《CLIP改进工作串讲》论文精读笔记
前言:
参考视频:CLIP 改进工作串讲(上)【论文精读·42】_哔哩哔哩_bilibili
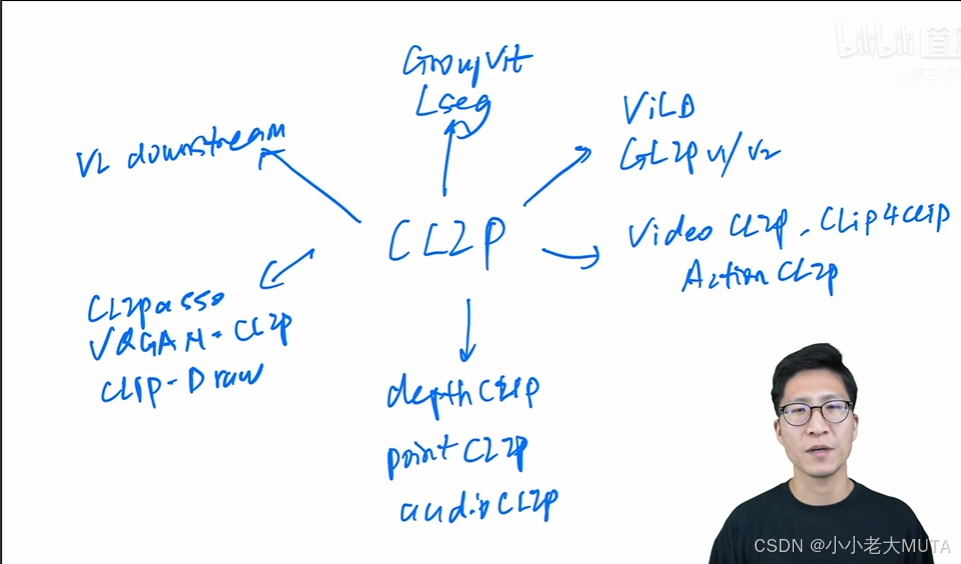
分割-Lseg《LANGUAGE-DRIVEN SEMANTIC SEGMENTATION》
论文链接:arxiv.org/pdf/2201.03546
分割其实可以理解为分类任务,把图片级别的分类变成了对像素级的分类。
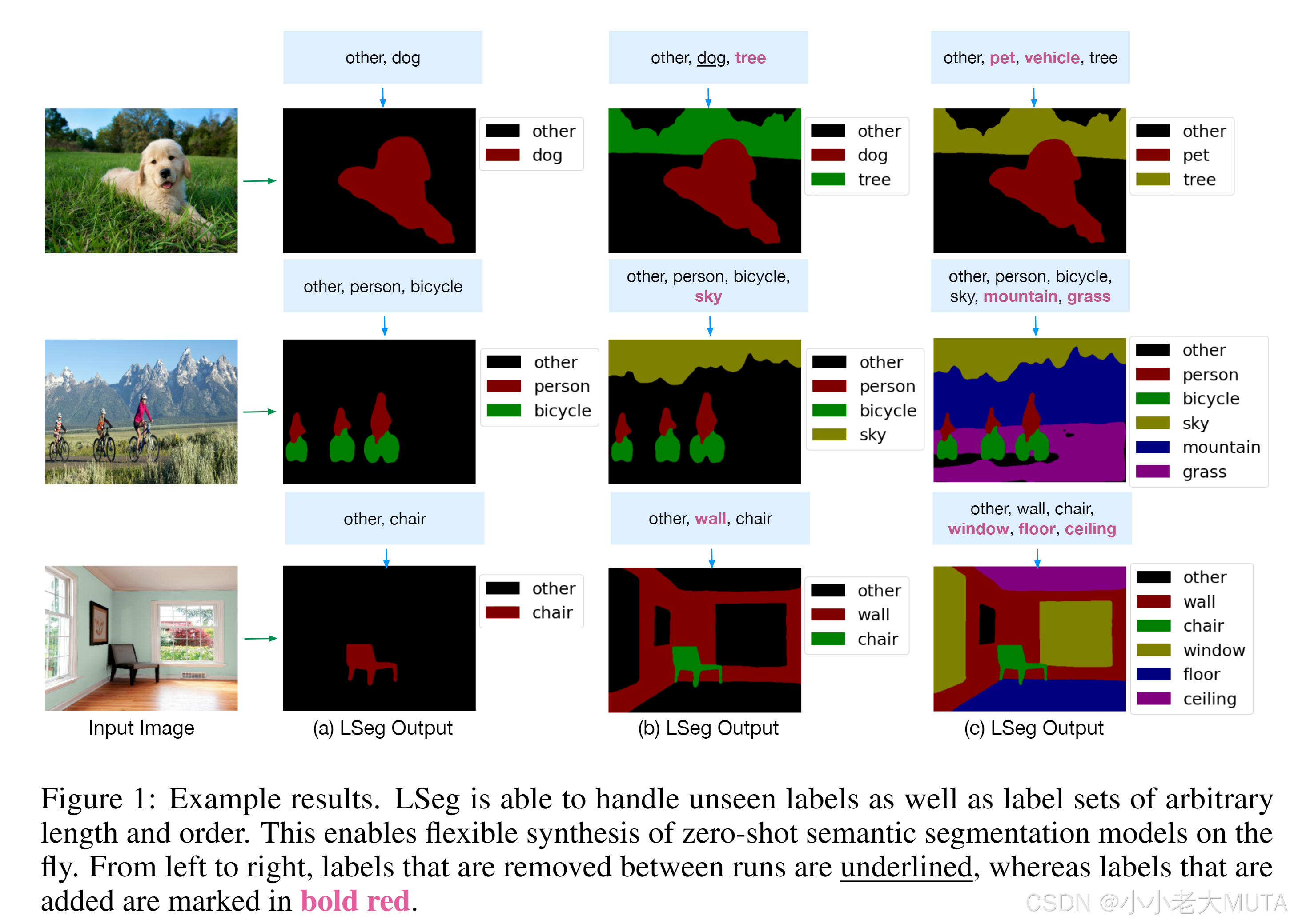
效果
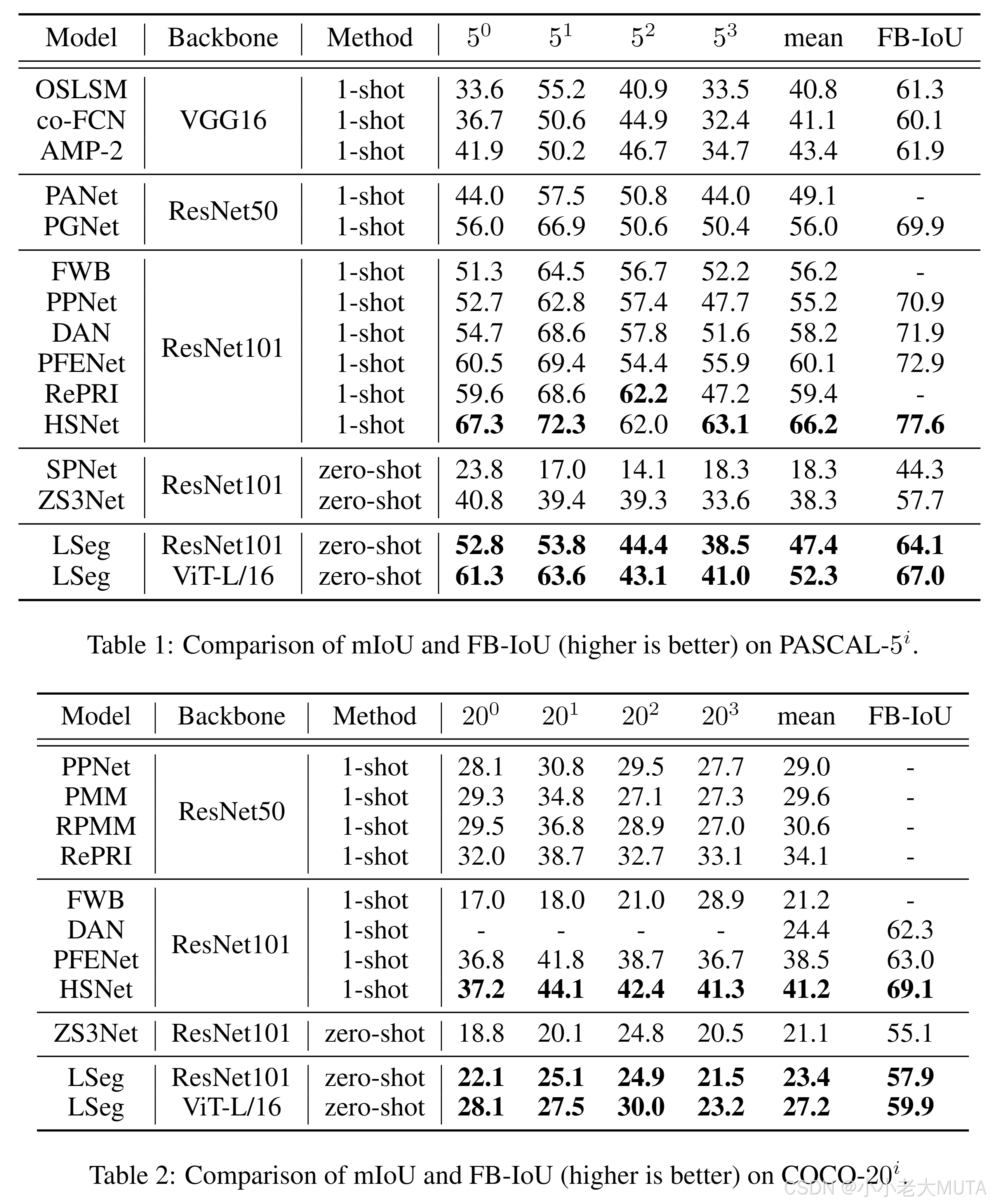
模型
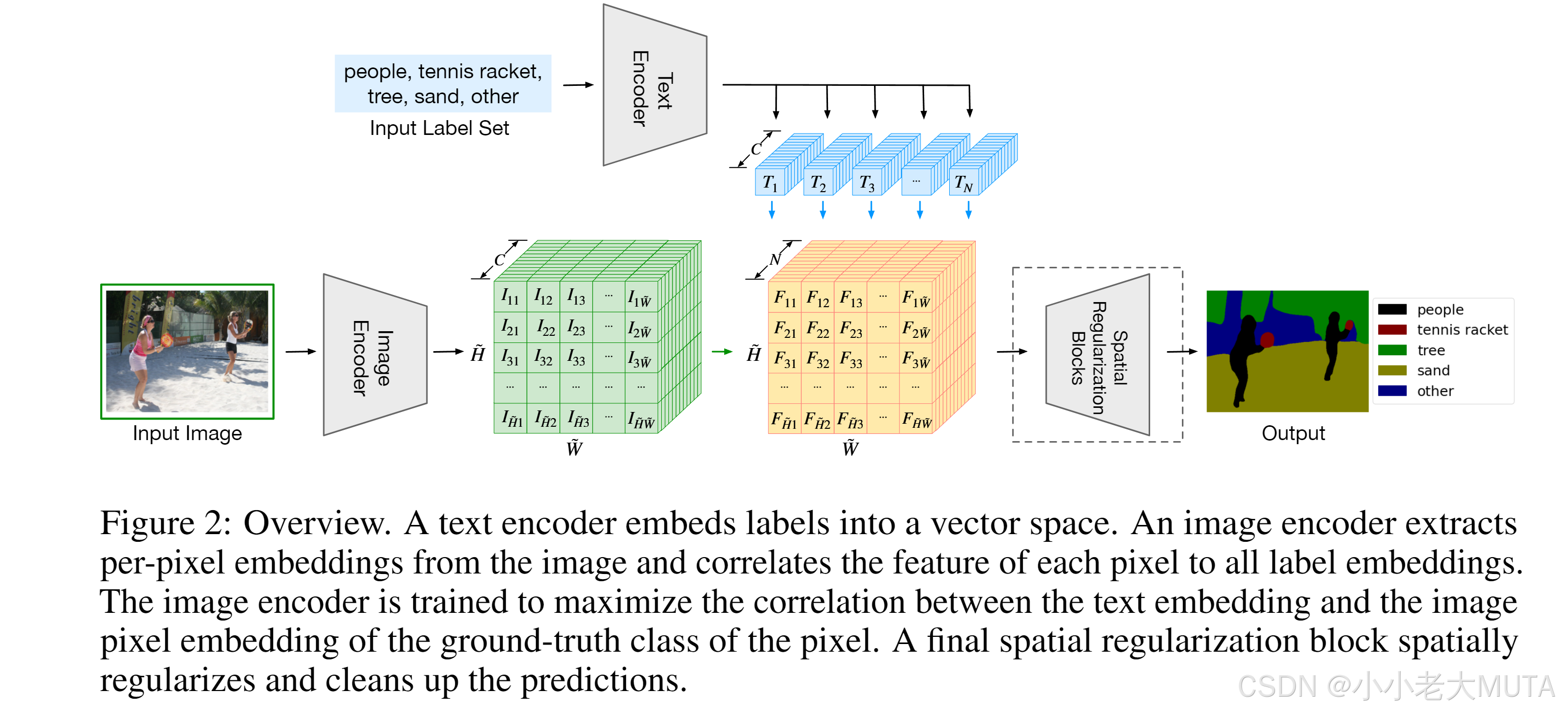
去除掉上面的文本分支,会发现和传统的有监督语义分割没有任何区别。
图片进入分割模型---> 特征图---> upsampling(因为是密集任务,要和原来图像的大小一样) ---> 模型输出和GT做cross entropy loss。
这里的分割模型是DPT结构,vision transformer + decoder,docoder作用就是讲bottlneck得到的feature upscale放大,类似PSP,ASPP这种。
原图 H*W*3 经过Image Encoder ---> (尺度比原图小);
文本数据集中有n个标签,经过Text Encoder--->n个文本特征 N*C;
疑惑:代码这部分N的大小?标签个数不同N怎么定义大小?训练的N统一尺寸吗?
