[2025CVPR-图像检索方向] COBRA:一种用于小样本自适应检索增强模型
目录
详细内容总结:COmBinatorial Retrieval Augmentation for Few-Shot Adaptation (COBRA)
1. 背景与问题陈述
2. 核心方法:COBRA(COmBinatorial Retrieval Augmentation)
3. 实验设置与结果分析
基线方法
关键结果
4. 贡献与结论
详细内容总结:COmBinatorial Retrieval Augmentation for Few-Shot Adaptation (COBRA)
这篇论文由华盛顿大学西雅图分校的研究团队(Arnav M. Das、Gantavya Bhatt 等人)提出,题为“COBRA: COmBinatorial Retrieval Augmentation for Few-Shot Adaptation”。论文的核心是解决少样本学习(few-shot learning)中检索增强(retrieval augmentation)的局限性,通过引入组合互信息(Combinatorial Mutual Information, CMI)框架,开发了一种新颖的检索方法 COBRA。以下从背景、问题陈述、方法创新、实验验证和结论几个方面进行详细总结,结构丰富且结合文档中的关键图片增强理解。
1. 背景与问题陈述
检索增强是一种在数据稀缺(low-data regime)场景下提升模型性能的有效技术,它通过从大型辅助数据集(auxiliary pool)中检索额外样本,来补充目标任务(target task)的有限数据。现有方法(如 Sim-Score 和 CLIP-score)主要基于最近邻(nearest-neighbor)策略,即根据辅助样本与目标任务样本的相似性进行检索。然而,这些方法存在两个关键问题:
- 冗余性(Redundancy):样本独立评分机制忽略了多样性(diversity),导致检索到的样本高度相似或重复,无法全面覆盖目标任务的信息空间。
- 效率低下:冗余样本会降低训练效率,并可能引入噪声,影响少样本模型的泛化能力。

图2展示了COBRA与Sim-Score的对比:COBRA检索到多样且相关的样本(如左图),而Sim-Score检索出冗余样本(如红框所示)。这凸显了现有方法的缺陷。
论文进一步形式化了检索增强问题:给定目标任务数据集 Dtar={(xi,yi)}(包含少量标注样本)和辅助数据集 Daux={zi}(如 LAION-2B,规模大但标签空间可能无关),目标是选择子集 A⊆Daux 以增强训练,提升下游模型性能。
2. 核心方法:COBRA(COmBinatorial Retrieval Augmentation)
COBRA的核心创新是将检索问题建模为组合互信息(CMI)优化框架,该方法不仅考虑相似性,还引入多样性,通过子模函数(submodular functions)高效求解。关键贡献包括:
- CMI框架的泛化:论文证明现有检索方法(如 Sim-Score 和 CLIP-score)是 CMI 的特例(具体为图割互信息 GCMI),但 GCMI 无法处理多样性。COBRA 使用了一种替代 CMI 函数——基于设施位置(Facility Location)的互信息(FLMI)。
- FLMI函数:FLMI 定义为:
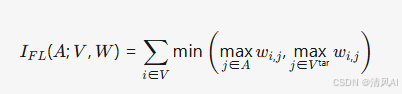
- 其中 W 是相似性矩阵(基于 CLIP 嵌入计算),V=Vtar∪Vaux。FLMI 鼓励选择既相关(高相似性)又多样(避免冗余)的样本,因为每个样本的贡献取决于其与目标集的关联以及与其他检索样本的交互。
- 软类平衡约束:为适应分类任务,COBRA 添加了一个子模函数来促进类平衡(class balance),避免硬约束导致的性能下降:
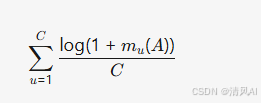
- 其中 mu(A) 是类 u 在检索集 A 中的样本数。这鼓励检索集在类分布上接近均匀。
- 可选质量评分:为过滤低质量样本(如 LAION-2B 中的噪声图像),COBRA 可整合质量函数(如 CLIP-score),进一步提升样本相关性。
- 优化与效率:COBRA 的目标函数是子模的,可通过贪心算法高效优化(时间复杂度低),并提供常数因子近似保证(1−e−1)。这确保了在实际大规模数据集(如 LAION-2B)上的可行性。
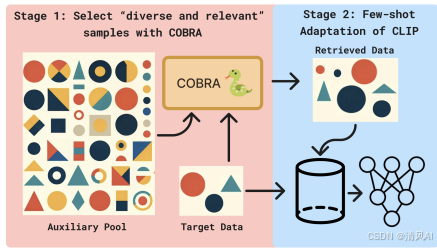
图1概述了COBRA流程:从辅助池中检索多样且相关的样本,结合目标任务数据训练少样本模型(基于CLIP骨干)。
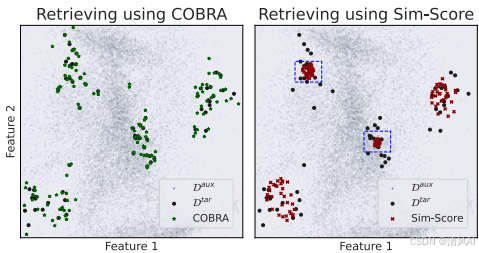
图3通过2D示例展示了COBRA的多样性优势:COBRA(左)均匀覆盖目标分布,而Sim-Score(右)选择聚集样本(如边界框所示)。
3. 实验设置与结果分析
论文在多个图像分类任务上验证 COBRA,使用 LAION-2B 作为辅助数据集,并与多种基线方法比较。实验流程包括:
- 目标任务:从标准数据集(如 ImageNet-1k、ImageNet-V2、Flowers102 等)采样少样本数据集(每类 1-16 个样本)。
- 检索步骤:对辅助数据预过滤(基于类名文本匹配),然后检索固定数量样本(约每类 16 个)。
- 少样本训练:在检索集和目标任务数据上,使用 CLIP 骨干 + 少样本适应技术(如 Linear Probe、Clip-Adapter、Tip-Adapter-F、CaFo)进行训练。
基线方法
- Sim-Score:基于图像-图像相似性(CLIP 嵌入)的最近邻检索。
- CLIP-score:基于文本-图像相似性(类名提示)的检索。
- Random:随机选择样本。
- SDXL-Aug:使用 Stable Diffusion XL 生成合成图像,再基于 CLIP-score 选择。
- No Retrieve:仅用目标任务数据训练(下界)。
关键结果
