ClickHouse物化视图避坑指南:原理、数据迁移与优化
摘要
ClickHouse物化视图通过预计算和自动更新机制,显著提升大数据分析查询性能,尤其适合高并发聚合场景。本文将深入解析其技术原理、生产实践中的优化策略,以及数据迁移的实战经验。
一、物化视图核心概念
ClickHouse的物化视图(Materialized View)是一种预计算技术,它将查询结果持久化存储,当基表数据变化时自动更新。与普通视图不同,物化视图实际占用存储空间,但能显著提升查询性能,特别适合以下场景:
- 高频执行的聚合查询
- 需要实时分析的大数据量场景
- 多维度组合分析需求
在腾讯云的实际项目中,物化视图集群成功支撑了5000+ QPS的高并发查询,证明了其在生产环境中的可靠性。
二、技术架构与实现原理
2.1 底层机制
ClickHouse物化视图通过触发器机制实现数据同步,当源表发生INSERT操作时自动更新。其核心组件包括:
- 存储引擎:默认使用与原表相同的引擎(通常为MergeTree系列)
- 更新策略:支持全量刷新和增量更新两种模式
- 查询重写:优化器会自动将适合的查询路由到物化视图
2.1.1 存储引擎
1. ClickHouse物化视图存储引擎与原表相同的原因
原因分类 | 具体说明 | 示例/影响 |
数据一致性保障 | 物化视图是原表的衍生数据,相同引擎确保索引结构、分区策略等特性一致 | 原表使用ReplicatedMergeTree时,物化视图自动继承副本同步机制 |
性能对齐 | 相同引擎的压缩算法、存储格式一致,减少ETL过程中的转换开销 | 共享底层数据分片策略,优化分布式查询性能 |
功能兼容性 | 特定功能(如TTL、数据跳过索引)仅在部分引擎中支持,引擎不一致会导致功能失效 | 若原表支持TTL而物化视图引擎不支持,则数据自动清理功能无法生效 |
2. ClickHouse存储引擎分类表
引擎类型 | 核心特性 | 适用场景 | 是否支持物化视图 |
MergeTree系列 | 列存/分区/主键索引/数据压缩 | 大规模数据分析(默认推荐) | 是 |
ReplicatedMergeTree | 增加副本同步与故障恢复能力 | 高可用生产环境 | 是 |
Memory | 纯内存存储,无持久化 | 临时数据/高速缓存 | 否 |
Log | 轻量级日志存储,追加写入 | 流式数据日志 | 否 |
Kafka | 直接消费Kafka消息流 | 实时数据管道 | 否 |
MySQL | 映射外部MySQL表 | 跨数据库查询 | 否 |
Dictionary | 内置字典数据存储 | 维度表/配置表 | 否 |
2.1.2 更新策略
操作类型 | 是否支持 | 具体行为 | 实现方式与限制 |
增量插入 | ✅ 支持 | 自动同步源表INSERT的新数据 | 依赖源表插入事件触发,仅追加新数据块(无法修改历史数据) |
全量刷新 | ⚠️ 间接支持 | 完全重建物化视图数据(覆盖旧版本) | 需手动执行REFRESH或替换表,资源消耗高 |
数据更新 (含修改/删除) | ❌ 不支持 | 无法直接更新或删除物化视图中的已有数据 | 源表的UPDATE/DELETE不会同步到物化视图,需全量刷新或通过ReplacingMergeTree等方案绕行 |
ReplacingMergeTree是ClickHouse专门用于处理数据更新的引擎,通过版本号字段实现去重合并机制:
- 相同排序键(ORDER BY字段)的数据行会被视为同一逻辑记录
- 后台合并时保留版本号最大的记录(或根据其他策略)
- 最终实现类似"更新"的效果
示例
