1 Studying《Systems.Performance》7-13
目录
7 Memory
7.1 Terminology
7.2 Concepts
7.3 Architecture
7.4 Methodology
7.5 Analysis
7.6 Tuning
8 File Systems
8.1 Terminology
8.2 Models
8.3 Concepts
8.4 Architecture
8.5 Methodology
8.6 Analysis
8.7 Experimentation
8.8 Tuning
9 Disks
9.1 Terminology
9.2 Models
9.3 Concepts
9.4 Architecture
9.5 Methodology
9.6 Analysis
9.7 Experimentation
9.8 Tuning
10 Network
10.1 Terminology
10.2 Models
10.3 Concepts
10.4 Architecture
10.5 Methodology
10.6 Analysis
10.7 Experimentation
10.8 Tuning
11 Cloud Computing
11.1 Background
11.2 OS Virtualization
11.3 Hardware Virtualization
11.4 Comparisons
12 Benchmarking
12.1 Background
12.2 Benchmarking Types
12.3 Methodology
12.4 Benchmark Questions
13 Case Study
13.1 Case Study: The Red Whale
13.2 Comments
13.3 Additional Information
7 Memory
系统主内存存储应用程序和内核指令,它们的工作数据和文件系统缓存。在许多系统中,用于存储这些数据的辅助存储设备是主要存储设备-磁盘,其操作速度比主内存慢几个数量级。一旦主内存填满,系统可能开始在主内存和存储设备之间切换数据。这是一个缓慢的过程,通常会成为系统瓶颈,大大降低性能。系统还可能终止最大的内存消耗进程。
其他需要考虑的性能因素包括分配和释放内存的CPU开销、内存复制以及管理内存地址空间映射的开销。在多处理器架构中,内存局部性可能成为一个因素,因为连接到本地插槽的内存比远程插槽具有更低的访问延迟。
本章分为五个部分,前三个部分提供了内存分析的基础知识,后两个部分展示了其在基于Linux和Solaris的系统中的实际应用。各部分内容如下:
- 背景介绍了与内存相关的术语和关键的内存性能概念。
- 架构提供了硬件和软件内存架构的通用描述。
- 方法论解释了性能分析方法论。
- 分析描述了内存分析的性能工具。
- 调优解释了调优和示例可调参数。
关于CPU上的内存缓存(一级/二级/三级缓存,TLB)在第6章《CPU》中有介绍。
7.1 Terminology
在本章中使用的与内存相关的术语如下:
- 主内存:也称为物理内存,描述了计算机的快速数据存储区,通常以DRAM形式提供。
- 虚拟内存:主内存的抽象,(几乎)是无限的,且非争用的。虚拟内存并非真实的内存。
- 驻留内存:当前驻留在主内存中的内存。
- 匿名内存:没有文件系统位置或路径名的内存。它包括进程地址空间的工作数据,称为堆。
- 地址空间:内存上下文。每个进程和内核都有虚拟地址空间。
- 段:一个标记为特定目的的内存区域,例如用于存储可执行或可写入页面。
- OOM:内存耗尽,当内核检测到可用内存较少时发生。
- 页:操作系统和CPU使用的内存单元。在历史上,它通常是4或8 K字节。现代处理器支持多种页面大小,用于更大的尺寸。
- 缺页:无效的内存访问。这些在使用按需虚拟内存时是正常发生的。
- 分页:在主内存和存储设备之间转移页面。
- 交换:来自Unix,这是在主内存和交换设备之间传输整个进程。Linux通常使用交换来指代向交换设备(交换页面的传输)。在本书中,使用了原始的定义:交换是指整个进程的交换。
- 交换区:用于分页匿名数据和交换进程的磁盘区域。它可以是存储设备上的区域,也称为物理交换设备,或者是文件系统文件,称为交换文件。一些工具使用交换术语来指代虚拟内存(这是令人困惑和不正确的)。
本章还介绍了其他术语。词汇表中包含了基本的术语供参考,包括地址、缓冲区和DRAM。此外,还请参阅第2章和第3章的术语部分。
7.2 Concepts
以下是关于内存和内存性能的一些重要概念的精选。
7.2.1 Virtual Memory
虚拟内存是一种抽象概念,为每个进程和内核提供了一个大型、线性且私有的地址空间。它简化了软件开发,将物理内存的分配交给操作系统来管理。它还支持多任务处理,因为虚拟地址空间通过设计进行了分离,同时也支持超额订阅,因为正在使用的内存可以扩展到主内存之外。虚拟内存在第3章的操作系统中介绍过。有关历史背景,请参考[Denning 70]。
图7.1显示了对于一个带有交换设备(辅助存储)的系统的进程而言,虚拟内存的作用。一个内存页面被展示出来,因为大多数虚拟内存实现都是基于页面的。

进程的地址空间由虚拟内存子系统映射到主内存和物理交换设备。内存页面可以根据需要在它们之间由内核移动,这个过程称为分页。这使得内核可以超额订阅主内存。
内核可能对超额订阅设置限制。在基于Solaris的内核中,限制是主内存和物理交换设备的大小之和。内核将拒绝试图超过此限制的分配。这样的“虚拟内存耗尽”错误一开始可能会让人困惑,因为虚拟内存本身是一个抽象资源。
Linux可以配置为支持相同的行为,但它也允许其他行为,包括不对内存分配设置任何限制。这称为过度承诺,并且在以下关于分页和需求分页的部分之后进行描述,这些部分对于过度承诺的工作是必要的。
7.2.2 Paging
分页是指将页面在主内存之间移动,分别称为页面调入(page-ins)和页面调出(page-outs)。它最早由Atlas计算机于1962年引入[Corbató 68],使得:
- 部分加载的程序能够执行
- 大于主内存的程序能够执行
- 程序在主内存和存储设备之间进行高效移动
这些功能至今仍然存在。与交换整个程序不同,分页是一种细粒度的管理和释放主内存的方法,因为页面大小单位相对较小(例如,4 K字节)。
通过BSD引入了带有虚拟内存的分页(分页虚拟内存)到Unix[Babaoglu 79],并成为标准实践。
随着后来引入文件系统页面缓存用于共享文件系统页面(参见第8章,文件系统),出现了两种不同类型的分页:文件系统分页和匿名分页。
File System Paging
文件系统分页是由于对内存映射文件中的页面进行读写而引起的。对于使用文件内存映射(mmap())的应用程序以及使用页面缓存的文件系统(大多数文件系统都使用;请参阅第8章,文件系统)来说,这是正常行为。它曾被称为“良好”分页[McDougall 06b]。
在需要时,内核可以通过将一些页面调出来释放内存。在这里术语会有点复杂:如果一个文件系统页面在主内存中被修改过(“脏”),则页面调出将需要将其写入磁盘。相反,如果文件系统页面没有被修改过(“干净”),则页面调出仅释放内存以便立即重用,因为磁盘上已经存在一份副本。由于这个原因,术语“页面调出”意味着页面被移出内存——这可能涉及或不涉及向存储设备的写入(您可能会看到这个定义有所不同)。
Anonymous Paging
匿名分页涉及进程私有的数据:进程堆和栈。它被称为匿名,是因为在操作系统中没有具体的命名位置(即没有文件系统路径名称)。匿名页面调出需要将数据移动到物理交换设备或交换文件。Linux使用术语"swapping"来指代这种类型的分页。
匿名分页会影响性能,因此被称为"不良"分页[McDougall 06b]。当应用程序访问已经调出的内存页面时,它们会阻塞在磁盘I/O上,以便将页面读回主内存。这就是匿名页面调入,它给应用程序引入了同步延迟。匿名页面调出可能不会直接影响应用程序性能,因为它们可以由内核异步执行。
性能最好的情况是没有匿名分页(或交换)。这可以通过配置应用程序保持在可用主内存范围内,并监视页面扫描、内存利用率和匿名分页,以确保不再出现内存不足的迹象。
7.2.3 Demand Paging
支持需求分页的操作系统(大多数都支持)根据需要将虚拟内存页映射到物理内存,如图7.2所示。这样做推迟了创建映射的CPU开销,直到它们真正被需要和访问,而不是在内存范围首次分配时进行。

图7.2中显示的序列始于对新分配的虚拟内存页的写入,导致按需映射到物理内存。当虚拟内存到物理内存之间最初没有页面映射时,会发生页面错误。
在已映射文件的情况下,第一步也可以是读取,该文件包含数据但尚未映射到该进程地址空间。
如果映射可以从内存中的另一页满足,则称为次要错误。这可能发生在将新页从可用内存映射到过程中(如图所示)。它还可以发生在将另一页映射到另一页,例如从映射的共享库读取一页。
需要访问存储设备(本图未显示)的页面错误,例如访问非缓存的内存映射文件,称为主要错误。
虚拟内存模型和按需分配的结果是,任何虚拟内存页可能处于以下状态之一:
A. 未分配
B. 已分配,但未映射(未填充且尚未错误)
C. 已分配,并映射到主内存(RAM)
D. 已分配,并映射到物理交换设备(磁盘)
如果由于系统内存压力而将页面调出,则达到状态(D)。从(B)到(C)的转换是一个页面错误。如果需要进行磁盘I/O,则是一个主要页面错误;否则是一个次要页面错误。
从这些状态中,还可以定义两个内存使用术语:
居住集大小(RSS):已分配主内存页的大小(C)
虚拟内存大小:所有已分配区域的大小(B + C + D)
通过BSD,Unix引入了需求分页,以及分页虚拟内存。
7.2.4 Overcommit
Linux支持超额分配的概念,允许分配比系统实际存储的内存更多的内存,即超过物理内存和交换设备的总和。它依赖于按需分页和应用程序不使用其已分配内存的倾向。
有了超额分配,应用程序对内存的请求(例如malloc())将在本应失败时成功。应用程序员可以慷慨地分配内存,之后根据需要稀疏地使用,而不是保守地分配内存以保持在虚拟内存限制范围内。
在Linux上,超额分配的行为可以通过可调参数进行配置。有关详细信息,请参阅第7.6节“调整”。超额分配的后果取决于内核如何管理内存压力;请参阅第7.3节“体系结构”中对OOM killer的讨论。
7.2.5 Swapping
交换是将整个进程在主内存和物理交换设备或交换文件之间移动的过程。这是管理主内存的最初Unix技术,也是“交换”一词的起源(Thompson 78)。
要交换出一个进程,必须将其所有私有数据写入交换设备,包括线程结构和进程堆(匿名数据)。来自文件系统且未被修改的数据可以被丢弃,并在需要时重新从原始位置读取。
被交换出的进程仍然由内核知晓,因为一小部分进程元数据始终驻留在内核内存中。要将进程交换回来,内核会考虑线程优先级、在磁盘上等待的时间以及进程的大小。长时间等待和较小的进程会受到青睐。
交换严重影响性能,因为已被交换出的进程需要大量的磁盘I/O才能再次运行。在早期的Unix系统中,如PDP-11型号的机器,最大进程大小为64K字节时,这种做法更为合理(Bach 86)。
虽然基于Solaris的系统仍然可以进行交换,但只有在分页无法快速释放足够的内存以满足应用程序需求时才会这样做(因为分页受页面扫描速率的限制;请参阅第7.3节“体系结构”)。Linux系统根本不交换进程,而只依赖分页。
当人们说“系统正在交换”时,他们通常指的是分页。在Linux中,“交换”一词指的是分页到交换文件或设备(匿名分页)。
7.2.6 File System Cache Usage
系统启动后内存使用量增长是正常的,因为操作系统利用可用内存来缓存文件系统,从而提高性能。原则是:如果有多余的主内存,则将其用于某些有用的事情。这可能会让幼稚的用户感到困扰,因为他们在启动后不久就看到可用空闲内存几乎降至零。但对应用程序来说并不构成问题,因为内核应该能够在应用程序需要时快速从文件系统缓存中释放内存。
关于可能占用主内存的各种文件系统缓存的更多信息,请参阅第8章《文件系统》。
7.2.7 Utilization and Saturation
主内存利用率可以计算为已使用内存与总内存的比值。文件系统缓存使用的内存可以视为未使用,因为这部分内存可以被应用程序重新利用。
如果对内存的需求超过了主内存的容量,主内存就会饱和。操作系统可以通过使用分页、交换和在Linux上使用OOM killer(稍后描述)来释放内存。这些活动中的任何一项都是主内存饱和的指标。
如果系统对所愿意分配的虚拟内存量设定了限制(Linux的过度承诺除外),也可以根据容量利用率来研究虚拟内存。如果是这样,一旦虚拟内存耗尽,内核将无法进行分配;例如,malloc() 函数返回 ENOMEM。
需要注意的是,系统当前可用的虚拟内存有时会(令人困惑地)称为可用交换空间。
7.2.8 Allocators
虚拟内存处理物理内存的多任务处理,而在虚拟地址空间内的实际分配和放置通常由分配器处理。这些分配器可以是用户空间库或基于内核的例程,为软件程序员提供了一个简单的内存使用接口(例如malloc()、free())。
分配器对性能有显著影响,系统可能提供多个用户级分配器库供选择。它们可以通过使用诸如每线程对象缓存等技术来提高性能,但如果分配变得碎片化和浪费,它们也可能损害性能。具体示例在第7.3节“体系结构”中有详细介绍。
7.2.9 Word Size
正如第6章介绍的那样,CPU处理器可能支持多种字长,例如32位和64位,允许软件在其中任一种上运行。由于地址空间大小受到字长可寻址范围的限制,需要超过4GB(通常略少)的应用程序对于32位地址空间来说太大了,需要编译为64位或更高位。
根据CPU架构的不同,使用更大的位宽可能会提高内存性能。在数据类型具有未使用位的情况下,可能会浪费少量内存。
7.3 Architecture
这一节介绍了内存架构,包括硬件和软件,还有处理器和操作系统的具体内容。这些主题被总结为性能分析和调优的背景知识。更多细节请参阅本章末尾列出的供应商处理器手册和操作系统内部的相关文献。
7.3.1 Hardware
内存硬件包括主存储器、总线、CPU高速缓存和内存管理单元(MMU)。
主存储器
如今常用的主存储器类型是动态随机存取存储器(DRAM)。这是一种易失性存储器,即在断电时会丢失其内容。DRAM提供了高密度存储,因为每个位只需要使用两个逻辑组件来实现:一个电容器和一个晶体管。电容器需要定期刷新以保持电荷。
企业服务器根据其用途配置不同数量的DRAM,通常范围从1GB到1TB甚至更大。这些数量可能使得云计算实例的内存相形见绌,后者通常在512MB到64GB之间。然而,云计算旨在将负载分布到一组实例上,因此它们可以共同为分布式应用程序提供更多DRAM,尽管这会带来更高的一致性成本。
延迟
主存储器的访问时间可以通过列地址选通(CAS)延迟来衡量:发送所需地址(列)到内存模块并且数据可以被读取之间的时间。这取决于内存类型(对于DDR3大约为10纳秒)。对于内存I/O传输,该延迟可能会在内存总线(例如64位宽)多次发生,以传输一个缓存行(例如64字节宽)。还有其他与CPU和MMU相关的延迟,用于读取新可用的数据。
主存储器架构
图7.3展示了一个通用的双处理器统一存储访问(UMA)系统的示例主存储器架构。
每个CPU通过共享系统总线对所有存储器具有统一的访问延迟。当由单个操作系统内核实例管理,并且在所有处理器上均匀运行时,这也是一种对称多处理(SMP)架构。
作为比较,在图7.4中显示了一个双处理器非均匀存储访问(NUMA)系统的示例,该系统使用的CPU互连成为存储器架构的一部分。对于这种架构,主存储器的访问时间取决于其相对于CPU的位置。
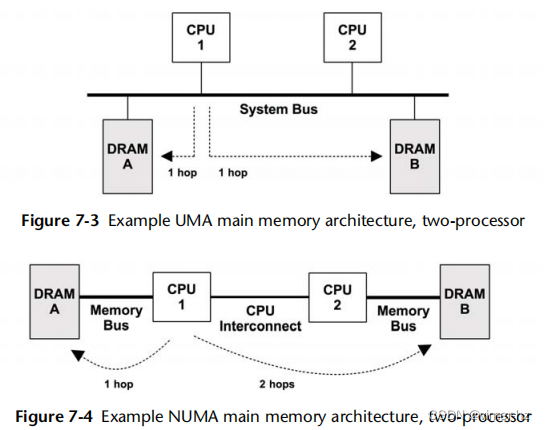
CPU 1可以通过其内存总线直接对DRAM A进行I/O。这被称为本地内存。CPU 1通过CPU 2和CPU互连(两次跳跃)对DRAM B执行I/O。这被称为远程内存,并具有更高的访问延迟。
连接到每个CPU的内存块被称为内存节点,或简称节点。操作系统可能根据处理器提供的信息意识到内存节点的拓扑结构,从而使其能够分配内存并根据内存局部性安排线程,尽可能偏向本地内存以提高性能。
总线
主存储器如何物理连接到系统取决于先前描绘的主存储器架构。实际实现可能涉及在CPU和存储器之间的额外控制器和总线,并以以下一种方式访问:
共享系统总线:单处理器或多处理器,通过共享系统总线、内存桥控制器,最终是内存总线。这在UMA示例图7.3中有所描述,并且在第6章CPU的图6.9中作为英特尔前端总线示例有所描述。该示例中的内存控制器是北桥。
直接:单处理器通过内存总线直接连接的内存。
互连:多处理器,每个处理器通过内存总线直接连接的内存,并且处理器通过CPU互连连接。这在前面作为NUMA示例的图7.4中有所描述;CPU互连在第6章CPU中有所讨论。
如果您怀疑您的系统不属于上述任何一种类型,请查找系统功能图并沿着CPU和内存之间的数据路径,注意沿途的所有组件。
DDR SDRAM
无论是哪种架构,内存总线的速度通常由处理器和系统主板支持的内存接口标准决定。自1996年以来,一种常见的标准是双倍数据速率同步动态随机存取存储器(DDR SDRAM)。双倍数据速率指的是数据在时钟信号的上升沿和下降沿上传输(也称为双倍泵送)。同步一词表示内存与CPU同步时钟。
表7.1显示了一些示例DDR SDRAM标准。
DDR4接口标准于2012年9月发布。这些标准通常以“PC-”开头,后面跟着以每秒兆字节为单位的数据传输速率的名称,例如PC-1600。
多通道
系统架构可能支持并行使用多个内存总线,以提高带宽。常见的倍数包括双通道、三通道和四通道。例如,英特尔Core i7处理器支持最多四通道DDR3-1600,最大内存带宽为51.2 G字节/秒。
CPU缓存
处理器通常包括片上硬件缓存,以提高内存访问性能。缓存可能包括下面逐渐降低速度和增加大小的级别:
第1级:通常分为独立的指令缓存和数据缓存
第2级:用于指令和数据的缓存
第3级:另一个更大的缓存级别
第1级通常由虚拟内存地址引用,而第2级及更高级别则由物理内存地址引用,具体取决于处理器。
这些缓存在第6章CPU中进一步讨论。本章还讨论了另一种类型的硬件缓存TLB。
MMU
内存管理单元负责虚拟地址到物理地址的转换。这些转换是按页执行的,页面内的偏移直接映射。MMU在第6章CPU中引入,与附近的CPU缓存相关。
图7.5显示了一个通用的MMU,包括CPU缓存和主存储器级别。
多种页面大小
现代处理器支持多种页面大小,允许操作系统和MMU使用不同的页面大小,例如4K字节、2M字节、1G字节。基于Solaris的内核支持多种页面大小以及动态创建更大页面大小,称之为多页面大小支持(MPSS)。
Linux具有一个名为huge pages的功能,它为特定的大页面大小(如2M字节)保留了一部分物理内存。提前保留大页面不如Solaris的动态分配方法灵活,但也避免了内存碎片化问题,使得无法动态分配更大的页面。
TLB
图7.5中的MMU使用TLB作为第一级地址转换缓存,然后是主存储器中的页表。TLB可以分成分别用于指令和数据页面的独立缓存。
由于TLB对映射的条目数有限,使用较大的页面大小扩大了可以从其缓存中进行转换的内存范围(其覆盖范围),从而减少了TLB未命中,并改善了系统性能。TLB还可以进一步分成每种页面大小的独立缓存,提高了在缓存中保留较大映射的概率。
以TLB大小为例,典型的Intel Core i7处理器提供了表7.2所示的四个TLB [Intel 12]。
这个处理器具有一个数据TLB级别。英特尔Core微体系结构支持两个级别,就像CPU提供多个主存储器缓存级别一样。
TLB的具体组成取决于处理器类型。请参考供应商的处理器手册,了解您的处理器中的TLB详细信息以及它们的运行方式。
7.3.2 Software
内存管理软件包括虚拟内存系统、地址转换、交换、分页和分配。本节包括与性能相关性最高的主题:释放内存、空闲列表、页面扫描、交换、进程地址空间和内存分配器。
释放内存
当系统上可用内存变得不足时,内核可以使用各种方法来释放内存,并将其添加到空闲页面列表中。
这些方法如图7.6所示,按照可用内存减少的一般顺序使用。

这些方法包括:
- 空闲列表:未使用的页面列表(也称为空闲内存),可立即分配。通常实现为多个空闲页面列表,每个用于一个局部群组(NUMA)。
- Reaping(收割):当低内存阈值被越过时,内核模块和内核slab分配器可以被指示立即释放任何可以轻松释放的内存。这也被称为收缩。
在Linux上,具体方法包括:
- 页面缓存:文件系统缓存。一个名为swappiness的可调参数设置了偏向从页面缓存中释放内存而非交换的程度。
- 交换:这是由页面输出守护进程kswapd进行的分页,它会找到最近未被使用的页面并将其添加到空闲列表中,包括应用程序内存。它们被分页出去,可能涉及写入基于文件系统的交换文件或交换设备。只有在配置了交换文件或设备时才可用。
- OOM killer:内存耗尽终结者将通过查找并终止一个牺牲进程来释放内存,该进程是通过select_bad_process()找到的,然后通过调用oom_kill_process()进行终止。这可能会记录在系统日志(/var/log/messages)中作为“内存不足:终止进程”消息。
在特定的基于Solaris系统上,方法包括:
- 循环页面缓存:这包含一个有效但当前未引用的文件系统页面列表,称为cachelist,根据需要可以将其添加到空闲列表中。这避免了页面扫描的开销。
- ZFS ARC:ZFS文件系统将检测到系统可能很快开始进行页面扫描,并将使用arc_kmem_reap_now()执行自己的收割以释放内存。
- 分页:由页面输出守护程序(也称为页面扫描器)执行,找到最近未被使用的页面并将其添加到空闲列表中,包括应用程序内存。它们被分页出去,可能涉及写入文件系统或交换设备。
- 交换:仍然存在于基于Solaris系统上,它将整个进程移动到交换设备,并是处理主内存压力的原始Unix方法。
- 硬交换:卸载未激活的内核模块,并顺序地将进程交换到交换设备。
这些系统之间的比较很有趣。在基于Solaris系统上,文件系统缓存在分页发生时应为空。Linux提供了一种平衡这种行为的方式:swappiness,一个介于0和100之间的参数(默认值为60),更高的值偏向通过分页应用程序释放内存,而较低的值则通过从页面缓存中回收内存(类似于基于Solaris系统的行为)。这允许通过保留热文件系统缓存而分页出冷应用程序内存来改善系统吞吐量。
如果两个系统上都没有配置交换设备或交换文件,这也很有趣。这将限制虚拟内存大小,因此除非使用超额分配,否则内存分配会更早失败。在Linux上,这也意味着可能更早地使用OOM killer。
考虑一个具有无限内存增长的应用程序问题。有了交换空间,这可能首先成为由于分页而导致的性能问题,这是实时调试问题的机会。没有交换空间,就没有分页的宽限期,所以应用程序要么遇到“内存耗尽”错误,要么OOM killer终止它。如果问题只在几个小时的使用后才出现,这可能会延迟调试问题。
接下来的部分将更详细地描述Linux和Solaris操作系统中的空闲列表、收割以及页面分页守护程序。
空闲列表
最初的Unix内存分配器使用了内存映射和首次适配扫描。随着BSD引入分页虚拟内存,添加了一个空闲列表和一个页面分页守护程序。空闲列表允许立即定位可用内存,如图7.7所示。

释放的内存被添加到列表的头部,以供将来分配使用。由页面分页守护进程释放的内存——可能仍包含有用的缓存文件系统页面——被添加到列表的尾部。如果在有用页面被重新使用之前出现对这些页面的未来请求,则可以重新获取并从空闲列表中删除该页面。
一种空闲列表形式仍然被Linux和基于Solaris的系统使用,如图7.6所示。空闲列表通常通过分配器(例如内核的slab分配器和用户空间的libc malloc)进行消耗。它们会消耗页面,然后通过其分配器API将其公开。
拥有一个单一的空闲列表也是一种简化;如何实现这一点取决于内核类型和版本。
Linux
Linux使用伙伴分配器来管理页面。这为不同大小的内存分配提供了多个空闲列表,遵循以2为底的方案。伙伴这个术语指的是找到相邻的空闲内存页面,以便它们可以一起分配。有关历史背景,请参阅[Peterson 77]。
伙伴空闲列表位于以下层次结构的底部,从每个内存节点pg_data_t开始:
- 节点:内存块,支持NUMA
- 区域:用于特定目的的内存范围(直接内存访问(DMA)、正常、高内存)
- 迁移类型:不可移动的、可回收的、可移动的等
- 大小:以2为底的页数
在节点的空闲列表内进行分配可以改善内存局部性和性能。
Solaris
基于Solaris的系统针对不同的内存位置(mnodes)、页面大小和页面着色使用多个空闲列表。它们也以一种类似伙伴的方式行事,将页面分组为更大的页面大小。这些列表在vm_dep.h中声明。

页面着色是虚拟页地址和物理页地址之间的映射关系,可以使用散列、轮询或其他方案。这是另一种提高访问性能的策略。
回收
回收主要涉及从内核slab分配器缓存中释放内存。这些缓存包含以slab大小为单位的未使用内存块,准备重用。回收将此内存返回给系统以进行页面分配。
在Linux上,内核模块还可以调用register_shrinker()函数来注册用于回收其自己内存的特定函数。
在基于Solaris的系统中,回收主要由kmem_reap()驱动的slab分配器完成。
页面扫描
通过页面分页方式释放内存由内核页面守护进程管理。当空闲列表中的可用主内存下降到阈值以下时,页面分页守护进程开始进行页面扫描。
页面扫描仅在需要时发生。一个通常平衡的系统可能不会经常进行页面扫描,而只在短时间内进行。而基于Solaris的系统在进行页面扫描之前会使用其他机制释放内存,如前面所示,超过几秒钟的页面扫描通常是内存压力问题的迹象。
Linux
页面分页守护进程称为kswapd(),它扫描处于非活跃和活跃内存的LRU(最近最少使用)页面列表以释放页面。它根据空闲内存和两个阈值唤醒,以提供滞后效应,如图7.8所示。

一旦空闲内存达到最低阈值,kswapd会以同步模式运行,根据请求释放内存页面(内核免除此要求)[Gorman 04]。这个最低阈值是可调的(vm.min_free_kbytes),其他阈值根据它进行缩放(乘以2倍、3倍)。
页面缓存有专门的列表用于存储非活跃页面和活跃页面。它们以LRU(最近最少使用)的方式运作,使得kswapd能够快速找到空闲页面。这些列表如图7.9所示。

kswapd首先扫描非活跃列表,如果需要的话再扫描活跃列表。扫描这个术语指的是在遍历列表时检查页面:如果页面被锁定或者是脏页,则不能释放。在原始的页面分页守护进程中,"扫描"一词有着不同的含义,它会扫描整个内存,在基于Solaris的系统中仍然存在。
Solaris
页面扫描循环遍历内存中的所有页面,找到最近最少使用的页面,然后安排将它们移动到物理交换设备上。这最初是在带有分页虚拟内存的BSD系统中添加的[Babaoglu 79],后来改进为使用两个指针来扫描内存,如图7.10所示(这种类似时钟的表示方法可以追溯到Multics系统[Corbató 68])。
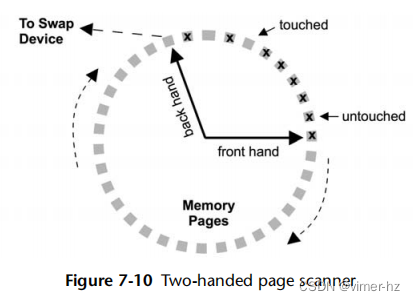
第一个hand在每个页面上设置一个位,指示该页面尚未被访问。当页面被访问时,这个位会被清除。第二个hand会检查这个位是否仍然被设置。如果是,页面扫描器就知道该页面最近没有被使用,可以被换出。两个hand之间的距离是可调的(handspreadpages)。
页面扫描的速率是动态的,根据可用的空闲内存而变化。这在图7.11中以一个128GB系统为例进行了说明,同时列出了可调的名称(基于[McDougall 06a])。

当可用内存降到desfree以下,然后是minfree以下时,页面换出守护进程会更频繁地被唤醒以扫描页面。如果可用内存连续30秒低于desfree,内核也会开始进行交换。
这些可调参数在setupclock()函数中初始化,根据主内存的比例进行设置。例如,lotsfree被设置为1/64。赤字参数是动态的,当内存消耗快速增加时会增长,这样内核就能更早地增加空闲列表。
对于较大的系统而言,页面扫描变得昂贵,因此添加了循环页面缓存,以便可以快速找到页面。这类似于Linux页面换出守护进程查找页面的方式。
7.3.3 Process Address Space
由硬件和软件共同管理,进程虚拟地址空间是一系列根据需要映射到物理页面的虚拟页面。这些地址被分割成称为段的区域,用于存储线程堆栈、进程可执行文件、库和堆。图7.12展示了32位进程的示例,适用于x86和SPARC处理器。

程序可执行段包含单独的文本和数据段。库也由单独的可执行文本和数据段组成。这些不同的段类型包括:
- 可执行文本:包含进程的可执行CPU指令。它是从文件系统上的二进制程序的文本段映射而来。它具有只读和可执行的权限。
- 可执行数据:包含从二进制程序的数据段映射而来的初始化变量。它具有读/写权限,因此可以在程序运行时修改变量。它还具有私有标志,以便修改不被刷新到磁盘上。
- 堆:这是程序的工作内存,是匿名内存(没有文件系统位置)。它根据需要增长,并通过malloc()进行分配。
- 栈:正在运行的线程的堆栈,映射为可读/写。
库的文本段可以被使用相同库的其他进程共享,每个进程都有一个私有副本的库数据段。
堆的增长
一个常见的困惑源于堆的无限增长。这是否意味着内存泄漏?
对于大多数分配器来说,不会将内存归还给操作系统;相反,它会保留内存以便为未来的分配提供服务。这意味着进程的常驻内存只会增长,这是正常的。进程减少内存的方法包括:
- 重新执行:从一个空地址空间重新开始
- 内存映射:使用和,它们会将内存归还给系统
一些分配器支持mmap作为一种操作模式。请参阅第8章文件系统中的第8.3.10节,内存映射文件。
7.3.4 Allocators
有各种用户级和内核级分配器用于内存分配。图7.13展示了分配器的作用,包括一些常见类型。
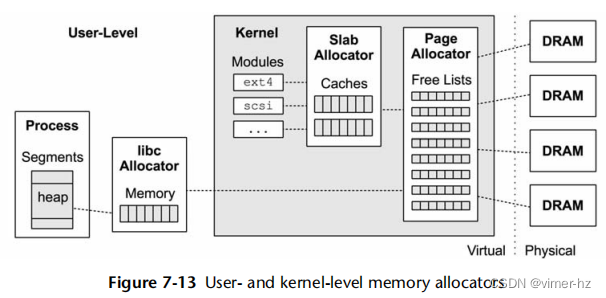
页面管理在之前的第7.3.2节“空闲列表”中有所描述。
内存分配器的特性可以包括:
- 简单的API:例如,`malloc`、`free`。
- 高效的内存使用:当为各种大小的内存分配提供服务时,内存使用可能会变得分散,存在许多未使用的区域浪费内存。分配器可以努力合并未使用的区域,使较大的分配能够利用它们,提高效率。
- 性能:内存分配可能频繁发生,在多线程环境下,由于同步原语的竞争,性能可能表现不佳。分配器可以被设计为尽量少地使用锁,并且利用每个线程或每个CPU的缓存来提高内存局部性。
- 可观察性:分配器可以提供统计信息和调试模式,显示它的使用方式以及哪些代码路径负责分配。接下来的章节将描述内核级分配器——slab和SLUB,以及用户级分配器——libmalloc、libumem和mtmalloc。
Slab(页框)
内核slab分配器管理特定大小对象的缓存,使它们能够在无需分配页面的情况下快速回收。这对于内核分配特别有效,因为内核分配通常是针对固定大小的结构体。
作为内核中的一个示例,以下两行代码摘自ZFS arc.c:

第一个函数`kmem_alloc()`展示了一种传统样式的内核分配,其大小作为参数传递。内核根据该大小将其映射到一个slab缓存(或者是一个超大尺寸区域)。第二个函数`kmem_cache_alloc()`直接在自定义的slab分配器缓存上操作,在这种情况下是`(kmem_cache_t *)hdr_cache`。
Solaris 2.4中引入了这一机制[Bonwick 94],后来通过每CPU缓存(称为magazines)进行了增强[Bonwick 01]:
我们的基本方法是给每个CPU分配一个包含M个对象的缓存,称为magazine,类比于自动武器。每个CPU的magazine可以在CPU需要重新加载之前满足M次分配——也就是说,将其空的magazine换成一个满的magazine。
除了高性能外,Solaris为slab分配器提供了各种调试和分析工具。其中包括审计功能,可以跟踪分配细节,包括堆栈信息。
slab分配器在Linux的2.2版本中引入,多年来一直是默认选项。最近的内核版本提供SLUB作为选项或默认选项。
SLUB
Linux内核的SLUB分配器基于slab分配器,并旨在解决slab分配器的各种问题,特别是其复杂性。这些包括移除对象队列和每个CPU缓存,将NUMA优化留给页面分配器(参见上文的自由列表部分)。
SLUB分配器在Linux 2.6.23中成为默认选项[2]。
libc
Solaris的用户级分配器由libc提供,它简单且通用。尽管通常是默认的分配器(取决于编译器配置),但man页不建议使用它(malloc(3C)):
这些默认的内存分配例程对于多线程应用程序是安全的,但不具备可扩展性。通过使用一个锁,多个线程的并发访问是单线程化的。对于大量使用动态内存分配的多线程应用程序,应链接使用为并发访问设计的分配库,如libumem(3LIB)或libmtmalloc(3LIB)。
除了性能问题外,该分配器是基于堆的,并且随着时间的推移可能会受到碎片化的影响。
glibc
GNU libc分配器基于Doug Lea的dlmalloc。其行为取决于分配请求的大小。小型分配从内存块中提供服务,这些内存块包含相似大小的单位,可以使用伙伴算法合并。较大的分配可以使用树查找来高效地找到空间。而非常大的分配则切换到使用mmap()。其结果是一个性能优秀的分配器,充分利用了多种分配策略的优势。
libumem
在基于Solaris的系统中,libumem是slab分配器的用户空间版本。可以通过链接或预加载库来使用,并为多线程应用程序提供改进的性能。
libumem从一开始就设计为可扩展,并具有以最小的时间和空间开销为代价的调试和分析功能。其他内存分析工具在分析模式下会减慢目标速度,有时甚至导致问题不再发生,而且通常会使它们不适合在生产环境中使用。
mtmalloc
这是另一个针对基于Solaris的系统的高性能多线程用户级分配器。它使用每个线程的缓存来处理小型分配,并使用单个超大区域来处理大型分配。每个线程的缓存避免了传统分配器中的锁争用问题。
7.4 Methodology
本节介绍了用于内存分析和调优的各种方法和练习。这些主题在表7.3中进行了总结。

