GraphRAG的部署和生成检索过程体验
文章目录
- 零 参考资料
- 一 前置环境
- 二 说明
- 三 缺陷
- 四 生成索引实践过程
- 五 局部查询过程
- 5.1 本地搜索
- 5.2 全局搜索
零 参考资料
- graphrag get_started
- GraphRAG快速部署与调用方法详解
- openai-hk openai 中转网站
- GraphRAG从原理到实战技术精讲
一 前置环境
- Anaconda环境
- Window环境
- 稳定的网络环境
二 说明
- 本次实践采用在线大模型gpt-4o-mini和在线向量化模型text-embedding-3-small,对本地GPU性能不做要求。
三 缺陷
- 构建索引过程受限于网络传输,耗时,token消耗较多。
- 最终效果严重依赖大模型的处理能力。
四 生成索引实践过程
- 创建并激活虚拟环境
conda create --name graphrag python=3.12 conda activate graphrag - 在虚拟环境中安装grapgrag
pip install graphrag - 在当前用户目录下创建
graphrag/input目录(这里使用window环境)
# win command
mkdir graphrag\input
mkdir graphrag\inputs
# linux /mac command
mkdir -p ./ragtest/input
mkdir -p ./ragtest/inouts
-
将需要构建RAG的文本放入
graphrag/input目录,截至2025.7.22,graphrag官方默认支持的文件格式主要为:txt,csv,json。具体详情可查看graphrag输入知道文档 -
初始化工作区,执行以下命令将在
ragtest中创建两个文件:.env和settings.yaml# win command graphrag init --root ragtest # linux command graphrag init --root ./ragtest -
自动优化提示词
graphrag prompt-tune --config ./settings.yaml --root ./ --no-discover-entity-types --language Chinese --output ./prompts(graphrag) C:\Users\kongyue\Desktop\ragtest>graphrag prompt-tune --config ./settings.yaml --root ./ --no-discover-entity-types --language Chinese --output ./prompts 2025-07-23 09:15:20.0856 - INFO - graphrag.cli.prompt_tune - Logging enabled at C:\Users\kongyue\Desktop\ragtest\logs\logs.txt 2025-07-23 09:15:20.0866 - INFO - graphrag.api.prompt_tune - Chunking documents... 2025-07-23 09:15:20.0866 - INFO - graphrag.storage.file_pipeline_storage - Creating file storage at C:\Users\kongyue\Desktop\ragtest\input 2025-07-23 09:15:20.0867 - INFO - graphrag.index.input.factory - loading input from root_dir=C:\Users\kongyue\Desktop\ragtest\input 2025-07-23 09:15:20.0867 - INFO - graphrag.index.input.factory - Loading Input InputFileType.text 2025-07-23 09:15:20.0867 - INFO - graphrag.storage.file_pipeline_storage - search C:\Users\kongyue\Desktop\ragtest\input for files matching .*\.txt$ 2025-07-23 09:15:20.0888 - INFO - graphrag.index.input.util - Found 7 InputFileType.text files, loading 7 2025-07-23 09:15:20.0889 - INFO - graphrag.index.input.util - Total number of unfiltered InputFileType.text rows: 7 2025-07-23 09:15:20.0894 - INFO - graphrag.index.workflows.create_base_text_units - Starting chunking process for 7 documents 2025-07-23 09:15:21.0103 - INFO - graphrag.index.workflows.create_base_text_units - chunker progress: 1/7 2025-07-23 09:15:21.0107 - INFO - graphrag.index.workflows.create_base_text_units - chunker progress: 2/7 2025-07-23 09:15:21.0111 - INFO - graphrag.index.workflows.create_base_text_units - chunker progress: 3/7 2025-07-23 09:15:21.0115 - INFO - graphrag.index.workflows.create_base_text_units - chunker progress: 4/7 2025-07-23 09:15:21.0120 - INFO - graphrag.index.workflows.create_base_text_units - chunker progress: 5/7 2025-07-23 09:15:21.0123 - INFO - graphrag.index.workflows.create_base_text_units - chunker progress: 6/7 2025-07-23 09:15:21.0126 - INFO - graphrag.index.workflows.create_base_text_units - chunker progress: 7/7 2025-07-23 09:15:21.0136 - INFO - graphrag.api.prompt_tune - Retrieving language model configuration... 2025-07-23 09:15:21.0136 - INFO - graphrag.api.prompt_tune - Creating language model... 2025-07-23 09:15:22.0234 - INFO - graphrag.api.prompt_tune - Generating domain... 2025-07-23 09:15:25.0649 - INFO - graphrag.api.prompt_tune - Generating persona... 2025-07-23 09:17:22.0279 - INFO - graphrag.api.prompt_tune - Generating community report ranking description... 2025-07-23 09:18:24.0945 - INFO - graphrag.api.prompt_tune - Generating entity relationship examples... 2025-07-23 09:23:27.0014 - INFO - graphrag.api.prompt_tune - Generating entity extraction prompt... 2025-07-23 09:23:27.0020 - INFO - graphrag.api.prompt_tune - Generating entity summarization prompt... 2025-07-23 09:23:27.0020 - INFO - graphrag.api.prompt_tune - Generating community reporter role... 2025-07-23 09:24:26.0767 - INFO - graphrag.api.prompt_tune - Generating community summarization prompt... 2025-07-23 09:24:26.0768 - INFO - graphrag.cli.prompt_tune - Writing prompts to C:\Users\kongyue\Desktop\ragtest\prompts 2025-07-23 09:24:26.0773 - INFO - graphrag.cli.prompt_tune - Prompts written to C:\Users\kongyue\Desktop\ragtest\prompts -
