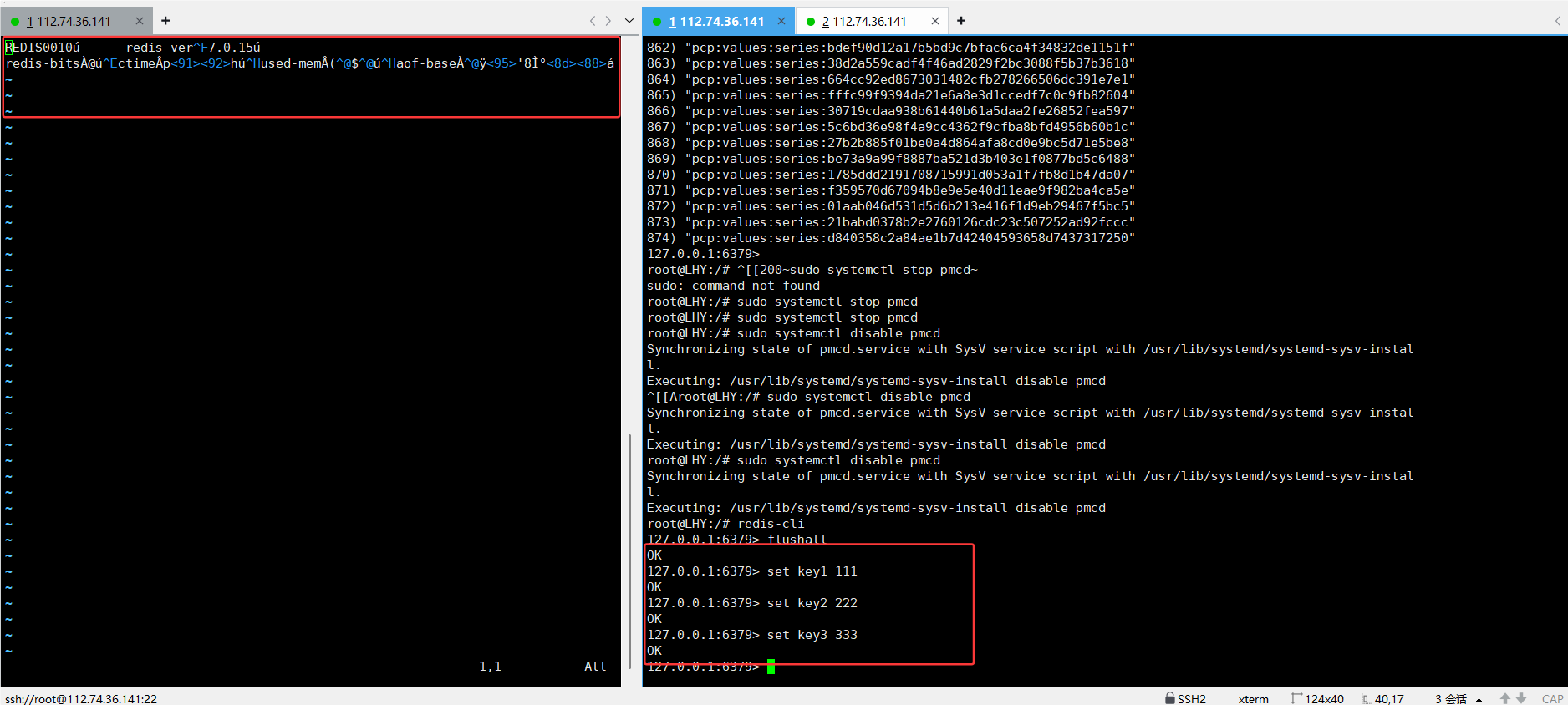
这就对了,因为触发保存需要手动触发和自动触发
手动触发:save命令和bgsave(一般都用bgsave,save命令可能引起阻塞,冷门)
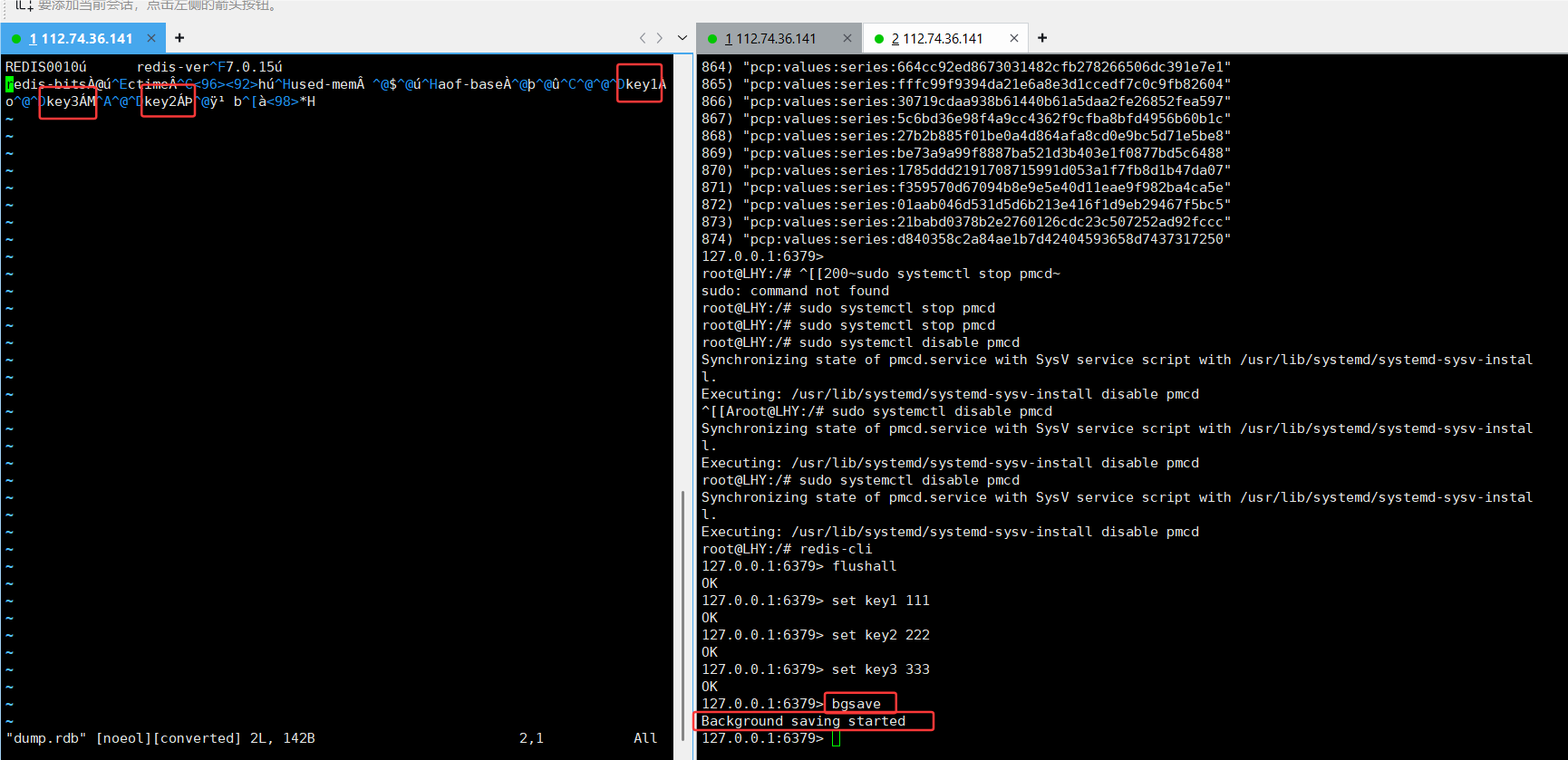
关闭服务器后,在重新启动服务器,内存上的数据会丢失,但可以在rdb文件获取持久化的数据
自动触发:配置文件




2.2.2AOF
RDB 最大的问题,不能实时的持久化保存数据。在两次生成快照之间,实时的数据可能会随着重启而丢失
2.2.2.1AOF(append only file)概念
类似于 mysql 的 binlog,会把用户的每个操作,都记录到文件中,当 redis 重新启动的时候,就会读取这个 aof 文件中的内容,用来恢复数据。
aof 默认一般是关闭状态,修改配置文件,来开启 aof 功能。

当开启 aof 的时候,rdb 就不生效了,启动的时候不再读取 rdb 文件内容了。

2.2.2.2AOF机制是否有影响redis处理请求速度?
Q:
Redis 虽然是一个单线程的服务器,但是速度很快,Q之所以速度快,很重要的原因只是操作内存,但是引入 AOF 之后,又要写内存,又要写硬盘。还能和之前一样快了嘛??
A:
实际上,是没有影响的!!!并没有影响到 redis 处理请求的速度
AOF 机制并非是直接让工作线程把数据写入硬盘,而是先写入一个内存中的缓冲区,积累一波之后,再统一写入硬盘
硬盘上读写数据,顺序读写的速度是比较快的 (还是比内存要慢很多)
随机访问则速度是比较慢的
