EVA series系列(上)
目录
一、EVA
1、概述
2、方法
二、EVA-02
1、概述
2、架构
三、EVA-CLIP
1、概述
2、方法
四、EMU
1、概述
2、架构
3、训练细节
4、评估
一、EVA
1、概述
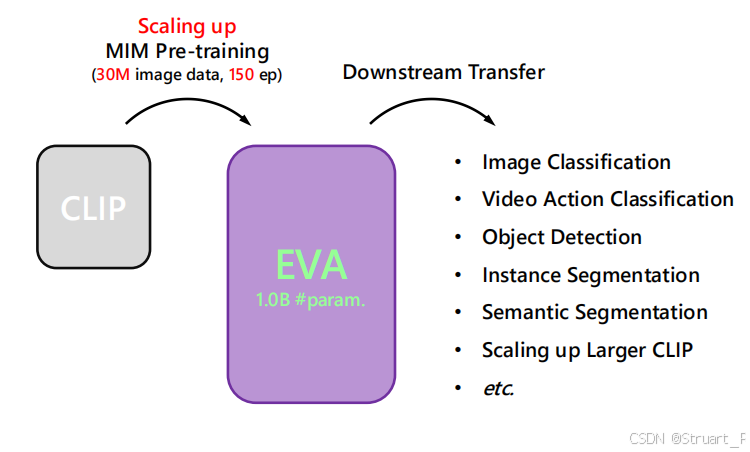
为探寻大规模表征学习任务的MIM预训练任务在ViT基础上扩展到1B参数量规模,结合10M级别(29.6M)未标注数据时的性能极限,构建高效、可扩展的视觉基础模型EVA。
EVA模型经过预训练后,可以实现数据量减少,计算资源有限,却可以扩展更高参数量,并超越以往同数据量下的(open data)下的图像/视频上的基准任务SOTA。并且显著提升CLIP模型训练和优化稳定性。
表征学习:让机器自动学习数据中的本质特征,替代传统人工设计特征(如SIFT,HOG),通过神经网络来逐层提取特征,再将预训练的表征泛化到多种下游任务中,在训练过程中无需人工标注数据,利用自监督经数据本身学习。
掩码图像建模(MIM):受NLP中BERT(随机语言建模)启发,迁移到视觉领域,随机遮盖输入图像的部分区域,训练模型基于上下文预测被遮盖内容。
2、方法
语义特征标记化的局限性
传统BEiT方法需要将视觉特征(Image)通过tokenizer(就是一个VQ-VAE编码器)离散成Tokens,并预测这个Tokens。主要目的是训练一个特征提取器(也就是BEiT encoder),可以用于下游任务,类似ViT可以用与支撑CLIP做跨膜态的检索,分类等下游任务。
具体做法,效仿MAE,将Image切成patches后进行random mask并flatten,经过BEiT encoder得到完整的包含预测图像信息的tokens,最终经过decoder 重建图像。
