数据结构初阶(5)队列
2. 队列
2.1 队列的概念及结构
队列:只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表。
队列具有 先进先出(First In First Out,FIFO)的特点。
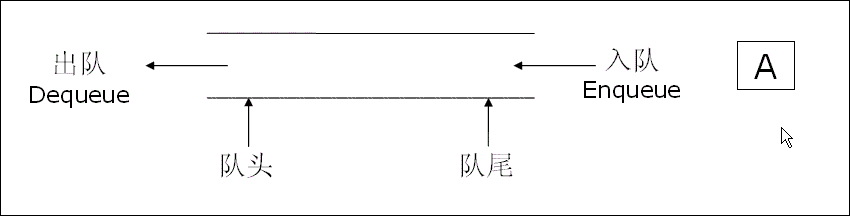
入队列:进行插入操作的一端称为队尾。
出队列:进行删除操作的一端称为队头。
2.2 队列的应用
由于是完全连号的,那用自己的号减去队头号,5-3=2就知道前面有2个人在排队。

2.3 队列的实现
逻辑分析
队列也可以顺序表(数组)和链表的结构实现。
使用 链表 的结构实现更优一些,因为如果使用数组的结构,出队列在数组头上出数据,效率会比较低。——涉及整个数组的数据挪动
① 顺序表还是链表
在栈的时候,选择数组和链表都比较好——只是数组可能是9分,链表是8分;
而在队列这里,使用链表可能是9-10分,使用数组就是5分——可以实现,但是已经很不好了
原因
队列要在一端进数据,一端出数据,而数组只有在尾插尾删时效率才高,不需要挪动数据,一进一出不管是头插(O(N))尾删(O(1))还是头删(O(N))尾插(O(1)),都会存在低效问题
② 单链表还是双链表
单链表一般都是不要哨兵位的居多,一般可要可不要的时候一般都不会要。
原因
创建哨兵位使用虽然方便,但是也有一定的代价 ——一是空间销耗,二是维护销耗
双向链表一定需要哨兵位,没有哨兵位,找尾 or 删除都不方便
(另外必要哨兵位的就是把链表拆分成大小链表再合并)
双向循环链表是应用于在任意位置插入、删除(头、尾、中间),而队列只需要头删、尾插,故没必要循环链表
有没有哨兵位的区别:不太影响头插,能让尾插更方便(不用判断链表非空)
结论1
队列的实现
- 单向
- 带头 or 不带头(都可以,本次实现不带哨兵位)
- 不循环
结论2
学完前面的数据结构的目的
- 在创建一种新的具有某种特定功能的数据结构时
- 在应用某种算法时
进行数据结构的选型。
代码实现
(1)Queue.h
初始版
// 结点数据域的类型
typedef int QDataType;
// 结点的类型
typedef struct QueueNode
{int val;struct QueueNode* next;
}QNode;// 入队列
void QueuePush(QNode* pphead)
//当链表为空,就会修改head指针的指向,需要二级指针void QueuePush(QNode** pphead)
//这样设计也不好——插入是尾插,效率是0(N)——因为要先找尾void QueuePush(QNode** pphead, QNode** pptail);
//为了效率,在这个地方需要两个指针// 出队列
void QueuePop(QNode** pphead);
// 队头出数据,就会修改head指针的指向,需要二级指针void QueuePop(QNode** pphead, QNode** pptail);
// 为了尾插的效率考虑,需要维护两个指针// 其他操作……只传一个值,就直接把它传了。
当有多个值需要记录,最好的方式就是把它们放到一个结构体中维护起来,然后传结构体。
这里的队列链表需要两个指针phead、ptail来维护,于是选择把它们放到一个结构体中去,转而去维护这一个结构体。
传参也不用传二级指针了,只需要传结构体的指针(一级指针)。