两个特征相乘 ×
=
。
融合后的特征经过Spatial Regularization Block(一些conv)多理解一下文本和视觉的交互。
N就是标签也就是类别个数,这里得到的就和传统监督学习得到的特征尺寸相似,然后和GT做损失计算。
实验
是有监督的训练,在7个分割数据集上训练出来的,是有Ground Truth MASK的,对比的zero-shot实验。
但是文本的Text Encoder就是用的CLIP的Text Encoder,参数完全没有改动,包括训练也是冻结的。因为7个分割数据集还是小。
图形部分的Image Encoer,使用的ViT,作者使用了CLIP中的vit权重和原始ViT和DIT的权重,最后发现加载原始ViT 和DIT的效果更好。但是作者没有解释这部分。
关于Spatial Regularization Block,作者做了消融实验,发现加到第四个block性能就崩了,但没有解释。
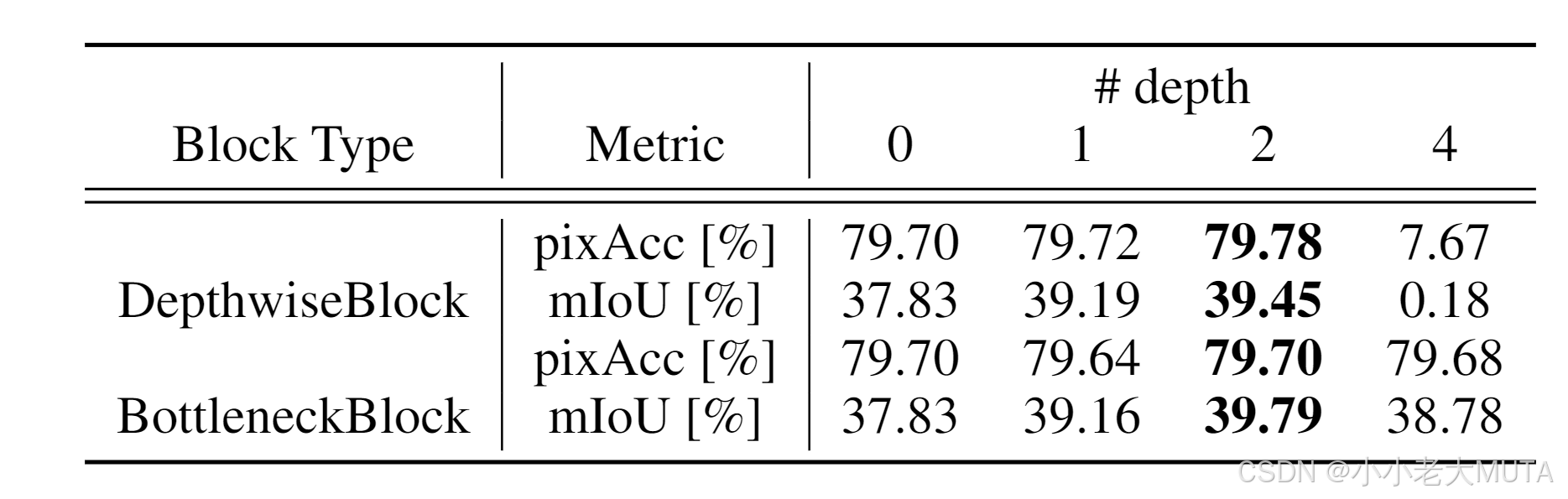
数据集和评价指标:
选用的PASCAL,COCO,FSS-1000的数据集。按照类别分成了四份,训练用其中的四分之一。
例如,PASCAL原本有20个类,这里只用了其中五个类别做训练。
这样就能做zero-shot了。

效果:
LSeg和其他zero-shot模型比较还是有提升,但是和有监督的训练效果区别不大,尤其是LSeg用的ViT-L比ResNet大很多。
总结
将文本部分加入到传统的有监督分割模型的pipeline中,通过图文的融合,模型训练的时候能够学到一些language aware的视觉特征,使得推理的时候能用文本的prompt得到想要的分割效果。
但是,LSeg虽然用了CLIP的预训练参数,但终究目标函数不是对比学习,也不是无监督的训练,并没有把文本当作监督信号来使用,所以其实还是依赖于手工标注的segametation mask。
分割—《GroupViT: Semantic Segmentation Emerges from Text Supervision》
论文链接:arxiv.org/pdf/2202.11094
GroupViT 监督信号来自于文本,不依赖于Segmentation mask的这种手工标注,可以像CLIP那样就利用图像文本对进行无监督的训练。
模型
Group:
无监督分割经常用一类方法叫做grouping,如果有一些聚类的那个中心点,从这个点开始发散,然后把附近周围相似的点逐渐扩充成一个group,这个group就相当于segametation mask,是一种自下而上的方式。
