Python与Spark
1.什么是Spark
Spark用于对海量数据进行分布式计算
pyspark是利用Python语言完成Spark任务的第三方包
2.安装pyspark
打开命令行,输入【pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark】
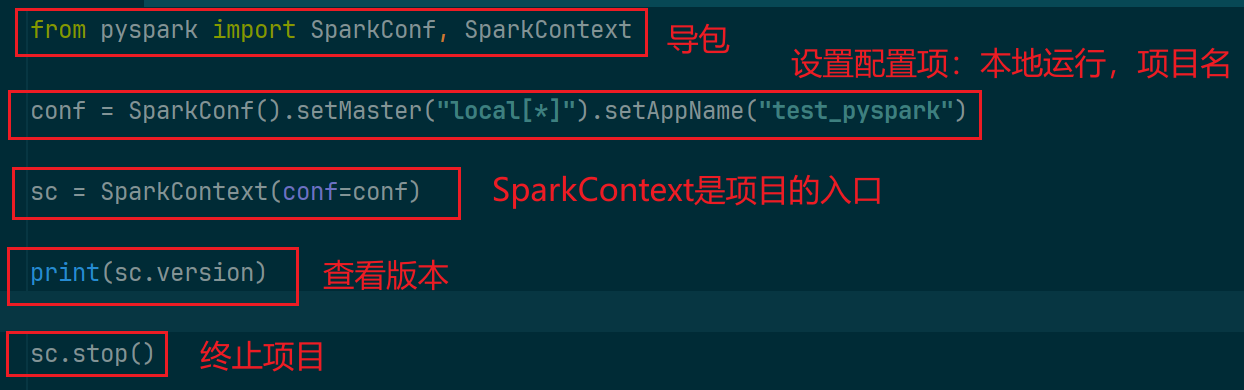
3.pyspark入门
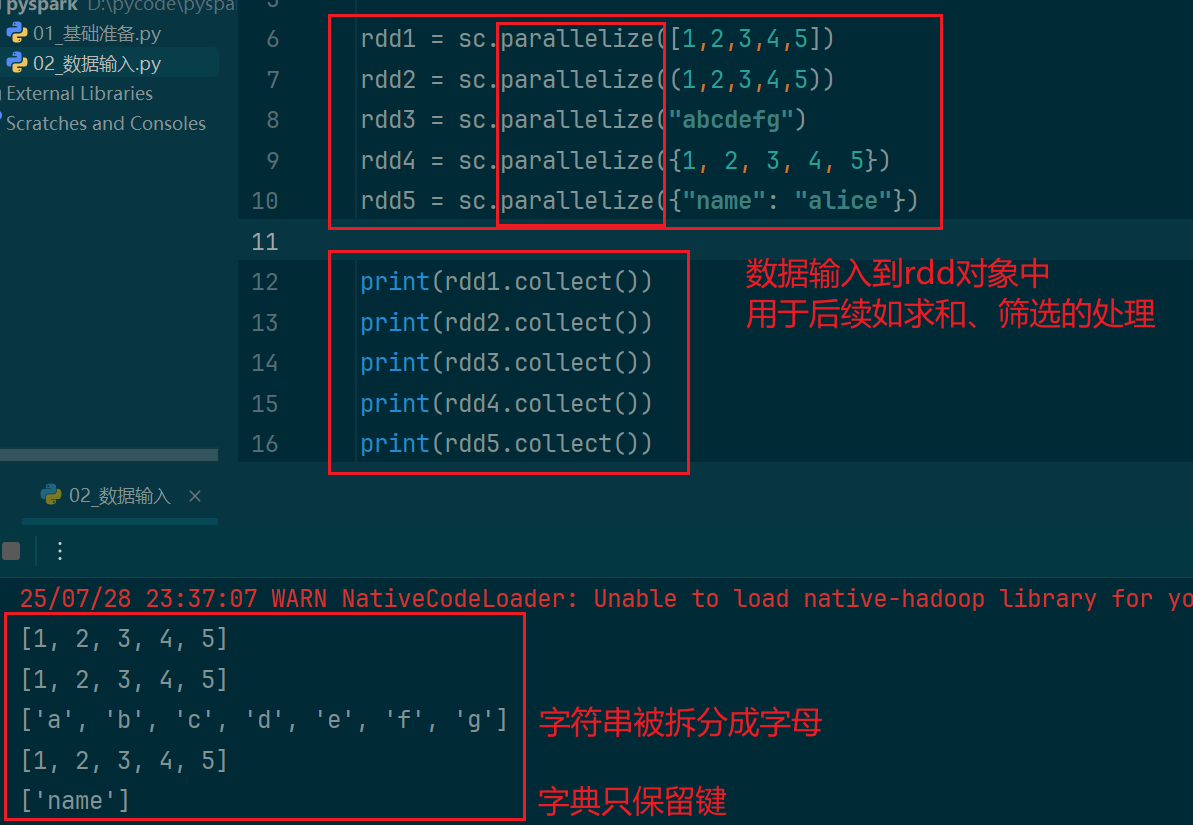
4. pyspark输入数据
(1)输入数据容器