AOF 是每次把新的操作写入到原有文件的末尾。属顺序写入假设 100 个请求,100 个请求的数据,一次写入硬盘,比分 100 次,每次写入一个请求
要快很多!!!写硬盘的时候,写入硬盘数据的多少,对于性能影响没有很大,但是写入硬盘的次数则影响很大了
2.2.2.3AOF的刷新策略
Q:
如果把数据写入到缓冲区里,本质还是在内存中呀
万一这个时候,突然进程挂了,或者主机掉电了,咋办??是不是缓冲区中的数据就丢了A:
是的!!!缓冲区中没来得及写入硬盘的数据是会丢的
刷新策略概念:
AOF 机制先把操作命令写入内存中的缓冲区,而不是直接写入硬盘。如果不进行刷新,这些数据就一直停留在内存缓冲区。一旦进程挂掉、主机掉电 等意外情况发生,缓冲区中未写入硬盘的数据就会丢失。通过刷新,能将缓冲区里的数据写入硬盘保存,确保 Redis 重启时,可以依据 AOF 文件恢复数据,实现数据持久化
所以redis 给出了一些选项,让程序猿,根据实际情况来决定怎么取舍(制定缓冲区的刷新策略)
就
- 刷新频率越高,性能影响就越大,同时数据的可靠性就越高.
- 刷新频率越低,性能影响就越小,数据的可靠性就越低
| 可配置值 | 说明 |
|---|---|
| always | 命令写入 aof_buf 后调用 fsync 同步,完成后返回 |
| everysec | 命令写入 aof_buf 后只执行 write 操作,不进行 fsync,每秒由同步线程进行 fsync. |
| second | 命令写入 aof_buf 后只执行 write 操作,由 OS 控制 fsync 频率. |
| no | 命令写入 aof_buf 后只执行 write 操作,由 OS 控制 fsync 频率. |
频率最高的,数据可靠性最高,性能最低.