打开openai-hk openai 中转网站,充值5元,获取api key,将其填写到
.env文件中,并同时修改setting.yamlGRAPHRAG_API_KEY=hk-xxxhttps://api.openai-hk.com/v1/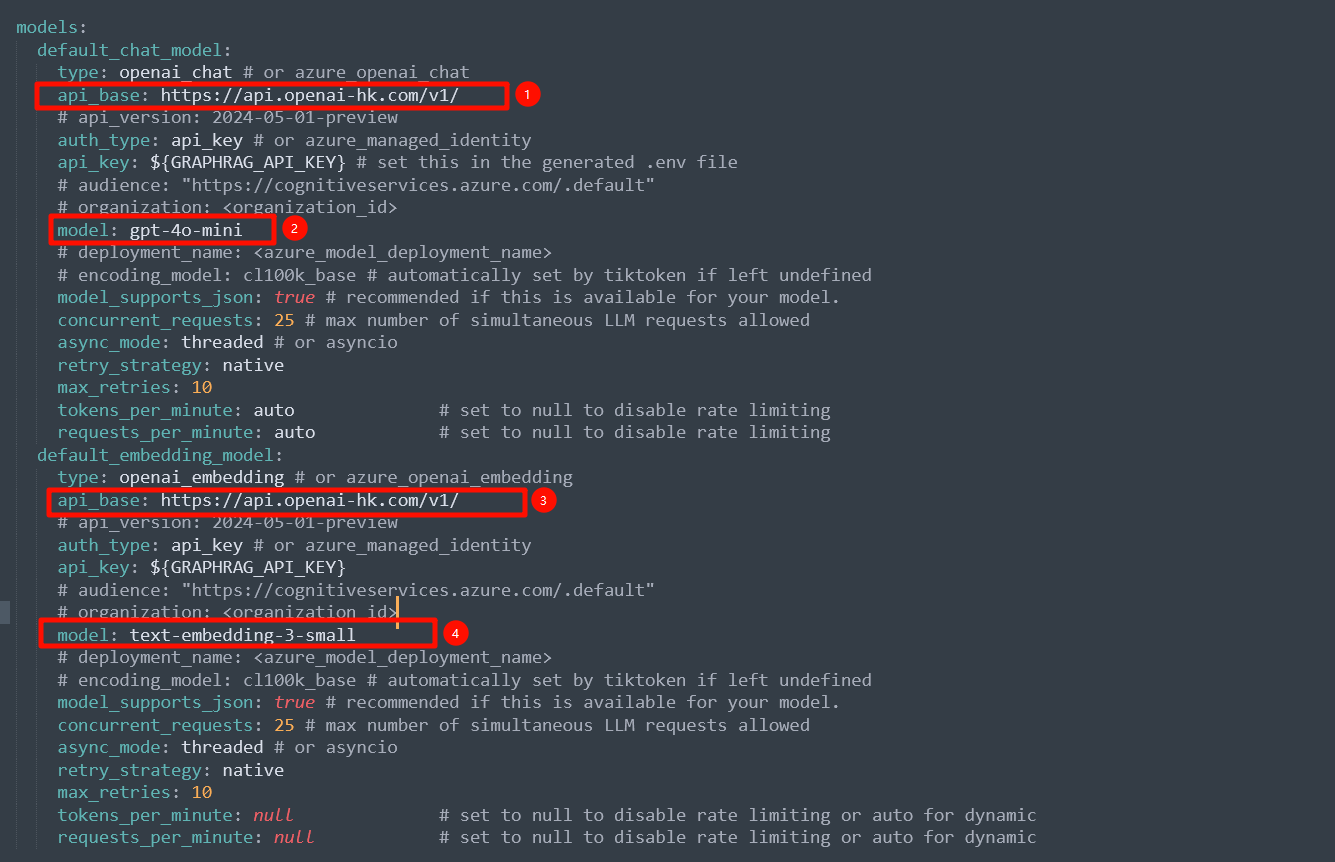
-
执行构建索引的命令
(graphrag) C:\Users\kongyue>graphrag index --root ./ragtest
(graphrag) C:\Users\kongyue>graphrag index --root ./ragtest
2025-07-22 19:00:30.0503 - INFO - graphrag.cli.index - Logging enabled at C:\Users\kongyue\ragtest\logs\logs.txt
2025-07-22 19:01:31.0835 - INFO - graphrag.index.validate_config - LLM Config Params Validated
2025-07-22 19:01:34.0057 - INFO - graphrag.index.validate_config - Embedding LLM Config Params Validated
2025-07-22 19:01:34.0058 - INFO - graphrag.cli.index - Starting pipeline run. False
2025-07-22 19:01:34.0061 - INFO - graphrag.cli.index - Using default configuration: {"root_dir": "C:\\Users\\kongyue\\ragtest","models": {"default_chat_model": {"api_key": "==== REDACTED ====","auth_type": "api_key","type": "openai_chat","model": "gpt-4o-mini","encoding_model": "o200k_base","api_base": "https://api.openai-hk.com/v1/","api_version": null,"deployment_name": null,"proxy": null,"audience": null,"model_supports_json": true,"request_timeout": 180.0,"tokens_per_minute": "auto","requests_per_minute": "auto","retry_strategy": "native","max_retries": 10,"max_retry_wait": 10.0,"concurrent_requests": 25,"async_mode": "threaded","responses": null,"max_tokens": null,"temperature": 0,"max_completion_tokens": null,"reasoning_effort": null,"top_p": 1,"n": 1,"frequency_penalty": 0.0,"presence_penalty": 0.0},"default_embedding_model": {"api_key": "==== REDACTED ====","auth_type": "api_key","type": "openai_embedding","model": "text-embedding-3-small","encoding_model": "cl100k_base","api_base": "https://api.openai-hk.com/v1/","api_version": null,"deployment_name": null,"proxy": null,"audience": null,"model_supports_json": true,"request_timeout": 180.0,"tokens_per_minute": null,"requests_per_minute": null,"retry_strategy": "native","max_retries": 10,"max_retry_wait": 10.0,"concurrent_requests": 25,"async_mode": "threaded","responses": null,"max_tokens": null,"temperature": 0,"max_completion_tokens": null,"reasoning_effort": null,"top_p": 1,"n": 1,"frequency_penalty": 0.0,"presence_penalty": 0.0}},"input": {"storage": {"type": "file","base_dir": "C:\\Users\\kongyue\\ragtest\\input","storage_account_blob_url": null,"cosmosdb_account_url": null},"file_type": "text","encoding": "utf-8","file_pattern": ".*\\.txt$","file_filter": null,"text_column": "text","title_column": null,"metadata": null},"chunks": {"size": 1200,"overlap": 100,"group_by_columns": ["id"],"strategy": "tokens","encoding_model": "cl100k_base","prepend_metadata": false,"chunk_size_includes_metadata": false},"output": {"type": "file","base_dir": "C:\\Users\\kongyue\\ragtest\\output","storage_account_blob_url": null,"cosmosdb_account_url": null},"outputs": null,"update_index_output": {"type": "file","base_dir": "C:\\Users\\kongyue\\ragtest\\update_output","storage_account_blob_url": null,"cosmosdb_account_url": null},"cache": {"type": "file","base_dir": "cache","storage_account_blob_url": null,"cosmosdb_account_url": null},"reporting": {"type": "file","base_dir": "C:\\Users\\kongyue\\ragtest\\logs","storage_account_blob_url": null},"vector_store": {"default_vector_store": {"type": "lancedb","db_uri": "C:\\Users\\kongyue\\ragtest\\output\\lancedb","url": null,"audience": null,"container_name": "==== REDACTED ====","database_name": null,"overwrite": true}},"workflows": null,"embed_text": {"model_id": "default_embedding_model","vector_store_id": "default_vector_store","batch_size": 16,"batch_max_tokens": 8191,"names": ["entity.description","community.full_content","text_unit.text"],"strategy": null},"extract_graph": {"model_id": "default_chat_model","prompt": "prompts/extract_graph.txt","entity_types": ["organization","person","geo","event"],"max_gleanings": 1,"strategy": null},"summarize_descriptions": {"model_id": "default_chat_model","prompt": "prompts/summarize_descriptions.txt","max_length": 500,"max_input_tokens": 4000,"strategy": null},"extract_graph_nlp": {"normalize_edge_weights": true,"text_analyzer": {"extractor_type": "regex_english","model_name": "en_core_web_md","max_word_length": 