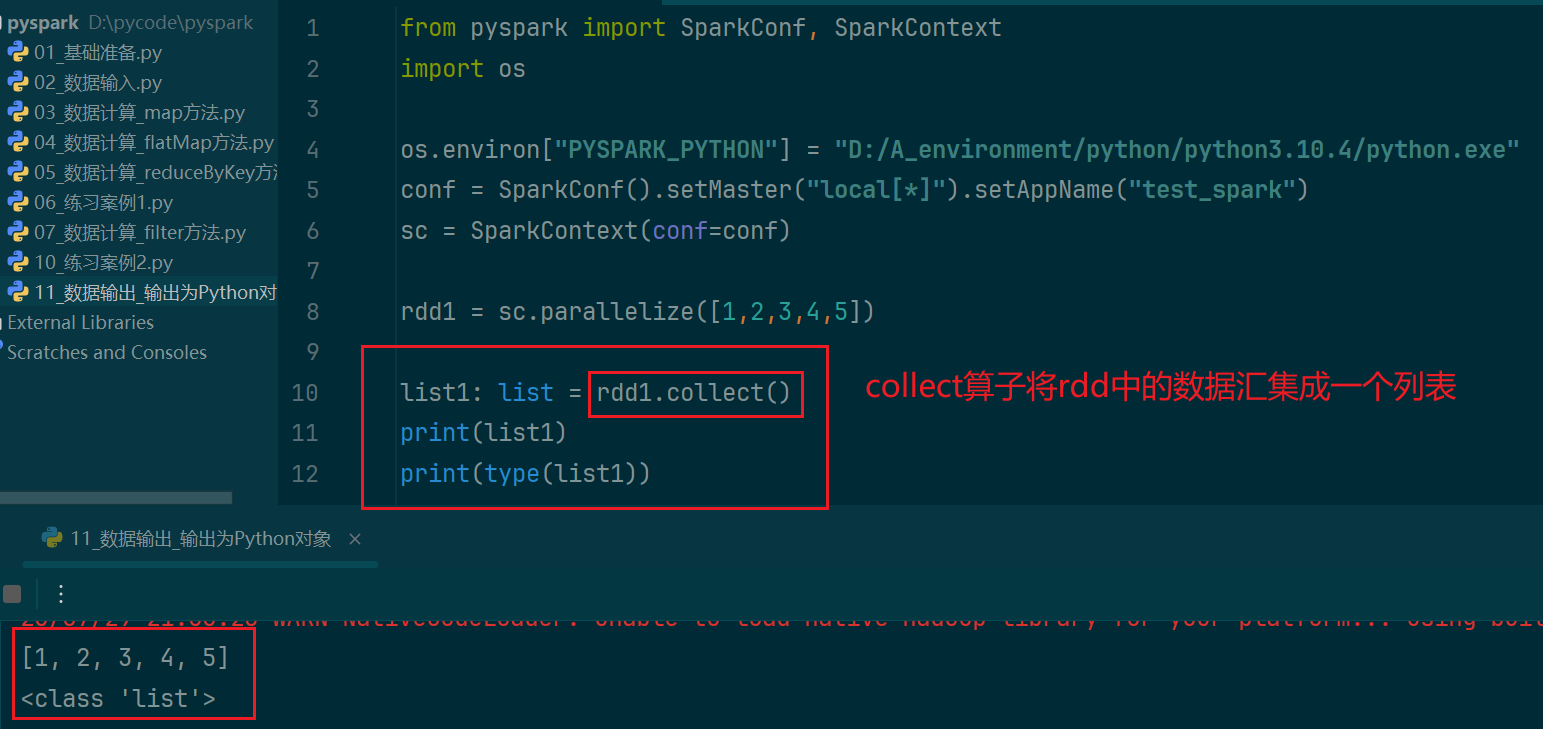
查看rdd中的内容,用collect()方法
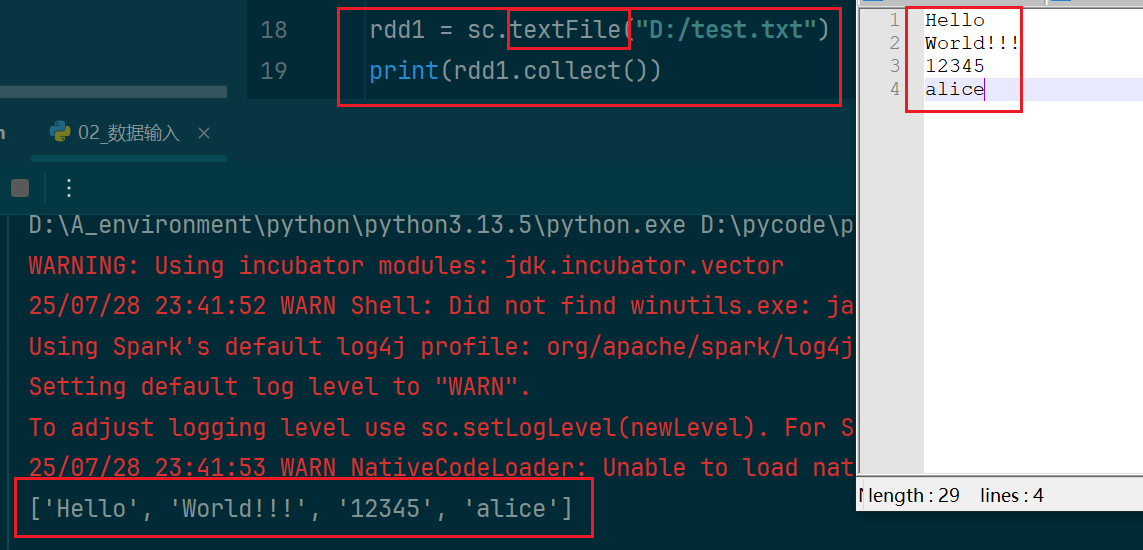
(2)输入文件
5.pyspark处理数据
(1)map成员方法(算子)
