嵌入式开发学习(第二阶段 C语言笔记)
MakeFile
基本概念
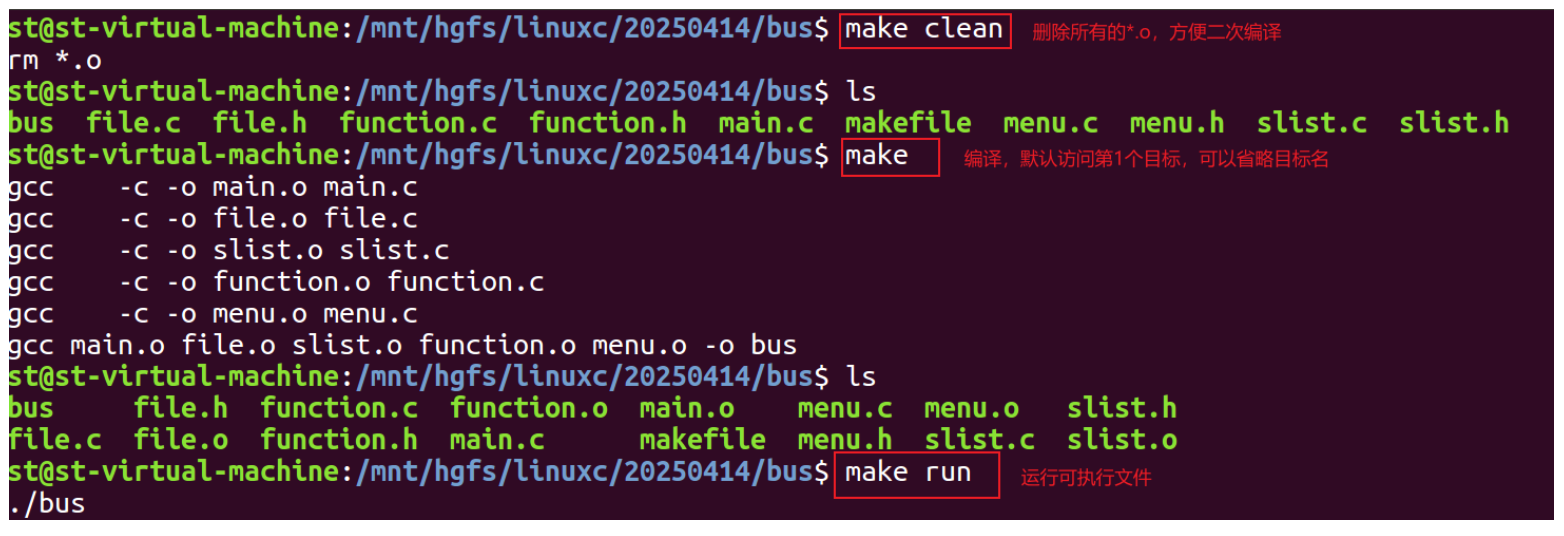
make:(工程管理器)主要通过makefile配置文件来工作。
makefile:简单来说:makefile可被视为make配置文件开配置make的一些工作细节。比如编译选项、指定编译环境makefile是被执行的。这个文件需要我们自己创建,文件名不能区分大小写
makefile语法结构
一般格式:
目标:[依赖]命令
注意:命令前的空格需要使用Tab键
解释
目标:生成文件/执行的动作
依赖:生成目标需要的东西
命令:依赖生成目标的方式方法
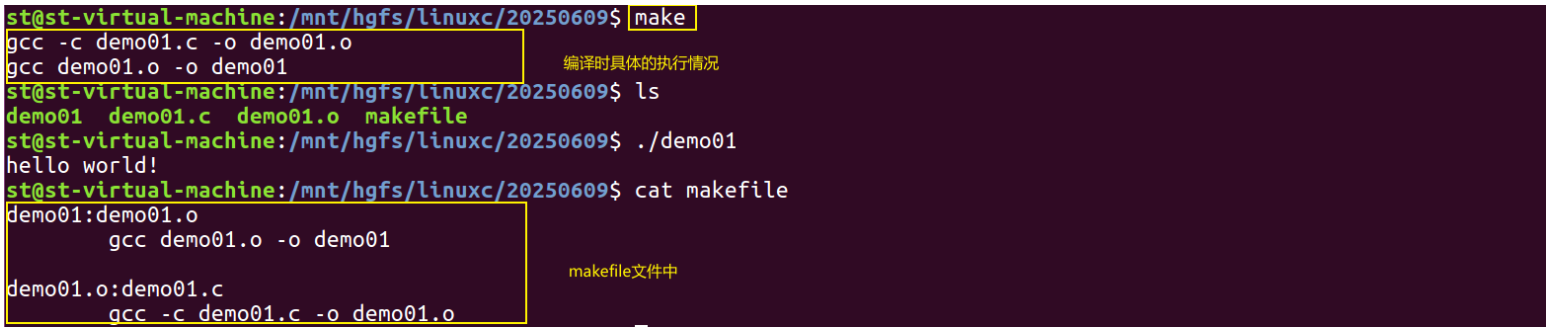
案例:
demo01.c : demo01.cgcc demo01.o -o demo01.c
demo01.o : demo01.c gcc -c demo01.c -o demo01.o
注意:makefile在执行的时候,默认执行最顶层的那个目标
通过 make 指令,直接进行编译:
解释:
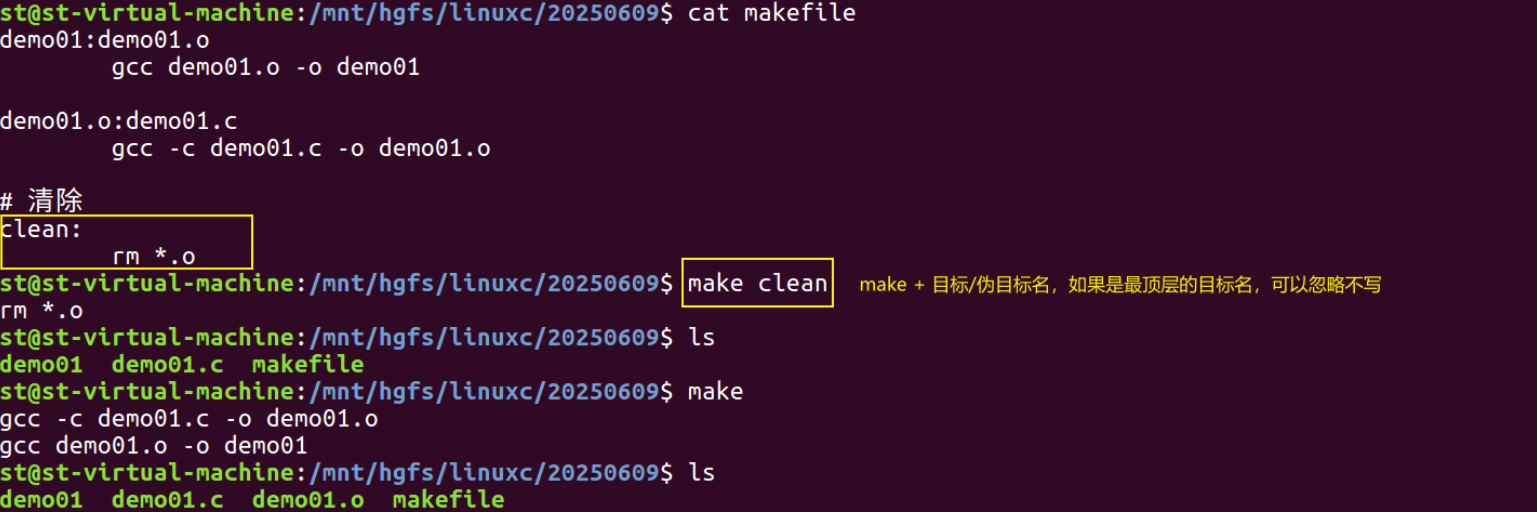
伪目标:没有依赖的目标,一般都是执行一个动作。
案例:
# 伪目标案例
clean:rm *.o
makefile中的变量
预定义变量
CC:C编译器名称,,默认值是cc
RM:文件删除的程序名,默认值是RM
…
注意:虽然预定义变量是makefile定义的;但我们仍然可以自定义和预定义变量名同名的变量。
自动变量
@:目标
^:所有依赖(^)
<:依赖中的第一个
用户自定义变量
变量的定义:
变量名 = 值;
注意:一般变量名使用大写字母。
变量的使用:
$(变量名)
说明:如果变量是一个字符,则变量使用小括号可以省略不写
举例:
# 单字符变量定义
O = main.o
