帝国网站建设/公司网站页面设计
GoogleLeNet
GoogLeNet在2014年的ImageNet Large Scale Visual Recognition Challenge (LSVRC)中获得了冠军。GoogLeNet的设计灵感来源于NiN(Network in Network),通过使用多个小的网络模块串联成更大的网络。这些小的网络模块被称为Inception模块,它们能够并行地从不同尺度提取特征,然后将这些特征合并起来,以提高网络的准确性和性能。
Inception模块的设计
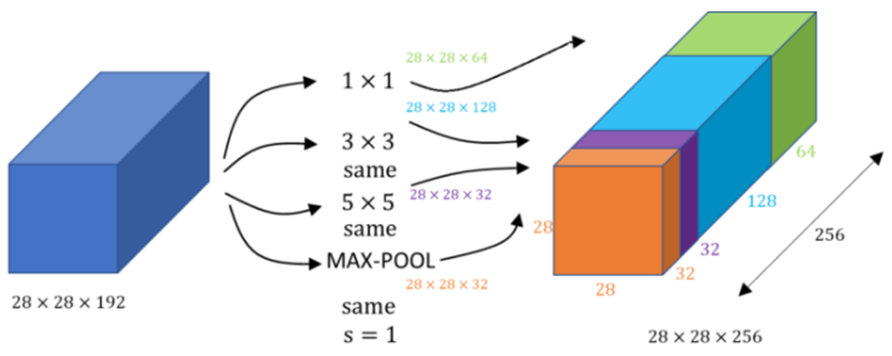
- 多尺度特征提取:Inception模块通过使用不同大小的卷积核(例如1x1、3x3、5x5)和3x3的MaxPooling层来并行地提取不同尺度的特征。这种设计使得网络能够捕捉到图像中的局部和全局信息。
- 特征融合:提取的特征图通过通道轴(channel axis)拼接起来,增加了网络的宽度,从而能够捕捉更多的图像特征。
- 尺寸一致性:为了保持特征图的尺寸一致,卷积层和池化层通常会使用
padding="same"和stride=1的参数设置,这样无论卷积或池化操作后,输出的特征图尺寸都与输入保持一致。
Inception模块的优化
-
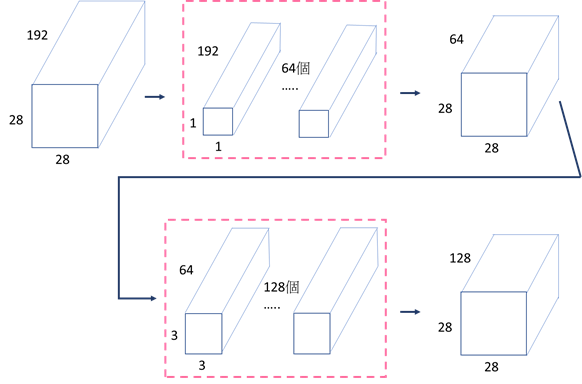
1x1卷积层:为了减少模型的参数数量和计算量,GoogLeNet在Inception模块中引入了1x1的卷积层。这些1x1的卷积层可以看作是一种降维操作,它们在进行更大卷积核操作之前减少输入通道的数量。

-
减少参数和计算量:1x1卷积层通过减少通道数,有效地减少了后续卷积层的参数数量和计算量,同时保持了网络的深度和宽度。
-
MaxPooling后的处理:在通过3x3的MaxPooling层后,通常会再使用1x1的卷积层来进一步减少输出的通道数,以控制模型的复杂度。将四个结果以通道轴串接在一起(来源)。
1x1卷积层如何降低输出通道数及参数量?
