科大讯飞运维 OceanBase 的实践
本文作者:李梦嘉,科大讯飞技术中心数据库方向负责人。10年以上DBA经验,对数据库的架构设计、优化、问题诊断、故障处理、数据恢复等有深刻地理解和实战经验。推动了科大讯飞数据库标准化、自动化运维、运维流程规范体系、高可用架构设计等建设。
科大讯飞是亚太地区知名的智能语音与人工智能上市企业,自成立以来深耕智能语音、自然语言理解及计算机视觉等核心技术。2023年,公司某AP业务开始实施数据库方案升级,引入了OceanBase 数据库。本文回顾并分享了这次升级过程中的实际应用场景与OceanBase运维实践经验。
数据库选型需求
2023年,我们上线了一个全新的业务,短短几月,数据增长就远远超出了上线初的预测,以至于底层数据库MySQL支撑出现瓶颈。对此,运维侧和业务侧提出了不同的诉求。
首先,业务侧希望数据库具备HTAP能力和多模能力。
HTAP能力。MySQL数据库在我们生产环境中被广泛使用,既支持TP类在线业务,又处理AP类业务的数据统计与分析。众所周知,MySQL对复杂SQL的优化能力较弱,当数据达到一定规模时就会出现性能瓶颈,这时开发人员需要找到一款性能更强的数据库,经过改造让其适配MySQL。为了减少改造成本,我们希望有一款数据库既兼容MySQL协议,又能支持HTAP 混合负载,最好一套系统代替 TP+AP 两套系统,无需分库分表,同时支持列存和行列混存及查询优化,以保障良好的查询性能。
多模能力。随着科大讯飞业务的多元化与复杂化,我们使用的数据库类型也越来越多,对开发、运维都是一种挑战。我们希望有一款数据库能够统一接口处理结构化、非结构化数据,简化我们的技术栈。另外,最好支持 NoSQL 功能,比如HBase、Redis、向量等产品形态。
其次在运维侧,我们对数据库的诉求主要包括两方面:数据迁移、白屏运维。
数据迁移。由于我们使用的数据库类型较多,DBA日常工作涉及在各个数据库集群中迁移、同步数据的操作,而使用的迁移工具、迁移方案也多种多样,因此,我们希望能有一款数据库支持 MySQL、HBase、Redis 、PostgreSQL等多种数据库的数据迁移、同步,同时具备数据校验能力。