频率低一些,数据可靠性也会降低,性能会提高
频率最低,数据可靠性也是最低的,性能是最高的
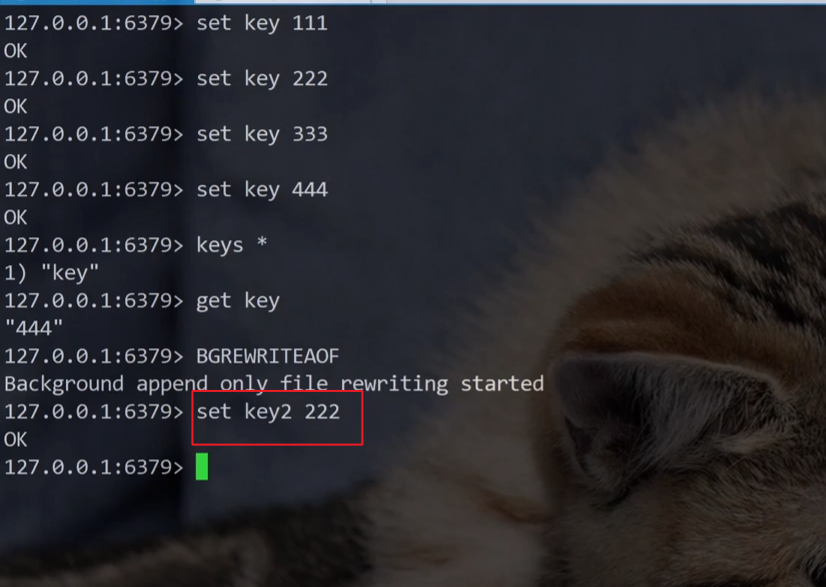
2.2.2.AOF重写机制
AOF 文件持续增长,体积越来越大,会影响到,redis 下次启动的启动时间。
因为redis 启动的时候要读取 aof 文件的内容,记录了中间的过程,但是实际上 redis 在重新启动的时候只是关注最终结果。
注意!!!上述 aof 中的文件,有一些内容是冗余的!!
举个栗子~
有一个客户端,对 redis 进行操作~~
比如,进行下列操作:
lpush key 111
lpush key 222
lpush key 333
合并为:lpush key 111 222 333再比如,进行下列操作
set key 111
set key 222
set key 333
合并为:set key 333set key 111
del key
set key 222
del key
合并为:啥都不做就可以了。
因此 redis 就存在一个机制,能够针对 aof 文件进行整理操作,这个整理就是能够剔除其中的冗余操作,并且合并一些操作,达到给 aof 文件 瘦身 这样的效果。
下面拆分可能有些复杂,但是无非就几步,先考虑清楚
1. 为啥要 “重写 AOF 文件”?
之前说过,AOF 会把操作命令一个个记下来,时间久了文件会越来越大(比如存了很多冗余操作)。重启 Redis 时要读这么大的文件,会很慢。所以 Redis 搞了个 “重写” 机制,帮 AOF 文件 “瘦身”—— 只保留能恢复最终数据的必要命令。
2. 重写的核心思路:用 “当前内存数据” 直接生成新 AOF
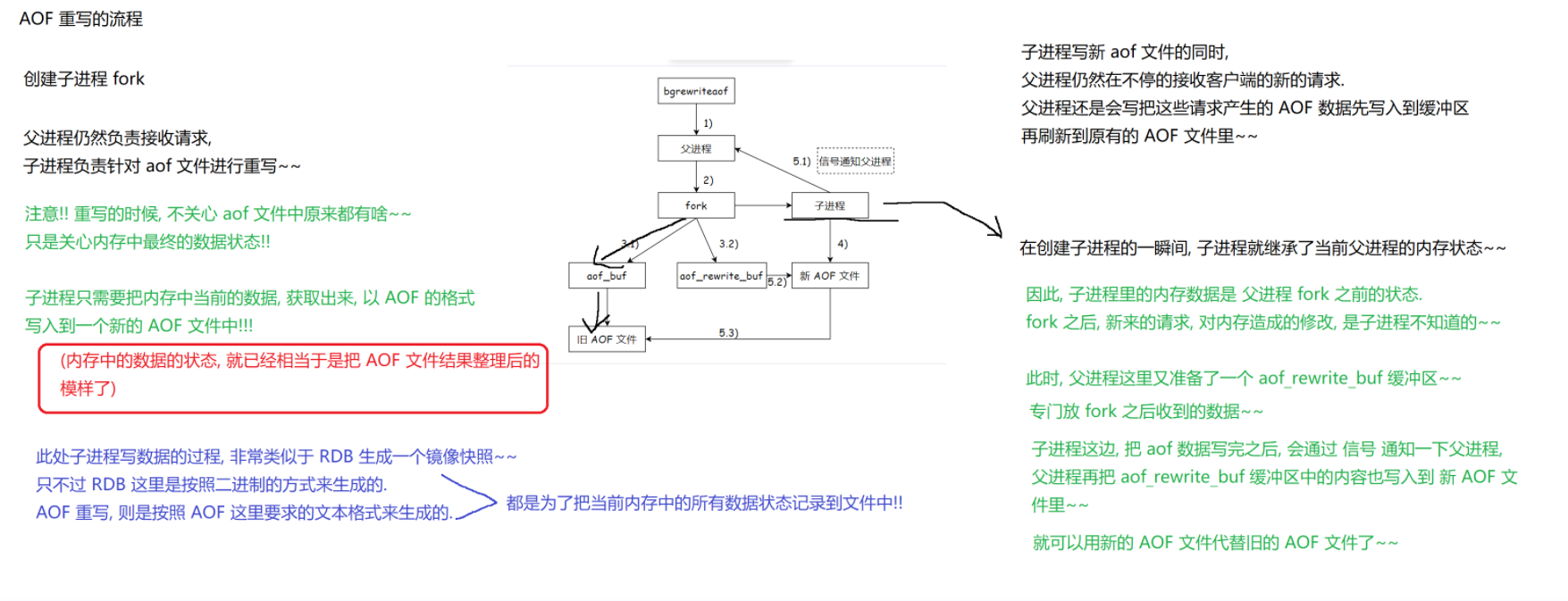
- Redis 启动重写时,会创建一个子进程(fork) 专门干这件事。
- 子进程不管旧 AOF 文件里写了啥,只看 “当前内存里的最终数据”(比如内存里 key 对应的值是啥,直接拿这个结果生成命令)。
- 子进程把这些数据,用 AOF 格式(文本形式的命令)写到新的 AOF 文件里。这一步很像 RDB 生成快照(只不过 RDB 是二进制,AOF 是文本命令),最终目的都是 “把内存数据存成文件”。
3. 重写时,父进程在干啥?