15,"word_delimiter": " ","include_named_entities": true,"exclude_nouns": ["stuff","thing","things","bunch","bit","bits","people","person","okay","hey","hi","hello","laughter","oh"],"exclude_entity_tags": ["DATE"],"exclude_pos_tags": ["DET","PRON","INTJ","X"],"noun_phrase_tags": ["PROPN","NOUNS"],"noun_phrase_grammars": {"PROPN,PROPN": "PROPN","NOUN,NOUN": "NOUNS","NOUNS,NOUN": "NOUNS","ADJ,ADJ": "ADJ","ADJ,NOUN": "NOUNS"}},"concurrent_requests": 25},"prune_graph": {"min_node_freq": 2,"max_node_freq_std": null,"min_node_degree": 1,"max_node_degree_std": null,"min_edge_weight_pct": 40.0,"remove_ego_nodes": true,"lcc_only": false},"cluster_graph": {"max_cluster_size": 10,"use_lcc": true,"seed": 3735928559},"extract_claims": {"enabled": false,"model_id": "default_chat_model","prompt": "prompts/extract_claims.txt","description": "Any claims or facts that could be relevant to information discovery.","max_gleanings": 1,"strategy": null},"community_reports": {"model_id": "default_chat_model","graph_prompt": "prompts/community_report_graph.txt","text_prompt": "prompts/community_report_text.txt","max_length": 2000,"max_input_length": 8000,"strategy": null},"embed_graph": {"enabled": false,"dimensions": 1536,"num_walks": 10,"walk_length": 40,"window_size": 2,"iterations": 3,"random_seed": 597832,"use_lcc": true},"umap": {"enabled": false},"snapshots": {"embeddings": false,"graphml": false,"raw_graph": false},"local_search": {"prompt": "prompts/local_search_system_prompt.txt","chat_model_id": "default_chat_model","embedding_model_id": "default_embedding_model","text_unit_prop": 0.5,"community_prop": 0.15,"conversation_history_max_turns": 5,"top_k_entities": 10,"top_k_relationships": 10,"max_context_tokens": 12000},"global_search": {"map_prompt": "prompts/global_search_map_system_prompt.txt","reduce_prompt": "prompts/global_search_reduce_system_prompt.txt","chat_model_id": "default_chat_model","knowledge_prompt": "prompts/global_search_knowledge_system_prompt.txt","max_context_tokens": 12000,"data_max_tokens": 12000,"map_max_length": 1000,"reduce_max_length": 2000,"dynamic_search_threshold": 1,"dynamic_search_keep_parent": false,"dynamic_search_num_repeats": 1,"dynamic_search_use_summary": false,"dynamic_search_max_level": 2},"drift_search": {"prompt": "prompts/drift_search_system_prompt.txt","reduce_prompt": "prompts/drift_search_reduce_prompt.txt","chat_model_id": "default_chat_model","embedding_model_id": "default_embedding_model","data_max_tokens": 12000,"reduce_max_tokens": null,"reduce_temperature": 0,"reduce_max_completion_tokens": null,"concurrency": 32,"drift_k_followups": 20,"primer_folds": 5,"primer_llm_max_tokens": 12000,"n_depth": 3,"local_search_text_unit_prop": 0.9,"local_search_community_prop": 0.1,"local_search_top_k_mapped_entities": 10,"local_search_top_k_relationships": 10,"local_search_max_data_tokens": 12000,"local_search_temperature": 0,"local_search_top_p": 1,"local_search_n": 1,"local_search_llm_max_gen_tokens": null,"local_search_llm_max_gen_completion_tokens": null},"basic_search": {"prompt": "prompts/basic_search_system_prompt.txt","chat_model_id": "default_chat_model","embedding_model_id": "default_embedding_model","k": 10,"max_context_tokens": 12000}
}
2025-07-22 19:01:34.0067 - INFO - graphrag.api.index - Initializing indexing pipeline...
2025-07-22 19:01:34.0067 - INFO - graphrag.index.workflows.factory - Creating pipeline with workflows: ['load_input_documents', 'create_base_text_units', 'create_final_documents', 'extract_graph', 'finalize_graph', 'extract_covariates', 'create_communities', 'create_final_text_units', 'create_community_reports', 'generate_text_embeddings']
2025-07-22 19:01:34.0068 - INFO - graphrag.storage.file_pipeline_storage - Creating file storage at C:\Users\kongyue\ragtest\input
2025-07-22 19:01:34.0068 - INFO - graphrag.storage.file_pipeline_storage - Creating file storage at C:\Users\kongyue\ragtest\output
2025-07-22 19:01:34.0077 - INFO - graphrag.index.run.run_pipeline - Running standard indexing.
2025-07-22 19:01:34.0083 - INFO - graphrag.index.run.run_pipeline - Executing pipeline...
2025-07-22 19:01:34.0084 - INFO - graphrag.index.input.factory - loading input from root_dir=C:\Users\kongyue\ragtest\input
2025-07-22 19:01:34.0085 - INFO - graphrag.index.input.factory - Loading Input InputFileType.text
