X265性能分析开源代码
X265性能分析开源代码
- 性能测试函数解析
- 对应的宏函数解析展开
- 1.为什么基准的性能测试次数是优化版本的1/4
- 2.为什么清除异常值,怎么清除异常值的?
- 3.周期数到底是怎么去计算的?
性能测试函数解析
void IntraPredHarness::measureSpeed(const EncoderPrimitives& ref, const EncoderPrimitives& opt)
{int width = 64; // 默认测试宽度uint16_t srcStride = 96; // 参考像素缓冲区步长(含填充区域)// 遍历所有块大小:4x4(0)到32x32(3)for (int i = BLOCK_4x4; i <= BLOCK_32x32; i++) {const int size = (1 << (i + 2)); // 计算实际尺寸:4<<i → 4/8/16/32/* --- 测试Planar模式 --- */if (opt.cu[i].intra_pred[PLANAR_IDX]) // 如果优化代码实现了Planar模式{printf("intra_planar_%dx%d", size, size);// 调用REPORT_SPEEDUP比较优化和参考实现REPORT_SPEEDUP(opt.cu[i].intra_pred[PLANAR_IDX], ref.cu[i].intra_pred[PLANAR_IDX],pixel_out_vec, // 输出缓冲区FENC_STRIDE, // 输出步长pixel_buff + srcStride, // 参考像素(跳过填充)0, 0); // 模式号和滤波标志}/* --- 测试DC模式 --- */if (opt.cu[i].intra_pred[DC_IDX]) {// 不过滤的情况printf("intra_dc_%dx%d[f=0]", size, size);REPORT_SPEEDUP(opt.cu[i].intra_pred[DC_IDX], ref.cu[i].intra_pred[DC_IDX],pixel_out_vec, FENC_STRIDE, pixel_buff + srcStride, 0, 0);// 仅对小块(≤16x16)测试滤波情况if (size <= 16) {printf("intra_dc_%dx%d[f=1]", size, size);REPORT_SPEEDUP(opt.cu[i].intra_pred[DC_IDX], ref.cu[i].intra_pred[DC_IDX],pixel_out_vec, FENC_STRIDE, pixel_buff + srcStride, 0, 1); // 滤波标志=1}}/* --- 测试AllAngs模式(组合角度预测)--- */if (opt.cu[i].intra_pred_allangs) {bool bFilter = (size <= 16); // 小块启用滤波pixel* refAbove = pixel_buff + srcStride; // 上方参考像素pixel* refLeft = refAbove + 3 * size; // 左侧参考像素refLeft[0] = refAbove[0]; // 填充左上角像素printf("intra_allangs%dx%d", size, size);REPORT_SPEEDUP(opt.cu[i].intra_pred_allangs,ref.cu[i].intra_pred_allangs,pixel_out_33_vec, // 输出缓冲区(33种角度)refAbove, refLeft, // 参考像素指针bFilter); // 滤波标志}/* --- 测试所有角度模式(2-34) --- */for (int