# 单字符变量使用
$O / $(O)# 多字符变量定义
OBJS = main.o slist.o
# 多字符变量使用
$(OBJS)
makefile中的规则
隐含规则
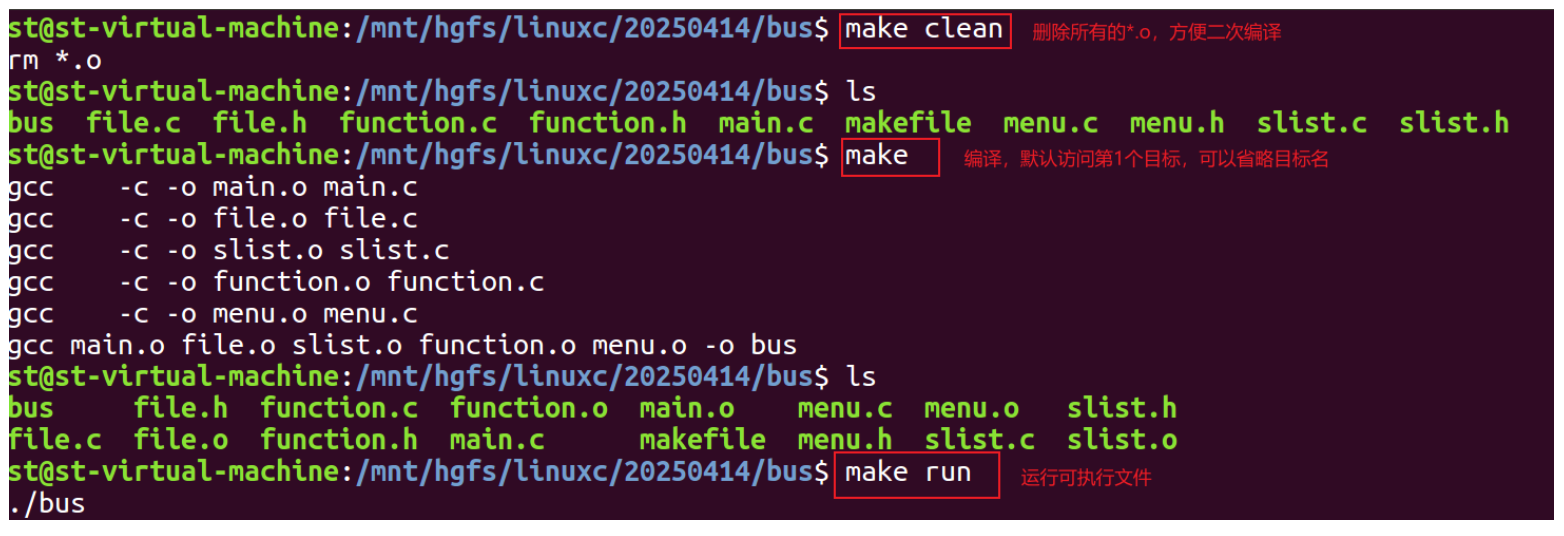
makefile可以根据指定 *.o 文件找到所需要的同名源文件*.c,并且自动帮助我们生成对应的编译语句。
# 定义变量
OBJS = main.o file.o slist.o function.o menu.o
CC = gcc
TARGET = ./bus# 规避目标与源文件同名,使用 .PHONYL来规避
.PHONY: clean# 构建编译伪目标,默认执行第一个目标/伪目标
bus:$(OBJS)$(CC) $^ -o $@ # gcc main.c file.c slist.c function.c menu.c -o bus# 构建清除伪目标
clean:rm *.o# 构建运行伪目标
run:$(TARGET)
隐含规则弊端:如果目标是一个动作,如果当前工程中存在一个同名的源文件,根据隐含规则makefile就会帮助我们生成对应的编译语句,从而引起冲突
解决方案:用 .PHONY 关键字告诉makefile不要为.PHONY修饰的目标采用隐含规则。
静态规则
如果我们子啊生成*.o文件的同时,需要自行指定额外的比阿姨选项例如: -dPIC ,-lm,则可以使用静态规则
一般格式
原始列表:匹配模式:依赖命令
利用匹配模式从原始列表中匹配出来
举例:
OBJ2 = main.o file.o slist.0$(OBJ2): %.o :%.c$(CC) -c $< -o $@ -lm // gcc -c main.c -o main.o -lm
makefile中的函数应用
wildcard
-
功能:利用指定参数匹配文件,比如说某个文件夹下所有文件
