【机器学习深度学习】线性回归
目录
一、定义
二、举例说明
三、 数学形式
四、 训练过程(机器怎么学会这条线?)
五、在 PyTorch 中怎么实现线性回归?
六、如果你学懂了线性回归,你也能理解这些
七、综合应用:线性回归示例
7.1 执行代码
7.2 运行效果
7.3 运行图示效果
7.4 代码解析
7.4.1 库名解析
7.4.2 生成数据
7.4.3 定义模型
7.4.4 训练设置
7.4.5 训练循环
7.4.6 结果可视化

一、定义
线性回归是用一条直线,来拟合数据中输入和输出之间的关系。
它是最简单的一种监督学习模型,目标是学会从输入 x预测输出 y。
线性回归就是用一条最合适的“直线”去拟合数据关系,是所有机器学习算法的“入门基础”和“核心思想的起点”。
二、举例说明
比如你有下面这些数据点(房屋面积 → 价格):
| 房屋面积 (㎡) | 房价 (万) |
|---|---|
| 50 | 100 |
| 60 | 120 |
| 70 | 140 |
| 80 | 160 |
你发现:
面积每增加 10 平方,价格多了 20 万
→ 明显是个线性关系:
三、 数学形式
最基本的一元线性回归:

-
x:输入特征(如面积)
-
y:目标输出(如房价)
-
w:权重(斜率)
-
b:偏置(截距)
-
模型要学会找到最合适的 w 和 b,使得预测值
 尽可能接近真实值 y
尽可能接近真实值 y
四、 训练过程(机器怎么学会这条线?)
通过梯度下降:
-
初始化 w、b(通常是随机值)
-
预测:算出
-
计算损失 MSE
-
反向传播(backward):计算损失对 w、b的梯度
-
更新参数:往损失下降的方向调整 w、b
-
重复上述步骤,直到 loss 越来越小,收敛为止
五、在 PyTorch 中怎么实现线性回归?
model = nn.Linear(1, 1) # 1 个输入,1 个输出
-
自动帮你创建了可训练的
weight和bias -
使用
MSELoss()做目标函数 -
使用优化器(如
SGD)进行参数更新
最终训练完后你得到的就是:
一个已经学会了你数据规律的函数:
它就可以用来对新样本进行预测了
六、如果你学懂了线性回归,你也能理解这些
| 模型 | 关系与区别 |
|---|---|
| 逻辑回归 | 用线性回归的结果接 softmax → 做分类任务 |
| 神经网络 | 多层线性回归 + 激活函数 |
| 支持向量机(SVM) | 类似线性分类器,只是优化目标不同 |
| RNN / LSTM / CNN | 都是在这个思想上发展出来的 |
七、综合应用:线性回归示例
7.1 执行代码
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
# ==============================
# 综合应用:线性回归
# ==============================
print("\n" + "=" * 50)
print("综合应用: 线性回归")
print("=" * 50)# 生成数据
torch.manual_seed(42) #种子数:42——生成重复的随机数据
X = torch.linspace(0, 10, 100).reshape(-1, 1) #在0-9之间,定义100个数据,每个数据一个特征
print(X.shape)
true_weights = 2.5 #W:权重:2.5
true_bias = 1.0 #b:偏置项:1.0
y = true_weights * X + true_bias + torch.randn(X.size()) * 1.5 #模拟真实数据# 定义模型
class LinearRegression(nn.Module):def __init__(self):super().__init__()self.linear = nn.Linear(1, 1)def forward(self, x):return self.linear(x)# 训练设置
model = LinearRegression() #初始化实例
criterion = nn.MSELoss() #定义损失函数,衡量预测和真实的差距
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) #设置优化器,用来更新模型的参数
epochs = 1000 #训练轮数:1000# 训练循环
for epoch in range(epochs):optimizer.zero_grad() #outputs = model(X) #loss = criterion(outputs, y) #loss.backward() #optimizer.step() #if (epoch + 1) % 20 == 0:print(f'Epoch [{epoch + 1}/{epochs}], Loss: {loss.item():.4f}')# 结果可视化
