【AI】——SpringAI通过Ollama本地部署的Deepseek模型实现一个对话机器人(二)

🎼个人主页:【Y小夜】
😎作者简介:一位双非学校的大三学生,编程爱好者,
专注于基础和实战分享,欢迎私信咨询!
🎆入门专栏:🎇【MySQL,Javaweb,Rust,python】
🎈热门专栏:🎊【Springboot,Redis,Springsecurity,Docker,AI】
感谢您的点赞、关注、评论、收藏、是对我最大的认可和支持!❤️

目录
🎈Java调用Deepseek
🍕下载Deepseek模型
🍕本地测试
🍕Java调用模型
🎈构建数据库
🍕增强检索RAG
🍕向量数据库
🍕Springboot集成pgvector
🎈chatpdf
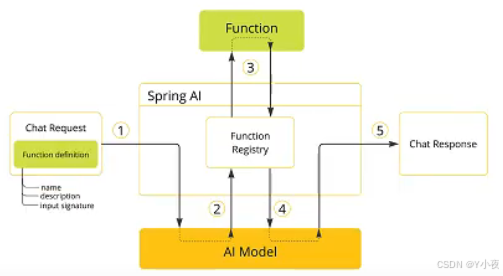
🎈function call调用自定义函数
🎈多模态能力
🎈Java调用Deepseek
本地没有安装Ollama、Docker,openwebUI,可以先学习一下这篇文章:【AI】——结合Ollama、Open WebUI和Docker本地部署可视化AI大语言模型_ollma+本地大模型+open web ui-CSDN博客
🍕下载Deepseek模型
打开命令行窗口,拉去一下Deepseek模型
ollama run deepseek-r1:7b
🍕本地测试
我们打开Docker Desktop软件。然后运行一下Open webUI

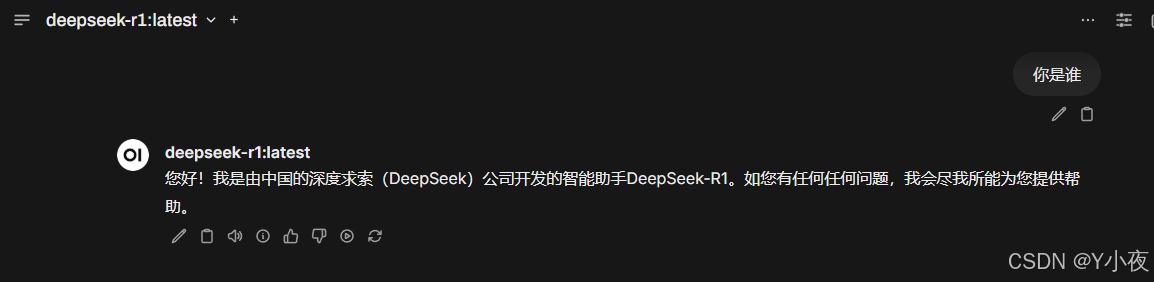
选择Deepseek-r1模型,然后进行测试
🍕Java调用模型
先把以前的moonshot依赖注释掉,然后将moonshot相关的删除,不然会报错。
引入ollama依赖:
<!-- 引入Ollama依赖-->
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
</dependency>修改一下模型:
package com.yan.springai;import lombok.RequiredArgsConstructor;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.MessageChatMemoryAdvisor;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.memory.InMemoryChatMemory;
import org.springframework.ai.ollama.OllamaChatModel;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
@RequiredArgsConstructor
public class Init {//要使用的模型final OllamaChatModel model2;@Beanpublic ChatClient chatClient(ChatMemory chatMemory){return ChatClient.builder(model2).defaultSystem("假如你是特朗普,接下来的对话你必须以特朗普的语气来进行?").defaultAdvisors(new MessageChatMemoryAdvisor(chatMemory))//这里主要负责拼接.build();}@Beanpublic ChatMemory chatMemory(){//负责存和读return new InMemoryChatMemory();}
}
修改配置文件:
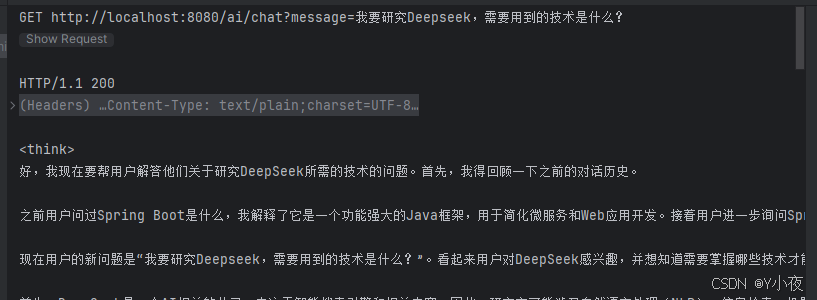
spring:ai:ollama:chat:options:model: deepseek-r1:7bbase-url: http://localhost:11434然后运行文件,看一下输出:
🎈构建数据库
🍕增强检索RAG
Embedding 是一种将对象(如词语、物品、用户等)表示为数值向量的方法。这种方法在深度学习和推荐系统中非常重要,因为它能够捕捉对象之间的相似性和关系。
我们先用ollama拉取一个embedding模型(我选择的这个模型比较小,适合小项目,不适合企业级项目)
ollama pull all-minilm
🍕向量数据库
我们这里讲的pgvector(你也可以用redis)
pgvector 是一个强大的 PostgreSQL 扩展,它为 PostgreSQL 数据库添加了向量相似性搜索功能。这使得我们可以在关系型数据库中执行语义搜索,将结构化数据查询与非结构化数据的语义理解相结合。
