【学习笔记】机器学习(Machine Learning) | 第七章|神经网络(2)
机器学习(Machine Learning)
简要声明
基于吴恩达教授(Andrew Ng)课程视频
BiliBili课程资源
文章目录
- 机器学习(Machine Learning)
- 简要声明
- 神经网络在图像识别及手写数字识别中的应用
- 一、神经网络在图像识别中的应用
- (一)人脸识别
- (二)汽车分类
- 二、神经网络层的计算与符号表示
- (一)神经网络层的计算
- (二)符号表示
- 三、手写数字识别案例
- (一)网络结构与参数设置
- (二)前向传播过程
- (三)预测判断
神经网络在图像识别及手写数字识别中的应用
一、神经网络在图像识别中的应用
(一)人脸识别
在人脸识别领域,图像数据的预处理是模型训练的基石。以一张 1000×10001000 \times 10001000×1000 像素的 RGB 彩色图像为例,其原始数据可视为一个三维矩阵 Image∈R1000×1000×3\text{Image} \in \mathbb{R}^{1000 \times 1000 \times 3}Image∈R1000×1000×3 ,每个元素对应一个像素点的红、绿、蓝通道值。为适配神经网络输入,需将其展平为一维向量 x⃗∈R3000000\vec{x} \in \mathbb{R}^{3000000}x∈R3000000 ,该向量包含了图像所有像素的色彩信息。实际应用中,还会进行归一化处理(如将像素值缩放到 0-1 区间),以加速模型收敛。
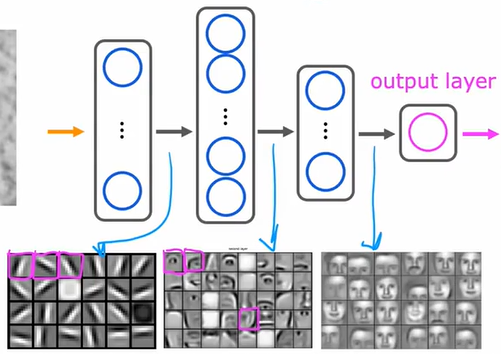
在网络架构设计上,人脸识别模型常采用多层卷积神经网络(CNN)。输入层接收展平图像向量后,隐藏层通过卷积、池化操作提取特征。以 VGG-16 为例,前几层卷积层用 3x3 卷积核检测边缘,池化层降维后,后续卷积层提取纹理等复杂特征。输出层输出概率分布向量,元素值接近 1 代表与对应人脸高度匹配。实际部署时结合余弦相似度计算,将概率转为相似度评分,增强识别鲁棒性。
(二)汽车分类
汽车分类任务的流程与人脸识别相似,但特征提取逻辑存在显著差异。输入图像同样需经过标准化处理,将其转化为适合网络计算的张量形式。除了常规的归一化,还会使用数据增强技术(如旋转、裁剪、亮度调整)扩充数据集,避免模型过拟合。
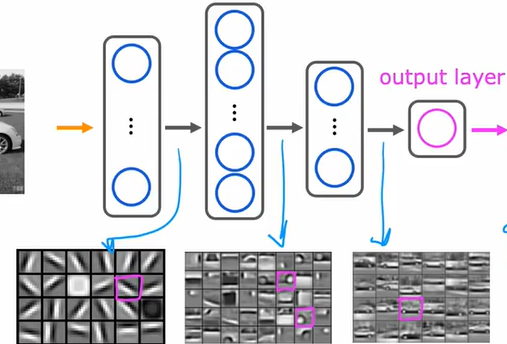
模型在隐藏层先识别汽车通用特征(如轮廓、车轮),再提取品牌专属特征(如宝马双肾格栅)。以 ResNet-50 为例,其残差结构克服梯度消失,支持深层特征学习。输出层以概率值表征分类置信度,如 0.85 表示 85% 概率为目标车型。实际应用中通过设置 0.7 阈值,筛除低置信预测,优化分类效果。
二、神经网络层的计算与符号表示
(一)神经网络层的计算
以全连接层为例,假设第 lll 层包含 mmm 个神经元,输入向量为 x⃗∈Rn\vec{x} \in \mathbb{R}^{n}x∈Rn ,其计算过程可拆解为以下步骤:
线性变换:对每个神经元 j∈[1,m]j \in [1, m]j∈[1,m] ,计算加权和
zj[l]=∑i=1nwij[l]xi+bj[l]=w⃗j[l]⋅x⃗+bj[l]z_{j}^{[l]} = \sum_{i = 1}^{n} w_{ij}^{[l]} x_i + b_{j}^{[l]} = \vec{w}_{j}^{[l]} \cdot \vec{x} + b_{j}^{[l]}zj[l]=∑i=1nwij[l]xi+bj[l]=wj[l]⋅x+bj[l]