2025-07-22 19:01:34.0086 - INFO - graphrag.storage.file_pipeline_storage - search C:\Users\kongyue\ragtest\input for files matching .*\.txt$
2025-07-22 19:01:34.0098 - INFO - graphrag.index.input.util - Found 1 InputFileType.text files, loading 1
2025-07-22 19:01:34.0099 - INFO - graphrag.index.input.util - Total number of unfiltered InputFileType.text rows: 1
2025-07-22 19:01:34.0100 - INFO - graphrag.index.workflows.load_input_documents - Final # of rows loaded: 1
2025-07-22 19:01:34.0146 - INFO - graphrag.api.index - Workflow load_input_documents completed successfully
2025-07-22 19:01:34.0162 - INFO - graphrag.index.workflows.create_base_text_units - Workflow started: create_base_text_units
2025-07-22 19:01:34.0163 - INFO - graphrag.utils.storage - reading table from storage: documents.parquet
2025-07-22 19:01:34.0215 - INFO - graphrag.index.workflows.create_base_text_units - Starting chunking process for 1 documents
2025-07-22 19:01:34.0524 - INFO - graphrag.index.workflows.create_base_text_units - chunker progress: 1/1
2025-07-22 19:01:34.0542 - INFO - graphrag.index.workflows.create_base_text_units - Workflow completed: create_base_text_units
2025-07-22 19:01:34.0542 - INFO - graphrag.api.index - Workflow create_base_text_units completed successfully
2025-07-22 19:01:34.0553 - INFO - graphrag.index.workflows.create_final_documents - Workflow started: create_final_documents
2025-07-22 19:01:34.0554 - INFO - graphrag.utils.storage - reading table from storage: documents.parquet
2025-07-22 19:01:34.0564 - INFO - graphrag.utils.storage - reading table from storage: text_units.parquet
2025-07-22 19:01:34.0598 - INFO - graphrag.index.workflows.create_final_documents - Workflow completed: create_final_documents
2025-07-22 19:01:34.0599 - INFO - graphrag.api.index - Workflow create_final_documents completed successfully
2025-07-22 19:01:34.0611 - INFO - graphrag.index.workflows.extract_graph - Workflow started: extract_graph
2025-07-22 19:01:34.0612 - INFO - graphrag.utils.storage - reading table from storage: text_units.parquet
2025-07-22 19:12:35.0481 - INFO - graphrag.logger.progress - extract graph progress: 1/11
2025-07-22 19:13:35.0500 - INFO - graphrag.logger.progress - extract graph progress: 2/11
2025-07-22 19:14:35.0510 - INFO - graphrag.logger.progress - extract graph progress: 3/11
2025-07-22 19:15:35.0521 - INFO - graphrag.logger.progress - extract graph progress: 4/11
2025-07-22 19:16:35.0522 - INFO - graphrag.logger.progress - extract graph progress: 5/11
2025-07-22 19:17:35.0527 - INFO - graphrag.logger.progress - extract graph progress: 6/11
2025-07-22 19:18:35.0536 - INFO - graphrag.logger.progress - extract graph progress: 7/11
2025-07-22 19:19:35.0528 - INFO - graphrag.logger.progress - extract graph progress: 8/11
2025-07-22 19:20:35.0540 - INFO - graphrag.logger.progress - extract graph progress: 9/11
2025-07-22 19:21:35.0559 - INFO - graphrag.logger.progress - extract graph progress: 10/11
2025-07-22 19:22:35.0571 - INFO - graphrag.logger.progress - extract graph progress: 11/11
2025-07-22 19:22:36.0175 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 1/70
2025-07-22 19:22:36.0176 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 2/70
2025-07-22 19:22:36.0176 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 3/70
2025-07-22 19:22:36.0176 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 4/70
2025-07-22 19:22:36.0177 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 5/70
2025-07-22 19:22:36.0177 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 6/70
2025-07-22 19:22:36.0178 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 7/70
2025-07-22 19:22:36.0178 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 8/70
2025-07-22 19:22:36.0180 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 9/70
2025-07-22 19:22:36.0181 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 10/70
2025-07-22 19:22:36.0181 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 11/70
2025-07-22 19:22:36.0181 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 12/70
2025-07-22 19:22:36.0182 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 13/70
2025-07-22 19:22:36.0187 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 14/70
2025-07-22 19:22:36.0188 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 15/70