父进程不会闲着!它继续干本职工作:接收客户端新请求。
- 新请求产生的 AOF 数据,会先写到临时缓冲区(aof_rewrite_buf) 里,同时也会刷到旧的 AOF 文件里(保证旧文件不会丢数据)。
4. 子进程和父进程的 “时间差” 问题
- 子进程刚创建(fork)的瞬间,会复制父进程的内存状态(相当于 “定格” 了一份当时的内存数据)。
- 但 fork 之后,父进程可能又处理了新请求、改了内存数据。这些 “新变化”,子进程一开始是不知道的(因为它复制的是 fork 时的内存)。
5. 怎么把 “新请求的数据” 合并到新 AOF?
为了不丢数据,Redis 做了两步:
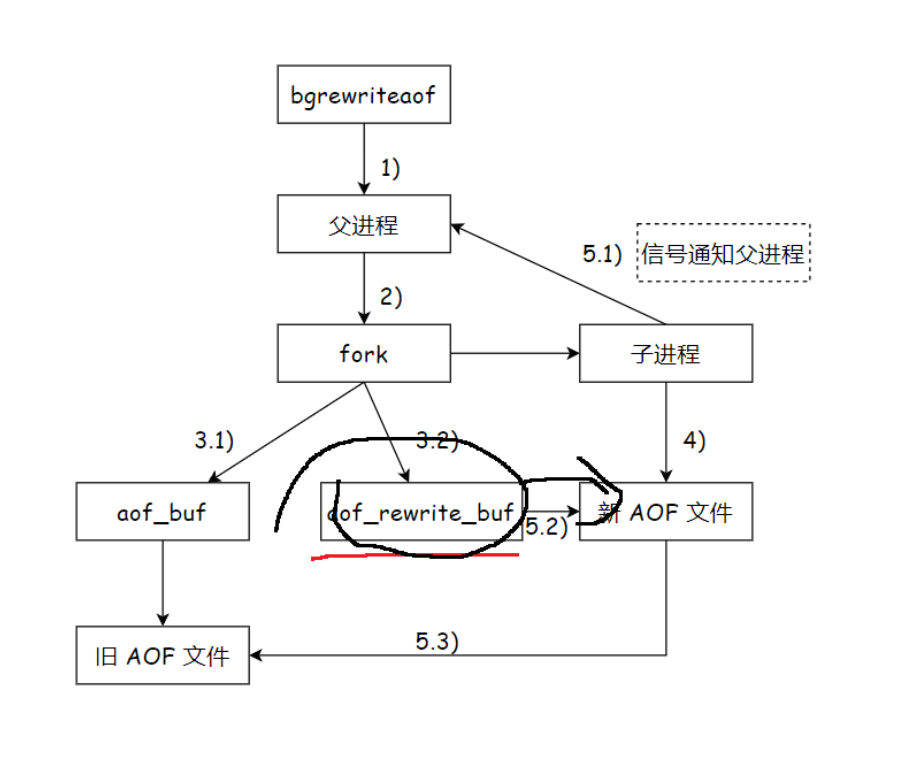
- 父进程把 fork 后的新请求,先存到 aof_rewrite_buf 缓冲区 里。
- 子进程写完 “初始内存数据” 的新 AOF 后,会发信号告诉父进程。父进程收到信号,就把 aof_rewrite_buf 里的 “新请求数据” 也写到新 AOF 文件里。
6. 最终替换:新文件换旧文件
等父进程把缓冲区数据也写完,新 AOF 文件就完整了(包含 fork 时的内存数据 + fork 后的新请求数据)。这时,Redis 用新 AOF 文件替换旧文件,重写完成!
总结步骤:
- 创建子进程:Redis 启动 AOF 重写时,创建子进程(fork),父进程继续接收客户端请求,子进程专门处理 AOF 文件重写。
- 子进程重写逻辑:子进程不关注旧 AOF 文件内容,仅依据 fork 瞬间父进程的内存最终数据状态,以 AOF 文本格式,将内存数据写入新 AOF 文件,过程类似 RDB 生成快照(RDB 为二进制,AOF 是文本命令 ),目标是记录当前内存数据。
- 父进程并行操作:父进程接收新请求,新请求产生的 AOF 数据,一方面写入临时缓冲区(aof_rewrite_buf ),另一方面刷入旧 AOF 文件,保证旧文件数据不丢失。
- 处理内存状态差:fork 瞬间子进程复制父进程内存状态,fork 后父进程新请求修改内存的数据,子进程初始不知,这些新数据暂存于 aof_rewrite_buf 。
- 合并新数据与替换文件:子进程写完新 AOF 文件后发信号给父进程,父进程将 aof_rewrite_buf 中数据写入新文件,之后用新 AOF 文件替换旧文件,完成重写,保障数据不丢、服务持续。
Q:如果执行 bgrewriteaof 时,Redis 已经在进行 AOF 重写了,会怎样?