CREATE TABLE example_table
(id UInt32,name String,value Float64,version UInt32, -- 版本号字段event_time DateTime
)
ENGINE = ReplacingMergeTree(version)
ORDER BY (id, name)- version字段作为合并依据,数值大的会覆盖小的
- ORDER BY定义去重逻辑(相当于主键)
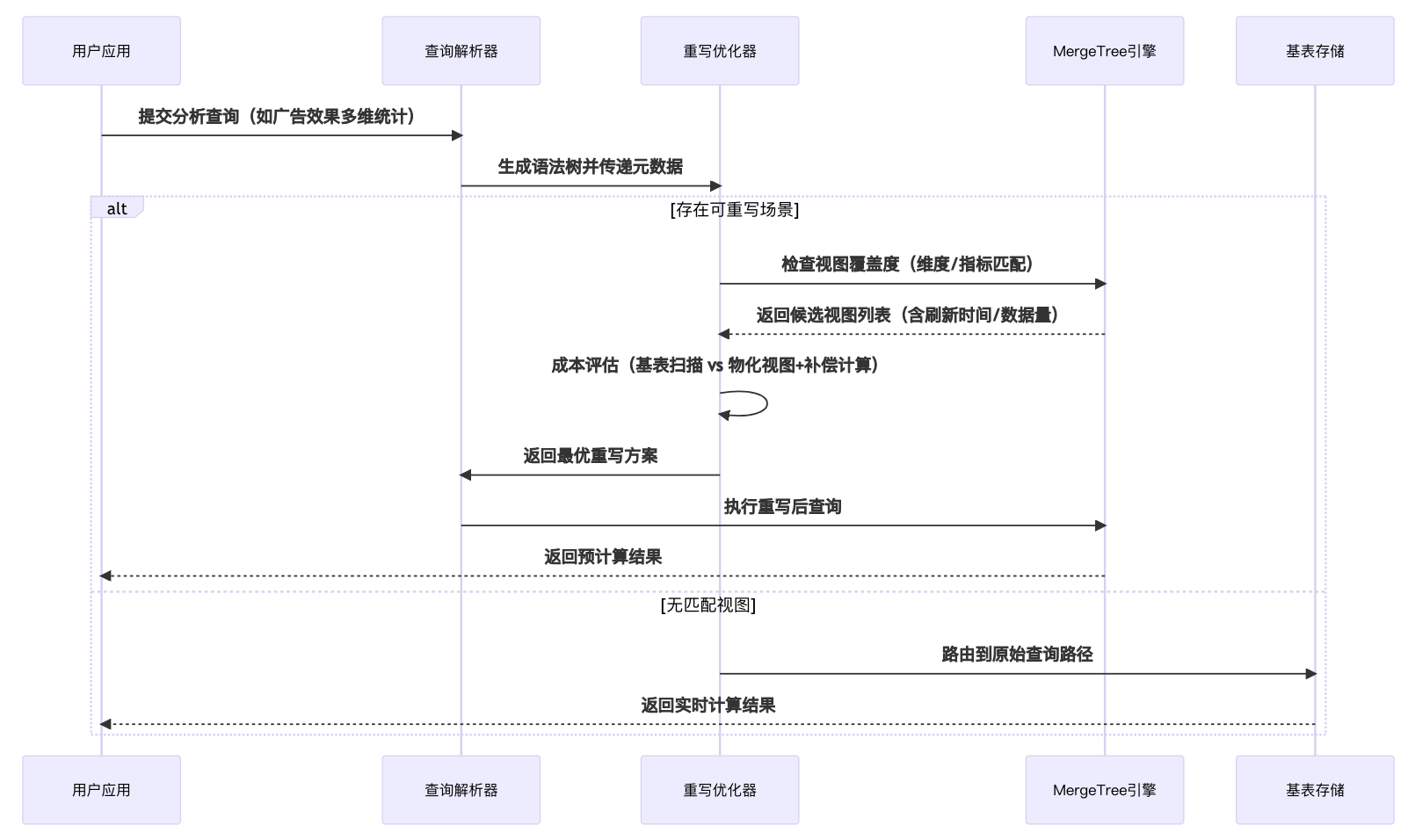
2.1.3 查询重写
是指数据库优化器自动将针对基表的查询转换为对物化视图的查询,从而提升性能的技术。当满足条件时,优化器会"路由"(即重定向)查询到已预计算好的物化视图,避免重复计算原始数据。
自动路由机制详解
- 匹配条件:查询的SELECT/WHERE/GROUP BY等子句与物化视图定义逻辑兼容
- 数据覆盖:物化视图包含查询所需的所有数据(或可通过计算派生)
- 时效性:物化视图数据满足查询的时效性要求(特别是增量更新场景)
工作原理时序图如下:
2. 与分层架构的结合
在腾讯云项目中,物化视图与数据分层架构深度整合:
原始底表 → DWD(轻聚合明细层) → DWS(指标服务层) → 物化视图
数据分层架构:
层级 | 名称 | 技术实现 | 数据处理方式 | 项目应用案例 | 优化效果 |
ODS | 原始数据层 | Flink实时采集+Kafka管道 | 无加工原始日志存储 | 用户行为事件原始日志 | 保留完整数据溯源能力 |
DWD | 明细数据层 | Flink窗口聚合+维度关联 | 轻度清洗标准化 | 广告点击与订单关联明细表 | 查询复杂度降低40% |
DWS | 服务数据层 | ClickHouse物化视图预聚合 | 多维度指标计算 | 广告效果分析聚合表(PV/UV/CTR) | 支撑5000+ QPS查询 |
ADS | 应用数据层 | 动态查询接口+Redis缓存 | 业务定制聚合 | 佣金结算实时报表API | 响应时间<300ms |
三、最佳实践要点:ClickHouse物化视图生产级管理
3.1 库表规划原则
对象类型 | 命名规范 | 存储策略 | 案例 |
基表 | ods_[业务域]_原始表名 | 按日期分区+TTL 7天 | ods_adsdk_click_log |
物化视图表 | mview_[聚合维度]_指标 | 与基表同分区策略+TTL 30天 | mview_advertiser_daily_stats |
中间过程表 | tmp_[用途]_日期 | 内存表或MergeTree临时分区 | tmp_uv_calc_202407 |
关键建议:
- 使用ON CLUSTER语句统一创建分布式对象
- 为物化视图单独建立数据库(如mviews)隔离资源
3.2 安全变更流程(生产环境)
-- 错误做法(阻塞写入且资源消耗大)
CREATE MATERIALIZED VIEW mview_stats
ENGINE=ReplicatedMergeTree
POPULATE -- 全量初始化会导致表锁
AS SELECT...-- 正确做法(分步执行)
-- 1. 创建空视图
CREATE MATERIALIZED VIEW mview_stats
ENGINE=ReplicatedMergeTree
AS SELECT... WHERE 1=0-- 2. 分批插入历史数据
INSERT INTO mview_stats
WITH 3000000 AS batch_size
SELECT * FROM source_table