作者提出了一个Grouping Block,还有一些Group Tokens(彩色的g_i),主要的目的就是想让这个模型在初始学习的时候就能慢慢的一点一点的把这个相邻相近的像素点都慢慢的Group起来,变成一个又一个的这个Segmentation mask。
在模型浅层的时候,学到的这些group token效果不是很好,各种五颜六色的颜色块,但经过学习分割效果越来越好。
group ViT的贡献:在一个已有的ViT的框架之中,加入了grouping block,同时加入了可学习的group tokens。
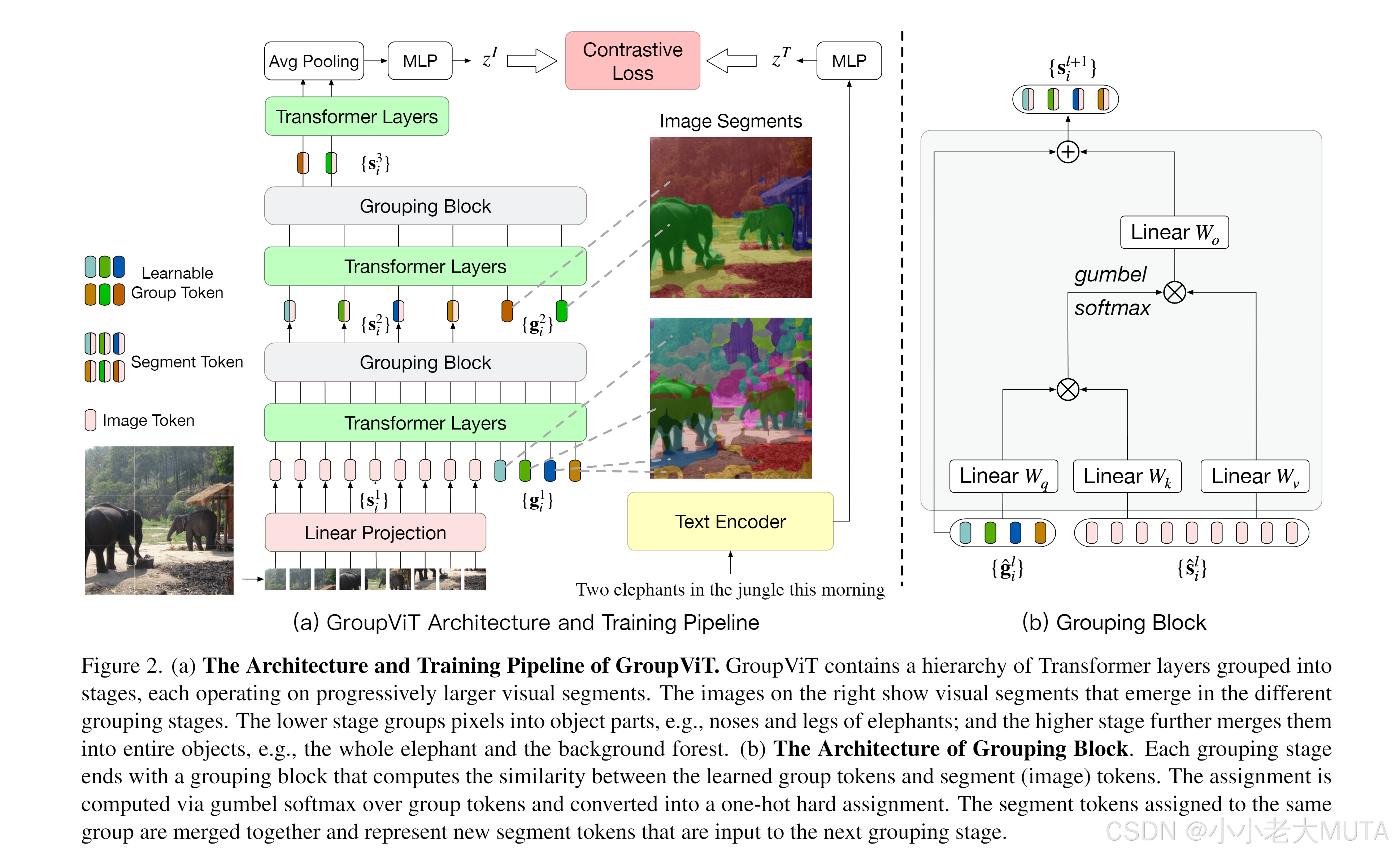
图像编码器:
Vision Transformer 从头到尾是12层,输入是两部分,patch embedding + group token。
这里ViT用的small,维度是384,即图片patch embedding后的维度是 196 * 384。
group token 是 64 * 384,64是初始的聚类中心。
patch 和 group token直接做拼接,(196+64)*384。
通过Transformer Layer 的自注意力机制,去学习图像的哪些patch属于哪个group token。
经过几层的Transformer Layer(这里是6层),作者尝试聚类一下,合并成更大的Group,利用Grouping Block,把patching embedding直接assign 对齐到这64个group token上,相当于做一次聚类分配。得到64个聚类中心,也就是64 * 384,这样也把序列长度给降低了,使得模型计算复杂度,训练时间降低。
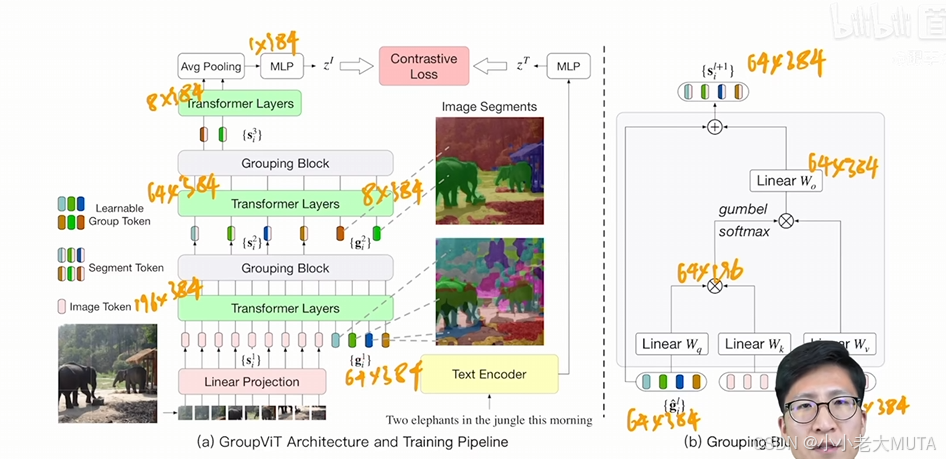
第一个Grouping Block:
grouping block类似于自注意力,先算了一个相似度矩阵,然后用这个相似的矩阵去帮助原来的这个image token做一些聚类中心的分配,从而完成了把这个输入从196*384 降维到64*384的过程。
因为做聚类中心分类是不可导的?????所以作者这里用了一个trick,用Gumbel softmax从而把这个过程呢变成可导的,这样整个模型就可以端到端的进行训练。
(因为硬聚类是离散操作,没有办法通过梯度下降学习(类似0-1的阶跃函数)?????)
