《推荐技术算法与实践》
文章目录
- 零、课程介绍
- 1.课程背景
- 2.课程目标
- 3.教材与参考资料
- 一、推荐系统概述
- 1.推荐系统概念
- (1)推荐系统与传统搜索引擎的区别
- (2)推荐系统的历史
- 2.推荐算法简介
- (1)算法概述
- (2)经典推荐算法
- ①基于人口统计学的推荐
- ②协同过滤推荐 CF
- ③基于内容的推荐
- TF-IDF算法
- VSM
- ④基于关联规则的推荐
- 3.推荐系统的评价
- 4.推荐系统研究发展的热点方向:用户行为的影响
- 二、推荐系统概述
- 1.推荐系统概念
- 2.经典算法
- 3.评价
- 4.用户行为的影响
- 三、推荐系统前沿研究介绍
- 1.推荐系统与深度学习
- 2.推荐系统与信息检索
- 3.推荐系统与知识图谱结合
- 四、前沿论文分享与作业讨论
- 1.论文
- 2.评估
- (1)NDCG@K
- (2)Recall@K
- 3.推荐系统基础
- (1)协同过滤
- (2)图卷积网络 GCN
- (3)LightGCN
- (4)BPR 贝叶斯个性化排序
- 五、2025 RecSys 比赛
- 1.官网
- 2.步骤
- 3.结果
零、课程介绍
1.课程背景
- 大数据时代,人们面临信息过载的情况。推荐系统是解决问题的重要工具。它的任务是联系用户和信息,帮助用户发现对自己有价值的信息,同时让信息能够展现到对它感兴趣的用户手中。
- 本课程主要对推荐技术进行介绍,同时讨论用户的行为对推荐技术的影响、推荐技术的前沿发展方向。
2.课程目标
- 基础知识学习:掌握推荐系统基础知识
- 学术素养培养:探索推荐系统前沿方向研究
- 动手能力提高:实现并改进推荐算法
3.教材与参考资料




一、推荐系统概述
1.推荐系统概念
- 互联网规模和覆盖面的迅速增长带来了信息超载 (information overload) 问题:过量信息同时呈现使得用户无法从中获取对自己有用的部分,信息使用效率反而降低。
- 现有的很多网络应用,如门户网站、搜索引擎和专业数据索引本质上都是帮助用户过滤信息的手段。然而这些工具只满足主流需求,没有个性化的考虑,仍然无法很好地解决信息超载的问题。
- 推荐系统的主要功能是以个性化的方式帮助用户从极大的搜索空间中快速找到感兴趣的对象。给定用户的信息(包括评分/偏好/个人信息/上下文等)和项目信息,找到相关得分,然后为用户推荐那些相关的项目。
推荐物品叫item
搜索引擎不能缺的是关键词。用户得到的查询结果的好坏,取决于查询词query。
- 在如今互联网信息过载的情况下,信息消费者想方便地找到自己感兴趣的内容,信息生产者则想将自己的内容推送给最合适的目标用户。推荐系统正充当了这两者的中介。
- 推荐系统(recommender system)作为一种信息过滤的重要手段,是解决信息超载问题的非常有潜力的方法。
- 更为广义的定义:以一种个性化方法引导用户在大量潜在候选项中找到感兴趣或有用的物品,或者产生这些物品作为输出结果的系统。

(1)推荐系统与传统搜索引擎的区别
- 对于搜索引擎来说,用户在搜索信息时,需要在搜索引擎中输入“查询关键词”,搜索引擎根据用户的输入,在系统后台进行信息匹配,将与用户查询相关的信息展示给用户。但是,若用户无法想到准确描述自己需求的关键词,搜索引擎就变得无能为力。
- 推荐系统不需要用户提供明确的需求,而是通过分析用户的历史行为来对用户的兴趣进行建模,从而主动给用户推荐可能满足他们兴趣和需求的信息。
- 搜索引擎和推荐系统对用户来说是两个互补的工具。

推荐系统与以搜索引擎为代表的信息检索(information retrieval)系统的区别:

(2)推荐系统的历史
- 推荐系统这个概念是1995年在美国人工智能大会(AAAI) 上提出的。当时CMU大学 (卡内基梅隆大学 Carnegie Mellon University) 的教授Robert Armstrong提出了这个概念,并推出了推荐系统的原型系统—— Web Watcher。在同一个会议上,美国斯坦福大学的Marko Balabanovic等人推出了个性化推荐系统 LIRA1。
- 1996年, Yahoo网站推出了个性化入口MyYahoo,可以看作第一个正式商用的推荐系统。
- 21世纪以来,推荐系统的研究与应用随着电子商务的快速发展而异军突起,各大电子商务网站都部署了推荐系统,其中Amazon网站的推荐系统比较著名。据报道,Amazon网站中35%的营业额来自于自身的推荐系统。
- 2006年,美国的DVD租赁公司Netflix在网上公开设立了一个推荐算法竞赛——Netflix Prize。 Netflix公开了真实网站中的一部分数据,包含用户对电影的评分。Netflix竞赛有效地推动了学术界和产业界对推荐算法的研究,期间提出了很多有效的算法。
- 随后几年,随着社会化网络的发展,推荐系统在工业界广泛应用并且取得了显著进步。比较著名的推荐系统应用有:Amazon和淘宝网的电子商务推荐系统、Netflix和MovieLens的电影推荐系统、Youtube的视频推荐系统、豆瓣和Last.fm的音乐推荐系统、Google的新闻推荐系统以及Facebook和Twitter的好友推荐系统。


- 从1999年开始,美国计算机学会每年召开电子商务研讨会 (ACM Conference on Electronic Commerce,ACM EC),越来越多的与推荐系统相关的论文发表在ACM EC上。
- ACM信息检索顶级会议 (ACM Special Interest Group of Information Retrieval,ACM SIGIR) 在2001年开始把推荐系统作为该会议的一个独立研究主题。同年召开的国际人工智能联合大会(The 17th International Joint Conference on Artificial Intelligence,IJCAI)也将推荐系统作为一
个单独的主题。 - 最近的10年间,学术界对推荐系统越来越重视。目前为止,数据库、数据挖掘、人工智能、机器学习方面的重要国际会议(如SIGMOD、VLDB、ICDE、KDD、AAAI、SIGIR、ICDM、WWW、ICML等)都有大量与推荐系统相关的研究成果发表。同时,第一个以推荐系统命名的国际会议ACM Recommender Systems Conference(ACM RecSys)于2007年首次举办。
- 在数据挖掘及知识发现国际会议(KDD)举办的KDD CUP竞赛中,也出现和用户行为分析及
推荐相关的主题。

2.推荐算法简介


(1)算法概述
- 推荐有3个组成要素:推荐候选对象(Item)、用户(User)、推荐算法。
- 用户可以向推荐系统主动提供个人偏好信息或推荐请求,或者用户不提供,由推荐系统主动采集。
- 推荐系统可以使用不同的推荐策略进行推荐,如将采集到的个性化信息和对象数据进行计算得到推荐结果,或者直接基于已建模的知识数据库进行推荐。
Paradigms of recommender systems
①Knowledge‐based:我买了自行车,要推荐我买头盔
②Social‐based:与我最相似的用户,称为“好友”。推荐我好友的行为
③Context‐aware:基于上下文
④Personality‐based:用户个性

(2)经典推荐算法
- 基于人口统计学的推荐
- 协同过滤推荐
- 基于内容的推荐
- 基于关联规则的推荐
- 基于效用的推荐
- 基于知识的推荐
- 混合推荐:不同的模型按照效果进行加权
①基于人口统计学的推荐
根据用户属性,推荐最相似的用户所喜欢的东西
没有新用户冷启动问题
最简单,只需要计算用户之间的相似度即可,再推荐完全相同的东西。
类似的还有,最流行推荐

②协同过滤推荐 CF
1.基于评分数据
2.思想:两个用户对某些项目的评分很相似,则认为这两个用户很相似。
3.分类:
(1)基于邻域 (memory based)
举例:甲喜欢ABC D,乙喜欢ABC E,则两者很相似,可以将D推荐给乙,将E推荐给甲
(2)基于模型 (model based)
4.协同过滤算法的缺点:
无法解决新用户、新物品的冷启动问题。没有任何特征信息,无法进行推荐。