map方法用于逐个处理rdd中的数据
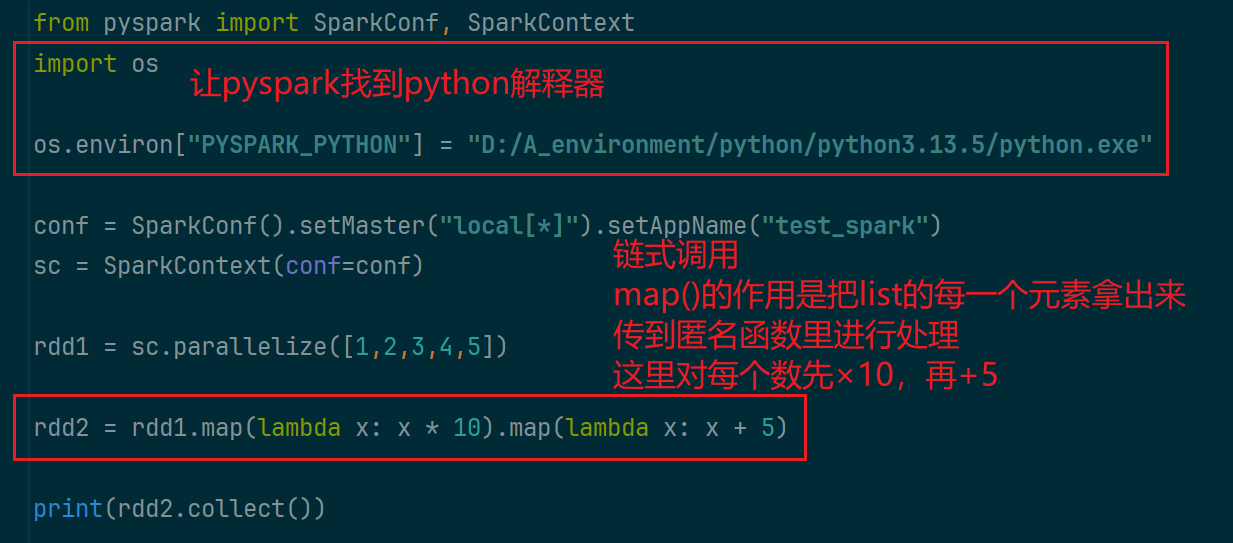
(2)flatmap算子
在map的基础上,多了解除嵌套的功能
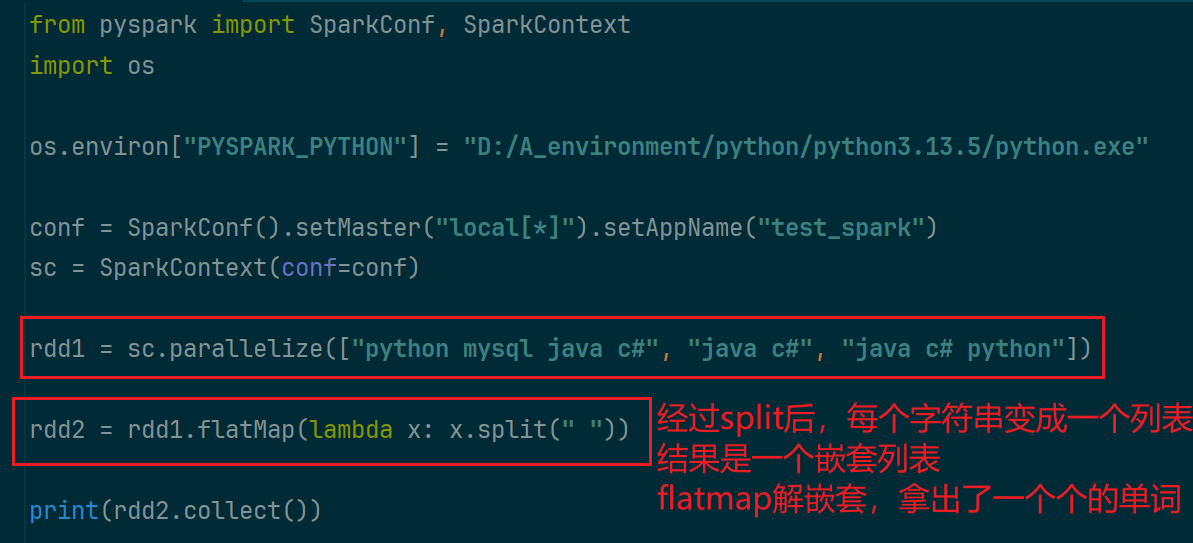