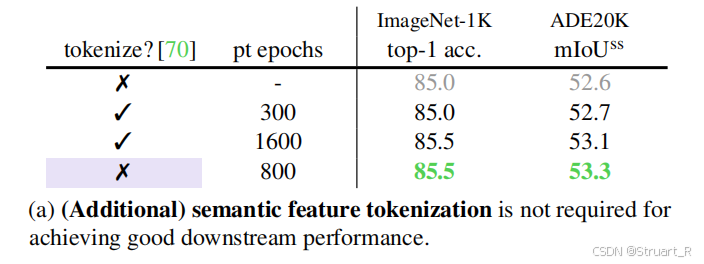
但是在EVA论文中提出,这种方法在量化过程中损失细微特征,并且离散空间难以表达视觉概念的连续性。并且做了以下实验,实验对比了以往CLIP方法,利用tokenizer进行训练,利用EVA方法进行训练在ImageNet上进行图像分类和ADE20K上进行语义分割下游任务。可以看到不带tokenizer时,800epochs就可达到85.5%的ImageNet精度,带tokenizer时需1600轮才能持平,证明了tokenizer方法脱缓了收敛,并且没有增益。
![]()
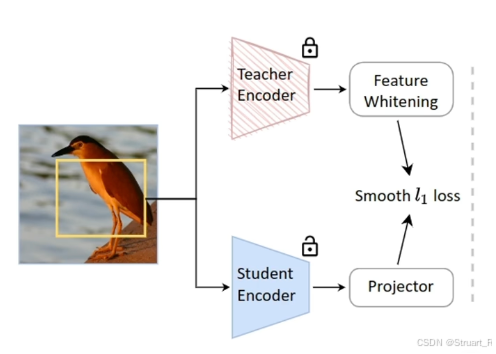
特征蒸馏机制失效
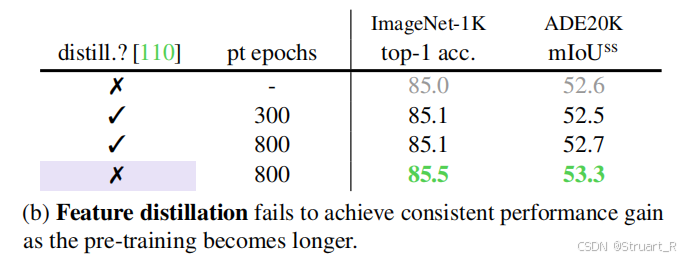
以往的蒸馏机制在长周期训练下精度增长并不明显,甚至阻碍了本身CLIP模型在下游任务的的精度增长。
传统方法在表征学习中引入tokenizer的离散化和蒸馏机制,导致限制了表征能力,同时收敛效率下降,难以支撑更大参数级的模型训练。
具体做法
EVA方法先通过预训练MIM算法遮蔽图像块预测CLIP特征,学习通用视觉表征。先输入图像进行分割得到patches,并随机遮蔽40%的块,并通过ViT编码器得到特征,而预训练的CLIP作为一个Teacher Model对EVA进行蒸馏,记住最后推理用的是这个EVA部分。
之后冻结预训练的主干部分,添加不同任务的特定头,比如图像分类添加线性分类头在ImageNet上微调,实例分割中添加Cascade Mask R-CNN在Objects365等数据集上微调,视频动作识别中扩展到视频空间。
最后应用于CLIP中,实现EVA-CLIP,再后面继续介绍。
二、EVA-02
1、概述