白屏运维。我们的运维工作也涉及平台化建设,在该平台尚未完成数据流转生命周期的覆盖时,就无可避免通过命令行黑屏去操作。进而产生误操作,给业务带来稳定性风险。我们希望通过白屏化运维包括安装部署、升级、备份恢复,以及集群巡检、故障分析、SQL优化建议等功能,实现数据流转全生命周期的覆盖。
在做产品调研时,OceanBase作为单机分布式一体化、TP与AP一体化的数据库吸引到了我们,其兼容MySQL协议和部分语法,稳定性与性能已经过市场验证,近年来也拥有了多模能力。同时,OceanBase拥有丰富的生态工具,在数据迁移和白屏运维方面页满足我们的要求。因此,我们决定引入OceanBase(对选型和测试、上线过程感兴趣的朋友可以查看博文:亿级规模大表数据,查询性能快40倍|科大讯飞HTAP探索实践)。
OceanBase落地场景
在业务上线OceanBase后,主要的应用情况体现在三类场景中。
场景一:海量数据统计
起初业务数据量很小,在线业务和统计业务共用一套MySQL集群,没想到上线不久后业务量猛增,增速远超产品侧的预测。
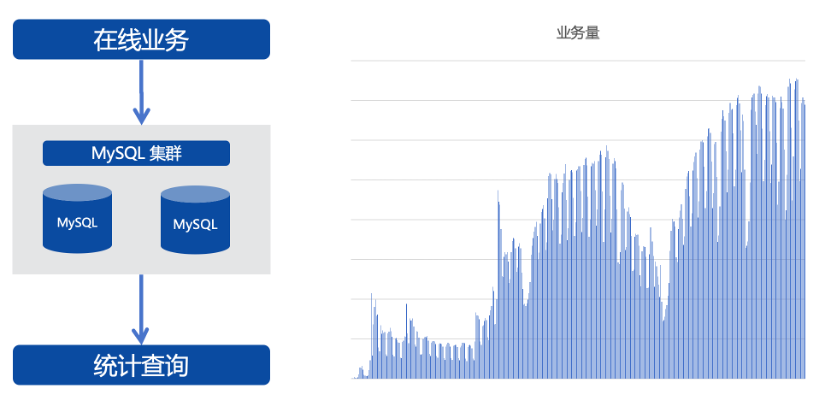
该业务有三个典型特点。第一,数据量大,核心表上亿级,最大的表超百亿规模;第二,增长快,核心表每天新增千万级数据,每年数据的存储量增加5TB以上,且不能删除,产品策略要求永久保存数据;第三,基于海量数据进行实时的多维度统计分析,要求秒级返回,并通过大屏进行实时展示(涉及报表40+)。
这三个业务特性使MySQL面临两个支撑难点,一是大规模数据的迅速增长已经超出MySQL的承载力,二是MySQL在统计查询方面较弱,无法满足业务需求。为了解决这两个问题,我们对系统进行改造和拆分。
首先,为了解决MySQL单集群的容量问题,我们将与核心业务关联较低的表拆分到单独的MySQL集群中,再把纯用户文本类的大字段的表单独拆分到MongoDB集群,相当于缓解了MySQL容量瓶颈和水平扩展问题。
其次,把数据拆分到多个集群后,出于统计分析的需求,业务侧仍然需要将数据进行汇总,一种可行的办法是将数据抽取到大数据平台,通过平台进行查询。但是,这种方法的缺陷在于查询是异步进行,无法满足秒级查询和展示的需求,同时,数据流向大数据平台,也需要经过开发和改造。
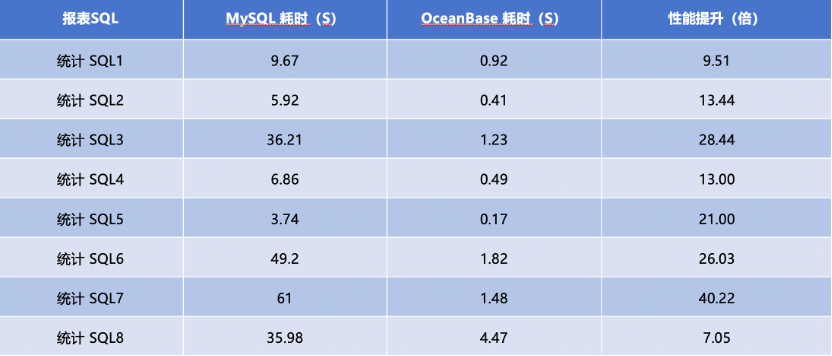