A:不会重复执行,直接返回。避免同时重写造成资源混乱。
Q:如果执行 bgrewriteaof 时,Redis 正在生成 RDB 文件快照(比如执行 bgsave ),会怎样?
A:AOF 重写会等待,等 RDB 快照生成完毕后,再执行 AOF 重写。因为 RDB 和 AOF 重写都依赖 fork 子进程,要避免冲突。
Q:父进程 fork 子进程写新 AOF 后,子进程很快写完新文件,要替换旧文件。但父进程还在写旧 AOF —— 这有意义吗?
A:必须写!必须考虑极端情况:重写过程中服务器突然挂掉,子进程内存数据丢失,新 AOF 可能不完整。
*AOF 与 RDB 的设计理念差异:
RDB:理念是 “定期备份”, fork 后对新数据变化 “置之不理”(只存 fork 时的内存快照 )。优点是备份快、文件小;缺点是可能丢 “定期备份间隔内” 的数据。
AOF:理念是 “实时备份”(近似 ), fork 后用 aof_rewrite_buf 缓冲区记录新数据。优点是数据更全;缺点是文件可能更大、重写更耗资源。
2.2.2AOF混合持久机制
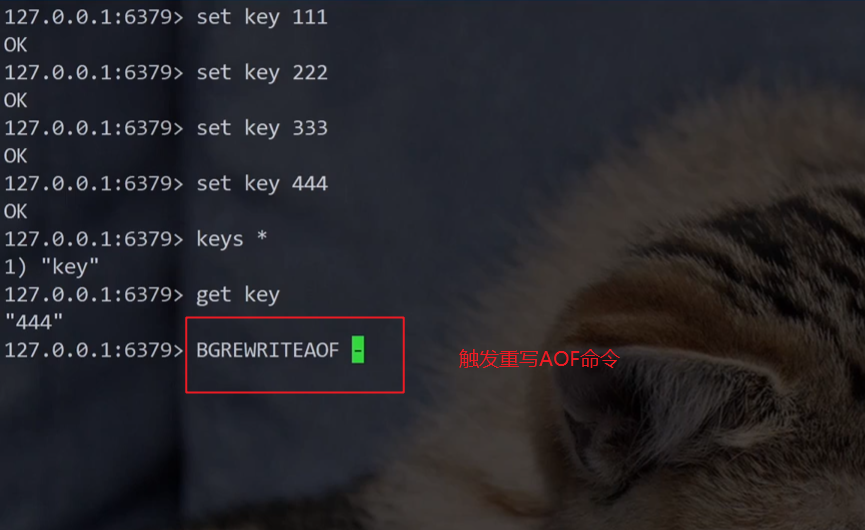

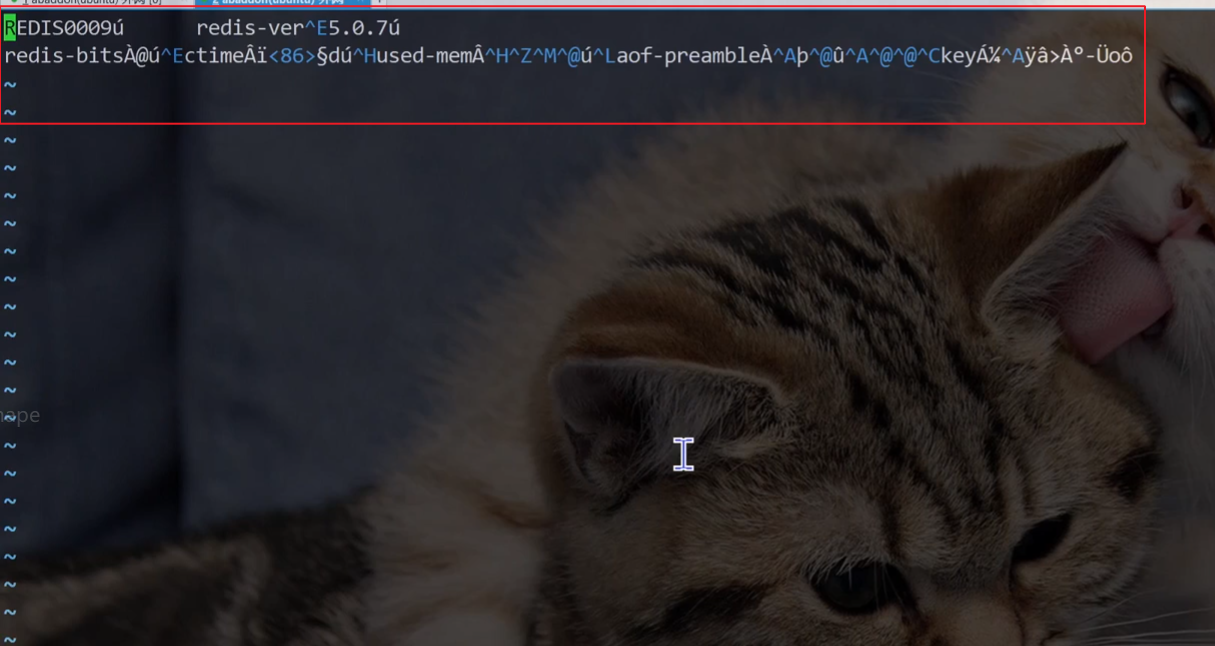
打开AOF文件查看内容:(发现怎么跟RDB文件一样写入的是二进制,而不是文本?)
