一次Oracle集群脑裂问题分析处理
问题描述
填写问题的基础信息。
| 系统名称 | 数据库集群 |
| IP地址 | xxxxxx |
| 操作系统 | Linux |
| 数据库 | Oracle 11.2.0.4 |
症状表现
问题的症状表现如下
4月26号晚22点02分左右,HIS集群发生脑裂,十几分钟后(22.18)一节点集群率先获得集群控制权,
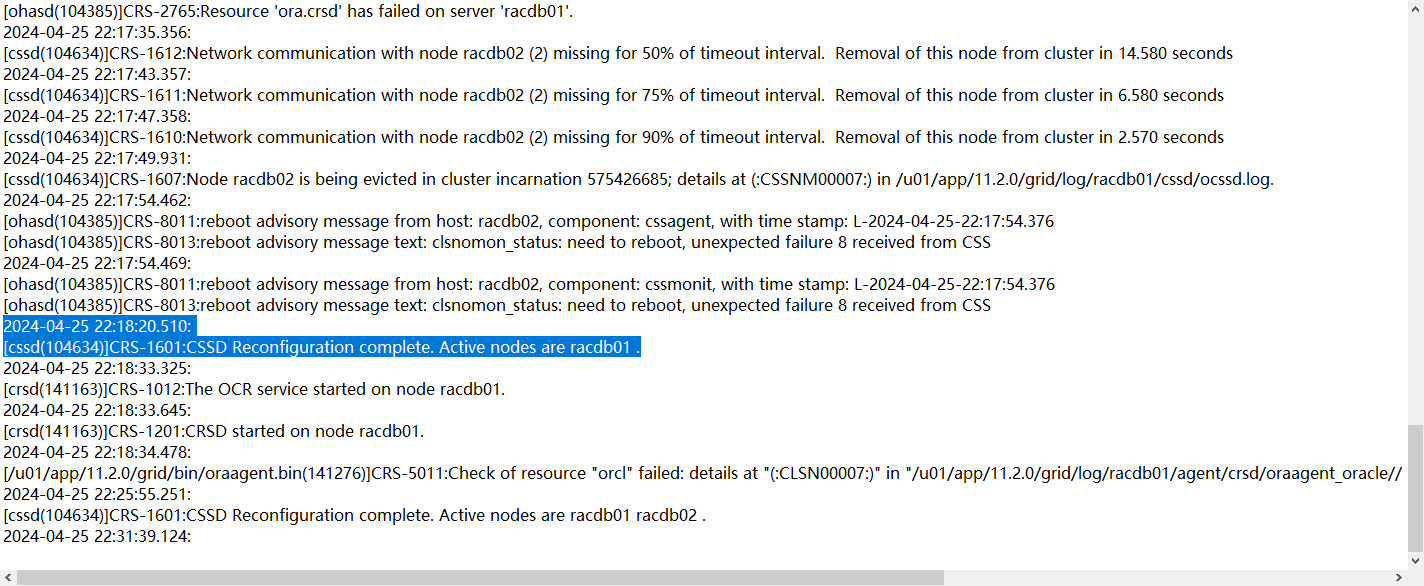
与此同时,一节点向而节点发起了member kill 以及 node kill请求
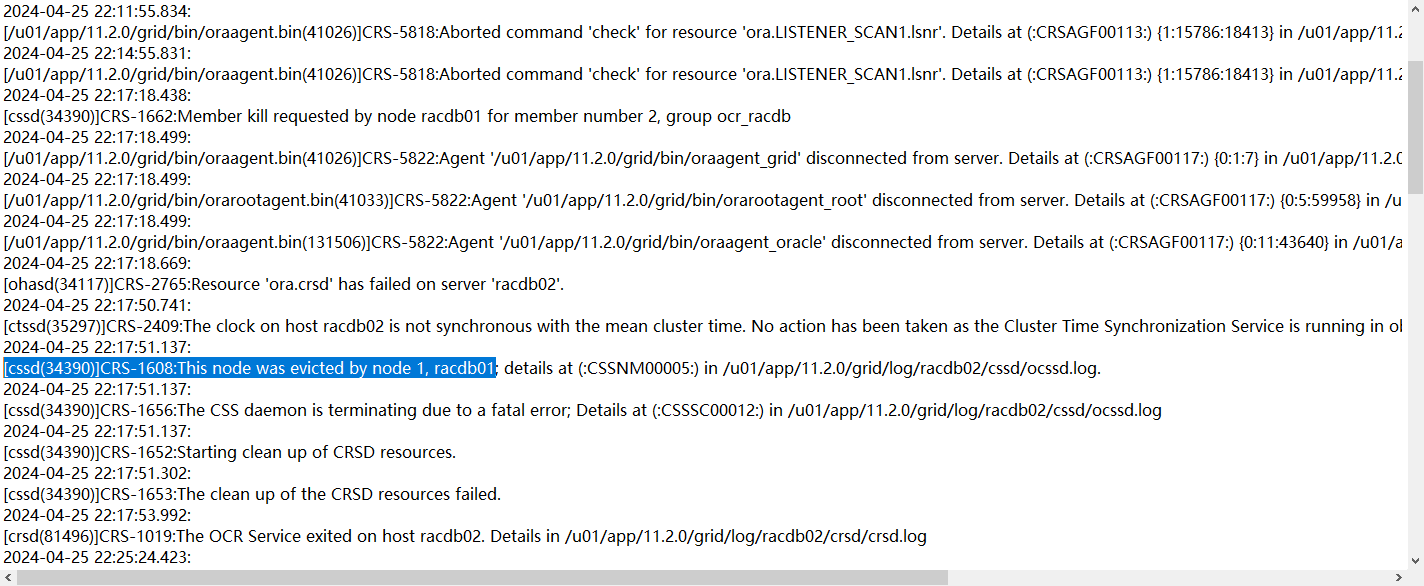
随后,22.25分二节点以incomplete状态node kill重启集群件,并尝试加入集群
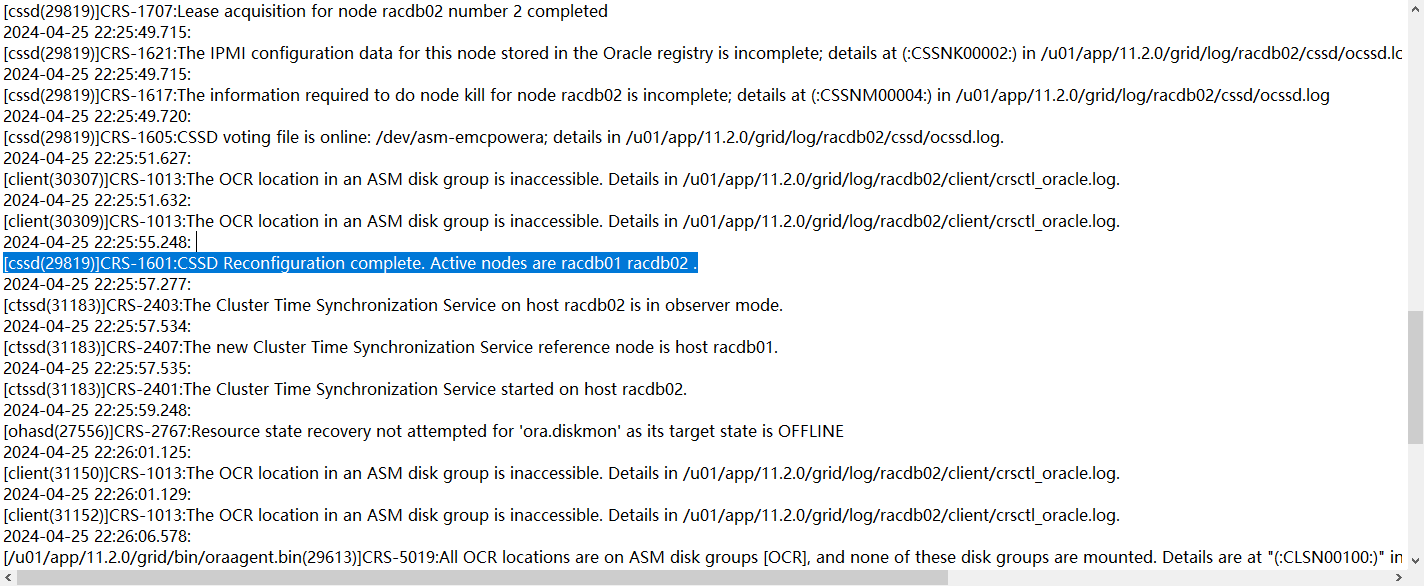