(3)reduceByKey算子
对二元元组按照key分组聚合后 ,对每个组内的元素两两进行处理
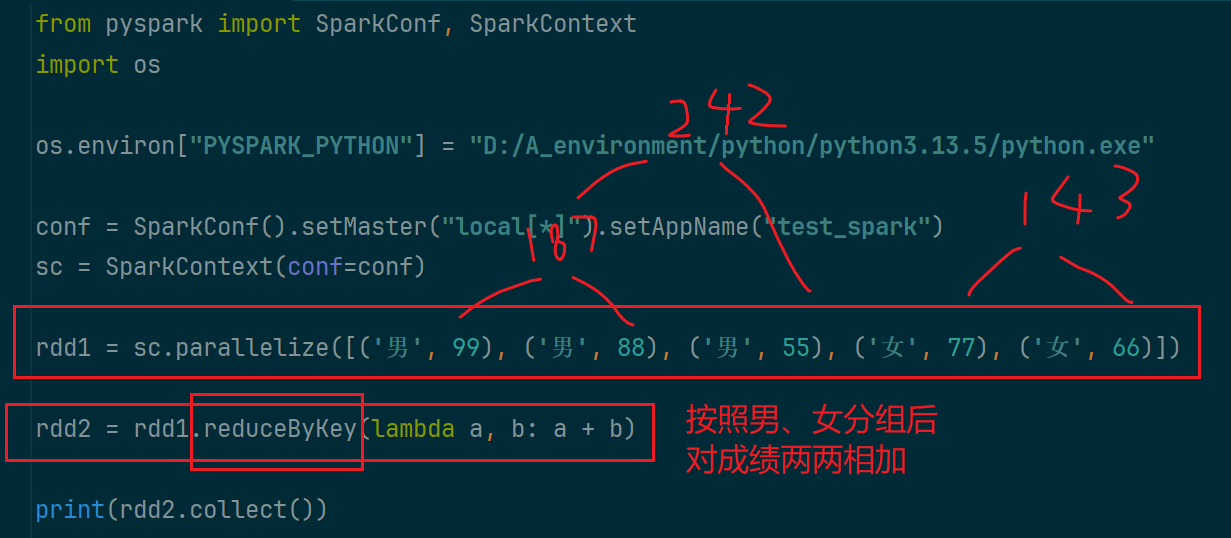
(4)filter算子
过滤元素,只保留满足条件的
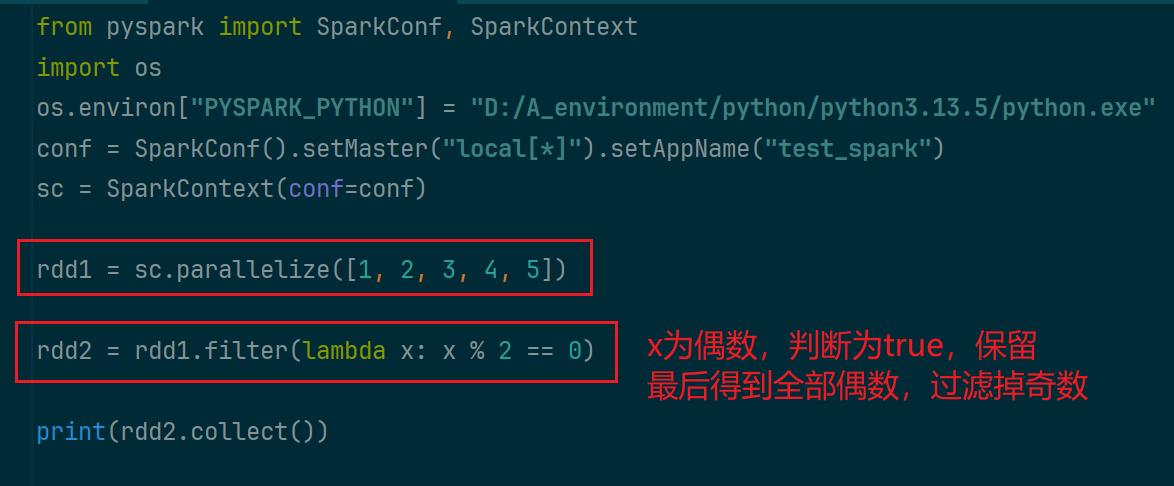
