自由学习记录(65)
其他脚本语言也可以热更新,但 Lua 特别适合,游戏主程序通常是 C++,Lua 只是逻辑脚本,改 Lua 不影响主程序运行
| 语言 | 应用场景 |
|---|---|
| Python | Web 后端 / 数据处理服务 |
| JavaScript | 浏览器端热重载 / React HMR |
| C# | Unity 的 ILRuntime / HybridCLR 实现 DLL 热更新 |
| TypeScript | 前端构建工具支持热替换 |
| WASM | 支持在不重启主进程的前提下动态替换模块 |
| 框架 | 特点 |
|---|---|
| XLua(Unity) | 支持 Lua 脚本与 C# 混合调用 |
| Tolua | 早期流行框架,适配 Unity |
| Cocos2d-x Lua | 天然支持热更新(如 loadstring、require) |
| Skynet | 服务级热更新(服务器端框架) |
XLua 是 Unity 官方推荐的 Lua 热更新解决方案,
它允许你在 Unity 项目中使用 Lua 脚本写逻辑,并在运行时替换、更新这些逻辑而不重新打包整个程序。
-
你可以写 C# 脚本,Unity 编译器会把它们 编译成 DLL,然后随游戏一起打包发布。
-
但是这些 DLL 是 不能在运行后更换的(尤其是用 IL2CPP 发布后,代码会被转成 C++ 编译成二进制)
| 文件 | 能否在运行时执行 | 原因 |
|---|---|---|
.cs(C# 脚本) | ❌ 不行 | 要编译成 DLL,运行时不能改 |
.lua(Lua 脚本) | ✅ 可以 | Lua 是脚本语言,由运行时解释器解释执行 |
.js(UnityScript) | ✅/❌(已废弃) | Unity 原生早期支持,后来移除 |
.py、.ts 等 | ❌ 不行 | Unity 无内建解释器,需自己嵌入 |
所以在 Unity 中,Lua 是特地“嵌入”的解释器环境,类似你在游戏内装了一个“小电脑”来读 .lua 脚本文件。
热更新 ≠ 必须联网,热更新只意味着:“你可以在运行时 用新的逻辑代码 替换旧逻辑,而不是必须重新打包游戏。”
【例 :联网游戏】
-
玩家打开游戏 → 发现服务器上有新版本的
skill_logic.lua -
游戏自动下载覆盖旧脚本
-
新技能逻辑立刻生效,不用重启或重装游戏
✅ 热更新起作用
但热更新只有在游戏有联网机制、支持下载新 Lua 脚本时才有“更新”的实际效果。
哪怕是单机:
-
使用 Lua 脚本仍然可以让逻辑更灵活(比如任务逻辑、关卡行为可以写在 Lua 里)
-
你仍可以在不同版本中方便地换脚本,不必全局改 C# 和重新打包
假设你开发了一个单机游戏,打包之后放在某个平台上供人下载。玩家下载之后完全断网。
✅ 情况 A:游戏只是用了 Lua,但不打算更新
-
你在开发阶段就把很多逻辑写在 Lua 脚本里(比如关卡配置、敌人 AI)
-
这些 Lua 文件被打包进安装包中
-
游戏运行时,Lua 虚拟机会加载并执行这些脚本
👉 这种只是运行时使用 Lua 脚本,不叫热更新。
✅ 情况 B:游戏打包时内置了备用脚本机制
-
虽然断网,但你设计了一个“插件目录”或“本地脚本读取路径”
-
玩家或开发者可以手动替换这些 Lua 文件
-
游戏运行时会读取外部的 Lua 脚本而不是打包内的
👉 这种属于本地热更新(不依赖网络,但仍可更新逻辑)
| 对比项 | Lua 脚本 | C# 代码(Unity 环境) |
|---|---|---|
| 执行方式 | 解释执行(通过虚拟机) | 编译成 IL,再由 Mono/IL2CPP 运行 |
| 文件是否可直接编辑 | ✅ 是文本,可随时改 | ❌ 编译后为 DLL,不可直接改 |
| 是否可脱离主程序更新 | ✅ 热替换,加载新脚本 | ❌ 更新必须重打包或特殊框架支持 |
| 运行开销 | 很小,轻量 | 稍重(尤其在移动平台) |
| 热更新难度 | 低 | 高,需要专门的反射或动态加载机制 |
NotebookLM 处理链接的原理是“抓取单一页面的 HTML 文本结构 + 语义索引分段提问”,它不支持自动抓取整个网站或跳转链接的子页面。
NotebookLM 是如何处理你传入的链接内容的?