predicted = model(X).detach().numpy()
plt.scatter(X.numpy(), y.numpy(), label='Original data')
plt.plot(X.numpy(), predicted, 'r-', label='Fitted line')
plt.legend()
plt.title(f'Final weights: {model.linear.weight.item():.2f}, bias: {model.linear.bias.item():.2f}')
plt.show()7.2 运行效果
==================================================
综合应用: 线性回归
==================================================
torch.Size([100, 1])
Epoch [20/1000], Loss: 2.7219
Epoch [40/1000], Loss: 2.6217
Epoch [60/1000], Loss: 2.5395
Epoch [80/1000], Loss: 2.4722
Epoch [100/1000], Loss: 2.4170
Epoch [120/1000], Loss: 2.3718
Epoch [140/1000], Loss: 2.3348
Epoch [160/1000], Loss: 2.3044
Epoch [180/1000], Loss: 2.2795
Epoch [200/1000], Loss: 2.2591
Epoch [220/1000], Loss: 2.2424
Epoch [240/1000], Loss: 2.2287
Epoch [260/1000], Loss: 2.2175
Epoch [280/1000], Loss: 2.2083
Epoch [300/1000], Loss: 2.2008
Epoch [320/1000], Loss: 2.1946
Epoch [340/1000], Loss: 2.1895
Epoch [360/1000], Loss: 2.1854
Epoch [380/1000], Loss: 2.1820
Epoch [400/1000], Loss: 2.1792
Epoch [420/1000], Loss: 2.1769
Epoch [440/1000], Loss: 2.1750
Epoch [460/1000], Loss: 2.1735
Epoch [480/1000], Loss: 2.1722
Epoch [500/1000], Loss: 2.1712
Epoch [520/1000], Loss: 2.1704
Epoch [540/1000], Loss: 2.1697
Epoch [560/1000], Loss: 2.1691
Epoch [580/1000], Loss: 2.1686
Epoch [600/1000], Loss: 2.1683
Epoch [620/1000], Loss: 2.1679
Epoch [640/1000], Loss: 2.1677
Epoch [660/1000], Loss: 2.1675
Epoch [680/1000], Loss: 2.1673
Epoch [700/1000], Loss: 2.1672
Epoch [720/1000], Loss: 2.1671
Epoch [740/1000], Loss: 2.1670
Epoch [760/1000], Loss: 2.1669
Epoch [820/1000], Loss: 2.1667
Epoch [840/1000], Loss: 2.1667
Epoch [860/1000], Loss: 2.1667
Epoch [880/1000], Loss: 2.1666
Epoch [900/1000], Loss: 2.1666
Epoch [920/1000], Loss: 2.1666
Epoch [940/1000], Loss: 2.1666
Epoch [960/1000], Loss: 2.1666
Epoch [980/1000], Loss: 2.1666
Epoch [1000/1000], Loss: 2.16667.3 运行图示效果

7.4 代码解析
7.4.1 库名解析
import torch
import torch.nn as nn