-
使用:
基本用法
MakeFile# 获取所有 .c 文件
SRCS := $(wildcard *.c)# 获取多个类型的文件
FILES := $(wildcard *.c *.h)
多目录匹配
MakeFile# 匹配 src 目录下所有 .c 文件
SRCS := $(wildcard src/*.c)# 递归匹配所有子目录中的 .c 文件
SRCS := $(wildcard src/**/*.c)
多模式组合
MakeFile# 匹配 src/ 和 include/ 目录下的 .h 文件
HEADERS := $(wildcard src/*.h include/*.h)
patsubst
-
功能:进行文本替换
-
语法:
$(patsubst 模式, 替换格式, 文本列表) -
参数说明:
- 模式:包含通配符 % 的匹配模式
- 替换格式:包含 % 的替换格式
- 文本列表:要进行替换操作的字符串列表(空格分隔)
-
使用:
# 将 .c 文件替换为 .o 文件 $(patsubst %.c, %.o, main.c utils.c) # 结果: main.o utils.o
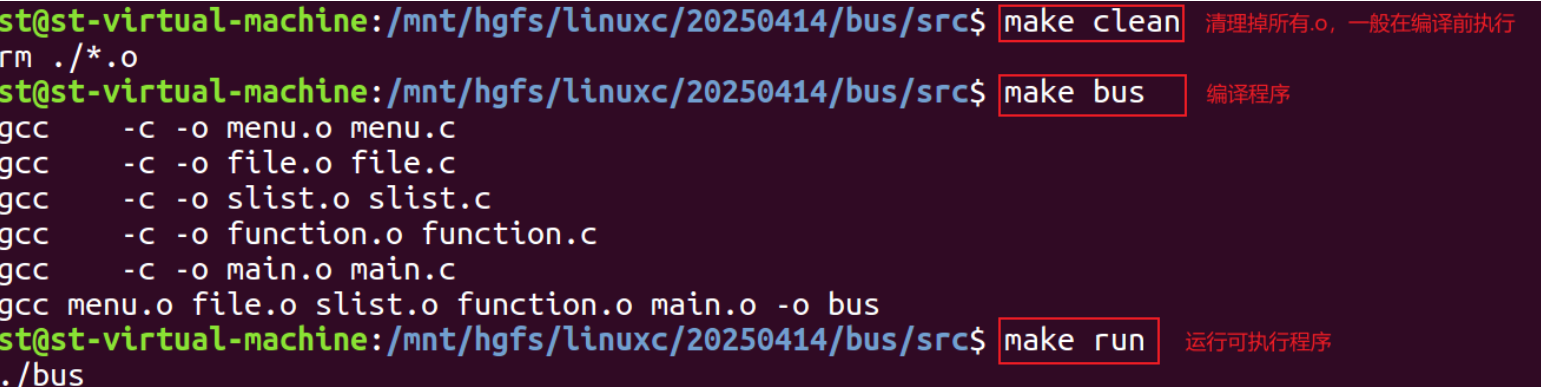
完整案例
# 定义变量
# 匹配当前文件夹所有的*.c,变量SRCS其实保存的是main.c file.c slist.c function.cmenu.c
SRCS := $(wildcard *.c)
# 将SRCS中的.c替换成.o,返回的是 main.o file.o slist.o function.o menu.o
OBJS := $(patsubst %.c, %.o, $(SRCS))
CC := gcc
# 可执行程序的名称
PROJECT_NAME := bus