其中 w⃗j[l]∈Rn\vec{w}_{j}^{[l]} \in \mathbb{R}^{n}wj[l]∈Rn 为权重向量,bj[l]b_{j}^{[l]}bj[l] 为偏置项。这里的权重矩阵 W[l]∈Rm×n\mathbf{W}^{[l]} \in \mathbb{R}^{m \times n}W[l]∈Rm×n 存储了该层所有神经元的权重参数,其每一行对应一个神经元的权重向量。
非线性激活:通过激活函数 g(⋅)g(\cdot)g(⋅) 引入非线性,典型的 sigmoid 函数定义为
g(z)=11+e−zg(z) = \frac{1}{1 + e^{-z}}g(z)=1+e−z1
得到神经元的激活值 aj[l]=g(zj[l])a_{j}^{[l]} = g(z_{j}^{[l]})aj[l]=g(zj[l]) ,所有神经元的激活值构成该层输出向量 a⃗[l]∈Rm\vec{a}^{[l]} \in \mathbb{R}^{m}a[l]∈Rm 。除了 sigmoid 函数,常用的激活函数还有 ReLU(Rectified Linear Unit)、tanh 等,它们各有优缺点,适用于不同场景。例如 ReLU 在解决梯度消失问题上表现优异,广泛应用于深层神经网络。
(二)符号表示
为统一描述神经网络计算过程,常用符号体系如下:
| 符号 | 含义 | 补充说明 |
|---|---|---|
| x⃗\vec{x}x | 输入向量 | 通常表示原始数据或上一层的输出 |
| a⃗[l]\vec{a}^{[l]}a[l] | 第 lll 层的激活值向量 | 所有神经元激活值组成的向量 |
| w⃗j[l]\vec{w}_{j}^{[l]}wj[l] | 第 lll 层第 jjj 个神经元的权重向量 | 与输入向量做内积计算加权和 |
| bj[l]b_{j}^{[l]}bj[l] | 第 lll 层第 jjj 个神经元的偏置项 | 调整激活函数的位置 |
| aj[l]a_{j}^{[l]}aj[l] | 第 lll 层第 jjj 个神经元的激活值 | 非线性变换后的输出 |
对于多层神经网络,层间计算遵循递推关系:
aj[l]=g(∑i=1ml−1wij[l]ai[l−1]+bj[l])a_{j}^{[l]} = g\left(\sum_{i = 1}^{m_{l - 1}} w_{ij}^{[l]} a_{i}^{[l - 1]} + b_{j}^{[l]}\right)aj[l]=g(∑i=1ml−1wij[l]ai[l−1]+bj[l])
其中 ml−1m_{l - 1}ml−1 为第 l−1l - 1l−1 层的神经元数量。这个公式清晰展示了每一层如何基于上一层的输出进行计算,是理解神经网络前向传播的核心。
三、手写数字识别案例
(一)网络结构与参数设置
构建一个三层全连接神经网络用于 MNIST 数据集的手写数字识别:
输入层:接收 28×2828 \times 2828×28 像素的灰度图像,展平后为 784 维向量。由于 MNIST 数据集中图像已经过预处理,我们直接使用原始数据,但在实际应用中,可通过添加高斯噪声等方式进行数据增强。
隐藏层 1:包含 25 个神经元,引入 ReLU 激活函数。ReLU 函数的计算简单高效,其公式为 f(x)=max(0,x)f(x) = \max(0, x)f(x)=max(0,x) ,有效避免了梯度消失问题。
隐藏层 2:包含 15 个神经元,同样使用 ReLU 激活。这一层进一步对特征进行抽象,提取更具判别性的信息。
输出层:10 个神经元对应 0-9 十个数字类别,采用 softmax 激活函数输出概率分布。softmax 函数将输出值转化为概率分布,其公式为 σ(z)j=ezj∑k=1Kezk\sigma(z)_j = \frac{e^{z_j}}{\sum_{k = 1}^{K} e^{z_k}}σ(z)j=∑k=1Kezkezj ,其中 KKK 为类别数,在本案例中 K=10K = 10K=10 。