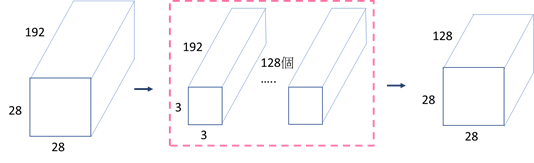
先看接了一层3x3卷积层的参数量,由下图所示,参数量为 (3 \times 3 \times 192 + 1 \times 128 = 106112)
接下来来看先接1x1卷积层,再接3x3卷积层的参数量为 (1 \times 1 \times 192 + 1 \times 64 + 3 \times 3 \times 64 + 1 \times 128 = 86208)。
从原先的参数量106112降至86208个,因此之后的Inception模块都是使用改良过的版本。
介绍完Inception模块后,接下来要讲述GoogLeNet的模型架构。下图为GoogLeNet的模型架构,由下至上为输入到输出。橘色的框框为Inception模块,而粉色的框框为分类辅助器(auxiliary classifiers)。
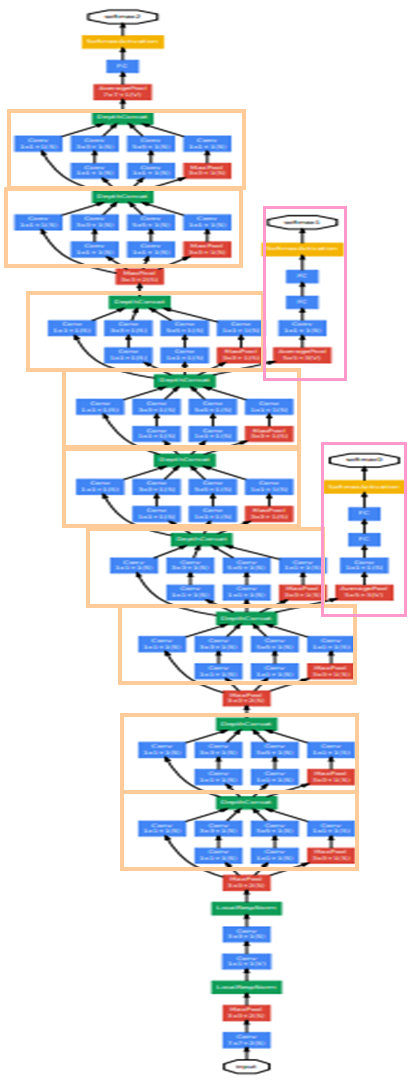
GoogLeNet是深层的神经网络,因此会遇到梯度消失的问题。分类辅助器就是为了避免这个问题,并提高其稳定性和收敛速度。方法是在两个不同层的Inception模块输出结果并计算loss,最后将这两个loss和真实loss加权总和,计算出总loss,其中Inception模块的loss权重值为0.3。
[
\text{total_loss} = \text{real_loss} + 0.3 \times \text{aux_loss_1} + 0.3 \times \text{aux_loss_2}
]
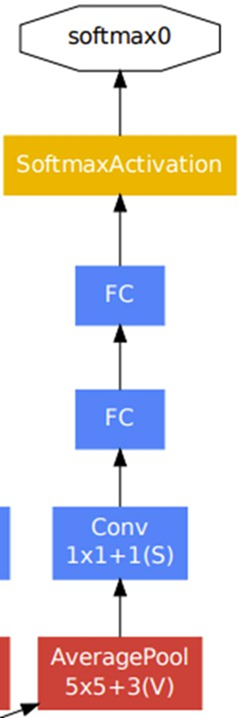
接下来是Inception-V1的代码,分别定义了InceptionV1 block和auxiliary classifiers,再将这两个模块组合成InceptionV1,其中辅助分类器只在训练时使用。
ResNet (2015)
