小红书开源dots.ocr:单一视觉语言模型中的多语言文档布局解析

简介
dots.ocr 是一款强大的多语言文档解析器,它将版面检测与内容识别统一整合到单一视觉语言模型中,同时保持出色的阅读顺序还原能力。尽管其基础模型仅为17亿参数的轻量级大语言模型(LLM),但性能达到了业界顶尖水平(SOTA)。
- 卓越性能:在OmniDocBench基准测试中,dots.ocr 的文本、表格和阅读顺序解析均达到SOTA水平,公式识别效果更可媲美豆包1.5、gemini2.5-pro等参数量大得多的模型。
- 多语言支持:针对低资源语言展现出强大的解析能力,在我们自建的多语言文档测试集上,版面检测与内容识别均取得显著优势。
- 统一简洁架构:依托单一视觉语言模型,dots.ocr 的架构远比依赖复杂多模型流水线的传统方案更精简。仅需调整输入提示词即可切换任务,证明视觉语言模型在检测任务上可比肩DocLayout-YOLO等传统检测模型。
- 高效推理:基于17亿参数的轻量LLM构建,推理速度优于许多基于更大规模基础模型的高性能方案。
性能对比:dots.ocr 与竞品模型
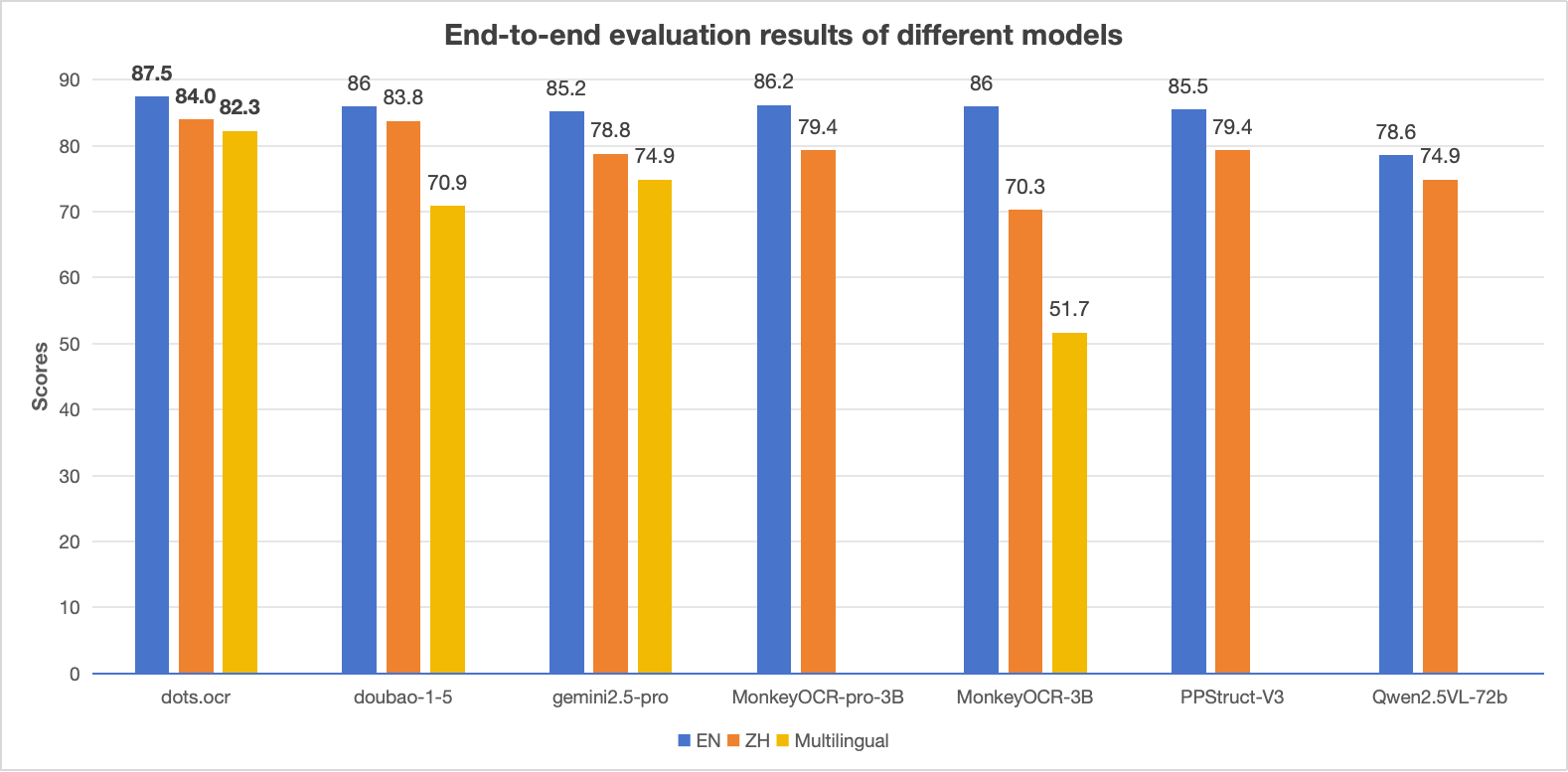
备注:
- EN、ZH 指标为 OmniDocBench 端到端评估结果,Multilingual 指标为 dots.ocr-bench 端到端评估结果。
基准测试结果
- OmniDocBench
不同任务的端到端评估结果
| Model Type | Methods | OverallEdit↓ | TextEdit↓ | FormulaEdit↓ | TableTEDS↑ | TableEdit↓ | Read OrderEdit↓ | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EN | ZH | EN | ZH | EN | ZH | EN | ZH | EN | ZH | EN | ZH | ||
| Pipeline Tools | MinerU | 0.150 | 0.357 | 0.061 | 0.215 | 0.278 | 0.577 | 78.6 | 62.1 | 0.180 | 0.344 | 0.079 | 0.292 |
| Marker | 0.336 | 0.556 | 0.080 | 0.315 | 0.530 | 0.883 | 67.6 | 49.2 | 0.619 | 0.685 | 0.114 | 0.340 | |
| Mathpix | 0.191 | 0.365 | 0.105 | 0.384 | 0.306 | 0.454 | 77.0 | 67.1 | 0.243 | 0.320 | 0.108 | 0.304 | |
| Docling | 0.589 | 0.909 | 0.416 | 0.987 | 0.999 | 1 | 61.3 | 25.0 | 0.627 | 0.810 | 0.313 | 0.837 | |
| Pix2Text | 0.320 | 0.528 | 0.138 | 0.356 | 0.276 | 0.611 | 73.6 | 66.2 | 0.584 | 0.645 | 0.281 | 0.499 | |
| Unstructured | 0.586 | 0.716 | 0.198 | 0.481 | 0.999 | 1 | 0 | 0.06 | 1 | 0.998 | 0.145 | 0.387 | |
| OpenParse | 0.646 | 0.814 | 0.681 | 0.974 | 0.996 | 1 | 64.8 | 27.5 | 0.284 | 0.639 | 0.595 | 0.641 | |