- AOF 纯文本方式的问题
AOF 本来是按照文本的方式来写入文件的. 但是文本的方式写文件, 后续加载的成本是比较高的
- 解释:Redis 的 AOF(Append - Only File,只追加文件)持久化,最初设计是把每个写操作以文本命令的形式,一行行追加到 AOF 文件里 。比如执行
SET key value,就把这条命令文本存到文件 。但文本形式有缺点,Redis 重启加载 AOF 文件时,得逐行解析这些文本命令再执行,数据量大时,解析、执行这些命令就会很慢,加载成本(时间、性能方面)高 。
- 混合持久化的引入及配置
配置文件可以修改混合持久配置
redis 就引入了 "混合持久化" 的方式,结合了 rdb 和 aof 的特点。 aof-use-rdb-preamble yes 这个选项为 yes 表示开启混合持久化 (修改配置项之后要记得重新启动服务器)
- 解释:为解决纯 AOF 加载慢的问题,Redis 搞了 “混合持久化” 。它结合了 RDB(Redis 数据快照,把内存数据按二进制格式快照保存 ,加载快 )和 AOF 的优点 。
- 配置项
aof-use-rdb-preamble,设为yes就是开启混合持久化 ;设为no就是关闭 。而且改了这个配置后,必须重启 Redis 服务器,配置才能生效 。
- 混合持久化的工作流程
按照 aof 的方式, 每一个请求/操作, 都记录入文件. 在触发 aof 重写之后, 就会把当前内存的状态按照 rdb 的二进制格式写入到新的 aof 文件中. 后续再进行的操作, 仍然是按照 aof 文本的方式追加到文件后面~~
- 解释:
- 正常情况下,混合持久化开启后,Redis 还是先按纯 AOF 那套,每个写操作(像
SETDEL等 ),都以文本命令形式追加到 AOF 文件,保证数据实时性 。- 当触发 AOF 重写(比如达到配置的文件大小增长率、达到指定文件大小等条件 ),Redis 会先把当前内存里的所有数据,用 RDB 的二进制快照方式,写入到新的 AOF 文件开头 。这一步好处是,RDB 二进制格式加载快,相当于用 RDB 快速 “定格” 一份当前完整数据快照 。
- 接着,后续新产生的写操作,又回到 AOF 文本追加的老样子,继续往文件后面加文本命令 。这样结合后,加载 AOF 文件时,先快速加载开头的 RDB 二进制部分恢复大部分数据,再接着解析后面的 AOF 文本命令,既保证了数据完整性(像 AOF 那样记录每一步操作 ),又提升了加载速度(借助 RDB 二进制的高效 ) 。
添加新的数据:
后续操作使用文本格式进行进行追加保存了

三.*Redis实现事务
3.1Redis 事务核心作用
Redis 事务核心作用——“打包” 防插队
Redis 事务最主要意义是 **“打包” 命令 **,把多个操作塞一块执行,避免其他客户端命令 “插队” 插中间。
举个栗子~:
你和女朋友约好去吃烧烤,你先到烧烤店点了羊肉串、五花肉(相当于 “开启事务,把这些点单操作放进队列” ),还跟服务员说 “先别烤,等人齐了再烤” ;女朋友到了又加烤韭菜、腰子(继续往事务队列里加操作 );最后你喊 “开始烤吧”(执行事务 ),这时候服务员就会把你们点的所有串一起烤,中间不会被其他桌点单插队 。
对应 Redis 里的逻辑:
每个客户端都有自己的事务队列(前提是开启了事务),开启事务(MULTI )后,发的命令先存队列里(不立即执行 );等执行事务(EXEC )命令,队列里的操作才会按顺序在 Redis 主线程里依次执行,执行完再处理其他客户端请求 。
3.2Redis 事务 vs MySQL 事务
Redis 事务 vs MySQL 事务 —— 为啥 “简单”?
MySQL 事务很强大(有原子性、一致性、持久性、隔离性 ),但代价高:要存更多数据占空间,执行起来也更耗时 。Redis 为了高效、轻量化,没搞这么复杂,主要靠 “打包执行” 解决问题,所以功能上和 MySQL 事务有差距 。