论文链接: https://arxiv.org/pdf/1512.03385.pdf
ResNet在2015年由微软的何恺明博士提出,并在同年ImageNet LSVRC分类竞赛中获得了冠军,同时也在ImageNet detection、ImageNet localization、COCO detection和COCO segmentation等任务中均获得了第一名,此外还获得了CVPR2016最佳论文奖。
在竞赛中,ResNet一共使用了152层网络,其深度比GoogLeNet高了七倍多(20层),并且错误率为3.6%,而人类在ImageNet的错误率为5.1%,已经达到了小于人类错误率的程度。
ResNet为何能够如此厉害?原因在于ResNet提出之前,神经网络一直无法进行更深层的训练,而ResNet提出的Residual Learning能够让深层网络更容易训练,开启了超深网络的时代。
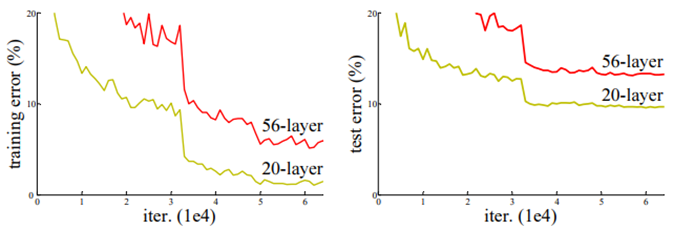
至于神经网络为何无法进行更深层的训练?随着网络层数的增加,当达到一定程度时,反而会降低训练准确率。由下图可以看出,56层的网络表现比20层还差,但这并不是因为过拟合的问题,而是深层网络的退化问题(degradation)。
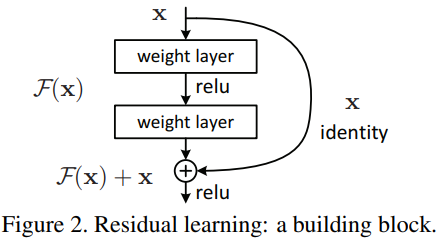
ResNet的特色在于使用了Shortcut Connection的结构,一共有两个分支:一个是将输入的x跨层传递,另一个是F(x)。将这两个分支相加再送到激活函数中,这种方式称为Residual Learning,可以解决模型退化的问题(degradation)。
❓Residual Learning是如何解决模型退化的问题?
由Residual Learning我们可以知道输出为F(x) + x,首先令这个式子等于H(x),也就是输出值为H(x) = F(x) + x。
当网络训练达到饱和的时候,F(x)容易被优化成0,这时只剩下x,此时H(x) = x,这种情况就是Identity mapping(恒等映射)。