✅ 1. 抓取网页内容(HTML)并转成纯文本结构
NotebookLM 在你添加一个链接(如 Unity 官方文档)后,会尝试:
-
抓取该链接的网页源代码(HTML)
-
使用网页解析器(如 Readability、或自研 parser)将主要正文内容提取成 Markdown / 文本块
-
忽略页面上的导航栏、页脚、广告、脚本等无关内容
✅ 它不会只是截图,而是真正读取文字内容构建“笔记”块(Source Note)
NotebookLM 的语义索引机制
抓取完文本内容后,它会:
-
对内容进行分段(chunking),每个段落成为一个“Note”(笔记源)
-
使用 embedding(文本向量化)将所有笔记内容编码入一个向量数据库
-
你提问时,通过语义相似度找到相关笔记片段,再由模型生成最终回答
📌 这是典型的“RAG(Retrieval-Augmented Generation)”机制
不推荐直接保存 HTML 的情况
有些网页(尤其是 React/Vue/Angular 构建的 SPA,比如 Unity 脚本 API 页面)用的是JavaScript 动态渲染,所以:
-
如果你用右键「保存为 .html」,保存下来的只是一个壳,正文根本没在里面
-
NotebookLM 加载后几乎是空的,或抓到大量 JS、空 div
🧪 测试方法:
把你保存下来的 HTML 文件用 VSCode 或记事本打开,搜索页面正文里的句子:
-
如果找不到,说明你保存的只是网页壳;
-
如果找得到,那这份 HTML 文件可以上传。
Google Slides
-
指的是 Google 幻灯片(PPT)。
-
如果你用 Slides 做了学习总结、图示流程,也可以导入。
-
NotebookLM 会将每页幻灯片的文本提取出来,作为知识块。
是的,本地部署 AI 模型的核心用途之一,就是:
✅ 让 AI 像 NotebookLM 一样,基于你自己的资料、文件、知识库进行提问和对话。
这其实是构建 RAG 系统(Retrieval-Augmented Generation),它和 NotebookLM 背后的原理基本一致,只不过:
| 项目 | NotebookLM | 本地 AI 部署 |
|---|---|---|
| 数据来源 | Google Docs / Slides / 链接 | 你本地的 PDF、HTML、TXT、数据库等 |
| 模型调用 | Google 的 Gemini 模型 | 你选择的模型(如 Llama3、Mistral) |
| 数据存储 | 云端 | 全部在你电脑或局域网 |
| 权限和隐私 | Google 控制 | 你完全掌控 |
果你要自己做一个“本地 NotebookLM”,你需要这些东西:
1. 大模型(LLM)本地推理能力
-
推荐模型:LLaMA 3 (Meta)、Mistral 7B、Qwen、Yi
-
推荐框架:
llama.cpp、Ollama(最简易)或vllm
2. 文档解析与嵌入(Embedding)工具
-
工具:
langchain,llama-index -
功能:将 HTML / PDF 分段、转为向量、构建索引数据库
3. 向量数据库(存放你的知识库)
-
推荐:
Chroma,FAISS,Weaviate(轻量开源)
4. 对话界面(Web UI)
-
简易:
text-generation-webui,Open WebUI,LM Studio -
复杂:你可以自己写一个界面,或集成进 VS Code、网页等
DeepSeek、LLaMA、Mistral 这类模型的 推理代码 + 权重文件 都可以本地完整下载,运行时无需联网。
所需组件都可以脱网运行:
| 组件 | 是否可本地使用 | 说明 |
|---|---|---|
| 模型参数(权重) | ✅ | 是 .bin 或 .gguf 等格式的矩阵数据,存储的是“知识” |
| Tokenizer | ✅ | 是文本转 ID 的规则集,通常是 tokenizer.json 文件 |
| 推理逻辑(前向计算) | ✅ | 例如 transformer block 的执行流程,已写死在推理引擎中 |
| 向量检索(RAG)部分 | ✅ | 可用本地 ChromaDB、FAISS 等做离线知识检索 |
