特征工程 --- 特征提取
特征工程
一、特征工程逻辑思维导图
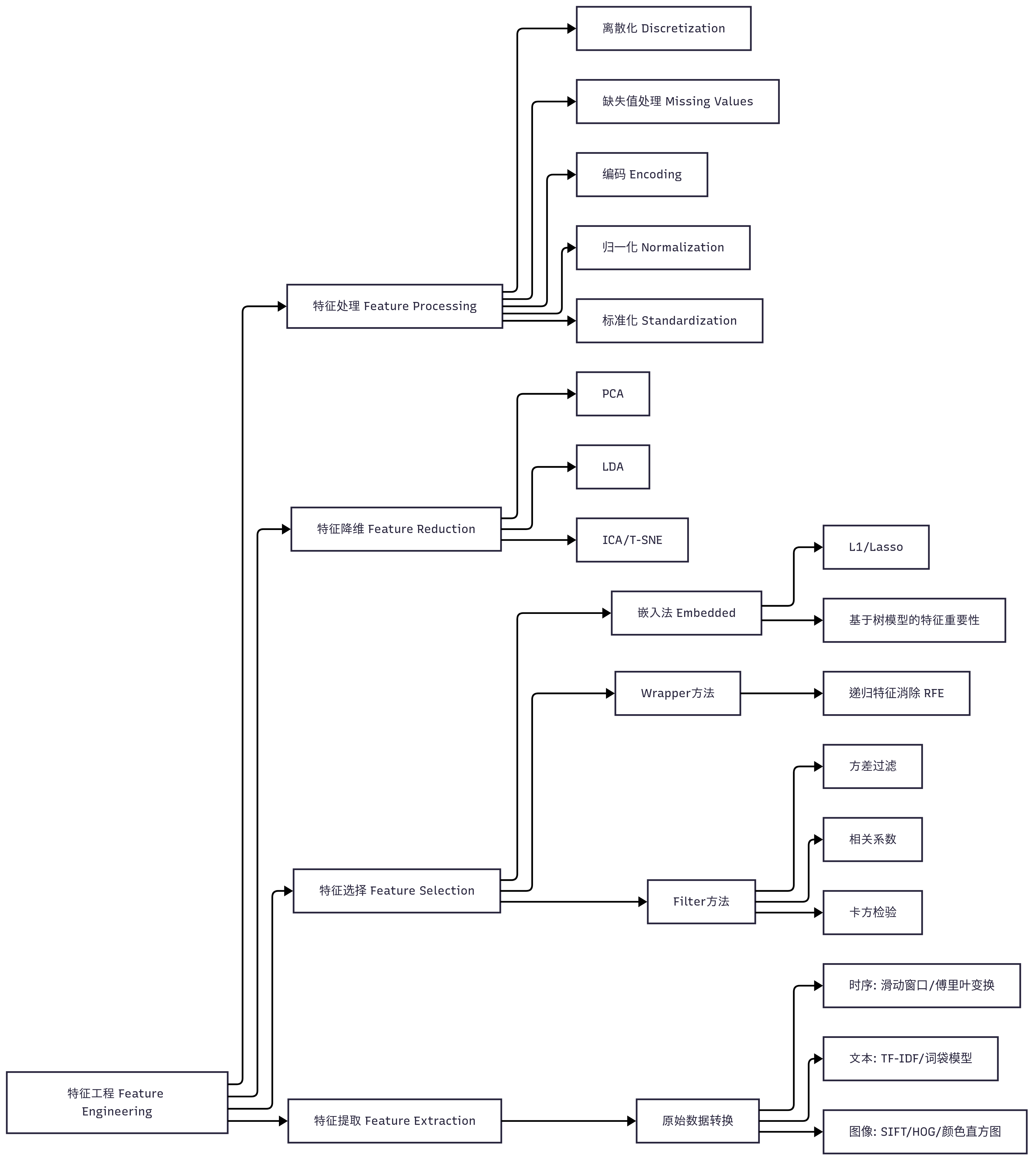
二、特征工程的概念
1.定义:
特征工程(Feature Engineering)是指在机器学习或深度学习项目中,为了更好地提高模型性能,通过构造、转换、选择特征的技术与过程。
2.目的:
| 目的 | 说明 |
|---|---|
| 提高模型性能 | 更有意义的特征 → 更好的模型拟合与预测能力 |
| 降低维度与计算复杂度 | 去除冗余、无关特征,加快模型训练 |
| 提升泛化能力 | 减少过拟合,提升对新数据的表现 |
| 增强可解释性 | 构造更具现实意义的特征,方便模型解释 |
3.特征工程包括哪些步骤:
- 特征提取
- 特征选择
- 特征处理
- 特征降维
4. 举个简单例子
假设你要预测一个人的购车行为,原始数据有这些字段:
| 姓名 | 年龄 | 年收入(元) | 婚姻状态 | 城市 | 是否购车 |
|---|---|---|---|---|---|
| 张三 | 25 | 120000 | 未婚 | 北京 | 否 |
| 李四 | 45 | 300000 | 已婚 | 上海 | 是 |
| 王五 | 35 | 200000 | 离异 | 广州 | 是 |
| 赵六 | 28 | 180000 | 未婚 | 深圳 | 否 |
5.特征工程做了什么?