为了减少开发改造的工作量,同时更好地解决问题,我们找到了兼容MySQL协议的单机分布式一体化数据库OceanBase,并在2023年将其应用于海量数据统计场景。因为OceanBase支持水平横向扩容,所以容量不会成为业务发展的阻碍。同时,OceanBase的HTAP特性,无论是TP场景的性能还是AP场景的统计分析都能够满足业务秒级查询的要求,在不同的统计SQL 场景,相比MySQL,OceanBase的OLAP性能提升7~40倍。
最终,我们通过数据同步工具将MongoDB和MySQL多个集群的数据统一汇总到OceanBase,在不改变业务逻辑的情况下,满足了业务统计查询报表的需求。
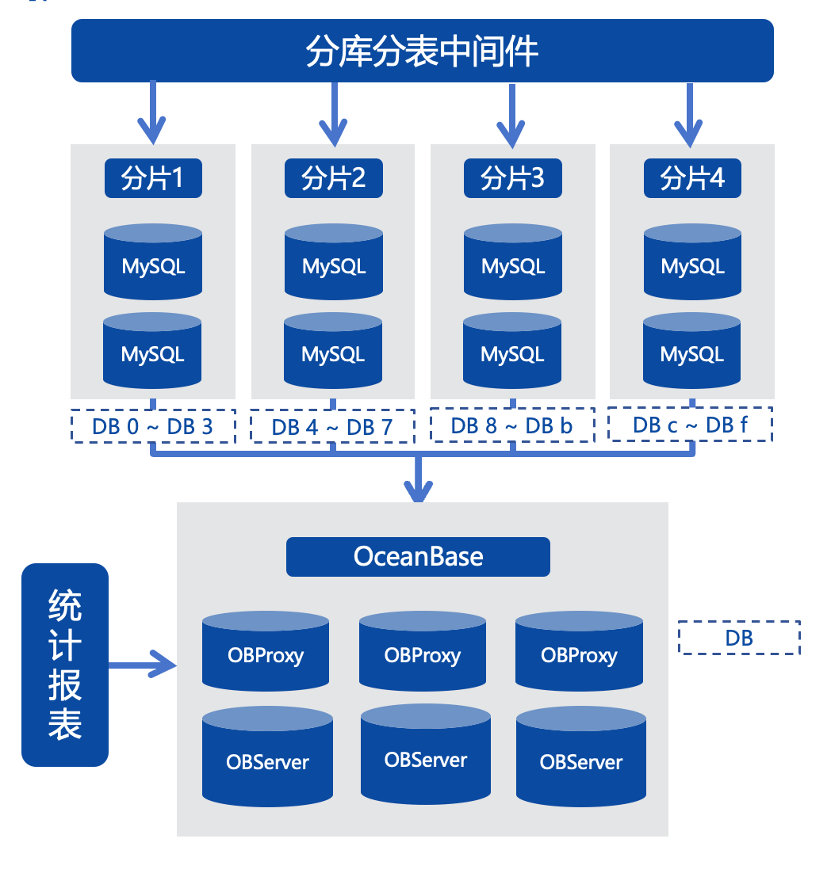
场景二:分库分表数据汇聚
对于一些规模较大的集群,我们在前期使用分库分表方案进行水平拆分,实际是将数据打散在多个分片上。比如将最大的表分成16个分库共256个分片。
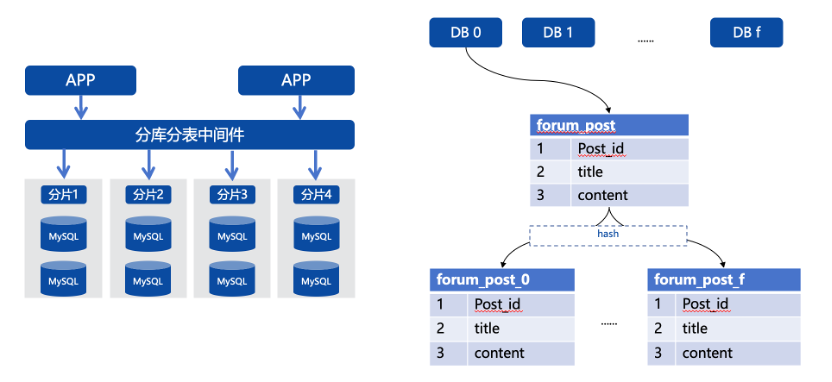
在这样的架构下,做统计查询就比较困难。因为分库分表中间件对跨分片的关联和汇聚查询能力较弱,所以无法直接在中间件查询。如果采用人工查询和汇聚的方式,面对单表256个分片,耗时较长。另外,在进行SQL统计分析时,涉及亿级数量的表扫描,可能导致集群性能抖动,影响业务稳定性。
基于上述背景,我们将多个经过分片的数据汇聚到同一个查询库里进行统计,这是一个过渡方案,本质是使用MySQL多元复制的能力将多个分片的数据汇聚到一个MySQL汇总查询库,可以暂时满足业务需求。
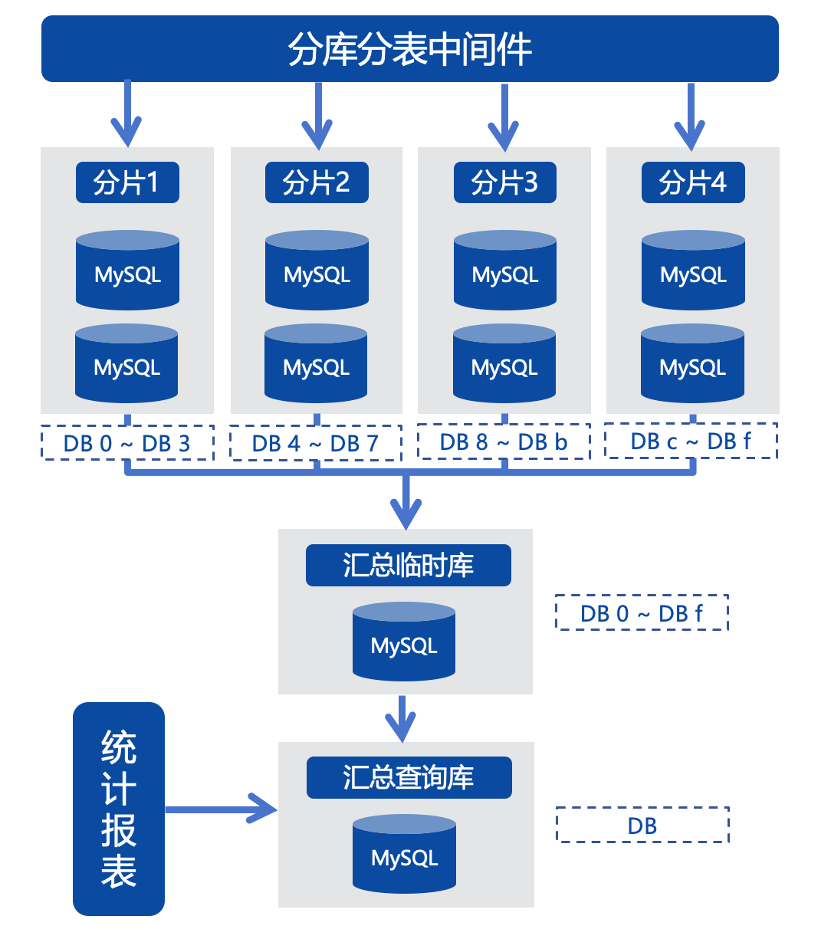
但是,这个方案的数据同步链路非常复杂,因为我们业务环境中使用的是MySQL 5.5,复制能力较弱,一些业务原因导致数据库版本无法升级和改造,所以数据必须经过一个临时的中转库,再结合MySQL 5.7的多元复制及replicate DB功能,把多个分片汇聚到一张表中。同时,每个分片都需要一个单独的同步链路,任何一个链路有问题,中转库及最终的数据查询汇聚库都要进行数据修复,导致整体链路出故障时难以修复。尤其是当线上需要变更表结构时。经过的每一个分片都要执行变更操作,致使汇聚链路中断,此时只能依靠人工修复链路。