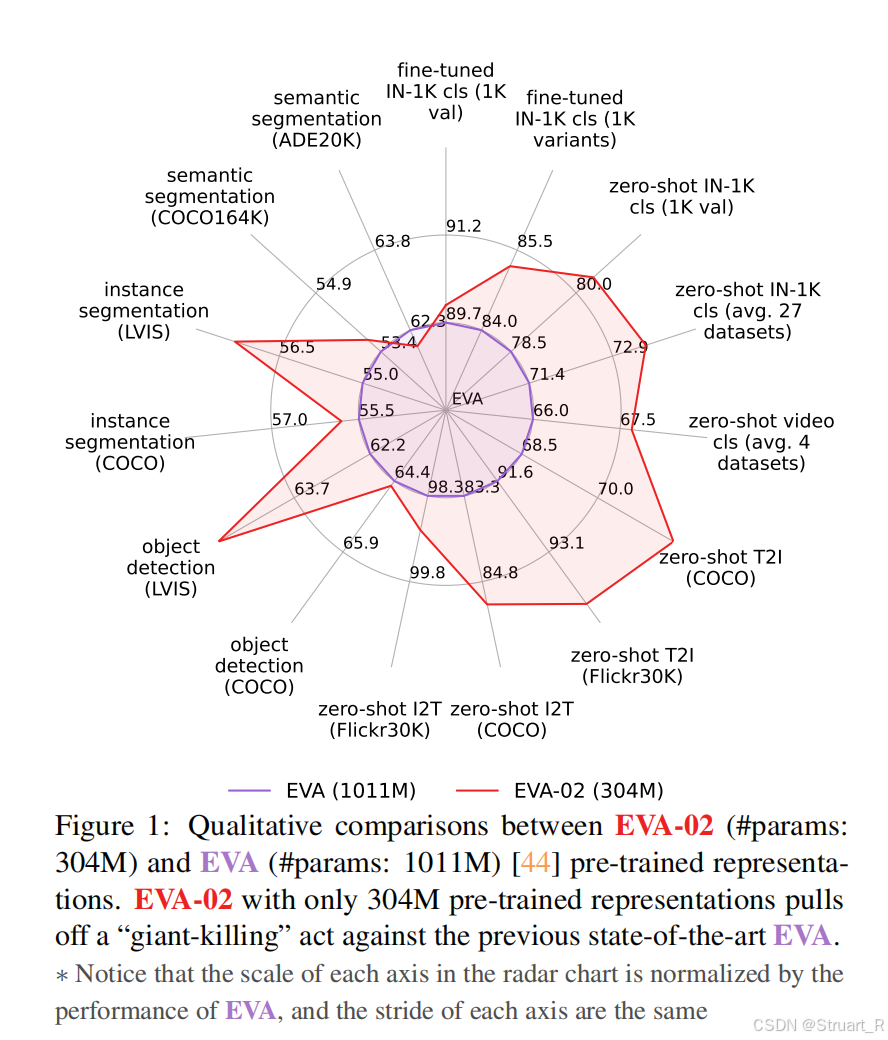
EVA-02基于EVA-01在结构上加了一些小的trick,将主干网络ViT修改为加trick后的TrV,训练过程中Teacher Model使用EVA-CLIP(EVA-01+CLIP),并且特征提取部分用了更小的参数量,在下图也可以看到,在不同的任务上全面碾压EVA-01。
2、架构
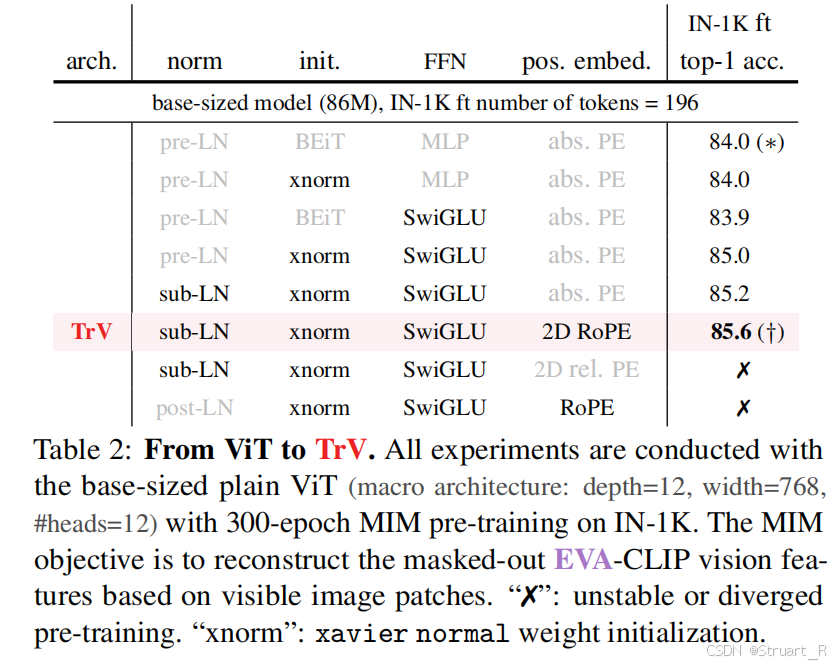
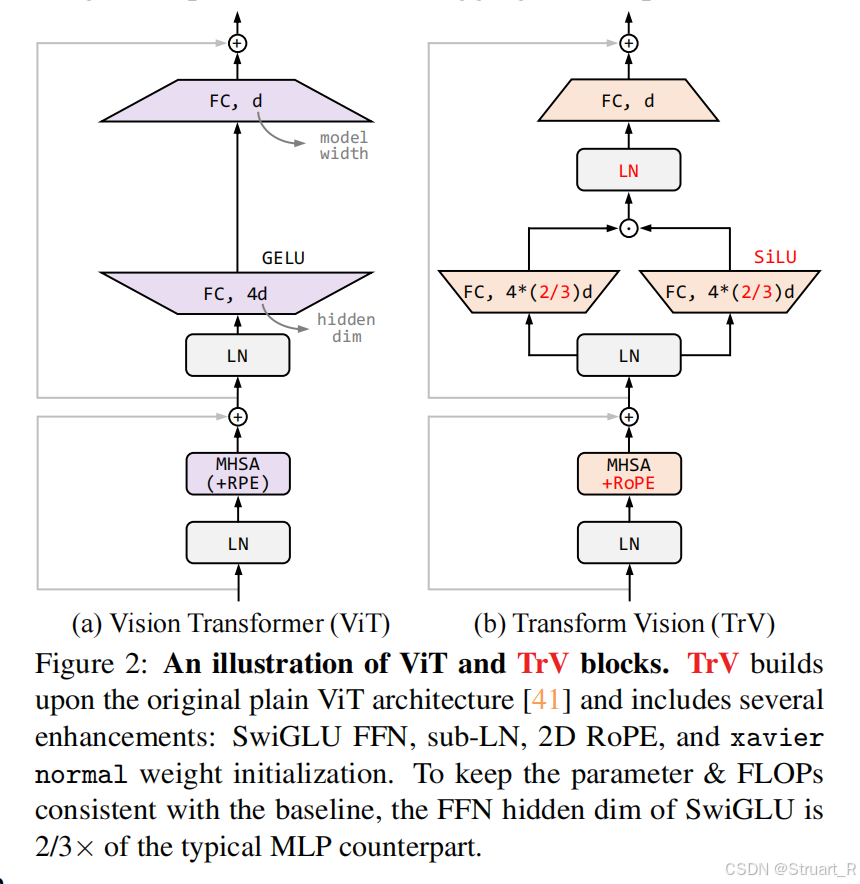
EVA-02从以往的ViT架构替换成Transform Vision(TrV),主要就是加了一些小的创新,可以看到包括sub- LN,xavier归一化,SwiGLU,2D RoPE等方法。
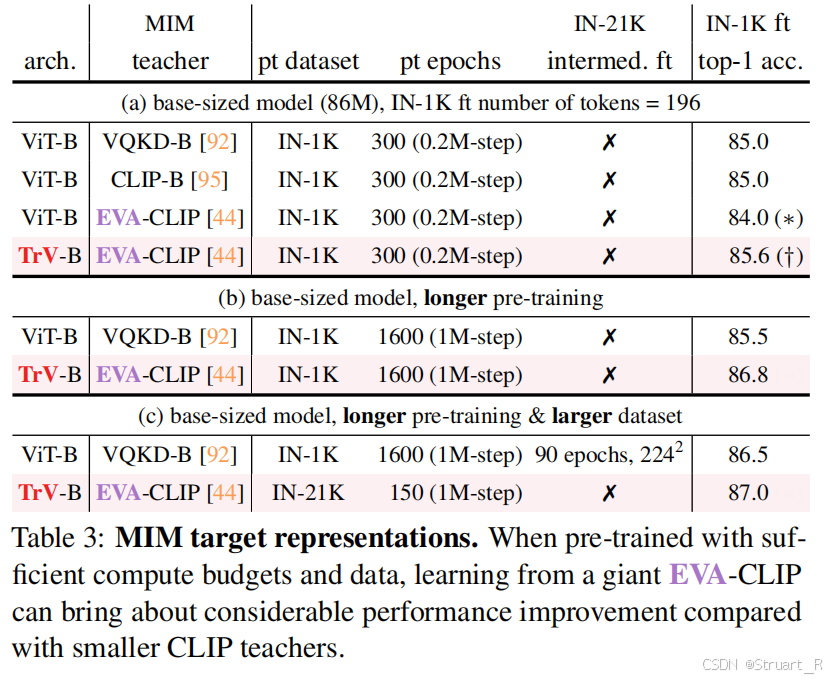
之后就是做了对比实验,验证EVA-02方法相比于以往方法的优势,其中ViT-B+VQKD-B就是BEiT模型,ViT-B+CLIP-B就是EVA-01,ViT-B+EVA-CLIP是EVA-CLIP,可以看到学生模型参数过于庞大时,也会造成收敛更慢,另外EVA-02也有更大的扩展性(提高数据量仍然可以提点)。
EVA-02在训练上仍然用EVA-01相同的方式,数据集使用了比EVA-01更多的38M的数据量。并使用EVA-CLIP作为teacher model,尤其是在zero-shot的多任务上,EVA-CLIP可以全面超过CLIP的性能。
三、EVA-CLIP
1、概述
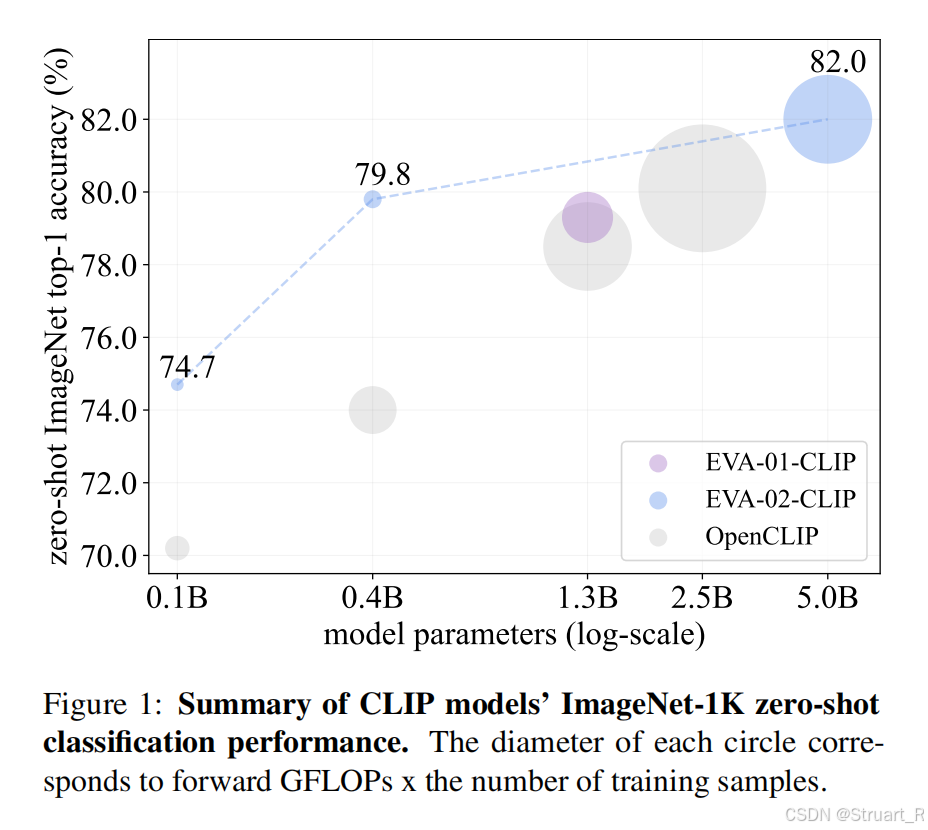
由于CLIP模型随着数据量增加,训练时,计算量更大,训练不稳定,EVA-CLIP在保持CLIP模型参数量的同时,用更低的训练成本,达到更多训练数据量的更高的准确率。(其中下图圆半径代表训练数据量大小)。