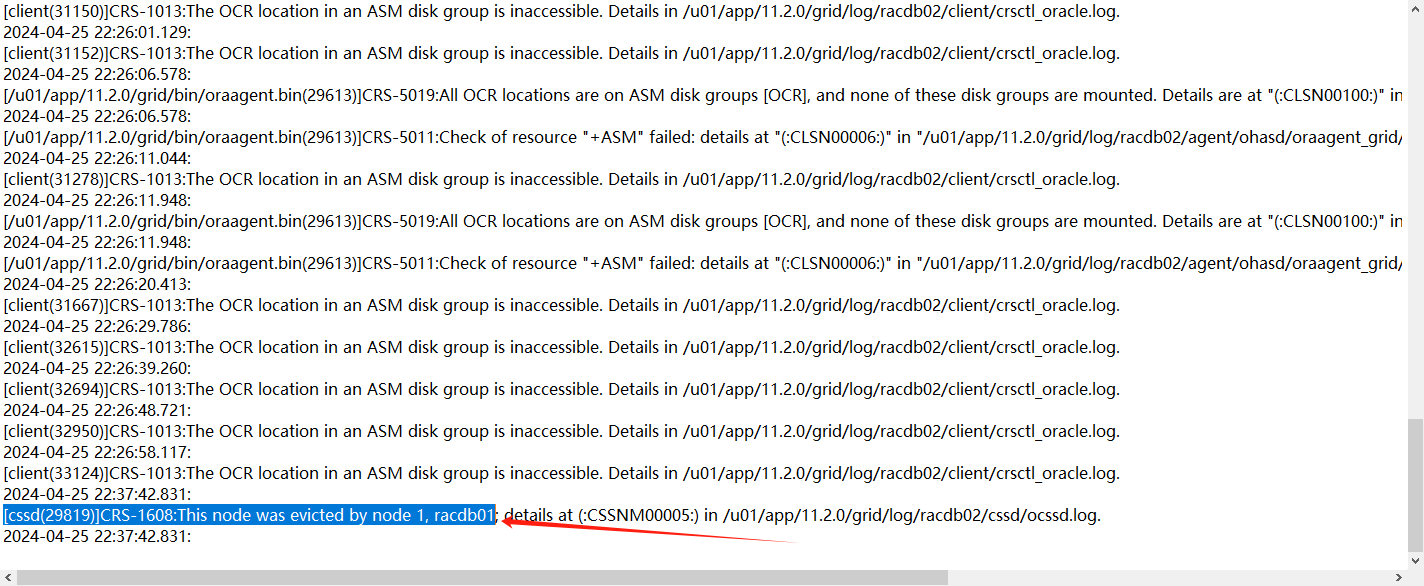
但是遇到了中裁盘不能访问的故障,直到22.37分再次被节点1驱逐
处理过程
处理过程推荐按照时间以列表形式,将处理过程时间点,处理内容。
1、从集群日志来看,最开始的异常时来自二节点的check scan_listener失败,大概在21.59分就发生:

2、查看对应的trace日志,看一下当时为什么check失败了
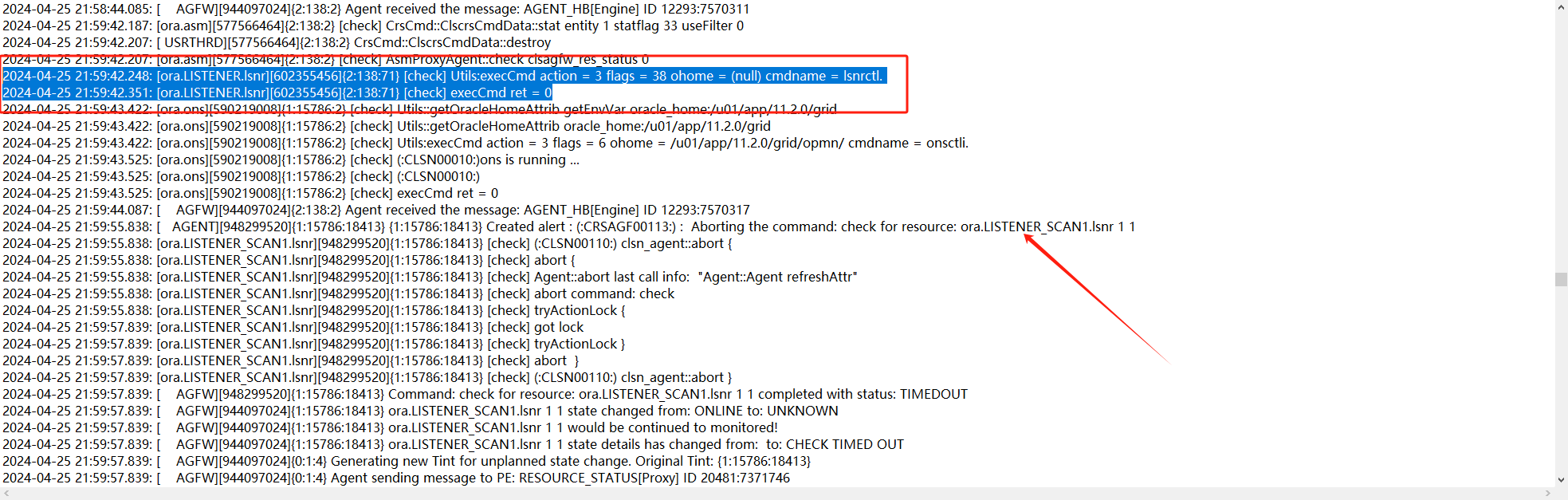
trace日志显示21.59.42秒对scan的check都还是成功的,59分55秒check出现了timeout。
3、然后接着就是一节点上实例挂了,一节点集群日志显示如下:
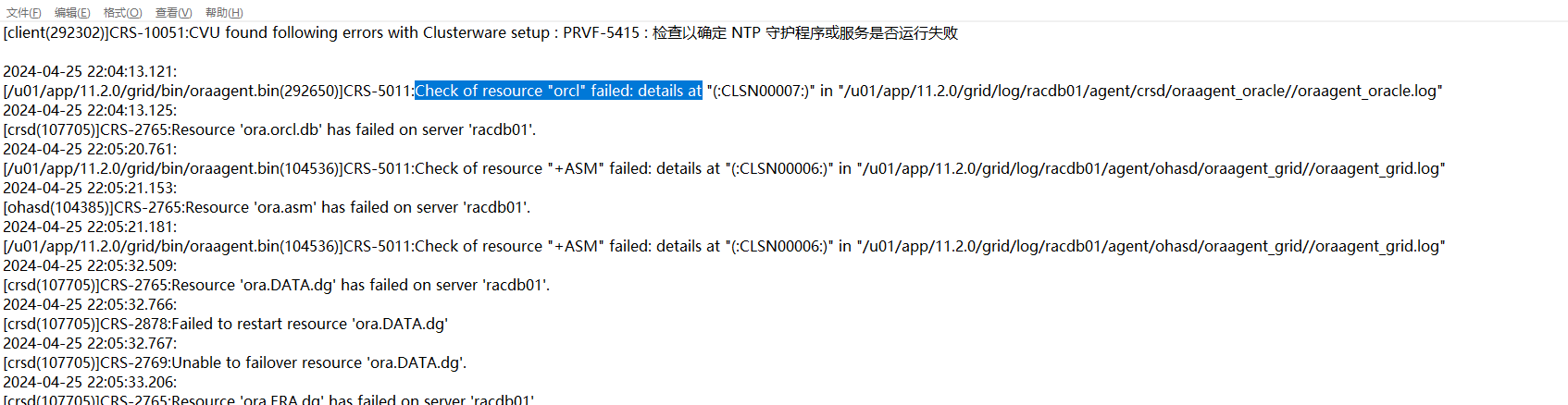