import matplotlib.pyplot as plt✅ 1. torch:PyTorch 的主库
作用:提供张量运算、自动求导和深度学习模型构建能力。
在本代码中,torch 的主要作用有:
-
torch.manual_seed(42):设置随机种子,确保每次运行生成的随机数(如噪声)一致,方便调试和复现实验结果。 -
torch.linspace(0, 10, 100):生成从 0 到 10 的 100 个等间距值,模拟自变量 XXX。 -
torch.randn(...):生成服从正态分布的随机噪声,加入到 yyy 中,模拟真实数据中的扰动。 -
X.size()/.reshape(-1, 1):控制张量形状,确保符合模型输入要求。 -
所有模型定义、参数、损失计算、反向传播 (
loss.backward())、优化 (optimizer.step()) 都依赖于torch的自动求导与计算图。
✅ 2. torch.nn:PyTorch 的神经网络模块
作用:构建和使用神经网络模块(如线性层、激活函数、损失函数等)。
在本代码中:
-
nn.Module:是所有神经网络模块的基类。LinearRegression类继承自它,定义了一个简单的线性模型。 -
nn.Linear(1, 1):定义一个具有一个输入特征和一个输出特征的线性层(即 y=wx+by = wx + by=wx+b)。 -
nn.MSELoss():均方误差损失函数,用于衡量预测值与真实值的差异。
✅ 3. matplotlib.pyplot:绘图库
作用:用于绘制图形、数据可视化。
在本代码中:
-
plt.scatter(...):绘制原始数据点(散点图),表示样本 (X, y)。 -
plt.plot(...):绘制模型拟合出的线性曲线(红线),表示预测值。 -
plt.legend()、plt.title(...):添加图例和标题,展示最终模型参数。 -
plt.show():展示图像窗口。
总结表:
| 依赖库 | 作用简述 |
|---|---|
torch | 张量操作、反向传播、优化等底层计算支持 |
torch.nn | 神经网络层、损失函数的模块化构建工具 |
matplotlib.pyplot | 数据可视化(绘图、展示模型预测结果) |
这些依赖共同构成了完整的“模型构建 → 训练 → 可视化”流程。你也可以理解为:
📦 torch 是“数据和训练引擎”、📦 torch.nn 是“模型建造工具”、📊 matplotlib.pyplot 是“成果展示板”。
7.4.2 生成数据
# 生成数据
torch.manual_seed(42)
X = torch.linspace(0, 10, 100).reshape(-1, 1)
print(X.shape)
true_weights = 2.5
true_bias = 1.0
y = true_weights * X + true_bias + torch.randn(X.size()) * 1.5这段代码的作用是:生成用于线性回归的模拟数据集。
🔹
torch.manual_seed(42)设置随机数生成器的种子为 42,使得每次运行代码时,生成的随机数都是可复现的,即
torch.randn()生成的噪声始终一样。让随机过程变得“确定”下来,这样你的实验结果每次都一样,方便复现和调试。🤔它的作用是:
固定随机数生成器的初始状态,这样每次你运行程序时,生成的“随机数”都是完全一样的。
这样你就能保证结果可重复、可调试!
🤔 为什么要用这个?
做实验、调试时要结果一致:如果你加入了随机噪声或模型参数是随机初始化的,每次运行结果都不同,会很难调试。
写教学/研究/博客代码时需要复现:别人运行你代码时希望结果一样。
可对比性:你换了一种训练方式,想验证哪个更好——如果噪声不同,是没法公平比较的。
🔹
X = torch.linspace(0, 10, 100).reshape(-1, 1)它的作用是:
生成一个形状为
[100, 1]的输入特征张量 X,范围从 0 到 10,共 100 个样本点。拆解说明:
▲torch.linspace(0, 10, 100):在区间 [0, 10] 上生成 100 个等间距的数,表示自变量(输入特征)。
tensor([0.0000, 0.1010, 0.2020, ..., 9.8990, 10.0000]) #100个点
▲.reshape(-1, 1):✅ 一句话解释
把张量变成 2 维,其中:
-1表示“这一维度让我自动算”,
1表示“我想要 1 列”。✅ 用 .reshape(-1, 1),含义就是: x.reshape(?, 1) # 问号表示“PyTorch 你帮我算出来”PyTorch 会看:原来你有 100 个数,你要求 1 列,那它自动算出你应该有 100 行。
所以变成:
x.shape → [100, 1]