- 选择让整个链表(队列)维护两个指针——head、tail;
- 而不是选择让单链表循环起来即让每个结点维护两个指针——next、prev;
//新定义一个队列的类型
typedef struct Queue
{QNode* phead;QNode* ptail;int size; //若没有size这个成员变量,则求队列大小的接口函数时间复杂度O(N)——低效//一个结构体的成员变量有哪些,都是根据需求来的
}Queue;这里有了一个突破
之前学链表,只定义了一个(结点的)结构体。
这里根据实践中的经验灵活处理,定义了两个结构体来维护链表。
还是需要看实际的需求。
单链表不搞ptail,因为ptail只能解决尾插,对于尾删还需要ptail的prev。
改进版
在链表章节就说过,需要修改维护链表的指针的指向时:
- 传参直接传维护链表的指针,就需要二级指针。(指针的传址调用)
- 传参传包含维护链表的指针的结构体,就只需要一级指针。(变量的传址调用)
// 结点数据域的类型
typedef int QDataType;
// 结点的结构
typedef struct QListNode
{ struct QListNode* _pNext; QDataType _data;
}QNode; // 队列的结构
typedef struct Queue
{ QNode* _front; QNode* _rear;
}Queue; // 初始化队列
void QueueInit(Queue* q); // 队尾入队列
void QueuePush(Queue* q, QDataType data);
// 队头出队列
void QueuePop(Queue* q); // 获取队列头部元素
QDataType QueueFront(Queue* q);
// 获取队列队尾元素
QDataType QueueBack(Queue* q); // 获取队列中有效元素个数
int QueueSize(Queue* q);
// 检测队列是否为空,如果为空返回非零结果,如果非空返回0
int QueueEmpty(Queue* q); // 销毁队列
void QueueDestroy(Queue* q);(2)Queue.c
队列和栈一样,核心是实现 Push() 和 Pop() 两个函数。
(这里的名称是跟着C++的STL库来的)
数据结构虽然没有规定,但它有很多的惯例——就是常规情况大家都是这么做的。
以下就是常规会实现的一些队列的接口。
栈一般只会取栈顶,队列有取队头,也有取队尾。
例:存储连续值时,队头、队尾的差值就是相隔元素个数、存储连续值时,入队的元素和队尾的元素有关、……
① 初始化
代码实现。
//初始化
void QueueInit(Queue* pq)
{assert(pq);pq->phead = NULL; //指针解引用之前,先判断不为空——断言pq->ptail = NULL;pq->size = 0;
}若没有size这个成员变量,则求队列大小的接口函数时间复杂度O(N)——低效。
所以在队列的结构体类型中添加了size这个成员变量。
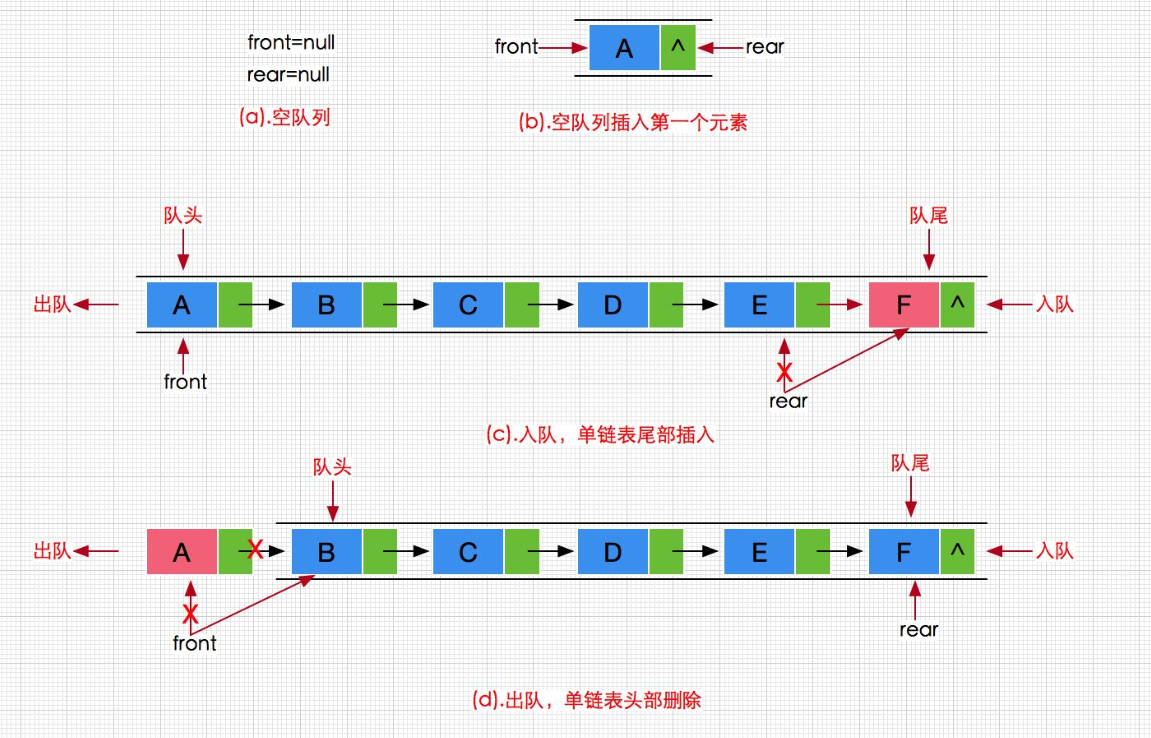
② 入队
插入数据——没有哨兵位的情况下,会稍微复杂一点,需要讨论链表不为空。
代码实现。
// 入队列——链接(!空)or 赋值(空)——没有哨兵位就要分类讨论