① 特征提取(Feature Extraction)
- 通常直接使用结构化数据的字段
- 或从原始字段中提取额外信息,如:
| 原始字段 | 新提取特征 |
|---|---|
| 城市 | 城市级别(如一线城市) |
| 年龄 | 年龄段(<30、30-50、>50) |
② 特征处理(Feature Processing)
| 操作 | 字段 | 方法/说明 |
|---|---|---|
| 数值缩放 | 年收入 | 标准化(Z-score)或归一化(Min-Max) |
| 分箱 | 年龄 | 分为年龄段(如 <30, 30-50, >50) |
| 编码 | 婚姻状态/城市 | 独热编码 One-Hot 或 Label Encoding |
| 缺失值处理 | 若有缺失 | 使用中位数/众数/插值填充 |
编码示例(婚姻状态):
| 婚姻状态 | 婚姻_未婚 | 婚姻_已婚 | 婚姻_离异 |
|---|---|---|---|
| 未婚 | 1 | 0 | 0 |
| 已婚 | 0 | 1 | 0 |
| 离异 | 0 | 0 | 1 |
③ 特征构造(Feature Construction)
| 构造目标 | 构造方法 |
|---|---|
| 家庭稳定指数 | 婚姻状态 × 年龄 |
| 收入等级 | 年收入分箱(如高/中/低) |
| 城市影响力评分 | 自定义字典,如北京=3,广州=2 |
④ 特征选择(Feature Selection)
- 目的:去除无用或冗余特征(如城市过多分散,且购车率差异小)
- 可采用:
相关系数法卡方检验L1 正则化树模型的重要性评分(Feature Importance)
⑤ 特征降维(可选)
如果有维度灾难风险,比如城市编码后有 100 维,可以用:
| 方法 | 适用场景 |
|---|---|
| PCA | 连续变量、数值特征降维 |
| LDA | 有监督、分类场景 |
| AutoEncoder | 深度特征压缩 |
🔄 转换后数据示意
| 年龄 | 年收入 | 婚姻_未婚 | 婚姻_已婚 | 婚姻_离异 | 城市_北京 | 城市_上海 | 城市_广州 | 城市_深圳 | 收入等级_高 | 是否购车 |
|---|---|---|---|---|---|---|---|---|---|---|
| 25 | 0.21 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 否 |
| 45 | 1.00 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 是 |
| 35 | 0.62 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 是 |
| 28 | 0.54 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 否 |
6. 特征工程与建模的关系
- 没有好的特征工程,再强的模型也很难表现好
- 特征工程 ≈ 模型效果的地基
三、特征工程API
-
实例化转换器对象,转换器类有很多,都是
Transformer的子类, 常用的子类有:DictVectorizer 字典特征提取 CountVectorizer 文本特征提取 TfidfVectorizer TF-IDF文本特征词的重要程度特征提取 MinMaxScaler 归一化 StandardScaler 标准化 VarianceThreshold 底方差过滤降维 PCA 主成分分析降维 -
转换器对象调用fit_transform()进行转换, 其中fit用于计算数据,transform进行最终转换fit_transform()可以使用fit()和transform()代替
data_new = transfer.fit_transform(data)
可写成
transfer.fit(data)
data_new = transfer.transform(data)
在后面我们会讲解为什么会设计成这样。
四、DictVectorizer字典列表特征提取
from sklearn.feature_extraction import DictVectorizer
1. 什么是字典列表特征提取?