推理 = 权重矩阵 + 编码向量 + 固定执行逻辑
一个大语言模型(如 DeepSeek)推理时的核心步骤:
文本输入 → 分词(Tokenizer)→ 编码为向量(Embedding)
→ 一层层 Transformer block 运算(矩阵相乘 + 激活)
→ 输出下一个词的概率分布
在这个过程中:
-
权重(Weight):
-
是模型的“知识”,本质上是几百亿个数字矩阵。
-
你下载的
.gguf或.safetensors文件就是这些权重。 -
是训练时学到的所有语言、逻辑、人类知识的载体。
-
-
推理逻辑(代码):
-
是程序中写死的算法,比如:Multi-head Attention、LayerNorm、MLP 等。
-
所有模型结构都是固定的,都是前向传播(forward pass),不涉及训练。
-
-
输入向量(Prompt):
-
是你给模型的提示,会影响其如何“激活”内部知识。
-
输入的词(prompt)不同,经过同样的逻辑,会激活不同的权重组合
同一个模型,对“猫”和“太阳能电池板”会走出完全不同的语义路径
采样策略会变化(也可以固定)
-
常见策略:
-
Top-k、Top-p(nucleus sampling)、temperature
-
-
会影响下一个词的选择(是否更“保守”或更“发散”)
-
这部分可以固定(设定 temperature=0 表示 deterministic 推理)
本地部署的 AI 模型有“两套知识来源”
| 来源 | 内容 | 控制方式 |
|---|---|---|
| ✅ 模型自身的知识 | 模型训练阶段学到的世界知识(百科常识、编程技能、英语表达、物理知识等) | 不能修改,存在于参数(权重)中 |
| ✅ 你的私有资料(文档) | 你上传的 HTML / PDF / 笔记等内容,作为问答参考 | 可控,可更新,可删除 |
默认情况下,网站GPT 回答问题是基于它自身知识库
也就是你说的这部分:
“不开联网搜索,其实和本地部署一样,靠的是原本的训练知识。”
具体表现:
| 场景 | 是否联网搜索 | 知识来源 |
|---|---|---|
| GPT-3.5 / GPT-4(无插件、无浏览器) | ❌ 不联网 | 只基于模型权重内的“世界知识” |
| GPT-4(浏览器/插件打开) | ✅ 联网检索 | 部分信息来自网络(会标注来源) |
所以:你在官网用 GPT 问技术问题,如果没开启联网,它和本地模型在“机制”上完全一致:都靠权重本身的记忆
这种默认模式等于 非-RAG 模式
RAG 模式 = 检索+补脑,可以额外喂内容
模型本身不会“自动记住”你文件夹里的内容
你即使有 100 个文本文件放在模型旁边,模型也不会自动读取它们。
文本资料转为“可查询知识”的三步过程
这就是构建一个资料库的标准做法:
🔹 第 1 步:加载文本内容
用程序(如
langchain/llama-index/haystack)遍历文件夹中的所有.txt文件。
for file in all_txt_files:content = open(file).read()
🔹 第 2 步:分段(chunking)+ 嵌入(embedding)成向量
将每个文档按段落/长度切块,然后对每段文本编码成一个“向量表示”
chunks = split_into_chunks(content, size=500, overlap=100)for chunk in chunks:vector = embedding_model.encode(chunk)store_in_vector_db(vector, metadata={source: file})
🔹 第 3 步:提问时检索相关段落 + 输入模型
当你问问题时,系统先找出最接近你问题的文本片段,再和你的问题一起发给语言模型
🔄 所以最终表现是:
-
模型本身不记得资料内容,但它每次回答前都“临时借用”你给的资料内容来判断。
-
每次回答都等价于你给它说:“你看一下这些段落,帮我回答这个问题。”
-
这个过程会自动进行,但你需要先把资料转换好(预处理阶段)
❓那你说的“之后回答的时候就按照这个来”,是不是只要文件放进去就行?