先来看一下Identity mapping的定义:
设M为一集合,于M上的恒等函数f被定义于一具有定义域和对应域M的函数,其对任一M内的元素x,会有f(x)=x的关系。
这段话的意思其实就是指输入函数的值会等于输出函数的值,因此越深的网络,也能确保准确率不会下降。
- Residual Block
Residual同样采用模块化的方式,针对不同深度的ResNet,作者提出了两种Residual Block。
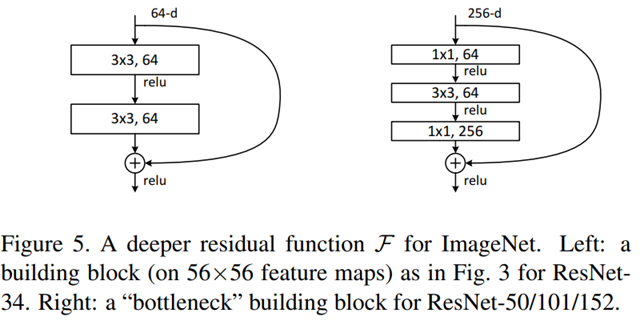
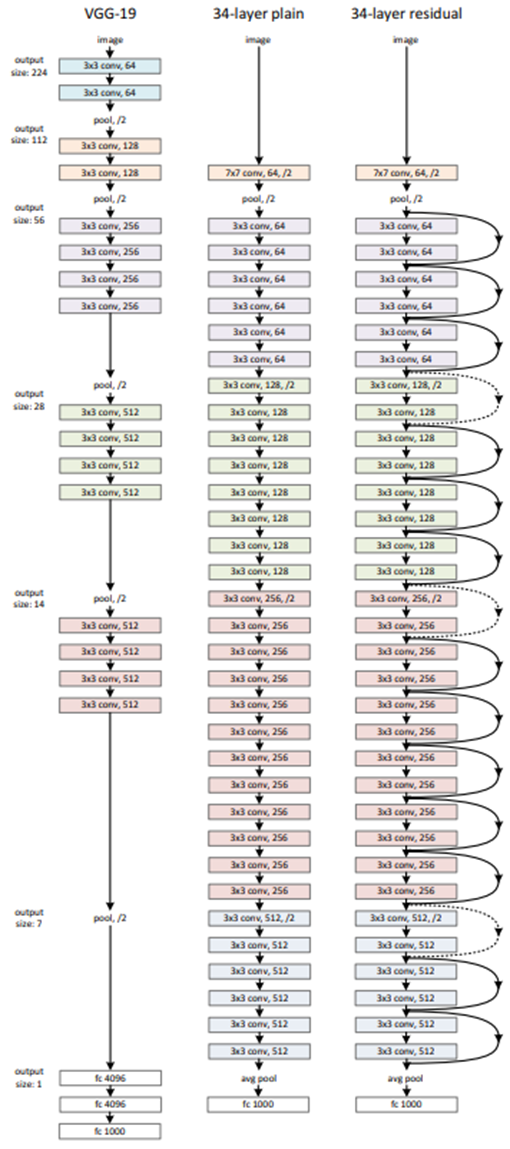
下图(a)为基本的Residual Block,使用连续的两个3x3卷积层,并每两个卷积层进行一次Shortcut Connection,用于ResNet-34。
下图(b)则是针对较深的网络所做的改进,称为bottleneck。因为层数越高,导致训练成本变高,因此为了降低维度,在送入3x3卷积层之前,会先通过1x1卷积层降低维度,最后再通过1x1卷积层恢复原本的维度。用于ResNet-50、ResNet-101、ResNet-152。
- ResNet架构
下图为ResNet不同层数的网络架构,可以看到第一层为7x7的卷积层,接上3x3 Maxpooling,接着再使用大量的Residual Block,最后使用全局平均池化(Global Average Pooling)并传入全连接层进行分类。
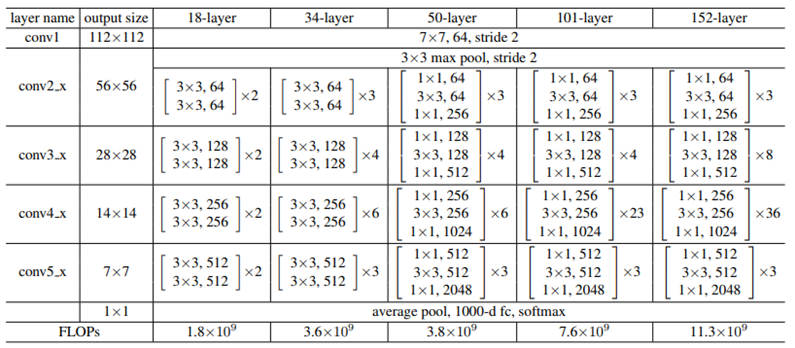
下图为ResNet-34的网络模型图,虚线部分就是指在进行Shortcut Connection时,输入的x与权重输出的F(x)通道(channel)数目不同,因此需要使用1x1卷积层调整通道维度,使其可以进行相加的运算。