2025-07-22 19:22:36.0188 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 16/70
2025-07-22 19:22:36.0188 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 17/70
2025-07-22 19:22:36.0189 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 18/70
2025-07-22 19:22:36.0189 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 19/70
2025-07-22 19:22:36.0189 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 20/70
2025-07-22 19:22:36.0190 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 21/70
2025-07-22 19:22:36.0190 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 22/70
2025-07-22 19:22:36.0204 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 23/70
2025-07-22 19:22:36.0205 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 24/70
2025-07-22 19:22:36.0206 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 25/70
2025-07-22 19:22:36.0206 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 26/70
2025-07-22 19:22:36.0207 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 27/70
2025-07-22 19:22:36.0207 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 28/70
2025-07-22 19:22:36.0208 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 29/70
2025-07-22 19:22:36.0208 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 30/70
2025-07-22 19:22:36.0209 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 31/70
2025-07-22 19:22:40.0791 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 32/70
2025-07-22 19:23:42.0152 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 33/70
2025-07-22 19:23:42.0154 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 34/70
2025-07-22 19:23:42.0154 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 35/70
2025-07-22 19:23:42.0154 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 36/70
2025-07-22 19:23:42.0155 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 37/70
2025-07-22 19:23:42.0155 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 38/70
2025-07-22 19:23:42.0155 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 39/70
2025-07-22 19:23:42.0156 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 40/70
2025-07-22 19:23:42.0156 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 41/70
2025-07-22 19:23:42.0157 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 42/70
2025-07-22 19:23:42.0157 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 43/70
2025-07-22 19:23:42.0157 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 44/70
2025-07-22 19:23:42.0158 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 45/70
2025-07-22 19:23:42.0158 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 46/70
2025-07-22 19:23:42.0158 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 47/70
2025-07-22 19:23:42.0159 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 48/70
2025-07-22 19:23:42.0160 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 49/70
2025-07-22 19:23:42.0160 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 50/70
2025-07-22 19:23:42.0160 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 51/70
2025-07-22 19:23:42.0162 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 52/70
2025-07-22 19:23:42.0162 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 53/70
2025-07-22 19:23:42.0164 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 54/70
2025-07-22 19:23:42.0165 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 55/70
2025-07-22 19:23:42.0165 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 56/70
2025-07-22 19:23:42.0166 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 57/70
2025-07-22 19:23:42.0166 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 58/70
2025-07-22 19:23:42.0167 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 59/70
2025-07-22 19:23:42.0167 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 60/70
2025-07-22 19:23:42.0167 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 61/70
2025-07-22 19:23:42.0168 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 62/70
2025-07-22 19:23:42.0168 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 63/70
2025-07-22 19:23:42.0168 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 64/70
2025-07-22 19:23:42.0174 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 65/70