请参阅第2章“方法论”了解更多策略以及对其中许多内容的介绍。
这些方法可以单独使用,也可以组合使用。我建议首先按照以下顺序使用以下策略:性能监控,USE方法和使用特征化。
第7.5节“分析”展示了应用这些方法的操作系统工具。
7.4.1 Tools Method
工具方法是一个迭代使用可用工具,检查它们提供的关键指标的过程。虽然是一种简单的方法,但它可能忽视那些工具无法提供良好或没有可见性的问题,并且执行起来可能耗时。
对于内存问题,工具方法可以包括检查以下内容:
- 页面扫描:查看持续的页面扫描(超过10秒)是否表示内存压力。在Linux上,可以使用sar -B命令并检查pgscan列。在Solaris上,可以使用vmstat(1M)命令并检查sr列。
- 分页:内存分页是系统内存不足的进一步指示。在Linux上,可以使用vmstat(8)命令并检查si和so列(这里,换出一词表示匿名分页)。在Solaris上,vmstat -p显示按类型的分页;要检查匿名分页。
- vmstat:每秒运行vmstat,并检查可用内存的free列。
- OOM killer:仅适用于Linux,在系统日志/var/log/messages中可以看到这些事件,也可以使用dmesg(1)命令。搜索“Out of memory”。
- 交换:仅适用于Solaris,通常在事后注意到,通过运行vmstat并检查w列来指示已交换出的线程。要实时查看交换情况,使用vmstat -S并检查si和so。
- top/prstat:查看哪些进程和用户是最大的物理内存消耗者(驻留),以及虚拟内存消耗者(请参阅man手册以获取列名,根据版本不同名称可能会有所不同)。这些工具还总结了可用内存。
- dtrace/stap/perf:使用堆栈跟踪跟踪内存分配,以确定内存使用的原因。
如果发现问题,请从可用工具的所有字段中检查,以获取更多上下文信息。有关每个工具的更多信息,请参阅第7.5节“分析”。其他方法可能会识别更多类型的问题。
7.4.2 USE Method
USE 方法用于在性能调查早期跨所有组件识别瓶颈和错误,这样可以在深入和耗时更长的策略之前进行检查。
系统范围内需要检查以下内容:
- 利用率:内存使用量及可用量。应检查物理内存和虚拟内存。
- 饱和度:页面扫描程度、分页、交换以及Linux OOM killer 的牺牲次数,作为减轻内存压力的措施。
- 错误:内存分配失败。
饱和度可能首先进行检查,因为持续饱和是内存问题的迹象。这些指标通常可以从操作系统工具中轻松获取,包括 vmstat(1)、sar(1) 和用于 OOM killer sacrifices 的 dmesg(1)。对于配置有单独磁盘交换设备的系统,任何与交换设备的活动也是内存压力的迹象。
利用率通常较难阅读和解释。通过饱和度指标,您可以了解物理内存是否不足:系统开始分页或进程被牺牲(OOM)。要确定物理利用率,您需要知道有多少可用内存(free)。不同工具可能以不同方式报告这一点,这取决于它们是否考虑了未引用的文件系统缓存页面或非活动页面。系统可能报告只剩下 10MB 可用内存,但实际上有 10GB 文件系统缓存,可以在需要时立即被应用程序回收。查看工具文档以了解其中包含哪些内容。
根据系统是否执行过量承诺,还可能需要检查虚拟内存利用率。对于那些不执行过量承诺的系统,一旦虚拟内存耗尽,内存分配将失败,这是一种内存错误。
历史上,内存错误一直由应用程序报告,尽管并非所有应用程序都这样做(而且在 Linux 过量承诺的情况下,开发人员可能认为没有必要这样做)。最近,SmartOS 添加了系统错误计数器,用于报告每个区域的失败 brk() 调用,作为一种内存相关错误计数器。
对于实施内存限制或配额(资源控制)的环境,如某些云计算环境,可能需要以不同方式测量内存饱和度。例如,在基于 Solaris 的系统上实施 OS 虚拟化时,对于每个客户实例强制执行内存配额的机制不同,并将其与传统的页面扫描器报告的方式有所不同。您的 OS 实例可能已达到其内存限制并进行分页,尽管系统并未使用传统的页面扫描器进行扫描。
7.4.3 Characterizing Usage
对内存使用情况进行表征是进行容量规划、基准测试和模拟工作负载时的重要练习。通过识别配置错误,它也可以带来一些最大的性能增益。例如,数据库缓存可能配置过小,导致命中率低,或者配置过大,引起系统分页。
对于内存,这涉及识别内存使用的位置和数量:
- 系统范围内的物理和虚拟内存利用率
- 饱和度程度:页面扫描、交换、OOM kill
- 内核和文件系统缓存内存使用
- 每个进程的物理和虚拟内存使用
- 如果存在,内存资源控制的使用
下面是一个示例描述,展示了如何将这些属性结合在一起表达:
该系统有 256GB 的主内存,仅利用了 1%,其中有 30% 存储在文件系统缓存中。最大的进程是一个数据库,消耗了 2GB 的主内存(RSS),这是它从之前迁移的系统中配置的限制。
随着更多内存用于缓存工作数据,这些特征可能随时间变化。由于内存泄漏(软件错误)而导致的内核或应用程序内存也可能随时间持续增长,而不仅仅是常规缓存增长。
高级用法分析/检查清单
可能需要包含更多详细信息以更详细地了解使用情况。以下列出了一些考虑问题的问题,这些问题在彻底研究内存问题时也可以作为检查清单:
- 内核内存用于哪里?每个 slab?
- 文件系统缓存(或页面缓存)中有多少是活动的,而不是非活动的?
- 进程内存用于哪里?
- 为什么进程分配内存(调用路径)?
- 为什么内核分配内存(调用路径)?
- 哪些进程正在被分页/交换出?
- 哪些进程以前曾被分页/交换出?
- 进程或内核可能存在内存泄漏吗?
- 在 NUMA 系统中,内存分布在内存节点上的情况如何?
- CPI 和内存停顿周期率是多少?
- 内存总线平衡程度如何?
- 本地内存 I/O 相对于远程内存 I/O 执行了多少?
接下来的章节可以帮助回答其中的一些问题。请参阅第二章“方法论”,了解此方法论的更高级摘要以及要测量的特征(谁、为什么、什么、如何)。
7.4.4 Cycle Analysis
可以通过检查 CPU 性能计数器(CPCs)来确定内存总线负载,这些计数器可以被编程为计算内存停顿周期。它们也可以用来测量每指令周期(CPI),作为衡量 CPU 负载对内存依赖程度的一种指标。请参阅第六章“CPU”了解更多信息。
7.4.5 Performance Monitoring
性能监测可以识别长期内的活跃问题和行为模式。内存的关键指标包括:
- 利用率:已使用百分比,可以从可用内存中推断出
- 饱和度:页面扫描、交换、OOM kill
对于实施内存限制或配额(资源控制)的环境,还可能需要收集与施加限制相关的统计信息。
还可以监视错误(如果可用),这些错误在第7.4.2节“USE 方法”中与利用率和饱和度一起描述。
随时间监视内存使用情况,尤其是按进程监视,可以帮助识别内存泄漏的存在和速率。
7.4.6 Leak Detection
当应用程序或内核模块不断增长,从空闲列表、文件系统缓存,最终从其他进程中消耗内存时,就会出现这个问题。首次注意到这个问题是因为系统正在分页,以应对不断增长的内存压力。
这种问题可能是由以下原因引起的:
- 内存泄漏:一种软件缺陷,内存被遗忘但永远不会释放。可以通过修改软件代码或应用补丁或升级(修改代码)来解决。
- 内存增长:软件正常消耗内存,但速度远高于系统所需。可以通过更改软件配置或软件开发人员更改应用程序消耗内存的方式来解决。
内存增长问题经常被误认为是内存泄漏。首先要问的问题是:它是否应该那样做?检查配置。
如何分析内存泄漏取决于软件和语言类型。一些分配器提供调试模式,用于记录分配细节,然后可以在事后进行分析,以确定责任调用路径。开发人员还可以使用工具进行内存泄漏调查。
7.4.7 Static Performance Tuning
静态性能调优侧重于已配置环境的问题。对于内存性能,需要检查静态配置的以下方面:
- 总共有多少主内存?
- 应用程序配置为使用多少内存(它们自己的配置)?
- 应用程序使用哪些内存分配器?
- 主内存的速度是多少?它是最快的类型吗?
- 系统架构是什么?NUMA,UMA?
- 操作系统是否具有NUMA意识?
- 存在多少内存总线?
- CPU缓存的数量和大小是多少?TLB?
- 是否配置并使用了大页?
- 是否可用并进行了超额承诺?
- 其他系统内存可调参数正在使用吗?
- 是否存在软件规定的内存限制(资源控制)?
回答这些问题可能会揭示被忽视的配置选择。
7.4.8 Resource Controls
操作系统可能为内存分配给进程或进程组提供细粒度控制。这些控制可能包括主内存和虚拟内存使用的固定限制。它们的工作方式是特定于实现的,并在第7.6节“调优”中进行了讨论。
7.4.9 Micro-Benchmarking
微基准测试可用于确定主存储器的速度和CPU缓存以及缓存行大小等特性。在分析系统之间的差异时,它可能会有所帮助,因为内存访问速度可能对性能的影响大于CPU时钟速度,这取决于应用程序和工作负载。在第6章“CPU”中,在CPU缓存下的延迟部分(第6.4.1节),展示了微基准测试内存访问延迟的结果,以确定CPU缓存的特性。
7.5 Analysis
这一部分介绍了针对基于Linux和Solaris的操作系统的内存分析工具。请参阅前一部分,了解在使用它们时应遵循的策略。本节中的工具列在表7.4中。

这是一些工具和功能的选择,用于支持第7.4节“方法论”,从系统范围的内存使用统计开始,然后深入到每个进程和分配的跟踪。请查看工具文档,包括man手册,以获取有关其功能的完整参考资料。此外,请参阅第8章“文件系统”,了解更多用于调查文件系统内存使用情况的工具。
虽然您可能只关注基于Linux或Solaris的系统,但请考虑其他操作系统工具以及它们提供的可观察性,以获得不同的视角。
7.5.1 vmstat
虚拟内存统计命令vmstat提供了系统内存健康状况的高层视图,包括当前空闲内存和分页统计信息。CPU统计信息也包括在内,如第6章“CPU”所述。
这个命令是由Bill Joy和Ozalp Babaoglu于1979年为BSD引入的。最初的man手册包括一个BUGS部分:打印出来的数字太多,有时很难弄清楚要观察什么。许多列自第一个版本以来基本保持不变,特别是对于Solaris。接下来的部分将展示Linux和基于Solaris的版本的列和选项。
Linux
以下是示例输出:

这个vmstat(8)版本在输出的第一行不打印自引导以来内存列的总结数值,而是立即显示当前状态。默认情况下,这些列的单位是千字节,并分别表示以下内容:
- swpd: 交换出的内存量
- free: 可用空闲内存
- buff: 缓冲区中的内存
- cache: 页面缓存中的内存
- si: 交换入的内存(分页)
- so: 交换出的内存(分页)
缓冲区和页面缓存在第8章“文件系统”中有描述。在系统引导后,系统中的可用空闲内存通常会减少,并被这些缓存使用以提高性能。当需要时,它可以被释放供应用程序使用。如果si和so列持续不为零,说明系统面临内存压力,并且正在向交换设备或文件进行分页(参见swapon(8))。可以使用其他工具,包括按进程查看内存使用情况,来调查内存的消耗情况。在拥有大量内存的系统上,这些列可能会变得不对齐并且有点难以阅读。您可以尝试使用-S选项将输出单位更改为兆字节。

还有一个-a选项,用于打印页面缓存中不活跃和活跃内存的详细信息:

可以使用-s选项将这些内存统计信息打印为列表。
Solaris
在基于Solaris的系统上,vmstat(1)命令更接近于BSD的原始版本。有许多字段显示了页面写出守护程序的活动情况,这对于尚未了解页面扫描器内部工作原理的用户来说可能有点不太友好。
以下是示例输出:

在拥有大量内存的系统上,这些列可能会变得不对齐。输出的第一行是自引导以来的总结情况。与内存相关的列包括:
- w: 被交换出的线程数
- swap: 可用虚拟内存(千字节)
- free: 可用空闲内存,包括页面缓存和空闲列表(千字节)
- re: 从页面缓存中回收的页面(缓存命中)
- mf: 小错误
- pi: 分页进入的内存,所有类型(千字节)
- po: 分页出去的内存,所有类型(千字节)
- fr: 页面缓存内存由页面扫描器或文件系统释放(千字节)
- de: 不足—预期的短期内存不足(千字节)(参见第7.3.2节“软件”的Solaris部分)
- sr: 被页面写出守护程序扫描的页面
示例输出显示了一个过去曾经出现问题的系统,有113个线程被交换出(w)。页面扫描器目前没有运行(sr),因此系统目前没有过多的内存压力。有少量的页面进入(pi),尽管它们可能是正常的(文件系统)或异常的(匿名)。-p选项显示了页面进入、页面退出和释放的详细情况:
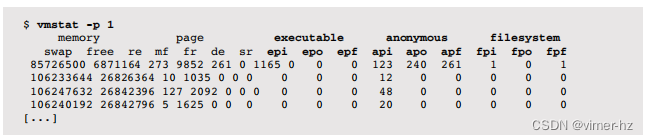
该系统存在匿名页面进入的频率(api),这是“不良”的分页行为。这会在应用程序运行时引起同步磁盘I/O级别的延迟。在这种情况下,这可能是由于先前的内存压力事件导致了内存页面出去,而活动线程目前正在被重新分页回来。
如果需要的话,可以通过kstat针对每个CPU观察许多这些统计信息。请参阅cpu::vm:统计数据组。kstat是在第4章“可观测性工具”中介绍的。
系统启动后,可用空闲内存(free)下降是正常的,因为内存被页面缓存和其他内核缓存使用。当需要时,这部分内存可以返回给应用程序使用。系统持续进行分页扫描(sr)并不正常,这是内存压力问题的迹象。如果是这种情况,请使用其他工具(例如按进程查看内存使用情况)来查看内存的使用情况。
7.5.2 sar
系统活动报告工具sar(1)可用于观察当前活动,并可配置为存档和报告历史统计数据。在本书的各个章节中提到了它,因为它提供了不同的统计信息。
Linux
Linux版本通过以下选项提供内存统计信息:
- B: 分页统计
- H: 大页面统计
- r: 内存利用率
- R: 内存统计
- S: 交换空间统计
- W: 交换统计
这些选项涵盖了内存使用情况、页面写出守护程序的活动以及大页面的使用情况。有关这些主题的背景,请参阅第7.3节“架构”。
提供的统计数据包括表7.5中列出的内容。


许多统计名称包括衡量单位:pg表示页面,kb表示千字节,%表示百分比,/s表示每秒。请查阅man手册获取完整列表,其中包括一些额外的基于百分比的统计数据。
重要的是要记住,在需要时可以获得关于高级内存子系统的使用和操作的如此详细的信息。要更深入地了解这些信息,您可能需要浏览mm目录下特定的源代码文件mm/vmscan.c。此外,linux-mm邮件列表中有许多帖子提供了进一步的见解,开发人员在讨论统计数据应该是什么。
%vmeff指标是页面回收效率的一个有趣的度量。高值表示页面成功从非活动列表中被窃取(健康);低值表示系统正在努力应对。man手册将近100%描述为高效,小于30%描述为低效。
Solaris版本提供以下选项:
- g: 分页统计
- k: 内核内存分配统计
- p: 分页活动
- r: 未使用内存指标
- w: 交换统计
这些选项涵盖了内存使用、内核分配、分页和交换等内容。有关这些主题的背景,请参阅第7.3节“架构”。
提供的统计数据包括表7.6中列出的内容。

将“-k”分解为“small”和“large”池在今天看来似乎有些不同寻常。我怀疑这是一个历史遗留问题,支持SVR4的延迟伙伴分配器所使用的大内存池和小内存池[Vahalia 96]。
更多有关内存子系统的统计信息可以通过kstat读取,或者使用DTrace动态构建。
7.5.3 slabtop
Linux的slabtop(1)命令从slab分配器中打印内核slab缓存的使用情况。类似于top(1),它实时刷新屏幕。
以下是一些示例输出:
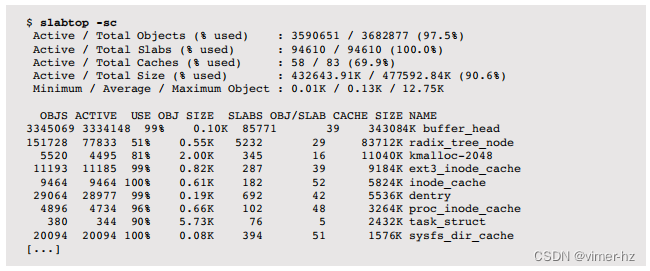
输出内容顶部有一个摘要,下面是一个slab列表,包括它们的对象数量(OBJS)、活跃对象数量(ACTIVE)、使用百分比(USE)、对象大小(OBJ SIZE,字节)和缓存的总大小(CACHE SIZE,字节)。
在这个例子中,使用了-sc选项按缓存大小排序,最大的在顶部。
这些slab统计数据来自/proc/slabinfo,也可以使用vmstat -m打印出来。
7.5.4 ::kmastat
在基于Solaris的系统上,用于mdb(1)的::kmastat调试器命令(dcmd)总结了内核内存的使用情况。输出分为三部分:slab分配器缓存使用情况、使用摘要和vmem使用摘要。
以下是一些示例输出:


输出内容超过了500行,这里进行了截断。尽管冗长,但在追踪内核内存增长的源头时可能是非常宝贵的。
其他有用的与内存相关的dcmd包括::kmem_slabs、::kmem_slabs -v和::memstat。例如:

虽然这是一个有用的摘要,但缺点是您必须是超级用户(root)并且正在运行mdb -k才能查看它。
7.5.5 ps
进程状态命令ps(1)列出了所有进程的详细信息,包括内存使用统计数据。其用法在第六章“CPU”中介绍。
例如,使用BSD风格选项:

这些输出包括以下列:
- %MEM:主内存使用量(物理内存,RSS)占系统总量的百分比
- RSS:常驻集大小(KB)
- VSZ:虚拟内存大小(KB)
尽管RSS显示了主内存的使用量,但它包括了诸如系统库之类的共享段,这些共享段可能被数十个进程映射。如果你对RSS列进行求和,你可能会发现它超过了系统中可用的内存,这是由于对这些共享内存的重复计数。请参阅后面的pmap(1)命令以分析共享内存的使用情况。
可以使用SVR4风格的-o选项选择这些列,例如:

Linux版本还可以打印主要和次要错误列(maj_flt,min_flt)。
在Solaris上,主要和次要错误信息可以在/proc中找到,但目前未从ps(1)中公开。另外请注意,aux输出中存在一个bug,导致RSS和VSZ列可能会合并——缺少空格分隔符。这个问题在最近的illumos/SmartOS中已经修复。
ps(1)的输出可以在内存列上进行后排序,以便快速识别消耗最高的进程。或者尝试使用top(1)和prstat(1M)工具,它们提供了排序选项。
7.5.6 top
top(1)命令监视当前运行的前几个进程,并包括内存使用统计数据。它在第六章“CPU”中介绍。例如,在Linux系统中:

顶部的摘要显示了主内存(Mem)和虚拟内存(Swap)的总量、已使用量和空闲量。同时也显示了缓冲缓存(buffers)和页面缓存(cached)的大小。
在这个例子中,通过配置top命令并改变排序顺序,按%MEM对每个进程的输出进行了排序。在这个例子中,最大的进程是node,它使用了2.2 GB的主内存和将近3 GB的虚拟内存。
主内存百分比列(%MEM)、虚拟内存大小(VIRT)和常驻集大小(RES)的含义与之前描述的ps(1)中相应的列相同。
7.5.7 prstat
prstat(1M)命令是为基于Solaris的系统引入的类似于top的工具,并在第6章“CPU”中介绍过。例如:

在这个例子中,排序顺序被设置为RSS(-s rss),以便将最大的内存消耗者列在顶部。进程名为redis-server的进程远远是最大的,占用45 GB的主内存(RSS)和65 GB的虚拟内存(SIZE)。
prstat(1M)可以打印微状态账户统计信息,其中包括文本和数据错误时间。对于这台服务器:

这个庞大的redis-server进程在等待数据错误(DFL)的时间百分比较高。这是之前vmstat -p示例中显示匿名页面换入率的相同服务器,这两者可能有关联:系统内存可能不足,将redis-server换出,并且现在正在等待(DFL)将其换回。
7.5.8 pmap
pmap(1)命令列出了进程的内存映射,显示它们的大小、权限和映射的对象。这允许更详细地检查进程的内存使用情况,并量化共享内存。例如,在基于Solaris的系统上:

这显示了一个PostgreSQL数据库的内存映射,包括虚拟内存(Kbytes)、主内存(RSS)、私有匿名内存(Anon)和权限(Mode)。对于大多数映射,很少有内存是匿名的,大部分是只读(r-x),这意味着这些页面可以与其他进程共享。这在系统库中尤其如此。这个例子中消耗的大部分内存位于一个共享内存段(ism)中。
Linux版本的pmap(1)类似,并基于Solaris版本。更新的版本使用Dirty一词代替Anon。
Solaris版本提供了一个-s选项来显示映射的页面大小:

这个PostgreSQL数据库的共享内存段主要使用了2兆字节的页面。
pmap(1)的输出对于具有许多映射的进程来说可能很长。它在报告内存使用情况时会暂停进程,这可能会影响正在进行的活动工作的性能。它在需要诊断和分析时很有用,但不应作为定期监控工具定期运行。
7.5.9 DTrace
DTrace可以用于跟踪用户级和内核级分配、次要和主要页面错误,以及页面换出守护进程的操作。这些功能支持对使用情况的表征和深入分析。
以下各节介绍了在基于Solaris和Linux的系统上进行内存分析的DTrace。除非另有说明,DTrace命令适用于两个操作系统。DTrace入门内容已包含在第4章“可观察性工具”中。
分配跟踪
如果可用,可以使用pid提供程序跟踪用户级分配器。这是一个动态跟踪提供程序,这意味着软件可以在任何时刻进行插装,无需重新启动,也无需事先配置分配器以运行在调试模式下。
以下示例总结了对malloc()调用的请求大小,针对PID 15041(一个Riak数据库):

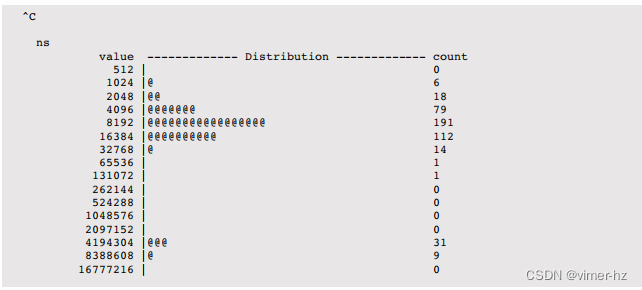
所有请求的分配大小介于512字节和16,383字节之间,大部分在1-2 K字节的范围内。
这个一行代码总结了malloc()的请求字节数,即将第一个参数(arg0)传递给二次幂quantize()聚合函数。如果需要,还可以跟踪malloc()的返回值,以检查分配是否成功。
关键是将其设置为“请求字节”,仅用于使用ustack()动作装饰输出时包含用户级堆栈跟踪。

在这种情况下,输出非常长,已经被截断以适应。它显示了导致分配的用户级堆栈跟踪,以及请求分配大小的分布情况。
由于分配是频繁发生的活动,尽管每个事件的追踪速度很快,但在追踪过程中成本可能会累积,并引起性能开销。
还可以调查用户级分配器的其他内部情况。例如,列出libumem分配器的入口探测点:

输出列出了163个入口探测点。这些可以用于构建更复杂的一行代码和脚本,以调查分配器的内部情况。
内核级分配器可以使用类似的方式进行跟踪,使用动态fbt提供程序。例如,在基于Solaris的系统上,以下一行代码跟踪slab分配器:
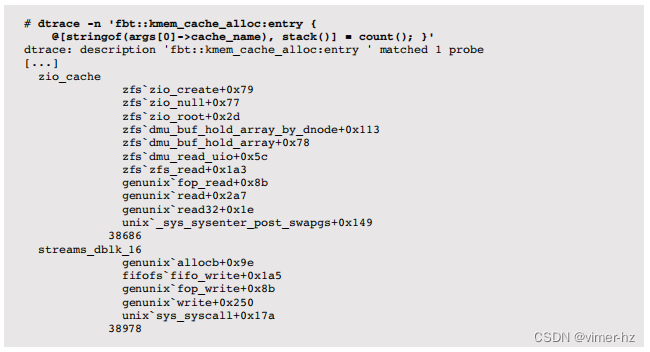
输出包括缓存的名称,后跟用于分配的内核堆栈跟踪,然后是跟踪时的计数。
以下一行代码展示了跟踪用户级和内核级分配器的不同方式。
一行代码示例
总结进程PID的用户级malloc()请求大小:
![]()
总结进程PID的带调用堆栈的用户级malloc()请求大小:
![]()
统计libumem函数调用次数:
![]()
统计用户级堆增长(通过brk()函数)的堆栈数:
![]()
跟踪Solaris系统中按缓存名称和堆栈跟踪的内核级slab分配:

故障跟踪
页面错误的跟踪可以进一步揭示系统如何提供内存。 可以使用动态fbt提供程序或可用的稳定vminfo提供程序来执行此操作。
例如,在基于Solaris的系统上,以下一行代码跟踪名为"beam.smp"的进程(这是 Erlang VM,在本例中运行 Riak 数据库)的次要错误,并统计用户级堆栈跟踪,深度为五层:

这总结了消耗内存并引起次要错误的代码路径。在这种情况下,是 Erlang 垃圾回收代码。也可以使用vminfo:::maj_fault探测点跟踪主要错误。
另一个有用的与故障相关的探测点是vminfo:::anonpgin,用于匿名页面导入。例如:

这条跟踪了系统范围内的匿名页面导入,统计了进程ID和进程名称。这与之前vmstat(1)示例所展示的相同系统,该示例确定了匿名页面导入,并且与prstat(1M)示例相同,该示例确定了redis-server在数据错误中花费的时间。这个DTrace一行代码连接了这些信息,确认了redis-server正花费时间在匿名页面导入上,这是由于系统内存不足和分页引起的。
页面输出守护进程
如果需要,也可以使用fbt提供程序跟踪页面输出守护进程的内部操作。具体操作取决于内核版本。
7.5.10 SystemTap
在Linux系统上,也可以使用SystemTap进行文件系统事件的动态跟踪。请参阅第4章“可观测性工具”中的第4.4节“SystemTap”,以及附录E,了解如何将之前的DTrace脚本转换为SystemTap脚本。
7.5.11 Other Tools
其他Linux内存性能工具包括以下内容:
- free:报告空闲内存,包括缓冲区缓存和页面缓存(请参阅第8章“文件系统”)。
- dmesg:检查来自OOM killer的“内存不足”消息。
- valgrind:一个性能分析套件,包括memcheck,用于内存使用分析和泄漏检测的用户级分配器包装器。这会带来显著的开销;手册建议可能导致目标运行速度减慢20到30倍。
- swapon:用于添加和观察物理交换设备或文件。
- iostat:如果交换设备是物理磁盘或分区,可以使用iostat(1)观察设备I/O,指示系统正在分页。
- perf:在第6章“CPU”中介绍,可用于调查CPI、MMU/TSB事件以及来自CPU性能测试计数器的内存总线停顿周期。它还提供用于页面故障和多个内核内存(kmem)事件的探针。
- /proc/zoneinfo:内存区域(NUMA节点)的统计信息。
- /proc/buddyinfo:内核伙伴分配器页面的统计信息。
其他Solaris内存性能工具包括以下内容:
- prtconf:显示已安装物理内存大小(可以使用|grep Mem或在更新版本中使用-m进行过滤)。
- prtdiag:显示物理内存布局(适用于支持的系统)。
- swap:交换统计信息:列出交换设备(-l),并总结使用情况(-s)。
- iostat:如果交换设备是物理磁盘或分区,可以使用iostat(1)观察设备I/O,指示系统正在分页或交换。
- cpustat:在第6章“CPU”中介绍,可用于调查CPI、MMU/TSB事件以及来自CPU性能测试计数器的内存总线停顿周期。
- trapstat:打印陷阱统计信息,包括不同页面大小的TLB/TSB缺失率和消耗的CPU百分比。目前仅在SPARC处理器上受支持。
- kstat:包含更多统计信息,用于了解内核内存使用情况。对于其中大多数内容,唯一的文档是源代码(如果可用)。
应用程序和虚拟机(例如Java虚拟机)也可能提供自己的内存分析工具。请参阅第5章“应用程序”。
一些分配器维护自己的统计信息以便观察。例如,可以使用Solaris上的mdb(1) dcmds来调查libumem库。


这显示了::vmem,它打印了由libumem使用的内部虚拟内存结构及其使用情况,以及::umem_malloc_info,它显示按缓存分配的统计信息,可以指示内存按大小的使用模式(将BUFSZ与MALLOCED进行比较)。虽然只提供基本属性,但这些命令可以揭示通常是不透明的进程堆中的情况。
7.6 Tuning
最重要的内存调优是确保应用程序保持在主内存中,避免频繁发生分页和交换。识别这个问题已经在第7.4节“方法论”和第7.5节“分析”中讨论过。本节讨论其他内存调优内容:内核可调参数、配置大页面、分配器和资源控制。
调优的具体内容——可用的选项以及如何设置它们——取决于操作系统版本和预期的工作负载。下面按调优类型组织的各节提供了可能可用的示例,以及为什么可能需要进行调优。
7.6.1 Tunable Parameters
这一部分描述了最近的Linux和基于Solaris的内核的可调参数示例。
Linux
各种内存可调参数在内核源代码文档Documentation/sysctl/vm.txt中有描述,并可以使用sysctl(8)进行设置。表7.7中的示例来自3.2.6内核,其中默认值来自Fedora 16。

这些可调参数采用了包含单位的一致命名方案。请注意,dirty_background_bytes和dirty_background_ratio是互斥的,同样dirty_bytes和dirty_ratio也是互斥的(只能设置一个)。
vm.min_free_kbytes的大小会动态设置为主内存的一部分。选择此数值的算法并非线性,因为空闲内存需求与主内存大小并不呈线性比例关系(有关详细信息,请参阅mm/page_alloc.c中的文档)。vm.min_free_kbytes可以减少以释放一些内存供应用程序使用,但这也可能导致在内存压力下内核被迫更早地使用OOM。
另一个避免OOM(Out of Memory)的参数是vm.overcommit_memory,可以将其设置为2以禁用过度承诺,并避免导致OOM的情况发生。如果希望根据每个进程进行OOM killer的控制,请查看您的内核版本是否具有/proc可调参数,例如oom_adj或oom_score_adj。这些内容应该在Documentation/filesystems/proc.txt中有所描述。
vm.swappiness可调参数在早于预期开始交换应用程序内存时可能会显著影响性能。该可调参数的值可以介于0和100之间,较高的值有利于交换应用程序,从而保留页面缓存。可能希望将其设置为零,以便尽可能长时间地保留应用程序内存,以牺牲页面缓存为代价。当仍然存在内存短缺时,内核仍然可以使用交换。
Solaris
表7.8显示了内存的关键可调参数,可以在/etc/system中设置,同时列出了典型的默认值。请参阅供应商文档以获取完整列表、设置说明、描述和警告。其中一些在图7.11中已经展示过。

可以使用pagesize(1)命令来确定这些单位的含义。
请注意,有时公司或供应商政策可能禁止调整内核可调参数(请先检查)。这些参数应该已经设置为适当的值,并且不需要进行调整。
对于大容量内存系统(超过100 GB),调整其中一些参数至较低值可能是值得的,以释放更多内存供应用程序使用。在具有多个存储设备(例如存储阵列)的系统中,可能需要增加maxpgio,以使队列长度更适合可用的I/O容量。
7.6.2 Multiple Page Sizes
大页面大小可以通过提高TLB缓存的命中率(增加其范围)来改善内存I/O性能。大多数现代处理器支持多种页面大小,例如4 K字节的默认大小和2 M字节的大页面。
在Linux上,可以以多种方式配置大页面(称为巨大页面)。有关详细信息,请参阅Documentation/vm/hugetlbpage.txt。
这些通常始于创建巨大页面:

一个应用程序使用巨大页面的方法是通过共享内存段,并在shmget()中使用SHM_HUGETLBS标志。
另一种方法涉及为应用程序创建基于巨大页面的文件系统,以便进行内存映射:

其他方法包括在mmap()中使用MAP_ANONYMOUS|MAP_HUGETLB标志,并使用libhugetlbfs API[4]。
最近,对透明巨大页面(THP)的支持已经得到开发。这在适当时使用巨大页面,无需系统管理员手动操作[5]。有关详细信息,请参阅Documentation/vm/transhuge.txt。
在基于Solaris的系统上,可以通过配置应用程序环境以使用libmpss.so.1库来配置大页面。例如:

这些可以被放置在应用程序的启动脚本中。大页面是由内核动态创建的,只有当有足够的页面可用来创建它们时才会成功(否则将使用默认的较小页面)。
使用Oracle Solaris Studio编译的程序可能会自动使用大页面,因此不需要手动预加载mpss。
7.6.3 Allocators
不同的用户级分配器可能可用,为多线程应用程序提供改进的性能。这些可以在编译时选择,也可以通过设置LD_PRELOAD环境变量在执行时选择。
例如,在Solaris上,可以使用libumem分配器进行选择
![]()
这可以放置在其启动脚本中。
7.6.4 Resource Controls
基本的资源控制,包括设置主内存限制和虚拟内存限制,可以使用ulimit(1)来实现。
对于Linux,容器组(cgroups)内存子系统提供各种额外的控制。其中包括
- memory.memsw.limit_in_bytes:允许的最大内存和交换空间,以字节为单位
- memory.limit_in_bytes:允许的最大用户内存,包括文件缓存使用量,以字节为单位
- memory.swappiness:类似于前面描述的vm.swappiness,但可以为cgroup设置
- memory.oom_control:可以设置为0,以允许为此cgroup启用OOM killer,或设置为1以禁用它
在基于Solaris的系统上,可以使用资源控制和prctl(1)命令应用每个区域或每个项目的内存限制。这些可以通过页面出内存来强制执行它们的限制,而不是失败的分配,这可能更适用于目标应用程序,具体内容请参见第11章云计算中的第11.2节OS虚拟化。
8 File Systems
在研究应用程序I/O性能时,文件系统的性能比磁盘性能更重要。文件系统使用缓存、缓冲和异步I/O来避免将应用程序暴露于磁盘级(或远程系统)的延迟中。然而,性能分析和可用的工具集通常过去主要关注磁盘的性能。
在动态跟踪的时代,文件系统分析现在变得简单和实用。本章展示了如何详细检查文件系统请求,包括使用动态跟踪从应用程序上下文中测量启动到完成时间。这通常可以快速排除文件系统及其底层磁盘设备作为性能不佳的源头,从而使调查可以转向其他领域。
本章由五部分组成,前三部分提供文件系统分析的基础,后两部分展示其在基于Linux和Solaris的系统中的实际应用。各部分内容如下:
- 背景介绍了与文件系统相关的术语、基本模型,说明文件系统原则和关键文件系统性能概念。
- 架构介绍了通用和特定的文件系统架构。
- 方法论描述了性能分析方法论,包括观察性和实验性方法。
- 分析展示了针对基于Linux和Solaris系统的文件系统性能工具,包括静态和动态跟踪。
- 调优描述了文件系统可调参数。
8.1 Terminology
在本章中使用的与文件系统相关的术语包括以下内容:
- 文件系统:将数据组织为文件和目录的一种方式,提供基于文件的接口来访问它们,并使用文件权限来控制访问。额外的内容可能包括用于设备、套接字和管道的特殊文件类型,以及包含文件访问时间戳等元数据。
- 文件系统缓存:主存储器(通常是DRAM)中用于缓存文件系统内容的区域,可能包括不同的缓存用于各种数据和元数据类型。
- 操作:文件系统操作是对文件系统的请求,包括read()、write()、open()、close()、stat()、mkdir()和其他操作。
- I/O:输入/输出。文件系统I/O可以用多种方式定义;这里仅表示直接读取和写入(执行I/O)的操作,包括read()、write()、stat()(读取统计信息)和mkdir()(写入新目录条目)。I/O不包括open()和close()。
- 逻辑I/O:应用程序向文件系统发出的I/O。
- 物理I/O:由文件系统直接(或通过原始I/O)发出到磁盘的I/O。
- 吞吐量:应用程序与文件系统之间的当前数据传输速率,以每秒字节数为单位衡量。
- inode:索引节点(inode)是一个包含文件系统对象元数据的数据结构,包括权限、时间戳和数据指针。
- VFS:虚拟文件系统,是一个内核接口,用于抽象和支持不同的文件系统类型。在Solaris中,VFS inode被称为vnode。
- 卷管理器:用灵活的方式管理物理存储设备的软件,从中创建虚拟卷供操作系统使用。
本章还介绍了其他术语。术语表包括用于参考的基本术语,包括fsck、IOPS、操作速率和POSIX。另请参阅第2章和第3章的术语部分。
8.2 Models
以下简单模型说明了文件系统及其性能的一些基本原理。
8.2.1 File System Interfaces
图8.1展示了一个文件系统的基本模型,涉及到其接口。

在图中还标记了逻辑和物理操作发生的位置。有关这些内容的更多信息,请参阅第8.3.12节《逻辑I/O与物理I/O》。研究文件系统性能的一种方法是将其视为黑匣子,重点放在对象操作的延迟上。这在第8.5.2节《延迟分析》中有更详细的解释。
8.2.2 File System Cache
图8.2中展示了存储在主内存中的通用文件系统缓存,用于执行读取操作。读取操作可以从缓存中返回(缓存命中)或从磁盘中返回(缓存未命中)。缓存未命中的数据会被存储到缓存中,填充缓存(使其变热)。

文件系统缓存还可以缓冲待写入(刷新)的数据。对于不同的文件系统类型,执行这一操作的机制各不相同,具体描述请参见第8.4节《架构》。
8.2.3 Second-Level Cache
二级缓存可以是任何内存类型;图8.3将其展示为闪存。这种缓存类型最初是为ZFS开发的。

8.3 Concepts
以下是关于文件系统性能的一些重要概念。
8.3.1 File System Latency
文件系统延迟是文件系统性能的主要度量标准,指的是从逻辑文件系统请求到完成所需的时间。它包括在文件系统、内核磁盘I/O子系统以及等待磁盘设备上花费的时间 — 即物理I/O。应用程序线程在应用程序请求期间通常会阻塞,等待文件系统请求完成,文件系统延迟直接且成比例地影响应用程序性能。
应用程序可能不直接受到影响的情况包括使用非阻塞I/O,或者当I/O是从异步线程(例如后台刷新线程)发出时。如果应用程序提供了其文件系统使用的详细指标,那么可以通过这些指标来识别这些情况。如果没有,一个通用的方法是使用可以显示导致逻辑文件系统I/O的用户级堆栈跟踪的内核跟踪工具。然后可以研究此堆栈跟踪,以查看是哪些应用程序例程发出了它。
操作系统在历史上并未使文件系统延迟易于观察,而是提供磁盘设备级别的指标。但有许多情况下,这些指标不会直接影响应用程序,使它们很难解释,甚至毫无意义。例如,文件系统执行写入数据的后台刷新,这可能会表现为高延迟磁盘I/O的突发。从磁盘设备级别的指标来看,这看起来令人担忧;然而,没有任何应用程序在等待这些操作完成。有关更多情况,请参阅第8.3.12节《逻辑I/O与物理I/O》。
8.3.2 Caching
启动后,文件系统通常会使用主内存(RAM)作为缓存以提高性能。对于应用程序来说,这个过程是透明的:它们的逻辑I/O延迟变得更低,因为可以从主内存中提供而不是从速度慢得多的磁盘设备中提供。
随着时间的推移,缓存会增长,而操作系统的空闲内存会减少。这可能会让新用户感到困扰,但这是完全正常的。原则是:如果有多余的主内存,就记住一些有用的东西。当应用程序需要更多内存时,内核应该迅速从文件系统缓存中释放空间供其使用。
文件系统使用缓存来提高读取性能,并使用缓冲区(在缓存中)来提高写入性能。文件系统和块设备子系统通常会使用多种类型的缓存,其中可能包括表8.1中的缓存。具体的缓存类型在第8.4节“架构”中进行了描述,第3章“操作系统”列出了缓存的完整列表(包括应用程序级和设备级)。