void QueuePush(Queue* pq, QDataType x)
{assert(pq);//这里只有push会创建新节点,没有其他的插入,没有复用就没有必要单独去写一个BuyNodeQNode* newnode = (QNode*)malloc(sizeof(QNode));if (newnode == NULL){perror("malloc fail");return;}newnode->val = x;newnode->next = NULL;//没有哨兵位,就要把插入分为两种情况//1.当链表不为空——把新节点链接到ptail后面if (pq->ptail){pq->ptail->next = newnode;pq->ptail = newnode;}//2.当链表为空——把新节点赋值给phead和ptailelse{pq->phead = pq->ptail = newnode;}pq->size++;
}③ 出队
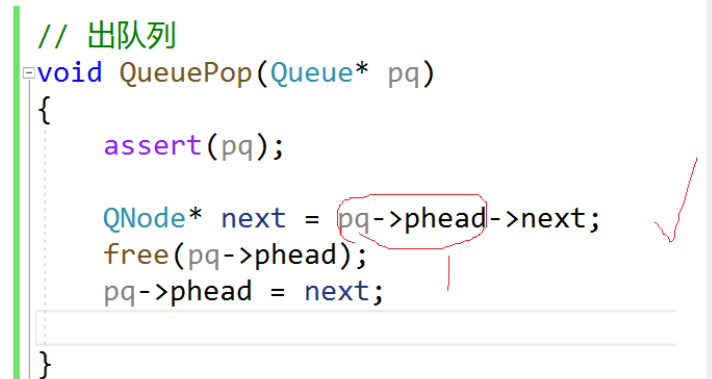
删除函数,对单链表来说这4句就够了。
但是队列Queue这里,增加了ptail和size两个变量,执行删除操作时就需要考虑到这两个变量值的变化。
同时这样的话,结构体不为空也就无法说明链表不为空。
这个代码的问题在于
- 默认有多个(≥2个)节点。
- 当只有1个结点,就还需要改ptail。(不改就是野指针)
- 当只有0个节点,就不能访问pq->head的next。
并且忘了修改size
感悟
增加了一个成员变量,让取队列大小这个接口函数变得高效,但是也增加维护的成本,涉及队列的操作都会增多一个需要维护的变量,很容易就会忘了维护它,导致程序出现bug。
代码实现。
// 出队列
void QueuePop(Queue* pq)
{assert(pq);// 1.零个节点// 温柔检查//if (pq->phead == NULL)// return;// 暴力检查 ——断言会直接终止掉程序,并报错提示assert(pq->phead != NULL);//没有第2个结点,就可以直接free掉//有第2个结点,就不能直接free掉——找不到下一个结点// 2.一个节点if (pq->phead->next == NULL){free(pq->phead);pq->phead = pq->ptail = NULL;}// 3.多个节点else{// 先保存第2个节点QNode* next = pq->phead->next;// 释放首结点free(pq->phead);// 链表头指向更替pq->phead = next;}pq->size--;
}④ 获取队头元素
代码实现。
//获取队头元素
QDataType QueueFront(Queue* pq)
{assert(pq);//只能暴力检查assert(pq->phead != NULL);//因为本函数带返回值,温柔检查不知道返回什么//返回什么,都有可能队首本身就是那个值//要是直接exit(1),还不如断言——有出错提示return pq->phead->val;
}断言的优势
- 使用简洁、简单、代码不繁复
- 出错有详细提示,在哪个文件第几行
(perror:系统调用失败后,将错误码转换成错误信息打印出来)
⑤ 获取队尾元素
代码实现。
//获取队尾元素
QDataType QueueBack(Queue* pq)