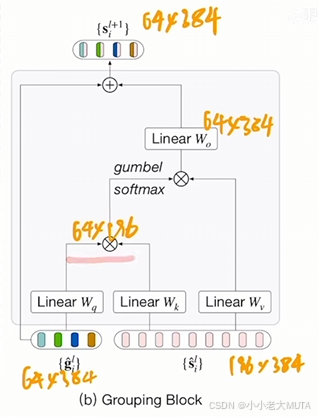
第二个Grouping Block:
因为一般的而数据集种类不太多,所以作者希望把这64个聚类中心再合并。所以再第一个Grouping Block输出后又加了8 个Group Token,经过三层Transformer Layer,再次映射到8个聚类中心上,然后经过Grouping Block。
Image 和 TXT 的交互:
和CLIP类似,都是通过图像文本对计算对比学习的loss从而训练整个网络。由于Image Encoder得到的是8*384,即八个图像块的特征,需要拟合成一个全图的特征才能和文本做匹配。
所以使用了一个Average Pooling将8*384 ---> 1* 384,后面就是和CLIP一样的操作了。
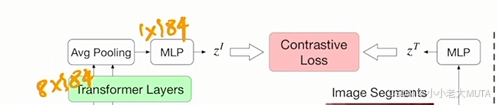
推理
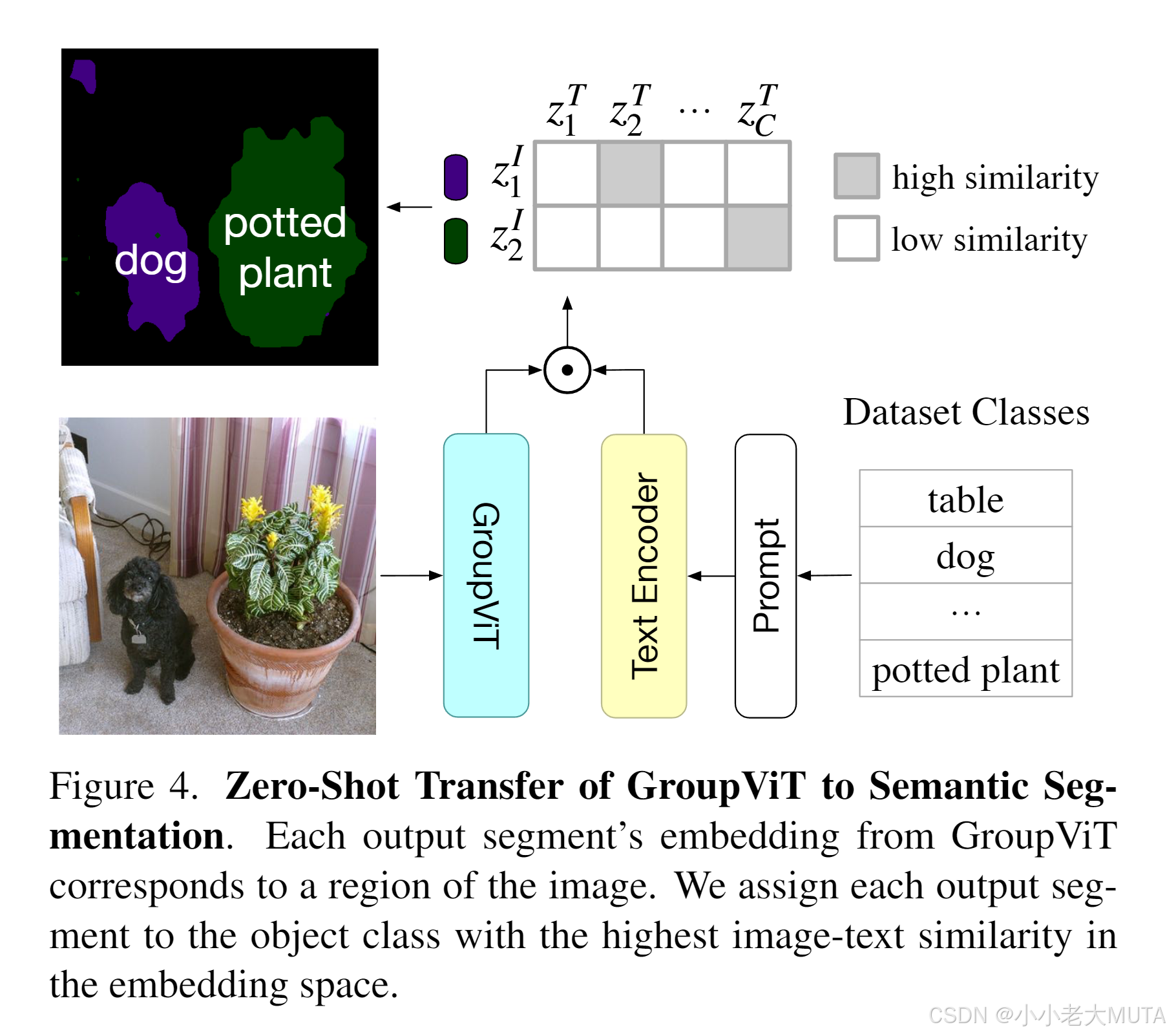
zero-shot推理:
给定一张图片,经过Group VIT得到八个group embedding;
再把可能的标签铜鼓哦文本编码器得到一些文本特征;
计算图像的Group Embedding 和 文本特征的相似度--->得到最终每个group embedding对应的class。
局限性: 只能检测八个类别。
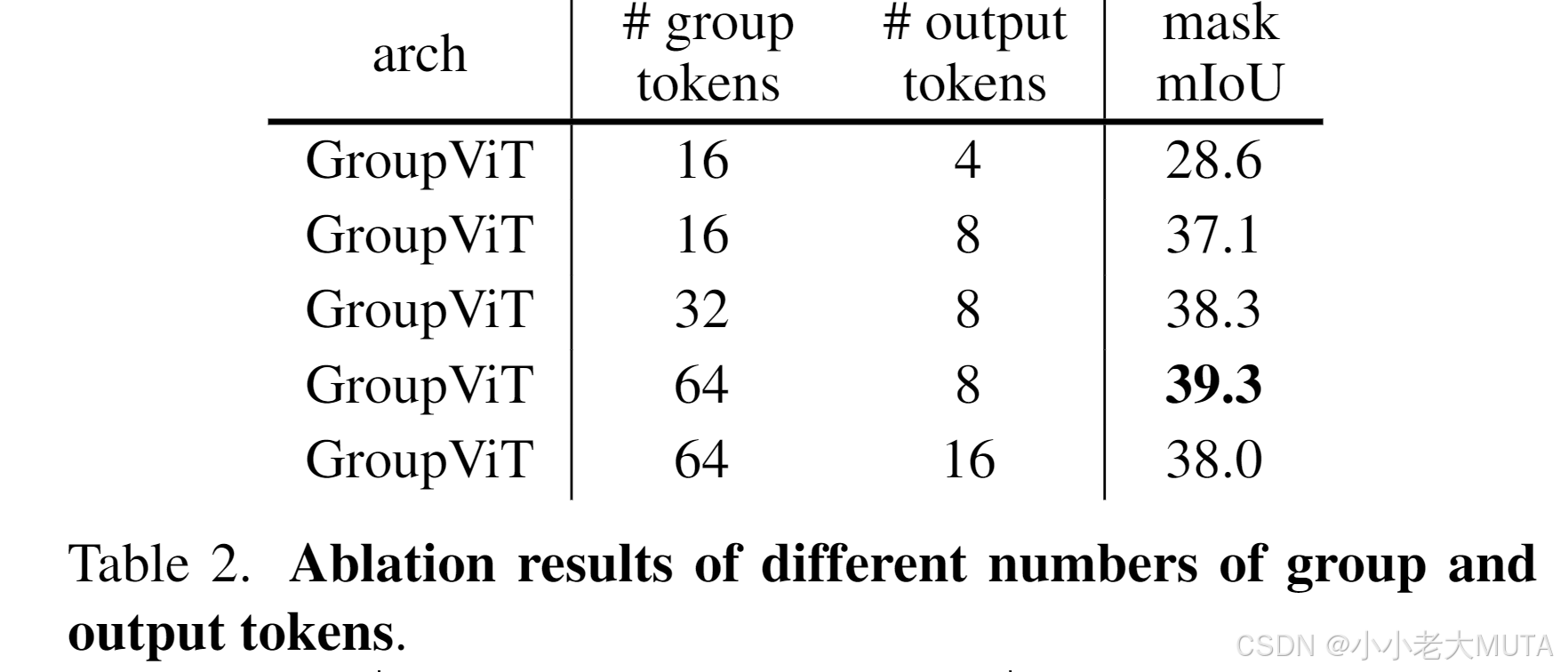
实验