mode = 2; mode <= 34; mode++) {if (opt.cu[i].intra_pred[mode]) // 如果实现了该角度模式{width = 1 << (i + 2); // 重新计算块宽bool bFilter = (width <= 16); // 滤波标志pixel* refAbove = pixel_buff + srcStride;pixel* refLeft = refAbove + 3 * width;refLeft[0] = refAbove[0]; // 填充左上角printf("intra_ang_%dx%d[%2d]", width, width, mode);REPORT_SPEEDUP(opt.cu[i].intra_pred[mode],ref.cu[i].intra_pred[mode],pixel_out_vec, FENC_STRIDE,pixel_buff + srcStride,mode, // 当前角度模式号bFilter); // 滤波标志}}/* --- 测试帧内滤波 --- */if (opt.cu[i].intra_filter) {printf("intra_filter_%dx%d", size, size);REPORT_SPEEDUP(opt.cu[i].intra_filter,ref.cu[i].intra_filter,pixel_buff, // 输入缓冲区pixel_out_c); // 输出缓冲区}}
}
对应的宏函数解析展开
#define BENCH_RUNS 2000/* Adapted from checkasm.c, runs each optimized primitive four times, measures rdtsc* and discards invalid times. Repeats BENCH_RUNS times to get a good average.* Then measures the C reference with BENCH_RUNS / 4 runs and reports X factor and average cycles.*/
#define REPORT_SPEEDUP(RUNOPT, RUNREF, ...) \{ \uint32_t cycles = 0; int runs = 0; \RUNOPT(__VA_ARGS__); \ //预热运行,避免冷启动影响for (int ti = 0; ti < BENCH_RUNS; ti++) { \ /* 主测试循环:运行BENCH_RUNS次,每次测4次连续调用 */uint32_t t0 = (uint32_t)__rdtsc(); \RUNOPT(__VA_ARGS__); \RUNOPT(__VA_ARGS__); \RUNOPT(__VA_ARGS__); \RUNOPT(__VA_ARGS__); \uint32_t t1 = (uint32_t)__rdtsc() - t0; \// 计算周期数if (t1 * runs <= cycles * 4 && ti > 0) { cycles += t1; runs++; } V\ /* 过滤异常值(超过平均4倍的测量值) */ \} \/* --- 测量参考代码性能(减少迭代次数)--- */ uint32_t refcycles = 0; int refruns = 0; \RUNREF(__VA_ARGS__); \for (int ti = 0; ti < BENCH_RUNS / 4; ti++) { \uint32_t t0 = (uint32_t)__rdtsc(); \RUNREF(__VA_ARGS__); \RUNREF(__VA_ARGS__); \RUNREF(__VA_ARGS__); \RUNREF(__VA_ARGS__); \uint32_t