-1表示“自动推断有多少行”,在这里 PyTorch 会计算出是 100 行;
1表示每行 1 个元素 → 每个样本有 1 个特征最终结果就变成了二维张量:
[[0.0000],[0.1010],[0.2020],...[9.8990],[10.0000] ] ← shape: [100, 1]✅ 为什么
-1就是“自动算”?PyTorch、Numpy 等都规定:
在 reshape 里,如果某一维写
-1,表示“我不想算这个维度,你帮我根据总元素数自动推断”。比如下面这些例子:
a = torch.arange(12) # shape: (12,)a.reshape(3, 4) # → (3, 4) a.reshape(-1, 4) # → (3, 4) ← -1 让 PyTorch 自己算出是 3 行 a.reshape(2, -1) # → (2, 6) ← -1 被自动推成 6 列🚩 错误示例(多于一个 -1 会报错):
a.reshape(-1, -1) # ❌ 报错:只能有一个 -1这是形状变换的关键:
原来
linspace生成的是 一维张量,形状是(100,)
注意:这里(100,)表示的是长度为100,不是100行
但我们希望它变成 二维张量,形状是
(100, 1),表示“100 个样本,每个样本有 1 个特征”📌 总结公式
你可以记住这句话:
.reshape(-1, n)就是:
“把这个张量 reshape 成 n 列,行数我不想算,PyTorch 你自动算就行。”
形状 含义 适合线性回归吗? [100, 1]✔️ 有 100 个样本,每个样本 1 个特征 ✅ 是 [1, 100]❌ 有 1 个样本,拥有 100 个特征 ❌ 否 [100]❓ 一维张量,不明确样本维度 ❌ 否(模型报错)
部分代码 含义 torch.linspace(0, 10, 100)生成 0~10 之间的 100 个点 .reshape(-1, 1)把一维的 [100]变成二维[100, 1]最终的 X是一个 100 行 1 列的输入张量
🔹
true_weights = 2.5这是你自己设定的**“真实模型的权重”**,代表线性函数的斜率:
y = 2.5 * x + 1.0 + 噪声
🔹
true_bias = 1.0表示真实模型的偏置项(截距)。
🔹
y = true_weights * X + true_bias + torch.randn(X.size()) * 1.5🧠主要作用:
生成“模拟的真实数据”(也叫“合成数据”),专门用来做线性回归训练的。
这里做了一个WX+b的计算,但是加入了【随机张量*1.5】,用于模拟噪声 使其能够更加贴合真实环境中的数据。🧠 拆解说明:
这是生成带有噪声的目标值 y,用于拟合:
true_weights * X + true_bias:构造一个理想的线性关系 y=2.5x+1.0y = 2.5x + 1.0y=2.5x+1.0
torch.randn(X.size()):生成一个与 XXX 形状相同的随机张量,服从标准正态分布 N(0,1)
* 1.5:将噪声的标准差放大为 1.5,模拟更复杂的实际场景(让数据点不是完全线性的)结果是:
🧠 总结一下这一块的直观含义:
手动生成了一批看起来像“真实世界采集”的数据:
X 是输入变量,从 0 到 10 均匀分布;
y 是输出变量,大致符合 y = 2.5x + 1 的关系,但加入了噪声,使得它不是完美的直线;
这就是后面用来训练模型拟合出的“模拟数据”。
7.4.3 定义模型
# 定义模型
class LinearRegression(nn.Module):def __init__(self):super().__init__()self.linear = nn.Linear(1, 1)def forward(self, x):return self.linear(x)这段代码定义了一个最简单的线性回归模型,输入 1 个数,输出 1 个数,核心是:
y = w * x + b,这个公式被封装在nn.Linear(1, 1)中。
定义了一个线性回归模型类,名字叫 LinearRegression,本质就是实现了:
![]()
也就是一个带权重和偏置的线性变换。
🔹class LinearRegression(nn.Module):
定义一个新的类,名字叫
LinearRegression,这个类继承自 PyTorch 提供的nn.Module。
nn.Module是 PyTorch 中所有模型的基类。你自定义的神经网络都应该继承它。
🔹super().__init__()
这一行是固定写法,它调用父类
nn.Module的构造方法。🧠 没有它,PyTorch 的模型结构和参数注册系统就没法正常工作。
🔹self.linear = nn.Linear(1, 1)
这一行很关键!