2025-07-22 19:23:42.0175 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 66/70
2025-07-22 19:25:42.0447 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 67/70
2025-07-22 19:26:39.0431 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 68/70
2025-07-22 19:28:36.0263 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 69/70
2025-07-22 19:29:36.0272 - INFO - graphrag.logger.progress - Summarize entity/relationship description progress: 70/70
2025-07-22 19:29:36.0290 - INFO - graphrag.index.workflows.extract_graph - Workflow completed: extract_graph
2025-07-22 19:29:36.0291 - INFO - graphrag.api.index - Workflow extract_graph completed successfully
2025-07-22 19:29:36.0323 - INFO - graphrag.index.workflows.finalize_graph - Workflow started: finalize_graph
2025-07-22 19:29:36.0324 - INFO - graphrag.utils.storage - reading table from storage: entities.parquet
2025-07-22 19:29:36.0331 - INFO - graphrag.utils.storage - reading table from storage: relationships.parquet
2025-07-22 19:29:36.0369 - INFO - graphrag.index.workflows.finalize_graph - Workflow completed: finalize_graph
2025-07-22 19:29:36.0369 - INFO - graphrag.api.index - Workflow finalize_graph completed successfully
2025-07-22 19:29:36.0397 - INFO - graphrag.index.workflows.extract_covariates - Workflow started: extract_covariates
2025-07-22 19:29:36.0397 - INFO - graphrag.index.workflows.extract_covariates - Workflow completed: extract_covariates
2025-07-22 19:29:36.0397 - INFO - graphrag.api.index - Workflow extract_covariates completed successfully
2025-07-22 19:29:36.0397 - INFO - graphrag.index.workflows.create_communities - Workflow started: create_communities
2025-07-22 19:29:36.0398 - INFO - graphrag.utils.storage - reading table from storage: entities.parquet
2025-07-22 19:29:36.0406 - INFO - graphrag.utils.storage - reading table from storage: relationships.parquet
2025-07-22 19:29:36.0458 - INFO - graphrag.index.workflows.create_communities - Workflow completed: create_communities
2025-07-22 19:29:36.0458 - INFO - graphrag.api.index - Workflow create_communities completed successfully
2025-07-22 19:29:36.0472 - INFO - graphrag.index.workflows.create_final_text_units - Workflow started: create_final_text_units
2025-07-22 19:29:36.0473 - INFO - graphrag.utils.storage - reading table from storage: text_units.parquet
2025-07-22 19:29:36.0479 - INFO - graphrag.utils.storage - reading table from storage: entities.parquet
2025-07-22 19:29:36.0485 - INFO - graphrag.utils.storage - reading table from storage: relationships.parquet
2025-07-22 19:29:36.0521 - INFO - graphrag.index.workflows.create_final_text_units - Workflow completed: create_final_text_units
2025-07-22 19:29:36.0521 - INFO - graphrag.api.index - Workflow create_final_text_units completed successfully
2025-07-22 19:29:36.0537 - INFO - graphrag.index.workflows.create_community_reports - Workflow started: create_community_reports
2025-07-22 19:29:36.0538 - INFO - graphrag.utils.storage - reading table from storage: relationships.parquet
2025-07-22 19:29:36.0545 - INFO - graphrag.utils.storage - reading table from storage: entities.parquet
2025-07-22 19:29:36.0550 - INFO - graphrag.utils.storage - reading table from storage: communities.parquet
2025-07-22 19:29:36.0570 - INFO - graphrag.index.operations.summarize_communities.graph_context.context_builder - Number of nodes at level=0 => 20
2025-07-22 19:32:37.0302 - INFO - graphrag.logger.progress - level 0 summarize communities progress: 1/3
2025-07-22 19:33:37.0309 - INFO - graphrag.logger.progress - level 0 summarize communities progress: 2/3
2025-07-22 19:34:37.0322 - INFO - graphrag.logger.progress - level 0 summarize communities progress: 3/3
2025-07-22 19:34:37.0336 - INFO - graphrag.index.workflows.create_community_reports - Workflow completed: create_community_reports
2025-07-22 19:34:37.0337 - INFO - graphrag.api.index - Workflow create_community_reports completed successfully
2025-07-22 19:34:37.0358 - INFO - graphrag.index.workflows.generate_text_embeddings - Workflow started: generate_text_embeddings
2025-07-22 19:34:37.0359 - INFO - graphrag.utils.storage - reading table from storage: documents.parquet
2025-07-22 19:34:37.0366 - INFO - graphrag.utils.storage - reading table from storage: relationships.parquet