用了不同个数的group token实验,最后发现是64,8的效果最好。
可视化:
从stage1 ---> stage2 ,聚类区域越来越大

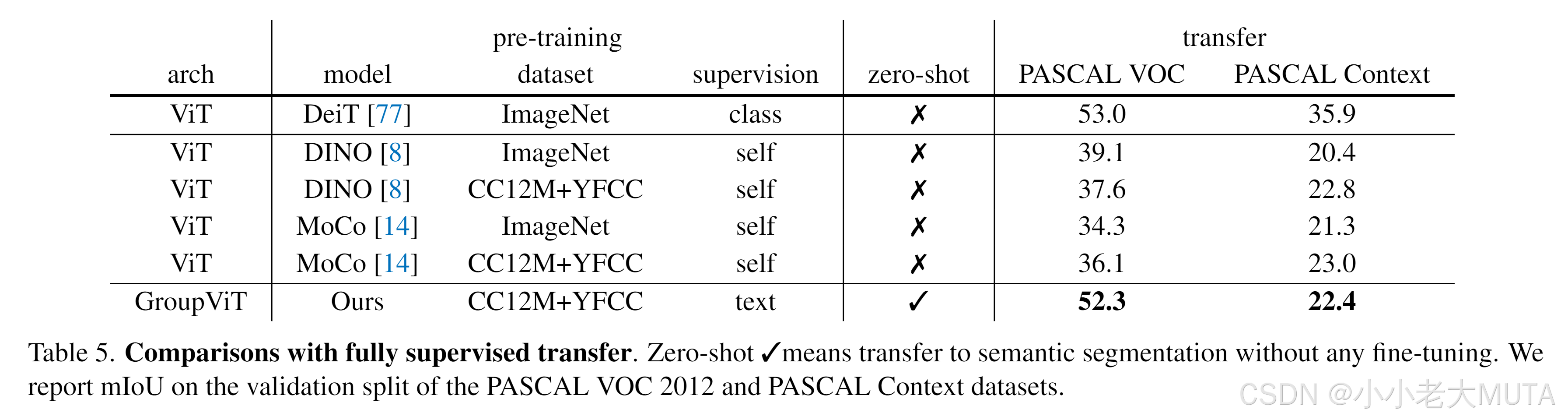
实验对比结果:
这里对比的有监督的算法还是基础算法,和有监督的sota比还是有很大的差距。
局限性和未来工作
1. 没有利用dense prediction的特性
分割中经常用的Dilated Convolution,Pyramid pooling或者U-Net结构,能够获取更多的上下文信息,更多的多尺度信息。Group ViT暂时没有考虑。
2. 背景和前景的区分
在Group ViT 的推理中,相似度计算以后,还需要设定一个阈值,提高前景类的分割性能,作者设置的0.9,即大于0.9的相似度才能被判断为前景,否则小于0.9,尽管,某个Group Token对应的文本相似度是最大相似度,还是会被判别为背景。
对于Pascal voc数据集来说,类别数少,有很明确的语义信息,不存在背景干扰,所以效果不错;
但对于Pascal context 和 coco数据集来说,类别很多,相似度就会比较低,导致很多被归为了背景类别。
所以阈值的设定很关键。
作者发现了这个问题并做了实验,证明Group Token的分割学的很好,只是最后的分类有问题。作者直接把预测出来的prediction mask 去和GT做对比,计算IOU,把GT的label直接给prediction mask当作标签,这样看结果就有了明显的提升。

