【机器学习】第三章 分类算法
现在天气预测越来越准确,预测的时间甚至可以精确到某时某分。我们知道,天气预测是气象台通过卫星对云层进行观察,分析天气图,并结合地形、气候等因素总结而来的。而通过机器学习也能够对事物进行预测,例如根据历年股票数据,对股票价格趋势进行预测。而对以上这些情况的预测,并不是每次都很准确,原因往往有两个,一是数据本身处理不当,二是算法选择上的失误。那对于不同的问题,应该选择何种算法呢?
从本章开始,读者将会进入机器学习算法的学习。本章主要对监督学习中的分类算法进行介绍,包括每种分类算法的介绍、应用及优缺点。
3.1 K近邻算法
3.1.1 算法介绍
K近邻(K-nearest neighbor,KNN)算法是分类算法中最简单的算法之一,也是一种理论很成熟的机器学习算法。KNN算法的核心思想是“近朱者赤,近墨者黑”,即KNN算法会根据训练集的数据构建一个模型,然后对于输入的新数据,算法会将其特征与训练集中数据对应的特征进行比对和匹配,在训练集中找到与之较为相似的k个数据,来判断其标签。如果一个样本在特征空间中有k个最邻近的样本,其中大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别中样本的特性。
假设有若干猫和狗的数据,其中包括听力、面容、生活习性等特征,且有猫和狗两个标签。然后通过KNN算法进行建模,给出一只狗的数据,算法能够根据特征给狗的数据贴上狗的标签。若再给出一只老虎的数据,算法此时就会根据老虎的特征进行判断,假如训练集中与老虎数据所邻近的k个数据中,大多数属于猫类,那么会给老虎数据贴上猫的标签。
那么这k个邻近的样本是如何计算出来的?在邻近样本中一半属于A类,一半属于B类的情况下应该如何处理?下面是KNN算法构造函数的参数,可以看到KNN算法有多个参数,但算法中有3类参数比较重要,分别是算法中的权重weights,距离度量方式的选择p、metric,k值n_neighbors。只要这3类参数确定了,算法的预测方式就确定了。

1.分类决策 KNN算法的分类决策规则通常采用多数表决法,即由k个邻近样本中大多数样本所属的类别决定输入样本的类别。如果存在两个类别,其包含的邻近样本的个数相同,这时权重weights就起到了作用,通过给邻近样本的距离加权从两个类别中选择一个,这也是KNN算法风险较小的原因。由于一般情况下不改变邻近样本的距离,遇到类别有相同个数的邻近样本的情况比较少,并且遇到后可以改变k值再次分类,因此我们可以把重点放在距离度量方式和k值选择上。
2.距离度量方式 距离度量方式是KNN算法选择数据所属类别的直接核心,新的测试集数据会从训练集中寻找与其距离最近的数据。那么距离是按照什么计算的呢?
在KNN算法中,常用的距离有3种,分别为欧氏距离、曼哈顿距离和闵可夫斯基距离。KNN算法默认使用欧氏距离,最常用的也是欧氏距离。下面是3种距离度量的公式,其中x|,x2,x、J2,"分别是两个数据的特征值。
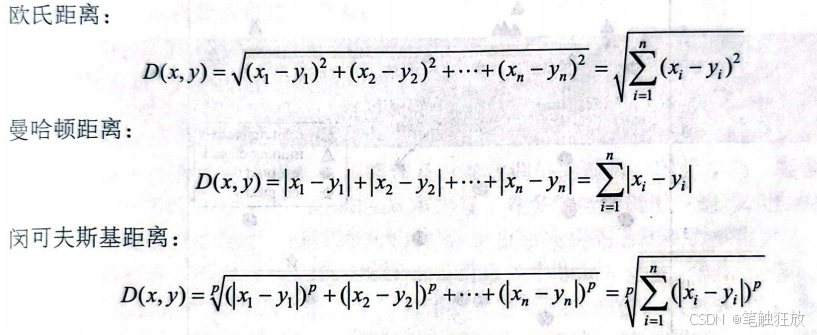
距离度量方式的选择在KNN算法构造函数中由两个参数控制,一个是p,另一个是metric。当metric='minkowski',p为2时表示欧氏距离、p为1时表示曼哈顿距离、p为其他值时表示闵可夫斯基距离。从上面的公式可以看出,欧氏距离、曼哈顿距离是闵可夫斯基距离的特例。
3.k值选择 k值的选择是非常重要的环节。当k=1时,称该算法为最近邻算法。
当选择的k值较小时,就相当于用较小的领域中的训练实例进行预测,训练误差、近似误差小,泛化误差会增大。预测结果对近邻的实例非常敏感,若此时近邻的实例存在噪声,预测就会出错。换句话说,k值较小就意味着整体模型变得复杂,容易发生过拟合。
当选择的k值较大时,就相当于用较大的领域中的训练实例进行预测,泛化误差小,但缺点是近似误差大。一个极端是k等于总实例数m,则完全无法分类,此时无论输入实例是什么,都只是简单地预测它属于训练实例个数最多的类,导致模型过于简单。换句话说,值较大就意味着整体模型变得简单,容易发生欠拟合。
k值的选择会对KNN算法的精度产生重大影响,因此说k值的选择有着极其重要的意义。
在实际的应用中,通常会选择较小的k值。由于k值小意味着整体的模型变得复杂,容易发生过拟合,因此通常采用交叉验证的方式选择最优的k值。交叉验证在后文中讲述。
KNN算法的原理比较简单,在确定分类的决策上只依据最邻近的一个或者几个样本的类别来决定待分类样本所属的类别,在理想状态下这是一个最为简单、有效的方法。但当训练集中出现噪声,即比较离谱的特殊样本时,KNN算法有时也会存在误差,例如选择k值为1,而此时待分类样本刚好离噪声最近,这时预测结果可能并不是该样本真实所属的类别。
3.1.2 算法实现
在读者对KNN算法的原理和参数有了一定了解后,下面利用sklearn中的数据集来实现应用。 在分类中,利用mglearn库进行可视化,观察KNN算法的工作原理。当k=1时,代码如下

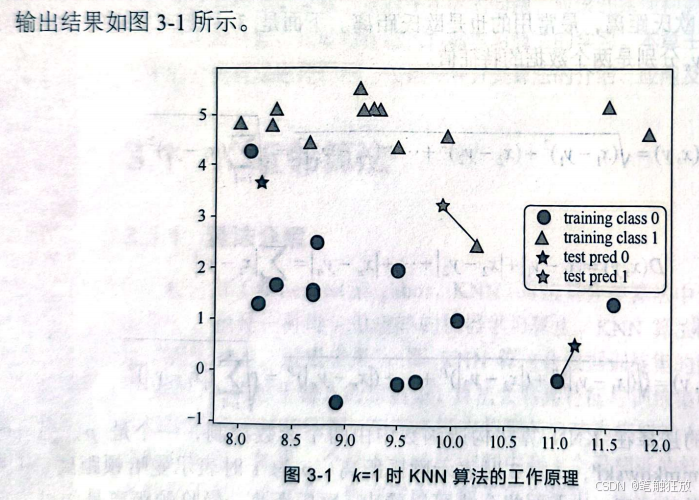

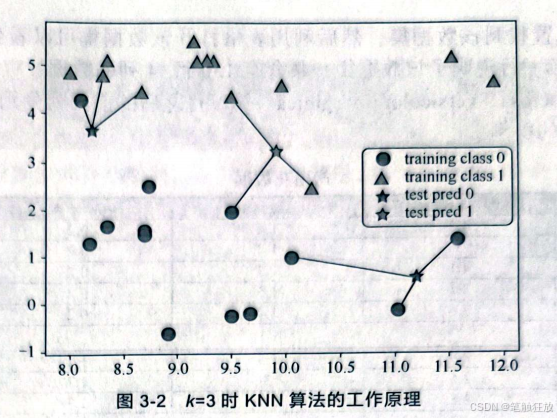
下面将利用KNN算法来对分类问题的数据集进行处理。通常我们需要的数据集可以在加州大学尔湾分校的网站上下载,下载完成后将其保存在项目的统计目录中,然后对数据进行导入。导入的方法有很多,例如利用Python的标准类库CSV、使用NumPy的loadtxtO函数,或者使用 pandas的read.csv(函数,该函数返回的值是DataFrame类型的。一般使用pandas来导入数据,例如对鸢尾花数据集进行导入:

在算法讲解中,要注重读者对算法原理及对参数调整的理解,因此本书一般使用sklearm库中的数据集,不必再进行导入。在sklearn中内置了许多数据集供用户练习,其中就有经典的数据集之一——鸢尾花数据集,接下来我们将KNN算法应用到鸢尾花数据集。
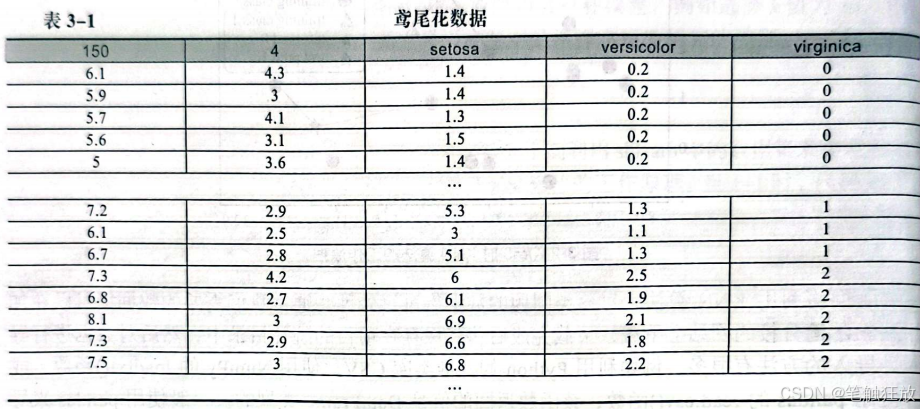
鸢尾花数据集是一个三分类问题,其返回类型是一个bunch对象,类似Python中的字典,因此可以使用Python中字典的功能,例如利用键来查看相应的值。数据集内包含3个种类,共150条数据,每类各50个数据。数据集有4项特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度),可以通过这4项特征预测鸢尾花属于setosa、versicolor、virginica中的哪一个标签(即类别)。
首先,可以从sklearn库的datasets模板中导入鸢尾花数据集。然后输出鸢尾花的键。

从输出结果可以看到鸢尾花的键包括 data、target、target_names、DESCR、feature_names、filename等。
filename用于输出数据集所在位置。

可以通过该设置找到该数据集,然后利用表格打开该数据集可以看到其中的鸢尾花数据(见表3-1)。表中第一行说明了该数据集一共含有150行×4列的数据,根据这些数据可以分为3个类别,分别是 setosa、versicolor、virginica。第二行之后的前四列分别是每一个属性的值,最后一列是该数据的类别。
data里面包括了数据集中的数据,这里用表格的形式输出,方便查看。可以看到共有150行、4列的数据:
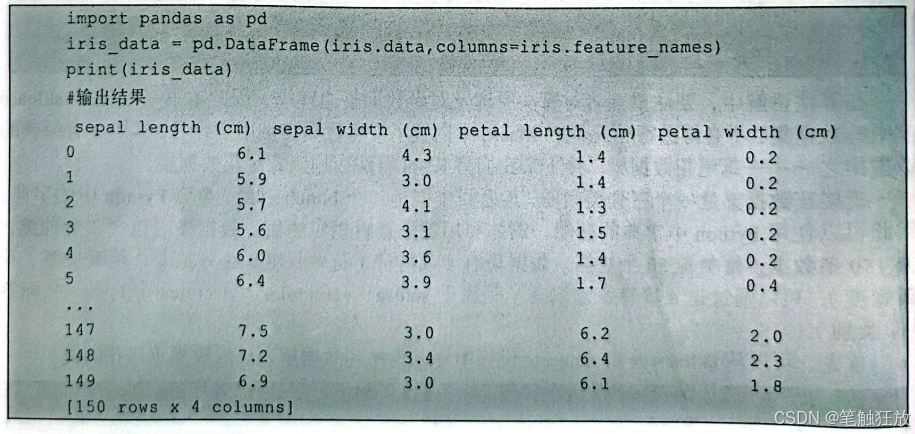




