企业级实时流处理:Kafka Streams完整解决方案
在当今数据驱动的世界中,实时数据处理能力已成为企业竞争力的关键因素。Kafka Streams作为Apache Kafka生态系统中的流处理库,提供了一种高效、可靠的实时数据处理解决方案。本文深入探讨了Kafka Streams的核心概念、架构设计、关键特性以及实际应用场景,通过详细的代码示例展示了如何构建一个完整的流处理应用。无论您是数据工程师、架构师还是技术决策者,本文都将为您提供关于Kafka Streams的全面理解,帮助您评估其在企业级应用中的价值。
Kafka Streams:实时数据处理的强大工具
什么是流处理?
流处理是一种连续处理无限数据流的技术,能够在数据到达时立即进行分析和处理。与传统的批处理不同,流处理强调实时性,能够在毫秒级别内产生洞察。这种能力使得流处理特别适合需要即时响应的应用场景,如金融交易监控、物联网设备数据分析、实时推荐系统等。
流处理的核心优势在于其能够处理持续不断的数据流,而无需等待数据积累到一定量再进行批量处理。这种特性不仅提高了数据处理的时效性,还简化了系统架构,避免了批处理中常见的数据采集、存储、批处理和结果整合的复杂流程。
Kafka Streams与Kafka的关系
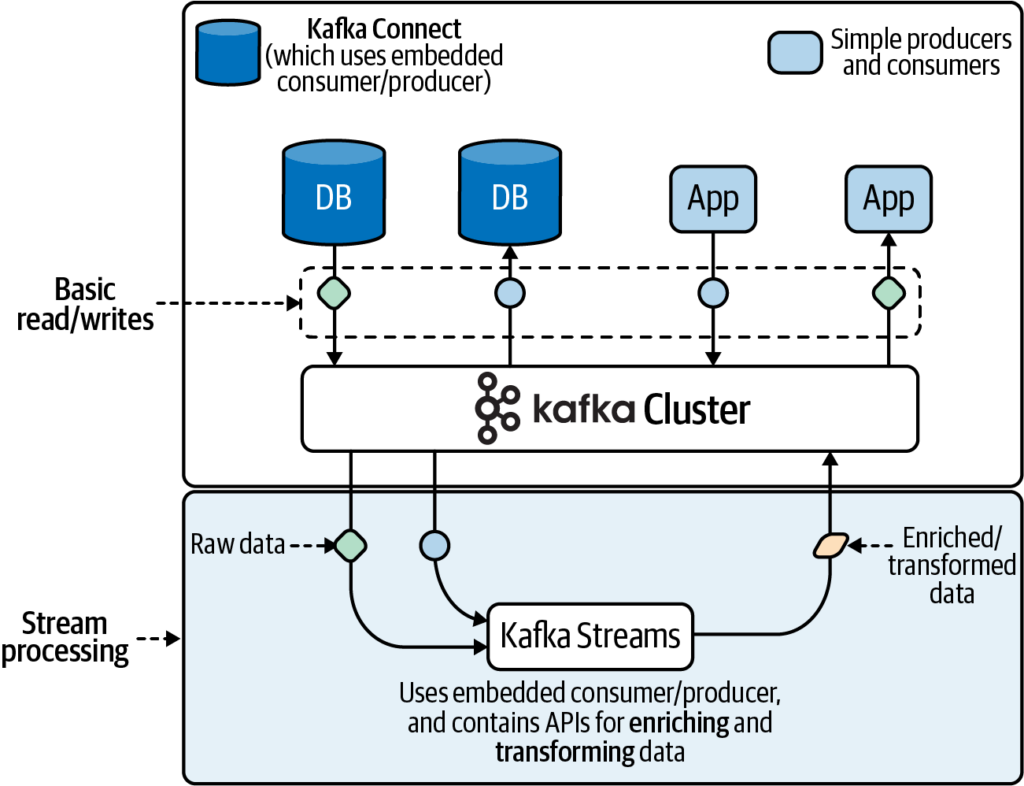
Apache Kafka是一个分布式流处理平台,最初设计用于高吞吐量的消息传递。Kafka的核心由四个API组成:生产者API、消费者API、连接器API和流处理API。Kafka Streams正是基于流处理API构建的客户端库,它提供了一种更高级别的抽象,简化了流处理应用的开发。
值得注意的是,虽然可以直接使用Kafka的消费者和生产者API构建流处理应用,但这种方式需要开发者自行管理消费者组、偏移量、分区分配等复杂细节。Kafka Streams通过抽象这些底层复杂性,使开发者能够专注于业务逻辑的实现,大大提高了开发效率。

Kafka Streams的核心概念与架构
处理拓扑:流处理的数据流图
Kafka Streams应用的核心是处理拓扑,它定义了数据如何从输入主题流向输出主题的路径。处理拓扑由一系列处理器节点和连接这些节点的流组成,形成一个有向无环图(DAG)。
在拓扑中,源处理器从Kafka主题读取数据,中间处理器执行各种转换操作,而接收处理器将结果写入输出主题。这种设计使得开发者可以灵活地构建复杂的数据处理流程,同时保持代码的清晰和可维护性。
时间语义:理解事件、处理和摄入时间
时间是流处理中的关键概念。Kafka Streams支持三种时间语义:
- 事件时间:事件实际发生的时间,通常由事件本身携带的时间戳表示。
- 处理时间:流处理应用实际处理事件的时间。
- 摄入时间:事件被写入Kafka主题的时间。
正确理解和使用这些时间语义对于确保流处理应用的正确性和一致性至关重要,特别是在处理乱序事件或构建窗口化聚合时。
状态管理:有状态与无状态处理
Kafka Streams支持两种处理模式:有状态和无状态。无状态处理简单直接,每个记录独立处理,不依赖于之前的记录或状态。而有状态处理则允许应用维护和更新状态信息,支持更复杂的操作如聚合、连接和窗口化计算。
Kafka Streams通过本地状态存储实现高效的状态管理,这些状态存储可以分布在集群中的不同节点上,并自动复制以保证容错性。这种设计使得有状态处理既高效又可靠。
构建Kafka Streams应用:实战示例
开发单词计数应用
让我们通过一个经典的单词计数示例来展示Kafka Streams的应用开发过程。这个应用将从输入主题读取文本数据,统计每个单词出现的次数,并将结果写入输出主题。
- 创建输入流:从指定的Kafka主题读取原始文本数据。
- 文本处理:将文本分割为单词,转换为小写形式。
- 计数聚合:对每个单词进行计数统计。
- 结果输出:将统计结果写入输出主题。
1. Maven依赖配置
首先确保您的pom.xml中包含以下依赖:
<dependencies><!-- Kafka Streams核心依赖 --><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-streams</artifactId><version>3.6.0</version> <!-- 使用最新稳定版本 --></dependency><!-- 可选:用于简化日志配置 --><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-simple</artifactId><version>1.7.36</version></dependency>
</dependencies>
2. 完整的Java实现代码
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KTable;
import org.apache.kafka.streams.kstream.Produced;import java.util.Arrays;
import java.util.Properties;