举个例子:你有一个这样的原始数据:
data = [{'age': 28, 'income': 50000, 'married': 'yes', 'city': 'Beijing'},{'age': 35, 'income': 80000, 'married': 'no', 'city': 'Shanghai'},{'age': 40, 'income': 90000, 'married': 'yes', 'city': 'Beijing'}
]
- 每条数据是一个字典,整个数据是“字典的列表”。
DictVectorizer会自动把分类变量做成 One-Hot,数值型保持原值。
2.代码演示(含稀疏矩阵和稠密矩阵)
from sklearn.feature_extraction import DictVectorizerdata = [{'age': 28, 'income': 50000, 'married': 'yes', 'city': 'Beijing'},{'age': 35, 'income': 80000, 'married': 'no', 'city': 'Shanghai'},{'age': 40, 'income': 90000, 'married': 'yes', 'city': 'Beijing'}
]# 1. 创建向量器
vec = DictVectorizer(sparse=True) # 默认为 True,返回稀疏矩阵# 2. 进行转换
X_sparse = vec.fit_transform(data)# 3. 查看稀疏结果(CSR格式)
print(X_sparse)# 4. 转成稠密矩阵
X_dense = X_sparse.toarray()# 5. 获取特征名
print(vec.get_feature_names_out())
print(X_dense)
3.返回值的不同(稀疏 VS 稠密)
| 参数 | 作用 | 返回类型 | 优点 |
|---|---|---|---|
sparse=True | 返回稀疏矩阵(默认) | scipy.sparse 三元组表形式(CSR) | 节省内存 |
sparse=False | 返回稠密 numpy.ndarray | 直接是 array | 便于查看与调试 |
4. 稀疏矩阵转换成稠密矩阵
X_dense = X_sparse.toarray()
5. 示例输出
稀疏矩阵:(行索引,列索引) 数据
<Compressed Sparse Row sparse matrix of dtype 'float64'with 12 stored elements and shape (3, 6)>Coords Values(0, 0) 28.0(0, 1) 1.0(0, 3) 50000.0(0, 5) 1.0(1, 0) 35.0(1, 2) 1.0(1, 3) 80000.0(1, 4) 1.0(2, 0) 40.0(2, 1) 1.0(2, 3) 90000.0(2, 5) 1.0
-
内存中:是 CSR 格式(
Compressed Sparse Row),存储的是:.data: 非零元素值列表.indices: 非零元素所在的列索引.indptr: 每行非零元素的起始位置索引
-
打印时显示出来的
(row, col) \t value只是为了可读性 —— 这叫做:“伪三元组表输出”(Human-readable triplet-like format)
它让我们看到非零值在矩阵中的具体位置和数值,但这不是它真实的底层结构。
特征名(vec.get_feature_names_out()):
['age' 'city=Beijing' 'city=Shanghai' 'income' 'married=no' 'married=yes']
稠密矩阵:
[[2.8e+01 1.0e+00 0.0e+00 5.0e+04 0.0e+00 1.0e+00][3.5e+01 0.0e+00 1.0e+00 8.0e+04 1.0e+00 0.0e+00][4.0e+01 1.0e+00 0.0e+00 9.0e+04 0.0e+00 1.0e+00]]
6. 特点总结
| 优点 | 缺点 |
|---|---|
| 自动处理分类变量(One-Hot) | 特征维度可能膨胀,尤其是高基类分类变量 |
| 数值变量保持原样 | 不支持嵌套结构(如 list、dict 中嵌 dict) |
输出与 OneHotEncoder + ColumnTransformer 类似 | 只适用于结构化数据(非嵌套 JSON) |
7.使用场景建议
- 小规模分类变量编码:如城市、性别等,用
DictVectorizer非常便捷。 - 大规模/高基类分类变量:建议使用
OneHotEncoder(handle_unknown='ignore')结合ColumnTransformer管理更灵活。
五、CountVectorizer 文本特征提取
from sklearn.feature_extraction.text import CountVectorizer
1.基本原理
CountVectorizer 是最基础的文本向量化工具,它将文本中的词语转换为词频(Bag-of-Words,简称 BOW)特征矩阵。
功能:将一组文本(corpus)转换成词频矩阵(bag-of-words)
- 每一行代表一条文本
- 每一列代表一个词(特征)
- 每个单元格表示该词在该文本中出现的次数
默认行为是:
- 按英文空格和标点分词
- 自动转小写
- 只能处理英文,处理中文会把整句话当成一个词
2.案例解释
①简洁版
from sklearn.feature_extraction.text import CountVectorizer
import jiebacorpus = ["我爱北京天安门","天安门上太阳升","The sun rises in the east","I love Beijing Tiananmen"