不过 Redis 也能一定程度应对 “超卖” 这类场景(比如秒杀、库存扣减 ):
- 场景举例:放 5000 台货,要是 5001 个人下单成功就是超卖 。
- 普通写法(不加控制会有问题 ):先查库存,库存>0 就下单、扣库存。但多线程 / 多客户端同时操作时,可能都查到库存够,最后超卖 。
- Redis 事务解决思路:把 “查库存 + 下单 + 扣库存” 打包成事务,保证这些操作连续执行,中间不被插队,避免超卖 。(以前多线程里靠加锁,Redis 里用事务就可以 )
3.3Redis 事务的操作命令
核心命令:

举个栗子~:
- MULTI:开启事务,之后发的命令进队列 。
- EXEC:执行事务,把队列里的命令按顺序执行 。
- DISCARD:放弃事务,清空队列里的命令,不执行 。
- WATCH:监控键,事务执行前,要是监控的键被其他客户端修改了,事务里的命令就不会执行(类似 “乐观锁” ,预防数据冲突 )。
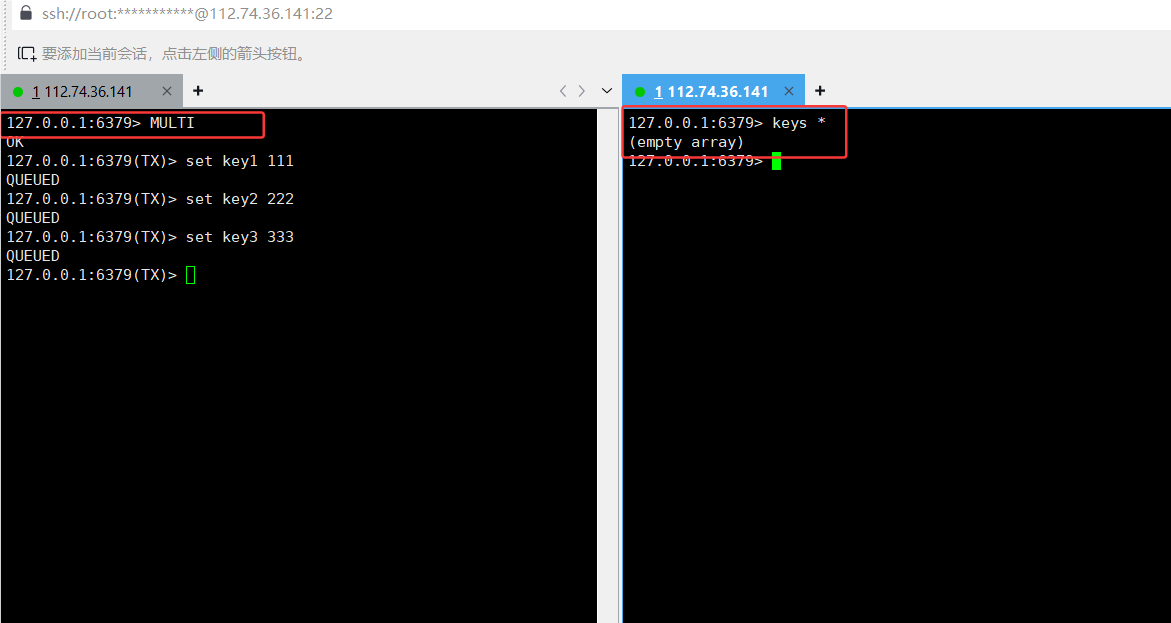
MULTI:开启事务,并输入数据,但是queue,并没有执行命令,使用keys 找不到key
exec:执行命令
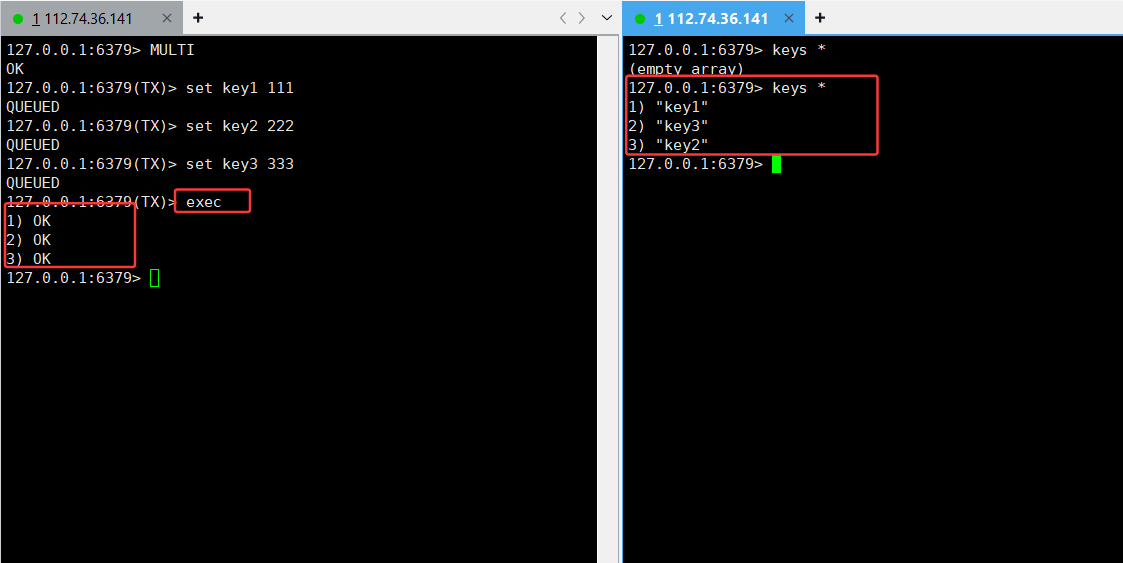
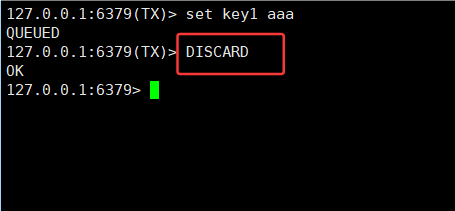
DISCARD:丢弃事务原有的操作
watch命令:


- 实际操作示例(看命令交互更清楚 ):
- 开启事务后发命令:SET key1 111 SET key2 222 … 这些命令会显示 QUEUED ,存在服务器事务队列里 。这时候其他客户端查这些 key,拿不到结果(还没执行 )。执行 EXEC ,队列里的命令才真正执行,返回结果 。要是事务执行前服务器重启,效果和 DISCARD 一样,事务被放弃 。
WATCH 的作用:
比如客户端 1 WATCH key 后开启事务、改 key 值;客户端 2 也改这个 key 。客户端 1 执行 EXEC 时,Redis 发现 key 被改过,事务里的修改就不执行(返回空 ),避免数据冲突
3.1Redis 事务的 “不足” & 场景
Redis 事务的 “不足” & 适用场景
不足:
- 没有 MySQL 事务那样严格的原子性、一致性保障 。要是事务里某个命令执行失败(比如语法错 ),其他命令可能继续执行;也没有回滚机制,执行中出错不会自动回滚 。
- 集群模式下不支持事务 。
- 应用场景比 MySQL 事务少,更像 “辅助打包执行” 的工具 。
适用场景:
主要解决 “命令打包执行,避免插队” 的问题,像秒杀库存扣减、简单的操作序列连续执行等场景 。要是需要复杂的事务逻辑(强原子性、回滚 ),还是得靠 MySQL 这类数据库 。
3.3额外补充
(Lua 脚本和事务的关系 )
Redis 原生命令里没有复杂条件判断(比如 IF count > 0 这种 ),但可以用 Lua 脚本 实现类似逻辑,而且 Lua 脚本也能打包批量执行,算是事务的 “进阶版” 。不过日常简单场景,用 Redis 事务的 MULTI/EXEC 就够啦~
简单说,Redis 事务就是个 “命令打包器” ,把一堆操作捆一起连续执行,解决插队问题;和 MySQL 事务功能、复杂度不同,各有各的应用场景,理解清楚这些,用的时候就知道啥场景选 Redis 事务,啥场景得靠 MySQL 啦~
3.4Redis 事务的特点
Redis 事务的特点(对比 MySQL 事务)
Redis 的事务比 MySQL 的事务简单很多,主要体现在这几个特性上:
- 原子性:MySQL 事务强调 “要么全成功,要么全回滚”,但 Redis 事务不支持回滚。即使事务里某条命令执行失败,其他命令也可能继续执行(除非语法错误等严重问题 )。
- 一致性:Redis 不保证 “事务执行前和执行后,数据绝对一致” 。比如执行过程中遇到错误,不会像 MySQL 那样严格回滚到初始状态,可能出现部分执行后的中间状态。