8.3.3 Random versus Sequential I/O
一系列逻辑文件系统I/O操作可以根据每个I/O的文件偏移量描述为随机或顺序。顺序I/O中,下一个I/O从上一个I/O的末尾开始。随机I/O之间没有明显的关系,偏移量会随机变化。随机文件系统工作负载也可能指随机访问许多不同的文件。图8.4说明了这些访问模式,展示了有序的I/O系列和示例文件偏移量。

由于某些存储设备的性能特征(在第9章“磁盘”中描述),文件系统在历史上一直试图通过将文件数据连续和顺序地放置在磁盘上来减少随机I/O。碎片化一词描述了当文件系统执行不佳时,导致文件分布在驱动器上变得散乱,使得顺序逻辑I/O导致随机物理I/O。
文件系统可以测量逻辑I/O访问模式,以便它们可以识别顺序工作负载,然后使用预取或预读取来提高性能。接下来的部分将涵盖这些主题。
8.3.4 Prefetch
常见的文件系统工作负载涉及顺序读取大量文件数据,例如进行文件系统备份。这些数据可能太大而无法放入缓存,或者可能只读取一次,并且不太可能被保留在缓存中(取决于缓存淘汰策略)。这样的工作负载表现相对较差,因为它的缓存命中率较低。
预取是解决这个问题的常见文件系统特性。它可以基于当前和先前的文件I/O偏移量检测顺序读取工作负载,然后在应用程序请求数据之前预测并发出磁盘读取指令。这会填充文件系统缓存,因此如果应用程序确实执行了期望的读取操作,就会导致缓存命中(所需数据已经存在于缓存中)。
以下是一个示例场景,假设一开始没有数据被缓存:
1. 应用程序发出文件read()请求,将执行权交给内核。
2. 文件系统向磁盘发出读取指令。
3. 将先前的文件偏移量指针与当前位置进行比较,如果它们是顺序的,文件系统就会发出额外的读取指令。
4. 第一次读取完成,内核将数据和执行权交还给应用程序。
5. 任何额外的读取完成后,填充了缓存,以供未来应用程序读取使用。
这个场景也在图8.5中有所说明,应用程序首先读取偏移量1,然后触发对接下来的三个偏移量的预取。

当预取检测工作良好时,应用程序表现出显著提高的顺序读取性能;磁盘能够在应用程序请求之前提前读取数据。当预取检测效果不佳时,会发出不必要的I/O请求,这些请求是应用程序不需要的,会污染缓存并消耗磁盘和I/O传输资源。文件系统通常允许根据需要调整预取设置。
8.3.5 Read-Ahead
在历史上,预取功能也被称为read-ahead。更近期,Linux采用了read-ahead这个术语作为系统调用readahead(2),该系统调用允许应用程序明确地预热文件系统缓存。
8.3.6 Write-Back Caching
写回缓存通常被文件系统用来提高写入性能。它的工作方式是将写入视为在传输到主内存后完成,并稍后异步地将其写入磁盘。文件系统处理将这些“脏”数据写入磁盘的过程称为刷新。一个示例序列如下:
1. 应用程序发出文件write()请求,将执行权交给内核。
2. 来自应用程序地址空间的数据被复制到内核中。
3. 内核将write()系统调用视为已完成,并将执行权返回给应用程序。
4. 稍后,异步的内核任务找到已写入的数据并发出磁盘写入操作。
这种折衷是可靠性。基于DRAM的主内存是易失性的,在断电事件发生时,即使应用程序认为写入已完成,脏数据也可能会丢失。它也可能未完全写入磁盘,留下一个磁盘上状态损坏的情况。
如果文件系统元数据损坏,文件系统可能无法加载。这种状态可能只能从系统备份中恢复,导致长时间的停机时间。更糟糕的是,如果损坏影响应用程序读取和使用的文件内容,业务可能会受到威胁。
为了平衡速度和可靠性的需求,文件系统可以默认提供写回缓存,并提供同步写选项以绕过此行为直接写入持久存储设备。
8.3.7 Synchronous Writes
同步写入只有在完全写入持久存储(例如磁盘设备)时才算完成,这包括写入任何必要的文件系统元数据更改。与异步写入(写回缓存)相比,同步写入要慢得多,因为同步写入会产生磁盘设备I/O延迟。一些应用程序,如数据库日志编写器,使用同步写入,因为异步写入可能导致数据损坏风险不可接受。
同步写入有两种形式:单个I/O是同步写入,以及先前写入的组合是同步提交。
单个同步写入
当使用标志O_SYNC或其变体之一O_DSYNC和O_RSYNC(截至Linux 2.6.31时由glib映射为O_SYNC)打开文件时,写入I/O是同步的。一些文件系统具有挂载选项,强制所有文件的写入I/O都是同步的。
同步提交先前的写入
应用程序可以在代码中的检查点处同步提交先前的异步写入,而不是同步写入单个I/O,使用fsync()系统调用。这可以通过分组同步写入来提高性能。
还有其他情况会提交先前的写入,例如关闭文件句柄,或者文件上存在太多未提交的缓冲区时。前一种情况在解压包含许多文件的归档文件时经常会注意到,特别是在NFS上。
8.3.8 Raw and Direct I/O
这些是应用程序可能使用的其他类型的I/O:
原始I/O直接发出到磁盘偏移量,完全绕过文件系统。一些应用程序,特别是数据库,可以比文件系统缓存更好地管理和缓存它们自己的数据而使用原始I/O。一个缺点是管理上的困难:常规文件系统工具集无法用于备份/恢复或可观性。
直接I/O允许应用程序使用文件系统但绕过文件系统缓存。这类似于同步写入(但不提供O_SYNC提供的保证),它也适用于读取。它不像原始设备I/O那样直接,因为文件偏移量到磁盘偏移量的映射仍然必须由文件系统代码执行,I/O也可能被调整大小以匹配文件系统用于磁盘布局的大小(其记录大小)。根据文件系统的不同,这不仅会禁用读取缓存和写入缓冲,还可能禁用预取。
直接I/O可用于执行文件系统备份的应用程序,以避免将只读取一次的数据污染文件系统缓存。原始I/O和直接I/O均可用于避免双重缓存,适用于在进程堆中使用自己的应用程序级缓存的应用程序。
8.3.9 Non-Blocking I/O
通常,文件系统I/O要么立即完成(例如,来自缓存),要么在等待一段时间后完成(例如,等待磁盘设备I/O)。如果需要等待,应用程序线程将被阻塞并释放CPU,允许其他线程在等待期间执行。虽然被阻塞的线程无法执行其他工作,但这通常不是问题,因为多线程应用程序可以创建额外的线程来执行,而有些线程被阻塞。
在某些情况下,非阻塞I/O是可取的,例如当需要避免线程创建的性能或资源开销时。可以通过在open()系统调用中使用O_NONBLOCK或O_NDELAY标志来执行非阻塞I/O,这会导致读取和写入返回EAGAIN错误而不是阻塞,告诉应用程序稍后再试。 (对此的支持取决于文件系统,该文件系统可能只针对咨询或强制文件锁而支持非阻塞。)非阻塞I/O也在第5章“应用程序”中进行了讨论。
8.3.10 Memory-Mapped Files
对于某些应用程序和工作负载,可以通过将文件映射到进程地址空间并直接访问内存偏移量来改善文件系统I/O性能。这样可以避免在调用read()和write()系统调用以访问文件数据时产生的系统调用执行和上下文切换开销。如果内核支持直接将文件数据缓冲区复制到进程地址空间,还可以避免数据的双重复制。
内存映射是使用mmap()系统调用创建的,并使用munmap()删除。可以使用madvise()对映射进行调优,如第8.8节“调优”中总结的那样。一些应用程序在其配置中提供了使用mmap系统调用的选项(可能称为“mmap模式”)。例如,Riak数据库可以使用mmap来进行内存数据存储。
我注意到人们倾向于在分析问题之前尝试使用mmap()来解决文件系统性能问题。如果问题是来自磁盘设备的高I/O延迟,那么通过mmap()避免小的系统调用开销可能意义不大,因为高磁盘I/O延迟仍然存在并且占主导地位。
在多处理器系统上使用映射的一个缺点是保持每个CPU的MMU同步的开销,特别是用于移除映射的CPU交叉调用(TLB shootdowns)。根据内核和映射的不同,这些开销可以通过延迟TLB更新(延迟shootdowns)[Vahalia 96]来最小化。
8.3.11 Metadata
数据描述文件和目录的内容,而元数据描述与它们有关的信息。元数据可能指的是可以从文件系统接口(POSIX)读取的信息,或者实现磁盘上文件系统布局所需的信息。这分别称为逻辑元数据和物理元数据。
逻辑元数据
逻辑元数据是由消费者(应用程序)读取和写入文件系统的信息,可以通过以下方式进行:
- 明确地:读取文件统计信息(stat()),创建和删除文件(creat(),unlink())和目录(mkdir(),rmdir())
- 隐式地:文件系统访问时间戳更新,目录修改时间戳更新
一个“元数据密集型”的工作负载通常指的是逻辑元数据,例如,Web服务器使用stat()函数检查文件是否自缓存以来未更改的频率远高于实际读取文件数据内容。
物理元数据
物理元数据是指在磁盘上记录所有文件系统信息所必需的元数据。所使用的元数据类型取决于文件系统类型,可能包括超级块、inode、数据指针块(主要的、次要的等),以及空闲列表。
逻辑和物理元数据是逻辑I/O和物理I/O之间差异的原因之一。
8.3.12 Logical versus Physical I/O
尽管这可能看起来违反直觉,应用程序向文件系统请求的I/O(逻辑I/O)可能与磁盘I/O(物理I/O)不匹配,原因有几个。文件系统做的远不止提供持久存储(磁盘)作为基于文件的接口。它们会缓存读取、缓冲写入,并创建额外的I/O 来维护需要记录一切位置的磁盘上物理布局元数据。这可能导致与应用程序I/O 不相关、间接、膨胀或紧缩的磁盘I/O。以下是一些示例。
不相关
这是与应用程序无关的磁盘I/O,可能是由于以下因素:
- 其他应用程序:磁盘I/O 来自另一个应用程序。
- 其他租户:磁盘I/O 来自另一个租户(在某些虚拟化技术下可通过系统工具看到)。
- 其他内核任务:例如,当内核正在重建软件RAID卷或执行异步文件系统校验和验证(请参见8.4节,体系结构)。
间接
这是应用程序I/O 没有直接对应的磁盘I/O,可能是由于以下因素:
- 文件系统预取:添加可能或可能不被应用程序使用的额外I/O。
- 文件系统缓冲:使用写回缓存延迟和合并写入以后刷新到磁盘。一些系统可能在写入前缓冲数十秒,然后以大且不经常的突发形式出现。
紧缩
这是磁盘I/O 小于应用程序I/O,甚至不存在的情况,可能是由于以下因素:
- 文件系统缓存:从主存储器中满足读取而不是磁盘。
- 文件系统写取消:相同的字节偏移在刷新到磁盘之前多次修改。
- 压缩:将逻辑I/O 数据量减少至物理I/O。
- 合并:在发送给磁盘之前合并顺序I/O。
- 内存中文件系统:内容可能永远不会写入磁盘(例如tmpfs)。
膨胀
在这种情况下,磁盘I/O 大于应用程序I/O,可能是由于以下因素:
- 文件系统元数据:添加额外的I/O。
- 文件系统记录大小:调整I/O 大小(增加字节),或分片I/O(增加计数)。
- 卷管理器奇偶校验:读-修改-写循环,添加额外的I/O。
示例
为了展示这些因素如何同时发生,以下列举的示例描述了应用程序进行1字节写入时可能发生的情况:
1. 应用程序对现有文件执行1字节写入。
2. 文件系统将该位置识别为128KB文件系统记录的一部分(未缓存,但其元数据已被引用)。
3. 文件系统请求从磁盘加载记录。
4. 磁盘设备层将128KB读取分成适合设备的较小读取。
5. 磁盘执行多个较小读取,总计128KB。
6. 文件系统现在将记录中的1字节替换为新字节。
7. 一段时间后,文件系统请求将128KB脏记录写回磁盘。
8. 磁盘写入128KB记录(如有必要,进行分解)。
9. 文件系统写入新的元数据,例如引用(用于写时复制)或访问时间。
10. 磁盘执行更多写入。
因此,虽然应用程序只执行了单个1字节写入,但磁盘执行了多次读取(总计128KB)和更多写入(超过128KB)。
8.3.13 Operations Are Not Equal
正如前面的部分所述,文件系统操作的性能可能会根据它们的类型而有所不同。仅仅从速率来看,你无法判断“每秒500次操作”的工作负载情况。一些操作可能会从文件系统缓存以主存储器速度返回,而另一些可能会从磁盘返回,速度慢得多。其他确定性因素包括操作是随机的还是顺序的,是读取还是写入,是同步写入还是异步写入,它们的I/O大小,是否包含其他操作类型,以及它们的CPU执行成本。
常见做法是对不同的文件系统操作进行微基准测试,以确定这些性能特征。例如,表8.2中的结果来自一个在Intel Xeon 2.4 GHz多核处理器上的ZFS文件系统。

这些测试没有涉及存储设备,而是测试文件系统软件和CPU速度。一些特殊的文件系统从不访问存储设备。
8.3.14 Special File Systems
文件系统的目的通常是持久存储数据,但也有用于其他目的的特殊文件系统类型,包括临时文件(/tmp)、内核设备路径(/dev)和系统统计信息(/proc)。
8.3.15 Access Timestamps
许多文件系统支持访问时间戳,记录每个文件和目录的访问(读取)时间。这会导致在读取文件时更新文件元数据,从而产生写入工作负载,消耗磁盘I/O资源。第8.8节“调整”展示了如何关闭这些更新。一些文件系统通过延迟和分组访问时间戳写入来优化,以减少对活动工作负载的干扰。
8.3.16 Capacity
当文件系统填满时,性能可能会因为几个原因而下降。在写入新数据时,可能需要更多时间来定位磁盘上的空闲块以进行计算,并执行任何磁盘I/O操作。磁盘上的空闲空间很可能更小,分布更稀疏,这会导致由于更小的I/O或随机I/O而降低性能。这个问题有多严重取决于文件系统类型、其在磁盘上的布局和存储设备。接下来的部分将介绍各种文件系统类型。
8.4 Architecture
本节介绍通用和特定的文件系统架构,从I/O堆栈、VFS、文件系统缓存和特性、常见文件系统类型、卷和池开始。在确定要分析和优化哪些文件系统组件时,这样的背景知识非常有用。要了解更深入的内部结构和其他文件系统主题,请参考源代码(如果可用)和外部文档。本章末尾列出了一些相关资源。
8.4.1 File System I/O Stack

图8.6展示了文件系统I/O堆栈的一般模型。具体的组件和层取决于操作系统类型、版本和使用的文件系统。完整的图表请参见第3章“操作系统”。这显示了I/O通过内核的路径。从系统调用直接到磁盘设备子系统的路径称为原始I/O。通过VFS和文件系统的路径是文件系统I/O,包括跳过文件系统缓存的直接I/O。
8.4.2 VFS
VFS(虚拟文件系统接口)为不同的文件系统类型提供了一个通用接口。其位置显示在图8.7中。

一些操作系统(包括最初的SunOS实现)将VFS视为两个接口:VFS和vnode,如在早期文件系统模型中逻辑上划分的那样[McDougall 06a]。VFS包括文件系统范围的操作,如挂载和卸载。vnode接口包括VFS索引节点(vnode)文件操作,例如打开、关闭、读取和写入。
Linux VFS接口使用的术语可能有点令人困惑,因为它重用术语inode和superblock来引用VFS对象,这些术语源自Unix文件系统的磁盘数据结构。Linux中用于描述这些对象的术语磁盘数据结构通常以它们的文件系统类型作为前缀,例如,ext4_inode 和 ext4_super_block。这些 VFS 索引节点和 VFS 超级块仅存在于内存中。
VFS 接口还可以作为衡量任何文件系统性能的共同位置。通过使用操作系统提供的统计信息或静态或动态跟踪,可能可以实现这一点。
8.4.3 File System Caches
Unix最初只有缓冲高速缓存来提高块设备访问性能。如今,Linux和Solaris拥有多种不同类型的高速缓存。
本节从基于Solaris系统开始,讨论其中一些高速缓存的起源。
Solaris
图8.8显示了基于Solaris系统的文件系统缓存概况,显示了UFS和ZFS的缓存。

这些高速缓存中有三个是操作系统通用的:旧缓冲高速缓存、页面高速缓存和目录名称缓存(DNLC)。其余的是特定于文件系统的,稍后会进行解释。
旧缓冲高速缓存
最初的Unix在块设备接口处使用缓冲高速缓存来缓存磁盘块。这是一个单独的、固定大小的高速缓存,并且随着页面高速缓存的添加,在平衡它们之间的不同工作负载以及双重缓存和同步开销方面存在调优问题。通过使用页面高速缓存来存储缓冲高速缓存,即SunOS引入的一种称为统一缓冲高速缓存的方法,这些问题在很大程度上得到了解决,如图8.9所示。

在Solaris中,原始的(“旧的”)缓冲高速缓存仍然存在,仅用于UFS索引节点和文件元数据,这些数据是通过它们的块位置而不是文件进行寻址。其大小是动态的,访问计数可以从kstat中观察到。
索引节点高速缓存也是动态增长的,至少保存所有已打开文件(已引用)的索引节点,以及由DNLC映射的那些索引节点。还会在一个空闲队列上保留一些额外的索引节点。
页面缓存
页面缓存是在1985年SunOS 4进行虚拟内存重写期间引入的,并在SVR4中添加[Vahalia 96]。它缓存虚拟内存页面,包括映射的文件系统页面。对于文件访问,它比需要为每次查找从文件偏移量转换为磁盘偏移量的缓冲高速缓存更有效。
多个文件系统类型使用页面缓存,包括最初的消费者UFS和NFS(但不包括ZFS)。页面缓存的大小是动态的,它会增长以利用可用内存,在应用程序需要时再次释放内存。
脏页内存,正在用于文件系统的页面,由一个称为文件系统刷新守护程序(fsflush)的内核线程写入磁盘,该守护程序定期扫描整个页面缓存。如果存在系统内存不足,另一个内核线程——分页守护程序(pageout,也称为页面扫描器)可能会找到并调度脏页写入磁盘,以便释放内存页面供重新使用(请参阅第7章,内存)。为了可观察性,pageout和fsflush显示为PID 2和3,即使它们是内核线程而不是进程。
页面缓存有两个主要的内核驱动程序:segvn,用于将文件映射到进程地址空间,以及segmap,用于缓存文件系统的读取和写入。有关这些内容以及页面扫描器的更多详细信息,请参见第7章,内存。
DNLC
目录名称查找缓存(DNLC)记住目录条目到vnode的映射,由Kevin Robert Elz在上世纪80年代初开发。它提高了路径名查找(例如,通过open())的性能,因为当遍历路径名时,每个名称查找都可以检查DNLC以获取直接vnode映射,而不必逐个遍历目录内容。DNLC被设计用于性能和可伸缩性,条目存储在一个哈希表中,由父vnode和目录条目名称进行哈希。
多年来,Solaris的DNLC已经添加了各种功能和性能特性。DNLC最初使用指针作为哈希链的一部分,以及LRU列表的附加指针。Solaris 2.4放弃了LRU指针,从而避免了LRU列表锁竞争。然后通过从哈希链的末端释放来实现LRU行为。Solaris 8增加了两个新特性:负缓存,用于记住不存在条目的查找,以及目录缓存,用于有意地缓存整个目录。负缓存有助于提高失败查找的性能,通常用于库路径查找。目录缓存通过避免扫描目录以查看新文件名是否已被使用,提高了文件创建时的性能。
DNLC的大小可以通过可调参数进行调整,当前大小以及命中和未命中计数可以从kstat中观察到。
Linux
图8.10概述了Linux上的文件系统缓存,展示了标准文件系统类型可用的通用缓存。

缓冲缓存
Linux最初使用类似Unix的缓冲缓存。自Linux 2.4以来,缓冲缓存已存储在页面缓存中(因此在图8.10中有虚线边框),遵循SunOS统一缓冲区方法,避免了双重缓存和同步开销。缓冲缓存功能仍然存在,改善了块设备I/O的性能。
缓冲缓存的大小是动态的,并且可以从/proc中观察到。
页面缓存
页面缓存缓存虚拟内存页面,包括文件系统页面,提高了文件和目录I/O的性能。页面缓存的大小是动态的,当应用程序需要时,它会增长以利用可用内存,并在应用程序需要时再次释放它(以及通过swappiness控制的页面调度;参见第7章,内存)。
已修改并供文件系统使用的内存页会被内核线程刷新到磁盘上。在Linux 2.6.32之前,有一个页面脏数据刷新(pdflush)线程池,根据需要在两个到八个之间。这些线程现已被刷新线程(命名为flush)取代,每个设备创建一个以更好地平衡每个设备的工作负载并提高吞吐量。页面被刷新到磁盘的原因包括:
- 经过一段时间间隔(30秒)
- sync()、fsync()或msync()系统调用
- 脏页过多(dirty_ratio)
- 页面缓存中没有可用页
如果系统内存不足,另一个内核线程——页面换出守护进程(kswapd,也称为页面扫描器)也可能找到并调度脏页写入磁盘,以便释放内存页供重用(参见第7章,内存)。就可观察性而言,从操作系统性能工具中可以看到kswapd和flush线程作为内核任务。
有关页面扫描器的更多详细信息,请参阅第7章,内存。
目录项缓存
目录项缓存(Dcache)记住从目录项(struct dentry)到VFS索引节点的映射,类似于早期的Unix DNLC。这提高了路径名查找的性能(例如,通过open()),因为在遍历路径名时,每个名称查找都可以检查Dcache以获取直接的索引节点映射,而不是逐个遍历目录内容。Dcache条目存储在哈希表中,以进行快速和可扩展的查找(由父级目录项和目录项名进行哈希处理)。
多年来,性能已经得到进一步改善,包括使用读-拷贝-更新-行走(RCU-walk)算法[1]。这试图在不更新目录项引用计数的情况下遍历路径名,因为在多CPU系统上高速率导致缓存一致性问题,这些问题会影响可伸缩性。如果在缓存中遇到不在缓存中的目录项,RCU-walk将恢复到较慢的引用计数遍历(ref-walk),因为在文件系统查找和阻塞过程中需要引用计数。对于繁忙的工作负载,预计目录项很可能被缓存,因此RCU-walk方法将成功。
Dcache还执行负面缓存,记住不存在条目的查找。这提高了失败查找的性能,这种情况通常发生在库路径查找中。
Dcache会动态增长,在系统需要更多内存时通过LRU缩小。其大小可以通过/proc查看。
索引节点缓存
此缓存包含VFS索引节点(struct inode),每个描述文件系统对象的属性,其中许多属性通过stat()系统调用返回。这些属性经常用于文件系统工作负载,例如在打开文件时检查权限,或在修改时更新时间戳。这些VFS索引节点存储在哈希表中,以进行快速和可扩展的查找(通过索引号和文件系统超级块进行哈希处理),尽管大多数查找将通过目录项缓存进行。
索引节点缓存会动态增长,至少保存目录项映射的所有索引节点。当系统内存压力较大时,索引节点缓存将缩小,删除没有相关目录项的索引节点。其大小可以通过/proc查看。
8.4.4 File System Features
除了缓存之外,影响性能的其他关键文件系统特性如下所述。
块与区段
基于块的文件系统将数据存储在固定大小的块中,这些块由存储在元数据块中的指针引用。对于大文件,这可能需要许多块指针和元数据块,并且块的放置可能会变得分散,导致随机I/O。一些基于块的文件系统尝试将块连续放置以避免这种情况。另一种方法是使用可变大小的块,使得文件增大时可以使用更大的块大小,这也减少了元数据开销。
基于区段的文件系统为文件预先分配连续空间(区段),根据需要进行扩展。虽然需要付出空间开销,但这提高了流式传输性能,并且可以改善随机I/O性能,因为文件数据是局部化的。
日志记录
文件系统日志(或日志)记录文件系统的更改,以便在系统崩溃时可以原子地重放这些更改——要么完全成功,要么失败。这使得文件系统可以快速恢复到一致状态。非日志记录的文件系统在系统崩溃时可能会损坏,如果与更改相关的数据和元数据写入不完整。要从这样的崩溃中恢复需要遍历所有文件系统结构,对于大型(几TB)文件系统可能需要数小时。
日志是同步写入磁盘的,并且对于一些文件系统,可以配置为使用单独的设备。一些日志记录同时记录数据和元数据,这会消耗存储I/O资源,因为所有I/O都会被写入两次。其他的只写入元数据,并通过采用写时复制来保持数据完整性。
有一种只包含一个日志的文件系统类型:日志结构化文件系统,其中所有数据和元数据更新都写入连续循环日志。这优化了写入性能,因为写入始终是顺序的,并且可以合并以使用更大的I/O大小。
写时复制
写时复制(COW)文件系统不会覆盖现有块,而是按照以下步骤进行:
1. 将块写入新位置(新副本)。
2. 更新到新块的引用。
3. 将旧块添加到空闲列表中。
这有助于在系统失败时保持文件系统的完整性,并通过将随机写入转换为顺序写入来提高性能。
巡检
这是一个文件系统特性,异步读取所有数据块并验证校验和,以尽早检测到故障驱动器,理想情况下在仍然可以通过RAID恢复的时候。然而,巡检读I/O可能会对性能产生负面影响,因此应该以低优先级发出。
8.4.5 File System Types
这一章的大部分内容描述了可以应用于所有文件系统类型的通用特性。以下部分总结了常用文件系统的特定性能特征。它们的分析和调优将在后续部分中进行。
FFS
许多文件系统都基于FFS,这是为了解决原始Unix文件系统存在的问题而设计的。一些背景信息可以帮助解释当前文件系统的状态。
原始Unix文件系统的磁盘布局包括inode表、512字节的存储块以及用于分配资源时使用的超级块。inode表和存储块将磁盘分区划分为两个范围,这在两者之间进行寻址时会导致性能问题。另一个问题是使用了固定的小块大小512字节,这限制了吞吐量,并增加了存储大文件所需的元数据(指针)量。一项试验将此块大小翻倍至1,024字节,然后遇到的瓶颈被描述如下:
尽管吞吐量翻了一番,但旧文件系统仍然只使用了大约四分之一的磁盘带宽。主要问题在于,尽管空闲列表最初按最佳方式排序以进行访问,但随着文件的创建和删除,它很快就变得混乱起来。最终,空闲列表变得完全随机,导致文件在磁盘上随机分配其块。这迫使在每次块访问之前进行寻道。尽管旧文件系统在最初创建时提供了高达175千字节/秒的传输速率,但由于数据块放置的随机化,经过几周适度使用后,该速率降至30千字节/秒。
这段摘录描述了空闲列表碎片化,随着文件系统的使用,这会随着时间的推移而降低性能。

伯克利快速文件系统(FFS)通过将分区分成多个柱面组来改善性能,如图8.11所示,每个柱面组都有自己的inode数组和数据块。文件inode和数据尽可能保持在同一个柱面组内,如图8.12所示,从而减少了磁盘寻址。相关的其他数据也被放置在附近,包括目录及其条目的inode。inode的设计类似(这里没有显示三重间接块)。

块大小增加到最小的4 K字节,提高了吞吐量。这减少了存储文件所需的数据块数量,因此间接块需要引用这些数据块的数量也减少了。由于间接指针块也更大,所以需要的间接指针块数量进一步减少了。为了在处理小文件时提高空间效率,每个块可以分成1 K字节的片段。
FFS的另一个性能特征是块交错:将磁盘上的顺序文件块之间放置一个或多个块的间隔[Doeppner 10]。这些额外的块给了内核和处理器时间来发出下一个顺序文件读取,因为它们在那时与控制磁盘更直接相关。如果没有交错,下一个块可能会在准备发出读取之前经过磁头,导致等待几乎完整旋转的延迟。
UFS
1984年,FFS作为UFS([McDougall 06a]中的SunOS 1.0)引入。在接下来的二十年中,向SunOS UFS添加了各种功能:I/O聚类、文件系统增长、多TB支持、日志记录、直接I/O、快照、访问控制列表(ACL)、扩展属性。Linux目前支持读取UFS,但不支持写入,而是支持另一个类似UFS的文件系统(ext3)。
UFS的关键性能特征包括以下内容:
- I/O聚类:通过延迟写入,将数据块分组在磁盘上,直到填满一个聚类,从而使它们被顺序放置。当检测到顺序读工作负载时,UFS执行预取(称为读取前瞻),通过读取这些聚类来执行。
- 日志记录(日志化):仅针对元数据。这提高了系统崩溃后的启动性能,因为日志重放可以避免运行fsck(文件系统检查)的需要。它还可以通过合并元数据写入来改善某些写入工作负载的性能。
- 直接I/O:绕过页面缓存,避免为数据库等应用程序进行双重缓存。
可配置功能在mkfs_ufs(1M)手册页中有文档。有关UFS及其内部的更多信息,请参阅Solaris Internals第2版,第15章[McDougall 06a]。
ext3
Linux扩展文件系统(ext)于1992年开发,是Linux及其VFS的第一个文件系统,基于原始Unix文件系统。第二个版本,1993年的ext2,包括来自FFS的多个时间戳和柱组。1999年的第三个版本,ext3,包括文件系统增长和日志记录。
关键性能特征,包括自发布以来添加的功能,包括:
- 日志记录:有序模式或日志模式,仅针对元数据或元数据和数据。日志记录提高了系统在崩溃后的启动性能,避免运行fsck的需要。它还可以通过合并元数据写入来改善某些写入工作负载的性能。
- 日志设备:可以使用外部日志设备,以便日志工作负载不与读取工作负载竞争。
- Orlov块分配器:将顶级目录分布在柱组中,使子目录和内容更有可能共同定位,减少随机I/O。
- 目录索引:为文件系统添加了散列B树,用于加快目录查找速度。
可配置功能在MKE2FS(8)手册页中有文档。
ext4
Linux ext4文件系统于2008年发布,通过添加各种功能和性能改进扩展了ext3:范围、大容量、使用fallocate()进行预分配、延迟分配、日志校验、更快的fsck、多块分配器、纳秒级时间戳和快照。
关键性能特征,包括自发布以来添加的功能,包括:
- 范围:范围改善连续放置,减少随机I/O并增加顺序I/O的I/O大小。
- 预分配:通过fallocate()系统调用,允许应用程序预先分配空间,这些空间可能是连续的,从而提高后续写入性能。
- 延迟分配:块分配被延迟至刷新到磁盘,允许写入组(通过多块分配器)以减少碎片化。
- 更快的fsck:未分配的块和inode条目被标记,减少fsck时间。
可配置功能在MKE2FS(8)手册页中有文档。某些功能,例如范围,可以应用于ext3文件系统。
ZFS
ZFS是由Sun Microsystems开发并于2005年发布的,它将文件系统与卷管理器相结合,并包括许多企业级特性:池化存储、日志记录、写时复制、自适应替换缓存(ARC)、大容量、可变大小块、动态条带化、多预读流、快照、克隆、压缩、数据校验和128位校验和。随着更新,还添加了其他功能,包括(其中一些将在下文中进一步解释)热备份、双奇偶校验RAID、gzip压缩、SLOG、L2ARC、用户和组配额、三重奇偶校验RAID、数据去重、混合RAID分配和加密。这些功能使ZFS成为文件服务器(文件存储器)的理想选择,Sun/Oracle和其他公司基于开源的ZFS版本开发了这些服务器。
自发布以来增加的主要性能特性包括:
池化存储:所有存储设备都放置在一个池中,从中创建文件系统。这允许所有设备并行使用,以获得最大吞吐量和IOPS。可以使用不同的RAID类型:0、1、10、Z(基于RAID-5)、Z2(双奇偶校验)和Z3(三重奇偶校验)。
写时复制(COW):按组顺序写入数据。
日志记录:ZFS刷新更改的事务组(TXGs),这些更改作为整体成功或失败,因此磁盘上的格式始终保持一致。这也批处理写操作,提高异步写入吞吐量。
自适应替换缓存(ARC):通过同时使用多种缓存算法(最近使用的(MRU)和最频繁使用的(MFU)),实现高缓存命中率。主存储器在这些算法之间进行平衡,根据它们的性能进行调整,通过维护额外的元数据(幽灵列表)来了解如果其中一个算法占据了整个主存储器将如何执行。
可变块大小:每个文件系统都有一个可配置的最大块大小(记录大小),可以选择以匹配工作负载。较小的大小用于较小的文件。
动态条带化:这在所有存储设备上进行条带化,以获得最大吞吐量,并在添加设备时将额外的设备包含在条带中。
智能预读:ZFS根据需要应用不同类型的预读:对于元数据、znodes(文件内容)和vdevs(虚拟设备)。
多预读流:单个文件上的多个流式读取器可以创建随机I/O工作负载,因为文件系统在它们之间寻找(这在UFS中是一个问题)。ZFS跟踪各个预读流,允许新的流加入它们,并有效地发出I/O。
快照:由于COW架构,可以几乎即时创建快照,推迟复制新块直到需要为止。
ZIO管道:设备I/O经过一系列阶段的处理,每个阶段由一组线程提供服务,以提高性能。
压缩:支持多种算法,通常由于CPU开销而降低性能。lzjb(Lempel-Ziv Jeff Bonwick)选项是轻量级的,通过降低I/O负载(因为它被压缩)可以在一定程度上提高存储性能,但会牺牲一些CPU性能。
SLOG:ZFS单独的意向日志允许将同步写入写入到单独的设备中,避免与池磁盘工作负载发生冲突。在系统故障时,写入SLOG只能被读取,以进行回放。这可以极大地提高同步写入的性能。
L2ARC:第二级缓存,用于在基于闪存的固态硬盘(SSD)上缓存随机读取工作负载。它不缓冲写入工作负载,只包含已经存在于存储池磁盘上的干净数据。L2ARC扩展了系统的缓存范围,有助于避免工作负载超出主存储器缓存时的性能急剧下降。它还提供滞后效应,因为与主存储器相比,它的填充速度较慢,它将包含长期数据的副本。如果干扰污染了主存储器缓存,L2ARC可以快速恢复“热”主存储器缓存状态。
vdev缓存:类似于原始缓冲缓存的作用,ZFS使用每个虚拟设备的独立vdev缓存,支持LRU和预读。(这在某些操作系统中可能已被禁用。)
数据去重:避免记录相同数据的多个副本的文件系统级特性。这个功能对性能有显著的影响,既有利(减少设备I/O),也有弊(当哈希表不再适合主存储器时,设备I/O会膨胀,可能会显著增加)。初始版本仅适用于哈希表预计始终适合主存储器的工作负载。
L2ARC和SLOG是ZFS混合存储池(HSP)模型的一部分,智能地在ZFS存储池中使用读取和写入优化的固态硬盘(SSD)。读取优化的SSD的价格/性能比介于主存储器和磁盘之间,使其适用于作为额外缓存层使用。
还包括其他次要的性能特性,例如“不在乎间隙”,在适当时发出更大的读取,即使不需要小部分(间隙);以及混合RAID,支持一个池中的不同策略。
与其他文件系统相比,ZFS的一个行为可能会降低性能:默认情况下,ZFS向存储设备发出缓存刷新命令,以确保写入在断电情况下已完成。这是ZFS的完整性特性之一;然而,代价是可能会导致必须等待缓存刷新的ZFS操作产生延迟,并且某些工作负载在ZFS上的表现可能会比其他文件系统差。可以调整ZFS以避免执行缓存刷新以提高性能;然而,与其他文件系统一样,这会引入部分写入和断电时数据损坏的风险,取决于所使用的存储设备。
有两个项目正在将ZFS引入Linux。一个是由劳伦斯利弗莫尔国家实验室[2]开发的ZFS on Linux,它是一个本地内核端口。另一个是ZFS-FUSE,在用户空间运行ZFS,由于上下文切换开销,其性能预计会较差。
btrfs
Btrfs(B-tree文件系统)基于写时复制的B树结构。这是一种现代文件系统和卷管理器相结合的架构,类似于ZFS,并且预计最终会提供类似的功能集。当前的功能包括池化存储、大容量、范围、写时复制、卷增长和收缩、子卷、块设备添加和移除、快照、克隆、压缩和CRC-32C校验和。该项目由甲骨文公司于2007年启动,目前仍在积极开发中,并被认为是不稳定的。
关键的性能特性包括以下内容:
- 池化存储:存储设备被放置在一个卷中,从中创建文件系统。这允许所有设备并行使用,以获得最大吞吐量和IOPS。可以使用不同的RAID类型:0、1和10。
- 写时复制(COW):按组顺序写入数据。
- 在线平衡:对象可以在存储设备之间移动,以平衡它们的工作负载。
- 范围:改善了顺序布局和性能。
- 快照:由于采用了写时复制的架构,可以几乎即时创建快照,推迟复制新块直到需要为止。
- 压缩:支持zlib和LZO。
- 日志记录:可以创建每个子卷的日志树,以记录同步写入的COW工作负载。
计划中与性能相关的特性包括RAID-5和6、对象级RAID、增量转储和数据去重。
8.4.6 Volumes and Pools
历史上,文件系统是建立在单个磁盘或磁盘分区之上的。卷和存储池允许文件系统建立在多个磁盘上,并可以使用不同的RAID策略进行配置(见第9章《磁盘》)。
卷将多个磁盘呈现为一个虚拟磁盘,文件系统建立在其上。如果建立在整个磁盘上(而不是切片或分区),卷会隔离工作负载,减少争用的性能问题。
卷管理软件包括Linux系统的逻辑卷管理器(LVM)和Solaris卷管理器(SVM)。卷或虚拟磁盘也可以由硬件RAID控制器提供。

存储池包括存储池中的多个磁盘,可以从中创建多个文件系统。在图8.13中显示了与卷进行对比的存储池。存储池比卷存储更灵活,因为无论支持设备如何,文件系统都可以增长和收缩。这种方法被现代文件系统(包括ZFS和btrfs)所采用。
存储池可以使用所有磁盘设备来支持所有文件系统,提高性能。工作负载不会被隔离;在某些情况下,可以使用多个存储池来分隔工作负载,尽管这会导致一定的灵活性降低,因为磁盘设备必须最初放置在一个池中或另一个池中。
在使用软件卷管理器或存储池时,额外的性能考虑包括以下内容:
- 条带宽度:与工作负载匹配。
- 可观察性:虚拟设备利用可能会令人困惑;请检查单独的物理设备。
- CPU开销:特别是在执行RAID奇偶校验计算时。随着现代更快的CPU,这已经不再是问题。
- 重建:也称为重新同步,当向RAID组添加空白磁盘(例如替换故障磁盘)并用必要的数据填充以加入组时。这可能会显著影响性能,因为它会消耗I/O资源,可能持续数小时甚至数天。
随着存储设备容量增长速度超过吞吐量的增长,未来重建可能会成为更严重的问题。
8.5 Methodology
这一部分介绍了文件系统分析和调优的各种策略和练习。这些主题在表8.3中有总结。