看完了ResNet架构,接下来是代码。刚刚有提到ResNet针对不同深度提出了两种Residual Block,所以代码里分别定义了basic_block及bottleneck_block两种模块。
DenseNet (2017)
论文链接: https://arxiv.org/pdf/1608.06993.pdf
DenseNet有别于以往的神经网络,不是从网络深度与宽度着手,而是从特征的角度去考虑,通过特征重用的方式,加强了特征的利用、减轻梯度消失的问题、大幅地减少了参数计算量,并达到了更好的准确率,因而获得了CVPR 2017最佳论文。
那DenseNet是如何从特征的角度去考虑的呢?它的做法就是将前面所有层的feature map作为输入,然后将其concat起来聚合信息,如此一来可以保留前面的特征,称为特征重用(feature reuse),让结构更加密集,提高了网络的信息和梯度流动,使得网络更加容易训练。
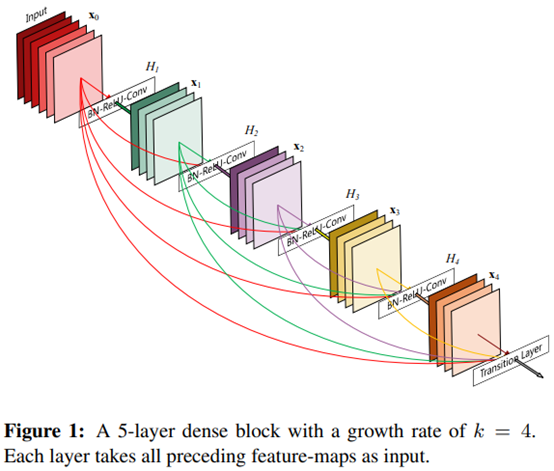
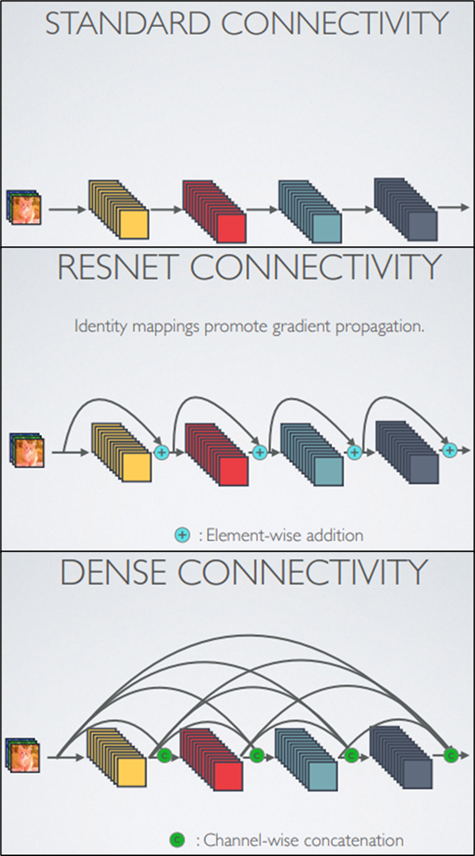
而这个特征重用的想法是来源于ResNet的Shortcut Connection思想,但不同的是ResNet是将feature map做跨通道的相加,而DenseNet则是以通道轴做串接的动作。
source
DenseNet由Dense block与Transition layer(过渡层)所组成,Dense block就是刚刚提到的特征重用的部分,而Transition layer就是将两个相邻的Dense block做连接。
下图是DenseNet的网络架构,总共有三个Dense block,并且两个block之间的卷积层与池化层为transition layer,全局平均池化(Global Average Pooling)以及全连接层。
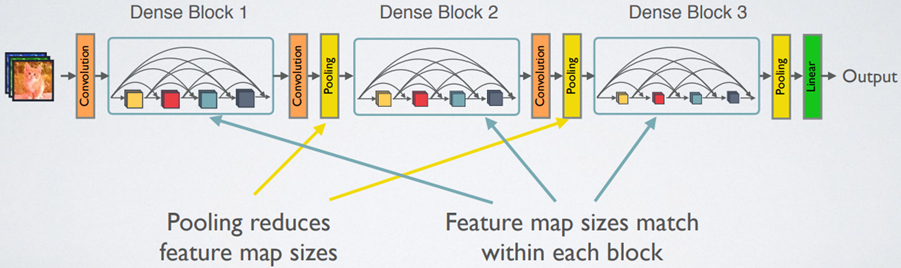
source
- Dense block
