YOLOv13发布 | 超图高阶建模+轻量化模块,保证实时性的情况下,检测精度再创新高!

YOLOv13: Real-Time Object Detection with Hypergraph-Enhanced Adaptive Visual Perception
摘要
YOLO系列模型在实时目标检测领域占据主导地位,这得益于其卓越的准确性和计算效率。然而,YOLO11及早期版本中的卷积架构,以及YOLOv12中引入的区域性自注意力机制,均局限于局部信息聚合和成对相关性建模,缺乏捕捉全局多对多高阶相关性的能力,这限制了复杂场景下的检测性能。在本文中,作者提出了YOLOv13,一种准确且轻量级的目标检测器。
为应对上述挑战,作者提出了基于超图的自适应相关性增强(HyperACE)机制,该机制能够自适应地利用潜在的高阶相关性,克服了以往方法仅限于基于超图计算的成对相关性建模的局限性,实现了高效的跨位置和跨尺度的特征融合与增强。随后,作者基于HyperACE提出了全流程聚合与分发(FullPAD)范式,通过将相关性增强特征分发至整个流程,有效实现了网络内的细粒度信息流与表征协同。最后,作者提出利用深度可分离卷积替代普通的宽卷积,并设计了一系列模块,在牺牲性能的前提下显著降低了参数量和计算复杂度。
在广泛使用的MS COCO基准数据集上进行了大量实验,实验结果表明,YOLOv13在更少的参数量和FLOPs下实现了最先进的性能。具体而言,YOLOv13-N相较于YOLO11-N提升了3.0%的mAP,相较于YOLOv12-N提升了1.5%。
1 引言
实时目标检测长期以来一直是计算机视觉研究的前沿领域,旨在以最小的延迟定位和分类图像中的目标,这对工业异常检测、自动驾驶和视频监控等广泛应用至关重要。近年来,单阶段CNN检测器在这一领域占据主导地位,将区域 Proposal 、分类和回归集成到一个统一的端到端框架中。其中,YOLO(You Only Look Once)系列因其推理速度和准确性的出色平衡而成为主流。
从早期的YOLO版本到最近的YOLO11模型,以卷积为核心的架构被采用,旨在通过不同设计的卷积层提取图像特征并实现目标检测。最新的YOLOv12进一步利用基于区域的自注意力机制来增强模型的表征能力:
-
一方面,卷积操作在固定感受野内进行局部信息聚合,因此建模能力受限于卷积核大小和网络深度。
-
•另一方面,尽管自注意力机制扩展了感受野,但其高计算成本需要以基于局部区域的计算作为权衡,从而阻碍了充分的全局感知和建模。
此外,自注意力机制可以被视为在完全连接的语义图上对成对像素相关性的建模,这本质上限制了其仅捕捉二元相关性的能力,并阻止其表征和聚合多对多的高阶相关性。因此,现有YOLO模型的结构限制了其建模全局高阶语义相关性的能力,导致在复杂场景中存在性能 瓶颈。超图可以建模多对多的高阶相关性。与传统图不同,超图中的每条超边连接多个顶点,从而能够建模多个顶点之间的相关性。一些研究[19]-[21]已经证明了使用超图来建模视觉任务(包括目标检测)中多像素高阶相关性的必要性和有效性。然而,现有方法仅使用手动设置的阈值参数值,根据像素特征距离来确定像素是否相关,即特征距离低于特定阈值的像素被视为相关。这种手动建模范式难以应对复杂场景,导致额外的冗余建模,从而限制了检测精度和鲁棒性。