更让人头疼的是,我们采用MySQL的源生同步,不支持数据校验,缺乏对已汇聚数据和源库原表的完整性校验的机制。如果同步链路中出错,我们只能选择忽略错误,继续保持链路的进度。因此,我们无法判定汇聚后的数据一致性和准确性,如果发现问题,只能重建同步链路,整个过程耗时又耗人。
为了解决上述痛点,我们使用了OceanBase的数据同步工具OMS,代替中转库的方案。
OMS对MySQL各版本兼容良好,可以让我们将数据从MySQL一步汇聚到OceanBase,同步链路被极大地简化。由于OMS的监控和数据校验功能完善,可以监控各种数据延迟,便于我们及时获取同步动态,当数据出现冲突或丢失时,我们也可以借助工具快速进行修复。另外,上文提到每一个分片都是单独的链路,我们可以复制链路原子化,如果单一链路出现问题,也不会影响其他链路的数据同步。
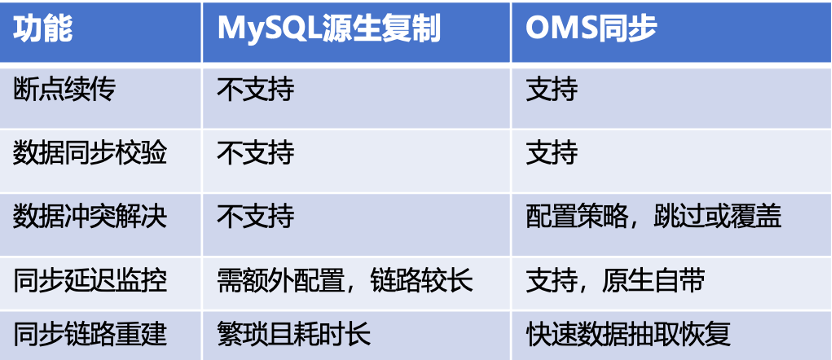
下图是MySQL源生复制和OMS同步的功能对比,可以看到OMS占据很大的优势。比如支持断点续传、数据同步校验、同步延迟监控,以及当数据发生冲突时可以根据配置选择跳过还是覆盖。同时OMS也支持同步链路重建,当出现同步故障时,我们可以通过数据抽取快速恢复链路。
场景三:NoSQL及多模
这是一个在线爬虫类业务,需要下载客户请求端的网页,并返回数据。该业务的并发很高,生产端和消费端的并发量均为1.5万个进程,同时业务对应用请求响应的时延要求是毫秒级,因此我们最初选择使用Redis去解耦生产端和消费端,使二者互不影响。
- 通过 lpush 和 rpush 把待下载网页的URL 数据存入 redis 的 list key。
- 通过 lpop 和 rpop 来获取待下载的网页URL。
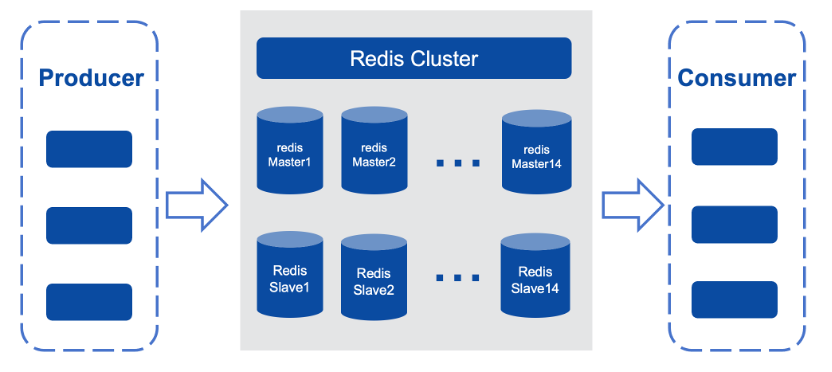
由于爬虫的数据量特别大,整个Redis集群使用三台服务器,共42个实例,最大的单实例内存约60GB,整个集群规模占内存约2TB,这为系统埋下了隐患。
第一,Redis主从复制是基于内存中的复制积压缓冲区,如果业务爬虫的瞬时写流量大,会把积压缓冲区的内存覆盖,导致内存不足,进而 Redis主从复制中断,重建频繁失败。这时只能人工介入。
第二,由于爬虫数据的分布不均,整个集群中会存在热 key,业务对部分 key 请求频率过高时(>2w/s),会使集群负载不均。而且因为业务逻辑,我们没办法针对热key进行拆分。