查看对应的trace日志发现就是当时的实例挂了,继续查看当时的数据库日志
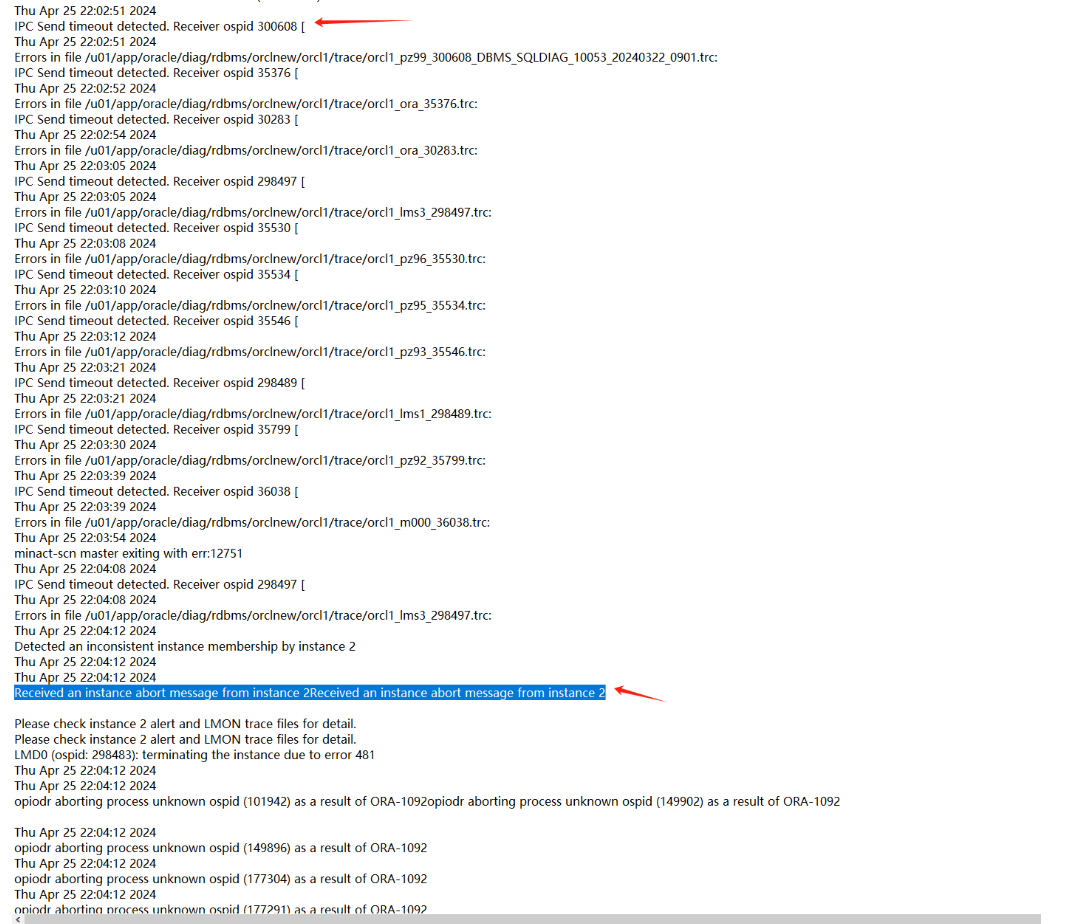
4、两节点的数据库日志显示如下:
一节点:
二节点:
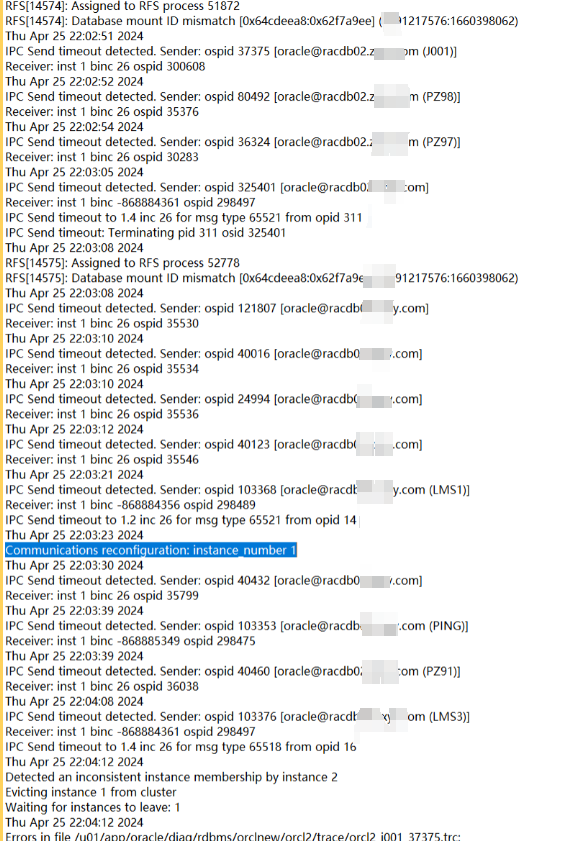
可以发现在22.02.51左右,二节点向一节点发送一些IPC请求出现timeout情况,过了一会(22.04)一节点实例被二节点驱逐(member kill),这个应该就是本次问题最开始的故障了。
4、继续排查为什么实例会出现IPC Send Timeout原因,注意看当时二节点的IPC Send Timeout进程有很多(不是固定的某一个进程),有Oracle自己的并行进程,还有客户的JDBC连接进程,怀疑这种Timeout问题应该是和私网性能有关,随即查看对应时间私网心跳是否有延迟或者丢包,并未发现异常。但是在一节点服务器上发现对应时间段有大量的packet reassembles failed。