为解决上述挑战,作者提出YOLOv13,一种新型实时突破性端到端目标检测器。作者提出的YOLOv13模型将传统的基于区域的成对交互建模扩展为全局高阶相关建模,使网络能够感知跨空间位置和尺度的深层语义相关性,从而显著提升复杂场景下的检测性能。具体而言,为克服现有方法中手工超边构建导致的鲁棒性和泛化能力限制,作者提出了一种基于超图的自适应相关增强机制,命名为HyperACE。HyperACE将多尺度特征图中的像素作为顶点,并采用可学习的超边构建模块自适应地探索顶点之间的高阶相关性。然后,利用具有线性复杂度的消息传递模块,在高层相关性的指导下有效聚合多尺度特征,以实现复杂场景的有效视觉感知。
此外,HyperACE还集成了低阶相关建模,以实现完整的视觉感知。基于HyperACE,作者提出了一种包含全流程聚合与分配范式的YOLO架构,命名为FullPAD。作者提出的FullPAD使用HyperACE机制聚合 Backbone提取的多级特征,然后将相关增强特征分配到 Backbone 、 Neck 和检测Head,以实现全流程的细粒度信息流和表示协同,显著改善梯度传播并提升检测性能。最后,为在不牺牲性能的情况下减小模型尺寸和计算成本,作者提出了一系列基于深度可分离卷积的轻量级特征提取块。通过用深度可分离卷积块替换大核常规卷积块,可以实现更快的推理速度和更小的模型尺寸,从而在效率和性能之间取得更好的平衡。

为验证YOLOv13的有效性和效率,在广泛使用的MS COCO上进行了大量实验。定性和定量的实验结果表明,YOLOv13在保持轻量级的同时优于所有先前的YOLO模型及其变体。特别是,YOLOv13-N/S与YOLOv12-N/S和YOLO11-N/S相比,mAP分别提升了1.5%/0.9%和3.0%/2.2%。消融实验进一步证明了每个提出模块的有效性。
作者的贡献总结如下:
-
作者提出了YOLOv13,一种更优越的实时端到端目标检测器。YOLOv13模型使用自适应超图来探索潜在的高阶相关性,并在高阶相关性的指导下,通过有效的信息聚合和分布实现精确和鲁棒的目标检测。
-
作者提出了HyperACE机制,基于自适应超图计算来捕获复杂场景中的潜在高阶相关性,并基于相关性引导实现特征增强。
-
作者提出了一种FullPAD范式,以在整个流程中实现多尺度特征聚合与分布,从而增强信息流和表征协同。
-
作者提出了一系列基于深度可分离卷积的轻量级模块,用以替代大核数的普通卷积模块,显著减少了参数数量和计算复杂度。
-
作者在MS COCO基准数据集上进行了广泛的实验。实验结果表明,YOLOv13在保持轻量化的同时,实现了最先进的检测性能。
2 相关工作
2.1 YOLO检测器的发展
自从CNN问世以来,实时目标检测技术已从以R-CNN系列为代表的分阶段流程迅速发展为以YOLO为代表的优化单阶段框架。原始YOLO首次将检测问题重新定义为单次回归问题,消除了候选框生成开销,并实现了出色的速度-精度权衡。后续的YOLO迭代版本不断优化架构和训练策略。YOLOv2通过引入基于 Anchor 框的预测和DarkNet-19 Backbone提升了精度。YOLOv3通过采用DarkNet-53和三尺度预测增强了小目标检测能力。YOLOv4至YOLOv8逐步集成了CSP、SPP、PANet、多模态支持和 Anchor-Free 框头等模块,进一步平衡了吞吐量和精度。YOLOv9和YOLOv10则专注于轻量级 Backbone和端到端部署的简化。