(5)distinct算子
对rdd中的数据去重
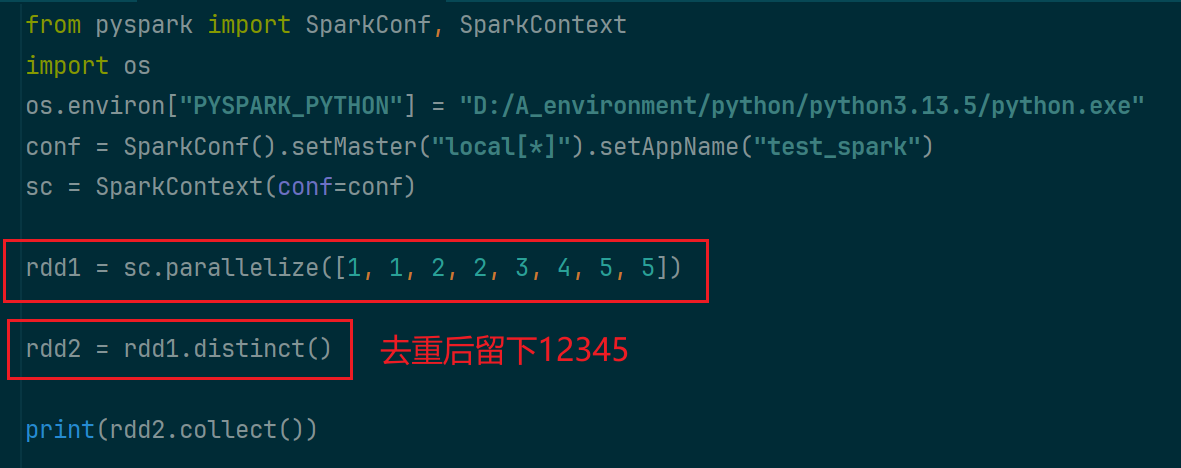
(6)sortBy算子
按照什么样的规则进行排序
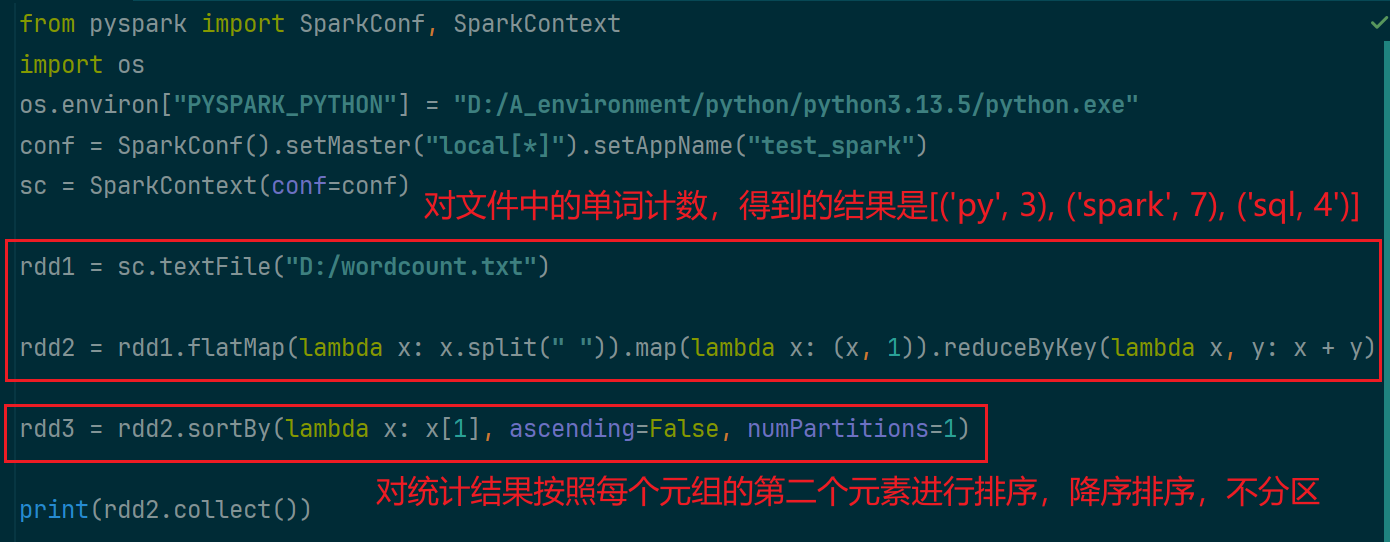