2、方法
(1)采用预训练的EVA模型提取特征并加速收敛
(2)使用LAMB优化器训练EVA-CLIP,LAMB优化器专门用于大batchsize而设计,支持自适应分层学习率与超大规模batchsize训练(131K)。
(3)随机mask 50%的image tokens,降低一半复杂度,时间减半,利用Flash Attention加速注意力计算,降低训练15%耗时。
数据上合并LAION-2B与COYO-700M构建Merged-2B数据集,训练硬件支撑144 x A100(80G)训练5B模型,太恐怖了)
四、EMU
1、概述
EMU是一种统一的多模态基础模型,通过自回归训练实现图像、文本、视频的跨模态理解,并且可以支持无差别处理单一模态或者多模态的输入,比如交替出现的图像和文本。EMU作为多模态的接口,支持T2I,I2T,上下文生成图像,并且在视频问答,视觉问答,图像理解,图像生成等零样本/少样本任务中,一度超越当时主流多模态模型的性能。
下图给出图像描述,图像问答,图像融合,上下文图像转文字,视频问答上的效果。

2、架构
EMU由四部分组成,视觉编码器,因果变换器,多模态建模器,视觉解码器,如下图。
视觉解码器利用EVA-CLIP(40层ViT)提取图像帧视频帧特征,(视频帧特征扩展本身EVA-CLIP的维数,在EVA-CLIP中已经训练出)
因果变换器目的是将二维的图像特征信息,转换为有因果关系的线性序列,并且添加[IMG]为起止标记。因果变换器本质上是一个12层的Transformer的Decoder部分,包含因果自注意力,交叉自注意力,FFN。
多模态建模器,以LLaMA-13B为基础,处理图文交错的序列。LLaMA是一个decoder-only Transformer架构。
