OpenCv中的 KNN 算法实现手写数字的识别
目录
一.案例:手写数字的识别
1.安装opencv-python库
2.将大图分割成100×50个小图,每份对应一个手写数字样品
3.训练集和测试集
4.为训练集和测试集准备结果标签
5.模型训练与预测
6.计算准确率
7.完整代码实现
一.案例:手写数字的识别
现有一张2000×1000像素的手写数字照片digits.png作为数据集,如下共有100列50行,由此我们可以计算出一个手写数字的大小是20×20像素

1.安装opencv-python库
安装opencv-python库指令(可以根据自己的需要指定版本)如下:
pip install opencv-python==3.4.11.45 -i Https://pypi.tuna.tsinghua.edu.cn/simple上面的digits.png图片是彩色图像,由RGB三个通道叠加而成,所以它的本质是三维矩阵
我们需要利用opencv-python这个库的imread()方法来读取图片数据
然后用cv2.cvtColor(img,COLOR_BGR2GRAY)将其转换为灰度图,灰度图仅保留亮度信息转化为二维矩阵,无彩色通道数据更简化
import numpy as np
import cv2
img = cv2.imread('digits.png')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)2.将大图分割成100×50个小图,每份对应一个手写数字样品
先利用numpy的vsplit()方法,将大图在垂直方向上分割成50行
再利用hsplit()方法把分割后的每一行在水平方向上切成100列
这样就得到了50×100个手写数字列表
cells = [ np.hsplit(row,100) for row in np.vsplit(gray,50)]再用numpy库的array()方法将列表转化成矩阵,提升处理效率
data = np.array(cells)
3.训练集和测试集
为了训练和测试的准确性我们将全部数据的前50列作为训练集,后50列作为测试集
train=data[:,:50]
test=data[:,50:]训练的数据都是一行数据代表一个样本,前面我们知道一个手写数字大小是20×20像素,所以我们可以将矩阵reshape为(-1,400)的样式,这样一行就是一个手写数字的400个特征,训练集和测试集各有2500行
数据类型也得从 uint8(0-255整数)转为 float32,以支持KNN算法中的距离计算(含小数)
train_new=train.reshape(-1,400).astype(np.float32)
test_new=test.reshape(-1,400).astype(np.float32)4.为训练集和测试集准备结果标签
用numpy库中的arange()方法,生成0到9的数字序列,由于测试集和训练集中每个数字都各有250个即他们的特征数据都各有250行,所以我们再用repeat()方法将数字序列重复250次
k=np.arange(0,10)
labels=np.repeat(k,250)再将标签labels通过np.newaxis 转为二维列向量(2500×1),与特征数据对齐
train_labels = labels[:,np.newaxis]
test_labels = labels[:,np.newaxis]5.模型训练与预测
优先使用OpenCV内置算法(如KNN)以减少依赖库数量,提升运行效率
使用OpenCV库的KNN算法:
通过 cv2.ml.KNearest_create()创建v模型,在通过train()方法传入训练数据(特征矩阵和标签),train()方法中的参数 cv2.ml.ROW_SAMPLE 表示指定每行为一个样本数据
knn = cv2.ml.KNearest_create()
knn.train(train_new,cv2.ml.ROW_SAMPLE,train_labels)
使用findNearest()方法完成对测试集的预测并指定K值
返回结果result中存放预测的结果
ret,result,neighbors,dist=knn.findNearest(test_new,k=3)6.计算准确率
由于OpenCV库的KNN算法中没有计算准确率的方法所以我们需要自己计算
通过result==test_labels,预测结果与标签相同则放回True反之返回False,最后返回一个只有True和False的序列
通过np.count_nonzero()方法来计算一共有多少个True
最后直接用True的个数除以总共的个数即为准确率
matches = result==test_labels
correct=np.count_nonzero(matches)
accuracy=correct*100.0/result.size
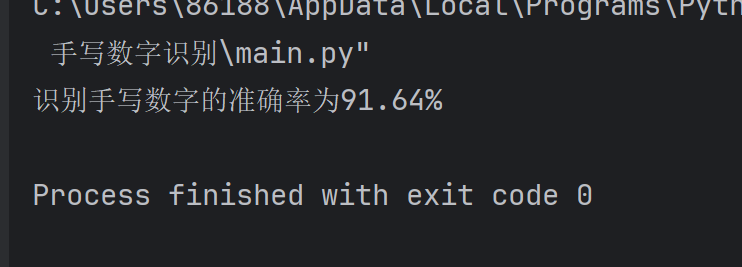
print("识别手写数字的准确率为{}%".format(accuracy))7.完整代码实现
import numpy as np
import cv2
img = cv2.imread('digits.png')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
cells = [ np.hsplit(row,100) for row in np.vsplit(gray,50)]
data = np.array(cells)train=data[:,:50]
test=data[:,50:]train_new=train.reshape(-1,400).astype(np.float32)
test_new=test.reshape(-1,400).astype(np.float32)k=np.arange(0,10)
labels=np.repeat(k,250)
train_labels = labels[:,np.newaxis]
test_labels = labels[:,np.newaxis]knn = cv2.ml.KNearest_create()
knn.train(train_new,cv2.ml.ROW_SAMPLE,train_labels)
ret,result,neighbors,dist=knn.findNearest(test_new,k=3)matches = result==test_labels
correct=np.count_nonzero(matches)
accuracy=correct*100.0/result.size
print("识别手写数字的准确率为{}%".format(accuracy))