import java.util.regex.Pattern;public class WordCountApplication {public static void main(String[] args) {// 1. 配置应用属性Properties props = new Properties();props.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-application");props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); // Kafka集群地址props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());// 设置精确一次处理语义(如果Kafka版本支持)props.put(StreamsConfig.PROCESSING_GUARANTEE_CONFIG, StreamsConfig.EXACTLY_ONCE_V2);// 2. 创建流处理拓扑StreamsBuilder builder = new StreamsBuilder();// 3. 从输入主题创建KStreamKStream<String, String> textLines = builder.stream("wordcount-input");// 4. 处理逻辑: 分割文本、计数单词Pattern pattern = Pattern.compile("\\W+", Pattern.UNICODE_CHARACTER_CLASS);KTable<String, Long> wordCounts = textLines// 将每行文本分割为单词.flatMapValues(value -> Arrays.asList(pattern.split(value.toLowerCase())))// 过滤掉空字符串.filter((key, word) -> word != null && !word.isEmpty())// 将单词作为key重新映射.map((key, word) -> new KeyValue<>(word, word))// 按单词分组.groupByKey()// 计数.count();// 5. 将结果写入输出主题wordCounts.toStream().to("wordcount-output", Produced.with(Serdes.String(), Serdes.Long()));// 6. 构建并启动流处理应用KafkaStreams streams = new KafkaStreams(builder.build(), props);// 添加关闭钩子以优雅地关闭应用Runtime.getRuntime().addShutdownHook(new Thread(streams::close));// 启动应用streams.start();}
}
3. 配置文件示例(streams.properties)
虽然上面的代码直接在代码中设置了配置属性,但更推荐的做法是使用外部配置文件:
# Kafka broker地址
bootstrap.servers=localhost:9092# 应用ID(必须唯一)
application.id=wordcount-application# 默认键和值的序列化器
default.key.serde=org.apache.kafka.common.serialization.Serdes$StringSerde
default.value.serde=org.apache.kafka.common.serialization.Serdes$StringSerde# 处理保证(可选)
processing.guarantee=exactly_once_v2# 提交间隔(毫秒)
commit.interval.ms=1000
然后在代码中加载这个配置文件:
// 替换直接设置属性的代码
Properties props = new Properties();
try (InputStream input = WordCountApplication.class.getClassLoader().getResourceAsStream("streams.properties")) {if (input == null) {System.err.println("无法找到配置文件streams.properties");return;}props.load(input);
} catch (IOException ex) {ex.printStackTrace();
}
4. 测试应用
创建输入主题:
kafka-topics.sh --create \--bootstrap-server localhost:9092 \--replication-factor 1 \--partitions 1 \--topic wordcount-input
创建输出主题:
kafka-topics.sh --create \--bootstrap-server localhost:9092 \--replication-factor 1 \--partitions 1 \--topic wordcount-output
生产测试数据:
kafka-console-producer.sh --broker-list localhost:9092 --topic wordcount-input
输入一些测试文本,例如:
Hello Kafka Streams
This is a test message
Kafka is awesome
Streams processing is powerful
消费输出结果:
kafka-console-consumer.sh --bootstrap-server localhost:9092 \--topic wordcount-output \--from-beginning \--formatter kafka.tools.DefaultMessageFormatter \--property print.key=true \--property print.value=true \--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
5. 高级特性扩展
添加窗口化计数(统计每分钟单词出现次数):
import org.apache.kafka.streams.kstream.TimeWindows;
import java.time.Duration;// 在原有处理逻辑后添加窗口化
KTable<Windowed<String>, Long> windowedWordCounts = textLines.flatMapValues(value -> Arrays.asList(pattern.split(value.toLowerCase()))).filter((key, word) -> word != null && !word.isEmpty()).map((key, word) -> new KeyValue<>(word, word)).groupByKey().windowedBy(TimeWindows.of(Duration.ofMinutes(1))) // 1分钟窗口.count();// 输出窗口化结果到新主题
windowedWordCounts.toStream().to("wordcount-windowed-output", Produced.with(WindowedSerdes.timeWindowedSerdeFrom(String.class), Serdes.Long()));
添加交互式查询功能:
// 在启动应用后添加
ReadOnlyKeyValueStore<String, Long> localStore = streams.store("wordcount-application-wordcount-output-store", QueryableStoreTypes.keyValueStore());// 可以定期查询本地存储的状态
new Thread(() -> {while (true) {try {Thread.sleep(5000);// 查询特定单词的计数Long count = localStore.get("kafka");System.out.println("Current count for 'kafka': " + (count != null ? count : 0));} catch (InterruptedException e) {Thread.currentThread().interrupt();break;}}
}).start();
注意:要使交互式查询工作,需要配置应用以启用查询功能,并可能需要额外的依赖和配置。
这个完整的示例展示了Kafka Streams的核心功能实现,包括基本的单词计数、配置管理、测试方法以及高级特性如窗口化处理和交互式查询的扩展。您可以根据实际需求调整和扩展这个基础示例。
完整的代码示例展示了如何使用Kafka Streams DSL(领域特定语言)以声明式的方式构建这个处理流程。DSL提供了丰富的操作符如flatMapValues、map、groupByKey、count等,使得复杂的数据转换变得简单直观。
应用部署与运行
构建完成后,只需几行代码即可启动Kafka Streams应用。应用会持续运行,处理输入主题中的新数据,并将结果写入输出主题。通过Kafka控制台消费者,可以实时查看处理结果。
这个简单的示例展示了Kafka Streams的强大能力:只需少量代码就能构建一个完整的、生产级的流处理应用,具备高吞吐量、低延迟和容错能力。
Kafka Streams的优势与适用场景
主要优势
- 简化开发:通过抽象底层复杂性,使开发者能够专注于业务逻辑。
- 高可扩展性:天然支持水平扩展,能够处理海量数据。
- 容错性:利用Kafka的复制机制和本地状态存储,确保故障恢复能力。
- 精确一次处理语义:保证每条记录只被处理一次,避免数据丢失或重复。
- 无缝集成:与Kafka生态系统完美集成,支持安全特性如SSL和SASL。
典型应用场景
- 实时数据分析与监控
- 事件驱动架构中的消息处理
- 物联网设备数据处理
- 实时推荐系统
- 金融交易监控与欺诈检测
总结
Kafka Streams代表了实时流处理技术的一个重要发展方向,它通过提供高级抽象和强大功能,使企业能够构建高效、可靠的流处理应用。本文详细介绍了Kafka Streams的核心概念、架构设计和实际应用,展示了其在简化开发、提高可扩展性和确保数据一致性方面的显著优势。
随着数据量和实时性要求的不断增长,Kafka Streams等流处理技术将在企业架构中扮演越来越重要的角色。无论是构建全新的实时应用,还是增强现有系统的实时能力,Kafka Streams都是一个值得考虑的强大工具。
对于技术团队而言,评估和采用Kafka Streams不仅能够提升数据处理能力,还能为业务创新提供技术支持。通过本文的介绍,希望您对Kafka Streams有了更深入的理解,并能够在实际项目中充分利用这一技术带来的优势。