我们先使用命令拉取一下pgvector(最好使用魔法,不然可能拉不下来)
docker run -d --name pgvector -p 5433:5432 -e POSTGRES_USER=postgres -e POSTGRES_PASSWORD=postgres pgvector/pgvector:pg16
🍕Springboot集成pgvector
首先引入依赖
<!-- 引入pgvector--><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-pgvector-store-spring-boot-starter</artifactId></dependency>然后对他进行配置
spring:ai:vectorstore:pgvector:index-type: HNSWdistance-type: COSINE_DISTANCE
# 维度,根据选的embedding模型所定dimensions: 384batching-strategy: TOKEN_COUNTmax-document-batch-size: 1000ollama:chat:options:model: deepseek-r1:7bembedding:enabled: truemodel: all-minilmbase-url: http://localhost:11434
# 进行连接数据库datasource:url: jdbc:postgresql://localhost:5433/springaiusername: postgrespassword: postgres
然后我们使用springboot连一下数据库:
然后建立Spring ai数据库
接着执行语句建表:
create extension if not exists vector;
create extension if not exists hstore;
create extension if not exists "uuid-ossp";
create TABLE if not exists vector_store(id uuid DEFAULT uuid_generate_v4() PRIMARY KEY,content text,metadata json,embedding vector(384)
);
create index on vector_store using HNSW(embedding vector_cosine_ops);然后在resources中尽力一个txt文件:
然后建一个vector文件夹,创建一个VectorAPI类
编写文件
package com.yan.springai.vector;import lombok.RequiredArgsConstructor;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.Arrays;@RestController
@RequiredArgsConstructor
public class VectorAPI {final VectorStore store;//导入方法@GetMapping("/vec/write")public String write() throws IOException {StringBuffer text = new StringBuffer();//用来存储文件ClassLoader classLoader=getClass().getClassLoader();//因为打包后,resource的文件就放在class:path下,我们使用这个获取InputStream inputStream=classLoader.getResourceAsStream("ncode.txt");//获取文件//把文件一行一行读取出来,放在text中去try(BufferedReader reader=new BufferedReader(new InputStreamReader(inputStream))){String line;while ((line=reader.readLine())!=null){text.append(line);}}//按照句号,将文本p成一行一行的store.write(Arrays.stream(text.toString().split("。")).map(Document::new).toList());return "success";}
}
然后运行一下