]def mixed_tokenizer(text):if any( '\u4e00' <= chinese <='\u9fff' for chinese in text):return " ".join(jieba.cut(text))else:return text.lower()counter = CountVectorizer()
data2 = [mixed_tokenizer(word) for word in corpus]
data = counter.fit_transform(data2)
print(data.toarray())
print(counter.get_feature_names_out())
输出结果如下:
[[0 0 0 0 0 0 0 0 1 1 0][0 0 0 0 0 0 0 0 0 1 1][0 1 1 0 1 1 2 0 0 0 0][1 0 0 1 0 0 0 1 0 0 0]]
['beijing' 'east' 'in' 'love' 'rises' 'sun' 'the' 'tiananmen' '北京' '天安门''太阳升']
②DataFrame构建词汇表
import jieba
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd# 自定义中文 + 英文分词函数
def mixed_tokenizer(text):if any('\u4e00' <= ch <= '\u9fff' for ch in text): # 中文检测return list(jieba.cut(text))else:return text.lower().split() # 英文按空格并小写处理# 用 CountVectorizer 进行词频统计
vectorizer = CountVectorizer(tokenizer=mixed_tokenizer,token_pattern=None)X = vectorizer.fit_transform(corpus)# 输出特征名(词汇表)
print("词汇表:")
print(vectorizer.get_feature_names_out())# 转成 DataFrame 展示词频矩阵
df = pd.DataFrame(X.toarray(), columns=vectorizer.get_feature_names_out())
print("\n词频矩阵:")
df.head()
输出如下所示:
词汇表:
['beijing' 'east' 'i' 'in' 'love' 'rises' 'sun' 'the' 'tiananmen' '上' '北京''天安门' '太阳升' '我' '爱']
词频矩阵:
| beijing | east | i | in | love | rises | sun | the | tiananmen | 上 | 北京 | 天安门 | 太阳升 | 我 | 爱 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 1 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 |
| 2 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
3.参数解释
| 参数名 | 作用 | 示例 |
|---|---|---|
lowercase | 是否转小写(默认True) | 'NLP' → 'nlp' |
stop_words | 停用词(如 ‘the’, ‘is’) | stop_words='english' |
max_features | 限制输出特征数量 | max_features=1000 |
ngram_range | 支持 n-gram 模型 | (1,2) → 1-gram + 2-gram |
token_pattern | 正则表达式控制分词方式 | 默认只保留词长 ≥2 的单词 |
binary | 是否将词频转为二值(出现为1) | binary=True |
六、TfidfVectorizer TF-IDF文本特征词的重要程度特征提取
from sklearn.feature_extraction.text import TfidfVectorizer
TfidfVectorizer 是 sklearn 中用于将文本数据转换为基于 TF-IDF(词频 - 逆文档频率) 权重的特征向量的工具,核心作用是量化词语在文本中的重要程度,是文本分类、聚类等任务中常用的特征提取方法。
1. TF-IDF 核心原理
TF-IDF 由两部分组成:词频(TF) 和 逆文档频率(IDF),最终通过两者的乘积衡量词语的重要性。

-
词频(Term Frequency, TF) 表示一个词在单篇文档中出现的频率,反映该词在当前文档中的重要性。
- 计算公式(sklearn 默认):直接使用词语在文档中出现的原始次数(与
CountVectorizer的结果一致)。 - 示例:若 “教育” 在文档 1 中出现 2 次,则该文档中 “教育” 的 TF 为 2。
- 计算公式(sklearn 默认):直接使用词语在文档中出现的原始次数(与
-
逆文档频率(Inverse Document Frequency, IDF) 反映一个词在整个文档集合中的稀有程度:若一个词在多数文档中都出现(如 “的”“是”),则其重要性低;若仅在少数文档中出现,则重要性高。
-
sklearn 中的计算公式(带平滑处理):
IDF(t)=log(总文档数+1包含词t的文档数+1)+1 \text{IDF}(t) = \log\left(\frac{\text{总文档数} + 1}{\text{包含词}t\text{的文档数} + 1}\right) + 1 IDF(t)=log(包含词t的文档数+1总文档数+1)+1
- 平滑目的:避免分母为 0(当某词未出现在任何文档中时)。
-
示例:若 “民办” 在 3 篇文档中出现 2 次,总文档数为 3,则其 IDF 为 log(3+12+1)+1≈0.2877+1=1.2877\log\left(\frac{3+1}{2+1}\right) + 1 \approx 0.2877 + 1 = 1.2877log(2+13+1)+1≈0.2877+1=1.2877