| PPStruct-V3 | 0.145 | 0.206 | 0.058 | 0.088 | 0.295 | 0.535 | - | - | 0.159 | 0.109 | 0.069 | 0.091 | |
| Expert VLMs | GOT-OCR | 0.287 | 0.411 | 0.189 | 0.315 | 0.360 | 0.528 | 53.2 | 47.2 | 0.459 | 0.520 | 0.141 | 0.280 |
| Nougat | 0.452 | 0.973 | 0.365 | 0.998 | 0.488 | 0.941 | 39.9 | 0 | 0.572 | 1.000 | 0.382 | 0.954 | |
| Mistral OCR | 0.268 | 0.439 | 0.072 | 0.325 | 0.318 | 0.495 | 75.8 | 63.6 | 0.600 | 0.650 | 0.083 | 0.284 | |
| OLMOCR-sglang | 0.326 | 0.469 | 0.097 | 0.293 | 0.455 | 0.655 | 68.1 | 61.3 | 0.608 | 0.652 | 0.145 | 0.277 | |
| SmolDocling-256M | 0.493 | 0.816 | 0.262 | 0.838 | 0.753 | 0.997 | 44.9 | 16.5 | 0.729 | 0.907 | 0.227 | 0.522 | |
| Dolphin | 0.206 | 0.306 | 0.107 | 0.197 | 0.447 | 0.580 | 77.3 | 67.2 | 0.180 | 0.285 | 0.091 | 0.162 | |
| MinerU 2 | 0.139 | 0.240 | 0.047 | 0.109 | 0.297 | 0.536 | 82.5 | 79.0 | 0.141 | 0.195 | 0.069< | 0.118 | |
| OCRFlux | 0.195 | 0.281 | 0.064 | 0.183 | 0.379 | 0.613 | 71.6 | 81.3 | 0.253 | 0.139 | 0.086 | 0.187 | |
| MonkeyOCR-pro-3B | 0.138 | 0.206 | 0.067 | 0.107 | 0.246 | 0.421 | 81.5 | 87.5 | 0.139 | 0.111 | 0.100 | 0.185 | |
| General VLMs | GPT4o | 0.233 | 0.399 | 0.144 | 0.409 | 0.425 | 0.606 | 72.0 | 62.9 | 0.234 | 0.329 | 0.128 | 0.251 |
| Qwen2-VL-72B | 0.252 | 0.327 | 0.096 | 0.218 | 0.404 | 0.487 | 76.8 | 76.4 | 0.387 | 0.408 | 0.119 | 0.193 | |
| Qwen2.5-VL-72B | 0.214 | 0.261 | 0.092 | 0.18 | 0.315 | 0.434 | 82.9 | 83.9 | 0.341 | 0.262 | 0.106 | 0.168 | |
| Gemini2.5-Pro | 0.148 | 0.212 | 0.055 | 0.168 | 0.356 | 0.439 | 85.8 | 86.4 | 0.13 | 0.119 | 0.049 | 0.121 | |