2025-07-22 19:34:37.0372 - INFO - graphrag.utils.storage - reading table from storage: text_units.parquet
2025-07-22 19:34:37.0379 - INFO - graphrag.utils.storage - reading table from storage: entities.parquet
2025-07-22 19:34:37.0386 - INFO - graphrag.utils.storage - reading table from storage: community_reports.parquet
2025-07-22 19:34:37.0399 - INFO - graphrag.index.workflows.generate_text_embeddings - Creating embeddings
2025-07-22 19:34:37.0399 - INFO - graphrag.index.operations.embed_text.embed_text - using vector store lancedb with container_name default for embedding entity.description: default-entity-description
2025-07-22 19:34:37.0432 - INFO - graphrag.index.operations.embed_text.embed_text - uploading text embeddings batch 1/1 of size 500 to vector store
2025-07-22 19:34:38.0123 - INFO - graphrag.index.operations.embed_text.strategies.openai - embedding 31 inputs via 31 snippets using 2 batches. max_batch_size=16, batch_max_tokens=8191
2025-07-22 19:34:40.0141 - INFO - graphrag.logger.progress - generate embeddings progress: 1/2
2025-07-22 19:34:40.0145 - INFO - graphrag.logger.progress - generate embeddings progress: 2/2
[2025-07-22T11:34:40Z WARN lance::dataset::write::insert] No existing dataset at C:\Users\kongyue\ragtest\output\lancedb\default-entity-description.lance, it will be created
2025-07-22 19:34:40.0514 - INFO - graphrag.index.operations.embed_text.embed_text - using vector store lancedb with container_name default for embedding community.full_content: default-community-full_content
2025-07-22 19:34:40.0520 - INFO - graphrag.index.operations.embed_text.embed_text - uploading text embeddings batch 1/1 of size 500 to vector store
2025-07-22 19:34:40.0524 - INFO - graphrag.index.operations.embed_text.strategies.openai - embedding 3 inputs via 3 snippets using 1 batches. max_batch_size=16, batch_max_tokens=8191
2025-07-22 19:34:41.0600 - INFO - graphrag.logger.progress - generate embeddings progress: 1/1
[2025-07-22T11:34:41Z WARN lance::dataset::write::insert] No existing dataset at C:\Users\kongyue\ragtest\output\lancedb\default-community-full_content.lance, it will be created
2025-07-22 19:34:41.0626 - INFO - graphrag.index.operations.embed_text.embed_text - using vector store lancedb with container_name default for embedding text_unit.text: default-text_unit-text
2025-07-22 19:34:41.0630 - INFO - graphrag.index.operations.embed_text.embed_text - uploading text embeddings batch 1/1 of size 500 to vector store
2025-07-22 19:34:41.0650 - INFO - graphrag.index.operations.embed_text.strategies.openai - embedding 11 inputs via 11 snippets using 2 batches. max_batch_size=16, batch_max_tokens=8191
2025-07-22 19:34:43.0131 - INFO - graphrag.logger.progress - generate embeddings progress: 1/2
2025-07-22 19:34:43.0213 - INFO - graphrag.logger.progress - generate embeddings progress: 2/2
[2025-07-22T11:34:43Z WARN lance::dataset::write::insert] No existing dataset at C:\Users\kongyue\ragtest\output\lancedb\default-text_unit-text.lance, it will be created
2025-07-22 19:34:43.0241 - INFO - graphrag.index.workflows.generate_text_embeddings - Workflow completed: generate_text_embeddings
2025-07-22 19:34:43.0242 - INFO - graphrag.api.index - Workflow generate_text_embeddings completed successfully
2025-07-22 19:34:43.0303 - INFO - graphrag.index.run.run_pipeline - Indexing pipeline complete.
2025-07-22 19:34:43.0311 - INFO - graphrag.cli.index - All workflows completed successfully.
import osimport pandas as pd
import tiktokenfrom graphrag.query.context_builder.entity_extraction import EntityVectorStoreKey
from graphrag.query.indexer_adapters import (read_indexer_covariates,read_indexer_entities,read_indexer_relationships,read_indexer_reports,read_indexer_text_units,
)
from graphrag.query.question_gen.local_gen import LocalQuestionGen
from graphrag.query.structured_search.local_search.mixed_context import (LocalSearchMixedContext,
)
from graphrag.query.structured_search.local_search.search import LocalSearch
from graphrag.vector_stores.lancedb import LanceDBVectorStore
五 局部查询过程
5.1 本地搜索
graphrag query --root ./ --method local --query "什么是graphrag?"
(graphrag) C:\Users\kongyue\ragtest>graphrag query --root ./ --method local --query "什么是graphrag?"