随后,YOLO11保留了" Backbone - Neck - Head "的模块化设计,但用更高效的C3k2单元替换了原始的C2f模块,并添加了具有部分空间注意力的卷积块(C2PSA)以增强对小型和遮挡目标的检测。最新的YOLOv12标志着注意力机制的全面集成,引入了残差高效层聚合网络(R-ELAN)结合轻量级区域注意力(A2)和闪存注意力机制,以优化内存访问,从而在保持实时性能的同时,实现高效的全局和局部语义建模,并提升鲁棒性和精度。
与此同时,一些基于YOLO的变体已经出现。YOLOR融合了显式和隐式特征以获得更丰富的表示和更强的泛化能力。YOLOX采用 Anchor-Free 头和动态标签分配来简化流程并提高小目标检测性能。YOLO-NAS利用AutoNAC进行神经架构搜索,使用Quant-Aware RepVGG和混合精度量化来优化吞吐量和小目标性能。Gold-YOLO引入了GD机制以增强多尺度特征融合能力。YOLOMS引入了带有集成全局 Query 学习的MS-Block,以及渐进式异构核大小选择策略,以最小的开销丰富多尺度表示。
然而,如前所述,当前YOLO系列模型的架构仅限于建模局部成对相关性,无法建模全局多对多高阶相关性。这限制了现有方法在复杂场景中的检测性能。
2.2 高阶相关建模
自然界中普遍存在复杂的多元高阶相关性,例如神经连接和蛋白质相互作用,以及在信息科学领域,例如社交网络[31][32]。在视觉数据中,不同物体通过空间、时间和语义交互形成复杂的相关性。这些相关性可能是成对(低阶)的,也可能是更复杂基于组的(高阶)相关性。超图作为普通图的扩展,不仅可以表示成对相关性,还可以表示多元高阶相关性[33][34]。近年来,超图神经网络(HGNNs)已成为建模此类高阶相关性的主要工具[35]-[38]。Feng等人[39]提出了频域HGNNs,在视觉检索任务中展示了其优势。Gao等人[40]进一步提出了带有空间超图卷积算子的HGNN+,增强了HGNN的适用性。最近,Feng等人[38]开创性地将HGNN集成到检测模型中,证明了高阶相关性建模对于检测的必要性。然而,该方法仅使用手工制作的固定参数作为阈值,将特征距离小于阈值的像素判定为相关,导致相关性建模精度和鲁棒性不足。
为解决上述挑战,作者提出一种基于超图的自适应相关增强机制,该机制通过自适应利用潜在相关性,高效地建模跨位置和跨尺度的语义交互。该机制克服了现有超图计算范式因手工超参数设置而导致的鲁棒性不足问题,以及现有YOLO系列模型中缺乏全局高阶相关建模的问题。
3 YOLOv13算法
在本节中介绍了YOLOv13方法。在III-A节中,作者介绍了所提出模型的整体网络架构。然后,在III-B节和III-C节中,分别介绍了所提出的基于超图的自适应相关增强机制以及全流程聚合-分配范式的详细理念与结构。最后,在III-D节中,作者介绍了所提出的轻量级特征提取模块的架构。