控制台上打印出:
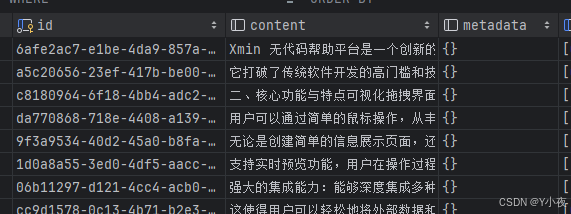
表示已经导入完毕,我们查看一下:
这时候你会得到,一个和普通模型差不多的答案:

其实我们RAG的能力也是通过advisor实现的,所以我们需要修改一下Init代码:
package com.yan.springai;import lombok.RequiredArgsConstructor;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.MessageChatMemoryAdvisor;
import org.springframework.ai.chat.client.advisor.QuestionAnswerAdvisor;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.memory.InMemoryChatMemory;
import org.springframework.ai.ollama.OllamaChatModel;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
@RequiredArgsConstructor
public class Init {//要使用的模型final OllamaChatModel model2;final VectorStore vectorStore;@Beanpublic ChatClient chatClient(ChatMemory chatMemory){return ChatClient.builder(model2).defaultSystem("假如你是特朗普,接下来的对话你必须以特朗普的语气来进行?").defaultAdvisors(new MessageChatMemoryAdvisor(chatMemory),new QuestionAnswerAdvisor(vectorStore))//这里主要负责拼接.build();}@Beanpublic ChatMemory chatMemory(){//负责存和读return new InMemoryChatMemory();}
}
然后我们在测试一下,测试成功!!!
🎈chatpdf
引入依赖:
<!-- 将pdf引入向量数据库--><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-pdf-document-reader</artifactId></dependency>然后再编写代码:
package com.yan.springai.Pdf;import lombok.RequiredArgsConstructor;
import org.springframework.ai.reader.ExtractedTextFormatter;
import org.springframework.ai.reader.pdf.PagePdfDocumentReader;
import org.springframework.ai.reader.pdf.config.PdfDocumentReaderConfig;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
@RequiredArgsConstructor
public class Pdf {final VectorStore store;@GetMapping("/pdf/read")public String getDocsFromPdf() {PagePdfDocumentReader pdfReader=new PagePdfDocumentReader("classpath:/baogao.pdf",PdfDocumentReaderConfig.builder().withPageTopMargin(0).withPageExtractedTextFormatter(ExtractedTextFormatter.builder().withNumberOfTopTextLinesToDelete(0).build()).withPagesPerDocument(1).build());store.write(pdfReader.read());return "success";}
}
然后运行测试一下,发现可以正常读入向量数据库
然后将md文档
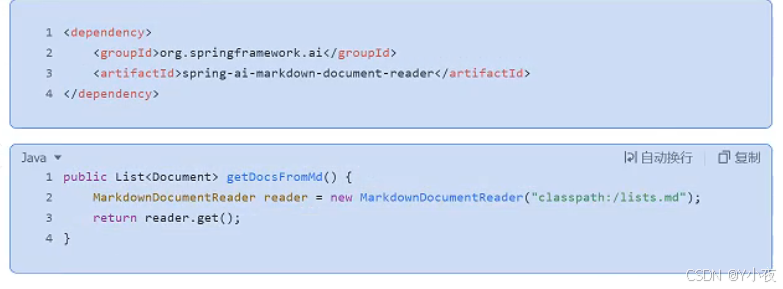
🎈function call调用自定义函数
(温馨提示:AI还不支持这个功能,比如Deepseek,然而Moonshot、OpenAI、Gimini等是可以的)
首先创建一个逻辑函数,实现Function函数
package com.yan.springai.func;import java.util.function.Function;public class OaService implements Function<OaService.Rquest, OaService.Response> {public Response apply(Rquest rquest) {//实现逻辑,这里是请假逻辑System.err.printf("%s is token off%n",rquest.who);return new Response(10);}public record Rquest(String who) {}public record Response(int days) {}
}
然后再将Function注册到spring容器中,
package com.yan.springai.func;import org.springframework.ai.model.function.FunctionCallback;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;//将function注册到spring容器中
@Configuration
public class FunctionRegistry {@Beanpublic FunctionCallback askForLeaveCallBack(){return FunctionCallback.builder().function("askForLeave",new OaService())//注册的名字和函数.description("当有人请假时,返回请假天数")//描述功能.build();}
}
然后再进行调用
package com.yan.springai.func;
//使用刚刚定义的函数import lombok.RequiredArgsConstructor;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;@RestController
@RequiredArgsConstructor
public class FuncAPI {final ChatClient chatClient;@GetMapping("/ai/func")public String funcCall(@RequestParam(value = "message")String message){return chatClient.prompt(message).functions("askForLeave")//调用名称.call().content();}
}
然后运行一下,就可以看到输出了。
🎈多模态能力
多模态大语言模型(Multimodal Large Language Models,简称Multimodal LLMs)是一种能够理解和生成多种类型数据的模型,包括文本、图片、音频和视频等。 这些模型可以跨越不同的数据形式,进行信息的交互与生成。 例如,传统语言模型只能处理文字,但多模态模型不仅能“读”文字,还能“看”图片、“听”声音,甚至“看”视频,并用文字或其他形式将它们的理解表达出来。
这里我拿图片转文字作为例子给大家介绍一下:
这里提示:Deepseek、Moonshot等是不支持的,可以下载一下llava
打开命令行窗口:
ollma run llava然后进行下载
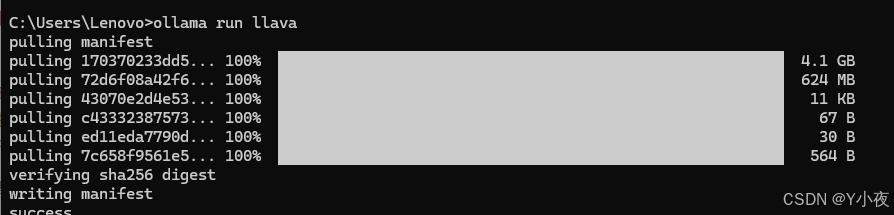
然后可以在resources传入一张图片,

package com.yan.springai.model;import lombok.RequiredArgsConstructor;
import org.springframework.ai.chat.messages.Message;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.ai.chat.prompt.ChatOptions;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.model.Media;
import org.springframework.ai.ollama.OllamaChatModel;
import org.springframework.ai.ollama.api.OllamaModel;
import org.springframework.core.io.ClassPathResource;
import org.springframework.util.MimeTypeUtils;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;import java.util.List;@RestController
@RequiredArgsConstructor
public class ImageAPI {final OllamaChatModel model;@GetMapping("/ai/chatWithPic")public String chatWithPic(){ClassPathResource imageData=new ClassPathResource("/cat.png");Message userMessage=new UserMessage("请用中文描述一下这张图片是什么东西?",List.of(new Media(MimeTypeUtils.IMAGE_PNG,imageData)));return model.call(new Prompt(List.of(userMessage),ChatOptions.builder().model(OllamaModel.LLAVA.getName()).build())).getResult().getOutput().getText();}
}
然后你就可以看到他的结果了