{assert(pq);//此处就不能使用if和return的组合,因为这个函数需要返回值//坚持用return给一个返回值的话,也无法判断这个返回值是正常返回的值,还是异常返回的值//而使用if和exit,那就相比于断言——就既不简洁也没提示信息//暴力检查assert(pq->ptail != NULL);return pq->ptail->val;
}⑥ 获取队列大小
代码实现。
//获取队列大小
int QueueSize(Queue* pq)
{assert(pq);return pq->size;
}⑦ 检空
代码实现。
布尔值比1、0更直观、可读性更强。
//检空
bool QueueEmpty(Queue* pq)
{assert(pq);return pq->size == 0;//或pq->head == NULL
}⑧ 销毁
代码实现。
//销毁
void QueueDestroy(Queue* pq)
{assert(pq);//链表的销毁需要遍历———销毁每一个链表结点QNode* cur = pq->phead;while (cur){//先保存下一节点QNode* next = cur->next;//再free本节点free(cur);//迭代cur = next;}pq->phead = pq->ptail = NULL; //维护队列的成员变量:全部复位pq->size = 0;
}(3)Test.c
边遍历,边弹出数据——遍历完,队列就空了。
void test1()
{//创建一个队列Queue q;//初始化QueueInit(&q);//插入QueuePush(&q, 1);QueuePush(&q, 2);//获取(打印)队头数据printf("%d ", QueueFront(&q));//弹出(头删)QueuePop(&q);//插入QueuePush(&q, 3);QueuePush(&q, 4);//和栈类似,不支持普通的遍历,是边遍历边出——符合需求while (!QueueEmpty(&q))//当为空为假{//获取队头数据printf("%d ", QueueFront(&q));//弹出(头删)QueuePop(&q);}//销毁QueueDestroy(&q);
}int main()
{test1();return 0;
}遍历的时候的操作:取队头的数据→弹出队头。
好像不需要写 获取队尾数据 这个接口:
实际上 获取队尾数据 不是队列必须实现的一个功能,数据结构的设计是根据经验来的,需要哪些接口就针对性的设计哪些接口。
之前的经验表明在:确定新号大小、排队人数、……等等场景,设计这样一个接口是比较方便的。
而且获取队尾元素也不会弹出队尾数据,更不会弹出队头数据(数据丢失)
但是队列出的方式和栈不同
- 栈的后进先出是 相对的
- 队列的先进先出是 绝对的
栈属于:后进不一定先出。
队列属于:先进一定先出。
是入完了再出,还是边入边出,出队列的顺序都不会变——绝对取决于入队列的顺序。
因为队列入、出是在两个端口进行的,在入的同时,也在出,也不会影响出的顺序。
拓展了解
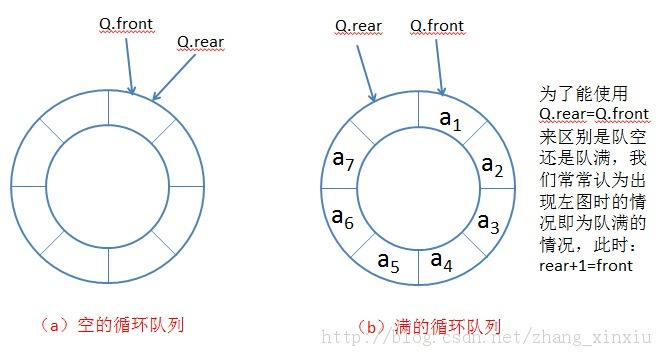
另外扩展了解一下,实际中我们有时还会使用一种队列叫 循环队列 。
如操作系统课程讲解生产者消费者模型时可以就会使用循环队列。
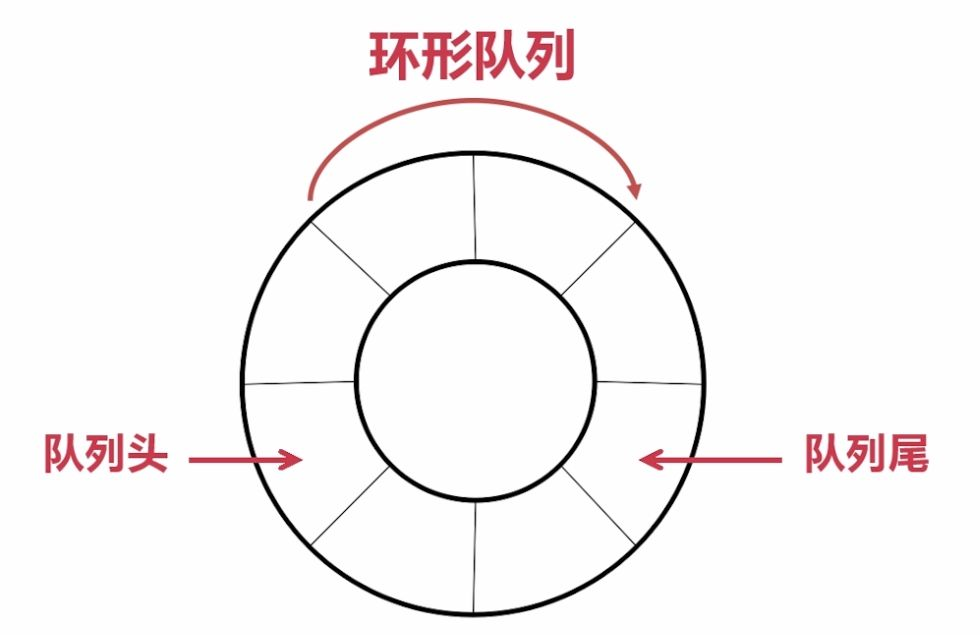
环形队列可以使用数组实现,也可以使用循环链表实现。