从上述对数据集的查看可以看出,数据中没有缺失值或者异常值,不需要对数据进行预处理等操作;而且数据是按照类别存放的,前50个为setosa,中间50个为versicolor,后50个为virginica。还可以通过以下方式对每条数据进行查看:

从输出结果看到,鸢尾花数据集中第一个数据的信息:花萼长6.1cm、花萼宽4.3cm、花瓣长1.4cm、花瓣宽0.2cm,目标值为0,即属于带刺类(setosa)。
了解了鸢尾花数据集,接下来用KNN算法建立模型。先导入、加载鸢尾花数据集。由于鸢尾花数据集中的数据是按照所属类别排列好的,不用再进行数据预处理,直接进行划分即可。利用sklearn的 model_selection选择train_test_split。train_test_split 的功能是将数据集随机打乱,划分为训练集和测试集,默认划分方式为:训练集数据个数:测试集数据个数→3:1。
然后分别用4个变量对应训练集的特征值、测试集的特征值、训练集的目标值、测试集的目标值,一般使用X_train、X_test、y_train、y_test作为变量名。变量名可以改变,但所赋值的顺序不能改变,即第一个必须是训练集的特征值,第二个必须是测试集的特征值,依此类推。

其中random_state随机数种子就是该组随机数的编号,在需要重复试验的时候,使用它可以保证得到一组一样的随机数。例如将其设置为1,在其他参数一样的情况下,下次得到的结果仍然不变。当将其设置为None时,产生的随机数组也会是随机的。
接下来,要从sklearn的neighbors中导入KNN分类器(KNeighborsClassifier)。因为数据量比较小,所以这里选择neighbors为1的最近邻情况,其余选择默认。

再利用KNN算法的fit()方法对训练集进行拟合。fit()方法传入训练集的特征值和目标值,然后对KNN模型进行训练,并将记录的各个样本的位置返回KNN对象本身。
![]()
最后通过对测试集精度的观察,确定模型的好坏。查看精度可以直接运用KNN算法中的score()方法。

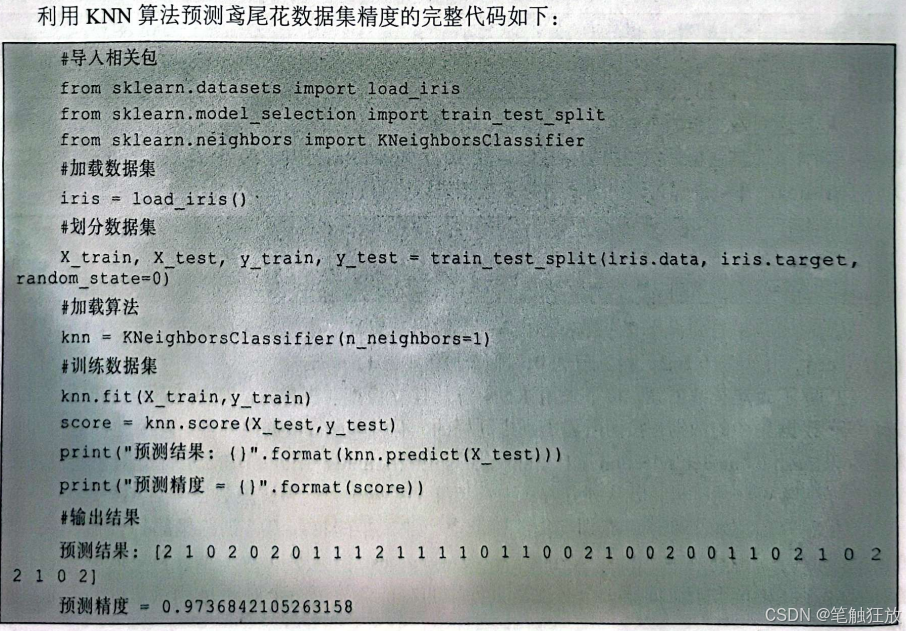
上述就是利用KNN算法预测鸢尾花数据集分类的精度结果。
鸢尾花数据集是一个三分类问题,KNN算法还能对二分类问题进行预测。下面将创建一个小型的数据集 一make_forge,代码如下:


这个数据集只有10个数据、2个特征,是一个二分类问题,只有2个特征可以用来实现可视化观察数据。

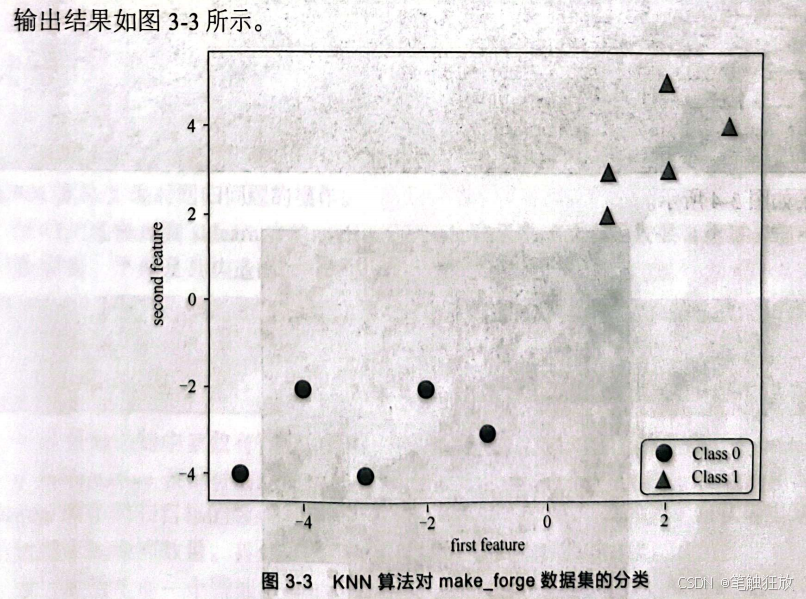



可以看到精度为100%(1.0),因为数据较少,且两类之间数据相对密集,所以其精度非常高。
接下来查看KNN算法的决策边界。代码如下:

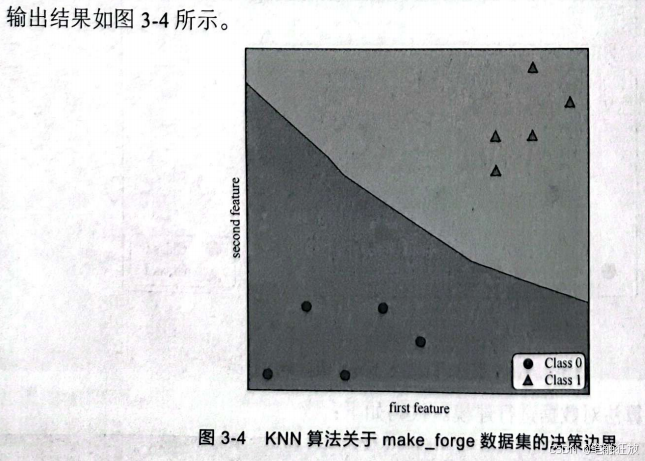
通过可视化结果可以清楚地看到,机器拟合的决策边界比较平滑,这是因为数据集比较简单。一般情况下,随着k值的减小,模型的复杂度越高,决策边界越复杂。
KNN算法虽然是一种分类算法,但是可以用于回归问题。在分类任务中可使用多数表决法,选择k个样本中出现次数最多的类别标记作为预测结果;在回归任务中可使用平均法,将k个样本的实值的平均值作为预测结果,当然还可使用基于距离远近程度进行加权平均等方法。
利用mglearn查看KNN算法的工作原理。代码如下:

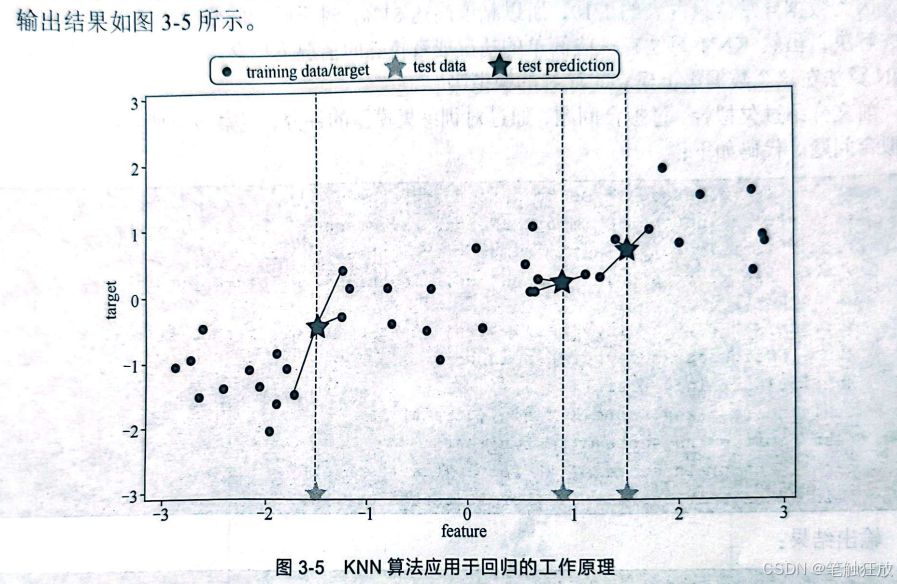
KNN算法应用于回归的工作原理与分类一致,都采用KNN算法通过距离来衡量。下面将用KNN算法实现对回归问题的操作。
回归问题将用到sklearn中的make_regression)函数。这个函数很有意思,它可以用于生成回归数据集,下面是其构造函数的代码:

可以看到函数中参数有很多:n_samples表示生成数据集的数据数量;n_features表示特征数;n_informative表示有信息的特征数量,也就是用来构造线性模型,生成输出的特征数量;n_targets表示回归目标的数量,对应于一个样本的输出向量y的维度,默认输出是标量;noise表示数据中的噪声数量。其他参数读者可通过资料自行查看其含义。
通过函数生成一个特征数为1、包含100个数据的回归数据集,噪声数量为12,该数据集用于实现 KNN 算法:
![]()


因为数据异常值只占大约1/10,所以精度高达81%。对于回归问题,一般用专用的回归算法去解决,虽然KNN算法在一些简单的情况或者特殊的情况下也会得到很好的模型,但这是KNN算法在这个数据集上建立的最好的模型吗?
前文介绍过欠拟合、过拟合问题,通过对训练集模型的评分,观察该模型是否存在过拟合欠拟合问题。代码如下:


模型在训练集上的评分达到了100%,比在测试集上的评分高很多,因此明显存在过拟合问题。在KNN算法中,还未对算法的参数进行调整。因为在这个数据集中含有大约1/10的噪声,所以如果将k值设置为1,明显会出现过拟合问题。接下来通过对k值进行调整来解决这个问题:


将k值设置为3,模型在测试集上的评分明显有了提高,但这也不一定是最优模型。读者可对参数进行调整,寻找精度更高的模型。
KNN算法还可以对回归问题进行可视化,以方便理解。代码如下:

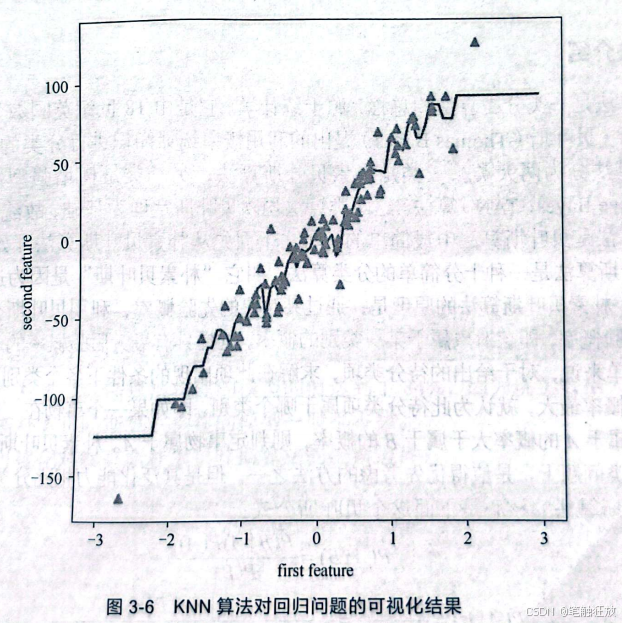
图3-6中的三角形表示数据集中的数据,线则表示KNN算法对数据预测的模型。可以看到在左下角和右上角有两个明显的异常值,如果将k值设置为1,KNN算法将对其进行拟合,影响模型的精度。
3.1.3 算法的优缺点
优点 (1)KNN可以处理分类问题,也可以处理多分类问题,例如鸢尾花数据集的分类。 (2)KNN简单、好用、容易理解,精度高,理论成熟,同时也很强大,对手写数字的识别、鸢尾花数据集的分类这一类问题来说,其准确率很高。 (3)KNN可以用于分类问题也可以用于回归问题,可以用于数值型数据也可以用于离散型数据,无数据输入假定,对异常值不敏感。
缺点 (1)KNN的时间复杂度和空间复杂度高。每一次分类或者回归,KNN要把训练数据和测试数据都算一遍,如果数据量很大的话,需要的算力会很惊人。但是在机器学习中,大数据处理又是一件很常见的事。一般数据量很大的时候KNN计算量太大,但是数据又不能太少,否则容易发生误分。 (2)KNN对训练数据的依赖度特别高,且对训练数据的容错性太差。虽然大多数机器学习的算法对数据的依赖度都很高,但是KNN尤其严重。如果训练数据集中,有一两个数据是错误的,刚好错误数据又在需要分类的数据的旁边,这样就会直接导致KNN分类不准确。 (3)KNN最大的缺点是无法给出数据的内在含义。
3.2 朴素贝叶斯算法
3.2.1 算法介绍
贝叶斯算法是一类分类算法的总称,源于统计学。它是由18世纪英国数学家、贝叶斯学派创始人托马斯·贝叶斯(ThomasBayes)提出的利用概率统计知识进行分类的方法演变而来的。
贝叶斯算法分为两大类,一类是朴素贝叶斯算法,另一类是树增强型朴素贝叶斯(treeaugmented naiveBayes,TAN)算法。这两类算法均以贝叶斯定理为基础,故统称为贝叶斯算法。朴素贝叶斯算法是贝叶斯算法中最简单的一种,下面先从朴素贝叶斯算法开始介绍。
朴素贝叶斯算法是一种十分简单的分类算法,叫它“朴素贝叶斯”是因为这种方法的原理真的很“朴素”。朴素贝叶斯算法的原理是:通过某对象的先验概率,利用贝叶斯公式计算出其在所有类别上的后验概率,即该对象属于某一类别的概率,选择具有最大后验概率的类别作为该对象所属的类别。简单来说,对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,在哪个类别出现的概率最大,就认为此待分类项属于哪个类别,即如果一个事物在一些属性条件发生的情况下,事物属于A的概率大于属于B的概率,则判定事物属于A。朴素贝叶斯算法较为简单、高效,在处理分类问题上,是值得优先考虑的方法之一,但是其泛化能力相比分类算法较差。
朴素贝叶斯算法的核心是下面这个贝叶斯公式:
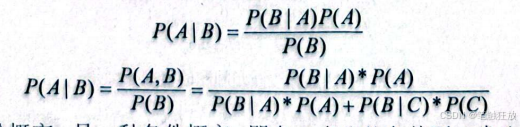
其中,P(A|B)代表后验概率,是一种条件概率,即在B发生的条件下A发生的概率。式中P(A,B)代表A、B同时发生的概率,展开得P(BIA)*P(A),P(B)的展开则运用了全概率公式。上面的公式换一个表达形式就会明朗很多:

朴素贝叶斯算法主要包括3种算法,分别是高斯朴素贝叶斯(Gaussian naive Bayes)算法、伯努利朴素贝叶斯(Bernoulli naive Bayes)算法、多项式朴素贝叶斯(multinomial naive Bayes)算法。高斯朴素贝叶斯算法利用正态分布解决一些连续数据的问题,伯努利朴素贝叶斯算法应用于二分类问题,多项式朴素贝叶斯算法在文本计数中经常使用。接下来对这3种贝叶斯算法进行模型的构建。
3.2.2 算法实现
在利用KNN算法处理回归问题中,用到了sklearn库中的make_regressionO函数,该函数可通过设置得到想要的数据集。同时在sklearn 库中还有一个手动设置的分类数据集make_blobs,其构造函数代码如下:

函数中,nsamples表示数据的数量,nfeatures表示特征的数量,而centers表示类别的数量。下面通过对函数的设置利用贝叶斯算法。
首先函数生成数据量为300、特征数为2、类别数为7的数据集,然后利用高斯朴素贝叶斯算法观察其精度。代码如下:


可以看到高斯朴素贝叶斯算法构建的模型的值达到了84%,因为现实数据大多数都符合正态分布,所以高斯朴素贝叶斯算法构建的模型一般都不错。
接下来通过可视化观察高斯朴素贝叶斯算法的决策边界:


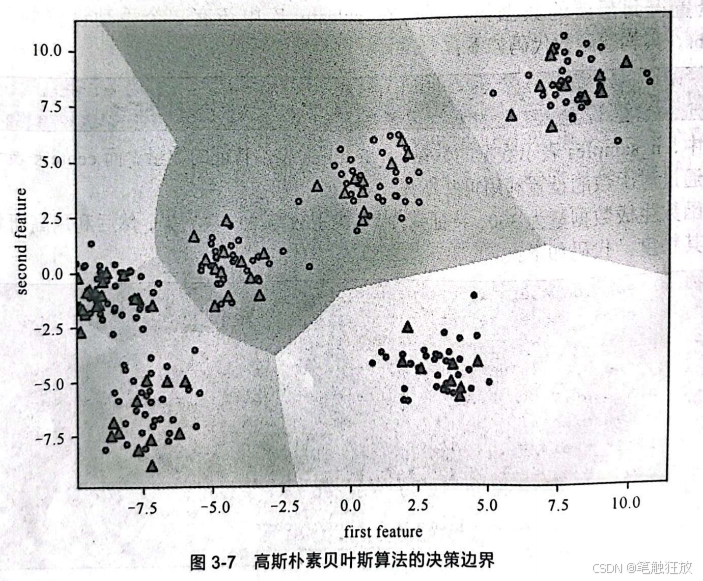
从图3-7中可以看到模型较好,除了左中部的数据可能不足外,其余类别非常完美。
接下来对伯努利朴素贝叶斯算法进行分析。伯努利朴素贝叶斯算法主要解决的是二项分布,即每个特征只有0或1两种情况。该算法对类别较多的数据集可能效果不是很好。代码如下:


从评分可以看出,模型并不是很好,接下来观察伯努利朴素贝叶斯算法的决策边界:
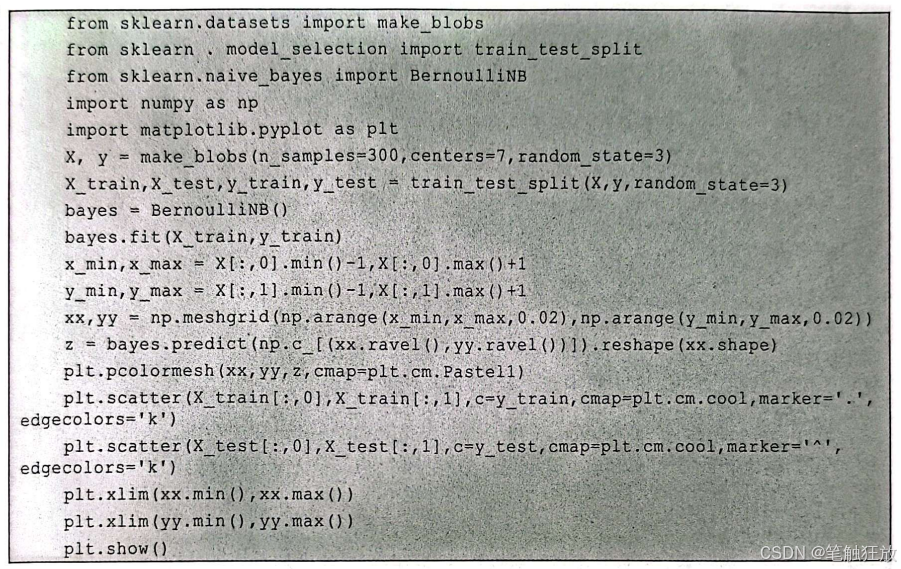 输出结果如图3-8所示。 从图3-8中可以看到,伯努利朴素贝叶斯算法的决策边界全在0处,因此对此数据集建模效果较差。图3-8同样表明如果一个数据集的特征全是0或1的话,算法将会建立良好的模型。
输出结果如图3-8所示。 从图3-8中可以看到,伯努利朴素贝叶斯算法的决策边界全在0处,因此对此数据集建模效果较差。图3-8同样表明如果一个数据集的特征全是0或1的话,算法将会建立良好的模型。
接下来是对多项式朴素贝叶斯算法的分析。因为多项式朴素贝叶斯算法只适用于处理非负离散型数值,多用于对文本的处理,对上述建立的数据集模型不适用,所以这里不详细讲解。我们只观察多项式朴素贝叶斯算法所构建的模型。因为算法要求数据中的值全为非负值,所以要先使用预处理中的归一化,将数据划到0~1。代码如下:

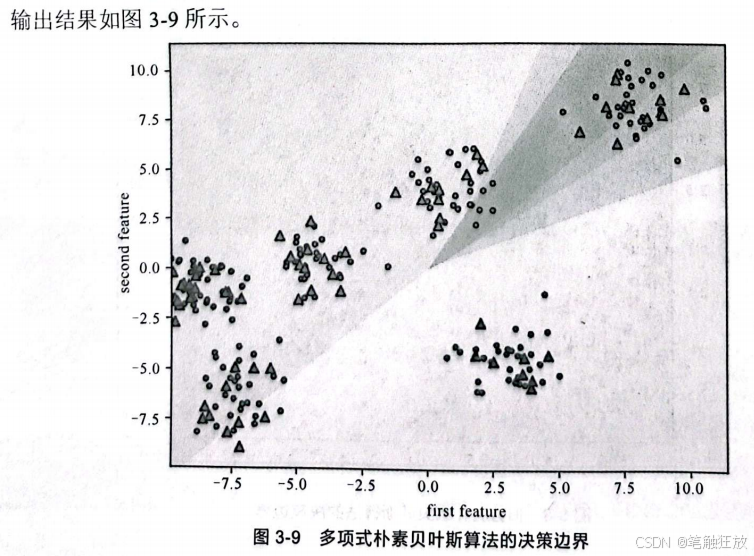
从图3-9所示的决策边界中就可以看出,模型非常不好。
多项式朴素贝叶斯算法主要应用于文本。例如,有3种不同类型的文本,这些文本经过处理后变成了机器能够读懂的数据,然后提取文本中重要的词汇作为特征。接下来在另一篇文章中查找上面3种文本的特征,根据机器学习就能判断这篇文章属于哪种类型了。
3.2.3 算法的优缺点
优点 (1)朴素贝叶斯算法分类效率稳定,不仅能处理二分类问题,还能处理多分类问题,适用于小规模数据。它还能做增量式训练,即数据过多、超出内存时,可以分批对数据进行增量式训练。 (2)朴素贝叶斯算法对缺失数据不太敏感,比较简单,常用于文本分类。 (3)当属性相关性较弱时,朴素贝叶斯算法性能较好。
缺点 (1)当属性个数比较多或者属性之间相关性较强时,朴素贝叶斯算法分类效果不好,往往无法预测精确的数据。 (2)朴素贝叶斯算法需要知道先验概率,且先验概率很多时候取决于假设,因此在某些时候算法会由于假设的先验模型不好而导致预测效果不佳。 (3)由于朴素贝叶斯算法是通过先验概率和数据来决定后验概率从而决定分类的,因此分类决策存在一定的错误率,并且对输入数据的表达形式很敏感。
3.3 逻辑回归
3.3.1 算法介绍
在分类算法中,有的可以用于回归问题,同样在回归算法中,有的可以用于分类问题。而逻辑回归属于线性模型中的一种,用于解决分类问题。逻辑回归用于处理自变量和结果的回归问题,虽然被叫作回归,它却是一种分类算法。逻辑回归主要有两种使用场景:一是用于研究二分类或者多分类问题;二是用于寻找因变量的影响因素。逻辑回归的原理是,根据一个问题,建立代价函数,然后通过迭代优化求解出最优的模型参数,再测试并验证这个求 解的模型的好坏。 逻辑回归算法与回归算法中的线性回归算法最大的差异是,逻辑回归中的#被当作决策边界,而线性回归等模型中被当作一条直线、一个平面或者超平面。逻辑回归建立模型的公式如下:
![]()
这个公式类似线性回归的公式,但是没有返回特征加权求和的值,而是设置了一个值与相比较,这个值被称为阈值。假设阈值设置为0,则当>0时属于一个类别,当<0时属于另一个类别。但是对于现实数据,阈值的设置也是一个问题,如果阈值被设置为平均值,假设正常数据点都处于0左右,而出现的一个异常值非常大,则最后的分类结果会出现错误。于是需要建立一个函数来映射概率,即Sigmoid函数:
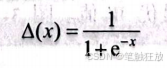

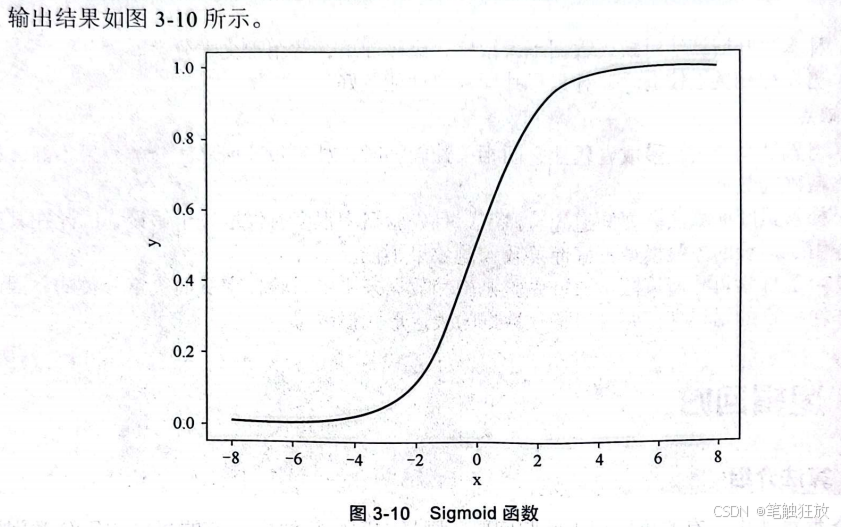
该函数将所有数据都映射到0~1,对异常值进行了处理。
对异常值进行处理后,为了能够得到较好的逻辑回归模型,需要对原始的模型构建损失函数,然后通过优化算法不断迭代以对损失函数进行优化,不断对参数和b进行调整,以求得最优参数。因此必须定义损失函数,也可称为代价函数。对于逻辑回归的参数◎一般使用极大似然法对其进行估计,然后将负的1og似然函数作为其损失函数,再利用基于梯度的方法求损失函数的最小值。
一般选取梯度下降法作为损失函数的优化算法。梯度下降法是一种迭代型的优化算法,根据初始点在每一次迭代的过程中选择下降方向,直至满足终止条件。梯度下降函数图像如图3-11所示。
梯度下降法先随机选取一个点为W,在图3-11中用笑脸表示,然后根据其切线的斜率决定下降的方向,选择步长,更新w值,查看其是否满足条件,直至切线斜率为0,即点处于极小值处,此时一般能得到最优W值。
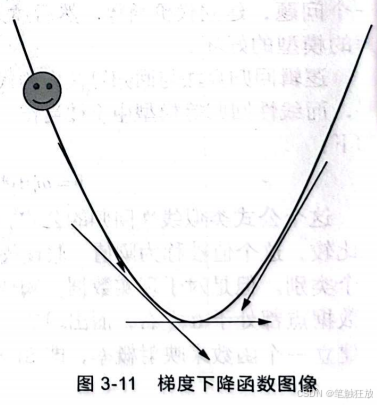
图中描述的是凸优化问题,即只存在一个极小值、只存在一个最优解的优化问题。线性回归、岭回归、逻辑回归都是凸优化问题。当然还存在非凸优化问题,非凸优化问题中存在多个局部最优解,而全局最优解才是真正的最优解。关于梯度下降法,最重要的是下降幅度的选择,也就是步长的选择。如果步长过小,则会影响效率;如果步长过大,则可能会错过最优解。一般选取一个递减函数对步长进行选择。下面对逻辑回归中的参数进行解析:

逻辑回归有一个重要的参数C,C值越大正则化越弱。正则化在回归算法中讲解,读者可以暂时不用了解,如果需要可以先跳至第4章进行学习。如果C值越大,那么特征系数也会越大,逻辑回归可能将训练集拟合得最好;而如果C值越小,那么模型更强调使特征系数接近于0,正则化越强。
3.3.2 算法实现
下面对病理数据集进行建模:

可以看到模型精度非常高,因为该数据集本身就是分类问题,恰好也说明了线性模型中的逻辑回归适用于分类问题。
接下来调整算法的参数,观察其作用:



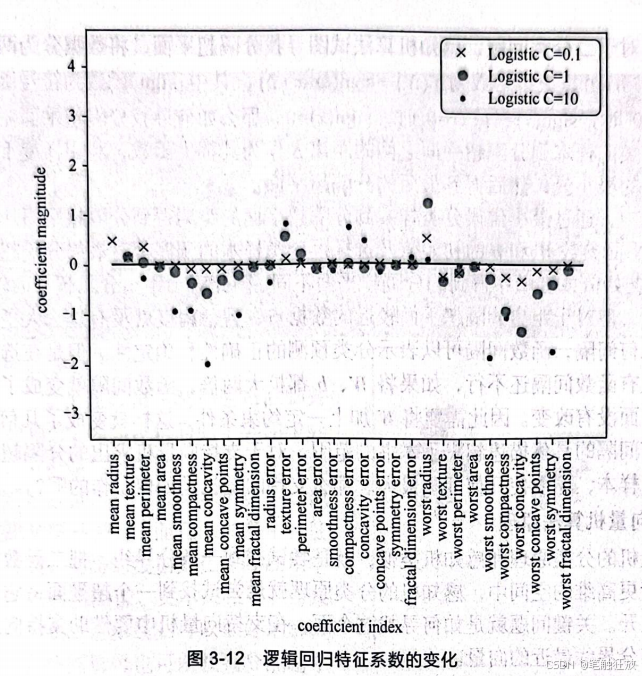
可以看到C值增大后,预测精度得到了提高。可能因为参数C的初始值过小,正则化过强,所以导致特征系数较小,评分较低。通过可视化观察特征系数的变化:
 输出结果如图3-12所示。 由于逻辑回归使用L2正则化,因此可以看到随着C值增大特征系数也会变大,随着C值减小特征系数也会变小,但是不会为0。相关内容在第4章有详细说明。
输出结果如图3-12所示。 由于逻辑回归使用L2正则化,因此可以看到随着C值增大特征系数也会变大,随着C值减小特征系数也会变小,但是不会为0。相关内容在第4章有详细说明。
3.3.3 算法的优缺点
优点 (1)逻辑回归算法简单、运行速度快,适用于二分类问题。 (2)逻辑回归算法易于理解,能直接看到各个特征的权重。 (3)逻辑回归算法容易吸收新的数据更新模型。
缺点 逻辑回归算法适应能力弱,对数据适应能力有局限性。
3.4 支持向量机
3.4.1 算法介绍
支持向量机是一种经典的算法,其应用领域主要是文本分类、图像识别,为避免过拟合提供了很好的理论保证。支持向量机是一种二分类模型。当然支持向量机被修改之后也可以用于多类别问题的分类,还可以用于回归问题的分析,它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。
感知机算法原理 由于支持向量机是在感知机的原理上改进而来的,因此在讲解支持向量机算法之前,先介绍感知机算法。对于感知机和支持向量机,其模型是二分类模型,因此以下面二分类问题为背景进行研究。对于二分类问题,感知机算法试图寻找分隔超平面,将数据分为两类。分隔超平面公式为∞Tx+b=0,决策函数为f(X)=sign(@x+b)。其中 sign 函数为符号函数,x>0 时,sign(x)=1;x<0 时,sign(x)=-1;x=0时,sign(x)=0。那么如何寻找分隔超平面呢?感知机算法直接使用误分类的样本到分隔超平面之间的距离S作为其损失函数,利用梯度下降法求得误分类的损失函数的极小值,然后得到最后的分隔超平面。
在感知机中,通过最小化误分类样本到分隔超平面的距离得到分隔超平面。但在分隔超平面中,分隔超平面参数W和b的初始值及选择误分类样本的顺序都对最终分隔超平面的计算有影响,不同的初始值或者顺序得到的分隔超平面不同,因此对于距离分隔超平面较远的数据点,置信程度较大,但对于距离分隔超平面较近的数据点,置信程度就没有这么大了。因此要定义函数间隔和几何间隔,函数间隔可以表示分类预测的正确性和确定性。但是在选择分隔超平面的过程中,只有函数间隔还不行,如果将W、b都扩大两倍,函数间隔就变成了原来的两倍,但是分隔超平面没有改变。因此需要将W加上一定约束条件,这样就变成了几何间隔。对于函数间隔和几何间隔的具体描述超出了本书的范围。对于支持向量机求出的分隔超平面,不仅要能够正确划分样本,还要使几何间隔最大。那么支持向量机是如何工作的呢?
支持向量机算法原理 支持向量机的分类原理和感知机类似,就是尝试找到一条分界线,把二元数据隔离开。在三维空间或者更高维的空间中,感知机的分类原理就是尝试找到一个超平面,它能够把所有的二元类别隔离开。关键问题就是如何寻找这个面。在支持向量机中要借助支持向量来寻找,支持向量就是离分界线最近的向量。
在介绍支持向量机之前,首先要介绍什么是线性不可分。线性不可分简单来说就是一个数据集不可以通过一个线性分类器(直线、平面)来实现分类。假设有一组数据,代码如下:
 输出结果如图3-14所示。 可以看到,对于上述数据集利用逻辑回归并不能实现很好的划分,因为逻辑回归主要用于处理二分类问题。如果要用逻辑回归解决上述问题的话,需要在原始数据集中添加非线性特征,但是往往不知道添加哪些特征,而且添加多个特征会大大提高计算量。上面的数据集在实际应用中是很常见的,例如人脸图像、文本文档等。如果数据集是线性可分的,逻辑回归可以很好地解决它的分类问题,支持向量机也可以找到分隔超平面对它进行划分,但如果它线性不可分,要在逻辑回归中进行处理就显得比较复杂,于是出现了支持向量机。可以在支持向量机的函数间隔中添加松弛变量或者核函数。一般先使用核函数,通过将样本映射到高维特征空间使得样本线性可分,这样会得到一个复杂模型,但是会导致过拟合,所以再使用松弛变量对其进行调整。经过支持向量机的计算会得到图3-15所示的图像。
输出结果如图3-14所示。 可以看到,对于上述数据集利用逻辑回归并不能实现很好的划分,因为逻辑回归主要用于处理二分类问题。如果要用逻辑回归解决上述问题的话,需要在原始数据集中添加非线性特征,但是往往不知道添加哪些特征,而且添加多个特征会大大提高计算量。上面的数据集在实际应用中是很常见的,例如人脸图像、文本文档等。如果数据集是线性可分的,逻辑回归可以很好地解决它的分类问题,支持向量机也可以找到分隔超平面对它进行划分,但如果它线性不可分,要在逻辑回归中进行处理就显得比较复杂,于是出现了支持向量机。可以在支持向量机的函数间隔中添加松弛变量或者核函数。一般先使用核函数,通过将样本映射到高维特征空间使得样本线性可分,这样会得到一个复杂模型,但是会导致过拟合,所以再使用松弛变量对其进行调整。经过支持向量机的计算会得到图3-15所示的图像。
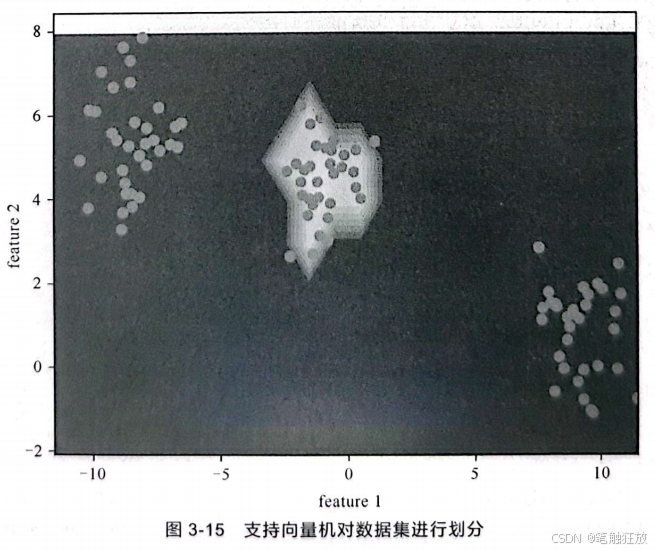
可以看到此时的决策边界已经不是一条直线,而是一个超平面,它映射到二维图像就变成了曲线。
支持向量机的参数如下:
 接下来分析支持向量机的参数,其中最重要的3个参数为kernel、gamma、C。 (1)kernel:关于核的选择。可以选择的 kernel有rbf、linear、poly等。其中rbf高斯核和poly多项式核适用于非线性超平面。下面举例说明线性核和非线性核在双特征鸢尾花数据集上的表现,如图3-16和图3-17所示。
接下来分析支持向量机的参数,其中最重要的3个参数为kernel、gamma、C。 (1)kernel:关于核的选择。可以选择的 kernel有rbf、linear、poly等。其中rbf高斯核和poly多项式核适用于非线性超平面。下面举例说明线性核和非线性核在双特征鸢尾花数据集上的表现,如图3-16和图3-17所示。
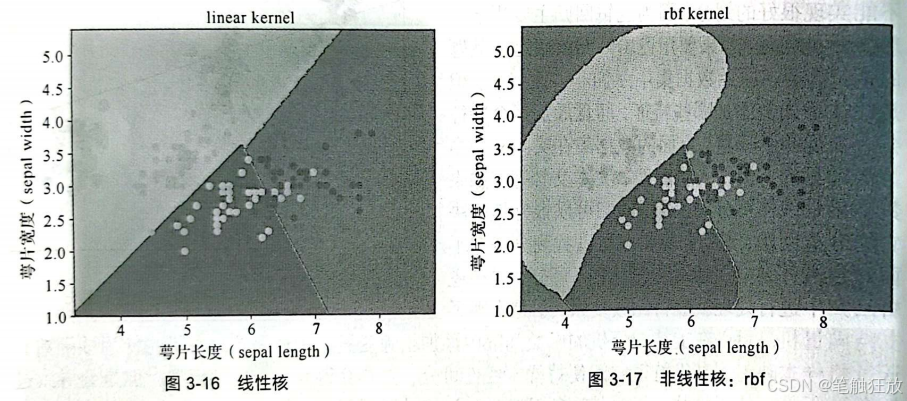
当特征数较大(特征数>1000)时建议使用线性核,因为在高维空间中,数据更容易线性可分,也可使用rbf,但需要做交叉验证以防止过拟合。
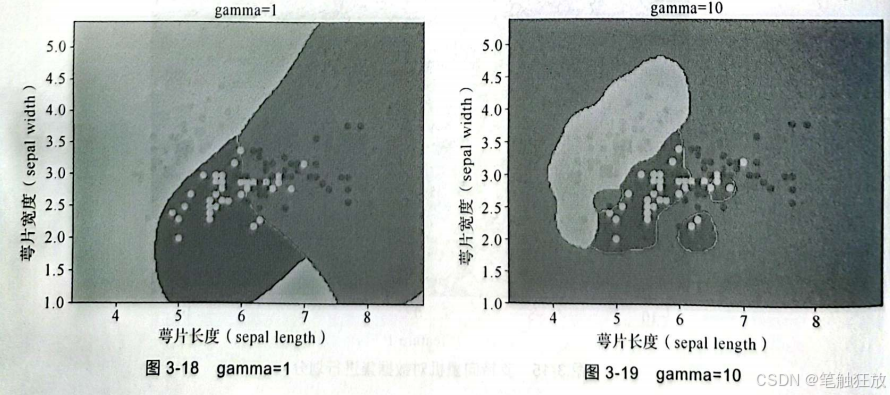
(2)gamma:当kernel一定时,gamma值越大,支持向量机(support vector machine,SVM)就会越倾向于准确地划分每一个训练集里的数据,这会导致泛化误差较大和过拟合,如图3-18和图3-19所示。
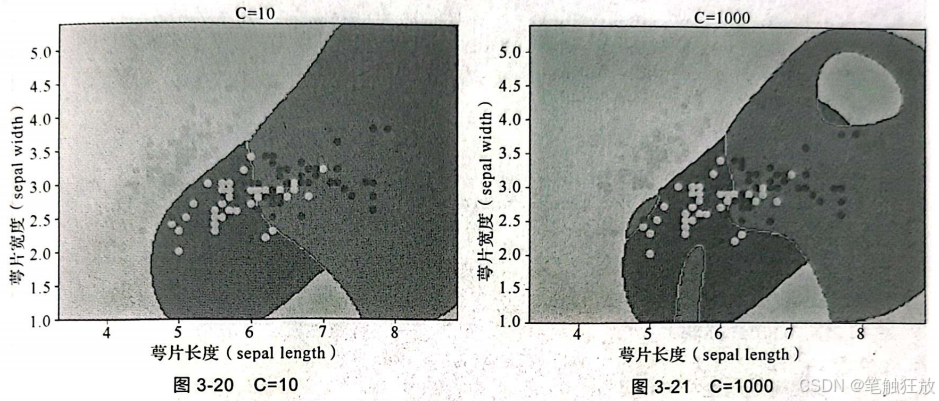
(3)C:错误项的惩罚参数,用于平衡(tradeoff)控制平滑决策边界和训练数据分类的准确性。与逻辑回归中的C值一样,值越大正则化越弱。与前面类似,如果C值越大,那么特征系数也会越大,逻辑回归和线性SVM可能将训练集拟合得最好;而如果C值越小,那么模型更强调使特征向量接近0,如图3-20和图3-21所示。
SVM涉及核的选择,那么对于核的选择技巧是什么呢?第1种情况,如果样本数小于特征数,那么没必要选择非线性核,简单使用线性核就可以了。第2种情况,如果样本数大于特征数,那么可以使用非线性核,将样本映射到更高维度,这样一般可以得到更好的结果。第3种情况,如果样本数量和特征数相等,那么可以使用非线性核,原理和第2种情况一样。
3.4.2 算法实现
下面用SVM来实现多分类问题。先用SVM对鸢尾花数据集进行精度测试,因为要用到特征可视化,所以暂取两个特征。

精度不算很高,可以通过调参来提高精度,将gamma调为1。


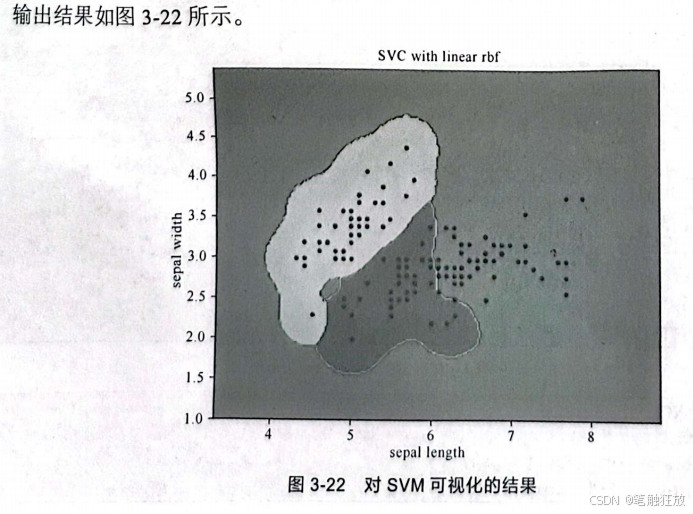
精度有所提高,还可以继续测试寻找最优方案。然后对SVM进行可视化。

3.4.3 算法的优缺点
优点 (1)SVM使用核函数,可以向高维空间进行映射,对高维分类问题的分类效果好。 (2)SVM使用核函数,可以解决非线性的分类。 (3)SVM分类效果较好,分类思想很简单,即将样本与分隔超平面的间隔最大化。 (4)因为SVM最终只使用训练集中的支持向量,所以节约内存。
缺点 (1)当数据量较大时,SVM训练时间会较长。 (2)当数据集的噪声过多时,SVM表现不好。 (3)SVM内存消耗大,难以解释,运行和调参也麻烦。 (4)SVM无法直接支持多分类,但是可以使用间接的方法来实现。
3.5 决策树
3.5.1 算法介绍
决策树是一种相对普遍的机器学习算法,常用于分类和回归。在机器学习中,决策树是一个预测模型,它代表的是对象属性与对象值之间的一种映射关系,它在对数据进行分类的同时,还可以给出各个特征的重要性评分。决策树在决策过程中,会根据数据的特征来划分数据的类别。表3-2所示为对数据集进行划分的例子。
 若表3-2所示的数据集是一个三分类问题,那么根据决策树的划分,结果如图3-23所示。
若表3-2所示的数据集是一个三分类问题,那么根据决策树的划分,结果如图3-23所示。
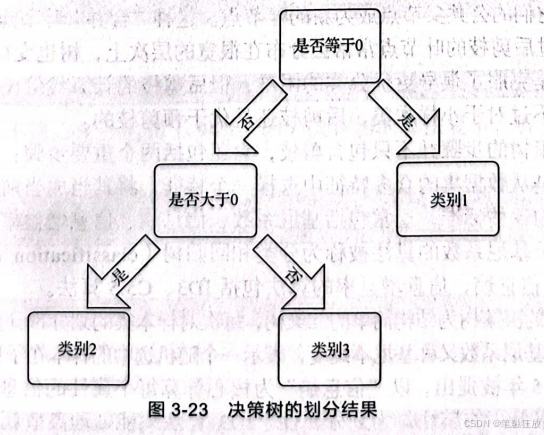
当然可能也会有其他划分方法。总而言之,在使用决策树分类的时候,从根节点开始,对数据集的某一个特征进行测验,选择最优特征,然后每一个数据被对应分配到子节点。如此循环进行,当到达叶节点时,循环停止,这时每个数据都被分到一个类别。如果还有子集不能被正确分类,就对这些子集选择新的最优特征,继续对其进行分类,构建相应的节点,如此循环进行,直至所有训练数据子集被基本正确分类,或者没有合适的特征为止。每个子集都被分到叶节点上,即都有了明确的类别,这样就生成了一棵决策树。但是如果在特征的数量非常大、数据非常多的 情况下,算法的计算量肯定会非常大,那应该如何处理呢?下面对决策树的参数进行分析。