不是自动的,你必须手动做一次预处理(但可以自动化):
| 操作 | 是否自动 |
|---|---|
| 遍历 text 文件夹 | ✅ 可以自动 |
| 分段处理 | ✅ 可以设定 chunk 大小 |
| 向量化文本 | ✅ 用本地 embedding 模型 |
| 构建索引库 | ✅ 一次性构建后反复使用 |
| 问题→相似段落→模型回答 | ✅ 每次对话中自动运行 |
-
截止训练数据时间点:Unity 2022 LTS(Long-Term Support) 是主要参考版本。
-
核心 API 覆盖范围:Unity 2018~2022,包含大量关于
Editor,MonoBehaviour,ScriptableObject,Shader,URP/HDRP,AssetDatabase,SceneManagement,SerializedObject,Gizmos等。 -
Unity 的 API 向后兼容性较好,因此对旧版本(如 2019)也广泛适用。
我能回答的问题包括但不限于:
-
编辑器快捷操作(如拖拽材质、添加组件、移动物体);
-
Editor 工具编写;
-
使用
MenuItem,EditorGUILayout,Selection,Undo.RecordObject等; -
渲染管线(如切换 URP、使用 ShaderGraph);
-
常见项目组织和资源结构(Assets/Scenes/Prefabs 等)。
我熟悉的主要渲染架构:
-
内置渲染管线(Built-in Render Pipeline)
-
通用渲染管线(URP)
-
高清渲染管线(HDRP)
支持的版本以 Unity 2019.3~2022.3 为主(URP/HDRP 较稳定阶段)。
Shift + 空格(Shift + Space)最大化

| 你提到的设置项 | 实际设置项是否存在 / 替代方案 |
|---|---|
| Surface: Transparent | ✅ 已存在,Surface Type → Transparent |
| Alpha Clipping: Off | ✅ 存在,Alpha Clipping 复选框未选中 |
| ZWrite: Off | ✅ 可通过 Depth Write → Auto / Off 控制 |
| Blend: Alpha | ✅ 存在,Blending Mode → Alpha |
| Two Sided: On | ✅ 存在,Render Face → Both |
图中这些设置都是 有效且匹配我描述的那一套配置,只不过在 Unity 新版中,表述方式稍有不同。例如:
-
ZWrite: Off → 在 Unity Shader Graph 中表述为
Depth Write: Auto,如果你需要强制关闭,改为Off即可; -
Two Sided: On → 对应
Render Face: Both; -
透明效果开启 →
Surface Type: Transparent+Blending Mode: Alpha。
为了实现“胎海流麻”这类半透明拖尾效果而进行的必要设置,它们直接影响透明度渲染、混合方式、遮挡关系和双面显示。下面我逐项解释原因:
✅ Surface: Transparent
-
目的:允许材质使用透明度(Alpha)通道进行混合。
-
默认是 Opaque(不透明),这会导致 Alpha 值被忽略。
-
用于拖尾/气体/魔法轨迹等带透明通道的特效材质必须设为
Transparent。
✅ Alpha Clipping: Off
-
目的:关闭透明裁剪。
-
如果开启裁剪,像素的透明度小于阈值就会完全剔除,形成“硬边界”。
-
拖尾需要平滑透明渐变,不需要硬边剔除,所以关闭。
✅ ZWrite: Off
-
目的:关闭深度写入,避免透明物体互相遮挡时出现“排序错乱”。
-
如果
ZWrite是On,透明拖尾会错误地遮挡后方物体或自己。 -
一般透明材质必须禁用 ZWrite,交给渲染队列排序处理。
✅ Blend: Alpha
-
目的:使用标准的
SrcAlpha / OneMinusSrcAlpha混合模式。 -
保证拖尾色彩与背景融合自然。
-
是最常见的 标准透明混合 模式(适用于烟雾、水流、光迹等)。
✅ Two Sided: On
-
目的:渲染模型的背面。
-
拖尾是片状或带状结构,背面默认不会被渲染,导致在某些角度下“消失”。
-
开启双面可确保从各个角度都看到拖尾。
Ctrl + K(Windows)
-
调出 Unity 的 Quick Search 窗口(类似 Spotlight 或 VS Code 的 Command Palette)。
-
可用于快速搜索:
-
项目资源(材质、预制体、脚本等)
-
菜单命令
-
设置项
-
场景对象
-
Package 包、帮助文档等
-
Unity 的 Quick Search 插件可能需单独安装:
-
打开
Window > Package Manager -
找到
Quick Search(或手动添加包com.unity.quicksearch) -
安装或更新后即可使用快捷键
Ctrl + K
xxxxx
“水面融合感增强”
“胎海流麻”这个效果,本质上是一种柔和透明的流动尾迹,往往会:
-
附着在角色或物体的运动轨迹后方
-
有一定程度的透明、虚幻、扰动感
-
看起来像拖曳、扩散、融化,甚至带有一点“流体”的质感
实现这个“视觉贴地/贴水”感的技术背后逻辑:
| 渲染策略 | 实现目的 | 技术核心 |
|---|---|---|
| 基于深度的透明度调整 | 让尾迹在靠近水面时显现,离开时淡出 | SceneDepth - PixelDepth 控制透明度 |
| 软边混合(Soft Blend) | 让边缘与水面过渡柔和,避免“剪影”感 | 使用 Alpha * smoothstep(...) |
| 扰动背景法线 | 让尾迹拖曳时“压出水痕”的感觉 | 用 FlowMap 或扰动法线输入到 Normal |
| 颜色调制 | 让尾迹颜色受水面或背景影响 | 可采样背景颜色、或者乘以偏蓝/偏水的调色 |
| UV 或 FlowMap 流动 | 表现“尾迹在水面上扩散流动” | 用 time 或 flow_uv 滚动贴图 |
你创造的是一种**“光学拟态”:尾迹其实是“挂在半空”的,但你通过视觉逻辑模拟出它正贴着水面自由流动**。
这就是技术美术的价值所在——在不动物理数据的前提下,创造出让玩家信服的视觉真实感。





角色走过的路径 → 留下拖尾 → 拖尾前端颜色深,尾端颜色淡
这就需要:
前端顶点颜色 = 白 + 高 Alpha(不透明)
尾端顶点颜色 = 粉蓝 + 低 Alpha(慢慢淡出)
而这正好就用 Vertex Color(顶点色) 来控制。
🔧 为什么不用 Texture 来代替?