- 跨数据集性能:COBRA 在多个数据集上显著优于基线。例如,在 ImageNet-1k 上,COBRA 的准确率比 Sim-Score 高 0.4%–1.2%(见图5)。在 Flowers102 等数据集上,COBRA 与 Sim-Score 表现相近(因数据集同质性高),但总体上 COBRA 更鲁棒。
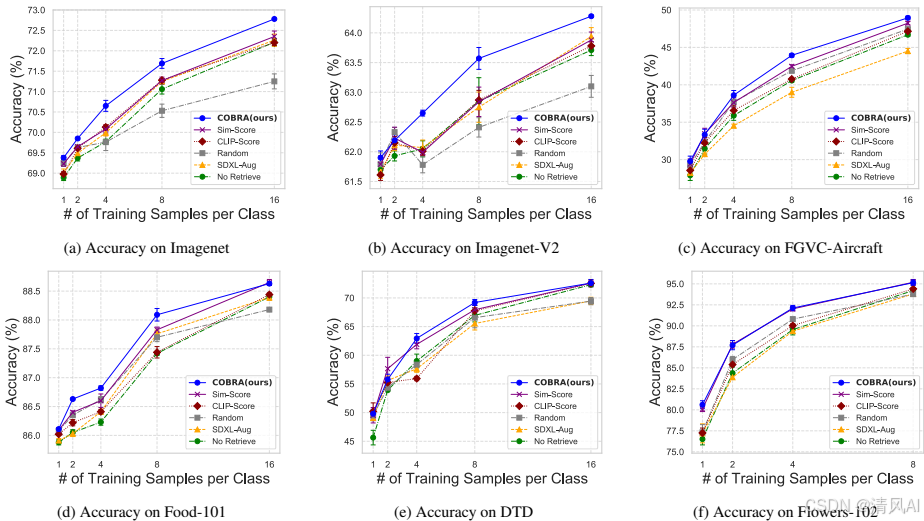
图5展示了跨数据集结果:COBRA在多个目标任务上优于其他检索策略(如ImageNet-1k 16-shot设置下)。
- 跨少样本技术性能:COBRA 在不同适应方法上一致领先(见图6)。例如,使用 Tip-Adapter-F 时,COBRA 在 ImageNet 上准确率达 72.78%,而 Sim-Score 为 72.35%。这表明 COBRA 的通用性。
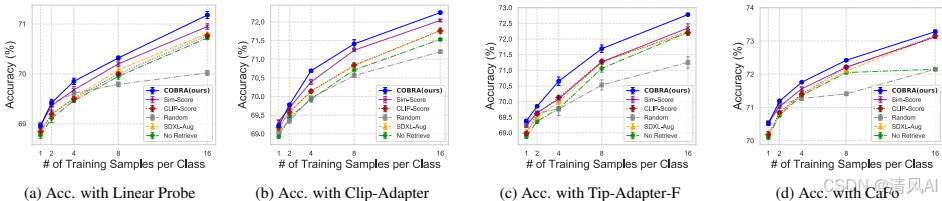
图6显示:在不同少样本适应技术下,COBRA检索始终优于其他策略(如Tip-Adapter-F和Linear Probe)。
- 平均排名分析:在 90+ 实验设置中(涵盖不同数据稀缺程度、数据集和随机种子),COBRA 的平均排名最低(见图4),证明其鲁棒性。
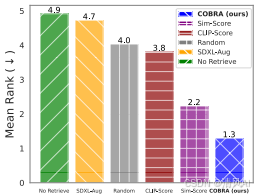
图4展示了平均排名:COBRA在多数实验中排名第一(排名越低越好),凸显其整体优势。
- 合成数据对比:SDXL-Aug(基于生成模型)表现不及检索方法(如 COBRA),因生成图像存在伪影(artifacts)和低多样性问题。
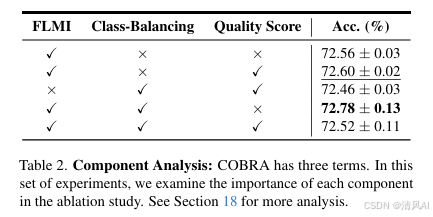
- 消融实验:FLMI 是 COBRA 的核心组件(贡献最大),软类平衡和质量评分提供额外增益(见表2)。其他 CMI 函数(如 log det-MI)效果较差,因计算复杂且需正定矩阵约束。
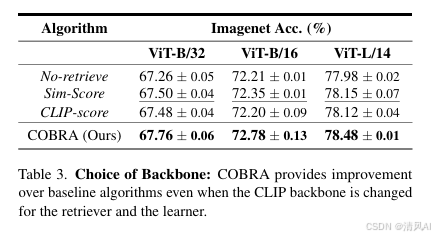
- 骨干网络鲁棒性:COBRA 在不同 CLIP 骨干(ViT-B/32、ViT-B/16、ViT-L/14)上均优于基线(见表3)。
4. 贡献与结论
- 主要贡献:
- 首次将 CMI 框架应用于检索增强,证明现有方法(如 Sim-Score)是其特例。
- 提出 COBRA,结合 FLMI、软类平衡和质量评分,高效解决多样性和相似性权衡问题。
- 在多个图像分类任务和少样本技术上验证了 COBRA 的优越性(平均准确率提升显著),计算开销可忽略。
- 实际意义:COBRA 为少样本学习提供了一种低成本、高效益的增强方案,尤其适用于标注数据稀缺的场景。
- 未来方向:扩展至生成任务(如 RAG in NLP)和更多模态,并探索 CMI 在其他检索应用中的潜力。
论文通过系统实验和理论分析,确立了多样性在检索增强中的关键作用,推动了该领域超越简单最近邻方法。
论文地址:https://openaccess.thecvf.com/content/CVPR2025/papers/Das_COBRA_COmBinatorial_Retrieval_Augmentation_for_Few-Shot_Adaptation_CVPR_2025_paper.pdf