皮尔逊相关系数:计算用户相似度
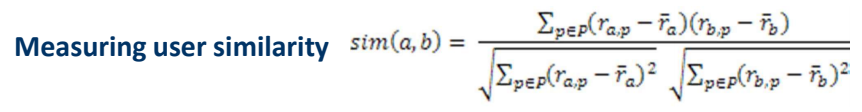
③基于内容的推荐
基于内容的推荐 (Content-based recommendation)

TF-IDF算法







VSM
VSM,vector space model
④基于关联规则的推荐
3.推荐系统的评价
4.推荐系统研究发展的热点方向:用户行为的影响
二、推荐系统概述
1.推荐系统概念
2.经典算法
3.评价
4.用户行为的影响
三、推荐系统前沿研究介绍
1.推荐系统与深度学习
2.推荐系统与信息检索
3.推荐系统与知识图谱结合
四、前沿论文分享与作业讨论
1.论文
1.CIKM_2024_MuLe Multi-Grained Graph Learning for Multi-Behavior Recommendation.pdf
2.评估
(1)NDCG@K
NDCG@K(Normalized Discounted Cumulative Gain at rank K)是一种常用于评估搜索引擎、推荐系统等排序模型效果的指标。它既考虑了文档的相关性,也考虑了其在排序列表中的位置,反映出模型将最相关的结果放在前面的能力。
(2)Recall@K
召回率(Recall@K):表示推荐系统在 K 个推荐列表中能否召回用户真正想要的商品。
3.推荐系统基础
(1)协同过滤
- 推荐系统中的一项基础任务。
- 基本思想:根据用户之前的喜好以及其他兴趣相近的用户的选择来给用户推荐物品。
- 但由于数据稀疏性等原因,传统方法如矩阵分解(Matrix Factorization)性能受限。
(2)图卷积网络 GCN
1.概念
图卷积网络 (Graph Convolutional Network,GCN)
- GCN的优势:通过高阶邻域信号增强数据表示,缓解稀疏性问题。
- 近期的研究表明GCN的有效性源于基于谱分析的图过滤 (Spectral Graph Filtering),即强调低频信号(用户-物品相似性)。
2.现有方法的局限性
(1)现有GCN方法的两类设计矛盾:
- 基于监督训练的图滤波(如LGCN):依赖训练优化低秩映射。
- 无监督图滤波(如SGF):直接过滤噪声频率。
(2)会导致的问题:两类方法在不同数据密度下表现不一致,且线性GCN(LGCN)的表达能力受限。
(3)泛化性不足
(4)LGCN 的理论局限性
3.改进
(1)泛化性改进:广义图归一化(G²N)
(2)表达能力改进:个性化图滤波器(IGF)
(3)用于协同过滤的简化图滤波方法(SGFCF)
SGFCF通过广义图归一化和个性化滤波,解决了图滤波在推荐系统中的通用性和表达能力问题。
实验表明,其在密集和稀疏数据上均优于现有方法,且计算效率显著提升。这一工作为谱图理论在推荐系统中的应用提供了新思路,尤其在处理数据稀疏性方面具有实际意义。
(3)LightGCN
LightGCN,轻量级图卷积网络
这种模型最早在推荐系统领域被提出,用于简化传统图卷积网络的结构,去除了非线性激活、特征变换等部分,从而达到更高效且有效的建模效果。
邻接矩阵
A = ( o R R T o ) A=\left(\begin{array}{cc} o & R\\ R^T & o \end{array}\right) A=(oRTRo)
R、RT:用户对物品、物品对用户
神经网络的可解释性不如贝叶斯
(4)BPR 贝叶斯个性化排序
BPR指的是贝叶斯个性化排序(Bayesian Personalized Ranking)算法。这是一种专门针对隐式反馈数据(如点击、浏览、购买等)设计的排序优化方法。
核心思想:BPR将推荐问题转化为一个排序问题。对于任一用户来说,如果某个物品曾与用户产生过交互(正反馈),而另一个物品未产生过交互(视为负反馈),则期望模型能够预测出正反馈物品的评分高于负反馈物品。
对比学习:BPR通过构造用户的正负样本对,利用对比损失函数来优化模型参数。
贝叶斯框架:在贝叶斯的思想指导下,BPR构造了一个后验概率模型,并通过最大化这个后验概率来求解模型参数,通常采用随机梯度下降(SGD)等优化方法进行迭代更新。
五、2025 RecSys 比赛
1.官网
2025RecSys比赛官网:https://www.codabench.org/competitions/7230/#/participate-tab
2.步骤
0.租卡:AutoDL
https://www.autodl.com/console/instance/list?tag_id=&random=1749399154870
1.下载RecSys代码
https://github.com/Synerise/recsys2025
2.在根目录创建一个名字为embedding的文件夹
mkdir embedding
3.下载数据集,文件夹名字为ubc_data,放在根目录
mkdir ubc_data
下载数据集到该目录下
tar -xzvf ubc_data.tar.gz
pip install -r .\requirements.txt