Dense block采用Batch Normalization、ReLU、3x3卷积层的结构,与ResNet block不同的是Dense block有个超参数k称为growth rate,是指每层输出的channel数目为k个(输出通道数会随着层数而增加)。为了不让网络变宽,通常使用较小的k。
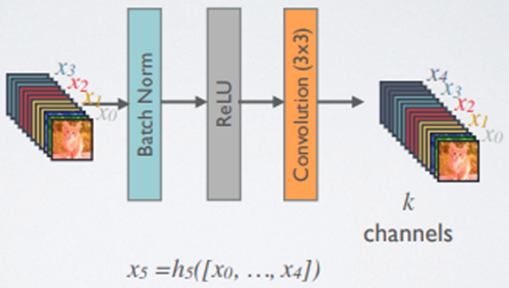
source
- Bottleneck Layer
因为特征重用的因素,输出通道数会随着层数而增加,因此Dense block可以采用Bottleneck来降低通道维度、减少参数计算量。
Bottleneck的结构为Batch Normalization、ReLU、1x1卷积层、Batch Normalization、ReLU、3x3卷积层,称为DenseNet-B。
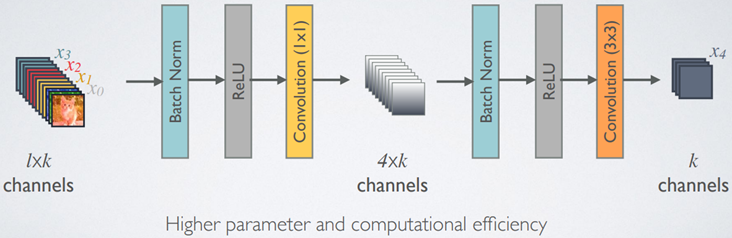
source
- Transition Layer
Transition layer的目的是为了压缩模型,使模型不会过于复杂,主要是将两个Dense block进行连接。由于Dense block的输出通道数目很多,会有通道数过长的问题,因此需要使用1x1卷积层来降维,并且使用平均池化来缩小特征图的尺寸。

- DenseNet架构
下图为DenseNet不同层数的网络架构,可以看到第一层为7x7的卷积层,接上3x3 Maxpooling,接着再使用大量的Dense Block、Transition Layer,最后使用全局平均池化(Global Average Pooling)并传入全连接层进行分类。
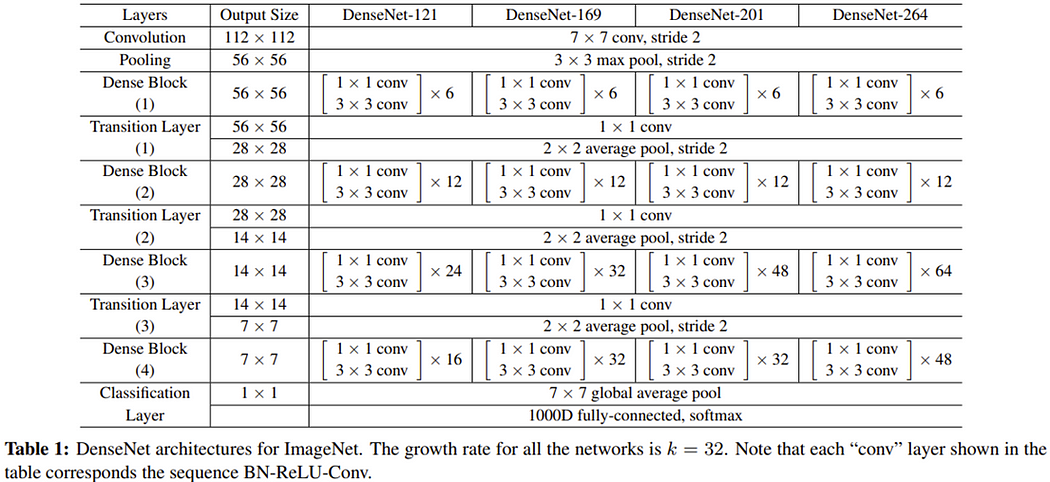
前面提到一开始的Dense block采用Batch Normalization、ReLU、3x3卷积层的结构,但后来为了降低通道维度就改采用Bottleneck。在代码里还是都有定义,只是DenseNet的结构是使用Bottleneck。