| doubao-1-5-thinking-vision-pro-250428 | 0.140 | 0.162 | 0.043 | 0.085 | 0.295 | 0.384 | 83.3 | 89.3 | 0.165 | 0.085 | 0.058 | 0.094 | |
| Expert VLMs | dots.ocr | 0.125 | 0.160 | 0.032 | 0.066 | 0.329 | 0.416 | 88.6 | 89.0 | 0.099 | 0.092 | 0.040 | 0.067 |
跨9种PDF页面类型的端到端文本识别性能。
| Model Type | Models | Book | Slides | Financial Report | Textbook | Exam Paper | Magazine | Academic Papers | Notes | Newspaper | Overall |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Pipeline Tools | MinerU | 0.055 | 0.124 | 0.033 | 0.102 | 0.159 | 0.072 | 0.025 | 0.984 | 0.171 | 0.206 |
| Marker | 0.074 | 0.340 | 0.089 | 0.319 | 0.452 | 0.153 | 0.059 | 0.651 | 0.192 | 0.274 | |
| Mathpix | 0.131 | 0.220 | 0.202 | 0.216 | 0.278 | 0.147 | 0.091 | 0.634 | 0.690 | 0.300 | |
| Expert VLMs | GOT-OCR | 0.111 | 0.222 | 0.067 | 0.132 | 0.204 | 0.198 | 0.179 | 0.388 | 0.771 | 0.267 |
| Nougat | 0.734 | 0.958 | 1.000 | 0.820 | 0.930 | 0.830 | 0.214 | 0.991 | 0.871 | 0.806 | |
| Dolphin | 0.091 | 0.131 | 0.057 | 0.146 | 0.231 | 0.121 | 0.074 | 0.363 | 0.307 | 0.177 | |
| OCRFlux | 0.068 | 0.125 | 0.092 | 0.102 | 0.119 | 0.083 | 0.047 | 0.223 | 0.536 | 0.149 | |
| MonkeyOCR-pro-3B | 0.084 | 0.129 | 0.060 | 0.090 | 0.107 | 0.073 | 0.050 | 0.171 | 0.107 | 0.100 | |
| General VLMs | GPT4o | 0.157 | 0.163 | 0.348 | 0.187 | 0.281 | 0.173 | 0.146 | 0.607 | 0.751 | 0.316 |
| Qwen2.5-VL-7B | 0.148 | 0.053 | 0.111 | 0.137 | 0.189 | 0.117 | 0.134 | 0.204 | 0.706 | 0.205 | |
| InternVL3-8B | 0.163 | 0.056 | 0.107 | 0.109 | 0.129 | 0.100 | 0.159 | 0.150 | 0.681 | 0.188 | |