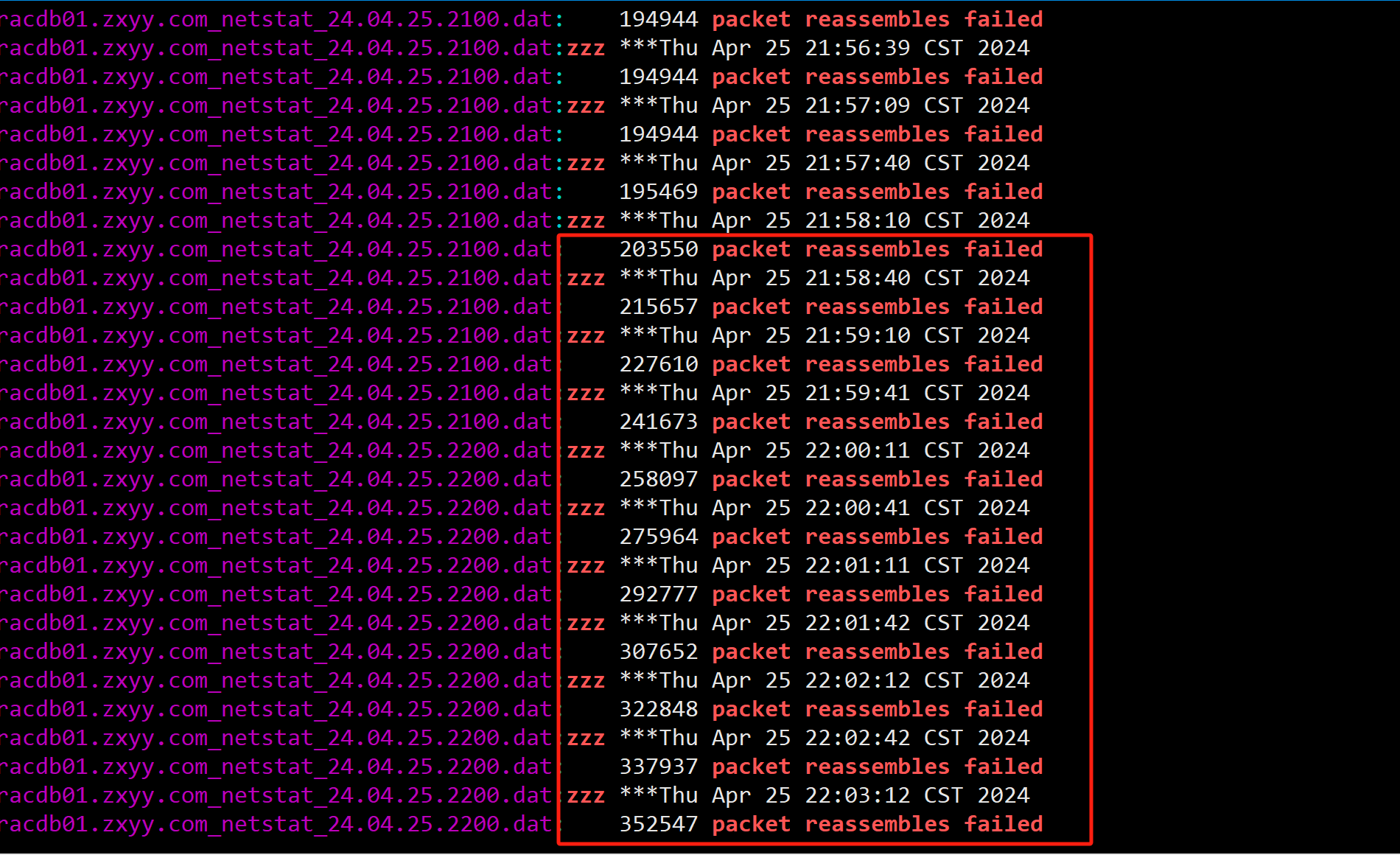
基本可以确认二节点向一节点发送IPC Timeout是由于一节点网络包重组失败造成的。(之前也有类似的案例)
什么是IP packet reassembles failed?
在linux平台使用netstat -s命令时会看到packet reassembles failed项, 记录的是IP重组包失败的累计数据值,什么时候要重组呢?当IP包通信存在碎片时。在网络通信协议中MTU(最大传输单元)限制了每次传输的IP 包的大小,一种是源端和目标端使用了不同的MTU时会交生碎片,这里需要先确认传输过程中的MTU大小配置,确认使用了相同的MTU;还有就是当传送的数据大于MTU时,回分成多个分片传递。