视觉解码器通过微调Stable Diffusion,将回归出的视觉嵌入解码成图片。
而另外两个分类头和回归头将通过训练时监督部分进行介绍。

训练的目的就是输入一组unlabeled的语料库可以是图文对,图文交替文档,甚至有字幕的视频,最后使得回归出来的最接近语料库。所以在训练中设计了分类头和回归头,分类头用于输出离散文本序列,通过交叉熵来监督。回归头用于对视觉tokens经decoder解码图像,利用L2损失监督。怎么分出是用分类头还是回归头呢,把所有需要进分类头的加一个[IMG]。
3、训练细节
数据集
图文对: LAION-2B,LAION-COCO,LAION-2B为LAION-5B的子集,LAION-COCO共600M由BLIP标注
视频文本对:WebVid-10M,并用启发式规则剔除text中无用信息。
图文交织信息:Multimodal-C4包含7500w图文文档,并在每个文档中抽取1024长度序列
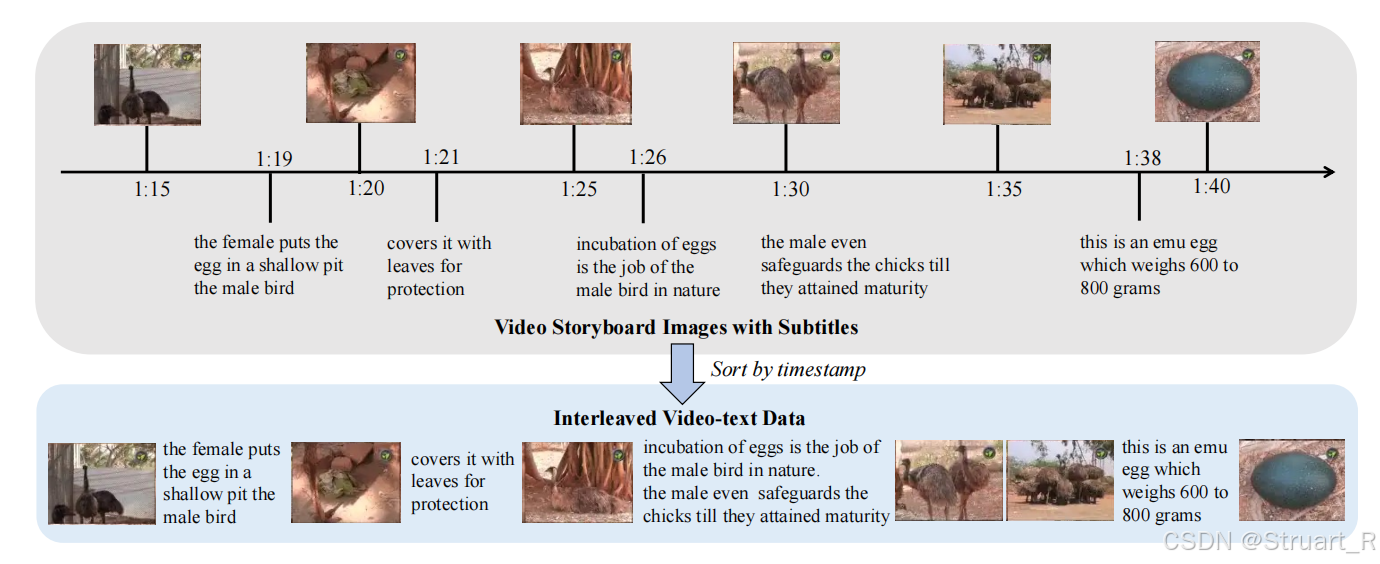
视频文本交织信息:YT-Storyboard-1B包含从Youtube上的18M video,从下图可以看到,根据时间轴上图片和文字理解的因果关系,组成了一个视频文本交织文档
训练过程
训练过程中冻结Image encoder,LLaMA,以及Decoder中的VAE部分,只保留U-Net为training。并在训练过程中随机选择10%的图像嵌入进行丢弃,以此来实现classifier-free的工作。
指令微调
指令微调的目的:通过监督微调使得预训练模型可以理解复杂指令,适应多模态交互场景(如问答、描述、推理),并解锁零样本/少样本任务能力,克服预训练任务的局限性。
微调过程中,冻结预训练EMU的所有参数,仅添加LoRA模块,插入到Transformer的自注意力层中。