- 持久性:Redis 主要靠内存存数据,虽然有 RDB、AOF 持久化,但和 MySQL 基于磁盘事务日志的持久化逻辑不同,持久性保障相对弱一些(依赖持久化策略 )。
- 隔离性:Redis 是单线程处理请求,所有命令本质上 “串行执行” 。不像 MySQL 有多线程并发,需要复杂的隔离级别(读未提交、读已提交等 ),Redis 天然通过单线程保证 “命令执行的顺序性”,隔离性简单很多。
Redis 里操作事务的基础命令:
- multi:开启事务,之后输入的命令会进入事务队列(暂不执行 )。
- exec:执行事务,把队列里的命令按顺序执行。
- discard:放弃事务,清空事务队列里的命令,不执行。
- watch/unwatch:配合事务实现 “乐观锁” 功能(后面详细讲 )。
另外,Redis 里的 Lua 脚本也能实现类似事务的效果,官方甚至说 “事务能做的事,Lua 脚本都能替代” 。因为 Lua 脚本可以把多个命令打包,让 Redis 一次性执行,中间不被其他操作打断。
3.5Redis 的 “乐观锁”
Redis 的 “乐观锁”(watch 命令的作用)
Redis 用 watch 命令实现类似 “乐观锁” 的逻辑,核心是通过版本号判定,避免数据冲突。用生活例子理解:
1. 场景设定(模拟多客户端操作同一个 key)
假设 key 初始版本号是 1,客户端 1 和客户端 2 都要修改这个 key:
客户端 1:
- watch key:给 key “打标记”,记录当前版本号(比如 1 )。
- multi:开启事务,准备操作 key。
- set key 222:把操作放进事务队列(还没执行 )。
- exec:执行事务时,Redis 会检查 key 的版本号。
客户端 2:
- 如果在客户端 1 执行 exec 前,客户端 2 执行了 set key 333 → 这会让 key 的版本号变大(比如从 1 变 2 )。
2. “乐观锁” 的判定逻辑
当客户端 1 执行 exec 时,Redis 会做这些事:
- 对比 “当前 key 的版本号” 和 “watch 时记录的版本号”。
- 如果版本号一致(说明没人改 key ):执行事务队列里的命令(比如
set key 222),正常修改数据。 - 如果版本号不一致(说明有其他客户端改了 key,比如客户端 2 改过 ):放弃事务里的操作,
exec返回nil,客户端 1 的修改不生效。
- 如果版本号一致(说明没人改 key ):执行事务队列里的命令(比如
简单说,watch 就是给 exec 加了个 “条件判定”:只有数据没被其他客户端修改过,事务才执行;否则就放弃,避免覆盖别人的修改。
3. watch 命令的使用规则
- watch必须在
multi之前用,先标记要监控的 key,再开启事务。 - 只要对监控的 key 做了修改(不管哪个客户端 ),key 的版本号就会变大。事务执行时,Redis 会拿最新版本号和
watch时记录的对比,决定是否执行事务。
3.6总结
关于Redis 事务怎么用、有啥特点)
- 简单流程:
watch(可选,做乐观锁 )→multi开启事务 → 发多个命令进队列 →exec执行 /discard放弃。 - 核心价值:把多个命令 “打包”,让它们连续执行,中间不被其他客户端的操作插队,解决类似 “超卖”“库存冲突” 问题(配合
watch更稳 )。 - 和 MySQL 事务的区别:Redis 事务更轻量化、简单化,不追求严格的原子性、一致性,适合高并发下简单的 “操作打包” 场景;MySQL 事务功能强、保障严,适合数据完整性要求高的业务(比如转账 )。
理解这些,你就明白 Redis 事务的设计逻辑了:用简单的 “队列 + 执行” 模式,解决 “命令连续执行” 的问题;用 watch 实现乐观锁,避免数据冲突。虽然功能不如 MySQL 事务全面,但胜在轻量、高效,适合 Redis 本身的使用场景~