(二)前向传播过程
第一层计算:
zj[1]=∑i=1784wij[1]xi+bj[1]aj[1]=max(0,zj[1])(j=1,⋯,25)\begin{align*} z_{j}^{[1]} &= \sum_{i = 1}^{784} w_{ij}^{[1]} x_i + b_{j}^{[1]} \\ a_{j}^{[1]} &= \max(0, z_{j}^{[1]}) \quad (j = 1, \cdots, 25) \end{align*} zj[1]aj[1]=i=1∑784wij[1]xi+bj[1]=max(0,zj[1])(j=1,⋯,25)
在这一步,输入图像的 784 维向量与权重矩阵 W[1]∈R25×784\mathbf{W}^{[1]} \in \mathbb{R}^{25 \times 784}W[1]∈R25×784 相乘,再加上偏置向量 b⃗[1]∈R25\vec{b}^{[1]} \in \mathbb{R}^{25}b[1]∈R25 ,得到 25 个神经元的加权和,经过 ReLU 激活后得到第一层的输出。
第二层计算:
zk[2]=∑j=125wkj[2]aj[1]+bk[2]ak[2]=max(0,zk[2])(k=1,⋯,15)\begin{align*} z_{k}^{[2]} &= \sum_{j = 1}^{25} w_{kj}^{[2]} a_{j}^{[1]} + b_{k}^{[2]} \\ a_{k}^{[2]} &= \max(0, z_{k}^{[2]}) \quad (k = 1, \cdots, 15) \end{align*} zk[2]ak[2]=j=1∑25wkj[2]aj[1]+bk[2]=max(0,zk[2])(k=1,⋯,15)
第一层的输出作为第二层的输入,重复上述计算过程,进一步提取特征。
输出层计算:
zs[3]=∑k=115wsk[3]ak[2]+bs[3]as[3]=ezs[3]∑t=110ezt[3](s=1,⋯,10)\begin{align*} z_{s}^{[3]} &= \sum_{k = 1}^{15} w_{sk}^{[3]} a_{k}^{[2]} + b_{s}^{[3]} \\ a_{s}^{[3]} &= \frac{e^{z_{s}^{[3]}}}{\sum_{t = 1}^{10} e^{z_{t}^{[3]}}} \quad (s = 1, \cdots, 10) \end{align*} zs[3]as[3]=k=1∑15wsk[3]ak[2]+bs[3]=∑t=110ezt[3]ezs[3](s=1,⋯,10)
第二层的输出经过加权求和后,通过 softmax 函数转化为 10 个数字类别的概率分布。
(三)预测判断
输出层的概率分布向量 a⃗[3]\vec{a}^{[3]}a[3] 中,索引值对应数字类别。通过选择概率最大值的索引实现分类:
y^=argmaxs∈{1,⋯,10}as[3]\hat{y} = \arg\max_{s \in \{1, \cdots, 10\}} a_{s}^{[3]}y^=argmaxs∈{1,⋯,10}as[3]
例如,若 a⃗[3]=[0.02,0.01,0.95,0.01,⋯,0.01]\vec{a}^{[3]} = [0.02, 0.01, 0.95, 0.01, \cdots, 0.01]a[3]=[0.02,0.01,0.95,0.01,⋯,0.01] ,则模型预测数字为 2。在实际评估模型性能时,会使用准确率、精确率、召回率、F1 值等指标,通过交叉验证等方法全面评估模型的泛化能力。
continue…