TARGET := ./$(PROJECT_NAME)# 规避目标与源文件同名,使用 .PHONY
.PHONY: all clean run# 默认目标
all: $(PROJECT_NAME)# 构建可执行文件
$(PROJECT_NAME): $(OBJS)$(CC) $^ -o $(TARGET)# 从.c生成.o的规则
%.o: %.c$(CC) -c $< -o $@# 构建清除伪目标
clean:rm -f $(OBJS) $(TARGET)# 构建运行伪目标
run: $(PROJECT_NAME)$(TARGET)
可以单独指定部分编译规则,优化如下:
# 定义变量
# 匹配当前文件夹所有的*.c,变量SRCS其实保存的是main.c function.c file.c menu.c
SRCS := $(wildcard *.c)
# 将SRCS中的.c替换成.o,返回的是main.o function.o file.o menu.o
OBJS := $(patsubst %.c, %.o, $(SRCS))
CC := gcc
# 可执行程序的名称
PROJECT_NAME := bus
TARGET := ./$(PROJECT_NAME)# 规避目标与源文件同名,使用 .PHONY
.PHONY: clean run rebuild# 默认构建目标
$(PROJECT_NAME): $(OBJS)$(CC) $^ -o $@ -lm# 通用的编译规则
%.o: %.c$(CC) -c $< -o $@# 构建清除伪目标
clean:rm -f $(OBJS) $(TARGET)# 构建运行伪目标
run:$(TARGET)# 完整重建伪目标
rebuild: clean $(PROJECT_NAME)
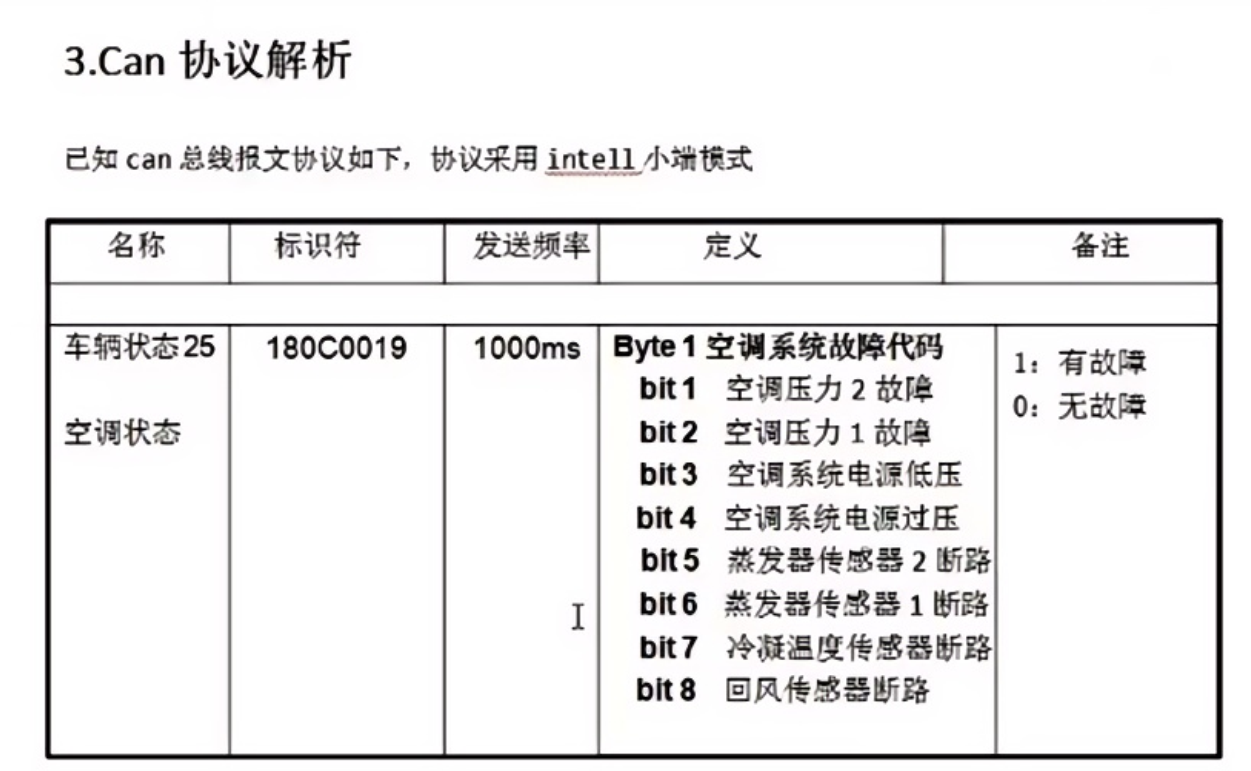