拖尾是运行时生成的动态网格,UV 通常不稳定;
顶点色可以更灵活表达“实时变化”;
更高效,不需要贴图采样,适合用于大批量的尾迹系统。
Unity 中拖尾的 Vertex Color 怎么来的?
Unity 的 TrailRenderer 在运行时会自动生成一段 mesh,并且:
✅ 会为拖尾的每个顶点写入 Vertex Color(包括 RGB 和 Alpha),Alpha 值自动随时间衰减。
如果你现在连线中用了 Vertex Color → BaseColor * _TintColor,那说明:
-
你用
VertexColor.rgb做了拖尾的颜色控制; -
用
VertexColor.a×_TintColor.a控制透明度渐变,非常合理。
也就是说我Shader里的tintcolor其实是设置拖尾颜色的,而对拖尾颜色的设置,出于uv不稳定的原因,所以使用了顶点颜色来存放设置的颜色,而效果是相同的
最终颜色 = VertexColor.rgb × _TintColor.rgb
最终 Alpha = VertexColor.a × _TintColor.a
-
(TrailRenderer 不生成 UV,或者 UV 排布随点数变化);
-
即使有,也难以做出渐变 + 时间衰减的同步控制;
-
顶点色天然适合表达 “随时间变化”、“路径上渐变”、“自动衰减” 这些视觉语言。
xxxxxx
还是有点太吃力了,,太多概念都是懵的,
03 反射光_哔哩哔哩_bilibili

pow()就是正片叠底

无脑用phong的vr直接点乘出夹角影响高光结果,blinnphong 是更省性能,但是没必要

Unity小白的TA之路:6个问题轻松掌握Unity前向渲染_哔哩哔哩_bilibili
-
投影:角色头部在太阳光下投在地面上的明确影子,是 Shadow。
-
AO:角色脖子和衣领之间的缝隙,或枪托与背包交接的缝里那一小块暗部,是 AO。
为什么叫 _MainTex,却不是拿来贴颜色的?
这是因为我们现在这个 Shader 的用途不是“常规的贴图着色器”,而是:
✳️ 利用贴图内容来扰动 UV 和/或 控制透明度 alpha
而这个作用本质上是:
-
用 FlowMap 的红绿通道扰动 UV
-
或者
-
用噪声贴图(灰度图)来控制 Alpha 的边缘溶解
所以 Shader Graph 中的 _MainTex 实际承担的职责有两种可能:
| 用途 | _MainTex 应挂什么 |
|---|---|
| 🎯 扰动流动(UV 动画) | FlowMap(红绿扰动纹理) |
| 🎯 边缘软混合 | 灰度贴图(圆形渐变、噪声等) |
你可以复用同一个 _MainTex 做两个作用(比如先扰动 UV,再采样它来做 Alpha),也可以拆成两个属性(比如 _FlowMap 和 _AlphaTex 分开挂)


镜面高光模型视觉对比
展示了如下高光模型的点光源反射强度图:
-
Blinn
-
Phong
-
Cook-Torrance
-
Beckmann