WHERE create_time <= '2024-07-01'
LIMIT batch_size
-- 循环执行直到覆盖全部历史数据3.3 维度控制黄金法则
- 基数控制:单个物化视图的维度组合不超过5个(如advertiser_id×campaign_id×day)
- 聚合粒度:预聚合到可接受的最粗粒度(分钟级→小时级)
- 字段选择:仅包含查询必需的列,避免SELECT *
四、数据迁移中的物化视图处理
1. 分布式环境迁移核心挑战
- 物化视图不会自动分片:直接使用CREATE MATERIALIZED VIEW ON CLUSTER会导致数据分布不均
- 数据一致性风险:基表与物化视图存在时间差时可能产生脏数据
- 性能瓶颈:全量迁移可能阻塞生产查询
2. 迁移方案
以下是简版迁移脚本:
#!/bin/bash
# 物化视图友好型迁移脚本
# 版本:v2.1-mv-safe# ===== 安全配置 =====
NODES=("node1" "node2" "node3" "node4" "node5") # 逻辑节点标识
TIME_RANGE=("2023-01-01" "2023-12-31")
CHUNK_SIZE=500000 # 每批处理量# ===== 执行迁移 =====
for node in "${NODES[@]}"; doclickhouse-client -h $node --query "INSERT INTO dwd_retail.sales_factSELECT order_id, -- 示例字段customer_code, -- 已脱敏amount,create_timeFROM ods_retail.sales_sourceWHERE create_time BETWEEN '${TIME_RANGE[0]}' AND '${TIME_RANGE[1]}'LIMIT ${CHUNK_SIZE}-- 关键优化参数(无事务保证):SET max_insert_block_size = ${CHUNK_SIZE};SET max_threads = 8; -- 根据CPU核数调整SET parallel_view_processing=1; -- 允许物化视图并行处理"
done3. 生产环境必须遵守的规则
风险点 | 解决方案 |
ZK锁冲突 | 每个分片单独执行脚本,禁止并发创建相同物化视图 |
数据丢失 | 先迁移基表数据,验证通过后再创建物化视图 |
查询中断 | 通过SET max_execution_time=300控制单批执行时间 |
4. 迁移后的校验方法
- 记录数校验缺陷
物化视图的聚合粒度受时间窗口影响,相同源数据可能因条件不同产生不同记录数,仅用count()校验会存在误判。
- 物化视图数据校验策略表
校验维度 | 校验方法 | 检测目标 | 实施频率 | 异常处理 | 技术实现 |
基础完整性校验 | SELECT hostName(), count(), uniqExact(order_no) FROM source_table GROUP BY shard | 分片数据是否完整 | 每次迁移后立即执行 | 触发数据重传机制 | 分布式计数+唯一键校验 |
金额总和比对 | ABS((SELECT sum(amt) FROM source) - (SELECT sum(amt) FROM mview)) < 0.001 | 聚合金额一致性 | 每日全量校验 | 记录差异明细并告警 | 高精度Decimal计算 |