t1 = (uint32_t)__rdtsc() - t0; \if (t1 * refruns <= refcycles * 4 && ti > 0) { refcycles += t1; refruns++; } \} \ /* --- 计算结果 --- */x265_emms(); \ // 清空MMX/SSE状态(避免浮点寄存器污染)float optperf = (10.0f * cycles / runs) / 4; \ /* 计算平均每次调用的周期数(×10提高显示精度) */float refperf = (10.0f * refcycles / refruns) / 4; \printf(" | \t%3.2fx | ", refperf / optperf); \ /* 输出加速比和绝对周期数 */ printf("\t %-8.2lf | \t %-8.2lf\n", optperf, refperf); \}
}
1.为什么基准的性能测试次数是优化版本的1/4
这里参考代码(RUNREF)的测试次数是 BENCH_RUNS / 4,而优化代码(RUNOPT)的测试次数是完整的 BENCH_RUNS
猜测有几个原因
参考代码(RUNREF):只需提供基准参考值,不需要和优化代码相同的精度,因此减少测试次数,优化代码(RUNOPT)需要更精确的测量。
2.为什么清除异常值,怎么清除异常值的?
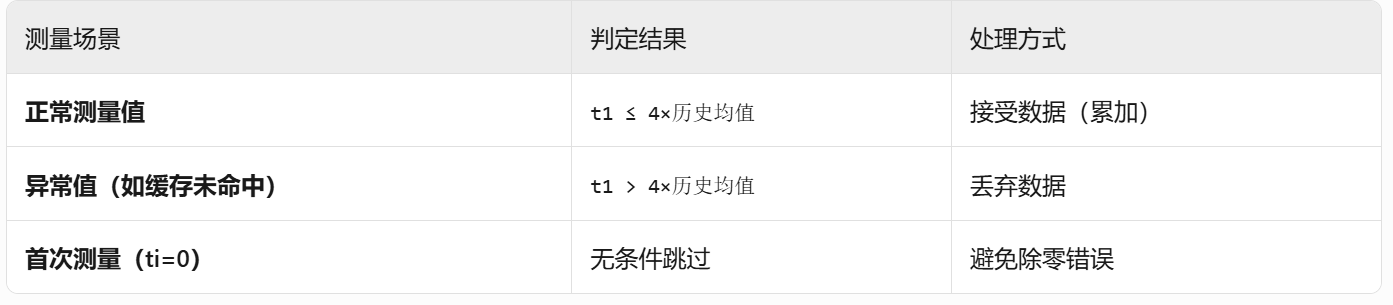
总结:首轮除外,每次更新接受小于平均值的数值值
if (t1 * runs <= cycles * 4 && ti > 0) { cycles += t1; runs++;
}
变量含义:
t1:当前测量的4次调用总周期数
runs:已接受的有效测量次数
cycles:已累积的总周期数
ti:当前迭代索引(从0开始)
逻辑分解:
t1 * runs:当前测量值 × 历史有效次数
cycles * 4:历史总周期数 × 4
ti > 0:跳过第一次测量(避免除零风险)
实际效果:
实际演算:
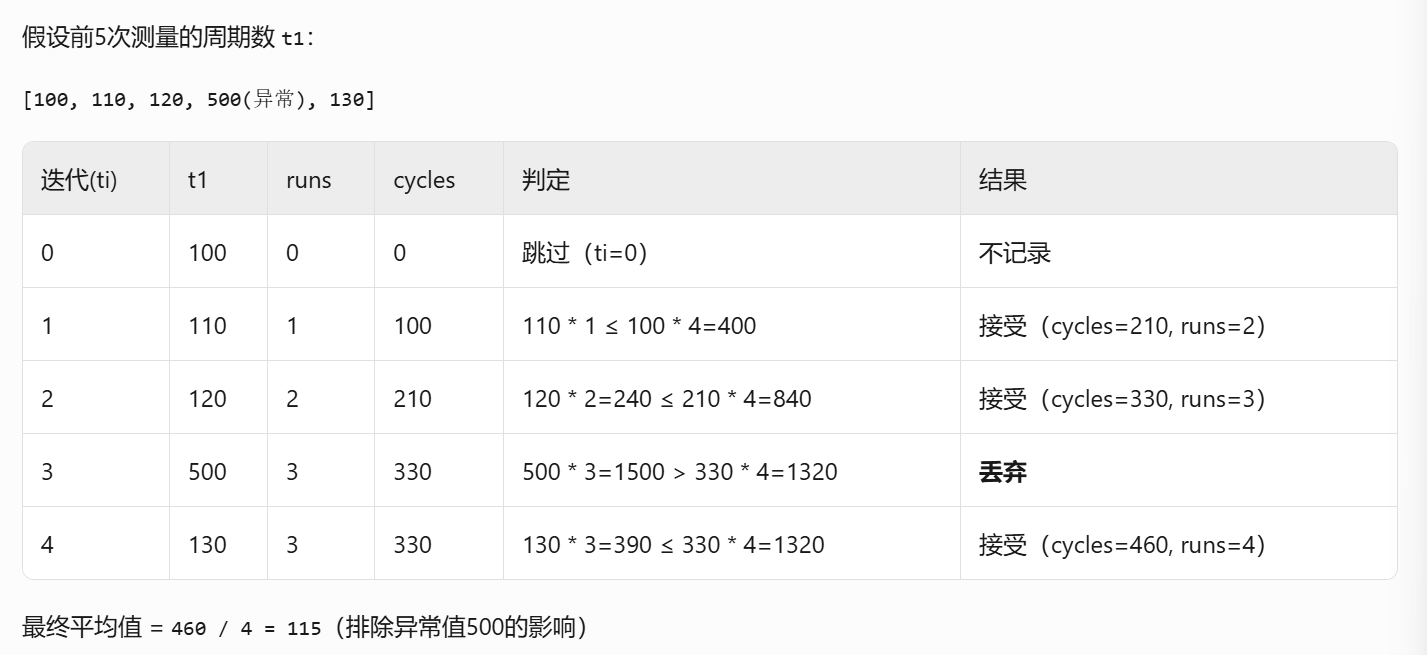
3.周期数到底是怎么去计算的?
/* fallback for older GCC/MinGW */
static inline uint32_t __rdtsc(void)
{uint32_t a = 0;#if X265_ARCH_X86asm volatile("rdtsc" : "=a" (a) ::"edx");
#elif X265_ARCH_ARM// TOD-DO: verify following inline asm to get cpu Timestamp Counter for ARM arch// asm volatile("mrc p15, 0, %0, c9, c13, 0" : "=r"(a));// TO-DO: replace clock() function with appropriate ARM cpu instructionsa = clock();
#elif X265_ARCH_ARM64asm volatile("isb" : : : "memory");asm volatile("mrs %0, cntvct_el0" : "=r"(a));
#endifreturn a;
}
咱们这里只对armv8架构的进行解读
asm volatile("isb" : : : "memory");
asm volatile("mrs %0, cntvct_el0" : "=r"(a));
- 指令:
isb:指令同步屏障(确保指令顺序执行)
mrs %0, cntvct_el0:读取虚拟计数器值 - 寄存器:
cntvct_el0:用户态可访问的64位虚拟计数器
频率通常为1-100MHz(非实际CPU频率)