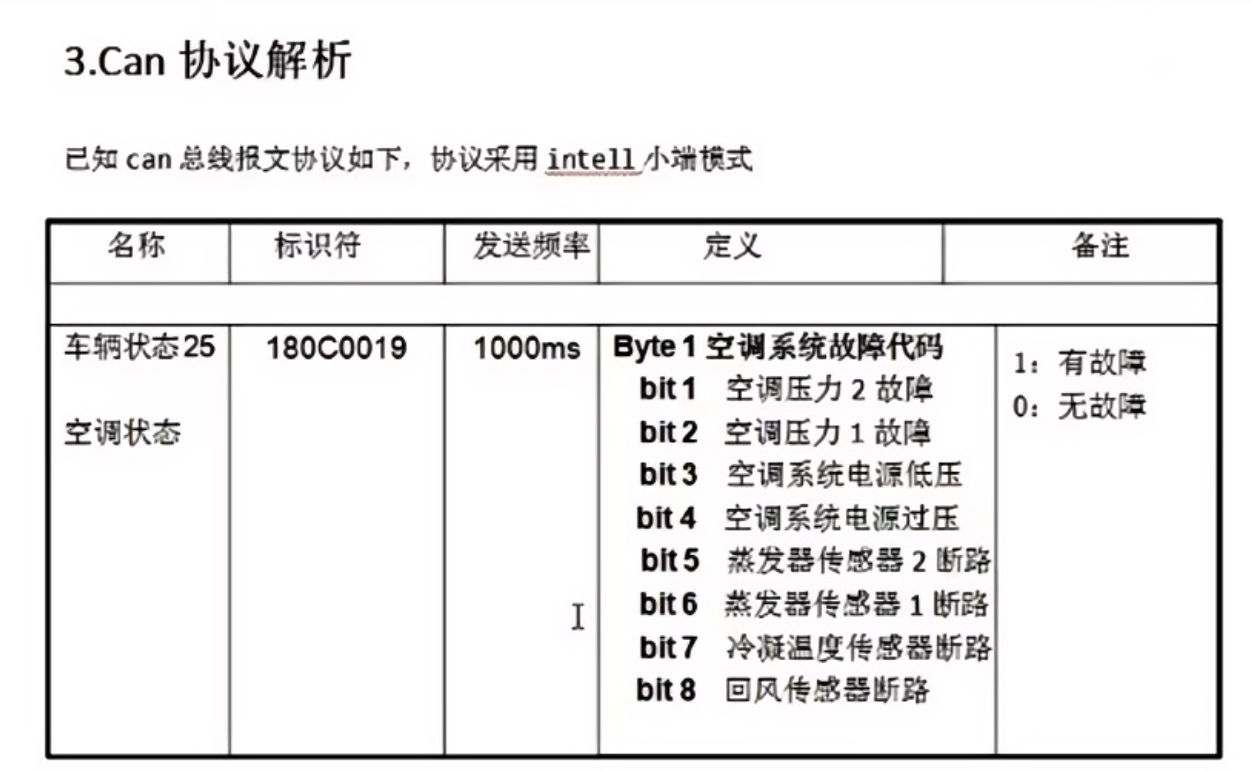
位运算
什么是位运算
针对数据的二进制位进行的相关操作,位运算在嵌入式开发领域有着非常重要的应用。
位运算常用的运算符
| 符号 | 说明 | 符号 | 说明 |
|---|---|---|---|
| & | 按位与 | ~ | 按位取反 |
| | | 按位或 | << | 按位左移 |
| ^ | 按位异或 | >> | 按位右移 |
注意:参与位运算的运算量只能是整型或者字符型,不能是实型。
位运算符的运算规则
~:按位取反
说明:单目运算符,数据的每一个bit位取反,也就是二进制数位上的0变1,1变0
举例:
unsigned char ret = ~0x05; // 0000 0101 ---> 1111 1010
printf("%d\n",-5); // -6
&:按位与
说明:双目运算符,对于两个操作数,只有相应二进制数据都为1时,结果为1,否则为0;
举例:
printf("%d\n",5 & 6); //0000 0101 & 0000 0110 = 0000 01000
作用:
①获取某二进制位的数据
②将指定二进制位数据清零
③保留指定位
|:按位或
说明:双目运算符,对于两个操作数据,只要相应二进制数据有一个为1,结果为1,否则为0
举例:
printf("%lu",5|6); // 0000 01010 | 0000 0110 = 0000 0111(7)
作用
①置位某二进制数据
^ :按位异或
说明:双目运算符,对于两个操作数据,只要相应二进制位数据相同,结果为0,否则为1
举例:
printf("%u\n",5 ^ 6); // 0000 0101 ^ 0000 0110 = 0000 0011(3)
作用:
①反转
②值交换
面试题:
题目:设 a = 3 ,b = 4 ,不用中间变量,交换两个数据的值?