-
GGX
越往右高光越柔和、拖尾越长,尤其 GGX 是现代 PBR 中的主流微表面分布函数。
常见的漫反射 BRDF 模型
| 模型名称 | 特点说明 |
|---|---|
| Lambert | 最基础的漫反射,反射强度只与入射角余弦有关(能量守恒),不考虑粗糙度 |
| Oren-Nayar | 更真实的漫反射模型,考虑了表面微观粗糙结构,适合模拟粉末类材质 |
| Hanrahan-Krueger | 常用于皮肤等次表面散射模型,结合体积散射计算 |
右侧的灰球矩阵显示了这些模型在不同视角下的明暗表现,说明了不同模型的视觉效果差异。
右下部分:更多 BRDF 模型名录
这些是更完整的 BRDF 名称列表,包括:
-
Blinn-Phong、Phong:经典高光模型
-
Cook-Torrance、GGX、Beckmann:基于微表面理论的现代模型
-
Ashikhmin-Shirley、Ward、Kelemen:各类各向异性或物理精度模型
-
Distribution-BRDF:强调微表面分布项
-
Halfway Vector Disk:用于优化中间向量计算
-
albedo pump-up:可能是调节反射率用于艺术控制的技巧
BRDF 结构三要素:
-
分布函数 D
-
几何遮蔽 G
-
菲涅尔 F
-
Lambert → Oren-Nayar:从简单漫反射过渡到考虑粗糙度的高级模型
-
Phong/Blinn-Phong → Cook-Torrance/GGX:从经典镜面高光过渡到现代物理模型


🌟 图中提到的光源类型说明:
| 中文 | 英文 | 说明 |
|---|---|---|
| 主灯光 | Key Light | 最主要的光源,定义了物体的明暗关系和方向。 |
| 反弹光 | Bounce Light / Fill Light | 从地面或周围环境反弹上来的弱光,缓解阴影太黑的区域。 |
| 反向灯光(KICK Light) | Rim Light / Kick Light | 从背后照射出的光,在轮廓边缘形成高光,增强空间感和材质边界。 |
| 轮廓光 | Rim Light(有时也叫 Back Light) | 强调角色边缘或背光区域,帮助从背景中分离角色。 |
🎯 除了图中的这些,还有其他常见光类型可搭配使用:
| 类型 | 说明 |
|---|---|
| Fill Light(补光) | 通常柔和,位于主光对侧,缓解阴影对比度。和 Bounce 不同,Fill 是主动设置的光源。 |
| Top Light / Overhead Light | 顶光,有时用于模拟太阳直射或棚拍环境中的顶灯。 |
| Ambient Light | 环境光,一般是非定向的柔光,用于提供最基本的全局亮度。 |
| Practical Light | 剧中光源,比如灯泡、窗户光等,用于增强真实感和故事氛围。 |

三方向的环境光遮罩设置,用法线green通道达成目的
利用法线方向(nDir)在世界空间中的 Y 分量,来模拟三向环境光(上、下、侧)