4.运行数据划分的代码:
python -m data_utils.split_data --challenge-data-dir ../ubc_data
5.运行baseline目录下的代码,生成embedding:
python -m baseline.aggregated_features_baseline.create_embeddings --data-dir ../ubc_data --embeddings-dir ../embeddings
6.运行训练代码(CPU版本)
python -m training_pipeline.train --data-dir ./ubc_data --embeddings-dir ./embeddings --tasks churn propensity_category propensity_sku --log-name initial_test --accelerator auto --devices 0 --disable-relevant-clients-check

训练代码那块儿,如果用的是GPU,那直接可以用README里的指令
7.create_embeddings.py里生成embedding的代码,目前用的是特征聚合的方式
def create_embeddings(data_dir: DataDir,num_days: List[int],top_n: int,relevant_client_ids: np.ndarray,
) -> Tuple[np.ndarray, np.ndarray]:"""Generate and merge user representation embeddings for specified event types.This function processes event data from CSV files, aggregates user's events basedon specified columns for each event type, and merges these embeddings into a singleuser representation.Args:data_dir (DataDir): The DataDir class where Paths to raw event data, input and targte folders are stored.num_days (List[int]): A list of time windows (in days) for generating features.Each time window will produce different set of features from aggregated eventsfrom defined period.top_n (int): Number of columns' top values to consider for aggregating events.Returns:Tuple[np.ndarray, np.ndarray] : generated feature matrix and the list of allclients in two np.ndarray's."""aggregator = FeaturesAggregator(num_days=num_days,top_n=top_n,relevant_client_ids=relevant_client_ids,)for event_type in EVENT_TYPE_TO_COLUMNS.keys():logger.info("Generating features for %s event type", event_type.value)logger.info("Loading data...")event_df = load_with_properties(data_dir=data_dir, event_type=event_type.value)event_df["timestamp"] = pd.to_datetime(event_df.timestamp)logger.info("Generating features...")aggregator.generate_features(event_type=event_type,client_id_column="client_id",df=event_df,columns=EVENT_TYPE_TO_COLUMNS[event_type],)logger.info("Merging features into embeddings")client_ids, embeddings = aggregator.merge_features()return client_ids, embeddings
3.结果
规则

baseline


228M


58M

两个表格其实对应同一模型在六个子任务(包括三个可见任务和三个隐藏任务)上的 AUC(或者类似的越大越好的评分):

两个提交的得分分别是:

- 图一 在 4/6 个子任务上得分更高(churn、hidden1、hidden2、hidden3)。
- 图二 只在两个可见的“propensity”任务上略胜一筹。
如果你的目标是追求对 所有 任务(尤其是隐藏任务)的 均衡泛化能力,那么图一的结果更好;
如果你只关心那两个“propensity”任务的成绩,图二会略优。但在真实比赛中,主办方会用 Borda count(按每个任务上的排名来打分)来决定最终名次,通常更看重在隐藏任务上的稳定表现——因此图一的提交几乎肯定会排得更靠前。