6. pyspark输出数据为Python对象
(1)collect算子
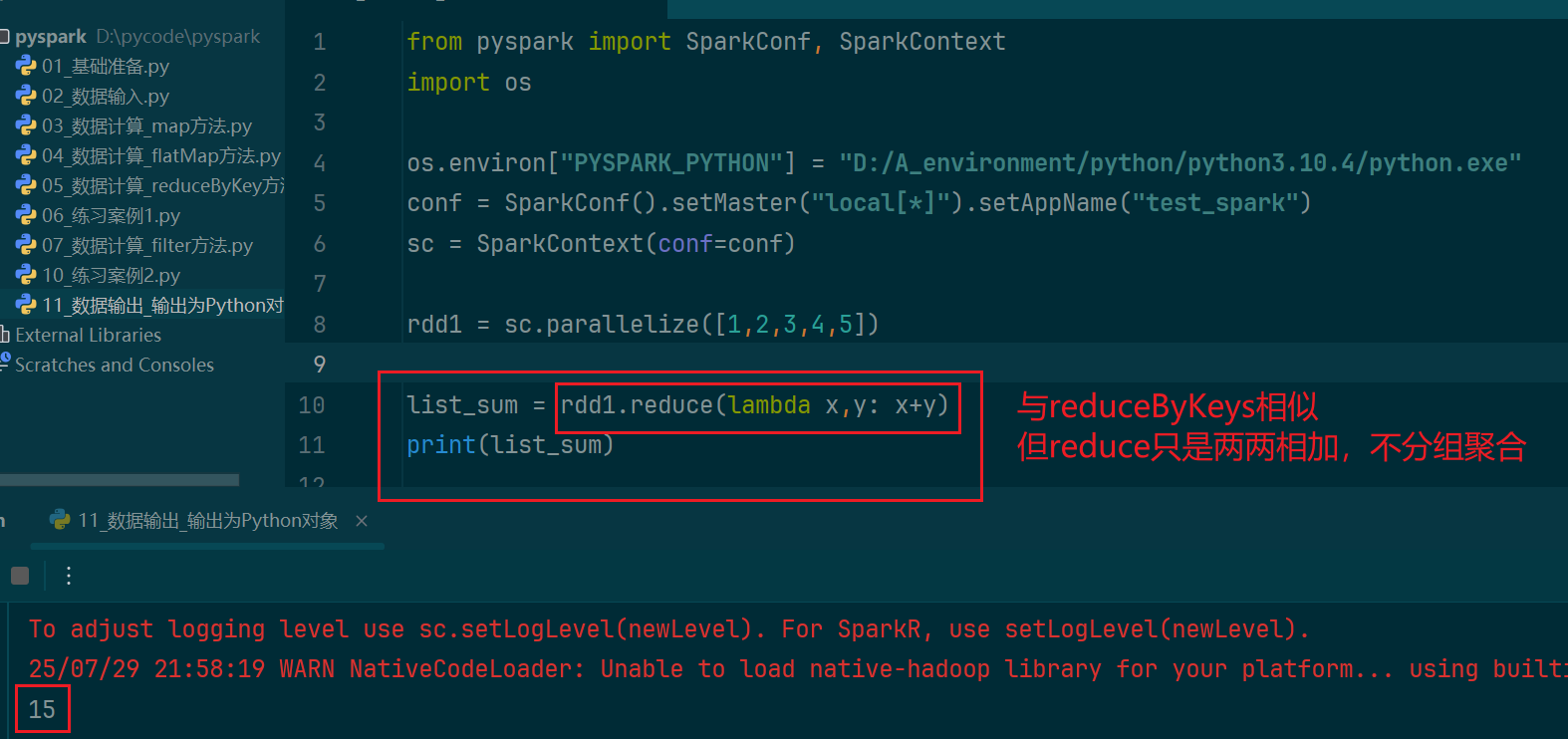
(2)reduce算子
(3)take算子
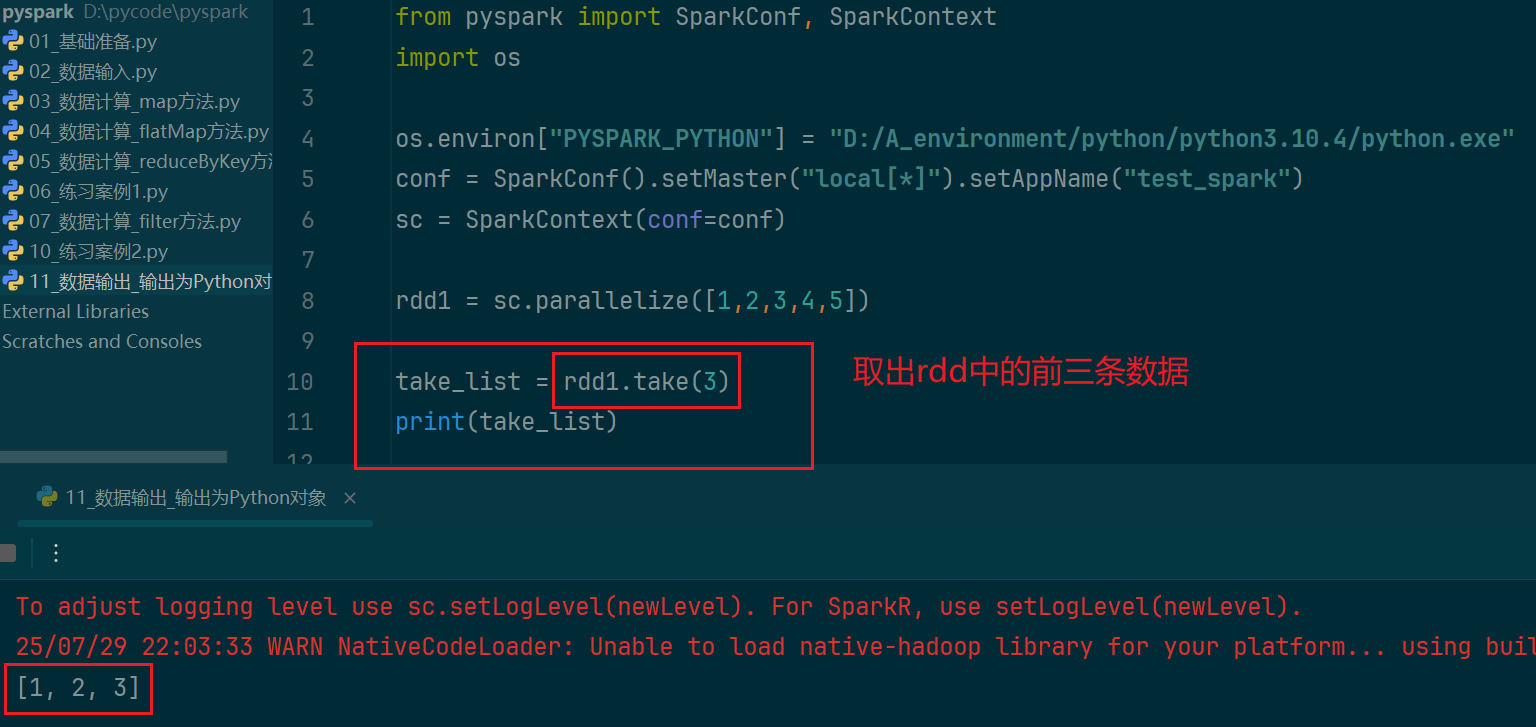