3.1整体架构
之前的YOLO系列遵循"Backbone Neck Head"计算范式,这本质上限制了信息的有效传递。相比之下,YOLOv13通过基于超图的自适应相关增强(HyperACE)机制,在传统YOLO架构中实现了全流程特征聚合与分配(FullPAD),从而提升了模型性能。因此,YOLOv13在整个网络中实现了细粒度信息流与表征协同,能够改善梯度传播并显著提升检测性能。

具体而言,如图2所示,YOLOv13模型首先使用与先前工作类似的 Backbone提取多尺度特征图,但将大卷积核替换为提出的轻量级DS-C3k2模块。不同于传统YOLO方法直接将输入到 Backbone,YOLOv13将这些特征汇聚并传递至HyperACE模块,实现跨尺度跨位置特征高阶相关自适应建模与特征增强。随后,FullPAD范式通过三个独立通道将相关性增强后的特征分别分配至 Backbone与 Neck 的连接、 Neck 内部层以及 Neck 与 Head 之间的连接,以优化信息流。最终, Neck 的输出特征图被传递至检测Head,实现多尺度目标检测。
3.2 基于超图的自适应相关性增强机制 (HyperACE)
YOLOv13的最核心创新,旨在有效捕捉特征间潜在的高阶关联。

-
基本原理:该机制借鉴了超图(Hypergraph)的理论。与普通图中一条边只能连接两个顶点不同,超图中的一条“超边”(Hyperedge)可以同时连接多个顶点,这使其天然适合建模“多对多”的关系。
-
自适应超边生成:为克服传统超图方法依赖手工设定参数的不足,HyperACE设计了一个可学习的超边生成模块。该模块能根据输入的视觉特征,自适应地学习并构建超边,动态地探索不同特征顶点之间的潜在关联。
-
超图卷积:在生成自适应超边后,通过超图卷积操作进行特征聚合与增强。每条超边先从其连接的所有顶点处聚合信息,形成高阶特征;随后,这些高阶特征再被传播回各个顶点,从而完成对顶点特征的更新与增强。
3.3 全流程聚合与分发范式 (FullPAD)
为了最大化HyperACE增强后特征的效用,作者设计了FullPAD这一新的网络信息流范式。
-
工作流程:FullPAD首先从骨干网络中汇集多尺度特征,并将其送入HyperACE模块进行处理。随后,通过专门的“FullPAD通道”,将这些经过高阶关联增强的特征重新分发至网络的多个关键位置,包括骨干网与颈部的连接处、颈部网络内部、以及颈部与检测头的连接处。
-
设计目的:这种设计旨在打破传统YOLO架构中单向的信息流,实现全网络范围内的信息协同与精细化流动,从而改善梯度传播并提升最终的检测性能。
3.4 深度可分离卷积轻量化设计
为保证模型的高效率,YOLOv13采用深度可分离卷积(Depthwise Separable Convolution, DSConv)作为基础单元,设计了一系列轻量化模块(如DSConv, DS-Bottleneck, DS-C3k, DS-C3k2),用于替代标准的大核卷积。这些模块被广泛应用于模型的骨干和颈部网络中,在基本不牺牲模型性能的前提下,显著降低了参数量和计算复杂度(FLOPs)。

4 实验