它定义了一个线性层,输入和输出都是 1 个特征,也就是:
y = w * x + b
in_features = 1:说明你每个样本的输入只有 1 个数(x)
out_features = 1:说明模型输出也只有 1 个数(预测 y)这个层会自动帮你创建两个参数:
参数 含义 weight线性函数的斜率 w bias偏置项 b
🔹def forward(self, x):
这是 PyTorch 模型的核心函数,定义了模型的“前向传播”逻辑。
也就是说,当你
model(x)的时候,实际调用的就是这个函数。
🔹return self.linear(x)
输入
x会通过self.linear这个线性层:
PyTorch 会自动处理矩阵乘法、广播等操作,并计算输出。
🎯 整体行为总结:
定义了一个“线性变换模型”,它会:
接收一个输入
x(形状是[batch_size, 1])自动用参数 w和 b 计算出预测结果 y=wx+b
参与训练(PyTorch 自动记录梯度和更新参数)
7.4.4 训练设置
# 训练设置
model = LinearRegression()
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
epochs = 1000这部分是模型训练的准备工作
🔹model = LinearRegression()
创建定义的线性回归模型实例
现在
model就包含了一个线性层nn.Linear(1, 1),其中的权重w和偏置b是 随机初始化 的。它准备好接收输入并产生预测值
y_hat = model(x)。
🔹criterion = nn.MSELoss()
这是设置损失函数:
它衡量的是:
预测值
y_hat与真实值y之间的平均平方差在回归问题中(输出是连续数值),MSE 是最常用的损失函数。
MSELoss = Mean Squared Error Loss,中文叫均方误差损失。公式是:
🔹optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
这行的作用是:
设置一个优化器,用来更新模型的参数(权重和偏置),以最小化损失函数。
解释:
SGD= 随机梯度下降(Stochastic Gradient Descent),一种常见的优化算法。
model.parameters():把模型的所有参数(权重w、偏置b)都传进去,让优化器负责更新它们。
lr=0.01:学习率,控制每一步更新的“幅度”。📌 如果学习率太小,训练会很慢;太大,可能震荡、甚至不收敛。
🔹epochs = 1000
设置训练的总轮数(epoch):
一个 epoch = 用全部训练数据训练一次模型
你让模型训练 1000 次,反复调整参数来逼近真实值
✅ 总结表格:
代码 含义 model = LinearRegression()创建模型实例,准备接收输入 criterion = nn.MSELoss()定义损失函数,衡量预测和真实的差距 optimizer = torch.optim.SGD(...)设置优化器,用来更新模型的参数 epochs = 1000训练轮数,表示训练模型多少遍
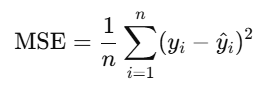
💡 小结一句话:
这四行代码是在为“模型训练”做好准备工作:模型、评判标准(损失)、优化方法和训练时间长度。
7.4.5 训练循环
# 训练循环
for epoch in range(epochs):optimizer.zero_grad()outputs = model(X)loss = criterion(outputs, y)loss.backward()optimizer.step()if (epoch + 1) % 20 == 0:print(f'Epoch [{epoch + 1}/{epochs}], Loss: {loss.item():.4f}')✅ 一句话总结
这段代码通过 “预测 → 计算损失 → 反向传播 → 更新参数” 的过程,反复 1000 次,让模型学会拟合数据点 X→y,找出最合适的权重和偏置。
这部分代码是训练的核心循环,也叫“训练主干”,负责让模型学会从数据中提取规律。
🔹for epoch in range(epochs):
这是训练的主循环,总共会执行
epochs次(这里是 1000 次)。每一次循环,模型都会用全部的训练数据
X,预测一遍,然后更新参数。
🔹optimizer.zero_grad()
每次迭代开始前,清空旧的梯度信息。
因为 PyTorch 会自动累积梯度,所以每次计算新梯度前要先清空。
🔹
outputs = model(X)
把输入数据
X喂进模型,得到预测输出outputs,也就是。
这一步会自动调用你模型里的
forward()函数:def forward(self, x):return self.linear(x)
🔹loss = criterion(outputs, y)
比较模型预测值
outputs和真实值y,计算损失值。
criterion = nn.MSELoss()是均方误差,越小表示预测越准确。
🔹loss.backward()
反向传播:根据损失
loss自动计算模型中所有参数的梯度(导数)。PyTorch 会自动为你完成链式法则的求导。
🔹optimizer.step()
使用前面算出来的梯度,更新模型参数(权重
w和偏置b)。优化器根据学习率和梯度来调整参数,让损失变得更小。
🔹
if (epoch + 1) % 20 == 0:
每训练 20 次,打印一次日志。
loss.item()把一个标量 tensor 取出数值,用于打印。结果例子:
Epoch [20/1000], Loss: 1.2234 Epoch [40/1000], Loss: 0.8912 ...