2025-07-23 10:13:10.0195 - INFO - graphrag.storage.file_pipeline_storage - Creating file storage at C:\Users\kongyue\ragtest\output
2025-07-23 10:13:10.0199 - INFO - graphrag.utils.storage - reading table from storage: communities.parquet
2025-07-23 10:13:10.0221 - INFO - graphrag.utils.storage - reading table from storage: community_reports.parquet
2025-07-23 10:13:10.0232 - INFO - graphrag.utils.storage - reading table from storage: text_units.parquet
2025-07-23 10:13:10.0241 - INFO - graphrag.utils.storage - reading table from storage: relationships.parquet
2025-07-23 10:13:10.0250 - INFO - graphrag.utils.storage - reading table from storage: entities.parquet
2025-07-23 10:13:18.0148 - INFO - graphrag.cli.query - Local Search Response:
### GraphRAG OverviewGraphRAG is an innovative framework designed to integrate traditional graph database queries with advanced generative models to effectively extract knowledge graphs from extensive text data. This system is specifically tailored to process large documents or corpora, emphasizing the importance of entity recognition and relationship extraction to construct structured knowledge graphs [Data: Entities (6); Reports (1)].### Key Features and CapabilitiesGraphRAG operates by querying and retrieving information based on the knowledge graphs it builds, employing sophisticated algorithms and language models to enhance its capabilities. The framework not only focuses on the extraction of entities and their interrelations but also incorporates graph-driven semantic search, which allows for more nuanced and context-aware information retrieval. This dual approach significantly improves the generation of responses, making it a powerful tool for users seeking to navigate and utilize large volumes of information efficiently [Data: Entities (6); Reports (1)].### Integration with Advanced TechniquesThe framework utilizes various advanced techniques such as embeddings, semantic matching, and large language models (LLMs) to enhance its functionality. Embeddings provide vector representations of text units, entities, and relationships, enabling similarity calculations essential for effective information retrieval. Semantic matching is employed to rank and filter information based on vector similarity and graph structure, ensuring that the most relevant information is presented to users [Data: Reports (1); Entities (24, 30, 25); Relationships (30, 36, 31)].### Community and Knowledge ExtractionGraphRAG is central to a community focused on knowledge extraction, where techniques like NLP and community clustering play crucial roles. NLP enhances the system's reasoning capabilities, allowing for complex queries and better comprehension of user inputs. Community clustering groups entities and relationships based on similarities, optimizing information processing and retrieval [Data: Reports (1); Entities (8, 16); Relationships (5, 15)].In summary, GraphRAG stands out as a comprehensive system that merges the strengths of graph databases with generative modeling, facilitating the creation and utilization of knowledge graphs for enhanced information processing and retrieval [Data: Entities (6); Reports (1)].
5.2 全局搜索
graphrag query --root ./ --method global--query "什么是graphrag?"
(graphrag) C:\Users\kongyue\ragtest>graphrag query --root ./ --method global --query "什么是graphrag?"
2025-07-23 10:14:02.0385 - INFO - graphrag.storage.file_pipeline_storage - Creating file storage at C:\Users\kongyue\ragtest\output
2025-07-23 10:14:02.0389 - INFO - graphrag.utils.storage - reading table from storage: entities.parquet
2025-07-23 10:14:02.0409 - INFO - graphrag.utils.storage - reading table from storage: communities.parquet
2025-07-23 10:14:02.0419 - INFO - graphrag.utils.storage - reading table from storage: community_reports.parquet
2025-07-23 10:16:08.0209 - INFO - graphrag.cli.query - Global Search Response:
### GraphRAG Framework OverviewGraphRAG is an innovative framework designed to integrate natural language processing (NLP) and advanced generative models for the purpose of extracting knowledge graphs from extensive text data. It serves as a core entity within its community, combining traditional graph database queries with generative models to create structured knowledge graphs from large text corpora. This framework places a strong emphasis on entity recognition and relationship extraction, which are essential for constructing these graphs [Data: Reports (1)].### Enhancing Information RetrievalGraphRAG significantly enhances information retrieval and processing by utilizing NLP techniques. These techniques enable the system to effectively understand and process human language, facilitating the extraction of meaningful insights from text data. This interaction between NLP and GraphRAG is crucial for identifying entities and their interrelations, thereby improving the quality and relevance of the information retrieved [Data: Reports (1)].### Key Processes: Indexing and ClusteringThe framework focuses on processes such as Indexing and Clustering, which are vital for transforming raw text into structured knowledge graphs. Indexing organizes information, thereby enhancing retrieval and reasoning capabilities. Clustering, on the other hand, groups entities based on their relationships and attributes within the knowledge graph, allowing for more efficient data management and retrieval [Data: Reports (0)].### Integration with Large Language ModelsGraphRAG utilizes large language models (LLM) to generate natural language responses based on the context provided by user queries. This integration allows the system to produce coherent and contextually relevant outputs, significantly enhancing the user interaction experience. By leveraging LLMs, GraphRAG can provide more accurate and context-aware responses to user inquiries [Data: Reports (1)].### Optimization TechniquesTo optimize information retrieval and processing, GraphRAG employs techniques such as Community Clustering, Embeddings, and Semantic Matching. These techniques help in organizing the knowledge graph, calculating similarity and relevance, and ranking information based on vector similarity and graph structure. This optimization ensures that the most relevant information is retrieved and presented to the user, improving the overall efficiency and effectiveness of the framework [Data: Reports (1)].In summary, GraphRAG is a comprehensive framework that integrates NLP and generative models to create and manage knowledge graphs, enhancing information retrieval and processing through advanced techniques and processes.