目标检测—ViLD《OPEN-VOCABULARY OBJECT DETECTION VIA
VISION AND LANGUAGE KNOWLEDGE DISTILLATION》
引言
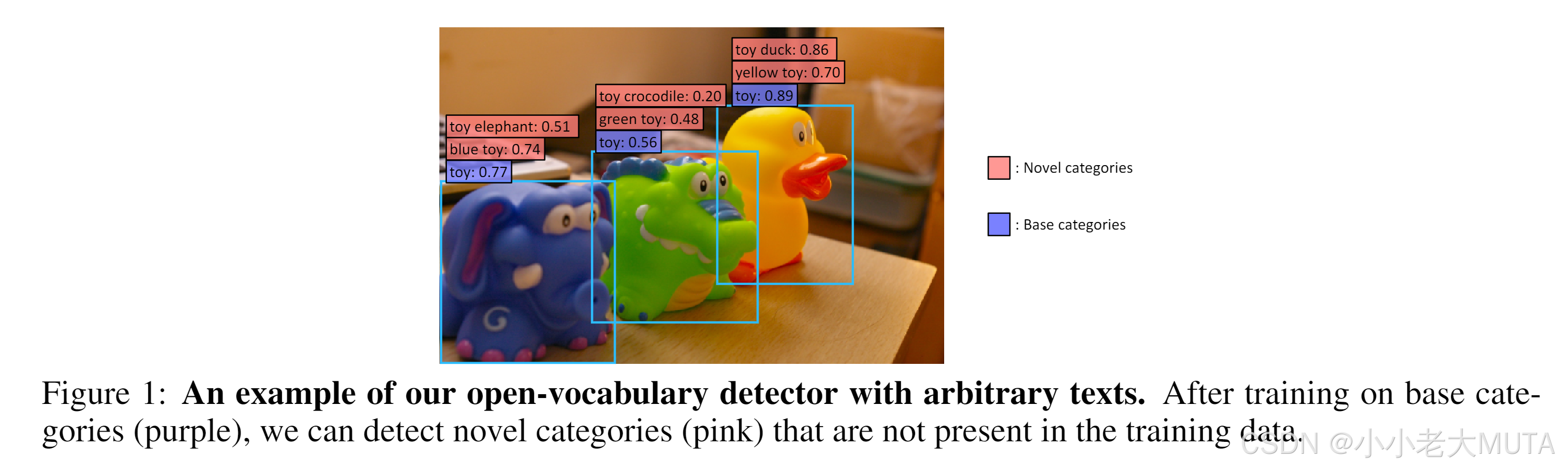
指出问题,现在的标注类别都是基础类,对应图中的蓝色base categories。但是作者想要不去额外标注这些玩具类别,直接检测物体能力novel categories,即虽然都是玩具,分别检测出蓝色大象,黄色鸭子,绿色鳄鱼等。
模型
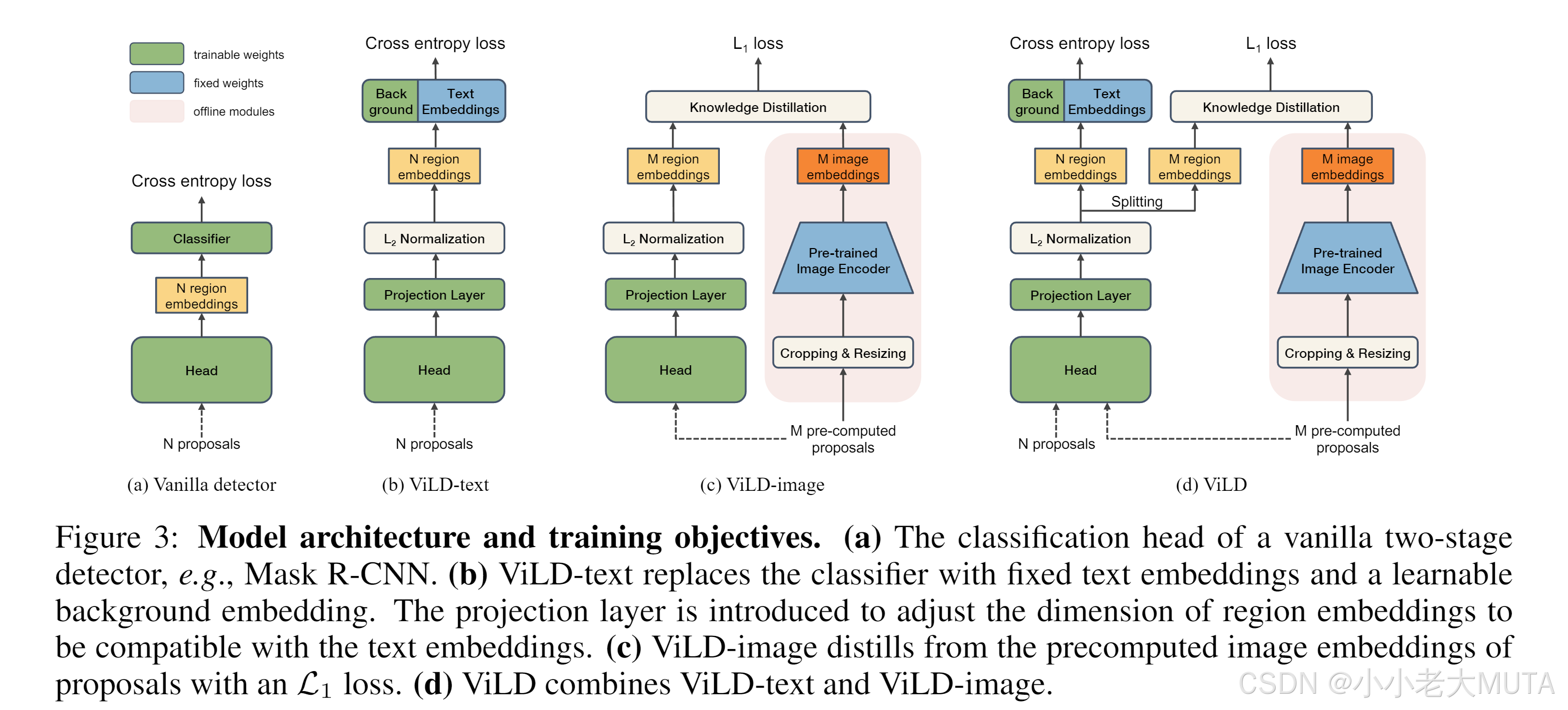
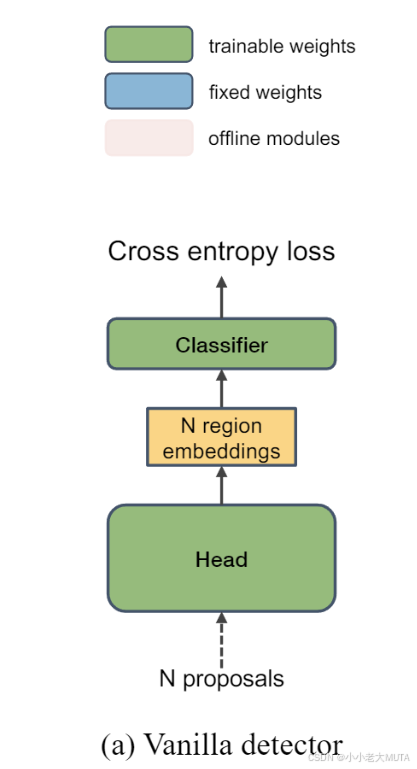
a)基础目标检测器
baseline 就是mask rcnn,两阶段分类器:
第一阶段出一些region proposal,这里提取出N个region proposal;
然后经过detection head,得到region embedding;
最后经过分类头,判断抽取出来的bbox是什么类别。
目标函数分两部分:一个是怎么定位,另一个是分类。
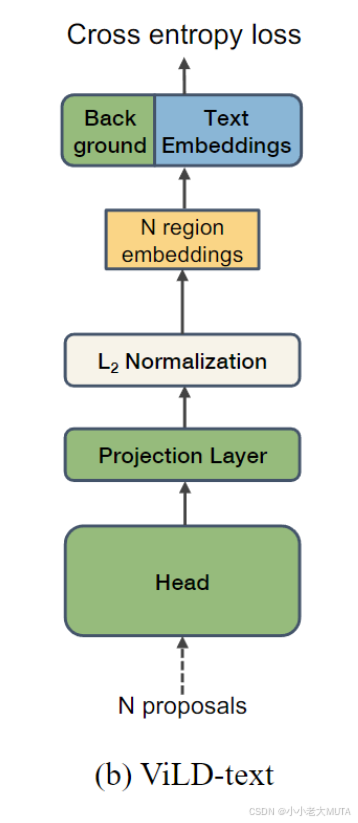
b) ViLD-text
前面的图像检测都不变,在提取出图像的N个region embedding以后,对类别做embedding。