-
-
TF-IDF 最终值 词语的 TF-IDF 权重 = 该词的 TF × 该词的 IDF。
- 含义:同时考虑词语在当前文档中的频率和在整体文档中的稀有性,权重越高则该词对当前文档的 “代表性” 越强。
-
L2 归一化(sklearn 默认) 为了避免长文档的向量权重普遍高于短文档,
TfidfVectorizer会对每个文档的 TF-IDF 向量进行 L2 归一化:
归一化后的值=xix12+x22+...+xn2 \text{归一化后的值} = \frac{x_i}{\sqrt{x_1^2 + x_2^2 + ... + x_n^2}} 归一化后的值=x12+x22+...+xn2xi
其中 $x_i $是向量中的每个元素(即某词的 TF-IDF 权重)。
2. ✅ 各部分 “+1” 的意义详解:
| 部分 | 数学目的 | 原因解释 |
|---|---|---|
| 分子 N+1 | 平衡缩放 | 如果没有这个,极端情况下 IDF 可能会小于 1(造成结果偏小),这个 +1 有助于提高稀有词的重要性。 |
| 分母 +1 | 防止除零 | 避免某个词没有出现在任何文档中(即 df=0),否则会导致除以 0。 |
| 整体 +1 | 平移,避免 0 | 让所有 IDF 都大于 0,防止乘上 IDF 后造成词权重为 0,特别是在只有一个文档时。 |
在 sklearn 的 TfidfVectorizer 中,输出的 TF-IDF 向量默认经过了 L2 正则化,目的如下:
- 保证每个文档的特征向量是单位长度,避免长文本向量绝对值过大
- 更好地支持 余弦相似度计算(常用于文本匹配)
- 提高模型对文本长度不一致的鲁棒性
3.案例演示:
①使用官方API:
from sklearn.feature_extraction.text import TfidfVectorizer
import jiebacorpus = ["我爱北京天安门","天安门上太阳升","The sun rises in the east","I love Beijing Tiananmen"
]def mixed_tokenizer(text):if any( '\u4e00' <= chinese <='\u9fff' for chinese in text):return " ".join(jieba.cut(text))else:return text.lower()transfer = TfidfVectorizer()
data = [mixed_tokenizer(word) for word in corpus]
data = transfer.fit_transform(data)
print(data.toarray())
print(transfer.get_feature_names_out())
结果输出:
[[0. 0. 0. 0. 0. 0.0. 0. 0.78528828 0.6191303 0. ][0. 0. 0. 0. 0. 0.0. 0. 0. 0.6191303 0.78528828][0. 0.35355339 0.35355339 0. 0.35355339 0.353553390.70710678 0. 0. 0. 0. ][0.57735027 0. 0. 0.57735027 0. 0.0. 0.57735027 0. 0. 0. ]]
['beijing' 'east' 'in' 'love' 'rises' 'sun' 'the' 'tiananmen' '北京' '天安门''太阳升']
②利用公式自定义函数:
from sklearn.feature_extraction.text import CountVectorizer
import numpy as np
from sklearn.preprocessing import normalizedef myTfidVectorizer(data):counter = CountVectorizer()TF = counter.fit_transform(data).toarray() # 词频矩阵(TF)IDF = np.log((len(TF) + 1) / ((TF != 0).sum(axis=0) + 1)) + 1 # IDF 计算TF_IDF = TF * IDF # 每个位置乘以对应的 IDFTF_IDF = normalize(TF_IDF, norm="l2") # L2归一化return TF_IDF,counter.get_feature_names_out()def default_tokenizer(text):if any("\u4e00" <= ch <= "\u9fff" for ch in text): # 判断是否含有中文字符return " ".join(jieba.cut(text))else:return text.lower()import jiebacorpus = ["我爱北京天安门","天安门上太阳升","The sun rises in the east","I love Beijing Tiananmen"
]data = [default_tokenizer(word) for word in corpus]
transfer,feature = myTfidVectorizer(data)
print(transfer,feature)
结果输出:
[[0. 0. 0. 0. 0. 0.0. 0. 0.78528828 0.6191303 0. ][0. 0. 0. 0. 0. 0.0. 0. 0. 0.6191303 0.78528828][0. 0.35355339 0.35355339 0. 0.35355339 0.353553390.70710678 0. 0. 0. 0. ][0.57735027 0. 0. 0.57735027 0. 0.0. 0.57735027 0. 0. 0. ]] ['beijing' 'east' 'in' 'love' 'rises' 'sun' 'the' 'tiananmen' '北京' '天安门''太阳升']