第三,无论是生产还是消费,业务的并发量都很高,但Redis本身是单线程的,如果业务出现偶发 o(n) 操作就会导致单线程阻塞 :如 hgetall,scan, lrange 0-1 等。
因此,我们需要重新选型数据处理方案以解决上述难题。
OBKV是构建在分布式存储引擎上的NoSQL产品,继承了OceanBase 的分布式、多租户、高性能、高可靠等基础能力。其分为OBKV-HBase和OBKV-Redis,后者正是我们当前选择的新方案,原因是:
- OBKV-Redis 完全兼容 Redis 协议,业务侧不需要修改。
- OBKV-Redis 持久化key 到磁盘,解决内存不足或使用过多的问题。
- OBKV-Redis 针对热 key底层通过表分片进行了优化。
- OBKV-Redis 利用OBServer多线程处理,无单线程阻塞问题。
- OBKV-Redis 无特殊运维,只需运维OceanBase集群。
- OBKV-Redis 的 P99 在 10 ms 以内,满足业务需求。
在上线前,我们针对OBKV和Redis进行了读写方面的压测,为了保证公平性,规格统一限定为12核20GB。从下图可见,在读场景,二者的性能、延时相近。而在写场景,OBKV写性能与Redis存在一定差距,但满足业务负载;OBKV写延迟比Redis略高,但都在10ms以内,满足业务需求。
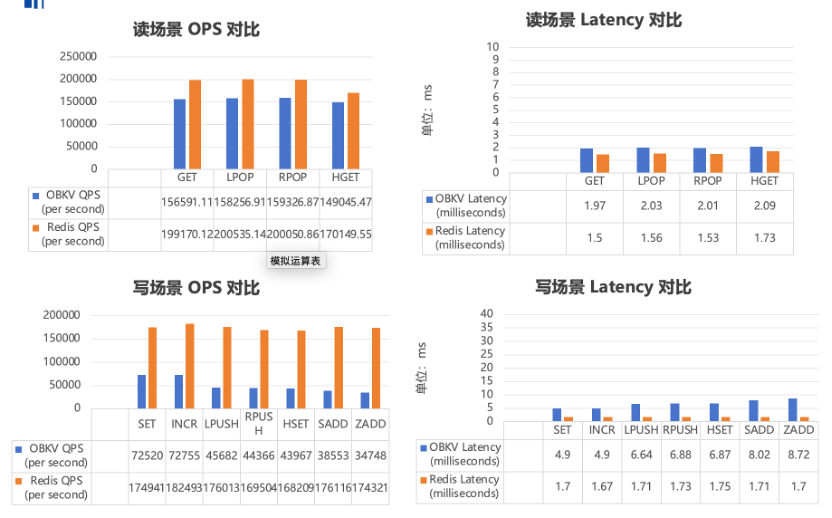
使用OBKV-Redis后,虽然性能与延时并未提升,但解决了此前Redis主从复制容易中断,产生热 key、单线程阻塞等问题。
OceanBase白屏运维
除了上述应用场景外,OceanBase丰富的工具体系为我们提供了极大便利。
本文开头提到复杂的运维操作促使我们寻找一个白屏化的运维平台,以管理数据库全生命周期。OceanBase运维平台——OCP基于 Web 的可视化白屏管理,将黑屏运维管理工作标准化、自动化,我们可以通过页面操作进行数据库运维,提升运维效率。
OCP具有几项典型功能:
- 资源管理。提供 OceanBase 集群,租户,主机等资源对象的全生命周期管理,包括管理,安装、运维、 性能监控、配置、升级等功能。
- 监控告警。全局监控及告警设置,支持所有资源对象不同维度,实时、准确地监控告警需求,支持自定义告警。