时间窗口覆盖 | SELECT min(insert_time), max(insert_time) FROM mview WHERE day = '2025-07-18' | 物化视图是否覆盖完整时间范围 | 按批次校验 | 补数缺失时间段 | 时间区间边界检测 |
维度下钻校验 | WITH dim_diff AS ( SELECT ka_id FROM source_dim EXCEPT SELECT ka_id FROM mview_dim ) SELECT count() FROM dim_diff | 关键维度是否缺失 | 每周全量扫描 | 触发维度表刷新 | 维度差异分析(EXCEPT子句) |
分布式一致性 | SELECT hostName(), sum(amt) FROM mview GROUP BY shard HAVING abs(sum - avg_sum) > threshold | 分片间数据分布是否均衡 | 随机抽查 | 重新平衡分片 | 分片级聚合比对 |
数据新鲜度 | SELECT now() - max(update_time) FROM mview WHERE day = '2025-07-18' | 数据更新是否及时 | 每小时监控 | 触发物化视图刷新 | 时间间隔监控 |
业务规则校验 | SELECT count() FROM mview WHERE paid_amount > 0 AND order_status = 'CANCELED' | 违反业务规则的数据 | 按需执行 | 数据修复工单 | 自定义规则引擎 |
历史数据追溯 | SELECT sumIf(amt, day = '2025-07-18') FROM mview FINAL | MV与源表历史版本一致性 | 每月归档时校验 | 使用FINAL关键字强制合并 | ReplacingMergeTree引擎专用校验 |
我采用了如下校验策略:

5. 特别注意事项
- 时间片选择:脚本中需要根据数据密度调整时间参数,例如:
- 高频数据:10-30分钟为时间窗口
- 低频数据:4-8小时为时间窗口
- 错误恢复:记录每批次的MIN_TIME/MAX_TIME,失败时可从断点续传
五、性能优化策略
1. 设计原则
- 聚合粒度:根据查询模式选择适当的聚合维度
- 字段精简:只包含必要字段,减少存储和计算开销
- TTL设置:为历史数据设置合理的生命周期
2. 实战优化技巧
- 预聚合计算:将分钟级数据预聚合为小时/天级别
- 多级物化:构建层级式物化视图金字塔
- 资源隔离:为物化视图更新分配独立资源池
六、与替代方案对比
方案 | 查询性能 | 数据实时性 | 存储开销 | 适用场景 |
物化视图 | ★★★★★ | ★★★★ | ★★★ | 高频聚合查询 |
普通视图 | ★★ | ★★★★★ | ★ | 临时分析 |
预聚合表 | ★★★★ | ★★ | ★★★★ | 固定维度分析 |
实时计算 | ★★★ | ★★★★★ | ★★ | 复杂事件处理 |
七、结论
物化视图作为数据库性能优化的利器,其核心价值在于通过预计算+持久化的架构思想,将查询时的计算压力前置到写入阶段。这种设计在实时分析、聚合统计等场景下能带来显著的查询加速效果,但同时也对存储资源和数据一致性管理提出了更高要求。
在实际应用中,开发者需要权衡查询性能提升与存储/维护成本之间的关系:
- 对于高频分析的固定维度聚合,物化视图能带来数量级的性能提升
- 需配套设计基表更新策略和TTL机制,避免"物化膨胀"问题
- 在分布式系统中要特别注意跨节点数据一致性的处理
随着实时数仓的发展,物化视图技术正在与流式计算、增量更新等能力深度融合,成为现代数据架构中不可或缺的加速层组件。