为验证YOLOv13模型的有效性和效率,作者进行了广泛的实验。在第四节A中,介绍了详细的实验设置。然后,在第四节B中,将YOLOv13与其他现有的实时目标检测方法进行比较,以证明YOLOv13的有效性。最后,在第四节C中,进行了消融实验,以证明每个提出模块的有效性。
4.1 实验设置
4.1.1 数据集
作者使用MS COCO数据集,这是目标检测任务中最广泛采用的基准数据集,用于评估YOLOv13模型以及其他最先进的实时检测器。MS COCO数据集的训练集(Train2017)包含约118,000张图像,验证集(Val2017)包含约5,000张图像,涵盖了自然场景中的80个常见物体类别。在作者的实现中,所有方法均在Train2017子集上进行训练,并在Val2017子集上进行测试。
随着YOLO系列的不断发展,具有更强泛化能力的通用模型变得越来越重要。为此,作者在评估中包含了跨领域泛化,并将其纳入分布偏移的范畴。作为补充基准,作者选择了Pascal VOC 2007数据集,该数据集的训练集和验证集共计5,011张图像,测试集包含4,952张图像,涵盖20个常见物体类别。为评估跨领域泛化能力,所有方法均使用在MS COCO数据集上训练的模型,直接在Pascal VOC 2007测试集上进行评估。
4.1.2 实现细节
与之前的YOLO模型类似,YOLOv13系列包含四个变体:Nano(N)、Small(S)、Large(L)和Extra-Large(X)。对于N、S、L和X模型,超边数分别设置为4、8、8和12。对于所有变体,作者使用256的批处理大小训练模型600个epoch。初始学习率为0.01,并使用SGD作为优化器,这与YOLO11和YOLOv12模型保持一致。作者采用线性衰减调度器,并在前3个epoch内应用线性预热。训练过程中,输入图像大小设置为。作者采用与之前YOLO版本相同的数据增强技术,包括Mosaic和Mixup。作者分别使用4和8块RTX 4090 GPU训练YOLOv13-N和YOLOv13-S,并分别使用4和8块A800 GPU训练YOLOv13-L和YOLOv13-X。此外,遵循之前YOLO系列的标准化做法,作者使用TensorRT FP16在单个Tesla T4 GPU上评估所有模型的延迟。此外,需要注意的是,为确保公平和严格的比较,作者使用官方设置在与作者YOLOv13模型相同的硬件平台上重新生成了之前YOLO11和YOLOv12(v1.0版本)的所有变体。
4.2 与其他方法的比较
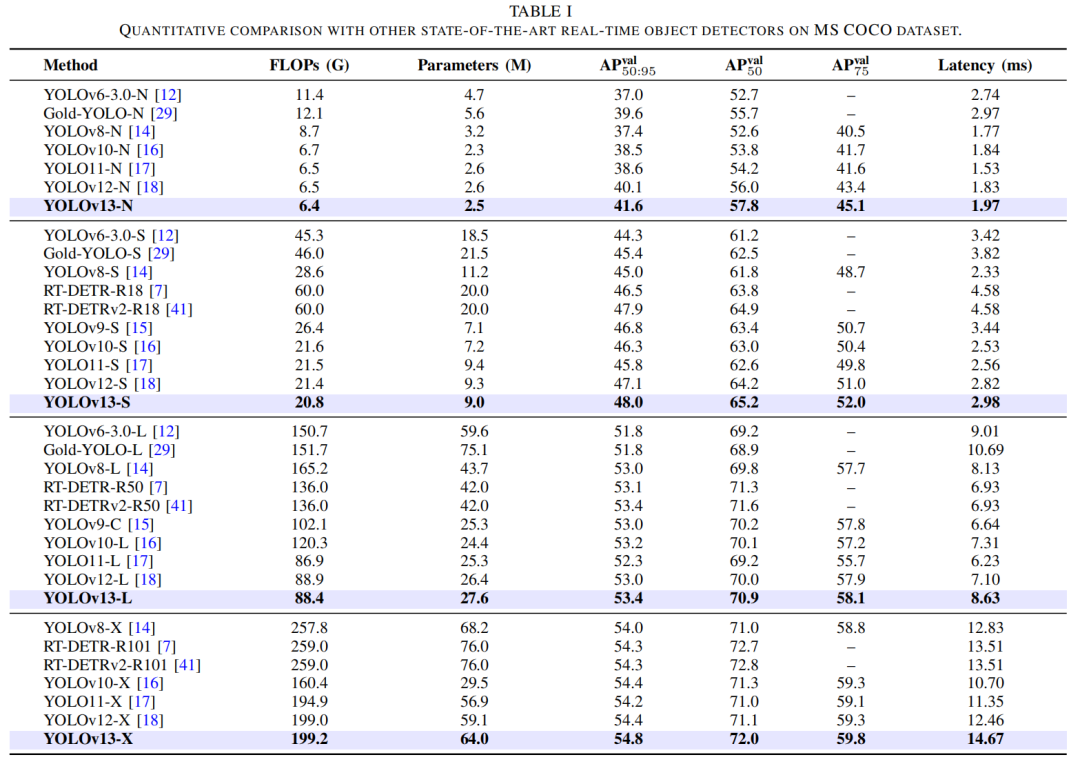
表1 展示了在 MS COCO 数据集上的定量比较结果。YOLOv13与之前的 YOLO 系列模型进行了比较。如前所述,作者的 YOLOv13 模型与 YOLO11 和 YOLOv12 模型使用相同的 GPU 进行训练,而现有方法使用其官方代码和训练参数进行训练。从表中可以看出,YOLOv13 模型的所有变体均实现了最先进的性能,同时保持了轻量化。
参考文献
[1]. YOLOv13: Real-Time Object Detection with Hypergraph-Enhanced Adaptive Visual Perception