- 备份恢复。支持集群和租户表级全量备份、增量备份及日志备份,支持在备份周期内任意时间点的恢复,支持多种云平台介质的备份恢复。
- 自治服务。自动化处理 “发现-诊断-定位-优化/应急”链路,极大地降低用户运维的成本。
从下面OCP平台的截图可以看到,无论是集群管理还是租户管理,我们部可以通过白屏化进行操作。在很大程度上简化了运维工作,降低了我们的运维投入。
OceanBase运维经验
OceanBase成功解决了我们在业务侧和运维侧的难题,在运维OceanBase一年后,我们也积累了一些运维经验,供大家借鉴。
1.产品版本选择
当我们在业务侧推广OceanBase时,通常业务侧会关心应该使用哪个版本,这时我们需要对各版本有较为全面的了解。OceanBase的版本号通常有三类:
- Va.b.c_CE,如V4.2.1_CE;
- Va.b.c_CE_BP1,如V4.2.1_CE_BP1;
- Va.b.c_CE_BP1_HF1,如V4.2.1_CE_BP1_HF1。
在上述版本号中:
- a表示主要的大版本,一般会有架构升级或较大的新功能发布。
- b表示计划迭代版本,含有重要功能或特性更新和提升。
- c表示发布更新版本,对已知问题进行修复,一般无功能或特性变更。
- BP:表示是第 X 个 Bugfix 版本,通常每个月发布一次,用于修复一些重大的 bug,引入一些小功能特性。
- HF:表示是第 X 个 Bugfix 版本的第 Y 个 Hotfix,如果在BP发布期间发现了重大的 bug,就通过 HF 来修复。
目前,OceanBase 4.x的长期支持版本有OceanBase 4.2.1和OceanBase 4.2.5,我们使用的是OceanBase 4.2.1。对于初次选择OceanBase的企业,我们推荐使用长期支持版本的最新BP或最新HF版本。
2.DDL分类
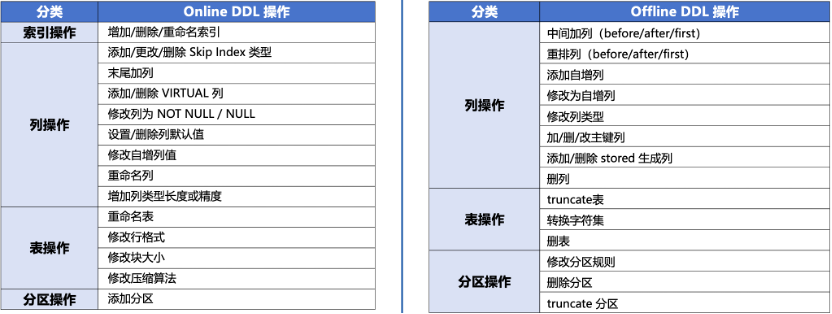
在MySQL的日常运维工作中,Online DDL操作或大表DDL操作对我们来说是一大痛点。OceanBase对Online DDL操作进行了增强,目前MySQL 中大表分钟级的DDL操作,在OceanBase中秒级完成,且不锁表,完全不会阻塞业务。不过,对于秒级完成的Offline DDL :操作,其原理是新建一张临时隐藏表,后台将原表的数据补全到隐藏表,最后重命名临时表为原表并删除旧表,在这个过程需要锁表,对业务有损。