📊 图示训练流程:
┌────────────┐
│ X │ ← 输入
└────┬───────┘
↓
┌────────────┐
│ model(X) │ ← 前向传播:预测 outputs
└────┬───────┘
↓
┌────────────┐
│ loss = MSE │ ← 损失函数:outputs vs y
└────┬───────┘
↓
┌────────────┐
│ backward │ ← 自动求导:loss.backward()
└────┬───────┘
↓
┌────────────┐
│ optimizer │ ← 参数更新:optimizer.step()
└────────────┘
7.4.6 结果可视化
# 可视化结果
predicted = model(X).detach().numpy()
plt.scatter(X.numpy(), y.numpy(), label='Original data')
plt.plot(X.numpy(), predicted, 'r-', label='Fitted line')
plt.legend()
plt.title(f'Final weights: {model.linear.weight.item():.2f}, bias: {model.linear.bias.item():.2f}')
plt.show()这段代码是整个线性回归项目的最后一步:结果可视化,帮助你直观地看到模型学得怎么样。例如:

🔹predicted = model(X).detach().numpy()
含义:让模型生成预测结果,并把它转换成 NumPy 格式,方便画图。
model(X):把输入X送入你训练好的模型,得出预测值(也就是模型估计的y_hat)
.detach():从计算图中分离出来,不需要梯度,只用于画图。
.numpy():把结果变成 NumPy 数组。得到的是一个形状也为
[100, 1]的数组,对应每个x值的预测y。
🔹plt.scatter(X.numpy(), y.numpy(), label='Original data')
画出原始训练数据点(带噪声的),用“散点图”表示。
X.numpy():把 PyTorch 的张量转成 NumPy 数组,才能用matplotlib来画图;
y.numpy():同样是把y转成 NumPy 数组,方便画图;
X.numpy(), y.numpy()是将你的输入数据和真实标签数据从 PyTorch 的 Tensor 转成 NumPy 数组,以便用matplotlib.pyplot画图;
横坐标是
X,纵坐标是y(真实的目标值)这是你用来训练模型的数据点
它们并不完美在一条直线上,是故意加了噪声的
🔹plt.plot(X.numpy(), predicted, 'r-', label='Fitted line')
用 matplotlib 画一条“红色直线”,表示模型预测出的结果,即模型学到的线性函数。
画出模型学习出来的那条“最佳拟合线”
横坐标:输入
X纵坐标:模型预测值
predicted
'r-'表示红色(red)实线这是你训练了这么久之后,模型认为最合适的那条线
🔹plt.legend()
显示图例,对应你前面加的
label='...'标签:
原始数据:蓝色点
拟合线:红色线
🔹plt.title(...)
给图加标题:显示模型最终学到的参数(权重和偏置):
f'Final weights: {model.linear.weight.item():.2f}, bias: {model.linear.bias.item():.2f}'意思是:
最终权重:比如 2.49,最终偏置:比如 1.02
这能帮你验证:
模型是不是成功学到了你最初设置的
2.5和1.0
🔹plt.show()
正式显示整个图像窗口。