这里简要插入一段具体做法的代码。LoRA的配置和pert模型转换函数通过peft引入,LoraConfig类用于建立一个LoRA,其中r代表rank,lora_alpha=16代表权重矩阵分解成两个低秩矩阵,并缩放到以往的1/16,来减少参数量。target_modules指定同时影响哪些投影层添加到LoRA中。而get_peft_model则将预训练模型转换为PEFT模型并引入LoRA模块,这样不需要全参数的微调整个模块,参数量只需要增加13M(小于总参数量1%),并且存储开销只有52MB。

数据上采用数据混合策略,包括语言指令,图像指令,视频指令,并使用<System Message>[USER]:<Instruction>[ASSISTANT]:<Answer>的方法进行结构性对话,最后计算<Answer>部分的输出损失。
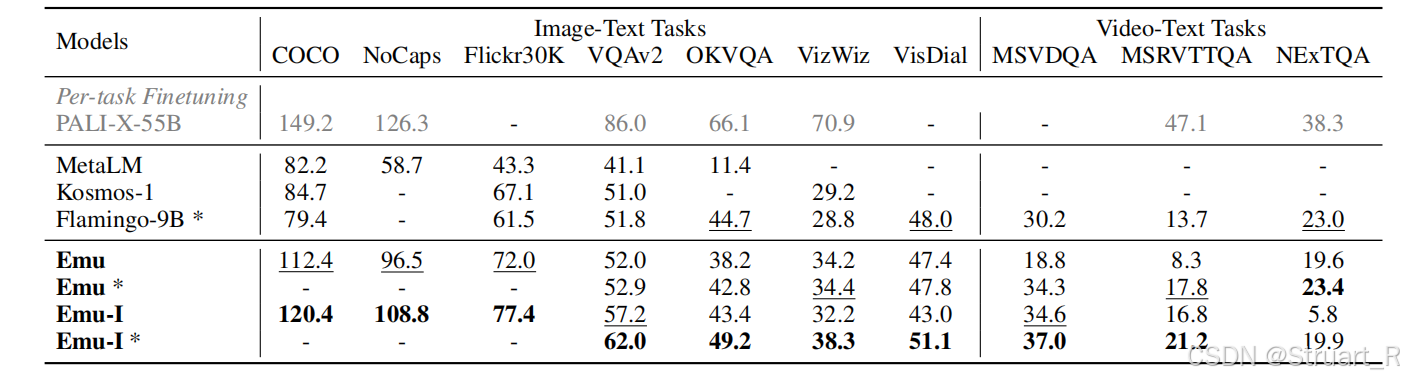
根据上表对比,Emu-I(经过指令微调)在各项指标中高于Emu。Emu *是用于建立复杂开放任务上的,通过从训练集中选取两个同类任务文本,并移除对应图片,作为前缀输入到prompt中的方法。Emu*可以从VQA任务中理解,如下。而Emu则只有当前问题,如描述该图片。
# Emu* 输入构建伪代码
text_prompt = """
Q: What is in the image? A: A cat. # 示例1(无图)
Q: What color is it? A: White. # 示例2(无图)
Q: {当前问题} # 待回答问题
"""
input_sequence = [图片嵌入] + tokenize(text_prompt) # 图文交错序列
output = model.generate(input_sequence) # 生成答案4、评估