(4)count算子
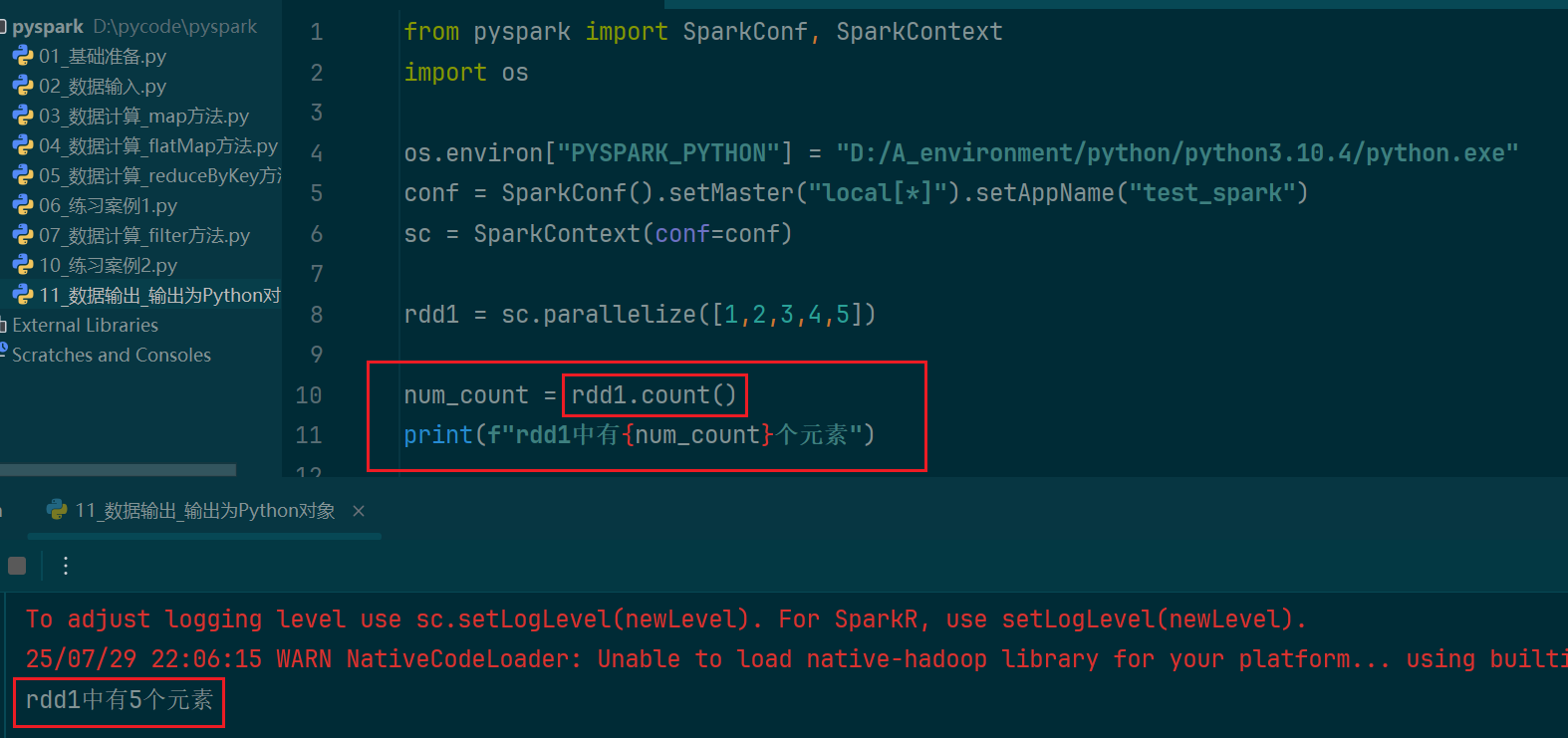
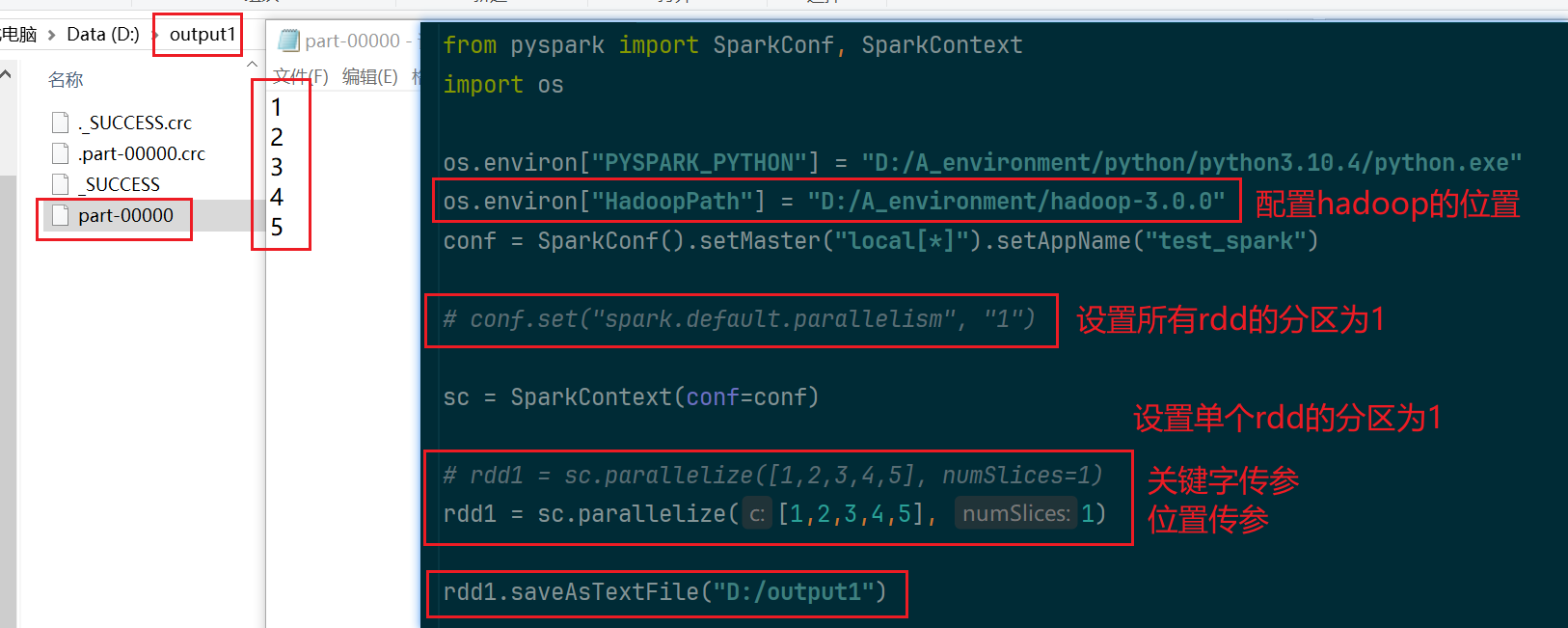
7.pyspark输出数据到文件中
saveAsTextFile算子