这时调整MTU就不可能解决所有的IP包碎片的问题,可以通过加大通信的buffer值,尽可能保留更多的数据在源端拆包,目标端缓存等接收完整后再重组校验。 在LINUX系统中调整BUFFER使用ipfrag_low_thresh 和ipfrag_high_thresh参数,如果调整了这个参数仍有较大的重组失败还可以加大ipfrag_time 参数控制IP 碎片包在内存中保留的秒数时间。
如果在ORACLE RAC环境中一个节点突然产生了大量的数据包输送给另一个节点,如应用设计问题,如数据文件cache fusion或归档只能一个节点访问时,都加大了网络通信量,这里需要检查网络负载及丢包或包不一致的现象,因为ORACLE在网络通信中使用了UDP和IP通信协议,这两类信息都需要关注。
5、为什么一节点上会在对应时间出现大量的网络包失败呢?这一般有以下几个原因:
A.节点之间有流量传输,并且有大量的巨帧包传输。
B.主机、交换机等网络相关参数设置问题。
C.主机CPU、内存资源不足导致。
D.A条件和B条件的相互作用。
条件A:
继续排查出问题前数据库实例内部是否有异常,收集了对应时间段的ash、awr以及addm报告,报告显示对应时间段数据库出现了大量的gc等待事件
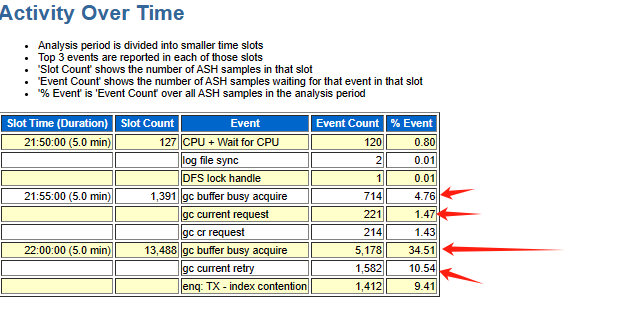
gc相关的等待事件一般都是和集群上的热块争用有关,集群上的热块交换依赖于RAC的私网,当出现大量的GC相关等待事件说明当时有一些SQL需要跨界点访问热点数据块,大量热点数据块的传输就满足的条件A。
条件B:
查看主机上的规定reassembles buffer 尺寸的大小,发现如下:
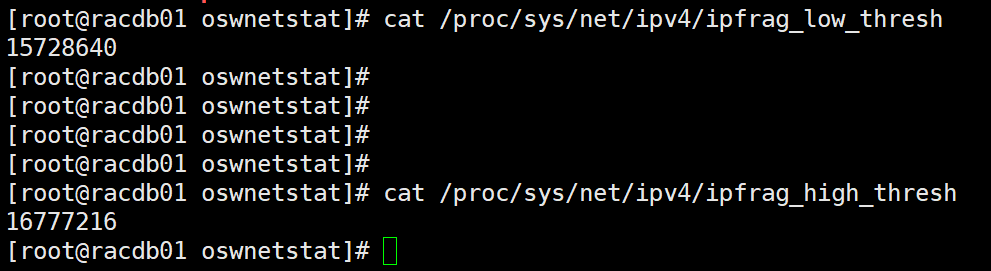