| doubao-1-5-thinking-vision-pro-250428 | 0.048 | 0.048 | 0.024 | 0.062 | 0.085 | 0.051 | 0.039 | 0.096 | 0.181 | 0.073 | |
| Expert VLMs | dots.ocr | 0.031 | 0.047 | 0.011 | 0.082 | 0.079 | 0.028 | 0.029 | 0.109 | 0.056 | 0.055 |
备注:
- 指标数据来源于MonkeyOCR、OmniDocBench及我们内部的评估结果。
- 我们在结果Markdown中删除了页眉和页脚单元格。
- 我们使用tikz_preprocess流程将图像分辨率提升至200dpi。
- dots.ocr-bench
这是一个内部基准,包含100种语言的1493张pdf图像。
不同任务的端到端评估结果。
| Methods | OverallEdit↓ | TextEdit↓ | FormulaEdit↓ | TableTEDS↑ | TableEdit↓ | Read OrderEdit↓ |
|---|---|---|---|---|---|---|
| MonkeyOCR-3B | 0.483 | 0.445 | 0.627 | 50.93 | 0.452 | 0.409 |
| doubao-1-5-thinking-vision-pro-250428 | 0.291 | 0.226 | 0.440 | 71.2 | 0.260 | 0.238 |
| doubao-1-6 | 0.299 | 0.270 | 0.417 | 71.0 | 0.258 | 0.253 |
| Gemini2.5-Pro | 0.251 | 0.163 | 0.402 | 77.1 | 0.236 | 0.202 |
| dots.ocr | 0.177 | 0.075 | 0.297 | 79.2 | 0.186 | 0.152 |
注:
- 我们采用了与 OmniDocBench 相同的指标计算流程。
- 在结果 markdown 中删除了页眉(Page-header)和页脚(Page-footer)单元格。
布局检测
| Method | F1@IoU=.50:.05:.95↑ | F1@IoU=.50↑ | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Overall | Text | Formula | Table | Picture | Overall | Text | Formula | Table | Picture | |
| DocLayout-YOLO-DocStructBench | 0.733 | 0.694 | 0.480 | 0.803 | 0.619 | 0.806 | 0.779 | 0.620 | 0.858 | 0.678 |
| dots.ocr-parse all | 0.831 | 0.801 | 0.654 | 0.838 | 0.748 | 0.922 | 0.909 | 0.770 | 0.888 | 0.831 |
| dots.ocr-detection only | 0.845 | 0.816 | 0.716 | 0.875 | 0.765 | 0.930 | 0.917 | 0.832 | 0.918 | 0.843 |
备注:
- prompt_layout_all_en 用于解析全部,prompt_layout_only_en 仅用于检测,请参阅提示
- olmOCR-bench.