从决策树函数中看到决策树的参数比较多,其中比较重要的参数是决策树的最大深度max_depth。因为决策树模型比较复杂,对训练集中的数据表现得很好,但在测试集上的表现并不是很好,所以容易产生过拟合。通过对最大深度进行限制则可以解决这一问题。这种对树预先进行处理的操作,称为预剪枝。
预剪枝是指在树的“生长”过程中设定一个指标,当达到该指标时树就停止生长。这样虽然方便,但是有局限性,即一旦达到指标,节点就变成了叶节点,不过如果往后继续分支可能会出现更好的分类方法。因此说预剪枝可能会误导更优分类。
还有一种方式可以解决过拟合问题,即先构建树,然后删除信息量很少的节点。这种方式被称为后剪枝。后剪枝中树首先要充分生长,充分利用全部数据集,让叶节点都有最小的不纯度。然后考虑是否消去所有相邻的成对叶节点的不纯度,如果消去能引起令人满意的不纯度增长,那么执行消去,并令它们的公共父节点成为新的叶节点。这种“合并”叶节点的做法和节点分支的过程恰好相反,经过后剪枝的叶节点常常会分布在很宽的层次上,树也变得非平衡。
后剪枝的优点是克服了误导更优分类的困难,但后剪枝的计算代价比预剪枝大得多,特别是在大样本集中,不过对于小样本集,后剪枝还是优于预剪枝的。
实际中构建决策树的步骤并不只包含剪枝,它还包括两个重要步骤:特征选择、决策树的生成。特征选择就是从数据集的众多特征中选择一个特征,将其当成当前节点的判断标志。选择特征有许多不同的评估标准,通常包括基尼系数、信息熵、信息增益率等,从而行生出不同的决策树算法。基于基尼系数的算法被称为分类和回归树(classificationandregressiontree,CART)算法,基于信息熵、信息增益率的算法包括ID3、C5.5算法。
CART算法生成的决策树为结构简单的二叉树,每次对样本集的划分都计算基尼系数,基尼系数越小则划分越合理。基尼系数又称基尼不纯度,表示一个随机选中的样本在子集中被分错的可能性。
ID3算法于1975年被提出,以“信息熵”为核心计算每个属性的信息增益率,节点划分标 准是选取信息增益率最高的属性作为划分属性。ID3算法只能处理离散属性,并且类别值较多的输入变量比类别值较少的输入变量更有机会成为当前最佳划分点。
C5.5算法使用信息增益率来选择属性,存在选择取值较少属性的偏好,因此,可采用启发式搜索方法,先从候选划分属性中找出信息增益率高于平均水平的属性,再从中选择信息增益率最高的属性作为划分属性。基于这些改进,C5.5算法克服了ID3算法使用信息增益率选择属性时偏向选择取值多的属性的不足。
算法的选择可以根据函数中的criterion参数进行调整,默认为基尼系数gini,可以调节为信息增益率的熵entropy。通过min_impurity_decrease来优化模型,这个参数用来指定信息熵或者基尼系数的阈值,当决策树分裂后,其信息增益率低于这个阈值时则不再分裂。
信息熵表示事件的不确定性。变量不确定性越高,熵越高。划分数据集的一大原则是,让数据从无序变得有序,在划分数据集前后信息发生的变化称为信息增益率,获得信息增益率最高的特征就是最好的选择。
基尼系数是一种与信息熵类似的、做特征选择的方式,通常用于CART算法中。基尼系数等于样本被选中的概率乘以它被分错的概率。当一个节点中所有样本都属于同一个类别时,基尼系数为零。
决策树生成是指根据选择的特征评估标准,从上至下递归地生成子节点,直到数据集不可分,则决策树停止生长。对树结构来说,递归结构是最容易理解的结构之一。
3.5.2 算法实现
接下来通过鸢尾花数据集对CART分类树(决策树解决分类问题)进行分析。CART分类树中,利用基尼系数作为划分树的指标,通过样本的特征对样本进行划分,直到所有的叶节点中的所有样本都属于同一个类别为止。代码如下:


算法建立的模型不错,评分达到了94%。因为决策树的算法复杂,容易产生过拟合,所以要对训练集进行测试:

可以看到模型在训练集上的评分达到了100%,与在测试集上的评分差得比较多,因此肯定发生了过拟合。因而可以对数据进行剪枝:



将最大深度设置为3,可发现精度提高了很多,说明刚才的猜测是正确的,发生了过拟合。 接下来通过可视化来观察决策原理。需要用到export_graphviz(函数:

输出结果如图3-24所示。 运行之后发现文件夹中出现了first_tree.dot文件,找到该文件,如图3-25所示。利用命令输出决策树,如图3-26 所示。

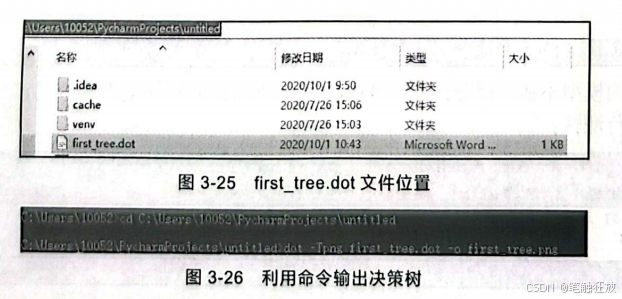
进入Windows命令提示符窗口,使用cd 命令切换到 tree.dot所在的路径,执行 dot-Tpng first_tree.dot-o first_tree.png,然后在文件夹中就出现了一个便捷式网络图形(portable network graphics,PNG)格式的图片,打开它后可以看到决策树的决策过程,如图3-27所示。
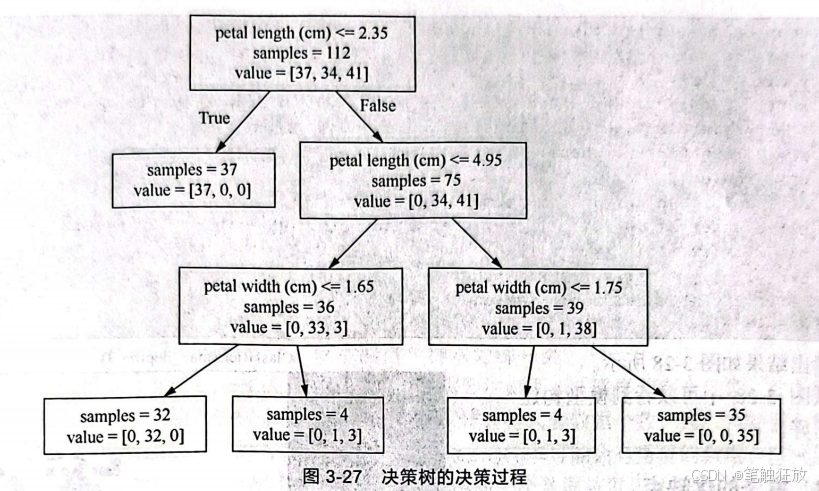
从图3-27中可以看到,对鸢尾花数据集的决策只用到了petal length和petalwidth两个特征。在决策树中还可以看到模型特征的重要性,特征的值全部在0~1,越接近1,表示特征越重要。代码如下:


可以看到只用到了两个特征。 为了方便可视化观察决策树的决策过程,只取数据集的两个特征,根据前面特征的重要性,选择后两个特征petal length和petalwidth:

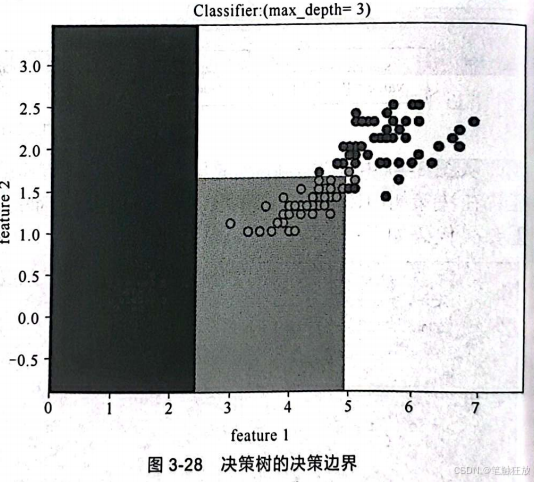
输出结果如图3-28所示。 从图3-28中可以看到模型构建得非常好。
3.5.3 算法的优缺点
优点 (1)决策树通过可视化的树容易被解释,一般人们在解释后都能理解决策树所表达的意义。 (2)决策树易于通过静态测试来对模型进行评测,可以处理连续数据和种类字段。决策树可以清晰地显示 哪些字段比较重要。其他的技术往往要求数据属性的单一。 (3)可以对有许多属性的数据集构建决策树。它在相对短的时间内能够对大型数据集得出可行且效果良好的结果。 (4)决策树可很好地扩展到大型数据库中,同时它的大小独立于数据库的大小,它的计算 量相对来说不是很大。
缺点 (1)对于那些各类别样本数量不一致的数据,在决策树当中,信息增益的结果偏向于那些具有更多数值的特征。决策树处理缺失数据时存在困难。 (2)决策树容易出现过拟合问题。 (3)对有时间顺序的数据,决策树需要做很多预处理工作。 (4)决策树容易忽略数据集中属性之间的相关性。当类别太多时,错误量可能会增加得比较快。它用于一般的算法分类的时候,只根据一个字段来分类。
3.6 随机森林
3.6.1 算法介绍
因为决策树通常会出现过拟合的问题,所以产生了随机森林这一算法。随机森林是集成算法的一种。
常见的集成算法有3类,分别是装袋(bagging)算法、提升(boosting)算法和投票(voting)算法。装袋算法是指将训练集分成多个子集,然后对各个子集进行模型训练。提升算法是指训练多个模型并将它们组成一个序列,序列中的每一个模型都会修正前一个模型的错误。投票算法是指训练多个模型,并采用样本统计来提高模型的精度。
随机森林属于装袋算法的一种,在分类和回归问题上都可以运用,相对来说是一种比较新的机器学习算法。所谓随机森林是指对变量、数据进行随机化,用随机的方式建立一个森林,森林里面有很多的决策树。随机森林的每一棵决策树之间是没有关联的,决策树算法通过循环的二分类方法实现,计算量大大降低。在得到森林之后,当有一个新的输入样本进入时,森林中的每一棵决策树分别进行判断,预测这个样本应该属于哪一类(对于分类算法)。一般情况下,决策树中哪一类被选择的次数最多,就预测这个样本为哪一类。
在利用随机森林构建每一棵决策树的过程中,需要注意两点:采样和完全分裂。首先是采样的过程,随机森林对于输入的样本要进行行和列的采样,行代表数据个数,列代表特征个数。对于行的采样,利用有放回采样的方式得到的每一棵树中的样本可能会有重复的数据,也就是说一棵树中可能有N个数据,而这N个数据只是数据集中的一个数据被重复抽取了N次得到的。采用有放回采样的方式保证了每棵树的差异性,假如一个样本只有N个数据,而采样数据也是N个数据,这样就使得每一棵树都不是完全相同的,不会出现每棵树都是这N个数据,也就减少了过拟合。对于列的采样,从特征中选取的特征数要远小于样本中的特征数,然后对每一棵树中的样本使用完全分裂的方式构建决策树。完全分裂可以保证决策树的每一个叶节点中只有一类。
随机森林在对数据进行分类的同时,还可以给出各个变量的重要性评分,评估各个变量在分类中所起的作用,再汇总分类的结果。许多研究表明,组合分类器比单一分类器的分类效果好,随机森林在运算量没有显著提高的前提下提高了预测精度。随机森林对多元共线性不敏感,对缺失数据和非平衡数据的分类比较稳健,可以很好地预测上千个解释变量的作用,被誉为当前最好的算法之一。
下面通过随机森林的参数,分析其具体实现方法。
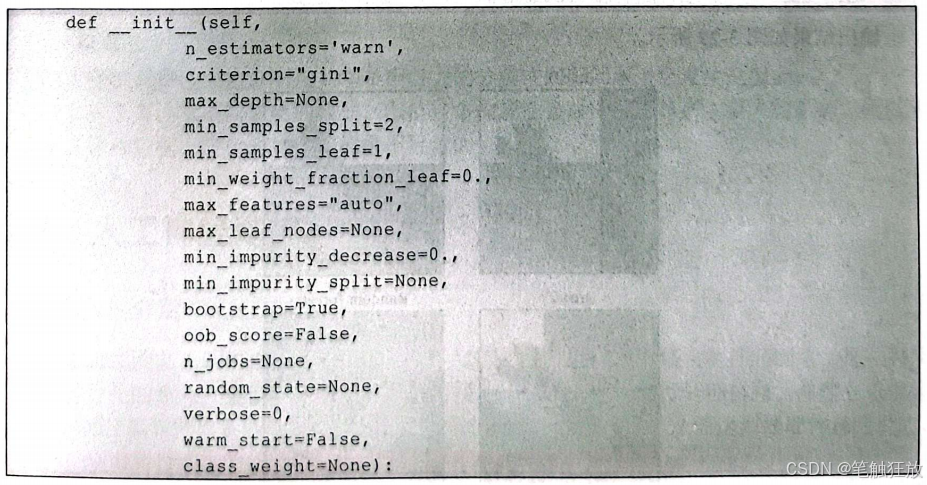
在随机森林中,有3个比较重要的特征,分别是最大特征数max_features、分类器的个数n_estimators、最小样本叶节点数min_samples_leaf。max_features是随机森林允许在单个树中尝试的最大特征数,如果设置max_features等于决策树中的n_features,那么每次划分数据集的时候都要考虑所有特征,失去了随机性。但在随机森林中,bootstrap表示自主采样,即有放回地来样,这样增强了随机森林的随机性。如果设置max_features等于1,那么划分时无法选择对哪个特征进行测试,只能对每个特征搜索不同的阈值。所以最大特征数的设置非常重要。叶子是决第树的末端节点。较小的叶节点数使模型更容易捕捉训练数据中的噪声。一般来说,将最小叶节点 数设置为大于50的数,应该尽量尝试不同数量和种类的叶节点,以找到最优的组合。
3.6.2 算法实现
接下来实现由3棵树组成的随机森林。代码如下:
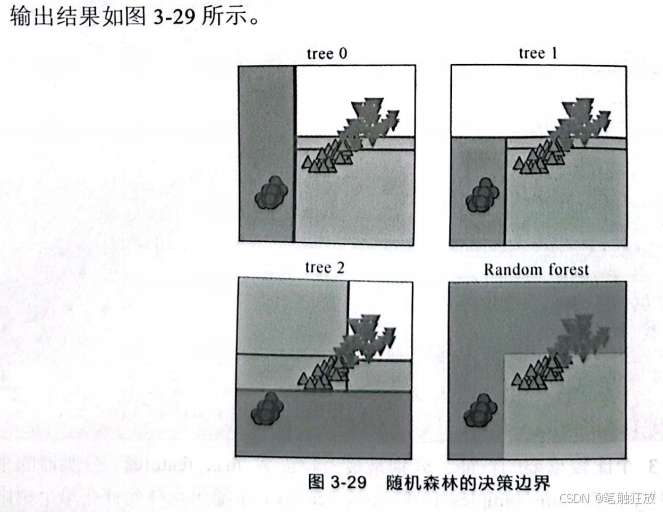
从图3-29中可以看出,每棵树都有不同的决策边界,而最后的随机森林模型由3棵树综合而成。随机森林的过拟合程度比任何一棵树都要小,给出的决策边界也更符合直觉。下面查看随机森林对数据集中特征重要性的分析。


从输出结果中可以看到,没有评分为0的特征,也就说明了随机森林构建的模型比决策树构建的模型更能从总体上进行分析。
3.6.3算法的优缺点
优点 (1)随机森林在数据集上表现良好,两个随机性的引入,使得随机森林不容易发生过拟合。 (2)在当前的很多数据集上,随机森林相对其他算法有着很大的优势,两个随机性的引入,使得随机森林具有很好的抗噪声能力。 (3)随机森林训练速度快,容易实现并行化。 (4)随机森林能够处理很高维度的数据,并且不用做特征选择,对数据集的适应能力强:既能处理离散型数据,也能处理连续型数据,且数据集无须规范化。
缺点 (1)随机森林已经被证明在某些噪声较大的分类或回归问题上会发生过拟合。 (2)对于属性有不同取值的数据,取值较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产生的属性权值是不可信的。
3.7 人工神经网络
3.7.1 算法介绍
人工神经网络(artificial neural network,ANN)简称为神经网络或类神经网络,是一种模拟动物神经元的算法,类似大脑中神经突触连接,它通过分布式并行处理信息,并建立数学模型。这种神经网络依靠系统的复杂程度,调节系统内部的连接关系,从而达到处理信息的目的,并具有自学习和自适应的能力。
神经网络是一种运算模型,一般通过统计学的方法进行优化,所以神经网络也是统计学方法的实践。一方面,通过统计学的方法可以得到大量函数来应用于神经网络结构。另一方面,在人工智能的感知领域,通过统计学的应用可以解决人工感知方面的决策问题,这种方法比正式的逻辑学推理演算更具有优势。 (1)结构:指定网络中的变量和它们的拓扑关系。例如,神经网络中的变量可以是神经元连接的权重和神经元的激励值。 (2)激励函数:每个神经元都有一个激励函数,它主要是一个根据输入传递输出的函数。大部分神经网络模型具有一个短时间尺度的动力学规则,来定义神经元如何根据其他神经元的活动改变自己的激励值。一般激励函数依赖于神经网络中的权重。 (3)学习规则:指定神经网络中的权重如何随着时间推进而调整。它一般被看作一个长时间尺度的动力学规则。一般情况下,学习规则依赖于神经元的激励值,但它也可能依赖于监督者提供的目标值和当前权重的值。
神经网络中比较重要的是多层感知机(multilayer perceptron,MLP)算法。MLP也被称为前馈神经网络,或者被泛称为神经网络。下面重点介绍这一算法。神经网络的预测精确,但是计算量相对来说也比较大。神经元之间的每个连接都有一个权重,用于表示输入值的重要性。一个特征的权重越高,说明该特征越重要。在线性回归中有下 面的公式:
![]()
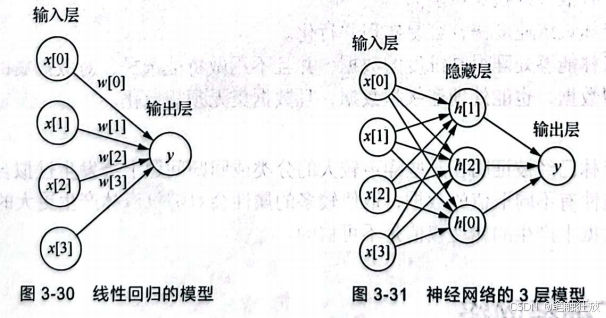
其中,x表示特征,w表示特征的权重,表示加权求和的结果。 线性回归的模型如图3-30所示。 而神经网络的神经元分为3种不同类型的层次:输入层、隐藏层、输出层。输入层接收输入数据,隐藏层对输入数据进行数学计算,输出层是神经元的最后一层,主要作用是为此程序产生指定的输出。神经网络的3层模型如图3-31所示。
当一组输入数据通过神经网络中的所有层后,最终通过输出层返回输出数据。但神经网络的计算并没有这么简单。神经网络是一种非线性统计性数据建模工具。如果只对每一层的隐藏层进行加权求和,得到的模型与线性模型相差无几,所以在生成隐藏层后需要进行非线性变换(一般是进行非线性矫正或者是双曲正切处理)。通过非线性变换,神经网络可以拟合任意一个函数。经过非线性处理的数据如下:


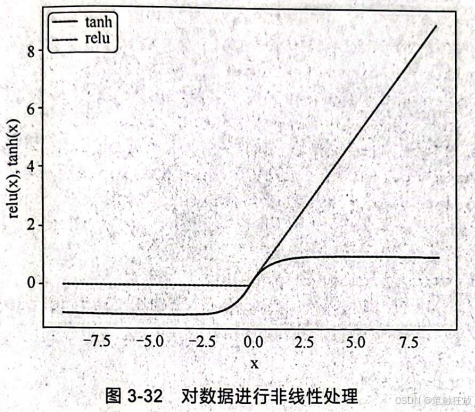

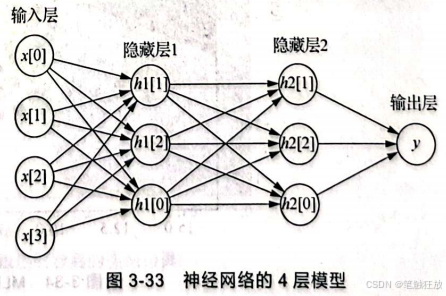
神经网络的4层模型如图3-33所示。 神经网络中的重要参数hidden_layer_sizes表示隐藏层中节点的数量和隐藏层的层数,例如hidden_layer_sizes=(100,100),表示有两层隐藏层,第一层隐藏层有100个神经元,第二层隐藏层也有100个神经元。还有激励函数参数activation用于选择非线性函数,默认为relu,还可以选择 tanh、identity函数,以及logistic逻辑函数Sigmoid,该函数在逻辑回归中提过。solver用来优化权重,默认为adam,solver'adam’在相对较大的数据集上效果比较好,对于项目实现演示所用的小数据集来说,lbfgs收敛更快,效果也更好。
3.7.2 算法实现
下面对MLP算法项目进行实现。代码如下:


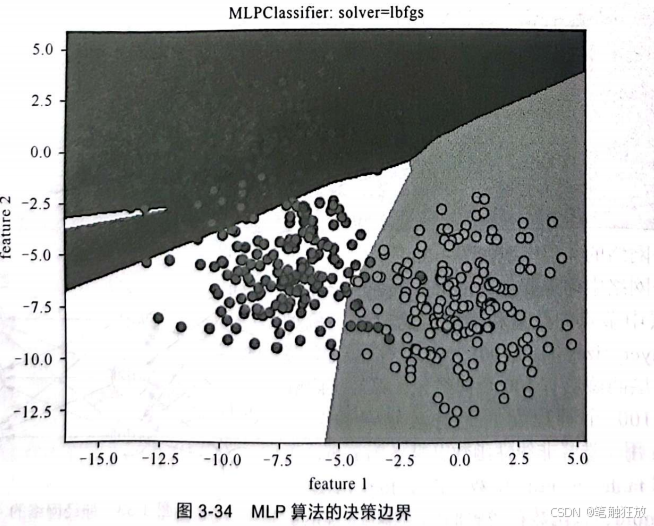
从运行的时间可以感觉到神经网络的计算量比较大。接下来调整隐藏层节点的数量和隐藏层的层数来进行对比:

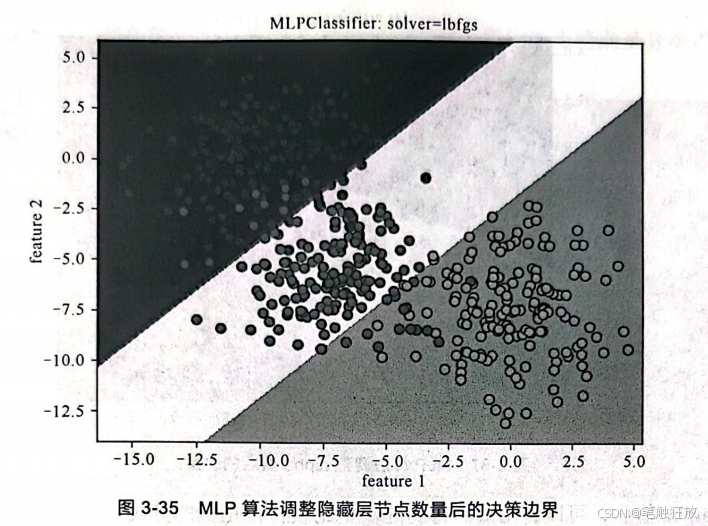

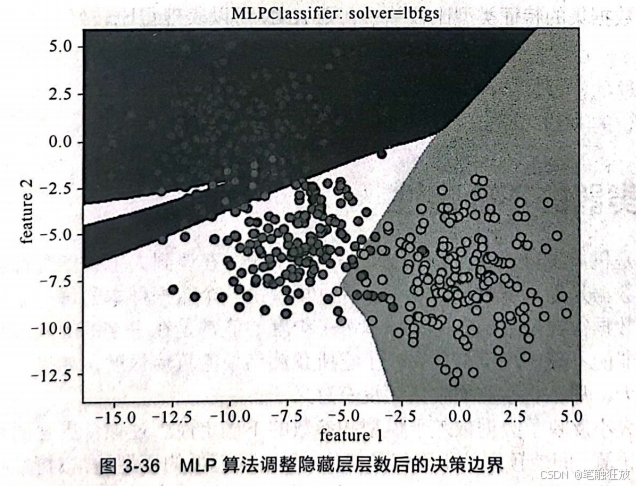
将隐藏层节点的数量调为1,明显看到决策边界没有了非线性变化,变成了平滑的直线。 对隐藏层层数进行调整后,决策边界也发生了变化,虽然变化不是很大,但精度得到了提高,运算时间也变得更长了。
对于模型的复杂度,还可以通过调节alpha的值来进行控制:
![]()
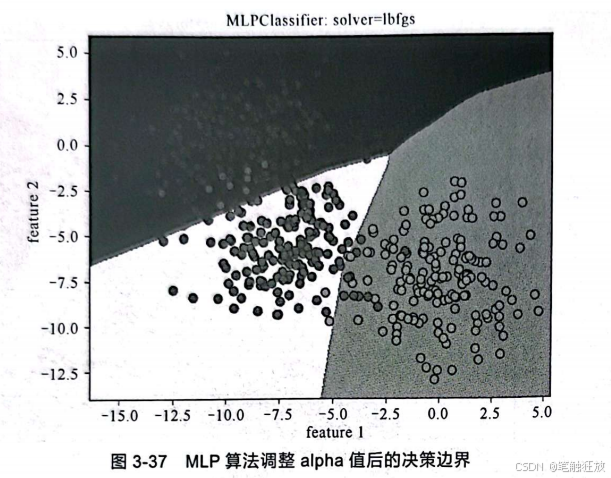
调节alpha值后,可以看出最后得到的模型比较符合正确的分类。
3.7.3 算法的优缺点
优点 (1)ANN可以根据数据构建复杂的模型。 (2)如果数据集的特征类型比较单一,则ANN可以表现得比较好。
缺点 (1)当构建的模型复杂时,ANN所需的计算量非常大。 (2)前文讲的MLP算法,仅限于处理小型数据集。
3.8 分类器的不确定性
不确定性是机器学习领域内一个重要的研究主题,在谈到人工智能时都会提到不确定性的概念。确定性数据是指训练数据集和测试数据集中每一个数据样本的每一个属性值都是唯一确定的。但现实数据往往是不确定的,样本每一维度的值都是在一定范围内服从某种分布的数据的集合。分类器的不确定性度量,反映了它所预测结果的置信程度,如果一个分类器预测结果不确定性非常大,那么它预测的结果就没有意义了。
不确定性大小反映了数据依赖于模型和参数的不确定性。过拟合更强的模型可能会得到置信程度更高的预测,即使预测结果可能是错的。复杂度越低的模型通常对预测的不确定性越大。如果模型给出的不确定性符合实际情况,那么这个模型被称为校正模型。在校正模型中,预测的正确度越高,预测结果正确的概率就越大。
在sklearn库中有两个函数可以获取分类器的不确定性估计,分别是决策函数decisionfunction()和预测函数predict_proba(),有的分类器含有这两个函数,有的只含有一个或者没有。
3.8.1 决策函数
决策函数 decision_function)返回的是一组浮点数,形状为(n_samples,)。该函数返回正值表明对类别1的偏好,返回负值表明对类别2的偏好。下面利用线性支持向量分类机(support vector classifier,SVC)来演示决策函数。代码如下:
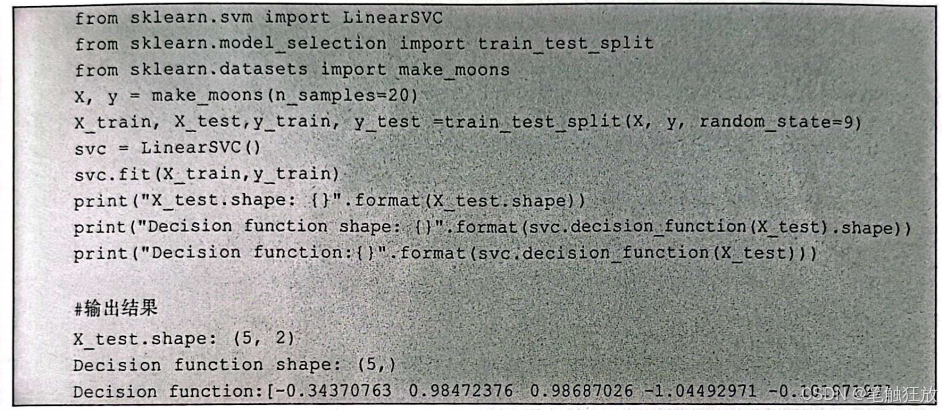
决策函数返回的是参数实例到各个类所代表的超平面的距离,对于这个返回的距离,或者说是分值,后续将指定阈值来进行过滤。
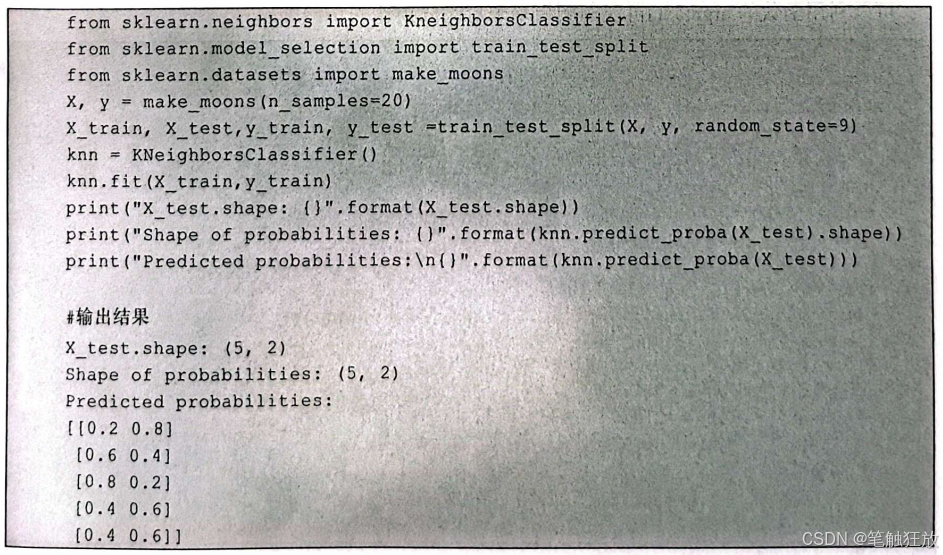
3.8.2 预测函数
预测函数predict_proba()返回的形状是(n_samples,2),一列中两个元素的和恰好为1,一般认为哪个类别的数值大,该列就属于哪个类别。代码如下:
3.8.3 多分类的不确定性
对于多分类的情况,decision_function)的形状为(n_samples,n_classes),每一列对应每个类别的“确定度分数”,得分较高的类别可能性更高,得分较低的类别可能性较低。predict_proba)的形状也是(n_samples,n_classes),同样各列类别之和为1,选取得分最高的类别作为该列的类别。代码如下:

可以利用函数的argmax(再现预测结果来对比分类器的预测结果:

3.9 小结
本章学习了监督学习算法中的分类算法,包括KNN、朴素贝叶斯、逻辑回归、SVM、决策树、随机森林、神经网络等。
KNN算法的原理就是当预测一个新的值的时候,根据它距离最近的k个点是什么类别来判断这个值属于哪个类别。朴素贝叶斯算法的原理就是如果一个事件在此类的发生概率最大,则属于此类。
朴素贝叶斯算法分为3类,包括高斯朴素贝叶斯算法、伯努利朴素贝叶斯算法、多项式朴素贝叶斯算法,其中多项式朴素贝叶斯算法常用于对文本的处理。
决策树算法的原理就是从根节点开始,对数据集选择最优特征并将其分配到子节点。如此循环进行,直至每个数据都被分到一个类别。
随机森林算法的原理就是随机选择:N个样本,共进行K轮选择,得到K个相互独立的训练集。对于K个训练集,训练K个模型;对于分类问题,由投票表决产生分类结果。
SVM算法的原理是在空间中找到一个能将所有数据划分开的超平面进行分类,并且使得数据集中所有数据与超平面的距离最短。
神经网络中的MLP算法,通过非线性变换(非线性矫正或者是双曲正切处理)可以拟合较为复杂的模型。
习题 3
1.分析各种算法的原理,并总结其优缺点。
2.生成一个每个特征都是布尔型数据的数据集,并用伯努利朴素贝叶斯算法建立模型,观察其评分。
3.实现SVM算法,并分析其不同的核所能完成的任务。
4.试分析决策树与随机森林的关系。
5.使用不同的算法对鸢尾花数据集进行处理,寻找较为合适的算法。