更多策略和这些主题的介绍,请参见第2章《方法论》。
这些策略可以单独遵循,也可以组合使用。我的建议是按照以下顺序开始使用这些策略:延迟分析、性能监控、工作负载特征化、微基准测试、静态分析和事件跟踪。您可以提出不同的组合和顺序,在您的环境中找到最佳的方法。
第8.6节《分析》展示了应用这些方法的操作系统工具。
8.5.1 Disk Analysis
一个常见的策略是忽略文件系统,而是专注于磁盘性能。这种做法假设最糟糕的I/O是磁盘I/O,因此通过仅分析磁盘,您便方便地聚焦于问题的预期来源。
在文件系统较简单且缓存较小的情况下,这通常是有效的。然而,如今这种方法变得令人困惑,并且忽略了整个类别的问题(请参见第8.3.12节《逻辑I/O与物理I/O之间的区别》)。
8.5.2 Latency Analysis
对于延迟分析,首先要测量文件系统操作的延迟。这应该包括所有对象操作,而不仅仅是I/O(例如,包括sync())。
操作延迟 = 时间(操作完成) - 时间(操作请求)
这些时间可以从附近的四个层中的任何一个进行测量,如表8.4所示。

选择层可能取决于工具的可用性。请检查以下内容:
应用程序文档:一些应用程序已经提供文件系统延迟指标,或者具有启用收集这些指标的功能。
操作系统工具:操作系统通常也会提供指标,最好是针对每个文件系统或应用程序分别统计。
动态跟踪:如果您的系统支持动态跟踪,可以通过自定义脚本检查所有层,无需重新启动任何内容。
延迟可能呈现为
每个间隔的平均值:例如,每秒的平均读取延迟
完整分布:作为直方图或热力图;请参见第8.6.18节《可视化》
每个操作的延迟:列出每个操作;请参见第8.5.5节《事件跟踪》
对于高缓存命中率(超过99%)的文件系统,每个间隔的平均值可能会受到缓存命中延迟的影响。当存在重要但难以从平均值中看到的高延迟实例(离群值)时,这可能是不幸的。检查完整分布或每个操作的延迟允许调查这些离群值,以及不同延迟层级(包括文件系统缓存命中和未命中)的影响。
一旦发现高延迟,继续深入分析文件系统以确定来源。
Transaction Cost
将文件系统延迟表示为应用程序事务(例如,数据库查询)中等待文件系统的总时间的另一种方法是:
文件系统中百分比时间 = 100 * 总阻塞文件系统延迟 / 应用程序事务时间
这允许以应用程序性能的术语量化文件系统操作的成本,并预测性能改进。该指标可以表示为在间隔期间所有事务的平均值,或者针对单个事务。

图8.14显示了用于服务事务的应用程序线程所花费的时间。该事务发出单个文件系统读取请求;应用程序阻塞并等待其完成,转移到了非 CPU 状态。在这种情况下,总阻塞时间是单个文件系统读取的时间。如果在事务期间调用了多个阻塞 I/O,则总时间为它们的总和。
作为具体示例,一个应用程序事务需要 200 毫秒,期间在多个文件系统 I/O 上等待了总共 180 毫秒。应用程序由文件系统阻塞的时间为 90%(100 * 180 毫秒 / 200 毫秒)。消除文件系统延迟可能最多可以将性能提高 10 倍。
另一个例子,如果一个应用程序事务需要 200 毫秒,在此期间仅花费了 2 毫秒在文件系统中,则文件系统——以及整个磁盘 I/O 栈——仅占事务运行时间的 1%。这个结果非常有用,因为它可以将性能调查引导到真正的延迟源,并避免浪费时间在不必要的地方进行调查。
如果应用程序正在发出非阻塞 I/O,那么在文件系统响应时应用程序可以继续在 CPU 上执行。在这种情况下,阻塞文件系统延迟仅度量应用程序在非 CPU 上阻塞的时间。
8.5.3 Workload Characterization
在容量规划、基准测试和模拟工作负载时,对所施加的负载进行特征化是一项重要的任务。通过识别可以消除的不必要工作,它还可以带来最大的性能提升。
以下是描述文件系统工作负载的基本属性:
- 操作速率和操作类型
- 文件 I/O 吞吐量
- 文件 I/O 大小
- 读/写比例
- 同步写入比例
- 随机与顺序文件偏移访问
操作速率和吞吐量的定义可参考第8.1节中的术语。同步写入和随机与顺序的描述可参考第8.3节中的概念。
这些特征可以从秒到秒地变化,特别是对于按间隔执行的定时应用程序任务。为了更好地描述工作负载,捕获最大值和平均值是必要的。更好的做法是对随时间变化的值进行完整的分布分析。
以下是一个工作负载描述的示例,展示了如何将这些属性结合起来表达:
在一个金融交易数据库中,文件系统具有随机读取的工作负载,平均每秒处理 18,000 次读取,平均读取大小为 2 Kbytes。总操作速率为 21,000 ops/s,其中包括读取、统计、打开、关闭以及约 200 次同步写入每秒。写入速率稳定,而读取速率则有所变化,最高峰可达到每秒 39,000 次读取。
这些特征可以描述单个文件系统实例,也可以描述同类型系统上的所有实例。
高级工作负载特征化/检查清单
可以包含额外细节来描述工作负载。以下列出了一些考虑的问题,这些问题也可以作为一个检查清单,在彻底研究文件系统问题时使用:
- 文件系统缓存命中率是多少?未命中率呢?
- 文件系统缓存容量和当前使用情况是多少?
- 还有哪些其他缓存存在(目录、inode、缓冲),它们的统计数据是什么?
- 哪些应用程序或用户正在使用文件系统?
- 正在访问哪些文件和目录?创建和删除了哪些?
- 是否遇到过任何错误?这是由于无效请求还是文件系统问题引起的?
- 文件系统 I/O 为何发出(用户级调用路径)?
- 文件系统 I/O 应用程式是多么同步?
- I/O 到达时间的分布是怎样的?
这些问题中的许多可以针对每个应用程序或每个文件提出。任何一个问题也可以随着时间的推移进行检查,以寻找最大值和最小值,以及基于时间的变化。此外,还请参阅第2章方法论中的2.5.10节,工作负载特征化,提供了要测量的特征的更高级摘要(谁、为什么、什么、如何)。
性能特性
以下问题(与之前的工作负载特性对比)描述了工作负载的结果性能:
- 平均文件系统操作延迟是多少?
- 是否有任何高延迟的异常值?
- 操作延迟的完整分布是什么样的?
- 系统资源控制是否存在并且对文件系统或磁盘 I/O 有效?
前三个问题可以分别针对每种操作类型进行提问。
8.5.4 Performance Monitoring
性能监控可以识别出活动问题和随时间变化的行为模式。文件系统性能的关键指标是:
- 操作速率
- 操作延迟
操作速率是应用负载的最基本特性,而延迟则是产生的性能结果。正常或不良延迟的值取决于您的工作负载、环境和延迟要求。如果您不确定,可以进行已知良好和不良工作负载的微基准测试,以调查延迟情况(例如,通常从文件系统缓存中命中的工作负载与通常未命中的工作负载)。请参阅第8.7节,实验。
操作延迟指标可以作为每秒平均值进行监控,并可以包括其他值,如最大值和标准偏差。理想情况下,可以检查延迟的完整分布,例如使用直方图或热力图,以查找异常值和其他模式。
速率和延迟也可以记录每种操作类型(读取、写入、stat、打开、关闭等)的情况。这将极大地帮助工作负载和性能变化的调查,通过识别特定操作类型的差异。
对于实施了基于文件系统的资源控制(例如ZFS I/O限流)的系统,可以包含统计信息,以显示何时使用了限流。
8.5.5 Event Tracing
事件跟踪捕获每个文件系统操作的详细信息。对于观察性分析来说,这是最后的手段。由于捕获和保存这些详细信息会增加性能开销,通常将它们写入日志文件以供后续检查。这些日志文件可以包含每个操作的以下详细信息:
- 文件系统类型
- 文件系统挂载点
- 操作类型:读取、写入、stat、打开、关闭、mkdir等
- 操作大小(如果适用):字节
- 操作开始时间戳:操作发出到文件系统的时间
- 操作完成时间戳:文件系统完成操作的时间
- 操作完成状态:错误
- 路径名(如果适用)
- 进程ID
- 应用程序名称
开始和完成时间戳允许计算操作延迟。许多跟踪框架允许在跟踪过程中进行计算,因此可以计算并将延迟包含在日志中。它还可以用于过滤输出,只记录超过某个阈值的操作。文件系统操作速率可以达到每秒数百万次,因此在适当的情况下进行过滤可能是一个很好的主意。
事件跟踪可以在第8.5.2节中列出的四个层级中的任何一个执行。有关示例,请参阅第8.6节,分析。
8.5.6 Static Performance Tuning
静态性能调优侧重于已配置环境的问题。对于文件系统性能,要检查静态配置的以下方面:
- 挂载和活动使用的文件系统数量是多少?
- 文件系统记录大小是多少?
- 是否启用了访问时间戳?
- 是否启用了其他文件系统选项(压缩、加密等)?
- 文件系统缓存如何配置?最大大小是多少?
- 其他缓存(目录、inode、缓冲区)如何配置?
- 是否存在并使用二级缓存?
- 存在和使用的存储设备数量是多少?
- 存储设备的配置是什么?RAID吗?
- 使用了哪些文件系统类型?
- 文件系统(或内核)的版本是什么?
- 是否存在应考虑的文件系统错误/补丁?
- 是否对文件系统I/O使用了资源控制?
回答这些问题可以揭示被忽视的配置选择。有时系统被配置为适应一种工作负载,然后被重新用于另一种用途。这种方法将重新审视这些选择。
8.5.7 Cache Tuning
内核和文件系统可能使用许多不同的缓存,包括缓冲区缓存、目录缓存、inode缓存和文件系统(页)缓存。各种缓存在第8.4节“架构”中进行了描述,可以按照第2章“方法论”中第2.5.17节“缓存调优”的描述进行调整。总的来说,检查存在哪些缓存,检查它们是否正常工作,检查它们的工作情况如何,检查它们的大小,然后为缓存调整工作负载,为工作负载调整缓存。
8.5.8 Workload Separation
某些类型的工作负载在配置为使用自己的文件系统和磁盘设备时可以获得更好的性能。这种方法被称为使用“独立的磁盘”,因为通过在两个不同的工作负载位置之间进行寻址来创建随机I/O对于旋转磁盘尤其不利(详见第9章“磁盘”)。
例如,数据库可以从为其日志文件和数据库文件使用单独的文件系统和磁盘受益。
8.5.9 Memory-Based File Systems
另一种改善性能的配置方法是使用基于内存的文件系统。这些文件系统保留在内存中,以便尽快提供文件内容。它们通常仅作为解决方案部署,因为许多应用程序在进程内存中具有自己的(可配置的)应用程序特定缓存,通过文件和系统调用接口访问比通过文件更高效。在现代系统中,使用大型文件系统缓存,通常不值得使用基于内存的文件系统。
/tmp
标准的/tmp文件系统用于存储临时文件,通常配置为基于内存。例如,Solaris使用tmpfs作为/tmp,它是一个由交换设备支持的基于内存的文件系统。Linux也有一个tmpfs,用于几个特殊的文件系统类型。
8.5.10 Micro-Benchmarking
用于文件系统和磁盘基准测试的基准工具(有很多种)可以用来测试不同文件系统类型或文件系统内的设置在给定工作负载下的性能。可能测试的典型因素包括:
操作类型:读取、写入和其他文件系统操作的速率
I/O 大小:从 1 字节到 1 M 字节及更大
文件偏移模式:随机或顺序
随机访问模式:均匀随机或帕累托分布
写入类型:异步或同步(O_SYNC)
工作集大小:它在文件系统缓存中的适应程度
并发性:正在进行中的 I/O 数量,或执行 I/O 的线程数量
内存映射:通过 mmap() 进行文件访问,而不是 read()/write()
缓存状态:文件系统缓存是“冷”(未填充)还是“热”
文件系统可调参数:可能包括压缩、数据去重等
常见的组合包括随机读取、顺序读取、随机写入和顺序写入。
最关键的因素通常是工作集大小:在基准测试期间访问的数据量。根据基准测试的不同,这可能是正在使用的文件的总大小。小的工作集大小可能完全从主内存中的文件系统缓存中返回(DRAM)。大的工作集大小可能主要从存储设备(磁盘)返回。性能差异可能是多个数量级。
考虑不同基准测试的一般期望,其中包括文件的总大小(工作集大小),见表 8.5。

一些文件系统基准测试工具并不清楚它们正在测试什么,并可能暗示进行磁盘基准测试,但使用小的总文件大小并完全从缓存中返回。参见第 8.3.12 节,逻辑与物理 I/O,了解测试文件系统(逻辑 I/O)与测试磁盘(物理 I/O)之间的区别。
一些磁盘基准测试工具通过使用直接 I/O 绕过缓存和缓冲来操作文件系统。文件系统仍然扮演较小的角色,增加了代码路径开销和文件与磁盘位置之间的映射差异。这有时是测试文件系统的一种有意策略:分析最坏情况性能(0% 缓存命中率)。随着内存系统变得越来越大,这种策略越来越不现实,因为应用程序通常期望有显著的缓存命中率。
有关这个主题的更多信息,请参见第12章“基准测试”。
8.6 Analysis
本节介绍了针对基于Linux和Solaris操作系统的文件系统性能分析工具。有关使用这些工具时要遵循的策略,请参见前一节。
本节中列出的工具如表8.6所示。


这是一些工具和功能的选择,用于支持前面的方法论部分,从系统范围和每个文件系统的可观测性开始,然后进行操作和延迟分析,并最后完成缓存统计。有关它们功能的完整参考,请参阅工具文档,包括man手册。
虽然您可能只对基于Linux或Solaris的系统感兴趣,但考虑一下其他操作系统工具以及它们提供的可观测性,可以获得不同的视角。
8.6.1 vfsstat
vfsstat(1) 是一个类似于 iostat(1M) 的工具,用于 VFS 层级,最初由 Bill Pijewski 为 SmartOS 开发。它会打印文件系统操作(逻辑 I/O)的每个时间间隔摘要,包括用户级应用程序经历的平均延迟。与 iostat(1) 中显示的磁盘 I/O(物理 I/O),包括异步类型的统计信息相比,这些信息对应用程序性能更为相关。

输出的第一行是自启动以来的摘要,其后是每秒的摘要。列包括:
- r/s, w/s:每秒的文件系统读取和写入次数
- kr/s, kw/s:每秒的文件系统读取和写入的千字节数
- ractv, wactv:服务中的读取和写入操作的平均数量
- read_t, writ_t:平均的VFS读取和写入延迟(毫秒)
- %r, %w:VFS读取和写入操作挂起的时间百分比
- d/s, del_t:每秒的I/O节流延迟,以及平均延迟(微秒)
vfsstat(1) 提供了用于描述工作负载以及其结果性能的信息。它还包括有关ZFS I/O节流的信息,该信息在SmartOS云计算环境中用于平衡租户。前面的示例显示了读取工作负载介于1.5到2K读取/秒之间,吞吐量介于73到92兆字节/秒之间。平均延迟非常小,以至于已被舍入为0.0毫秒。这种工作负载很可能是从文件系统缓存返回的,它使文件系统处于忙碌(活动)状态的时间仅占3%到4%。
8.6.2 fsstat
Solaris的fsstat工具报告各种文件系统统计信息:
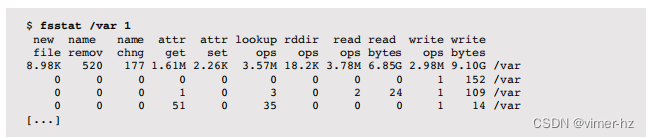
这些信息可用于工作负载特征化,并且可以根据每个文件系统进行检查。请注意,fsstat不包括延迟统计信息。
8.6.3 strace, truss
以前用于详细测量文件系统延迟的操作系统工具包括针对系统调用接口的调试器,例如Linux中的strace(1)和Solaris中的truss(1)。这些调试器可能会影响性能,并且只有在性能开销可接受且无法使用其他方法分析延迟时才适合使用。
以下示例显示了在ext4文件系统上使用strace(1)定时读取的情况:


-tt选项在左侧打印相对时间戳,-T在右侧打印系统调用时间。每个read()调用读取64 KB,第一个调用花费了18毫秒,接着是56微秒(可能是缓存),然后是5毫秒。这些读取是对文件描述符9的。要检查这是否是对文件系统的读取(而不是套接字),要么open()系统调用将在较早的strace(1)输出中可见,要么可以使用其他工具如lsof(8)。
8.6.4 DTrace
DTrace可以从系统调用接口、VFS接口和文件系统内部来检查文件系统行为。这些功能支持工作负载特征化和延迟分析。以下部分介绍了在基于Solaris和Linux的系统上进行文件系统分析的DTrace。除非另有说明,否则DTrace命令适用于两种操作系统。在第四章《可观测性工具》中包括了一个DTrace入门指南。
操作计数
通过应用程序和类型对文件系统操作进行汇总,提供了有用的工作负载特征化的指标。
这个Solaris的一行命令通过应用程序名称,使用fsinfo(文件系统信息)提供程序统计文件系统操作次数:

输出显示,在跟踪期间,名为node的进程执行了25,340次文件系统操作。可以添加一个tick-1s探针来报告每秒的汇总情况,以便观察速率。
操作的类型可以通过对probename进行聚合来报告。例如:

这也展示了如何检查特定应用程序,本例中过滤条件是"splunkd"。
在Linux上,可以从syscall和fbt提供程序观察文件系统操作,直到fsinfo可用为止。例如,使用fbt跟踪内核VFS函数:

在这个跟踪过程中,执行最多文件系统操作的应用程序名为sysbench(一个基准测试工具[3])。
通过对probefunc进行聚合来计算操作类型的数量:

这与sysbench进程匹配,该进程在执行随机读写基准测试时显示了操作的比率。要从输出中去掉vfs_,而不是使用@[probefunc],可以使用@[probefunc + 4](指针加偏移量)。
文件打开
之前的一行命令使用DTrace来汇总事件计数。接下来的示例演示了单独打印所有事件数据,即在此情况下,系统范围内open()系统调用的详细信息:

opensnoop是来自DTraceToolkit的基于DTrace的工具;它默认包含在Oracle Solaris 11和Mac OS X中,并可用于其他操作系统。它提供了对文件系统工作负载的某种视图,显示了open()的进程、路径名和错误,这对性能分析和故障排除都很有用。在这个示例中,nginx进程遇到了一个打开失败的情况(ERR 2 == 文件未找到)。其他常用的DTraceToolkit脚本包括rwsnoop和rwtop,它们跟踪和汇总逻辑I/O。rwsnoop跟踪read()和write()系统调用,而rwtop使用sysinfo提供程序汇总吞吐量(字节)。
系统调用延迟
这个一行命令在系统调用接口处测量文件系统的延迟,并将其汇总为以纳秒为单位的直方图:

该分布显示了两个峰值,第一个在4到16微秒之间(缓存命中),第二个在2到8毫秒之间(磁盘读取)。与quantize()不同,avg()函数可以用于显示平均值(均值)。然而,这将对两个峰值进行平均,这可能会产生误导性。
这种方法跟踪单个系统调用,本例中为read()。要捕获所有文件系统操作,需要跟踪所有相关的系统调用,包括每种类型的变体(例如,pread()、pread64())。这可以通过构建一个脚本来捕获所有类型,或者针对给定的应用程序,通过DTrace检查它使用的系统调用类型,然后只跟踪那些类型来执行。
这种方法还捕获了所有文件系统活动,包括非存储文件系统,如sockfs。对于这个一行命令,文件系统类型通过检查fds[arg0].fi_fs的值来进行过滤,该值将文件描述符(read()的arg0)转换为文件系统类型(fds[].fi_fs)。在这种情况下,还可以应用其他有用的过滤器,例如按应用程序名称或PID、挂载点或路径名组件进行过滤。
请注意,此延迟可能会直接影响应用程序的性能,如第8.3.1节“文件系统延迟”所述。这取决于延迟是在应用程序请求期间遇到的,还是在异步后台任务期间遇到的。您可以使用DTrace开始回答这个问题,方法是捕获用于系统调用I/O的用户级堆栈跟踪,这可能会解释为什么执行了该操作(例如,使用@[ustack(), "ns"]进行聚合)。这可能会根据应用程序的复杂性和其源代码变得更加复杂。
VFS延迟
VFS接口可以通过静态提供程序(如果存在)或通过动态跟踪(fbt提供程序)进行跟踪。
在Solaris上,可以通过fop_*()函数跟踪VFS,例如:

与先前的系统调用示例不同,这显示了一个完全缓存的工作负载。这个一行命令还具有更广泛的可见性,因为它匹配了所有的读取变体。
其他VFS操作也可以类似地进行跟踪。列出入口探针:

请注意,fbt提供程序被认为是一个不稳定的接口,因此任何基于fbt的一行命令或脚本可能需要更新,以匹配随着内核变化而变化的情况(尽管VFS实现并不经常更改)。
在Linux上,可以使用DTrace原型:

这次的谓词匹配的是ext4文件系统。可以看到缓存命中和未命中的峰值,伴随着预期的延迟。
列出VFS函数入口探针:


块设备I/O堆栈
检查块设备I/O的内核堆栈跟踪是了解文件系统内部工作原理以及导致磁盘I/O的代码路径的绝佳方法。它还可以帮助解释超出预期工作负载的附加磁盘I/O(异步、元数据)的原因。
通过在发出块设备I/O时对内核堆栈跟踪进行频率计数来暴露ZFS内部:

输出显示了跟踪过程中堆栈跟踪及其出现次数。
顶部堆栈显示了一个异步的ZFS I/O(来自运行ZIO管道的taskq线程)和一个源自读取系统调用的同步I/O。为了收集更多细节,可以使用DTrace fbt提供程序对这些堆栈的每一行进行单独跟踪,采用相同的方法来暴露ext4:

这条路径显示了一个read()系统调用触发了页面缓存的预读取。
文件系统内部
必要时,可以通过跟踪其实现来确定文件系统中的延迟。
在Solaris上列出ZFS函数入口探针:
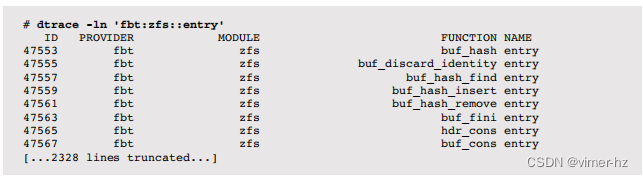
ZFS与VFS有直接的映射关系,使得高级跟踪变得简单。例如,跟踪ZFS读取延迟:

输出显示了大约8μs(缓存命中)左右的I/O峰值,另一个在大约4毫秒(缓存未命中)左右。这是因为zfs_read()在系统调用上同步阻塞。在ZFS内部更深处,函数会发出I/O,但不会阻塞等待其完成,因此测量I/O时间变得更加复杂。
在Linux上,可以以类似的方式跟踪ext4文件系统的内部实现:

一些函数是同步的,例如ext4_readdir(),其延迟可以像前面的zfs_read()示例一样进行测量。
其他函数则不是同步的,包括ext4_readpage()和ext4_readpages()。要测量它们的延迟,需要将I/O发出和完成之间的时间相关联并进行比较。或者,可以在堆栈中更高的位置进行跟踪,就像VFS示例中演示的那样。
慢事件跟踪
DTrace可以打印每个文件系统操作的详细信息,就像第9章“磁盘”中的iosnoop打印每个磁盘I/O一样。然而,在文件系统级别进行跟踪可能会产生更大量的输出,因为它包括文件系统缓存命中。解决这个问题的一种方法是只打印慢操作,这有助于分析特定类别的问题:延迟异常值。
zfsslower.d脚本[4]打印了比设定的毫秒数慢的ZFS级别操作:

这个经过编辑的输出显示了比10毫秒慢的文件系统操作。
高级跟踪
在需要进行高级分析时,动态跟踪可以更详细地探索文件系统。为了提供可能性的想法,表8.7显示了来自DTrace的《文件系统》章节(共108页)的脚本[Gregg 11](这些脚本也可以在网上找到[4])。


尽管这种程度的可观察性令人难以置信,但许多这些动态跟踪脚本都与特定的内核内部绑定在一起,并且需要进行维护以匹配新内核版本中的更改。
作为高级跟踪的一个示例,以下是一个DTraceToolkit脚本,它在从UFS读取50KB文件时跟踪了多个层面的事件:
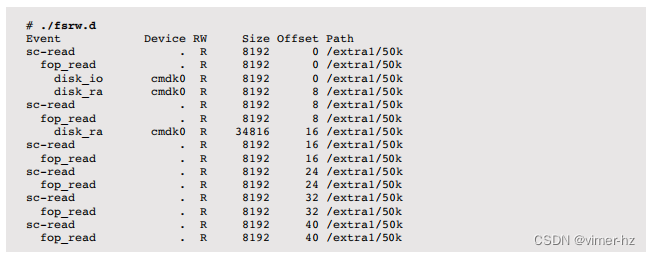

第一个事件是一个8千字节的系统调用读取(sc-read),它被处理为VFS读取(fop_read),然后是磁盘读取(disk_io),随后是下一个8千字节的预读(disk_ra)。接下来的偏移8千字节的系统调用读取不会触发磁盘读取,因为它已经被缓存,而是触发了从偏移16开始的预读,以获取下一个34千字节的数据——50千字节文件的剩余部分。其余的系统调用都从缓存中返回,只有VFS事件可以看到。
8.6.5 SystemTap
SystemTap也可以用于Linux系统中对文件系统事件进行动态跟踪。有关如何将先前的DTrace脚本转换的帮助,请参阅第4章可观测性工具中的第4.4节SystemTap,以及附录E。
8.6.6 LatencyTOP
LatencyTOP是一种报告延迟来源的工具,可以汇总系统范围和每个进程的延迟[5]。它最初是为Linux开发的,后来已经移植到基于Solaris的系统上。
LatencyTOP会报告文件系统的延迟。例如:

顶部部分是系统范围的摘要,底部是一个单独的gzip(1)进程,正在压缩一个文件。gzip(1)的大部分延迟是由于文件读取,占70.2%,而同步写入占27.2%,因为新压缩的文件正在写入。
LatencyTOP需要以下内核选项:CONFIG_LATENCYTOP和CONFIG_HAVE_LATENCYTOP_SUPPORT。
8.6.7 free
Linux的free(1)命令显示内存和交换空间的统计信息:

buffers列显示缓冲区缓存大小,cached列显示页面缓存大小。使用了-m选项以兆字节为单位呈现输出。
8.6.8 top
一些版本的top(1)命令包括文件系统缓存的详细信息。这来自Linux top的一行包括缓冲区缓存大小,这也由free(1)报告:
![]()
有关top(1)的更多信息,请参阅第6章的CPU部分。
8.6.9 vmstat
vmstat(1)命令,类似于top(1),也可能包括有关文件系统缓存的详细信息。有关vmstat(1)的更多详细信息,请参阅第7章内存部分。
Linux
以下命令运行vmstat(1),间隔为1,以提供每秒更新:

buff列显示缓冲区缓存大小,cache列显示页面缓存大小,单位均为千字节(kilobytes)。
Solaris
Solaris vmstat(1)的默认输出不显示缓存大小,但在这里值得一提:

free列的单位为千字节(kilobytes)。自Solaris 9以来,页面缓存被视为空闲内存,并且其大小包含在此列中。
-p选项显示按类型的页面进入/退出详细信息:

这允许将文件系统分页与匿名分页(低内存)区分开来。不幸的是,文件系统列目前不包括ZFS文件系统事件。
8.6.10 sar
系统活动报告工具sar(1)提供各种文件系统统计信息,并可以配置记录历史信息。sar(1)在本书的各个章节中都提到了,因为它提供了不同的统计信息。
Linux
执行sar(1)以报告当前活动的间隔:

-v选项提供以下列:
- dentunusd:目录条目缓存未使用计数(可用条目)
- file-nr:正在使用的文件句柄数
- inode-nr:正在使用的索引节点数
还有一个-r选项,用于打印缓冲区和页面缓存大小的kbbuffers和kbcached列,单位为千字节(kilobytes)。
Solaris
通过指定间隔和次数执行sar(1)以报告当前活动:

-v选项提供inod-sz,显示索引节点缓存大小和最大值。
还有一个-b选项,提供有关旧缓冲区缓存的统计信息。
8.6.11 slabtop
Linux的slabtop(1)命令打印有关内核slab缓存的信息,其中一些用于文件系统缓存:

在没有-o输出模式的情况下,slabtop(1)将刷新并更新屏幕。
Slabs可能包括:
- dentry:目录项缓存
- inode_cache:索引节点缓存
- ext3_inode_cache:用于ext3的索引节点缓存
- ext4_inode_cache:用于ext4的索引节点缓存
slabtop(1)使用/proc/slabinfo,如果启用了CONFIG_SLAB选项,则会存在该文件。
8.6.12 mdb ::kmastat
Solaris上可以使用mdb -k中的::kmastat查看详细的内核内存分配器统计信息,其中包括文件系统使用的各种缓存:

输出很长,显示所有的内核分配器缓存。可以研究正在使用的内存列,以确定哪些缓存存储了大量数据,从而了解内核内存使用情况。在此示例中,ZFS 8K字节文件数据缓存使用了23.5GB的内存。如果需要,还可以动态跟踪到特定缓存的分配,以识别代码路径和消费者。
8.6.13 fcachestat
这是一个针对基于Solaris的系统的开源工具,使用Perl的Sun::Solaris::Kstat库,并打印适合在UFS上进行缓存活动分析的摘要:

第一行是自启动以来的摘要。有五组列,用于各种缓存和驱动程序。ufsbuf是旧的缓冲区缓存,segmap和segvn显示页面缓存的驱动程序。列显示命中/未命中比例的百分比(%hit)和总访问数(total)。
fcachestat可能需要更新才能正常工作;这里包括它是为了展示系统可以提供哪些信息。
8.6.14 /proc/meminfo
Linux的/proc/meminfo文件提供了内存细分的摘要,并被像free(1)这样的工具所读取:

其中包括缓冲区缓存(Buffers)和页面缓存(Cached),并提供系统内存使用的其他高级细分。这些内容在第7章“内存”中有所涉及。
8.6.15 mdb ::memstat
Solaris中,使用mdb -k的::memstat命令可以提供Solaris内存使用的高级细分:
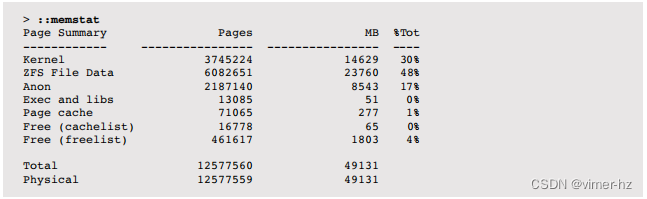
其中包括由ARC缓存的ZFS文件数据,以及包括UFS缓存数据的页面缓存。
8.6.16 kstat
前述工具的原始统计数据可以通过kstat获得,可以通过Perl的Sun::Solaris::Kstat库、C的libkstat库或kstat(1)命令来访问。表8.8中的命令显示了文件系统统计信息的组,以及可用数量(来自最近的内核版本)。

以下是其中一个示例:

虽然kstats可以提供丰富的信息,但它们在历史上并没有被文档化。有时统计名称是自说明的;有时需要查看内核源代码(如果可用)来确定每个统计数据的含义。
可用的统计数据也会因内核版本而异。在最近的SmartOS/illumos内核中,以下计数器已添加:

这些计数器记录了超出描述周期的文件系统操作,并按区域进行记录。在追踪云计算环境中的文件系统延迟时,这些信息可能非常宝贵。
8.6.17 Other Tools
其他工具和可观察性框架可能存在用于调查文件系统性能并描述其使用情况的情况。其中包括:
- df(1):报告文件系统使用情况和容量统计信息
- mount(8):可以显示文件系统挂载选项(静态性能调优)
- inotify:Linux的一个框架,用于监视文件系统事件
一些文件系统类型除了操作系统提供的工具外,还有自己特定的性能工具,例如ZFS。
ZFS
ZFS附带了zpool(1M),它具有用于观察ZFS池统计信息的iostat子选项。它报告池操作速率(读取和写入)和吞吐量。
一个受欢迎的附加工具是arcstat.pl工具,它报告ARC和L2ARC的大小以及命中率和未命中率。例如:


这些统计数据是按照间隔来统计的,其中包括:
- read, miss:总的 ARC 访问次数,未命中次数
- miss%,dm%,pm%,mm%:ARC 未命中百分比的总和,需求访问,预取访问,元数据访问
- dmis,pmis,mmis:需求访问,预取访问,元数据访问的未命中次数
- arcsz,c:ARC 大小,ARC 目标大小
arcstat.pl 是一个 Perl 程序,从 kstat 中读取统计数据。
8.6.18 Visualizations
应用于文件系统的负载可以随时间绘制成折线图,以帮助识别基于时间的使用模式。为了更好地理解,可以分别绘制读取、写入和其他文件系统操作的不同图表。
文件系统延迟的分布预计是双峰的:一个峰值代表文件系统缓存命中时的低延迟,另一个峰值代表缓存未命中(存储设备 I/O)时的高延迟。因此,将分布表示为单一值——如平均值、众数或中位数——是误导性的。

解决这个问题的一种方法是使用能够显示完整分布的可视化工具,比如热力图(热力图在第二章“方法论”中介绍过)。图 8.15 中给出了一个例子,它将时间的变化显示在 x 轴上,将 I/O 延迟显示在 y 轴上。
这个热力图展示了随机读取一个 1 G 字节文件时的文件系统情况。在热力图的前半部分,可以看到介于 3 到 10 毫秒之间的延迟云,这很可能反映了磁盘 I/O。底部的线表示文件系统缓存命中(DRAM)。在超过一半的位置,文件完全被缓存在了DRAM中,磁盘I/O云消失了。
这个例子来自 Joyent Cloud Analytics,它允许选择和隔离文件系统操作类型。
8.7 Experimentation
本节描述了用于主动测试文件系统性能的工具。请参阅第8.5.10节“微基准测试”,了解建议的跟随策略。
在使用这些工具时,建议始终保持 iostat(1) 运行,以确认达到磁盘的工作负载是否符合预期。例如,当测试应轻松适合文件系统缓存的工作集大小时,对于读取工作负载的期望是100%的缓存命中,因此 iostat(1) 不应显示磁盘I/O。iostat(1) 在第9章“磁盘”中有介绍。
8.7.1 Ad Hoc
dd(1) 命令(设备到设备复制)可用于执行顺序文件系统性能的临时测试。以下命令用于以 1 M 字节的 I/O 大小写入,然后读取名为 file1 的 1 G 字节文件:

Linux 版本的 dd(1) 在完成时会打印统计信息。
8.7.2 Micro-Benchmark Tools
有许多可用的文件系统基准测试工具,包括Bonnie、Bonnie++、iozone、tiobench、SysBench、fio和FileBench。以下是一些讨论的工具,按照递增复杂性的顺序排列。还请参阅第12章“基准测试”。
Bonnie, Bonnie++
Bonnie工具是一个简单的C程序,用于在单个文件上测试多个工作负载,从单个线程执行。它最初由Tim Bray于1989年编写。使用方法很简单:

使用 -s 参数设置要测试的文件大小。默认情况下,Bonnie使用100兆字节,该大小在此系统上完全被缓存:

输出包括每个测试期间的CPU时间,当CPU时间达到100%时,这表明Bonnie从未在磁盘I/O上阻塞,而总是从缓存中命中并保持在CPU上。
有一个称为Bonnie-64的64位版本,允许测试更大的文件。还有一个由Russell Coker重写的C++版本,名为Bonnie++。
不幸的是,像Bonnie这样的文件系统基准测试工具可能会误导人,除非您清楚地了解正在测试的内容。第一个结果是一个putc()测试,它可能会因系统库的实现而异,这样就会成为测试的目标,而不是文件系统本身。请参阅第12章“基准测试”的12.3.2节“主动基准测试”中的示例。
fio
The Flexible IO Tester (fio),由Jens Axboe开发,是一个可定制的文件系统基准测试工具,具有许多高级功能[8]。导致我选择使用它而不是其他基准测试工具的两个特点是:
1. 非均匀随机分布,可以更准确地模拟实际访问模式(例如,-random_distribution=pareto:0.9)。
2. 报告延迟百分位数,包括99.00、99.50、99.90、99.95、99.99。
以下是一个示例输出,显示了一个随机读取工作负载,其中包括8 K字节的I/O大小、5 G字节的工作集大小和非均匀访问模式(pareto:0.9):

延迟百分位数(clat)清楚地显示了缓存命中的范围,本例中可达到50th百分位数,因为它们的延迟较低。其余百分位数显示了缓存未命中的影响,包括队列的尾部;在本例中,99.99th百分位数显示了63毫秒的延迟。
尽管这些百分位数缺乏信息来真正理解可能是多模式分布的情况,但它们确实专注于最有趣的部分:较慢模式的尾部(磁盘I/O)。
如果你想要一个类似但更简单的工具,你可以尝试SysBench。另一方面,如果你想要更多的控制权,可以尝试FileBench。
FileBench
FileBench是一个可编程的文件系统基准测试工具,可以通过描述它们的工作负载模型语言来模拟应用程序工作负载。这允许模拟具有不同行为的线程,并指定同步线程行为。它附带了各种这些配置,称为个性化配置,包括用于模拟Oracle 9i I/O模型的配置。不幸的是,FileBench不是一个易于学习和使用的工具,可能只对全职从事文件系统工作的人感兴趣。
8.7.3 Cache Flushing
Linux提供了一种清空(从中删除条目)文件系统缓存的方法,这对于从一致且“冷”缓存状态进行性能基准测试可能很有用,比如在系统启动后。这个机制在内核源代码文档(Documentation/sysctl/vm.txt)中被非常简单地描述为:

目前Solaris系统中没有类似的机制。
8.8 Tuning
已经在第8.5节“方法论”中涵盖了许多调优方法,包括缓存调优和工作负载特征化。后者通过识别和消除不必要的工作,可能会带来最高的调优效果。本节包括具体的调优参数(可调参数)。
调优的具体方式——可用选项和如何设置它们——取决于操作系统版本、文件系统类型和预期的工作负载。以下各节提供了可能可用的示例以及它们可能需要进行调优的原因。涵盖的内容包括应用程序调用和两种示例文件系统类型:ext3和ZFS。有关页面缓存的调优,请参阅第7章“内存”。
8.8.1 Application Calls
第8.3.7节《同步写入》提到,通过使用fsync()来刷新一组逻辑写入,而不是在使用O_DSYNC/O_RSYNC open()标志时单独刷新,可以改善同步写入工作负载的性能。其他可以提高性能的调用包括posix_fadvise()和madvise(),它们提供了缓存合格性的提示。
posix_fadvise()
这个库调用在文件的一个区域上操作,并具有以下函数原型
![]()
该建议可能如表8.9所示。

内核可以使用这些信息来提高性能,帮助它决定何时最好预取数据,以及何时最好缓存数据。这可以提高高优先级数据的缓存命中率,如应用程序建议的那样。请参阅您系统上的man页,以获取建议参数的完整列表。
posix_fadvise()在第3章《操作系统》的第3.3.4节《差异》中被用作示例,因为支持可能会根据内核的不同而变化。
madvise()
这个库调用在内存映射上操作,并具有概要。
![]()
建议可能如表8.10所示。

与posix_fadvise()类似,内核可以利用这些信息来提高性能,包括做出更好的缓存决策。
8.8.2 ext3
在Linux上,可以使用tune2fs(8)命令来调整ext2、ext3和ext4文件系统。还可以在挂载时设置各种选项,可以手动使用mount(8)命令进行设置,也可以在/boot/grub/menu.lst和/etc/fstab中设置启动时的选项。可用的选项在tune2fs(8)和mount(8)的man页面中,可以使用tunefs -l 设备 和 mount(无选项)命令查看当前设置。可以使用mount(8)中的noatime选项禁用文件访问时间戳更新,这样如果文件系统用户不需要这些更新,则会减少后端I/O,从而提高整体性能。
用于提高性能的tune2fs(8)的一个关键选项是
![]()
它使用哈希B树来加速大型目录中的查找。
e2fsck(8)命令可用于重新索引文件系统中的目录。例如:
![]()
e2fsck(8)的其他选项与检查和修复文件系统相关。
8.8.3 ZFS
ZFS支持每个文件系统的大量可调参数(称为属性),还有一些可以在系统范围内设置(/etc/system)。可以使用zfs(1)命令列出文件系统的属性。例如:


(截断的)输出包括属性名称、当前值和来源的列。来源显示了如何设置属性:是从更高级别的ZFS数据集继承的,是默认值,还是在该文件系统上本地设置的。
这些参数也可以使用命令进行设置,并在man页面中进行了描述。与性能相关的关键参数列在表8.11中。

调整最重要的参数通常是记录大小,以匹配应用程序的I/O。它通常默认为128 KB,这对于小范围的随机I/O可能效率低下。请注意,这不适用于小于记录大小的文件,这些文件使用与其文件长度相等的动态记录大小保存。
如果不需要时间戳,禁用atime也可以提高性能(尽管其更新行为已经经过优化)。
表8.12中显示了示例系统范围的ZFS可调参数。(随着ZFS版本的变化,对性能最重要的参数可能会有所不同;表中的这三个参数在您阅读时可能会再次更改。)

在多年的发展中,zfs_txg_synctime_ms和zfs_txg_timeout可调参数的默认值已经降低,这样TXG就会更小,不太可能因为排队而与其他I/O竞争。与其他内核可调参数一样,请查阅供应商文档以获取完整列表、描述和警告。根据公司或供应商政策,设置这些参数可能也被禁止。
关于ZFS调优的更多信息,您可能会喜欢查阅《ZFS邪恶调优指南》[9]。
9 Disks
磁盘I/O可能会导致应用程序延迟显著增加,因此是系统性能分析的重要目标。在高负载下,磁盘成为瓶颈,导致CPU空闲,系统等待磁盘I/O完成。识别和消除瓶颈可以将性能和应用程序吞吐量提高数个数量级。
术语“磁盘”指的是系统的主要存储设备。它们包括磁性旋转磁盘和基于闪存存储的固态硬盘(SSD)。后者主要是为了提高磁盘I/O性能而引入的,它们确实做到了。然而,对于容量和I/O速率的需求也在增加,闪存存储设备也不免遇到性能问题。
本章包括五个部分,前三部分为磁盘I/O分析提供基础,后两部分展示了它在基于Linux和Solaris的系统中的实际应用。这些部分如下:
- 背景介绍了与存储相关的术语、磁盘设备的基本模型和关键的磁盘性能概念。
- 架构提供了存储硬件和软件架构的通用描述。
- 方法论描述了性能分析方法论,包括观察和实验。
- 分析展示了基于Linux和Solaris的系统上进行分析和实验的磁盘性能工具,包括跟踪和可视化。
- 调优描述了示例磁盘可调参数。
上一章讨论了建立在磁盘上的文件系统的性能。
9.1 Terminology
在本章中使用的与磁盘相关的术语包括以下内容:
- 虚拟磁盘:存储设备的仿真。它在系统中显示为单个物理磁盘;然而,它可能由多个磁盘构成。
- 传输:用于通信的物理总线,包括数据传输(I/O)和其他磁盘命令。
- 扇区:传统上大小为512字节的磁盘上的存储块。
- I/O:严格来说,对于磁盘,这仅指读取和写入,并不包括其他磁盘命令。I/O至少包括方向(读取或写入)、磁盘地址(位置)和大小(字节)。
- 磁盘命令:除了读取和写入之外,磁盘可能被命令执行其他非数据传输命令(例如,缓存刷新)。
- 吞吐量:对于磁盘,吞吐量通常指当前的数据传输速率,以每秒字节计量。
- 带宽:这是存储传输或控制器的最大可能数据传输速率。
- I/O延迟:I/O操作的时间,在操作系统堆栈中广泛使用,不仅仅在设备级别。请注意,网络使用此术语的方式不同,延迟是指启动I/O的时间,然后是数据传输时间。
- 延迟异常值:具有异常高延迟的磁盘I/O。
本章还介绍了其他术语。如果需要,词汇表包括基本术语供参考,包括磁盘、磁盘控制器、存储阵列、本地磁盘、远程磁盘和IOPS。另请参阅第2章和第3章中的术语部分。
9.2 Models
以下简单模型说明了磁盘I/O性能的一些基本原理。
9.2.1 Simple Disk
现代磁盘包括一个用于I/O请求的磁盘队列,如图9.1所示。
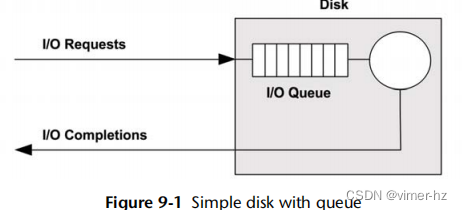
磁盘接受的I/O请求可能在队列中等待或正在被处理。
这个简单的模型类似于杂货店的结账,顾客排队等待服务。它也非常适合使用排队理论进行分析。
虽然这可能暗示着一个先来先服务的队列,但磁盘控制器可以应用其他算法来优化性能。这些算法可能包括对旋转磁盘进行电梯搜索(请参阅第9.4.1节,磁盘类型中的讨论),或者为读和写I/O分别设置队列(特别是对于基于闪存的磁盘)。
9.2.2 Caching Disk
在磁盘上添加一个缓存允许一些读取请求从更快的内存类型中得到满足,如图9.2所示。这可以实现为包含在物理磁盘设备内部的少量内存(DRAM)。
虽然缓存命中的延迟非常低(良好),但通常仍然会出现缓存未命中,返回带有高磁盘设备延迟的情况。
磁盘上的缓存也可以用于提高写入性能,通过将其用作写回缓存。这意味着在数据传输到缓存之后,但在较慢的传输到持久磁盘存储之前,将写入标记为已完成。与之相对应的术语是写直通缓存,它仅在完全传输到下一级之后才完成写入。
9.2.3 Controller
图9.3展示了一个简单类型的磁盘控制器,它连接了CPU I/O传输和存储传输,并连接了磁盘设备。这些也被称为主机总线适配器(HBAs)。
性能可能会受到这些总线、磁盘控制器或磁盘的限制。有关磁盘控制器的更多信息,请参阅第9.4节《体系结构》。
9.3 Concepts
以下是磁盘性能中的重要概念。
9.3.1 Measuring Time
存储设备的响应时间(也称为磁盘I/O延迟)是从I/O请求到I/O完成的时间。它由服务时间和等待时间组成:
- 服务时间:I/O被积极处理(服务)所花费的时间,不包括在队列中等待的时间。
- 等待时间:I/O在队列中等待被处理的时间。
这些概念如图9.4所示,还有其他相关术语。
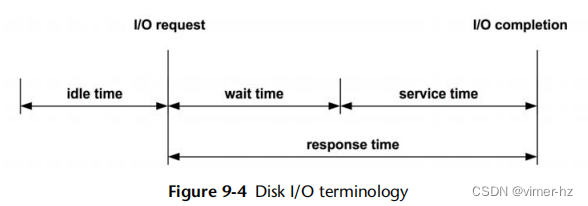
响应时间、服务时间和等待时间都取决于它们所测量的位置。以下是对此进行解释,通过描述操作系统和磁盘上下文中的服务时间(这也是一种简化):
在操作系统(块设备接口)的上下文中,服务时间可以被定义为从发出 I/O 请求到磁盘设备的时间,到完成中断发生的时间。它不包括在操作系统队列中等待的时间,并且仅反映磁盘设备对所请求操作的整体性能。
在磁盘的上下文中,服务时间指的是磁盘积极为 I/O 提供服务的时间,不包括在磁盘自身的磁盘队列上等待的任何时间。 服务时间一词源自于磁盘是由操作系统直接管理的更简单的设备时代,因此操作系统知道磁盘何时在积极为I/O提供服务。 现在磁盘有自己的内部队列,操作系统的服务时间包括在设备队列上等待的时间。 这个操作系统度量标准可能更好地被描述为“磁盘响应时间”。
响应时间这个术语也可以从不同的角度应用。 例如,“磁盘响应时间”可能描述从操作系统观察到的服务时间,而“ I/O响应时间”则是从应用程序的角度来看,可能指系统调用层以下的一切(服务时间,所有等待时间和代码路径执行时间)。
来自块设备接口的服务时间通常被视为磁盘性能的一种度量标准(也是iostat(1)显示的内容); 但是,您应该意识到这是一种简化。 在图9.6中,描绘了一个通用的I/O堆栈,显示了块设备接口下方的三个可能的驱动程序层。 这些任何一个都可以实现自己的队列,或者可能在互斥体上阻塞,从而增加I/O的延迟。 这个延迟包含在从块设备接口测量的服务时间中。
计算时间
通常,操作系统无法直接观察到磁盘服务时间;但是,可以使用IOPS和利用率推断出平均磁盘服务时间:
磁盘服务时间 = 利用率 / IOPS
例如,如果利用率为60%,IOPS为300,则平均服务时间为2毫秒(600毫秒/300 IOPS)。这假设利用率反映了一个只能一次处理一个I/O的单个设备(或服务中心)。磁盘通常可以并行处理多个I/O。
9.3.2 Time Scales
磁盘I/O的时间尺度可以差异巨大,从几十微秒到数千毫秒不等。在时间尺度的最慢端,单个慢速磁盘I/O可能导致应用响应时间不佳;在最快端,磁盘I/O问题可能只会在数量众多时出现(许多快速I/O的总和等于一个慢速I/O)。
为了提供背景信息,表9.1提供了磁盘I/O延迟可能的一般范围的概念。要获取准确和最新的值,请参阅磁盘供应商的文档,并进行您自己的微基准测试。另请参阅第2章《方法论》,了解除磁盘I/O之外的时间尺度。
为了更好地说明涉及的数量级差异,"缩放"列显示了基于虚构的一秒钟内磁盘缓存命中延迟的比较。