下图是OceanBase目前已经支持的DDL操作,相信随着版本的快速演进,Online DDL操作会越来越多,Offline DDL :操作会越来越少
此外,值得一提的是,为了解决Offline DDL锁表的问题,OceanBase提供了一个功能——ODC 无锁结构变更。其本质是依赖OMS、OCP解决问题,首先创建临时表并改变表结构,其次全量拷贝数据并做增量同步和校验,最终切换新旧表。
下图是ODC 无锁结构变更支持的变更范围。
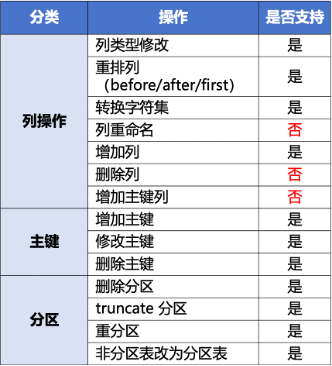
在进行无锁结构变更操作时,我们需要注意:
- 表必须有主键或非空唯一键;
- 需要操作对象至少 2 倍的磁盘空间;
- 无锁结构变更期间,其它关于该表的 DDL 变更将导致任务失败。
根据我们的实测数据,线网5亿单表(200GB)修改列类型耗时约 5 小时,但经过我们和官方技术人员分析,耗时较长的原因是 ODC 依赖的 OMS 同步效率慢,可以通过参数调优实现加速。
3.善用Hint
优化器是数据库SQL执行的关键,但往往无法正确选择准确的执行时间。当优化器选择了错误的执行计划时,就需要通过Hint指定执行计划。Hint 是一种 SQL 语句注释,用于将指令传递给数据库优化器,使优化器生成指定的执行计划。一般情况下,优化器会为用户查询选择最佳的执行计划,不需要用户使用 Hint 指定。
下面来看一个简单的SQL在是否增加Hint的执行效率对比。该表的全量数据为600万行。虽然有围绕条件,但过滤条件不是很好,没有办法走索引。经过扫描,结果集也是600万,可以判定为全局扫描。
数据量:
obclient [oceanbase]> select count(1) from chat_req_uid_doctype_daily;
count(1)|
--------+
6097816
obclient [oceanbase]> select count(1) from chat_req_uid_doctype_daily where doctype in ('0', '1', '2', '3', '1100');