对EMU的评估建立了多维度的完善评估体系。
| 任务类型 | 数据集 | 评估指标 | 创新点 |
| 图像理解 | COCO, NoCaps | CIDEr↑ | 零样本超越Flamingo-9B 33分 |
| 视觉问答 | VQAv2, OKVQA | 准确率↑ | 引入知识推理链(table 10) |
| 视频理解 | MSVDQA, NextQA | WUPS↑ | 首次支持视频字幕交错输入 |
| 文本生成图像 | COCO | FID↓ | 联合视觉嵌入回归 |
| 开放场景理解 | MM-Vet | 多能力综合得分 | 6大核心能力分解评估 |
思维链(Chain of Thought,CoT)在EMU中作为一种多模态推理增强技术,通过生成中间推理步骤来提升复杂任务的表现。先对输入图像进行文本描述得到"caption",再将描述与问题拼接获得新问题的答案。"A picture of {caption}.based on the picture,{question} answer:"

参考论文:
[2211.07636] EVA: Exploring the Limits of Masked Visual Representation Learning at Scale
[2303.11331] EVA-02: A Visual Representation for Neon Genesis[2303.15389] EVA-CLIP: Improved Training Techniques for CLIP at Scale
[2309.15807] Emu: Enhancing Image Generation Models Using Photogenic Needles in a Haystack