| Model | ArXiv | Old Scans Math | Tables | Old Scans | Headers and Footers | Multi column | Long Tiny Text | Base | Overall |
|---|---|---|---|---|---|---|---|---|---|
| GOT OCR | 52.7 | 52.0 | 0.2 | 22.1 | 93.6 | 42.0 | 29.9 | 94.0 | 48.3 ± 1.1 |
| Marker | 76.0 | 57.9 | 57.6 | 27.8 | 84.9 | 72.9 | 84.6 | 99.1 | 70.1 ± 1.1 |
| MinerU | 75.4 | 47.4 | 60.9 | 17.3 | 96.6 | 59.0 | 39.1 | 96.6 | 61.5 ± 1.1 |
| Mistral OCR | 77.2 | 67.5 | 60.6 | 29.3 | 93.6 | 71.3 | 77.1 | 99.4 | 72.0 ± 1.1 |
| Nanonets OCR | 67.0 | 68.6 | 77.7 | 39.5 | 40.7 | 69.9 | 53.4 | 99.3 | 64.5 ± 1.1 |
| GPT-4o (No Anchor) | 51.5 | 75.5 | 69.1 | 40.9 | 94.2 | 68.9 | 54.1 | 96.7 | 68.9 ± 1.1 |
| GPT-4o (Anchored) | 53.5 | 74.5 | 70.0 | 40.7 | 93.8 | 69.3 | 60.6 | 96.8 | 69.9 ± 1.1 |
| Gemini Flash 2 (No Anchor) | 32.1 | 56.3 | 61.4 | 27.8 | 48.0 | 58.7 | 84.4 | 94.0 | 57.8 ± 1.1 |
| Gemini Flash 2 (Anchored) | 54.5 | 56.1 | 72.1 | 34.2 | 64.7 | 61.5 | 71.5 | 95.6 | 63.8 ± 1.2 |
| Qwen 2 VL (No Anchor) | 19.7 | 31.7 | 24.2 | 17.1 | 88.9 | 8.3 | 6.8 | 55.5 | 31.5 ± 0.9 |
| Qwen 2.5 VL (No Anchor) | 63.1 | 65.7 | 67.3 | 38.6 | 73.6 | 68.3 | 49.1 | 98.3 | 65.5 ± 1.2 |
| olmOCR v0.1.75 (No Anchor) | 71.5 | 71.4 | 71.4 | 42.8 | 94.1 | 77.7 | 71.0 | 97.8 | 74.7 ± 1.1 |
| olmOCR v0.1.75 (Anchored) | 74.9 | 71.2 | 71.0 | 42.2 | 94.5 | 78.3 | 73.3 | 98.3 | 75.5 ± 1.0 |
| MonkeyOCR-pro-3B | 83.8 | 68.8 | 74.6 | 36.1 | 91.2 | 76.6 | 80.1 | 95.3 | 75.8 ± 1.0 |
| dots.ocr | 82.1 | 64.2 | 88.3 | 40.9 | 94.1 | 82.4 | 81.2 | 99.5 | 79.1 ± 1.0 |
快速开始
- 安装
安装 dots.ocr
conda create -n dots_ocr python=3.12
conda activate dots_ocrgit clone https://github.com/rednote-hilab/dots.ocr.git
cd dots.ocr# Install pytorch, see https://pytorch.org/get-started/previous-versions/ for your cuda version
pip install torch==2.7.0 torchvision==0.22.0 torchaudio==2.7.0 --index-url https://download.pytorch.org/whl/cu128
pip install -e .
如果在安装过程中遇到问题,可以尝试使用我们的Docker镜像以简化配置,并按照以下步骤操作:
git clone https://github.com/rednote-hilab/dots.ocr.git
cd dots.ocr
pip install -e .