这些延迟可能根据环境需求有不同的解释。在企业存储行业工作时,我认为任何超过10毫秒的磁盘I/O都异常缓慢,可能是性能问题的潜在来源。在云计算行业中,对于高延迟有更高的容忍度,特别是在面向网络和客户端浏览器之间已经预期高延迟的Web应用程序中。在这些环境中,磁盘I/O可能只在超过100毫秒(在单个应用程序请求期间或总体上)时成为问题。
这个表格还说明了磁盘可以返回两种类型的延迟:一种是针对磁盘缓存命中的延迟(小于100微秒),另一种是针对未命中的延迟(1–8毫秒或更高,取决于访问模式和设备类型)。由于磁盘将返回这两种延迟的混合,将它们一起表达为平均延迟(正如iostat(1)所做的那样)可能会产生误导,因为这实际上是具有两种模式的分布。请参阅第2章《方法论》中的图2.22,这是一个示例磁盘I/O延迟分布的直方图(使用DTrace测量)。
9.3.3 Caching
磁盘I/O性能最佳的情况是完全避免磁盘I/O。软件堆栈的许多层次都试图通过缓存读取和缓冲写入来避免磁盘I/O,甚至直到磁盘本身。这些缓存的完整列表在《操作系统》第3章的表3.2中,包括应用程序级别和文件系统级别的缓存。在磁盘设备驱动程序级别及以下,它们可能包括表9.2中列出的缓存。
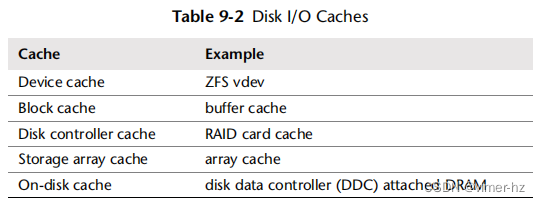
基于块的缓冲缓存在《文件系统》第8章进行了描述。这些磁盘I/O缓存对于提高随机I/O工作负载的性能尤为重要。
9.3.4 Random versus Sequential I/O
磁盘I/O工作负载可以用随机和顺序两个术语来描述,这取决于I/O在磁盘上的相对位置(磁盘偏移量)。这些术语在第8章《文件系统》中讨论过,涉及到文件访问模式。
顺序工作负载也被称为流式工作负载。流式通常在应用程序级别使用,用于描述“对磁盘”的流式读取和写入。
在磁性旋转盘时代,研究随机与顺序磁盘I/O模式非常重要。对于这些情况,随机I/O会增加额外的延迟,因为磁盘磁头在I/O之间进行寻道并且盘片在其间旋转。如图9.5所示,磁头在扇区1和扇区2之间移动需要进行寻道和旋转(实际路径将尽可能直接)。性能调优涉及识别随机I/O,并尝试通过多种方式消除它,包括缓存、将随机I/O隔离到单独的磁盘以及通过磁盘位置调整以减少寻道距离。
其他类型的磁盘,包括基于闪存的固态硬盘(SSD),通常在随机和顺序I/O模式之间表现不同。根据磁盘的不同,可能会存在一些差异,例如,由于其他因素,如地址查找缓存可能会跨越顺序访问但不跨越随机访问。
请注意,从操作系统中看到的磁盘偏移量可能与物理磁盘上的偏移量不匹配。例如,硬件提供的虚拟磁盘可能会将连续的偏移范围映射到多个磁盘上。磁盘可能会以自己的方式重新映射偏移量(通过磁盘数据控制器)。有时,随机I/O并非通过检查偏移量来识别,而是通过测量增加的服务时间来推断。
9.3.5 Read/Write Ratio
除了识别随机与顺序工作负载之外,另一个特征性指标是读取与写入的比例,指的是IOPS或吞吐量。这可以表示为随时间的比率,以百分比的形式,例如,“系统自启动以来读取占80%”。
了解这个比率有助于在设计和配置系统时。读取率高的系统可能最适合增加缓存。写入率高的系统可能最适合增加更多磁盘以增加最大可用吞吐量和IOPS。
读取和写入本身可能是不同的工作负载模式:读取可能是随机I/O,而写入可能是顺序的(特别是对于写时复制文件系统)。它们也可能展示不同的I/O大小。
9.3.6 I/O Size
平均I/O大小(字节)或I/O大小的分布是另一个工作负载特征。较大的I/O大小通常提供更高的吞吐量,尽管会增加每个I/O的延迟。
I/O大小可能会被磁盘设备子系统改变(例如,量化为512字节的块)。自从应用程序级别发出I/O以来,大小可能已被内核组件(如文件系统、卷管理器和设备驱动程序)进行了膨胀和收缩。请参阅第8章文件系统中第8.3.12节《逻辑与物理I/O》中的膨胀和收缩部分。
一些磁盘设备,特别是基于闪存的,对不同的读写大小表现出非常不同的性能。例如,基于闪存的磁盘驱动器可能会在4KB的读取和1MB的写入时表现最佳。理想的I/O大小可能由磁盘供应商记录,也可以使用微基准测试进行识别。当前使用的I/O大小可以通过观察工具找到(参见第9.6节《分析》)。
9.3.7 IOPS Are Not Equal
由于这些最后三个特性,IOPS并非相等,不能直接在不同设备和工作负载之间进行比较。一个IOPS值单独而言意义不大,不能单独使用来准确比较工作负载。例如,在旋转磁盘上,一个5,000个顺序IOPS的工作负载可能比一个1,000个随机IOPS的工作负载快得多。基于闪存内存的IOPS也很难比较,因为它们的I/O性能通常相对于I/O大小和方向(读或写)而言。
为了理解IOPS,应包括其他细节:随机或顺序、I/O大小、读/写。还应考虑使用基于时间的指标,如利用率和服务时间,这些指标反映了结果性能并且可以更容易地进行比较。
9.3.8 Non-Data-Transfer Disk Commands
除了I/O读取和写入之外,磁盘还可以发送其他命令。例如,具有磁盘缓存(RAM)的磁盘可以被命令将缓存刷新到磁盘。这样的命令不是数据传输;数据先前通过写入命令发送到了磁盘。这些命令可能会影响性能,并导致磁盘被利用,而其他I/O处于等待状态。
9.3.9 Utilization
利用率可以被计算为在一个时间段内磁盘忙于主动执行工作的时间。
利用率为0%的磁盘处于“空闲”状态,而利用率为100%的磁盘则持续忙于执行I/O(和其他磁盘命令)。处于100%利用率的磁盘很可能是性能问题的一个来源,特别是如果它们保持在100%一段时间。然而,任何磁盘利用率都可能导致性能不佳,因为磁盘I/O通常是一个缓慢的活动。
在0%和100%之间可能还存在一个点(比如说,60%),在这个点上,由于排队的可能性增加,磁盘的性能不再令人满意,无论是在磁盘队列上还是在操作系统中。成为问题的确切利用率取决于磁盘、工作负载和延迟要求。在第二章方法论的2.6.5节排队理论中的M/D/1和60%利用率部分有更多信息。
要确认高利用率是否导致应用程序问题,请研究磁盘响应时间以及应用程序是否在此I/O上阻塞。应用程序或操作系统可能会异步执行I/O,因此缓慢的I/O并不直接导致应用程序等待。
请注意,利用率是一个时间段的摘要。磁盘I/O可能会突发发生,特别是由于写入刷新,这可能在长时间间隔内进行摘要时被掩盖。在第二章方法论的2.3.11节利用率中有关于利用率度量类型的进一步讨论。
虚拟磁盘利用率
对于由硬件提供的虚拟磁盘(例如,磁盘控制器提供的),操作系统可能只知道虚拟磁盘何时忙碌,但对其构建所依赖的底层磁盘的性能一无所知。这导致了一种情况,即操作系统报告的虚拟磁盘利用率与实际磁盘情况(并且是违反直觉的)显著不同:
- 包含写回缓存的虚拟磁盘在写工作负载期间可能看起来并不繁忙,因为磁盘控制器立即返回写完成,尽管底层磁盘之后可能忙碌。
- 一个100%繁忙的虚拟磁盘,构建在多个物理磁盘之上,可能能够接受更多的工作。在这种情况下,100%可能意味着某些磁盘一直处于繁忙状态,但并非所有磁盘都一直处于繁忙状态,因此某些磁盘可能处于空闲状态。
出于相同的原因,解释操作系统软件创建的虚拟磁盘(软件RAID)的利用率可能会很困难。然而,操作系统应该也会公开物理磁盘的利用率,可以对其进行检查。
一旦物理磁盘达到100%的利用率并且请求更多I/O,它就会变得饱和。
9.3.10 Saturation
饱和度是排队工作量的度量,超出资源可以提供的范围。对于磁盘设备而言,它可以被计算为操作系统中设备等待队列的平均长度(假设它进行排队)。
这提供了一个超过100%利用率点的性能度量。一个利用率为100%的磁盘可能没有饱和(排队),或者它可能有很多,由于I/O的排队而显著影响性能。
可以假设利用率低于100%的磁盘没有饱和。然而,这取决于利用率间隔:在一个时间段内的50%磁盘利用率可能意味着在其中一半时间内利用率达到100%,而在其余时间内处于空闲状态。任何间隔摘要都可能遇到类似的问题。当需要准确了解发生了什么时,可以使用跟踪来检查I/O事件。
9.3.11 I/O Wait
I/O等待是一个基于每个CPU的性能指标,显示了空闲时间,当CPU调度队列上有线程(处于睡眠状态)被阻塞在磁盘I/O上时。这将CPU的空闲时间分成两部分:一部分是没有任务可执行的时间,另一部分是被阻塞在磁盘I/O上的时间。每个CPU的高I/O等待率表明磁盘可能是一个瓶颈,导致CPU在等待磁盘时处于空闲状态。I/O等待可能是一个非常令人困惑的指标。如果另一个CPU密集型进程出现,I/O等待值可能会下降:CPU现在有任务可执行了,而不是处于空闲状态。然而,尽管I/O等待指标下降,但相同的磁盘I/O仍然存在并阻塞线程。有时,当系统管理员升级应用软件并且新版本更高效、使用的CPU周期更少时,会出现相反的情况,从而暴露了I/O等待。这可能会让系统管理员误以为升级导致了磁盘问题,并使性能变差,但实际上磁盘性能保持不变,CPU性能得到了改善。关于如何在Solaris上计算I/O等待,还存在一些微妙的问题。对于Solaris 10发布版,I/O等待指标已被弃用,并且对于仍需要显示它的工具(为了兼容性),该指标已被硬编码为零。一个更可靠的指标可能是应用线程在磁盘I/O上被阻塞的时间。这捕获了应用线程由于磁盘I/O而遭受的痛苦,而不管CPU可能在做什么其他工作。可以使用静态或动态跟踪来测量此指标。I/O等待仍然是Linux系统上一个流行的指标,尽管它具有令人困惑的性质,但成功地用于识别一种类型的磁盘瓶颈:磁盘繁忙,CPU空闲。解释它的一种方式是将任何等待I/O都视为系统瓶颈的迹象,然后调整系统以将其最小化——即使I/O仍然与CPU利用率同时发生。并发I/O更有可能是非阻塞I/O,不太可能引起直接问题。如I/O等待所指示的非并发I/O更可能是应用阻塞I/O,是一个瓶颈。
9.3.12 Synchronous versus Asynchronous
重要的是要理解,如果应用程序I/O和磁盘I/O是异步操作的话,磁盘I/O延迟可能不会直接影响应用程序性能。这种情况通常发生在写回缓存中,其中应用程序I/O提前完成,而磁盘I/O稍后发出。
应用程序可能会使用预读取来执行异步读取,这可能不会在磁盘完成I/O时阻塞应用程序。文件系统可以自行启动此过程以预热缓存(预取)。
即使一个应用程序正在同步等待I/O,该应用程序代码路径也可能是非关键的并且与客户端应用程序请求异步。
有关更详细的解释,请参阅第8章文件系统中的第8.3.9节“非阻塞I/O”、第8.3.5节“预读取”、第8.3.4节“预取”和第8.3.7节“同步写入”。
9.3.13 Disk versus Application I/O
磁盘I/O是各种内核组件(包括文件系统和设备驱动程序)的最终结果。导致这种磁盘I/O的速率和数量与应用程序发出的I/O不匹配的原因有很多。这些原因包括:
- 文件系统的膨胀、紧缩和不相关的I/O。请参阅第8章文件系统中的第8.3.12节“逻辑I/O与物理I/O”。
- 由于系统内存不足而导致的页面调度。请参阅第7章内存中的第7.2.2节“页面调度”。
- 设备驱动程序I/O大小:将I/O大小舍入或分片。
当出现意外时,这种不匹配可能会令人困惑。通过学习体系结构并进行分析,可以理解这种不匹配。
9.4 Architecture
本节描述了磁盘架构,通常在容量规划期间进行研究,以确定不同组件和配置选择的限制。在调查后续性能问题时,还应该检查磁盘架构,以防问题源于架构选择而不是当前的负载和调优。
9.4.1 Disk Types
目前最常用的两种磁盘类型是磁性旋转硬盘和基于闪存存储的固态硬盘(SSD)。这两种提供永久存储;与易失性内存不同,在断电后它们存储的内容仍然可用。
磁性旋转硬盘
也称为硬盘驱动器(HDD),这种类型的磁盘由一个或多个盘片组成,称为盘片,其中充满了氧化铁颗粒。这些颗粒的一小部分可以在两个方向中的一个方向上磁化;此方向用于存储位。盘片旋转,同时带有读写数据电路的机械臂伸展到表面。这些电路包括磁头,一个臂可能有一个以上的磁头,使其能够同时读写多个位。数据存储在盘片的圆形轨道上,每个轨道分为扇区。
由于是机械设备,它们的性能相对较慢。随着基于闪存存储的技术的进步,固态硬盘正在取代旋转硬盘,可以想象有一天旋转硬盘将会过时(以及鼓式磁盘和核心内存)。与此同时,在某些情况下,如经济型高密度存储(每兆字节成本低)中,旋转硬盘仍然具有竞争力。
以下主题总结了旋转硬盘性能中的因素。
搜索和旋转
磁性旋转硬盘的慢I/O通常是由于磁头的搜索时间和盘片的旋转时间,两者都可能需要毫秒级的时间。最理想的情况是,下一个请求的I/O位于当前正在服务的I/O的末尾,这样磁头就不需要搜索或等待额外的旋转。正如前文所述,这被称为顺序I/O,而需要磁头搜索或等待旋转的I/O被称为随机I/O。
有许多策略可以减少搜索和旋转等待时间,包括
- 缓存:完全消除I/O
- 文件系统的放置和行为,包括写入时复制
- 将不同的工作负载分开放置到不同的磁盘上,以避免在工作负载I/O之间进行搜索
- 将不同的工作负载移到不同的系统上(某些云计算环境可以通过这种方式减少多租户效应)
- 电梯搜索,由磁盘自身执行
- 更高密度的磁盘,以紧凑的工作负载位置
- 分区(或“切片”)配置,例如,短距离行驶
另一种减少旋转等待时间的策略是使用更快的磁盘。
磁盘以不同的旋转速度提供,包括每分钟5400、7200、10000(10K)和15000(15K)转。
理论最大吞吐量
如果一个磁盘的最大每磁道扇区数已知,则可以使用以下公式计算磁盘的吞吐量:
\[ \text{max throughput} = \text{max sectors per track} \times \text{sector size} \times \frac{\text{rpm}}{60 \text{ s}} \]
这个公式在过去更适用于准确公开这些信息的老式磁盘。现代磁盘将提供虚拟磁盘映像给操作系统,并公开这些属性的合成值。
短程慢速
短程慢速是指只使用磁盘的外部磁道进行工作负载;其余的要么未使用,要么用于低吞吐量的工作负载(例如,存档)。这减少了寻道时间,因为磁头移动受较小范围的限制,并且磁盘可能将磁头放置在外部边缘,减少闲置后的首次寻道。由于扇区分区(见下一节),外部磁道通常也具有更好的吞吐量。在检查发布的磁盘基准测试时要特别注意短程慢速,特别是那些不包括价格的基准测试,并且可能使用了许多短程慢速的磁盘。
扇区分区
磁盘磁道的长度不同,中心处最短,外侧边缘最长。与固定每磁道扇区数(和位数)不同,扇区分区(也称为多区域记录)增加了长磁道的扇区计数,因为可以物理写入更多扇区。由于旋转速度恒定,较长的外侧边缘磁道提供比内部磁道更高的吞吐量(每秒兆字节)。
扇区大小
存储行业已经制定了一项新的磁盘设备标准,称为高级格式,支持更大的扇区大小,特别是 4 KB。这减少了 I/O 计算开销,提高了吞吐量,同时减少了磁盘每扇区存储的元数据开销。通过称为高级格式 512e 的仿真标准,磁盘固件仍然可以提供 512 字节的扇区。根据磁盘的不同,这可能会增加写入开销,调用读修改写循环将 512 字节映射到 4 KB 扇区。要注意的其他性能问题包括不对齐的 4 KB I/O,它们跨越两个扇区,使得扇区 I/O 膨胀以服务它们。
磁盘缓存
这些磁盘的一个常见组成部分是少量内存(RAM),用于缓存读取的结果和缓冲写入。这段内存还允许将I/O(命令)排队在设备上,并以更高效的方式重新排序。对于SCSI,这被称为标记命令排队(TCQ);对于SATA,它被称为原生命令排队(NCQ)。
电梯寻道
电梯算法(也称为电梯寻道)是命令队列可以提高效率的一种方式。它根据它们在磁盘上的位置重新排列I/O,以最小化磁盘磁头的移动。结果类似于建筑电梯,它不会根据按下楼层按钮的顺序服务楼层,而是上下扫过建筑,停在当前请求的楼层。
当检查磁盘I/O跟踪并发现按完成时间排序的I/O与按启动时间排序的I/O不匹配时,此行为变得明显:I/O无序完成。
虽然这似乎是一个显而易见的性能优势,但请考虑以下情景:一批I/O被发送到偏移量1,000附近的磁盘,以及偏移量2,000的单个I/O。磁盘磁头当前位于1,000。那么偏移量2,000的I/O将何时得到服务?现在考虑到,当服务于1,000附近的I/O时,更多的I/O接近1,000到达,还有更多,还有更多——足以持续让磁盘在偏移量1,000附近忙碌10秒。那么现在偏移量2,000的I/O将何时得到服务,它的最终I/O延迟是多少?
ECC
磁盘在每个扇区的末尾存储一个纠错码,因此驱动器可以验证数据是否被正确读取,并可能纠正一些错误。如果扇区读取不正确,磁盘磁头可能会在下一次旋转时重试读取(并可能多次重试,每次稍微变化磁头的位置)。在性能上下文中,了解这一点可能很重要,因为这可能是异常缓慢I/O的一个可能解释。请调查操作系统和磁盘错误计数器以确认。
振动
虽然磁盘设备供应商对振动问题早有所闻,但这些问题在业界并不被普遍了解或认真对待。2008年,在调查一个神秘的性能问题时,我进行了一个振动诱发的实验,当时我对着一个磁盘阵列大声喊叫,而它正在执行写入基准测试,结果引发了一次非常缓慢的I/O爆发。我的实验立即被录制成视频并上传到YouTube,迅速走红,被描述为首次展示振动对磁盘性能影响的示范[Tuner 10]。这段视频已经获得了超过800,000次的观看,提升了对磁盘振动问题的认识[1]。根据我收到的电子邮件,我还似乎意外地催生了一个声音隔离数据中心的行业:现在你可以聘请专业人员分析数据中心的声音水平,并通过减震来改善磁盘性能。
慢速磁盘
目前一些旋转磁盘的一个性能问题是我们发现了我们所称的慢速磁盘。这些磁盘有时会返回非常缓慢的I/O,超过一秒钟,而没有报告任何错误。如果这样的磁盘报告了一个故障,实际上可能会更好,而不是花费如此长的时间,这样操作系统或磁盘控制器就可以采取纠正措施,比如在冗余环境中将磁盘下线并报告故障。慢速磁盘是一个麻烦,特别是当它们是存储阵列呈现的虚拟磁盘的一部分时,以至于操作系统无法直接看到它们,这使得它们更难以识别。
磁盘数据控制器
机械磁盘向系统提供了一个简单的接口,意味着一个固定的每磁道扇区比率和一个连续的可寻址偏移范围。实际上发生在磁盘上的事情取决于磁盘数据控制器——这是一个由固件编程的磁盘内部微处理器。磁盘如何布置可寻址的偏移量取决于磁盘,它可以实现包括扇区分区在内的算法。这是需要注意的事情,但很难分析——操作系统无法看到磁盘数据控制器的内部情况。
固态硬盘
这些有时也被称为固态磁盘(SSD),这是指它们使用固态电子技术。存储介质采用可编程的非易失性存储器,通常比旋转磁盘具有更好的性能。没有运动部件,这些磁盘也具有物理耐用性,并且不易受振动引起的性能问题的影响。
这种磁盘类型的性能通常在不同的偏移量上保持一致(没有旋转或搜索延迟),对于给定的I/O大小是可预测的。工作负载的随机或顺序特性与旋转磁盘相比不那么重要。所有这些都使它们更容易进行研究和容量规划。然而,如果它们遇到性能病理,了解它们可能会像旋转磁盘一样复杂,这是由于它们内部的操作方式。
一些固态硬盘使用非易失性DRAM(NV-DRAM)。大多数使用闪存存储器。
Flash Memory
基于闪存内存的固态硬盘(SSD)是一种存储类型,提供了高读取性能,特别是随机读取性能,可以比旋转磁盘提高数量级。大多数采用NAND闪存存储器构建,它使用基于电子的被困电荷存储介质,在无电源状态下可以持久地存储电子[Cornwell 12]。名称“闪存”与数据写入的方式有关,这需要一次擦除整个内存块(包括多个页面,通常每页8 KBytes)并重写内容。由于这些写入开销,闪存存储器具有不对称的读/写性能:读取速度快,写入速度较慢。
闪存存储器有不同类型。单级单元(SLC)将数据位存储在单个单元中,多级单元(MLC)可以在单元中存储多个位(通常是两个,需要四个电压级别)。还有三级单元(TLC)用于存储三位(八个电压级别)。与MLC相比,SLC倾向于具有更高的性能,并且在企业使用时更受青睐,尽管成本更高。还有eMLC,这是带有高级固件的MLC,专为企业使用而设计。
控制器
SSD的控制器具有以下任务[Leventhal 13]:
输入:按页进行读写(通常为8 K字节);只能对已擦除的页面进行写入;页面以32到64块(256-512 K字节)的块进行擦除。
输出:模拟硬盘块接口:对任意扇区(512字节或4 K字节)进行读取或写入。
控制器的闪存转换层(FTL)负责在输入和输出之间进行转换,还必须跟踪空闲块。它基本上使用自己的文件系统来执行此操作,例如日志结构文件系统。
写入特性可能会对写入工作负载造成问题,特别是在写入的I/O大小小于闪存内存块大小时(可能达到512 K字节)。这可能会导致写入放大,即在擦除之前将块的余下部分复制到其他位置,并且至少会有擦除-写入周期的延迟。一些闪存驱动器通过提供由电池支持的磁盘缓冲区(基于RAM),来缓解延迟问题,以便在发生断电时可以缓冲写入并稍后写入。
我使用过的最常见的企业级闪存存储器,由于闪存内存的布局,对于4 K字节的读取和1 M字节的写入性能最佳。这些值因不同驱动器而异,并可以通过I/O大小的微基准测试找到。
由于闪存的本机操作与暴露的块接口之间存在差异,操作系统及其文件系统有改进的空间。TRIM命令就是一个例子:它通知SSD某个区域不再使用,从而使SSD更容易组装其空闲块池。(对于SCSI,可以使用UNMAP或WRITE SAME命令来实现此操作;对于ATA,可以使用DATA SET MANAGEMENT命令。)
寿命
NAND闪存作为存储介质存在各种问题,包括烧毁、数据衰减和读扰动[Cornwell 12]。这些问题可以通过SSD控制器解决,它可以移动数据以避免问题。通常会采用磨损平衡技术,将写入分散到不同的块中,以减少单个块上的写入周期,并进行内存过度配置,保留额外的内存,以在需要时进行映射。
尽管这些技术可以改善寿命,但SSD仍然具有有限数量的每个块的写入周期,这取决于闪存类型和驱动器采用的缓解特性。企业级驱动器使用内存过度配置和最可靠的闪存类型SLC,以实现100万次以上的写入周期。基于MLC的消费级驱动器可能仅提供1,000个周期。
病理学
以下是一些需要注意的闪存SSD病理学:
- 由于老化造成的延迟异常和SSD尝试更努力提取正确数据(使用ECC进行检查)
- 由于碎片化导致的较高延迟(重新格式化可能通过清理FTL块映射来解决此问题)
- 如果SSD实现了内部压缩,则吞吐性能较低
请查看关于SSD性能特性和遇到的问题的更多最新发展。
9.4.2 Interfaces
接口是驱动器支持的用于与系统通信的协议,通常通过磁盘控制器实现。以下是SCSI、SAS和SATA接口的简要概述。您需要检查当前的接口和支持的带宽是什么,因为随着新的规范的开发和采用,它们会随着时间而变化。
SCSI
SCSI(Small Computer System Interface)最初是一个并行传输总线,使用多个电连接器以并行方式传输位。最初的版本,1986年的SCSI-1,数据总线宽度为8位,允许每个时钟传输1字节,并提供5兆字节/秒的带宽。这是使用50针Centronics C50连接的。后来的并行SCSI版本使用了更宽的数据总线和更多的连接器引脚,最多可达到80针,并具有数百兆字节的带宽。由于并行SCSI是一个共享总线,可能会由于总线争用而出现性能问题。例如,预定的系统备份可能会用低优先级的I/O饱和总线。解决方法包括将低优先级设备放置在自己的SCSI总线或控制器上。在更高速度下,并行总线的时钟分频也成为一个问题,这连同其他问题(包括设备数量有限以及需要SCSI终端器包)导致转向串行版本:SAS。
SAS
串行连接SCSI接口被设计为高速点对点传输,避免了并行SCSI的总线争用问题。最初的SAS规范为3 Gbit/s,2009年增加到了6 Gbit/s,2012年增加到了12 Gbit/s。支持链路聚合,因此多个端口可以组合以提供更高的带宽。由于8b/10b编码,实际的数据传输速率为带宽的80%。其他SAS特性包括驱动器的双端口化以与冗余连接器和体系结构一起使用、I/O多路径、SAS域、热插拔以及对SATA设备的兼容性支持。这些特性通常使SAS在企业环境中更受青睐,特别是在冗余体系结构中。
SATA
出于与SCSI和SAS类似的原因,平行ATA(又称IDE)接口标准已经发展成为串行ATA接口。串行ATA于2003年创建,SATA 1.0支持1.5 Gbit/s;后续版本支持3.0和6.0 Gbit/s,并且额外的特性包括本地命令排队支持。SATA使用8b/10b编码,因此数据传输速率为带宽的80%。SATA在消费者台式机和笔记本电脑中广泛使用。
9.4.3 Storage Types
存储可以以多种方式提供给服务器;以下各节描述了四种通用架构:磁盘设备、RAID、存储阵列和网络附加存储(NAS)。
磁盘设备
最简单的架构是由操作系统独立控制的内部磁盘服务器。磁盘连接到磁盘控制器,这是主板或扩展卡上的电路,允许看到和访问磁盘设备。在这种架构中,磁盘控制器仅充当通道,以便系统可以与磁盘通信。典型的个人电脑或笔记本电脑使用这种方式连接的磁盘作为主存储。
这种架构是使用性能工具最容易分析的,因为每个磁盘对操作系统都是已知的,可以单独观察。
一些磁盘控制器支持这种架构,称为混合硬盘(JBOD)。
RAID
高级磁盘控制器可以为磁盘设备提供冗余独立磁盘阵列(RAID)架构(最初称为廉价磁盘冗余阵列[Patterson 88])。RAID可以将磁盘呈现为一个大的、快速的、可靠的虚拟磁盘。这些控制器通常包括一个内置缓存(RAM)以提高读写性能。
通过磁盘控制器卡提供RAID称为硬件RAID。RAID也可以由操作系统软件实现,但硬件RAID更受青睐,因为CPU昂贵的校验和奇偶校验计算可以在专用硬件上更快地执行。然而,处理器的进步产生了大量的周期和核心,减少了将奇偶校验计算卸载的需要。许多存储解决方案已经回到了软件RAID(例如使用ZFS),这减少了复杂性和硬件成本,并提高了操作系统的可观察性。
以下各节描述了RAID的性能特征。
类型
有各种RAID类型可满足不同的容量、性能和可靠性需求。本摘要重点关注表9.3中显示的性能特征。
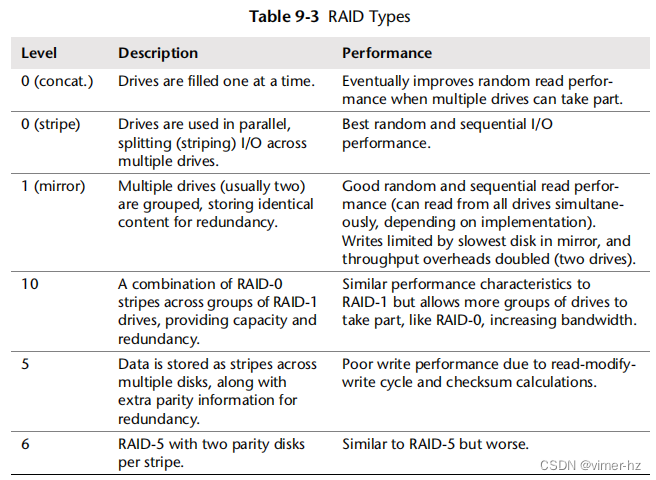
虽然RAID-0条带化性能最佳,但没有冗余性,使其在大多数生产环境中不实用。
可观察性
如前所述,使用硬件提供的虚拟磁盘设备可能会使操作系统中的可观察性更加困难,因为操作系统无法知道物理磁盘的活动情况。如果RAID是通过软件提供的,则通常可以观察到各个磁盘设备,因为操作系统直接管理它们。
读-修改-写
当数据存储为包含校验和的条带时(如RAID-5),写入I/O可能会产生额外的读取I/O和计算时间。这是因为小于条带大小的写入需要读取整个条带,修改字节,重新计算校验和,然后重新写入条带。跨越整个条带的写入可以覆盖先前的内容,而无需先读取它们。在这种环境中,通过平衡条带的大小和写入的平均I/O大小,可以减少额外的读取开销,从而提高性能。
缓存
实现RAID-5的磁盘控制器可以通过使用写回缓存来缓解读-写-修改性能。这些缓存可能是带电池备份的,以便在断电情况下仍然可以完成缓冲写入。
附加功能
请注意,高级磁盘控制器卡可以提供可能影响性能的高级功能。查阅供应商文档是一个好主意,至少要了解可能涉及的内容。例如,以下是戴尔PERC 5卡的一些功能:
- 巡逻读取:每隔几天,读取所有磁盘块并验证它们的校验和。如果磁盘正在忙于处理请求,则给予巡逻读取功能的资源会减少,以避免与系统工作负载竞争。
- 缓存刷新间隔:在将脏数据刷新到磁盘之间的时间(以秒为单位)。较长的时间可能会减少由于写入取消而导致的磁盘I/O,并实现更好的集合写入;然而,它们也可能会导致较大刷新期间更高的读取延迟。这两者都可能对性能产生重大影响。
存储阵列
存储阵列允许将许多磁盘连接到系统。它们使用高级磁盘控制器,以便可以配置RAID,并通常提供大型缓存(以GB为单位)以提高读取和写入性能。这些缓存通常也是带电池备份的,使它们可以在写回模式下运行。一个常见的策略是在电池故障时切换到写通过模式,这可能首先表现为由于等待读-修改-写周期而导致的写入性能突然下降。另一个性能考虑因素是存储阵列如何连接到系统——通常是通过外部存储控制器卡。卡和其与存储阵列之间的传输都将对IOPS和吞吐量有限制。为了在性能和可靠性上实现改进,存储阵列通常具有双连接性,意味着它们可以使用两根物理电缆连接到一个或两个不同的存储控制器卡。
网络附加存储
网络附加存储(NAS)通过现有网络使用网络协议(例如NFS、SMB/CIFS或iSCSI)提供给系统,通常是从专用系统,即NAS设备。这些是独立的系统,应该作为单独的实体进行分析。一些性能分析可能会在客户端上进行,以检查应用的工作负载和I/O延迟。网络的性能也成为一个因素,问题可能由网络拥塞和多跳延迟引起。
9.4.4 Operating System Disk I/O Stack
磁盘I/O堆栈中的组件和层次结构将取决于操作系统、版本以及所使用的软件和硬件技术。图9.6展示了一个通用模型。完整的图表请参见第3章《操作系统》。
块设备接口
块设备接口是早期Unix中创建的,用于以512字节的块为单位访问存储设备,并提供缓冲区缓存以提高性能。该接口今天仍然存在于Linux和Solaris中,尽管随着其他文件系统缓存的引入,缓冲区缓存的作用已经减弱,如第8章《文件系统》所述。
Unix提供了一条绕过缓冲区缓存的路径,称为原始块设备I/O(或简称原始I/O),可以通过字符特殊设备文件使用(请参见第3章《操作系统》)。在Linux中,默认情况下这些文件已不再常见。原始块设备I/O与“直接I/O”文件系统功能有所不同,但在某些方面类似,如第8章《文件系统》所述。
块I/O接口通常可以通过操作系统性能工具(如iostat(1))观察到。它也是静态跟踪的常见位置,最近也可以通过动态跟踪进行探索。Linux通过增加了组成块层的其他功能来增强了内核的这一领域。
Linux
Linux块层在图9.7 ([2], [Bovet 05])中显示出来。
电梯层提供了通用功能,用于对请求进行排序、合并和批处理以进行传输。这些包括早期描述的电梯寻找算法(根据它们的位置对挂起的I/O进行排序以减少磁盘头旋转移动)以及在图9.8中显示的合并和合并I/O的方法。
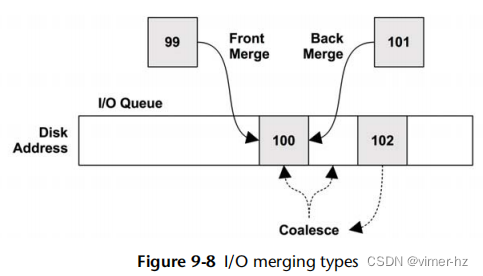
这些功能实现了更高的吞吐量和更低的I/O延迟。I/O调度程序允许对I/O进行排队和重新排序(或重新调度),以进行优化传输,由额外的调度策略确定。这可以进一步提高性能并更公平地平衡性能,特别是对于I/O延迟较高(转动磁盘)的设备。
可用的策略包括:
- Noop:不执行调度(noop是CPU对于无操作的说法),当认为调度的开销是不必要的时候可以使用(例如,在RAM磁盘中)。
- Deadline:尝试强制执行延迟期限;例如,可以选择以毫秒为单位的读取和写入到期时间。这对于需要确定性的实时系统非常有用。它还可以解决饥饿问题:当新发出的I/O跳过队列时,导致I/O请求被磁盘资源饥饿,从而产生延迟异常值。饥饿可能是由写入饿死读取,以及由于电梯寻找和对磁盘的某一区域进行大量I/O而使I/O饥饿另一区域而导致的。截止时间调度程序部分地解决了这个问题,它使用三个单独的I/O队列:读取FIFO、写入FIFO和排序队列。有关更多内部信息,请参见[Love 10]和Documentation/block/deadline-iosched.txt。
- Anticipatory:deadline的增强版本,具有预测I/O性能的启发式方法,提高了全局吞吐量。这些可以包括在读取后暂停几毫秒,而不是立即服务写入,以预测在此期间可能会收到附近磁盘位置的另一个读取请求,从而减少整体的磁盘头寻找。
- CFQ:完全公平队列调度程序为进程分配I/O时间片,类似于CPU调度,以公平使用磁盘资源。它还允许通过ionice(1)命令为用户进程设置优先级和类别。请参阅Documentation/block/cfq-iosched.txt。
进行I/O调度后,请求被放置在块设备队列上,以被发送到设备。
Solaris
基于Solaris的内核使用简单的块设备接口,在目标驱动程序(如sd)中使用队列。高级I/O调度通常由ZFS提供,它可以优先处理和合并I/O(包括跨容量的合并)。与其他文件系统不同,ZFS是一个组合的卷管理器和文件系统:它管理自己的虚拟磁盘设备和一个I/O队列(管道)。
图9.6中显示的底层三层使用诸如以下驱动程序:
- 目标设备驱动程序:sd、ssd
- 多路径I/O驱动程序:scsi_vhci、mpxio
- 主机总线适配器驱动程序:pmcs、mpt、nv_sata、ata
所使用的驱动程序取决于服务器硬件和配置。
9.5 Methodology
该部分描述了磁盘I/O分析和调优的各种方法和练习。这些主题在表9.4中有概述。
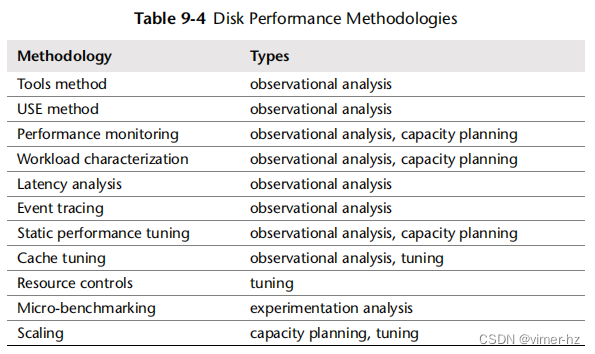
请参阅第2章“方法论”了解更多策略和这些方法的介绍。
这些方法可以单独或结合使用。在调查磁盘问题时,我的建议是按照以下顺序使用以下策略:使用USE方法、性能监控、工作负载特征化、延迟分析、微基准测试、静态分析和事件跟踪。
第9.6节“分析”展示了用于应用这些方法的操作系统工具。
9.5.1 Tools Method
工具方法是对可用工具进行迭代,检查它们提供的关键指标。虽然这是一种简单的方法,但它可能会忽视工具无法提供良好或没有可见性的问题,并且执行起来可能耗时。
对于磁盘,工具方法可以涉及以下检查:
- iostat:使用扩展模式查看繁忙的磁盘(利用率超过60%)、高平均服务时间(例如超过10毫秒)和高IOPS(取决于情况)
- iotop:识别导致磁盘I/O的进程
- dtrace/stap/perf:包括iosnoop(1)工具以详细检查磁盘I/O延迟,查找延迟异常值(例如超过100毫秒)
- 磁盘控制器特定的工具(来自供应商)
如果发现问题,要从可用工具中检查所有字段以了解更多上下文信息。有关每个工具的更多信息,请参阅第9.6节“分析”。也可以使用其他方法,这些方法可以识别更多类型的问题。
9.5.2 USE Method
USE 方法用于在性能调查的早期阶段识别所有组件中的瓶颈和错误。以下各节描述了USE 方法如何适用于磁盘设备和控制器,第9.6节“分析”展示了用于测量特定指标的工具。
磁盘设备
对于每个磁盘设备,检查以下内容:
- 利用率:设备繁忙的时间
- 饱和度:I/O 在队列中等待的程度
- 错误:设备错误
错误可能首先进行检查。它们可能被忽视,因为尽管磁盘发生故障,系统仍然能够正常运行,尽管速度较慢:磁盘通常配置为冗余磁盘池,设计用于容忍故障。除了操作系统提供的标准磁盘错误计数器外,磁盘设备可能支持更广泛的错误计数器,可以通过特殊工具(例如 SMART 数据)检索。
如果磁盘设备是物理磁盘,那么利用率应该很容易找到。如果它们是虚拟磁盘,利用率可能不反映底层物理磁盘的活动。有关此事的更多讨论,请参阅第9.3.9节“利用率”。
磁盘控制器
对于每个磁盘控制器,检查以下内容:
- 利用率:当前吞吐量与最大吞吐量的比较,以及操作速率的比较
- 饱和度:I/O 等待由于控制器饱和度造成的程度
- 错误:控制器错误
在这里,利用率指标并未以时间为单位定义,而是以磁盘控制器卡的限制为基础:吞吐量(每秒字节)和操作速率(每秒操作)。操作包括读/写和其他磁盘命令。吞吐量或操作速率可能也受到连接磁盘控制器与系统的传输的限制,就像它也可能受到从控制器到各个磁盘的传输的限制一样。每种传输都应该以相同的方式进行检查:错误、利用率、饱和度。
您可能会发现观测工具(例如 Linux 的 iostat(1))不会提供每个控制器的度量指标,而仅提供每个磁盘的度量指标。有解决方法:如果系统只有一个控制器,您可以通过对所有磁盘的度量指标求和来确定控制器的 IOPS 和吞吐量。如果系统有多个控制器,您需要确定哪些磁盘属于哪个控制器,并相应地求和度量指标。
磁盘控制器和传输的性能通常被忽视。幸运的是,它们不是系统瓶颈的常见来源,因为它们的容量通常超过所连接的磁盘的容量。如果总磁盘吞吐量或 IOPS 在不同工作负载下始终保持在某个速率,这可能是磁盘控制器或传输实际上引起问题的线索。
9.5.3 Performance Monitoring
性能监控可以识别随时间活跃的问题和行为模式。磁盘 I/O 的关键指标包括磁盘利用率和响应时间。磁盘利用率在多秒钟内达到 100% 很可能是一个问题。根据您的环境,超过 60% 的利用率也可能由于增加排队而导致性能不佳。响应时间的增加会影响性能,并可能是由于工作负载的变化或新增竞争工作负载而导致的。对于“正常”或“不良”的值取决于您的工作负载、环境和延迟要求。如果不确定,可以执行已知为良好和不良工作负载的微基准测试,以调查响应时间(例如,随机与顺序、小型与大型 I/O、单个租户与多个租户)。参见第 9.7 节,“实验”。
这些指标应该按磁盘进行检查,以查找不平衡的工作负载和性能差的单个磁盘。响应时间指标可以作为每秒的平均值进行监控,并可以包括其他值,例如最大值和标准差。理想情况下,可以检查响应时间的完整分布,例如使用直方图或热力图,以查找延迟异常值和其他模式。
如果系统施加了磁盘 I/O 资源控制,还可以收集显示这些控制何时以及何时被使用的统计信息。由于施加的限制,磁盘 I/O 可能会成为瓶颈,而不是磁盘活动本身。
利用率和响应时间显示了磁盘性能的结果。还可以添加更多指标来描述工作负载,包括 IOPS 和吞吐量,这些是用于容量规划的重要数据(请参见下一节和第 9.5.11 节,“扩展”)。
9.5.4 Workload Characterization
表征所施加的负载是容量规划、基准测试和模拟工作负载的重要练习。通过识别可以消除的不必要工作,它还可以带来一些最大的性能增益。以下是表征磁盘I/O工作负载的基本属性。它们集合起来可以提供对磁盘被要求执行的工作的近似描述:
- I/O率
- I/O吞吐量
- I/O大小
- 随机与顺序
- 读/写比率
随机与顺序、读/写比率和I/O大小在第9.3节“概念”中有描述。I/O率(IOPS)和I/O吞吐量在第9.1节“术语”中定义。
这些特征可能会随着时间的推移而变化,特别是对于应用程序和文件系统来说,它们会在间隔期间缓冲和刷新写入。为了更好地描述工作负载,捕获最大值以及平均值。更好的是,检查随时间变化的所有值的完整分布。
下面是一个示例工作负载描述,展示了如何将这些属性一起表达出来:
系统磁盘具有轻量级的随机读工作负载,平均每秒进行350次IOPS,吞吐量为3兆字节/秒,读取率为96%。偶尔会有短暂的顺序写入突发,将磁盘推动到最高4800次IOPS和560兆字节/秒。读取大小约为8千字节,写入大小约为128千字节。
除了系统范围内描述这些特征外,它们还可以用于描述每个磁盘和每个控制器的I/O工作负载。
高级工作负载特性/检查清单
可以包含更多细节来描述工作负载。以下列出了作为考虑因素的问题,这些问题也可以作为彻底研究磁盘问题时的检查清单:
- 系统范围内的IOPS速率是多少?每个磁盘?每个控制器?
- 系统范围内的吞吐量是多少?每个磁盘?每个控制器?
- 哪些应用程序或用户正在使用磁盘?
- 正在访问哪些文件系统或文件?
- 是否遇到过任何错误?这些错误是由于无效请求还是磁盘问题引起的?
- I/O在可用磁盘上的平衡程度如何?
- 每个涉及的传输总线的IOPS是多少?
- 每个涉及的传输总线的吞吐量是多少?
- 正在发出哪些非数据传输磁盘命令?
- 为什么发出磁盘I/O(内核调用路径)?
- 磁盘I/O多大程度上与应用程序同步?
- I/O到达时间的分布是什么?
针对读取和写入分别提出IOPS和吞吐量的问题。这些问题也可以随时间进行检查,以查找最大值、最小值和基于时间的变化。另请参阅第2章方法论中第2.5.10节“工作负载特性”,提供了要测量的特性的高级摘要(谁、为什么、什么、如何)。
性能特性
与工作负载特性进行比较,以下问题描述了工作负载的结果性能:
- 每个磁盘的繁忙程度如何(利用率)?
- 每个磁盘的I/O饱和程度如何(等待队列长度)?
- 平均I/O服务时间是多少?
- 平均I/O等待时间是多少?
- 是否存在高延迟的I/O异常值?
- I/O延迟的完整分布是什么?
- 系统资源控制,如I/O限制,是否存在并处于活动状态?
- 非数据传输磁盘命令的延迟是多少?
9.5.5 Latency Analysis
延迟分析涉及深入系统,以找出延迟的来源。对于磁盘而言,这通常会止步于磁盘接口:即I/O请求和完成中断之间的时间。如果这与应用程序级别的I/O延迟匹配,通常可以安全地假设I/O延迟源自磁盘,从而使您能够将调查重点放在它们上面。如果延迟不同,通过在操作系统堆栈的不同级别测量它,将能够确定其来源。图9.9显示了I/O堆栈,显示了两个I/O异常值A和B在不同级别的延迟。
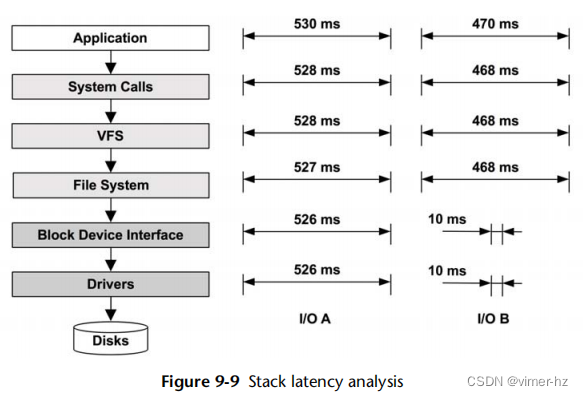
I/O A的延迟在从应用程序到磁盘驱动程序的每个级别上都相似。这种相关性指向磁盘(或磁盘驱动程序)作为延迟的原因。如果独立测量了各层,基于它们之间的相似延迟值,就可以推断出这一点。
B的延迟似乎起源于文件系统级别(锁定或排队?),较低级别的I/O延迟贡献的时间要少得多。请注意,堆栈的不同层可能会增加或减少I/O,这意味着大小、计数和延迟将在不同层之间有所不同。B示例可能是仅观察了较低级别的一个I/O(10毫秒),但未考虑用于处理相同文件系统I/O的其他相关I/O的情况(例如元数据)。
每个级别的延迟可以呈现为:
- 每个间隔的I/O平均值:通常由操作系统工具报告
- 完整的I/O分布:作为直方图或热力图;请参阅第9.6.12节“可视化”中的延迟热力图
- 每个I/O的延迟值:请参阅下一节“事件跟踪”
最后两种方法对于追踪异常值的来源并且有助于确定I/O是否已分割或合并是有用的。
9.5.6 Event Tracing
事件跟踪是指捕获和记录每个I/O事件的信息。对于观察性分析而言,这是最后的手段。由于捕获和保存这些细节,通常会增加一些性能开销,这些细节通常会被写入日志文件以供以后检查。这些日志文件应至少包含每个I/O的以下细节:
- 磁盘设备ID
- I/O类型:读或写
- I/O偏移量:磁盘位置
- I/O大小:字节
- I/O请求时间戳:当I/O被发送到设备时(也称为I/O策略)
- I/O完成时间戳:当I/O事件完成时(完成中断)
- I/O完成状态:错误
其他细节可能包括(如果适用)PID、UID、应用程序名称、文件名,以及所有非数据传输磁盘命令的事件(以及这些命令的自定义细节)。
I/O请求和完成时间戳允许计算磁盘I/O延迟。在阅读日志时,可以对每个时间戳单独进行排序以进行比较,以了解磁盘I/O如何被设备重新排序。还可以从时间戳中研究到达分布情况。
由于磁盘I/O通常被分析,因此通常会为此目的提供静态跟踪点,跟踪请求和完成。动态跟踪也可能用于高级分析,并且可能捕获以下类似的跟踪日志:
- 块设备驱动程序I/O
- 接口驱动程序命令(例如,sd)
- 磁盘设备驱动程序命令
命令意味着读取/写入和非数据传输。请参阅第9.6节“分析”中的示例。
9.5.7 Static Performance Tuning
静态性能调优关注的是配置环境的问题。对于磁盘性能,需要检查静态配置的以下方面:
- 存在多少个磁盘?属于哪些类型?
- 磁盘固件的版本是多少?
- 存在多少个磁盘控制器?属于哪种接口类型?
- 磁盘控制器卡是否连接到高速插槽?
- 磁盘控制器固件的版本是多少?
- 是否配置了RAID?具体如何配置,包括条带宽度?
- 是否可用并配置了多路径?
- 磁盘设备驱动程序的版本是多少?
- 是否存在适用于任何存储设备驱动程序的操作系统错误/补丁?
- 是否对磁盘I/O使用了资源控制?
需要注意的是,设备驱动程序和固件可能存在性能缺陷,最好通过供应商的更新来修复。
回答这些问题可以揭示被忽视的配置选择。有时,系统已配置为处理一种工作负载,然后被重新用于处理另一种工作负载。这种策略将重新审视这些选择。
在担任Sun公司ZFS存储产品的性能主管期间,我收到的最常见的性能投诉是由于错误配置引起的:使用了半个JBOD(12个磁盘)的RAID-Z2(宽条带)。我学会了首先要求配置细节(通常通过电话)然后再花时间登录系统并检查I/O延迟。
9.5.8 Cache Tuning
系统中可能存在许多不同的缓存,包括应用程序级别、文件系统、磁盘控制器以及磁盘本身的缓存。这些缓存的列表包含在第9.3.3节“缓存”中,可以按照第2章“方法论”中第2.5.17节“缓存调优”的描述进行调优。总之,检查存在哪些缓存,检查它们是否在工作,检查它们的工作效果如何,然后调整工作负载以适应缓存,并为缓存调整工作负载。
9.5.9 Resource Controls
操作系统可能提供控制功能,用于将磁盘I/O资源分配给进程或进程组。这些功能可能包括为IOPS和吞吐量设置固定限制,或者使用份额来进行更灵活的处理。这些功能的工作方式是特定于实现的,并在第9.8节“调优”中进行了讨论。
9.5.10 Micro-Benchmarking
在第8章“文件系统”中介绍了微基准测试磁盘I/O的方法,其中解释了测试文件系统I/O和测试磁盘I/O之间的区别。在这里,我们想要测试磁盘I/O,通常意味着通过操作系统的设备路径进行测试,特别是如果可用的话,要使用原始设备路径,以避免所有文件系统行为(包括缓存、缓冲、I/O分割、I/O合并、代码路径开销和偏移映射差异)。
微基准测试的因素包括:
- 方向:读取或写入
- 磁盘偏移模式:随机或顺序
- 偏移范围:完整磁盘或紧密范围(例如,仅偏移0)
- I/O大小:512字节(典型最小值)到1兆字节
- 并发性:进行中的I/O数量,或执行I/O的线程数量
- 设备数量:单个磁盘测试,或多个磁盘(用于探索控制器和总线限制)
接下来的两节展示了如何将这些因素结合起来测试磁盘和磁盘控制器的性能。有关可以用来执行这些测试的具体工具的详细信息,请参阅第9.7节“实验”。
磁盘
可以按磁盘进行微基准测试,以确定以下内容,并提供建议的工作负载:
- 最大磁盘吞吐量(每秒兆字节):128K字节读取,顺序
- 最大磁盘操作速率(IOPS):512字节读取,仅偏移0
- 最大磁盘随机读取(IOPS):512字节读取,随机偏移
- 读取延迟概要(平均微秒):顺序读取,重复进行512字节,1K,2K,4K等操作
- 随机I/O延迟概要(平均微秒):512字节读取,重复进行完整偏移跨度,仅开始偏移,仅结束偏移
这些测试也可以用于写入。使用“仅偏移0”旨在将数据缓存在磁盘缓存中,以便测量缓存访问时间。
磁盘控制器
可以通过将工作负载应用于多个磁盘来对磁盘控制器进行微基准测试,设计用于达到控制器的极限。可以使用以下内容执行这些测试,并提供磁盘的建议工作负载:
- 最大控制器吞吐量(每秒兆字节):128K字节,仅偏移0
- 最大控制器操作速率(IOPS):512字节读取,仅偏移0
逐个将工作负载应用于磁盘,观察是否存在极限。即使可能需要超过十几个磁盘才能找到磁盘控制器的极限。
9.5.11 Scaling
磁盘和磁盘控制器具有吞吐量和IOPS限制,可以通过之前描述的微基准测试来展示。调优只能提高性能达到这些限制。如果需要更多的磁盘性能,并且其他策略如缓存无效,那么就需要扩展磁盘。以下是一种简单的基于资源容量规划的方法:
1. 确定目标磁盘工作负载,按照吞吐量和IOPS来衡量。如果这是一个新系统,请参阅第2章方法论中的第2.7节容量规划。如果系统已经有了工作负载,请将用户人口表达为当前磁盘吞吐量和IOPS,并将这些数字按比例缩放到目标用户人口。(如果在同一时间不扩展缓存,则磁盘工作负载可能会增加,因为缓存每用户比例变小,将更多I/O推送到磁盘。)
2. 计算支持此工作负载所需的磁盘数量。考虑RAID配置。不要使用每个磁盘的最大吞吐量和IOPS值,因为这将导致计划将磁盘驱动器利用率达到100%,从而导致由于饱和和排队而立即出现性能问题。选择一个目标利用率(例如50%)并相应地缩放值。
3. 计算支持此工作负载所需的磁盘控制器数量。
4. 检查是否已超出传输限制,并在必要时扩展传输。
5. 计算每个磁盘I/O的CPU周期数以及所需的CPU数量。
所使用的每个磁盘吞吐量和IOPS的最大值取决于它们的类型和磁盘类型。请参阅第9.3.7节“IOPS不相等”。微基准测试可用于查找给定I/O大小和I/O类型的特定限制,而工作负载特征化可用于现有工作负载,以查看哪些大小和类型至关重要。
为了满足磁盘工作负载要求,通常会发现需要连接到存储阵列的数十个磁盘的服务器。我们曾经说,“增加更多的磁盘轴承。”现在我们可能会说,“增加更多的闪存。”
9.6 Analysis
本节介绍了用于基于Linux和Solaris的操作系统的磁盘I/O性能分析工具。有关使用它们的策略,请参见前一节。
本节中的工具列在表9.5中。
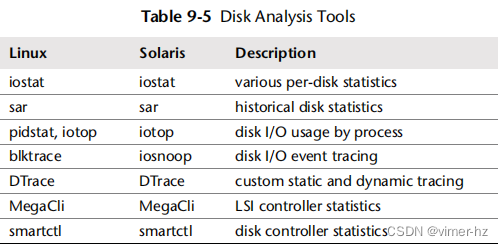
这是一些工具的选择,用于支持第9.5节“方法论”,从系统范围的统计数据开始,然后是每个进程的统计数据,再深入到事件跟踪和控制器统计数据。有关其功能的完整参考,请参阅工具文档,包括man页面。
9.6.1 iostat
iostat(1)总结了每个磁盘的I/O统计信息,提供了工作负载特征化、利用率和饱和度的指标。它可以由任何用户执行,通常是在命令行上调查磁盘I/O问题时首先使用的命令。它所提供的统计信息始终由内核维护,因此该工具的开销被认为是可以忽略不计的。
名称“iostat”缩写为“I/O统计”,尽管更好的做法可能是将其命名为“diskiostat”以反映其报告的I/O类型。这导致了偶尔的混淆,当用户知道应用程序正在执行I/O(到文件系统)但想知道为什么在iostat(1)(磁盘)中看不到时。
iostat(1)是在上世纪80年代初编写的,不同版本可用于不同的操作系统。它可以通过sysstat软件包添加到基于Linux的系统中,并且在基于Solaris的系统中默认包含。尽管其通用目的在两者中是相同的,但列和选项有所不同。请参阅您操作系统的iostat手册页面,以查看您的版本支持的内容。
以下部分描述了Linux和Solaris系统的iostat(1),其中选项和输出略有不同。iostat(1)可以使用各种选项执行,然后是一个可选的间隔和计数。
Linux
常用的iostat(1)选项如表9.6所示。
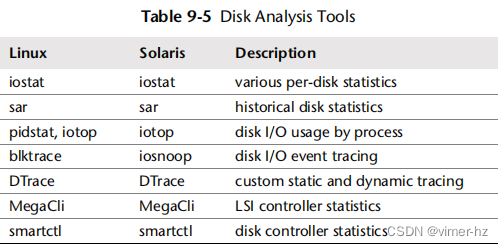
默认行为是启用-c和-d报告;如果在命令行上指定了一个选项,则另一个选项将被禁用。一些旧版本包含了一个用于NFS统计信息的选项,-n。自sysstat版本9.1.3以来,这个选项被移到了单独的nfsiostat命令中。
如果没有任何参数或选项,则打印-c和-d报告的自启动以来的摘要。这里将其作为对该工具的介绍进行了介绍;然而,预计您不会使用这种模式,因为后面介绍的扩展模式通常更有用。
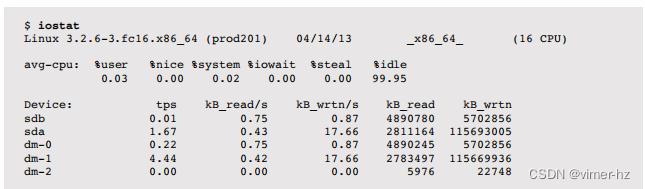
默认情况下,iostat显示系统的摘要信息,包括内核版本、主机名、日期、架构和CPU数量,然后是自启动以来的摘要统计信息,分别针对CPU(avg-cpu)和磁盘设备(在设备下)。每个磁盘设备显示为一行,列出了基本细节:
- tps:每秒事务数(IOPS)
- kB_read/s,kB_wrtn/s:每秒读取的千字节和每秒写入的千字节
- kB_read,kB_wrtn:总共读取和写入的千字节
SCSI设备,包括磁带和CD-ROM,目前在Linux版本的iostat(1)中无法看到。这导致了一些解决方法,包括SystemTap的iostat-scsi.stp脚本。还要注意,虽然iostat(1)报告了块设备的读取和写入,但根据内核的不同(例如,在blk_do_io_stat()中的逻辑),它可能会排除一些其他类型的磁盘设备命令。
如前所述,可以使用-m选项将输出报告为兆字节。在较旧版本的iostat(1)(sysstat 9.0.6及更早版本)中,默认输出使用块(每个512字节)而不是千字节。可以通过以下环境变量强制使用旧的行为:

通过使用-x选项可以选择扩展输出,提供了额外的列,对于前面介绍的许多策略非常有用。这些额外的列包括用于工作负载特征化的IOPS和吞吐量指标,用于USE方法的利用率和队列长度,以及用于性能特征化和延迟分析的磁盘响应时间。
以下输出太宽以至于无法放在一页上,因此左侧和右侧部分被显示在一起。此示例包括-d仅用于磁盘报告,-k用于千字节,以及-z用于省略所有零行(空闲设备):
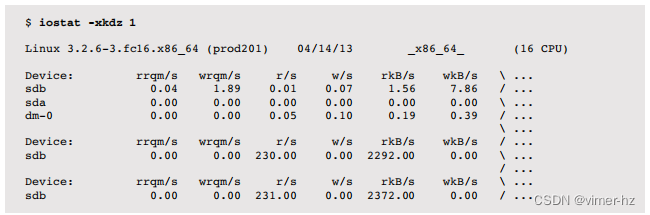
输出列如下:
- rrqm/s:每秒放置在驱动程序请求队列上并合并的读请求
- wrqm/s:每秒放置在驱动程序请求队列上并合并的写请求
- r/s:每秒发出到磁盘设备的读请求
- w/s:每秒发出到磁盘设备的写请求
- rkB/s:每秒从磁盘设备读取的千字节
- wkB/s:每秒写入到磁盘设备的千字节
在rrqm/s和wrqm/s列中的非零计数显示了在传递给设备之前合并的连续请求,以改善性能。这个度量指标也是顺序工作负载的标志。r/s和w/s列显示实际发给设备的请求。
以下是剩余的输出部分:
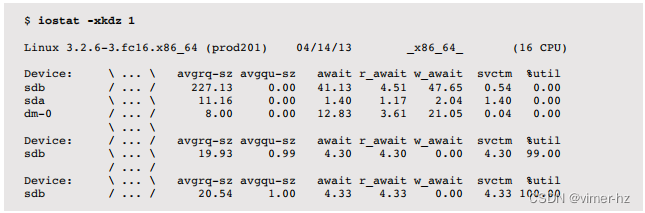
输出列如下:
- avgrq-sz:平均请求大小,以扇区(512字节)为单位
- avgqu-sz:平均等待在驱动程序请求队列中并在设备上活动的请求数量
- await:平均I/O响应时间,包括等待在驱动程序请求队列中的时间和设备的I/O响应时间(毫秒)
- r_await:与await相同,但仅针对读取(毫秒)
- w_await:与await相同,但仅针对写入(毫秒)
- svctm:磁盘设备的平均(推断)I/O响应时间(毫秒)
- %util:设备忙于处理I/O请求的时间百分比(利用率)
由于avgrq-sz是在合并之后,小尺寸(16个扇区或更少)表明无法合并的随机I/O工作负载。大尺寸可能是大I/O或合并的顺序工作负载(由早期列指示)。
交付性能的最重要度量标准是await。如果应用程序和文件系统使用一种技术来减轻写入延迟(例如,写透传),则w_await可能不那么重要,您可以转而关注r_await。
对于资源使用和容量规划,%util很重要,但请注意它仅是忙碌度(非空闲时间)的度量,并且对于由多个磁盘支持的虚拟设备可能意义不大。这些设备可能更好地通过所施加的负载来理解:IOPS(r/s + w/s)和吞吐量(rkB/s + wkB/s)。
r_await和w_await列是iostat(1)工具的较新添加;以前的版本只有await。iostat(1)的man页面警告说svctm字段将在未来的版本中被删除,因为这个度量被认为是不准确的。(我不认为它是不准确的,但我认为它可能会误导人们,因为它是一个推断值,而不是设备延迟的测量。)
以下是另一个有用的组合:
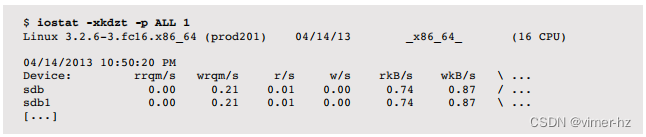
-t包括时间戳,当与其他有时间戳的来源进行比较时可以很有用。-p ALL包括每个分区的统计信息。
不幸的是,当前版本的iostat(1)不包括磁盘错误;否则,所有USE方法的度量都可以从一个工具中检查!
Solaris
列出使用-h选项的选项(尽管出现“非法选项”错误):

这包括-e和-E选项来报告错误计数。
-I选项打印计数,而不是计算的间隔摘要;它通常由定期运行iostat(1)的监控软件使用,然后对输出进行自己的计算以生成摘要。