实现
a = a ^ b = 7 ; // 011 ^ 100 = 111
b = a ^ b = 3 ; // 111 ^ 100 = 011
a = a ^ b = 4 ; // 111 ^ 011 = 100
<<:左移,按位往左偏移
说明:原操作数所有的二进制位数整体向左移动指定位
无符号左移:(左侧移出部分舍弃,右侧空余部分补0)
-
语法:
原操作数 << 移动位数unsigned int a = 3 << 3; // 计算规则 3 * ( 2 ^ 3) = 24 printf("%u\n",a); // 24
有符号左移:
-
语法:
原操作数 << 移动位数int a = -3 << 3; // 计算规则 -3 * ( 2 ^ 3) = 24 printf("%u\n",a); // -24 -
注意:
如果符号位被覆盖或者高位全为1 时溢出或者极端溢出时,公式不适用,其他使用都
>>右移,按位往右偏移
说明:原操作数所有的二进制位数据整体向右移动指定位,移出的数据舍弃。
如果操作数是无符号数:左边用0补齐
如果操作数是有符号数,左边用什么补全,取决于计算机系统:
- 逻辑右移:用0补全
- 算术右移:(大部分计算机道循)由原本的符号位决定补什么,如果符号位是1用1补全;如果符号位是0,用0补全。
无符号右移:
语法: 操作数 >> 移动位数
unsigned char a = 3 >> 3;
printf("%d\n",a);// 0
有符号右移:
语法: 操作数 >> 移动位数
char a = -3 >> 3;
printf("%d\n",a);// -1
位运算赋值符
-
运算符:&=, |=, >>=, <<=, ∧=
-
举例:
a &= b 等价于 a = a & b a <<= 2 等价于 a = a << 2 a >>= 2 等价于 a = a >> 2 a |= b 等价于 a = a | b a ^= b 等价于 a = a ^ b
不同长度数据进行位运算
如果两个数据长度不同(例如long型和short型),进行位运算时(如a & b,而a为long型,b为short型),系统会将二者按右端对齐。
- 如果b为正数,则高位16位补满0;
- 如果b为负数,则高位16应补满1;
- 如果b为无符号整数型,则高位16为补满0。
位运算符的应用场景
注意:以下所有场景的n都是从右侧开始计数,从0开始 1011 1001
①将某个数据从右侧(低位)指定的二进制位(n1,n2,n3…)清零
-
公式
a &= ~ (1<<(n1 -1) | 1 << (n3 -1) | ...);// 如果是指定第几,n就代表第n个,从1开始 a &= ~(1<<n1 | 1<<n2 | 1<<n3) | ...); // 如果是指定索引,n代表索引,从0开始1 2 -
解释;
其中,n1, n2, n3, ...是我们想清零的位的索引,从右侧开始计数(从0开始)。
通过一个例子来详细解释这个公式:
假设我们有一个char类型的变量a,其二进制表示是 1011 0110 (即十进制的182)。我们想要将它的第1位、第3位和第5位清零(注意:从右侧开始计数,从0开始)。
-
确定位的位置
-
第1位:从右侧开始第1位(索引0)
-
第3位:从右侧开始第3位(索引2)
-
第5位:从右侧开始第5位(索引4)
-
-
生成位掩码
- 我们需要生成一个掩码,其中这些位是1,其他位是0。然后取反(使用 ~ 运算符),使得这些位变成0,其他位变成1(
0000 0001)。 1<<(1-1)即1<<0结果是1011 0110–0000 00011<<(3-1)即1<<2结果是1011 0110–0000 01001<<(5-1)即1<<4结果是1011 0110–0001 0000- 将这些位掩码进行按位或运算:
0000 0001 | 0000 0100 | 0001 0000结果是0001 0101 - 取反:
~(0001 0101)结果是1110 1010
- 我们需要生成一个掩码,其中这些位是1,其他位是0。然后取反(使用 ~ 运算符),使得这些位变成0,其他位变成1(
-
应用掩码
使用按位与运算将
a与掩码1110 1010进行运算:1011 0110 & 1110 1010结果是1010 0010
-
案例
#include <stdio.h> #include <stdlib.h>int main(int argc, char *argv[]) {// unsigned int a = 0b10110110;unsigned int a = 182; // 初始值:1011 0110(二进制),182(十进制)a &= ~(1 << (1 - 1) | 1 << (3 - 1) | 1 << (5 - 1)); // 清零第1(索引0)、3(索引2)、5(索引4)位// 打印结果printf("Result: %u,%x\n", a,a); // 十进制:162,十六进制:A2printf("Binary: ");for (int i = 7; i >= 0; i--){printf("%d", (a >> i) & 1); // 二进制:1010 0010} printf("\n");return 0; }
②获取某个数据指定的二进制位(n)上的数是0还是1
-
公式
(a & (1 << n)) >> n -
解析
步骤 1:
1 << n这一步是将数字 1 左移
n位。左移操作的规则是将二进制数整体向左移动指定的位数,右边空出的位置用 0 填充。例如,当n为 3 时,数字 1 的二进制表示是0000 0001,左移3 位后就变成了0000 1000。步骤 2:
a & (1 << n)按位与运算符
&的规则是,只有当两个对应位都为 1 时,结果的该位才为 1,否则为 0。
这里我们将a与步骤 1 生成的掩码进行按位与运算。假设
a的二进制表示是1011 0110,当 n 为 3 时,掩码是0000 1000。进行按位与运算时:1011 0110 & 0000 1000 -----------0000 0000由于
a的第 3 位是 0,所以按位与的结果是0000 0000。如果a的第 3 位是 1,那么结果就会是0000 1000。也就是说,通过按位与运算,我们把除了第n位之外的其他位都清零了,只保留了第n位的原始值。步骤 3:
(...) >> n
这一步是将步骤 2 的结果右移n位。右移操作的规则是将二进制数整体向右移动指定的位数,左边空出的位置用 0 填充。因为步骤 2 的结果中只有第
n位可能是 1,其他位都是 0,所以右移n位后,第n位就会移动到最低位(索引 0)上。例如,如果步骤 2 的结果是0000 1000,右移 3 位后就变成了0000 0001;如果结果是0000 0000,右移 3 位后还是0000 0000。这样,我们就可以通过检查最低位是 0 还是 1 来确定a的第n位是 0 还是 1。 -
案例
#include <stdio.h>
#include <stdlib.h>int main(int argc, char *argv[])
{
#include <stdio.h>unsigned int a = 182; // 二进制 1011 0110 ,十进制 182 初始值int n = 3;int bit = (a & (1<<n)) >> n;printf("这个二进制数据%d位上的数据是%d\n", n, bit); // 3,0return 0;
}
③ 将某个数据从低位(右侧)指定的二进制位(n1, n2,n3)设置为1
-
公式
a |= (1 << n1 | 1 << n2 | 1 << n3 | ...); -
解析
步骤 1:
1 << n左移运算符
<<的作用是把一个二进制数整体向左移动指定的位数,右边空出的位置用 0填充。当我们对数字 1 进行左移n位操作时,就相当于把 1 放到了二进制数的第n位上,其余位都变成 0。比如,数字 1 的二进制表示是
0000 0001。若n为 2,将 1 左移 2 位后,得到的二进制数就是0000 0100。这就好比我们拿着一个 “1” 的小旗子,把它插到了二进制数的第 n位这个位置上。步骤 2:
1 << n1 | 1 << n2 | 1 << n3按位或运算符
|的规则是,只要两个对应位中有一个为 1,结果的该位就为 1,只有当两个对应位都为 0 时,结果的该位才为 0。我们把步骤 1 中得到的多个左移后的数进行按位或运算。假设
n1为 1,n2为 3,n3为 5。那么1 << n1得到0000 0010,1 << n2得到0000 1000,1 << n3得到0010 0000。进行按位或运算时:0000 0010 | 0000 1000 | 0010 0000 -----------0010 1010这样就得到了一个新的二进制数,这个数在第
n1、n2、n3位上是 1,其他位可能是 0也可能是 1(取决于参与运算的数)。可以把这个过程想象成把多个插着 “1” 小旗子的位置合并到一个二进制数里。步骤 3:
a |= (1 << n1 | 1 << n2 | 1 << n3)复合赋值运算符
|=其实就是按位或运算和赋值运算的结合,等同于a = a | (1 << n1| 1 << n2 | 1 << n3)。我们把变量 a 与步骤 2 得到的二进制数进行按位或运算。按位或运算会保证在
a的二进制表示中,第n1、n2、n3位上的值变成 1。因为按位或运算只要有一个操作数的对应位为 1,结果的该位就为 1,所以不管a原来在这些位置上是 0 还是 1,经过运算后都会变成 1。 -
案例:
#include <stdio.h> #include <stdlib.h>int main(int argc, char *argv[]) { #include <stdio.h>unsigned int a = 0b10101010; // 初始值,二进制表示为10101010int n1 = 2, n2 = 4, n3 = 6; // 要设置为1的位// 将a在第n1, n2, n3位上设置为1a |= (1 << n1) | (1 << n2) | (1 << n3);// 打印结果printf("Result: %u\n", a); // 输出结果,二进制表示为11111110printf("Binary: ");for (int i = 7; i >= 0; i--){printf("%d", (a >> i) & 1);} printf("\n");return 0; }
④ 将某个数据指定的二进制位(n)反转
-
公式:
a ^= (1 << n) a ^= (1 << n1 | 1 << n2 | 1 << n3 | ...) -
1 << n:将数字1左移n位,得到一个仅在n位上为1的数。 -
a ^= (1 << n):将a与上述得到的数进行按位异或运算,从而反转a在n位上的值(0变为1,1变为0)。 -
说明:n的取值从右侧开始,从0开始计数
-
案例:
#include <stdio.h>int main() {unsigned int a = 174; // 初始值,二进制表示为10101010int n = 2; // 要反转的位// 将a在第n位上反转a ^= (1 << n);// 打印结果printf("Result: %u\n", a); // 输出结果,十进制表示为174printf("Binary: ");for (int i = 7; i >= 0; i--) {printf("%d", (a >> i) & 1);// 输出结果,二进制表示为10101110} printf("\n");return 0; }
位段/ 位域
概念
在结构体中,以位(bit)为单位的成员,称为位段或位域。位段本质是结构体的成员,可以通过数字指明它所占内存空间的大小(以bit为单位)
说明:
// eg: STM32中电源控制寄存器(PWR_CR)
struct PWR
{unisgned int ldps : 1; // 1bitunsigned int pdds : 1; // 1bitunsigned int cwuf : 1; // 1bitunsigned int csbf : 1; // 1bitunsigned int pvde : 1; // 1bitunsigned int pls : 3; // 3bitunsigned int pvde : 1; // 1bitunsigned short d ; // 16bit
};struct Stu stu = {1,0,1,1,1,7,1};// 应用: 方便给寄存器中的某些数据位设置数据
注意
-
位段不能取地址
struct S {char a:2; // 2bitunsigned char b:4;// 4bit }; struct S s; printf("%p\n",&s); // s是结构体变量,可以取地址 printf("%p\n",&(s.a)); // s.a是结构体成员位段a,不能对它取地址 -
给段成员赋值,不能超出成员所占内存
struct S {char a: 2; // 2bitunsigned char b: 4; // 4bitunsigned char c: 5; // 5bit };struct S s = {1, 3};// 赋值操作 s.a = 1; // a占2个bit,并且是有符号数,它被赋值的范围:-1,0,1,除此以外都会报错,超范围了 s.b = 10;// b占4个bit,并且是无符号数,它被赋值的范围:0~15,如果取值是-8~15,编译正常,只是在-8输出时值被转换为15 s.c = 20; // c占5个bit位,并且是无符号数,它的取值范围为:[0,31],如果取值是[-16,31],编译正常,只是在-16输出时值为31 -
一个位段必须存放在一个内存单元中,不能跨两个单元
struct A {char a; //a 占了7个bit位,当前内存单元声音char b; // b占了7个bit位,此时b在新的内存单元,因为上一个内存单元空余1bit,空间不够char c: 3; // c占了3个bit位,由于上一个内存单元空间不足,此时c位于新的内存空间,剩余5bitchar d: 3; // d占了3个bit位,由于上一个内存单元空余5bit,此时空间足够,所以c,d在同一内存单元 } -
位段的长度不能大于存储单元的长度
struct A {char a: 1; // char总大小为8bit,位段占1bit,足够char b: 8; // char总大小为8bit,位段占8bit,足够char c: 9; // char总大小为8bit,位段占9bit,空间不足,无法通过编译 }; -
如果一个位段从另一个存储单元开始,可以在它面前定义一个匿名成员,占0 字节
struct A {char a:1;char b: 2; //a,b总共占3bit,没有超过总大小8bit,所以a,b在同一个内存单元中,此时没有跨内存单元,剩余5bitchar : 0; //匿名成员,占0个字节,它的作用是为了实现跨内存单元char c: 2; //因为前面加了匿名成员,所以c使用新的内存单元,此时不会占用a,b所在内存单元 }说明:如果成员c上面没有匿名成员,c就和a,b在同一个字节(同一个内存单元中)
struct A {char a; //a 占了7个bit位,当前内存单元声音char b; // b占了7个bit位,此时b在新的内存单元,因为上一个内存单元空余1bit,空间不够char c: 3; // c占了3个bit位,由于上一个内存单元空间不足,此时c位于新的内存空间,剩余5bitchar d: 3; // d占了3个bit位,由于上一个内存单元空余5bit,此时空间足够,所以c,d在同一内存单元 } -
位段的长度不能大于存储单元的长度
struct A {char a: 1; // char总大小为8bit,位段占1bit,足够char b: 8; // char总大小为8bit,位段占8bit,足够char c: 9; // char总大小为8bit,位段占9bit,空间不足,无法通过编译 }; -
如果一个位段从另一个存储单元开始,可以在它面前定义一个匿名成员,占0 字节
struct A {char a:1;char b: 2; //a,b总共占3bit,没有超过总大小8bit,所以a,b在同一个内存单元中,此时没有跨内存单元,剩余5bitchar : 0; //匿名成员,占0个字节,它的作用是为了实现跨内存单元char c: 2; //因为前面加了匿名成员,所以c使用新的内存单元,此时不会占用a,b所在内存单元 }说明:如果成员c上面没有匿名成员,c就和a,b在同一个字节(同一个内存单元中)