下载模型权重
💡注意:请为模型保存路径使用不含句点的目录名(例如用DotsOCR而非dots.ocr)。这是我们与Transformers集成前的临时解决方案。
python3 tools/download_model.py
- 部署
vLLM推理
我们强烈建议使用vLLM进行部署和推理。我们所有的评估结果均基于vLLM 0.9.1版本。Docker镜像基于官方vLLM镜像构建,您也可以参考Dockerfile自行搭建部署环境。
# You need to register model to vllm at first
python3 tools/download_model.py
export hf_model_path=./weights/DotsOCR # Path to your downloaded model weights, Please use a directory name without periods (e.g., `DotsOCR` instead of `dots.ocr`) for the model save path. This is a temporary workaround pending our integration with Transformers.
export PYTHONPATH=$(dirname "$hf_model_path"):$PYTHONPATH
sed -i '/^from vllm\.entrypoints\.cli\.main import main$/a\
from DotsOCR import modeling_dots_ocr_vllm' `which vllm` # If you downloaded model weights by yourself, please replace `DotsOCR` by your model saved directory name, and remember to use a directory name without periods (e.g., `DotsOCR` instead of `dots.ocr`) # launch vllm server
CUDA_VISIBLE_DEVICES=0 vllm serve ${hf_model_path} --tensor-parallel-size 1 --gpu-memory-utilization 0.95 --chat-template-content-format string --served-model-name model --trust-remote-code# If you get a ModuleNotFoundError: No module named 'DotsOCR', please check the note above on the saved model directory name.# vllm api demo
python3 ./demo/demo_vllm.py --prompt_mode prompt_layout_all_en
Huggingface 推理
python3 demo/demo_hf.py
Huggingface 推理细节
import torch
from transformers import AutoModelForCausalLM, AutoProcessor, AutoTokenizer
from qwen_vl_utils import process_vision_info
from dots_ocr.utils import dict_promptmode_to_promptmodel_path = "./weights/DotsOCR"
model = AutoModelForCausalLM.from_pretrained(model_path,attn_implementation="flash_attention_2",torch_dtype=torch.bfloat16,device_map="auto",trust_remote_code=True
)
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)image_path = "demo/demo_image1.jpg"
prompt = """Please output the layout information from the PDF image, including each layout element's bbox, its category, and the corresponding text content within the bbox.1. Bbox format: [x1, y1, x2, y2]2. Layout Categories: The possible categories are ['Caption', 'Footnote', 'Formula', 'List-item', 'Page-footer', 'Page-header', 'Picture', 'Section-header', 'Table', 'Text', 'Title'].3. Text Extraction & Formatting Rules:- Picture: For the 'Picture' category, the text field should be omitted.- Formula: Format its text as LaTeX.- Table: Format its text as HTML.- All Others (Text, Title, etc.): Format their text as Markdown.4. Constraints:- The output text must be the original text from the image, with no translation.- All layout elements must be sorted according to human reading order.5. Final Output: The entire output must be a single JSON object.
"""messages = [{"role": "user","content": [{"type": "image","image": image_path},{"type": "text", "text": prompt}]}]# Preparation for inference
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(text=[text],images=image_inputs,videos=video_inputs,padding=True,return_tensors="pt",
)inputs = inputs.to("cuda")# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=24000)
generated_ids_trimmed = [out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
3.文档解析
基于vLLM服务器,您可以使用以下命令解析图像或pdf文件:
# Parse all layout info, both detection and recognition
# Parse a single image
python3 dots_ocr/parser.py demo/demo_image1.jpg
# Parse a single PDF
python3 dots_ocr/parser.py demo/demo_pdf1.pdf --num_threads 64 # try bigger num_threads for pdf with a large number of pages# Layout detection only
python3 dots_ocr/parser.py demo/demo_image1.jpg --prompt prompt_layout_only_en# Parse text only, except Page-header and Page-footer
python3 dots_ocr/parser.py demo/demo_image1.jpg --prompt prompt_ocr# Parse layout info by bbox
python3 dots_ocr/parser.py demo/demo_image1.jpg --prompt prompt_grounding_ocr --bbox