float upMask = max(0.0, nDir.y); // 朝上的法线:上环境光强度
float downMask = max(0.0, -nDir.y); // 朝下的法线:下环境光强度
float sideMask = 1.0 - upMask - downMask;// 剩余部分归为侧面(水平向量)
含义说明:
遮罩名 作用区域 原理(nDir.y)
upMask 向上的面(顶面) nDir.y > 0,越朝上越亮
downMask 向下的面(底面) nDir.y < 0,越朝下越亮
sideMask 水平面(侧面) 剩余权重,用于补充侧边这三者权重之和始终为 1,所以可以安全做加权混合。
🌞 直接光源遮挡(Shadow)——投影
定义:
光线从光源出发,被物体挡住后无法照到表面,形成投影。
特征:
-
来源是光源方向(Directional / Spot / Point)。
-
遮挡后完全无光照输入。
-
通常是有方向、有边界、有模糊程度的(软阴影/硬阴影)。
-
计算方式有:Shadow Map、Ray Tracing、Voxel Cone Tracing 等。
举例:
太阳光打过来,被墙挡住形成的地面阴影,就是光源遮挡。
🌫️ 环境光遮挡(AO, Ambient Occlusion)
定义:
表面由于自身结构的复杂导致接收不到环境光,形成的遮蔽暗部。
特征:
-
没有特定光源方向,是基于周围空间的开阔程度。
-
与光源无关,模拟“环境光无法进入的区域”。
-
常用于增强凹陷、接缝处的真实感。
-
通常是灰度图(Ambient Occlusion Map)。
举例:
沙发与地面交界的缝隙、小洞穴内部、衣服褶皱处的阴暗,就是 AO 提供的效果。

这些模型的资源贴图都有了之后,这个模型才算是可以使用,所以把模型导入到unity里面,需要先把这些贴图都得到,然后这个角色就可以去渲染了,渲染的部分和这些贴图的制作是分开的
xxxxxx
【技术美术入行作品准备经验分享】原神角色渲染还原教程_哔哩哔哩_bilibili
老师帮大忙了



如果压缩包里的文件乱码,要注意先改字符编码再转文件

| 项目 | .fbx | .vmd |
|---|---|---|
| 用途 | 游戏/影视通用 3D 格式 | MikuMikuDance 的专用动作格式 |
| 包含内容 | 模型、骨骼、动画、材质等 | 仅包含骨骼动画数据 |
| 骨骼命名 | 各不相同,无标准 | MMD 有标准命名规则(日文骨骼名) |
| 绑定关系 | 多种方式(Humanoid/Generic) | 限定结构(PMX 模型) |
所以你要做的是提取 FBX 动作 → 重定向到 MMD 骨架 → 导出 VMD。
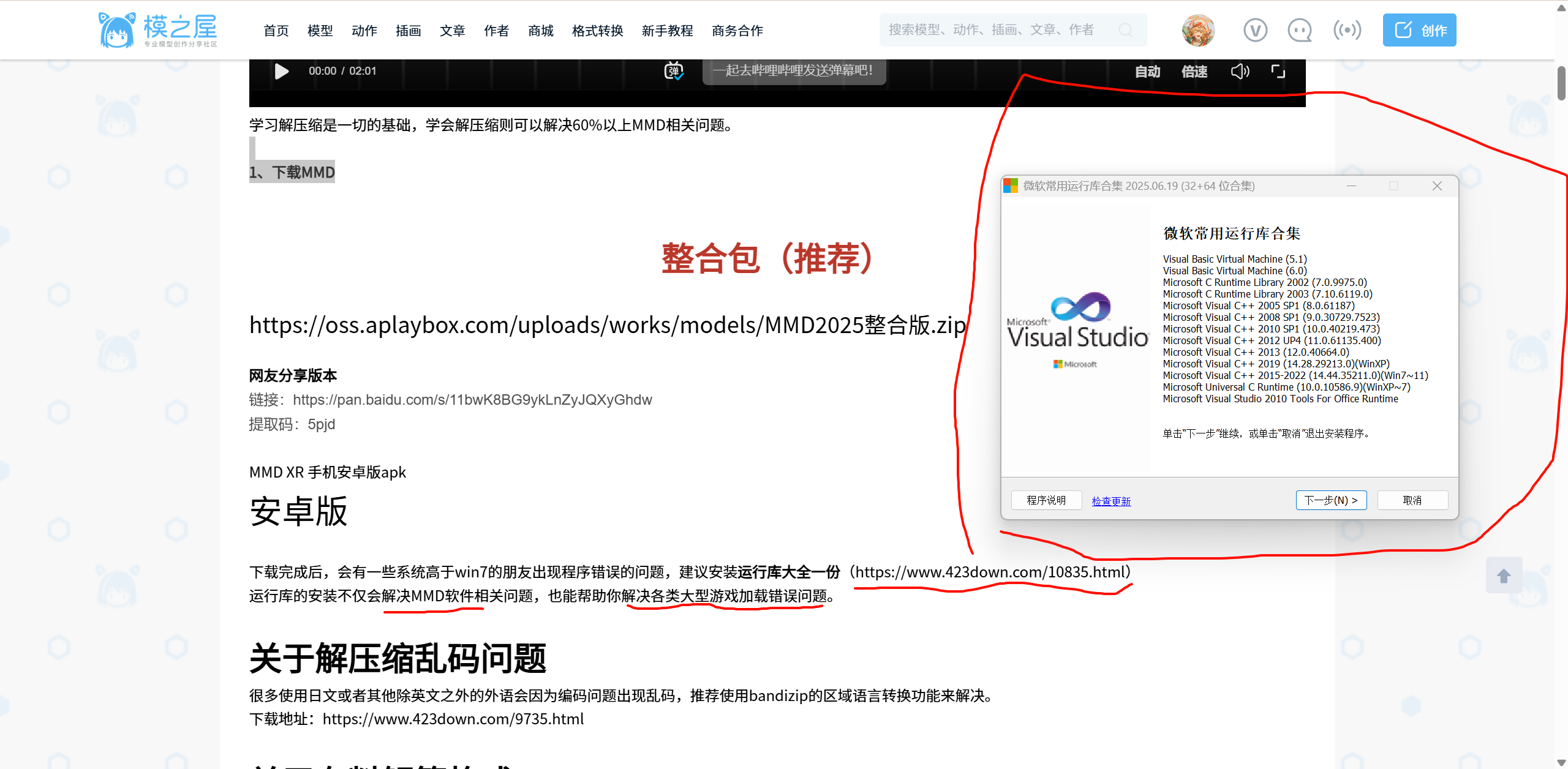
安装这些组件不会对你之后的软件产生消极影响。
相反,它们的作用是确保各类软件能正常运行,尤其是使用 C++ 编写的程序。
它们的作用是什么?