两个节点都是满足最佳实践的要求的,但是如果还是出现大量的packet reassembles faile 问题,可以考虑开启巨帧传输(调整MTU值),当然这个也需要交换机能够支持。
条件C:
通过监控工具,未发现当时一节点主机有CPU\内存不足等问题。
条件D:
有些时候网络流量不大,网络带宽没有跑满的情况下,条件A和条件B的相互作用也会导致大量的packet reassembles failed,就是当网络传输的数据包都通过大量IP分片的方式进行传输,fragmentation rate比较高,那么主机网卡采用较小的MTU值进行传输(接收),当reassembles buffer满,也会出现大量的packet reassembles failed,本次故障中通过监控工具发现是有大量的网络包通过IP分片方式进行传输:
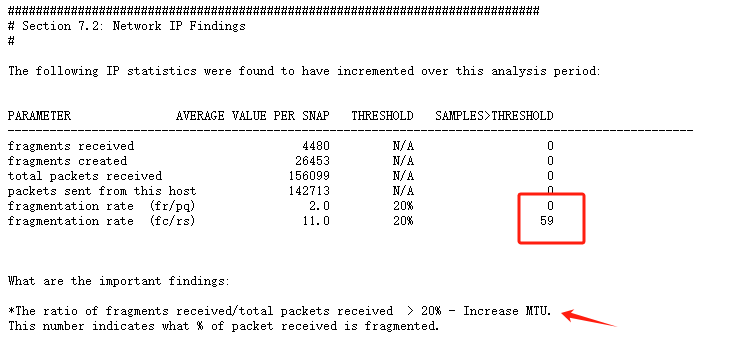
问题原因
问题原因如下
数据库有SQL产生大量的GC等待事件,集群上的热块需要跨节点进行传输,有大量的网络包采用IP分片的方式进行传输,目标端主机不能及时将接收到的巨帧包进行重组,诱发实例间IPC Send Timeout,进而出发集群member kill以及后续的node kill,最后集群需要花费一些时间完成重组。
问题解决
问题解决如下
1、对于容易产生大量GC的SQL尽量在一个节点运行,本次抓到的一些SQL如下:
抓到多个SQL如下:
📎addmrpt_2_78505_78506.txt
主要有如下SQL:
7r5mtbybcggnk
一节点执行次数:3347,平均时间1.03秒 ,二节点执行次数131次,平均时间10.71秒 764wd65m5y2sf 一节点执行次数:460 ,平均时间 3.69秒,二节点执行次数 453次,平均时间2.06秒2、如果可以,开启私网心跳巨帧传输(需要交换机硬件支持)