具体操作:把物体类别拿过来,然后给一些prompt生成一个句子,把这个句子传入文本编码器得到text embedding。这里的Text Embedding是蓝色的,即模型参数是锁住的,不参与预训练。
注意这个类别还是基础类,还是有监督的学习,也就是说图像和文本都是做的有监督训练,这个阶段只是把两个模态特征联系到一起。而不在基础类的类别,就全部分类给了Back Ground,专门设计了一个背景embedding。具体计算背景embedding 和 text embedding一样,都是直接和图像的embedding做点乘计算相似度。
I 是图像,
就是抽取图像特征;
r是提前知道的proposal,也就是抽取出来的bounding box candidate候选框;
R 就是额外层的计算,得到的e_r就是region embedding;
定义了e_bg background embedding;
t1,t2,...,t|C_B|,也就是多少C_B个类别的text embedding:
然后e_r 分别和e_bg 和 t 做点乘,相似度计算;
最后得到的z(r)就是类似logits的东西;
然后将z(r)做softmax,就能和GT做cross entropy loss。
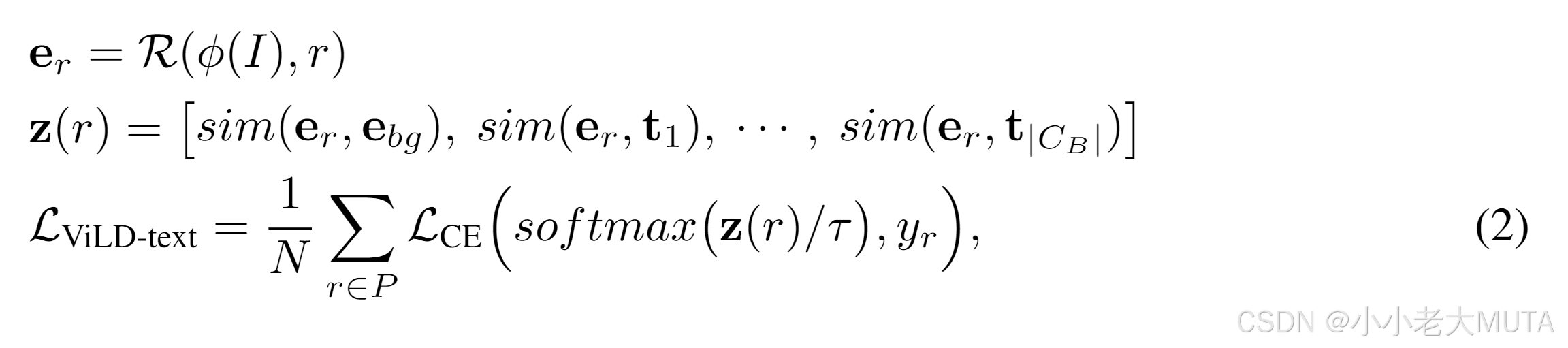
c) ViLD-image
《CLIPasso: Semantically-Aware Object Sketching》
论文链接:arxiv.org/pdf/2202.05822
待更