【数学建模论文学习笔记】基于历史数据的蔬菜类商品定价与补货决策模型
本文内容大部分出自于基于历史数据的蔬菜类商品定价与补货决策模型--《数学建模及其应用》2024年02期,只修正了论文中的一些笔误,并在一些读者可能不容易理解的地方做了一些补充解释,如果觉得不错的话还请支持原作者。
这篇论文解答的题目是2023年高教社杯全国大学生数学建模竞赛的C题,题目内容如下:
问题一
研究对象为蔬菜各单品和品类的销售量,而附件2仅提供了三年内各单品蔬菜的销售流水数据,因此要先对该数据进行预处理。首先需要观察分析原始数据,检查是否有缺失值、异常值等,并进行相应的处理。其次,需要将附件1和附件2的表格进行匹配,对数据进行加总,分别获得各单品和各品类蔬菜的日销售量、周销售量等数据。之后,才能对蔬菜各单品、品类的销售分布和相互关系进行分析。
针对不同品类蔬菜的总体分布规律及相互关系,可以首先从总体的角度把握数据, 如进行假设检验、模拟拟合和可视化分析等操作;之后再从周销量、月销量和年销量的角度分别详细分析其分布规律及相关系数。
设各单品蔬菜的上四分位点、中位数、下四分位点为、
和
, 记四分位距
,该指标反映位于中间的50%的数据的离散程度。定义正常分布区间为:
超出该区间的视为异常值。
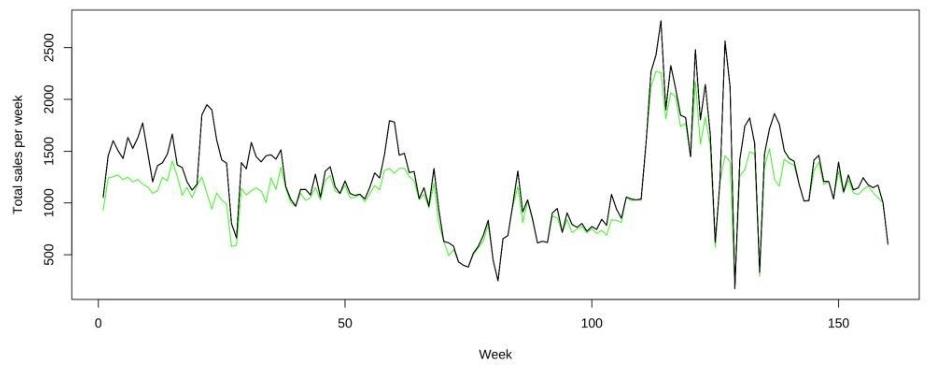
之后,求得去除异常值之后日销量的平均值,并用该平均值替换异常值,从而获得异常值处理之后的单品蔬菜日销量数据。可以从花叶类蔬菜周销量随时间变化的图中, 看出替换异常值前后的效果变化。如下图所示,用黑色线条来描绘替换异常值之前的数 据,用绿色线条来描绘替换异常值之后的数据。可以发现替换异常值之后,周销量数据明显变得更加平滑。
K-S检验
使用K-S检验的方法分别检验各蔬菜品类两两之间的销量是否属于同一分布。本节从日销量和月销量的角度,分析了各品类蔬菜销量分布之间的关系。首先,将各蔬菜品类每日的销售流水加总,获得各蔬菜品类每日的销售总量,之后分别两两组合进行K-S 检验,共进行15次检验。
检验步骤如下(以花叶类蔬菜与水生根茎类蔬菜的日销量分布为例):
Step1)提出假设
原假设:花叶类蔬菜与水生根茎类蔬菜的日销量样本来自于同一分布。
被择假设:花叶类蔬菜与水生根茎类蔬菜的日销量样本来自于不同分布。
Step2)构造检验统计量
其中, 和
分别为花叶类蔬菜日销量和水生根茎类蔬菜日销量的经验分布函数。经验分布函数的定义为:
Step3)计算并分析结果
通过R语言代码,得到以下结果:
 如图所示,K-S 检验的p-value小于0.001,因此有充足的把握拒绝原假设
如图所示,K-S 检验的p-value小于0.001,因此有充足的把握拒绝原假设:花叶类蔬菜与水生根茎类蔬菜的日销量样本来自于同一分布。
关于p-value的更多介绍可以参考以下链接:
对于p值(p-value)和显著性水平的理解 - 知乎
p值-p_value计算方法 - 知乎