count(1)|
--------+
6025383
在不用Hint的情况下,初始SQL执行需要6s,为了优化性能,我们为该SQL加入Hint,执行效率提升至了1s,效果较为显著。我们线网一般是把OceanBase作为一个AP类的场景去使用。所以说它的并发不是特别高。所以说在为了提升查询效率的情况下,我们一般会建议业务适当增加Hint,因为Hint并不是越多越好,达到一定并行量后,性能提升效果会受限。
原SQL(6s):
obclient [oceanbase]> select count(distinct uid) as uidcnts
from chat_req_uid_doctype_daily
where doctype in ('0', '1', '2', '3', '1100');
添加Hint的SQL(1s):
obclient [oceanbase]> select /*+ parallel(4) */
count(distinct uid) as uidcnts
from chat_req_uid_doctype_daily
where doctype in ('0', '1', '2', '3', '1100');
4.优化器版本对SQL的影响
不同版本的优化器,对SQL性能会产生不同的影响。举个例子,某SQL的条件列中是一个条件中的一个非相关子查询,最初我们使用OceanBase 4.1.0版本时,该SQL的执行时间为0.3s,当我们升级为OceanBase 4.2.1版本后。执行时间退化到了50s。
经过测试,发现问题在于条件列的子查询,如果把这个子查询换成子查询返回的固定日期,它的查询时间会恢复到0.3s。这是由于数据库版本之间优化器的变化导致的,最终我们通过添加Hint并修改执行计划,使该SQL的执行效率重回0.3s。
OceanBase的优化器是基于规则优化和代价优化相结合,在一般情况下通过代价进行查询优化,可能会产生错误的执行计划,这时就需要通过Hint基于规则进行“修剪”实现优化。
目前OceanBase还在不断演进,其研发人员完全覆盖所有SQL场景,还是要依赖于用户在生产场景不断发现问题、反馈问题。而官方的响应和改进也非常快速。在如此重视用户反馈和快节奏迭代的情况下,我们希望OceanBase能够越做越好。