很多 Windows 软件都是用 C++ 编写的,尤其是:
-
游戏(Unity、Unreal)
-
工具类软件(Blender、OBS、各种音视频软件)
-
中间件(驱动、解码器等)
这些程序在运行时需要依赖「运行时库」:
就像你写代码时需要 .dll,它运行时也需要系统提供这些支持库。
⚠️ 有无副作用?
| 可能的疑问 | 实际情况 |
|---|---|
| 会不会导致冲突? | ❌ 不会,每个版本的 VC++ 运行库是独立的 Side-by-side 安装 |
| 会不会拖慢系统? | ❌ 不会,它们只在被调用时才会载入,平时完全不影响性能 |
| 会不会篡改系统文件? | ❌ 不会,它们是官方安装包 repack(仅做了合集优化) |
这么有用为什么不电脑自带
Windows 不预装所有 Visual C++ 运行库,是为了保持系统精简、降低维护负担,并鼓励开发者自带依赖。
1. 🔧 每个 VC++ 版本都是独立产品
-
Visual C++ 的每个版本(2005、2008、2010、2012…)运行库并不向前/向后兼容。
-
比如用 VC++ 2010 编译的软件就必须装 2010 的运行库,不能用 2015 的替代。
-
这意味着系统无法预知你未来会用哪个版本的软件,所以不能预装所有版本。
2. 🎯 微软设计哲学:“按需分发”
-
微软鼓励开发者自行打包所需运行库,比如使用 Installer 安装时静默安装对应 VC++。
-
这样可以:
-
避免系统预装太多版本造成维护冗余
-
保证软件运行时的版本精确性
-
-
所以很多正规软件(如 Unity 安装器、游戏大作)都会自动附带 VC++ 安装步骤。
3. 💡 Windows 预装了最常用的核心组件
-
Windows 确实默认包含了部分运行库(特别是 VC++ 2015+),但:
-
很多旧版本不再被默认捆绑
-
某些 SP1/SP2 扩展包体积较大,微软选择由软件商分发
-
4. 📉 不预装是为了减少系统膨胀与潜在安全攻击面
-
每个运行库版本都含 DLL 和 COM 接口,预装过多可能:
-
增加维护成本
-
引入旧版本漏洞
-
增加系统攻击面(DLL 劫持等)
-
🔄 举个例子你就懂了:
你下载一个原神 MOD 工具,它是用 VC++ 2008 写的。Windows 11 没有预装 2008,所以你运行时报错缺少
MSVCR90.dll。但这并不是 Windows 的错,而是开发者没有在安装包里带上运行库安装器。
✅ 解决办法(也是你现在用的):
安装「VC++ 运行库合集」本质上就是为你统一解决了这些“分发责任不清”的历史遗留问题。
你装好一遍之后,就能跑 90% 民间工具/旧版游戏/编辑器。

PmxEditor 是专门用于 编辑/修正/导出 MMD 模型 的 GUI 工具。
它可以:
-
修改模型的顶点、骨骼、表情、材质、物理刚体
-
替换贴图 / 调整透明 / 调整描边
-
导入/导出
.pmx、.pmd格式 -
可用于动作测试、附加插件(.vmd 动作可在 PmxView 中查看)
| 文件/文件夹名 | 说明 |
|---|---|
PmxEditor.exe | 主程序,32位运行版 |
PmxEditor_x64.exe | 主程序,64位运行版(建议用这个) |
.config 文件 | 启动配置参数(比如语言环境) |
readme.docx | 使用说明(通常是日文/英文) |
_plugin/ | 插件目录,比如自动权重、法线修复工具等 |
Lib/ | 核心运行库(DLL)所在位置,程序调用的依赖库 |
_data/ | UI 本地化、界面配置、材质预设等资源文件 |
❓需要安装 VC++ 运行库吗?
是的,推荐先安装你上面贴的 VC++ 运行库合集,尤其是:
-
VC++ 2010(PmxEditor 是 C# + C++ 混合开发的) -
VC++ 2013和VC++ 2015+(部分 DLL 插件也可能依赖)
🚫 如果你不装运行库,可能会遇到:
-
❌ 启动直接闪退无提示
-
❌ 报错缺失
MSVCP*.dll或.NET Framework组件 -
❌ 插件无法加载、无法导出
.pmx
【动作配布】甘雨·杰克逊_哔哩哔哩_bilibili
mikudance简单接触