从左到右,默认输出显示终端(tty)的输入和输出字符(tin,tout),然后是最多三组列(kps,tps,serv)用于磁盘设备,然后是用于CPU统计信息的一组列(cpu)。在这个系统上,显示的磁盘设备是ramdisk1,sd0和sd1。更多设备没有以这种方式显示,因为iostat(1)试图保持80字符宽度的输出。
磁盘设备列是:
- kps:每秒读写的千字节
- tps:每秒事务数(IOPS)
- serv:服务时间,毫秒
此示例使用-n选项使用磁盘设备的描述性/dev名称,而不是内核实例名称,并使用-z选项省略所有零行(空闲设备):


输出列是:
- r/s, w/s:每秒读取次数,每秒写入次数
- kr/s, kw/s:每秒读取的千字节数,每秒写入的千字节数
- wait:块驱动程序队列中等待的请求平均数量
- actv:设备上已发出并处于活动状态的请求的平均数量
- wsvc_t:在块驱动程序队列中等待的平均时间(毫秒);wsvc_t表示等待服务时间
- asvc_t:设备上活动的平均时间(毫秒);asvc_t表示活动服务时间,尽管这实际上是平均设备I/O响应时间
- %w:I/O在等待队列中存在的时间百分比
- %b:I/O忙碌的时间百分比(利用率)吞吐量
平均读取或写入I/O大小不包括在内(它在Linux版本中可用),但可以通过将IOPS速率除以来轻松计算,例如,平均读取大小=(kr/s)/(r/s)。
另一个有用的组合是
使用-C可以显示每个控制器的统计信息,使用-p可以显示每个分区的统计信息,并且可以使用-Td对输出进行时间戳标记。
可以使用-e选项将错误计数器添加到输出中:
然而,除非您的设备正在积极地遇到错误,否则每个间隔的摘要可能并不那么有用。要仅检查自启动以来的计数,请使用-E选项获取不同的iostat输出格式:
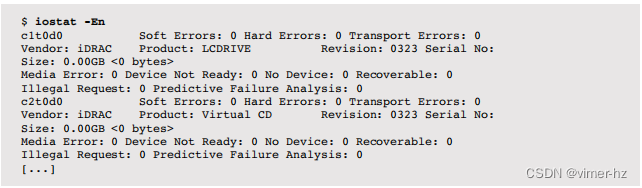
软错误(在-e输出中为s/w)是可恢复的错误,可能会导致性能问题。硬错误(来自-e输出的h/w)对磁盘不可恢复,尽管它们可能可由更高级别的架构(如RAID)恢复,这允许系统继续运行,但通常也会导致性能问题(例如,I/O超时延迟,随后是服务降级)。
可以使用更简单的方式阅读错误计数器:

使用iostat(1M)可以推导出USE方法:
- %b:显示磁盘利用率。
- actv:大于一的数字表示饱和:在设备中排队。对于前端连接多个物理设备的虚拟设备,这更难确定(这取决于RAID策略);大于设备数量的actv可能表明设备饱和。
- wait:大于零的数字表示饱和:在驱动程序中排队。
- 错误总数:总错误计数。
正如9.4.1节“磁盘类型”中早期“懒惰磁盘”部分所述,可能存在错误计数未增加的磁盘问题。希望这种情况很少发生,您不会遇到它。以下是此类问题的示例屏幕截图:
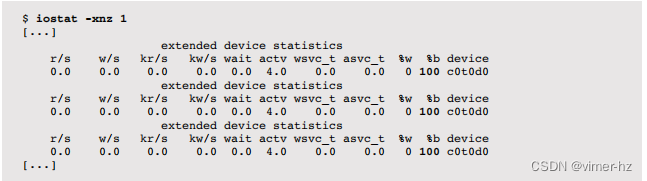
请注意,磁盘处于100%繁忙状态,但没有执行I/O操作(r/s和w/s的计数为零)。这个特定的示例来自于RAID控制器的问题。如果这种情况持续了很短的时间,将引入多秒级的I/O延迟,从而导致性能问题。如果持续时间更长,系统可能会出现挂起的情况。
9.6.2 sar
系统活动报告工具sar(1)可用于观察当前活动,并可配置为存档和报告历史统计数据。在本书的各个章节中提到了sar(1),因为它提供了不同的统计信息。
使用-d选项打印sar(1)磁盘摘要,以下示例演示了每秒一个间隔。
Linux
这个磁盘摘要输出很宽,这里分为两部分列出:
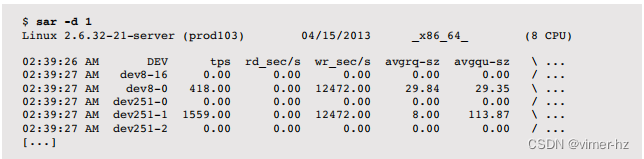
以下是剩余的列:
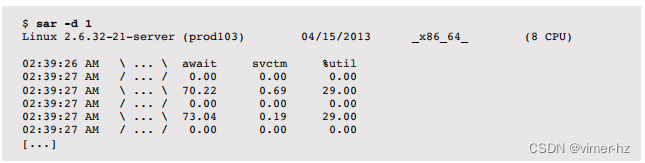
许多列与iostat(1)相似(请参阅前面的描述),但有以下区别:
- tps:每秒设备数据传输次数
- rd_sec/s、wr_sec/s:每秒读取和写入扇区(每扇区512字节)
Solaris
以下是使用1秒间隔运行sar(1)来报告当前活动的命令:
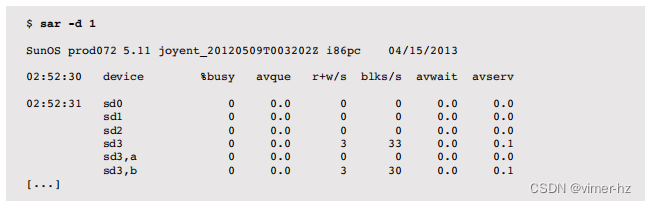
输出列类似于iostat(1M)的扩展模式,但具有不同的名称。
例如,%busy对应iostat(1M)中的%b,avwait和avserv被称为iostat(1M)中的wsvc_t和asvc_t。
9.6.3 pidstat
Linux的pidstat(1)工具默认打印CPU使用情况,并包含一个-d选项用于磁盘I/O统计信息。这在2.6.20及更高版本的内核上可用。例如:

列包括:
- kB_rd/s:每秒读取的千字节
- kB_wd/s:每秒写入的千字节
- kB_ccwr/s:每秒取消写入的千字节(例如,在刷新之前被覆盖)
只有超级用户(root)可以访问他们不拥有的进程的磁盘统计信息。这些信息通过/proc/PID/io读取。
9.6.4 DTrace
DTrace可以用于从内核内部检查磁盘I/O事件,包括块设备接口I/O、I/O调度器事件、目标驱动程序I/O和设备驱动程序I/O。这些功能支持工作负载特征化和延迟分析。以下各节介绍了用于磁盘I/O分析的DTrace,演示了应该适用于基于Linux和Solaris的系统的功能。除非特别指出是针对Linux的,否则这些示例均取自基于Solaris的系统。在第4章“可观察性工具”中包含了一个DTrace入门。用于跟踪磁盘I/O的DTrace提供程序包括表9.7中列出的那些。
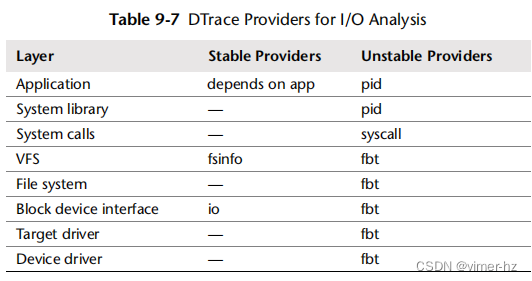
应尽可能始终使用稳定的提供程序;然而,对于磁盘I/O堆栈,确实只有io提供程序可用于进行严肃的分析。检查您的操作系统是否已发布了更稳定的提供程序用于其他领域。如果没有,可以使用不稳定的接口提供程序,尽管脚本将需要更新以匹配软件更改。
io Provider
io提供程序提供了对块设备接口的可见性,并可用于表征磁盘I/O并测量延迟。探针包括:
- io:::start:向设备发出了一个I/O请求。
- io:::done:设备上的一个I/O请求已完成(完成中断)。
- io:::wait-start:一个线程开始等待一个I/O请求。
- io:::wait-done:一个线程完成了对一个I/O请求的等待。
在Solaris上列出这些:
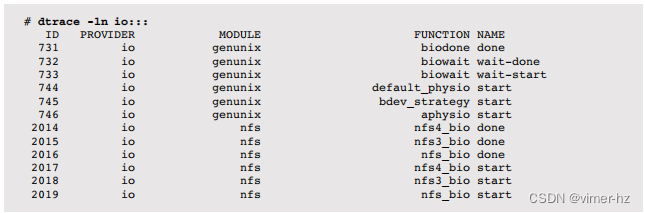
MODULE和FUNCTION列显示了探针的位置(作为实现细节,不属于稳定接口的一部分)。请注意,在Solaris上,nfs客户端I/O也通过io提供程序进行跟踪,如nfs模块探针所示。
这些探针具有稳定的参数,提供了有关I/O的详细信息,包括:
- args[0]->b_count:I/O大小(字节)
- args[0]->b_blkno:设备I/O偏移量(块)
- args[0]->b_flags:按位标志,包括B_READ以指示读取I/O
- args[0]->b_error:错误状态
- args[1]->dev_statname:设备实例名称+实例/次要号码
- args[1]->dev_pathname:设备路径名
- args[2]->fi_pathname:文件路径名(如果已知)
- args[2]->fi_fs:文件系统类型
除了标准的DTrace内置函数外,这些参数还允许构建一些强大的单行命令。
事件跟踪
以下是每个磁盘I/O请求的跟踪,包括PID、进程名称和I/O大小(字节):
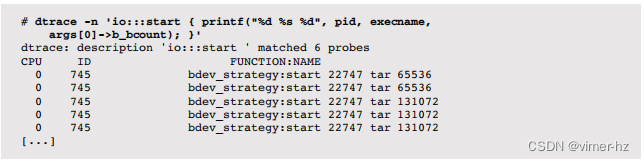
这个单行命令使用printf()语句打印每个I/O的详细信息。输出显示PID为22747的tar进程发出了五个I/O请求,大小为64或128KB。在这种情况下,当发出I/O请求时,应用程序线程仍处于CPU上,使得可以通过execname看到它。(在某些情况下,这将以异步方式发生,并且将标识内核、sched。)
I/O大小摘要
通过应用程序名称总结磁盘I/O大小:
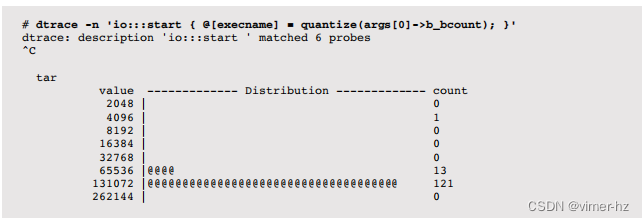

与使用DTrace报告平均、最小或最大I/O大小不同,这个单行命令生成了一个分布图来可视化完整的分布。值列显示了字节范围,计数列显示了在该范围内的I/O数量。在跟踪过程中,名为tar的进程执行了121个I/O,大小在128到256KB之间(即131,072到262,143字节)。内核(sched)具有一个有趣的分布(看起来是双峰的),这种分布无法通过单一的平均值来很好地理解。
除了按进程名称(execname)总结外,I/O大小还可以按以下方式进行总结:
- 设备名称:使用args[1]->dev_statname
- I/O方向(读/写):使用args[0]->b_flags & B_READ ? "read" : "write"
除了大小(args[0]->b_count)之外,还可以总结其他特征。例如,可以检查磁盘上的位置以测量I/O搜索。
I/O Seek Summary
I/O搜索摘要跟踪相同应用程序对同一设备连续I/O之间的搜索距离,并将其按进程报告为直方图。这已经变得太长,无法作为一个单行命令,因此已经实现为以下的DTrace脚本(diskseeksize.d):

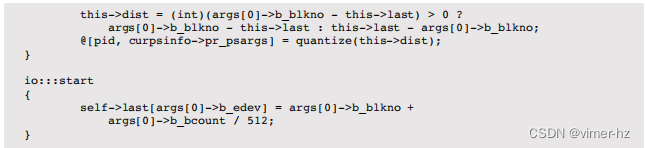
该脚本计算了一个I/O与前一个I/O的最后一个扇区(起始偏移量+大小)之间的扇区距离。这是针对每个设备进行跟踪的,同时也通过每个线程(使用self->)进行跟踪,以便可以将不同进程的工作负载模式分离和研究。
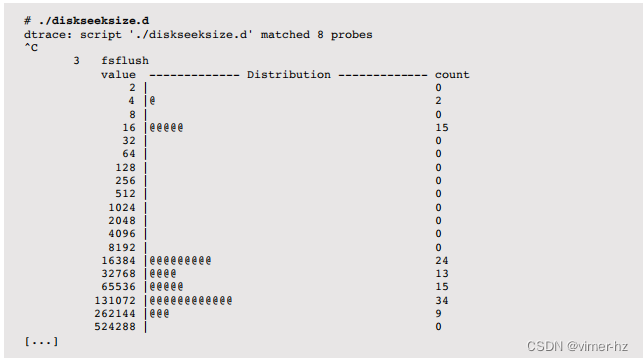
这显示了来自fsflush线程的I/O,通常会寻求超过8,192个块。如果搜索距离主要为0,那么这表明是顺序工作负载。
I/O Latency Summary
这个脚本(disklatency.d)跟踪块I/O的开始和完成事件,并将延迟分布总结为直方图:

在开始探针上记录了一个时间戳,以便在完成时计算时间差。这个脚本的技巧在于将开始时间与结束时间戳关联起来,因为可能有很多I/O正在进行中。使用了一个关联数组,其键是I/O的唯一标识符(恰好是缓冲结构的指针)。
执行中:
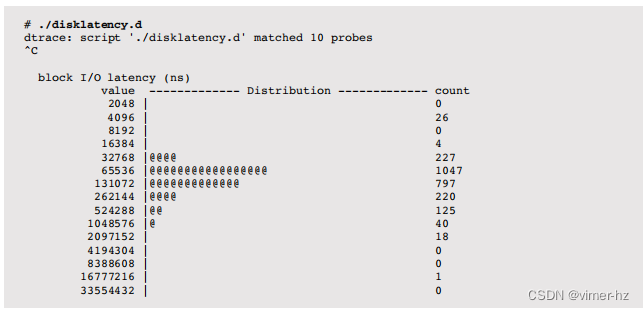
在跟踪过程中,大多数I/O在65,536到262,143纳秒的范围内(0.07到0.26毫秒)。最慢的是在16到33毫秒范围内的单个I/O。这种直方图输出非常适合识别这样的I/O延迟异常值。
这里,对所有设备的I/O进行了总结。该脚本可以改进为根据设备、进程ID或其他标准生成单独的直方图。
I/O Stacks
I/O堆栈频率计算了发出I/O请求的调用内核堆栈,直到块设备驱动程序(io:::start探针的位置)。在基于Solaris的系统上:
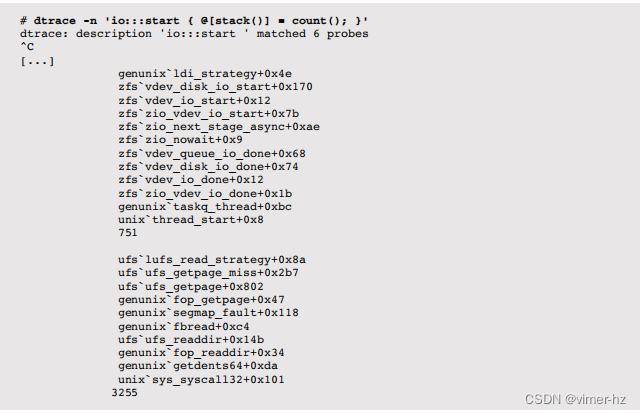
输出内容很长,显示了通过内核所采取的确切代码路径,导致发出磁盘I/O,然后是每个堆栈的计数。在调查超出工作负载预期速率的意外额外I/O(异步、元数据)时,这通常很有用。顶部堆栈显示了来自任务队列线程运行ZIO管道的异步ZFS I/O,底部显示了由getdents()系统调用发起的同步UFS I/O。
在Linux上,这是通过对内核submit_bio()函数进行动态跟踪实现的(io:::start探针仍在为此原型机开发中):
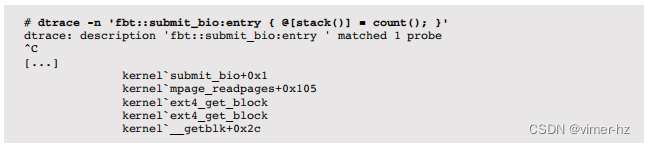
该路径显示了祖先关系,从系统调用接口(底部开始),VFS,页面缓存,到ext4。
这些堆栈的每一行都可以通过DTrace的fbt提供程序进行单独跟踪。请参阅第9.8节《调优》,了解通过fbt跟踪sd_start_cmds()函数的示例。
SCSI 事件
这个脚本(scsireasons.d)演示了在SCSI层进行跟踪,报告带有描述完成原因的特殊SCSI代码的I/O完成情况。以下是关键摘录(有关完整脚本参考,请参见下一节):

该脚本使用关联数组将SCSI原因整数转换为人类可读的字符串。在scsi_destroy_pkt()中引用了这一点,在那里,原因字符串被频率计数。在跟踪过程中没有发现错误。
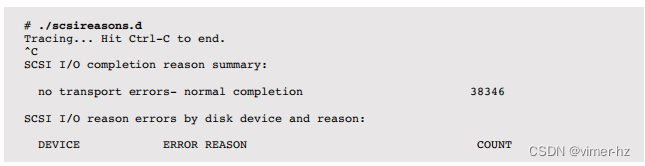
高级跟踪
在需要进行高级分析时,动态跟踪可以更详细地探索内核I/O堆栈的每一层。为了提供对其功能的了解,表9.8显示了来自DTrace [Gregg 11](该书有140页)磁盘I/O章节的脚本(这些脚本也可以在线获取 [4])。
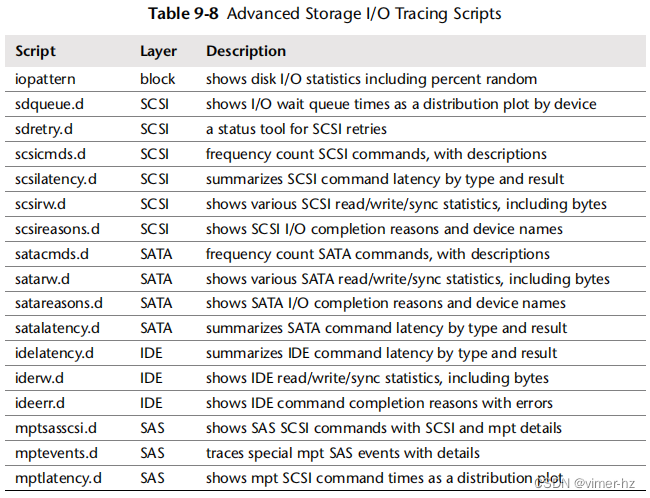
虽然这种观测度令人难以置信,但这些动态跟踪脚本与特定的内核内部绑定在一起,将需要维护以适应新内核版本的变化。
9.6.5 SystemTap
SystemTap也可以用于Linux系统,用于对磁盘I/O事件进行动态跟踪,并使用其ioblock提供程序进行静态跟踪。请参阅第4章《可观测性工具》中的第4.4节《SystemTap》,以及附录E,以获取有关转换前面的DTrace脚本的帮助。
9.6.6 perf
Linux perf(1)工具(在第6章《CPU》中介绍)提供了块跟踪点,可以用于跟踪一些基本信息。以下是它们的列表:
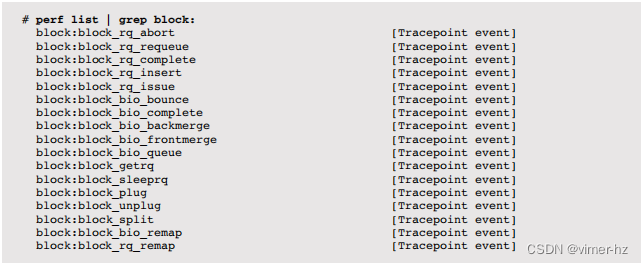
例如,以下跟踪块设备问题,并提供调用图,以便可以检查堆栈跟踪。提供了一个sleep 10命令作为跟踪持续时间。
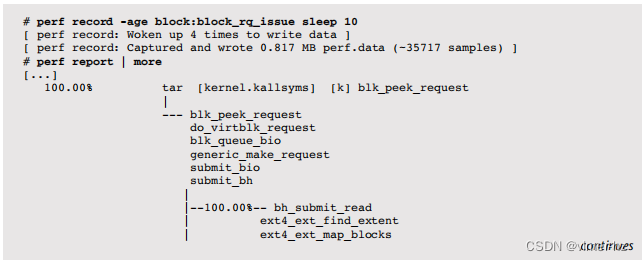

输出很长,显示了导致块设备I/O的不同代码路径。这里给出的部分是用于ext4目录读取的。
9.6.7 iotop
iotop(1)是一个包含磁盘I/O列的top版本。第一个版本于2005年编写,使用了基于Solaris的系统的DTrace [McDougall 06b],作为一个较早版本的psio(1)工具(带有I/O的进程状态,该工具使用了DTrace之前的跟踪框架)的top风格版本。iotop(1)及其伴侣iosnoop(1M)现在默认随许多具有DTrace的系统一起提供,包括Mac OS X和Oracle Solaris 11。在Linux上也有基于内核账户统计信息的iotop(1)工具可用[5]。
Linux
iotop(1)需要内核版本2.6.20(根据后端口状态可能稍早一些)或更高版本,以及以下内核选项:CONFIG_TASK_DELAY_ACCT、CONFIG_TASK_IO_ACCOUNTING、CONFIG_TASKSTATS和CONFIG_VM_EVENT_COUNTERS。
用法
提供了各种选项以自定义输出:
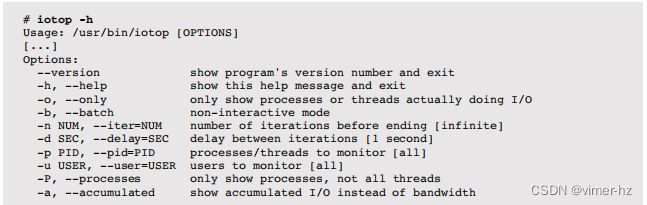

默认情况下,iotop(1)会清除屏幕并打印一秒钟的摘要。
批处理模式
批处理模式(-b)可用于提供滚动输出(不清除屏幕);以下示例演示了仅包含I/O进程(-o)和5秒间隔(-d5)的情况:
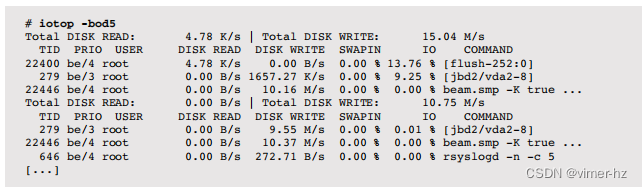
输出显示了beam.smp进程(Riak)执行约10兆字节/秒的磁盘写入工作负载。
其他有用的选项包括-a,用于累积I/O而不是间隔平均值,以及-o,用于仅显示执行磁盘I/O的那些进程。
Solaris
iotop(1)可能已经在/opt/DTT或/usr/DTT目录下可用。它也可以在DTraceToolkit中找到(源自该工具包)。
用法
以下是iotop(1)的用法示例:
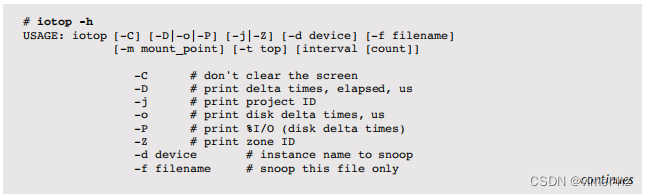

默认设置
默认情况下,输出间隔为5秒,使用统计数据以字节为单位呈现:

在此示例中,tar(1)命令在这5秒的间隔内从sd5设备读取了约3GB的数据。
利用率
-P选项显示磁盘利用率,-C打印滚动输出:
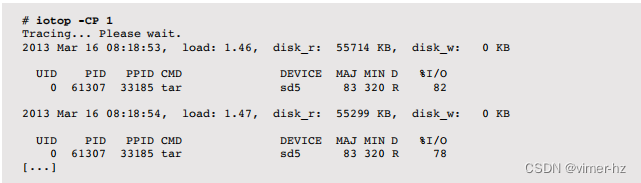
这显示了tar(1)命令使sd5磁盘的使用率约为80%。
disktop.stp
另一个基于SystemTap的iotop(1)版本被命名为disktop.stp。名称“disktop”应该比“iotop”更好,因为“io”具有歧义,可能意味着应用程序级(VFS)或磁盘级别。不幸的是,disktop.stp 中的“disk”指的是“从用户空间的角度读写磁盘”,并通过跟踪VFS 来实现这一点。这意味着对于从文件系统缓存大量返回的应用程序,disktop.stp 的输出可能与iostat(1)完全不匹配。
9.6.8 iosnoop
iosnoop(1M)通过块设备接口同时跟踪所有磁盘,并为每个磁盘I/O打印一行输出。提供了各种命令行选项以输出额外的详细信息,并且由于iosnoop(1M)是一个简短的DTrace脚本,可以轻松修改以提供更多功能。这个工具对于先前的跟踪和延迟分析策略非常有用。
用法
以下是iosnoop(1)的用法示例:
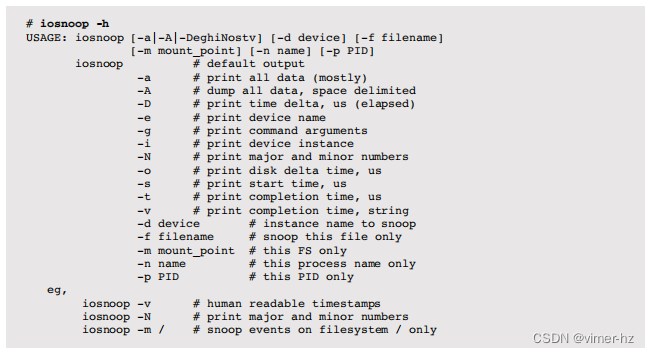
跟踪磁盘I/O
在启动(非缓存的)vim文本编辑器时的磁盘I/O:

列标识如下:
- PID:进程ID
- COMM:进程名称
- D:方向(R = 读取,W = 写入)
- BLOCK:磁盘块地址(扇区)
- SIZE:I/O大小(字节)
- PATHNAME:文件系统路径名(如果适用且已知)
前面的示例跟踪了一个UFS文件系统,其中路径名通常是已知的。路径名未知的情况包括UFS磁盘文件系统元数据以及当前所有ZFS I/O。有一个功能请求,要求将ZFS路径名添加到DTrace io提供程序中,这将被iosnoop(1M)所见。(与此同时,可以通过对内核进行动态跟踪来获取ZFS路径名。)
时间戳
以下显示了一个运行在ZFS上的Riak云数据库(使用Erlang虚拟机beam.smp)。它正在使用来自硬件存储控制器的虚拟磁盘。
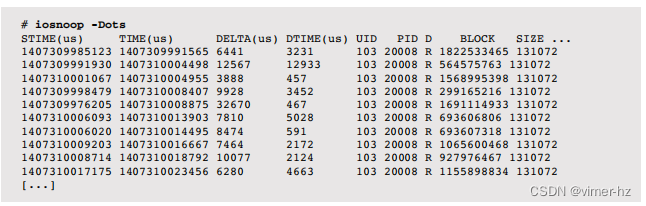
宽输出已被截断以适应;右侧缺失的列是 COMM 和 PATHNAME,它们都包含了 beam.smp <none>。
输出显示了一个128 K字节读取的工作负载,具有某种随机的块地址。iostat(1)确认了这个工作负载的结果:

iostat(1)没有显示I/O响应时间的变化,但是iosnoop的DELTA(us)列(微秒)显示了这种变化。在这个样本中,I/O的响应时间介于3,888到32,670微秒之间。DTIME(us)列显示了从I/O完成到上一个磁盘事件的时间,作为对该I/O实际磁盘服务时间的估计。
iosnoop(1M)的输出大致按照完成时间排序,由TIME(us)列显示。请注意,起始时间STIME(us)并不完全按照相同的顺序排列。这表明磁盘设备已经重新排序了请求。最慢的I/O(32,670)是在1407309976205之前发出的,而之前已完成的I/O是在1407310001067发出的。对于旋转磁盘,重新排序的原因通常可以通过检查磁盘地址(BLOCK)并考虑电梯搜索算法来看到。在这个例子中并不明显,因为它是在几个物理磁盘上构建的虚拟磁盘,偏移映射仅由磁盘控制器知道。
在繁忙的生产服务器上,仅仅几秒的跟踪就可以生成数百行的iosnoop(1M)输出。这非常有用(可以研究到底发生了什么),但也可能需要花费大量时间来阅读。考虑使用另一种工具(比如散点图,在第9.6.12节中介绍)来可视化输出,以便更快地考虑。
9.6.9 blktrace
blktrace(8)是Linux上用于跟踪块设备I/O事件的自定义跟踪工具,包括一个内核组件来跟踪和缓冲数据(后来被移动到tracepoints),以及一个用于控制和报告的机制,供用户态工具使用。这些工具包括blktrace(8),blkparse(1)和btrace(8)。
blktrace(8)使内核块驱动程序跟踪并检索原始跟踪数据,可以使用blkparse(1)来处理以产生可读的输出。为了方便起见,btrace(8)工具同时运行blktrace(8)和blkparse(1),因此以下两者是等效的:

默认输出
以下显示了btrace(8)的默认输出,并捕获了由cksum(1)命令执行的单个磁盘读取事件:
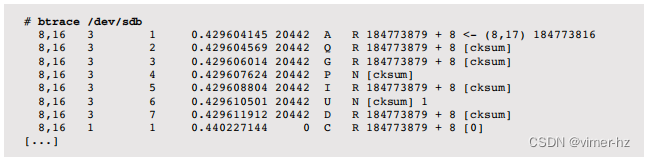
对于这个单个磁盘I/O,报告了八行输出,显示了涉及块设备队列和设备的每个动作(事件)。
默认情况下,有七列:
1. 设备的主要和次要编号
2. CPU ID
3. 序列号
4. 动作时间,以秒为单位
5. 进程ID
6. 动作标识符(见下文)
7. RWBS描述:可能包括R(读取)、W(写入)、D(块丢弃)、B(屏障操作)、S(同步)
这些输出列可以使用 -f 选项进行自定义。它们后面是基于动作的自定义数据。
最终的数据取决于动作。例如,184773879 + 8 [cksum] 表示在块地址184773879处的大小为8个(扇区)的I/O,来自名为 cksum 的进程。
动作标识符
这些在blkparse(1)手册页中有描述:


这个列表被包含在这里,因为它还显示了blktrace框架的可见性。
动作过滤
blktrace(8)和btrace(8)命令可以过滤动作,只显示感兴趣的事件类型。例如,要仅跟踪D动作(已发出的I/O),请使用过滤选项 -a issue:

其他过滤器在blktrace(8)手册页中有描述,比如仅跟踪读取(-a read)、写入(-a write)或同步操作(-a sync)。
9.6.10 MegaCli
磁盘控制器(主机总线适配器)由系统外部的硬件和固件组成。即使是操作系统分析工具,甚至是动态跟踪,也无法直接观察它们的内部。有时,可以通过仔细观察输入和输出(包括通过静态或动态内核跟踪),来推断它们的工作方式,以了解磁盘控制器如何响应一系列的I/O操作。
对于特定的磁盘控制器,例如LSI的MegaCli,有一些分析工具可供使用。以下是最近的控制器事件:
最后两个事件显示,在凌晨3:00到5:55之间发生了一次巡逻读取(可能会影响性能)。巡逻读取在第9.4.3节“存储类型”中提到过;它们读取磁盘块并验证它们的校验和。
MegaCli有许多其他选项,可以显示适配器信息、磁盘设备信息、虚拟设备信息、外壳信息、电池状态和物理错误。这些帮助识别配置和错误问题。即使有了这些信息,有些问题仍然很难分析,比如为什么特定的I/O操作需要几百毫秒。
查看供应商文档,了解磁盘控制器分析的接口情况,如果有的话。
9.6.11 smartctl
磁盘具有控制磁盘操作的逻辑,包括排队、缓存和错误处理。与磁盘控制器类似,操作系统无法直接观察磁盘的内部行为,通常是通过观察I/O请求及其延迟来推断。
许多现代驱动器提供SMART(自我监控、分析和报告技术)数据,其中包含各种健康统计信息。以下是在Linux上使用smartctl(8)显示的样本数据(这是访问虚拟RAID设备中的第一个磁盘,使用-d megaraid,0):
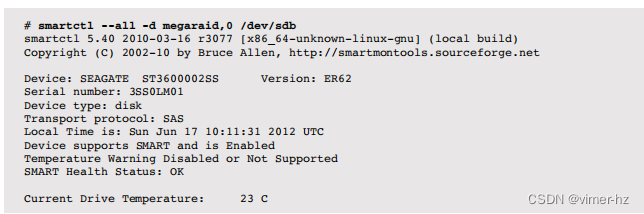
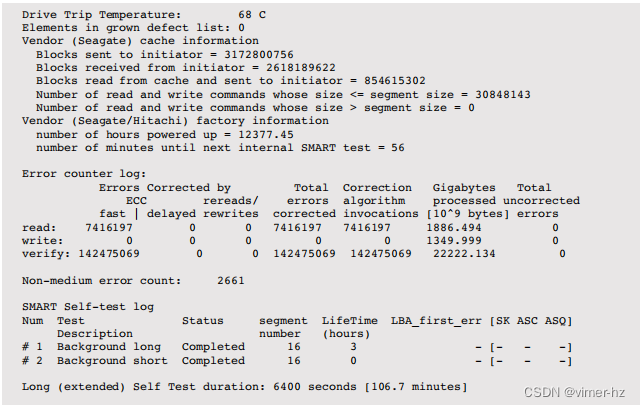
虽然这非常有用,但它不能解决有关单个缓慢磁盘I/O的问题,类似于内核跟踪框架。
9.6.12 Visualizations
有许多类型的可视化工具可帮助分析磁盘I/O性能。本节将使用各种工具的截图来演示这些工具。关于一般可视化工具的讨论,请参阅第2章方法论中的第2.10节“可视化”。
折线图
性能监控解决方案通常将磁盘IOPS、吞吐量和利用率随时间的测量值绘制为折线图。这有助于说明基于时间的模式,例如一天中负载的变化,或者像文件系统刷新间隔这样的周期性事件。
注意正在绘制的度量标准。跨所有磁盘设备的平均值可能隐藏了不平衡的行为,包括单个设备的异常值。跨较长时间段的平均值也可能隐藏了较短期的波动。
散点图
散点图对于可视化I/O跟踪数据非常有用,这些数据可能包含成千上万个事件。图9.10中的示例绘制了来自生产MySQL数据库服务器的1,400个I/O事件,使用iosnoop捕获,并使用R绘制。
散点图根据它们的完成时间(x轴)和I/O响应时间(y轴)显示了读取(+)和写入(o)。其他维度也可以绘制,例如,在y轴上绘制磁盘块地址。
这里可以看到几个读取异常值,延迟超过150毫秒。以前不知道这些异常值的原因。这个散点图以及其他包含类似异常值的图表显示,它们发生在大量写入之后。这些写入具有较低的延迟,因为它们从RAID控制器的写回缓存返回,该缓存在返回完成后将它们写入设备。有人怀疑这些读取在排队等待设备写入。
这个散点图显示了一个服务器的几秒钟。多个服务器或更长的时间间隔可以捕获更多事件,当绘制时会合并在一起,变得难以阅读。在那时,考虑使用热图(请参阅本章后面的“延迟热图”部分)。
偏移热图
图9.11显示了一个热图(更正式地称为列量化),用于可视化磁盘I/O访问模式。
磁盘偏移(块地址)显示在y轴上,时间显示在x轴上。每个像素根据在该时间和延迟范围内落入其中的I/O数量着色,数字越大颜色越深。可视化的工作负载是一个文件系统存档,从块0逐渐遍布整个磁盘。较深的线表示顺序I/O,较浅的云表示随机I/O。
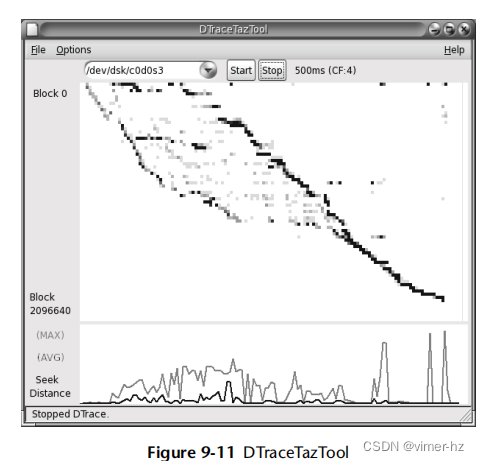
这种可视化是由Richard McDougall在1995年引入的,使用taztool。此屏幕截图来自我在2006年编写的DTrace版本的taztool,名为DTraceTazTool。磁盘I/O偏移热图后来出现在其他工具中,包括Sun ZFS存储设备分析、Joyent云分析和seekwatcher(Linux)。
延迟热图
热图的另一种用途是显示I/O延迟的完整分布[Gregg 10b],如图9.12所示。
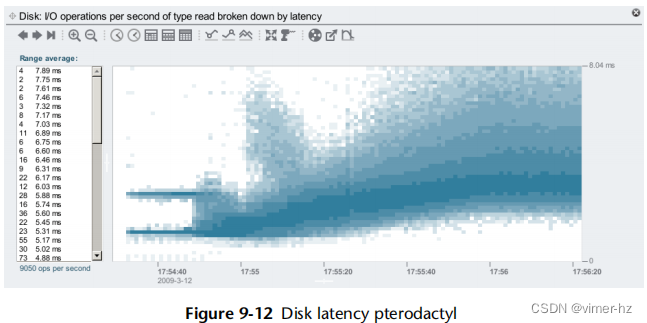
y轴显示I/O响应时间(延迟),x轴显示时间的流逝。可视化的工作负载是实验性的,一次对多个磁盘应用顺序读取,以探索总线和控制器的限制。结果的热图出乎意料(它被描述为翼龙),显示了仅考虑平均值时可能遗漏的信息。这个特定的屏幕截图来自Oracle ZFS存储设备上的Analytics。
利用率热图
每个设备的利用率也可以显示为热图,以便识别设备利用率平衡和个别异常值;参见图9.13。
设备利用率位于y轴,时间位于x轴,利用率和时间范围内设备数量由颜色深浅表示(颜色越深表示设备越多)。这个热图显示许多设备是空闲的或接近空闲(底部的深色区域),一组设备的利用率相似,变化在约20%至50%之间。右上角有一条深线,显示一些设备已达到100%。(这个特定的可视化是交互式的,所以这些像素可以点击以显示负责的主机和设备。)
我创建了这种可视化类型,以帮助识别单个的高热磁盘,包括之前描述的懒惰磁盘。这个屏幕截图来自Joyent Cloud Analytics,它显示了超过200台物理服务器云中的磁盘设备利用率。
9.7 Experimentation
本节介绍了用于主动测试磁盘I/O性能的工具。请参阅第9.5.10节“微基准测试”,了解建议的方法论。
在使用这些工具时,最好让iostat(1)持续运行,以便可以立即对任何结果进行双重检查。
9.7.1 Ad Hoc
dd(1)命令(设备到设备的复制)可用于执行顺序磁盘性能的临时测试。例如,使用1兆字节的I/O大小进行顺序读取测试:

基于Solaris系统的dd(1)版本目前不会打印这个摘要。理想情况下,磁盘设备路径将是字符特殊的,以便直接应用请求的工作负载。Solaris系统默认提供这些特殊路径,在/dev/rdsk下。在Linux上,如果可用,raw(8)命令可以创建字符特殊版本,在/dev/raw下。如果使用块特殊文件,则要考虑缓冲。
顺序写入可以类似地进行测试;但是,请注意可能会销毁磁盘上的所有数据,包括主引导记录和分区表!
9.7.2 Custom Load Generators
为了测试定制的工作负载,您可以编写自己的负载生成器,并使用iostat(1)来测量结果性能。自定义负载生成器可以是一个简短的C程序,它打开设备路径并应用预期的工作负载。在Linux上,可以使用O_DIRECT打开块特殊设备文件,以避免缓冲。如果您使用更高级的语言,请尝试使用也避免缓冲的系统级接口(例如,在Perl中使用sysread())。
9.7.3 Micro-Benchmark Tools
可用的磁盘基准测试工具包括,在Linux上,例如hdparm(8):

-T选项测试缓存读取,而-t选项测试磁盘设备读取。结果显示了在磁盘缓存命中和未命中之间的显著差异。
请仔细研究工具文档以了解任何注意事项,并参阅第12章“基准测试”,以了解有关微基准测试的更多背景知识。还请参阅第8章“文件系统”,了解通过文件系统测试磁盘性能的工具,其中有许多其他工具可用。
9.7.4 Random Read Example
作为一个示例实验,编写了一个定制工具来执行磁盘设备路径的随机8K字节读取工作负载。并发地运行了从一个到五个实例的该工具,并运行了iostat(1)。以下是基于Linux和Solaris系统的结果。
Linux
已删除写入列(全部为零):
请注意avgqu-sz的逐步增加,以及await的延迟增加。
Solaris
来自基于Solaris的系统的相同实验:

请注意actv的逐步增加,以及asvc_t的延迟增加。这是在由RAID卡支持的虚拟磁盘设备上进行的测试,它允许进行许多并发I/O(其sd_max_throttle为256;请参阅第9.8.1节,“操作系统可调参数”)。物理磁盘设备具有较低的并发设置,并且会更早地将I/O排队到驱动程序中,从而增加等待列而不是活动列。
9.8 Tuning
在第9.5节“方法论”中涵盖了许多调优方法,包括缓存调优、扩展和工作负载特征化,这些方法可以帮助您识别和消除不必要的工作。调优的另一个重要领域是存储配置,它可以作为静态性能调优方法论的一部分进行研究。接下来的章节展示了可以调优的不同领域:操作系统、磁盘设备和磁盘控制器。可用的可调参数因操作系统的版本、磁盘型号、磁盘控制器及其固件而异;请参阅它们各自的文档。尽管更改可调参数可能很容易,但默认设置通常是合理的,很少需要进行大量调整。
9.8.1 Operating System Tunables
这些包括ionice(1)、资源控制和内核可调参数。
ionice
在Linux上,ionice(1)命令可用于为进程设置I/O调度类别和优先级。调度类别以数字形式标识:
- 0,none:未指定类别,因此内核将选择默认的——尽力而为,其优先级基于进程nice值。
- 1,real-time:对磁盘的最高优先级访问。如果被滥用,这可能会使其他进程饥饿(就像RT CPU调度类别一样)。
- 2,best effort:默认的调度类别,支持优先级0-7,0为最高。
- 3,idle:只有在磁盘闲置一段时间后才允许进行磁盘I/O操作。
以下是示例用法:
![]()
将进程ID 1623置于idle I/O调度类别中。对于长时间运行的备份作业,这可能是理想的,以减少它们干扰生产工作负载的可能性。
资源控制
现代操作系统提供了资源控制,以自定义方式管理磁盘或文件系统的I/O使用情况。
对于Linux,容器组(cgroups)块I/O(blkio)子系统为进程或进程组提供了存储设备资源控制。这可以是比例权重(如份额)或固定限制。可以独立设置读取和写入的限制,以及IOPS或吞吐量(每秒字节)的限制。
一些基于Solaris的系统具有ZFS I/O限制,它在文件系统级别(而不是磁盘级别)进行I/O限制,并且可以针对每个区域进行设置。这在第11章“云计算”中有描述。
可调参数
操作系统可调参数示例包括
- /sys/block/sda/queue/scheduler(Linux):选择I/O调度程序策略:noop、deadline、an(anticipatory)、cfq。请参阅第9.4节“架构”中对这些的早期描述。
- sd_max_throttle(Solaris):这调节可以发送到sd存储设备的最大命令数。对于由多个磁盘支持的存储阵列支持的虚拟设备,增加此值可能是有意义的。
可以通过对活动命令数量进行分析来获取调整sd_max_throttle的信息,以了解其是否接近限制。例如(来自生产云环境):
这显示了当前sd_max_throttle的活动值为256,而I/O的最高速率仅在8-15范围内。如果在存储设备上排队更合理,那么这个值就不需要调整。
与其他内核可调参数一样,请查看供应商文档以获取完整列表、描述和警告。公司或供应商政策也可能禁止设置这些参数。
9.8.2 Disk Device Tunables
在Linux上,hdparm(8)工具可以设置各种磁盘设备的可调参数。在Solaris上,可以使用format(1M)命令。
9.8.3 Disk Controller Tunables
可用的磁盘控制器可调参数取决于磁盘控制器型号和供应商。以下是使用MegaCli命令查看的Dell PERC 6卡的一些设置,以此来给您一个概念:

每个设置都有一个相当描述性的名称,并在供应商文档中有更详细的描述。
10 Network
随着系统变得更加分布式,特别是在云计算环境中,网络在性能中扮演着更重要的角色。除了改善网络延迟和吞吐量外,另一个常见任务是消除由丢包引起的延迟异常。
网络分析涵盖硬件和软件。硬件是物理网络,包括网络接口卡、交换机、路由器和网关(这些通常也包含软件)。系统软件是内核协议栈,通常是TCP/IP,以及所涉及的每个协议的行为。
网络经常因潜在的拥塞而被指责性能不佳。本章将展示如何弄清楚实际发生了什么,这可能会证明网络无辜,从而使分析得以继续进行。
本章分为五个部分,前三部分提供网络分析的基础知识,后两部分展示其在基于Linux和Solaris的系统中的实际应用。这些部分包括:
背景介绍与网络相关的术语、基本模型和关键的网络性能概念。
架构提供物理网络组件和网络协议栈的通用描述。
方法论描述了性能分析的方法论,包括观察性和实验性方法。
分析展示了用于在基于Linux和Solaris的系统上进行分析和实验的网络性能工具。
调整描述了示例可调参数。
10.1 Terminology
供参考,本章中使用的与网络相关的术语包括以下内容:
接口:术语接口端口指的是物理网络连接器。术语接口或链接指的是操作系统所见和配置的网络接口端口的逻辑实例。
数据包:术语数据包通常指的是IP级可路由消息。
帧:物理网络级消息,例如以太网帧。
带宽:网络类型的最大数据传输速率,通常以每秒位数(bits per second)为单位。例如,“10 GbE”是带有10 Gbits/s带宽的以太网。
吞吐量:网络端点之间当前的数据传输速率,以每秒位数或每秒字节数为单位。
延迟:网络延迟可以指消息在端点之间往返的时间,也可以指建立连接所需的时间(例如TCP握手),不包括随后的数据传输时间。
本章还介绍了其他术语。术语表包括基本术语供参考,包括客户端、以太网、主机、RFC、服务器、SYN、ACK等。
还请参阅第2章和第3章的术语部分。
10.2 Models
以下简单模型阐明了一些基本的网络和网络性能原理。第10.4节《架构》将深入探讨,包括实现特定的细节。
10.2.1 Network Interface
网络接口是操作系统中用于网络连接的端点;它是由系统管理员配置和管理的抽象概念。

网络接口如图10.1所示。网络接口在其配置中被映射到物理网络端口。端口连接到网络,通常具有单独的发送和接收通道。
10.2.2 Controller
网络接口卡(NIC)为系统提供一个或多个网络端口,并容纳一个网络控制器:用于在端口和系统I/O传输之间传输数据包的微处理器。图10.2显示了一个带有四个端口的示例控制器,展示了所涉及的物理组件。

控制器可以作为一个独立的卡片提供,也可以集成在系统主板上。
10.2.3 Protocol Stack
网络连接是通过一堆协议完成的,每一层都有特定的目的。图10.3展示了两种堆栈模型,并附带示例协议。

较低的层被绘制得更宽,以表示协议的封装。发送的消息从应用程序向物理网络下传。接收的消息向上传递。
请注意,以太网标准也描述了物理层,以及如何使用铜线或光纤。
尽管TCP/IP堆栈已成为标准,但考虑到OSI模型也是有用的。例如,OSI会话层通常以BSD套接字的形式存在于TCP/IP堆栈中。 "层"这个术语来自OSI,其中第3层指的是网络协议。
10.3 Concepts
以下是网络和网络性能中的一些重要概念:
10.3.1 Networks and Routing
网络是由通过网络协议地址相关联的连接主机组成的集合。拥有多个网络而不是一个巨大的全球网络有许多优点,尤其是可扩展性。一些网络消息将广播到所有相邻的主机。通过创建较小的子网络,这些广播消息可以在本地进行隔离,以免在规模化时造成洪泛问题。这也是将常规消息的传输仅限于源和目的地之间的网络的基础,从而更有效地利用网络基础设施。

路由管理跨这些网络传递消息(称为数据包)。路由的作用如图10.4所示。从主机A的角度来看,本地主机就是主机A本身。所描绘的其他主机都是远程主机。主机A可以通过本地网络连接到主机B,通常由网络交换机驱动(参见第10.4节,架构)。主机A可以通过路由器1连接到主机C,通过路由器1、2和3连接到主机D。由于网络组件(如路由器)是共享的,来自其他流量(例如,主机C到主机E)的争用可能会影响性能。主机对之间的连接涉及单播传输。多播传输允许发送方同时向多个目的地发送,这些目的地可能跨越多个网络。路由器配置必须支持此功能以允许传送。
用于路由数据包的地址信息包含在IP头部中。
10.3.2 Protocols
网络协议标准,如IP、TCP和UDP等,是系统和设备之间进行通信的必要条件。通信是通过传输称为数据包的消息来完成的,通常是通过封装有效载荷数据来进行的。
网络协议具有不同的性能特征,这些特征源自原始协议设计、扩展或软件或硬件的特殊处理。例如,IP协议的不同版本IPv4和IPv6可能通过不同的内核代码路径进行处理,并且可能表现出不同的性能特征。
通常,还有一些系统可调参数可以影响协议的性能,例如通过更改缓冲区大小、算法和各种计时器等设置。这些特定协议的差异将在后面的部分中描述。
数据包的大小及其有效载荷也会影响性能,较大的尺寸可以提高吞吐量并减少数据包开销。对于TCP/IP和以太网,数据包的大小通常在54到9,054字节之间,包括封装数据的协议头部的54字节(或更多,取决于选项或版本)。
10.3.3 Encapsulation
封装在有效载荷的开头(标题)、结尾(页脚)或两者都添加了元数据。这不会改变有效载荷数据,尽管会稍微增加消息的总大小,这会为传输增加一些开销。图10.5展示了一个TCP/IP堆栈与以太网的封装示例。

E.H.是以太网头,E.F.是可选的以太网页脚。
10.3.4 Packet Size
数据包大小通常受网络接口的最大传输单元(MTU)大小限制,对于许多以太网网络来说,MTU大小通常配置为1,500字节。以太网支持更大的数据包(帧),最大可达约9,000字节,称为超大帧。这些超大帧可以提高网络吞吐量性能,以及数据传输的延迟,因为它们需要更少的数据包。
两个因素的交汇干扰了超大帧的采用:老旧的网络硬件和配置错误的防火墙。不支持超大帧的老旧硬件可以使用IP协议对数据包进行分段,或者响应ICMP的“无法分段”错误,通知发送方减小数据包大小。现在配置错误的防火墙开始起作用:过去曾发生过基于ICMP的攻击(包括“死亡之ping”),一些防火墙管理员对此做出了回应,即阻止所有ICMP。这样就阻止了有用的“无法分段”消息传递给发送方,并在数据包大小超过1,500后导致网络数据包被静默丢弃。
为了避免这个问题,许多系统坚持使用1,500的MTU默认值。1,500的MTU帧的性能已经通过网络接口卡功能得到了改进,包括TCP卸载和大分段卸载。这些功能向网络卡发送更大的缓冲区,然后网络卡可以使用专用和优化的硬件将它们分割成较小的帧。这在某种程度上缩小了1,500和9,000的MTU网络性能之间的差距。
10.3.5 Latency
延迟是网络性能的重要指标,可以通过不同的方式进行测量,包括名称解析延迟、ping延迟、连接延迟、首字节延迟、往返时间和连接寿命。这些都是由客户端连接到服务器时进行的测量。
名称解析延迟
当建立到远程主机的连接时,主机名通常被解析为IP地址,例如通过DNS解析。这需要的时间可以单独测量为名称解析延迟。在最坏情况下,这种延迟涉及到名称解析超时,可能需要几十秒钟的时间。
有时,名称解析对应用程序的运行并非必需,可以禁用以避免这种延迟。
Ping延迟
这是一个ICMP回显请求到回显响应的时间,由ping(1)命令测量。此时间用于测量主机之间的网络延迟,包括中间的跳数,并且被测量为一个数据包往返所需的时间。它被广泛使用,因为它简单易行,而且通常容易获得:许多操作系统默认会对ping作出响应。

表10.1显示了示例ping延迟。为了更好地说明涉及的数量级,缩放列显示了基于想象中本地主机ping延迟为一秒的比较。
在接收端,ICMP回显请求通常在中断上下文中处理并立即返回,最大程度地减少了执行内核代码的额外时间。在发送端,由于时间戳是从用户态测量的,可能会包含一点额外的时间,使得内核上下文切换和内核代码路径时间也被计入其中。
连接延迟
连接延迟是建立网络连接所需的时间,在任何数据传输之前。对于TCP连接延迟来说,这是TCP握手时间。从客户端测量,它是从发送SYN到接收相应的SYN-ACK的时间。连接延迟更好地称为连接建立延迟,以清晰地区分它与连接寿命。
连接延迟类似于ping延迟,尽管它会调用更多内核代码来建立连接,并包括重新传输任何丢失的数据包的时间。特别是TCP的SYN数据包,如果服务器的等待队列已满,可能会被服务器丢弃,导致客户端重新传输SYN。这发生在TCP握手期间,因此连接延迟包括重新传输延迟,增加了一秒或更多的时间。
连接延迟之后是首字节延迟。
首字节延迟
也称为首字节时间(TTFB),首字节延迟是从建立连接到接收第一个字节的时间。这包括远程主机接受连接的时间,安排服务线程的时间以及该线程执行并发送第一个字节的时间。
虽然ping和连接延迟测量网络产生的延迟,但首字节延迟包括目标服务器的思考时间。这可能包括服务器超负荷时需要处理请求的时间(例如TCP等待队列),以及安排服务器的时间(CPU运行队列延迟)。
往返时间
往返时间描述了网络数据包在端点之间进行往返的时间。
连接寿命
连接寿命是从建立网络连接到关闭连接的时间。一些协议使用保持活动策略,延长连接的持续时间,以便将来的操作可以使用现有连接,避免连接建立的开销和延迟。
10.3.6 Buffering
尽管可能会遇到各种网络延迟,但通过在发送端和接收端使用缓冲区,网络吞吐量可以保持在较高的速率。较大的缓冲区可以通过在阻塞并等待确认之前继续发送数据来缓解较高的往返时间的影响。
TCP采用了缓冲区,以及滑动发送窗口,以提高吞吐量。网络套接字也有缓冲区,并且应用程序可能会额外使用它们来在发送之前聚合数据。
缓冲也可以由外部网络组件执行,例如交换机和路由器,以提高其自身的吞吐量。不幸的是,这些组件上的大型缓冲区的使用可能会导致一个称为缓冲膨胀的问题,其中数据包被排队等待了很长时间。这会导致主机上的TCP拥塞避免,从而限制性能。Linux 3.x内核已添加了用于解决此问题的功能(包括字节队列限制、CoDel队列管理[Nichols 12]和TCP小队列),并且有一个讨论此问题的网站[1]。
缓冲(或大型缓冲)的功能可能最好由端点(主机)而不是中间网络节点提供,遵循一种称为端到端论证的原则[Saltzer 84]。
10.3.7 Connection Backlog
另一种类型的缓冲是用于初始连接请求。TCP实现了一个后备队列,在用户空间进程接受之前,SYN请求可以在内核中排队等待。当有太多的TCP连接请求无法及时被进程接受时,后备队列达到上限,SYN数据包被丢弃,稍后由客户端重新发送。这些数据包的重新传输会导致客户端连接时间延迟。衡量后备队列丢弃是衡量网络连接饱和度的一种方法。
10.3.8 Interface Negotiation
网络接口可以以不同的模式运行,并与另一端点进行自动协商。一些例子包括:
带宽:例如,10、100、1,000、10,000 Mbits/s
双工:半双工或全双工
这些例子来自以十进制为基础的以太网,其倾向于使用圆整的基数限制带宽。其他物理层协议,如SONET,具有不同的可能带宽集合。
网络接口通常根据其最高带宽和协议来描述,例如,1 Gbit/s以太网(1 GbE)。然而,如果需要,该接口可以自动协商到较低的速度。如果另一个端点无法以更快的速度运行,或者为了适应连接介质的物理问题(如糟糕的布线),这种情况可能会发生。
全双工模式允许双向同时传输,具有分别用于发送和接收的独立路径,可以以全带宽运行。半双工模式一次只允许一个方向的传输。
10.3.9 Utilization
网络接口利用率可以计算为当前吞吐量除以最大带宽。由于自动协商导致带宽和双工模式可变,计算这一指标并不像听起来那么简单。
对于全双工模式,利用率适用于每个方向,并且被测量为该方向的当前吞吐量除以当前协商的带宽。通常情况下,只有一个方向的利用率最重要,因为主机通常是非对称的:服务器的传输负载较重,而客户端的接收负载较重。
一旦网络接口的某个方向达到100%的利用率,它就会成为瓶颈,限制性能。
一些操作系统性能工具仅以数据包为单位报告活动,而不是字节。由于数据包的大小可能差异很大(如前面提到的),因此不可能将数据包计数与字节计数相关联,用于计算吞吐量或(基于吞吐量的)利用率。
10.3.10 Local Connections
网络连接可以在同一系统上的两个应用程序之间发生。这些是本地主机连接,并使用虚拟网络接口:环回接口。
分布式应用程序环境通常被划分为逻辑部分,它们通过网络进行通信。这些部分可以包括Web服务器、数据库服务器和应用服务器。如果它们在同一主机上运行,则它们的连接是到本地主机的。
通过IP连接到本地主机是进程间通信(IPC)的IP套接字技术。另一种技术是Unix域套接字(UDS),它在文件系统上创建一个文件进行通信。使用UDS可能会提高性能,因为可以绕过内核TCP/IP栈,跳过内核代码和协议数据包封装的开销。
对于TCP/IP套接字,内核可能会在握手之后检测到本地主机连接,然后快捷方式使用TCP/IP栈进行数据传输,从而提高性能。这种方法在基于Solaris的系统中被称为TCP融合。
10.4 Architecture
本节介绍了网络架构:协议、硬件和软件。这些被总结为性能分析和调优的背景,重点放在性能特征上。更多详细信息,包括一般网络主题,请参阅网络文本([Stevens 93],[Hassan 03]),RFC以及网络硬件的供应商手册。一些这些资源在本章末尾列出。
10.4.1 Protocols
本节总结了TCP和UDP的性能特征。
TCP
传输控制协议(TCP)是创建可靠网络连接的常用互联网标准。TCP由[RFC 793]和后续补充规定。在性能方面,TCP可以在高延迟网络上通过使用缓冲和滑动窗口提供高吞吐量。TCP还采用拥塞控制和由发送方设置的拥塞窗口,以便在不同和变化的网络中保持高但适当的传输速率。拥塞控制避免发送过多的数据,这会导致拥塞和性能下降。
以下是TCP性能特性的摘要,包括自原始规范以来的补充:
- 滑动窗口:这允许在收到确认之前在网络上发送多个大小不超过窗口大小的数据包,即使在高延迟网络上也能提供高吞吐量。接收方通告窗口大小以指示其在该时间段内愿意接收多少个数据包。
- 拥塞避免:为了防止发送过多的数据并导致饱和,从而引发数据包丢失和更差的性能。
- 慢启动:作为TCP拥塞控制的一部分,它从一个小的拥塞窗口开始,然后随着在一定时间内收到的确认(ACK)增加而增加。当没有收到时,拥塞窗口会减小。
- 选择性确认(SACKs):允许TCP确认不连续的数据包,减少需要重新传输的数量。
- 快速重传:TCP可以根据接收到的重复ACK的到达而重新传输丢失的数据包,而不是等待定时器。这些是往返时间的函数,而不是通常更慢的定时器。
- 快速恢复:在检测到重复ACK后,通过将连接重置为执行慢启动来恢复TCP性能。在某些情况下,这些功能通过添加到协议头的扩展TCP选项来实现。
TCP性能的重要主题包括三次握手、重复ACK检测、拥塞控制算法、Nagle算法、延迟确认、SACK和FACK。
三次握手
主机之间使用三次握手建立连接。一个主机被动监听连接;另一个主动发起连接。要澄清的术语:被动和主动来自[RFC 793];然而,在套接字API之后,它们通常分别称为监听和连接。对于客户端/服务器模型,服务器执行监听,客户端执行连接。三次握手如图10.6所示。

客户端的连接延迟被指示,当最后一个ACK被发送时完成。之后,数据传输可以开始。这个图示了握手的最佳情况延迟。一个数据包可能会被丢弃,增加延迟,因为它超时并被重新发送。
重复ACK检测
重复ACK检测由快速重传和快速恢复算法使用。它在发送方执行,工作如下:
1. 发送方发送一个序列号为10的数据包。
2. 接收方回复一个序列号为11的ACK。
3. 发送方发送11、12和13。
4. 数据包11被丢弃。
5. 接收方通过发送对11的ACK来回复12和13,因为它仍然期望11。
6. 发送方接收到重复的11 ACK。
重复ACK检测也被TCP Reno和Tahoe拥塞避免算法使用。
拥塞控制:Reno和Tahoe
这些用于拥塞控制的算法首次在4.3BSD中实现:
- Reno:三次重复的ACK触发:拥塞窗口减半,慢启动阈值减半,快速重传和快速恢复。
- Tahoe:三次重复的ACK触发:快速重传,慢启动阈值减半,拥塞窗口设置为一个最大段大小(MSS),慢启动状态。
一些操作系统(例如Linux和Oracle Solaris 11)允许选择算法作为系统调整的一部分。为TCP开发的较新算法包括Vegas、New Reno和Hybla。
Nagle
这个算法[RFC 896]通过延迟传输小数据包来减少网络上的小数据包数量,以允许更多的数据到达和合并。只有在管道中存在数据并且已经遇到延迟时,才会延迟数据包。系统可能会提供一个可调参数来禁用Nagle,如果它的操作与延迟的ACK冲突,则可能需要禁用Nagle。
延迟确认(Delayed ACKs)
这个算法[RFC 1122]延迟发送确认ACK,最多延迟500毫秒,以便将多个ACK组合在一起。其他TCP控制消息也可以组合,从而减少网络上的数据包数量。
SACK和FACK
TCP选择性确认(SACK)算法允许接收方通知发送方它接收到了非连续的数据块。如果没有这个功能,数据包丢失最终会导致整个发送窗口被重新传输,以保持顺序确认的方案。这会损害TCP性能,大多数支持SACK的现代操作系统都会避免这种情况。
SACK已经被前向确认(FACK)扩展,Linux默认支持。FACK跟踪额外的状态,并更好地调节网络中未完成数据的数量,从而提高了整体性能[数学家96]。
UDP
用户数据报协议(UDP)是一个常用的Internet标准,用于在网络上发送消息,称为数据报[RFC 768]。在性能方面,UDP提供了:
简单性:简单且小的协议头减少了计算和大小的开销。
无状态性:连接和传输的开销更低。
无重传:这会给TCP连接增加显著的延迟。
虽然简单且通常性能良好,但UDP并不打算提供可靠性,数据可能会丢失或乱序。这使其不适用于许多类型的连接。UDP也没有拥塞避免机制,因此可能会导致网络拥塞。
一些服务,包括NFS的某些版本,可以根据需要配置为通过TCP或UDP进行操作。执行广播或组播数据的其他服务可能只能使用UDP。
10.4.2 Hardware
网络硬件包括接口、控制器、交换机和路由器。了解它们的操作是有用的,即使这些组件中的任何一个都由其他人员(网络管理员)管理。
接口
物理网络接口在连接的网络上发送和接收消息,称为帧。它们管理所涉及的电气、光学或无线信号传输,包括处理传输错误。
接口类型基于第二层标准,每种提供最大带宽。更高带宽的接口通常提供更低的延迟,尽管成本也更高。这在设计新服务器时通常是一个关键选择,以平衡服务器价格和期望的网络性能。
对于以太网,选择包括有线或光学,以及最大速度为1 Gbit/s(1 GbE)、10 GbE、40 GbE或100 GbE。许多供应商制造以太网接口控制器,尽管您的操作系统可能不支持其中一些的驱动程序。
接口利用率可以通过当前协商的带宽除以当前吞吐量来检查。大多数接口都有单独的传输和接收通道,在全双工模式下运行时,必须分别研究每个通道的利用率。
控制器
物理网络接口通过控制器提供给系统,控制器可以是集成在系统主板上的,也可以通过扩展卡提供。
控制器由微处理器驱动,并通过I/O传输(例如PCI)连接到系统。其中任何一个都可能成为网络吞吐量或IOPS的限制因素。
例如,双端口10 GbE网络接口卡连接到一个四通道PCI Express(PCIe)Gen 2插槽。该卡的最大带宽为2 x 10 GbE = 20 Gbits/s。插槽的最大带宽为4 x 4 Gbits/s = 16 Gbits/s。因此,在两个端口上的网络吞吐量都将受到PCIe Gen 2带宽的限制,而且不可能同时以线速率驱动它们(我也从实践中了解到这一点!)。
交换机和路由器
交换机提供了任意两个连接主机之间的专用通信路径,允许多个主机对之间进行传输而不会发生干扰。这项技术取代了集线器(以及之前的共享物理总线:例如,厚型以太网同轴电缆),后者将所有数据包与所有主机共享。这种共享导致了当主机同时传输时的竞争,这可能被接口识别为使用“带冲突检测的载波侦听多路访问”(CSMA/CD)算法的冲突,并指数级地进行退避和重传,直到成功。这种行为在负载下会导致性能问题。通过使用交换机,这些问题已经过去了,但是观察工具仍然具有冲突计数器,即使这些通常只是由于错误(协商或错误布线)而发生。
路由器在网络之间传递数据包,并使用网络协议和路由表确定有效的传递路径。在两个城市之间传递数据包可能涉及十几个或更多的路由器,以及其他网络硬件。路由器和路由通常配置为动态更新,以便网络可以自动响应网络和路由器的故障,并平衡负载。这意味着在特定时间点,没有人能确定数据包实际经过的路径。由于存在多条可能的路径,还存在数据包可能被乱序传递的可能性,这可能导致TCP性能问题。网络上的这种神秘元素经常被归咎于性能不佳:也许来自其他不相关主机的大量网络流量正在使源和目的地之间的路由器饱和?因此,网络管理团队经常需要免除其基础设施的责任。他们可以使用先进的实时监控工具来检查所有涉及的路由器和其他网络组件。
路由器和交换机都包含微处理器,它们本身在负载下可能成为性能瓶颈。作为一个极端的例子,我曾经发现一个早期的10 GbE交换机总共无法驱动超过11 Gbit/s的带宽,这是由于其有限的CPU容量。
其他设备
您的环境可能包括其他物理网络设备,例如集线器、桥接器、中继器和调制解调器。其中任何一个都可能是性能瓶颈和丢包的来源。
10.4.3 Software
网络软件包括网络堆栈、TCP和设备驱动程序。本节讨论与性能相关的主题。
网络堆栈
所涉及的组件和层取决于操作系统类型、版本、使用的协议和接口。图10.7描述了一个通用模型,显示了软件组件。

在现代内核上,堆栈是多线程的,入站数据包可以由多个CPU处理。入站数据包映射到CPU的方式可能有不同的方式:可以基于源IP地址的哈希进行,以均匀分配负载;或者可以基于最近处理套接字的CPU来进行,以从CPU缓存热度和内存局部性中受益。Linux和基于Solaris的系统都有不同的框架来支持这种行为。
Linux
在Linux系统中,TCP、IP和通用网络驱动程序软件是核心内核组件,设备驱动程序是额外的模块。数据包以struct sk_buff数据类型通过这些内核组件传递。
图10.8更详细地展示了通用网络驱动程序,包括新API(NAPI)接口,通过合并中断来提高性能。

通过利用多个CPU来处理数据包和TCP/IP堆栈可以实现高数据包速率。有关此内容已经记录在Linux 3.7内核文档(Documentation/networking/scaling.txt)中,其中包括:
- RSS:接收端侧扩展(Receive Side Scaling):适用于支持多队列并且能够将数据包哈希到不同队列的现代网卡,这些数据包通过直接中断不同的CPU来处理。此哈希可能基于IP地址和TCP端口号,以便来自同一连接的数据包最终由同一CPU处理。
- RPS:接收数据包定向(Receive Packet Steering):RSS的软件实现,适用于不支持多队列的网卡。这涉及一个简短的中断服务例程,将入站数据包映射到CPU进行处理。可以使用类似的哈希将数据包映射到CPU,基于数据包头字段。
- RFS:接收流定向(Receive Flow Steering):类似于RPS,但具有对套接字上一次在CPU上处理的亲和性,以提高CPU缓存命中率和内存局部性。
- 加速接收流定向(Accelerated Receive Flow Steering):这在支持此功能的网卡上通过硬件实现RFS。它涉及向网卡更新流信息,以便确定要中断哪个CPU。
- XPS:传输数据包定向(Transmit Packet Steering):对于具有多个传输队列的网卡,此功能支持由多个CPU向队列传输。
如果没有针对网络数据包的CPU负载平衡策略,网卡可能只会中断一个CPU,这可能会达到100%的利用率并成为瓶颈。根据诸如缓存一致性之类的因素将中断映射到CPU,就像RFS所做的那样,可以显着提高网络性能。irqbalancer进程也可以完成这个任务,它将中断请求(IRQ)线路分配给CPU。
Solaris
在基于Solaris的系统中,套接字层是 sockfs 内核模块,而 TCP、UDP 和 IP 协议被合并到 ip 模块中。数据包通过内核作为消息块 mblk_t 传递。更详细地展示了底层堆栈,如图10.9所示 [McDougall 06a]。

GLDv3 软件还通过垂直边界(vertical perimeters)提高了性能:这是与连接相关的每个 CPU 同步机制,避免了网络堆栈中每个数据结构的锁需求。这使用了一个称为序列化队列(squeue)的抽象,它处理每个连接。
通过启用 IP fanout 可以实现高数据包速率,该功能可以在多个 CPU 之间负载均衡入站数据包。
最近,Erik Nordmark 在 Solaris IP 数据通路重构项目中简化了网络堆栈的内部。关于之前堆栈状态的描述,包括性能[2],来自该项目:
IP 数据通路非常难以理解……这使得甚至修复代码中的错误都变得困难,更不用说使其性能达到最佳状态了。通过创建许多快速路径,即完整数据通路的子集,来改善性能。这进一步使代码维护成为一项危险的活动。
该项目已经集成到 snv_122,并将 IP 代码从 140,000 行减少了 34,000 行。
TCP
TCP 协议之前已经描述过。本节描述了内核 TCP 实现的性能特性:积压队列和缓冲区。
通过使用积压队列来处理连接的突发性增加。有两个这样的队列,一个用于在 TCP 握手完成之前的未完成连接(也称为 SYN 积压),另一个用于已建立会话等待被应用程序接受的已建立会话(也称为监听积压)。这些在图10.10中显示。

在早期的内核中只使用了一个队列,并且容易受到 SYN 洪水攻击的影响。SYN 洪水是一种 DoS 攻击类型,涉及向虚假 IP 地址发送大量的 SYN,以连接到监听 TCP 端口。这会在 TCP 等待完成握手时填满积压队列,阻止真实客户端连接。
有了两个队列,第一个可以作为潜在虚假连接的暂存区,只有在连接建立后才将其提升到第二个队列。第一个队列可以被设置得很长,以吸收 SYN 洪水,并优化为仅存储必要的最小元数据。
这些队列的长度可以独立调整(参见第10.8节,调整)。第二个队列也可以由应用程序设置为监听(listen())的积压参数。
通过使用与套接字关联的发送和接收缓冲区来提高数据吞吐量。这些在图10.11中显示。

对于写路径,数据被缓存在TCP发送缓冲区中,然后发送到IP进行传送。虽然IP协议具有分片数据包的能力,但TCP通过将数据作为MSS大小的段发送到IP来尽量避免这种情况。这意味着(重新)传输的单位与分片的单位相匹配;否则,丢失的分片将需要重新传输整个预分片的数据包。这种方法还可以提高TCP/IP堆栈的效率,因为它避免了常规数据包的分片和重组。
发送和接收缓冲区的大小都是可调整的。较大的大小会提高吞吐量性能,但每个连接消耗的主存更多。如果预计服务器需要更多发送或接收,则可以将其中一个缓冲区设置为较大。Linux内核还会根据连接活动动态增加这些缓冲区的大小。
网络设备驱动
网络设备驱动程序通常具有额外的缓冲区——环形缓冲区——用于在内核内存和网卡之间发送和接收数据包。
随着10GbE网络的引入,一个越来越常见的性能特性是使用中断合并模式。不是为每个到达的数据包中断内核,而是仅在定时器(轮询)到达或达到一定数量的数据包时才发送中断。这降低了内核与网卡通信的速率,允许更大的传输被缓冲,从而提高了吞吐量,尽管在延迟方面会付出一些代价。在基于Solaris的内核中,这被称为动态轮询。
10.5 Methodology
本节介绍了网络分析和调优的各种方法和练习。表10.2总结了这些主题。

有关更多策略和其中许多内容的介绍,请参阅第2章“方法论”。
这些方法可以单独跟随,也可以组合使用。我建议首先按照以下顺序使用以下策略:性能监控,USE方法,静态性能调优和工作负载特征化。
第10.6节“分析”展示了应用这些方法的操作系统工具。
10.5.1 Tools Method
工具方法是一个迭代使用可用工具、检查它们提供的关键指标的过程。这种方法可能会忽视工具未能提供良好或没有可见性的问题,并且可能需要花费大量时间来执行。
对于网络,工具方法可能涉及以下检查:
netstat -s:查看重传率和乱序数据包的高速率。对于何为“高”重传率取决于客户端:面向互联网的系统与不可靠的远程客户端应该具有比同一数据中心内的内部系统更高的重传率。
netstat -i:检查接口错误计数器(特定计数器取决于操作系统版本)。
ifconfig(仅适用于Linux版本):检查“errors”,“dropped”,“overruns”。
吞吐量:检查字节传输和接收的速率——在Linux上,通过ip(8);在Solaris上,通过nicstat(1)或dladm(1M)。高吞吐量可能会达到协商速度的线速并受到限制。它还可能在系统上的网络用户之间造成争用和延迟。
tcpdump/snoop:虽然在CPU成本方面可能昂贵,但在短时间内使用它们可能足以查看谁在使用网络,并识别可以消除的不必要工作。
dtrace/stap/perf:用于在应用程序和线路之间选择性地检查数据包,包括检查内核状态。
如果发现问题,请从可用工具的所有字段中检查以了解更多上下文。有关每个工具的更多信息,请参见第10.6节“分析”。还可以使用其他方法,这些方法可以识别更多类型的问题。
10.5.2 USE Method
USE方法用于快速识别所有组件中的瓶颈和错误。对于每个网络接口,在每个方向(发送(TX)和接收(RX))检查以下内容:
利用率(Utilization):接口忙于发送或接收帧的时间。
饱和度(Saturation):由于完全利用的接口而产生的额外排队、缓冲或阻塞程度。
错误(Errors):对于接收端:坏校验和、帧太短(小于数据链路头)或太长、碰撞(在交换网络中不太可能);对于发送端:迟到的碰撞(坏的布线)。
错误可能首先进行检查,因为它们通常很快检查完毕并且易于解释。
利用率通常不会直接由操作系统或监控工具提供。可以将其计算为每个方向(RX、TX)的当前吞吐量除以当前协商速度。当前吞吐量应以字节每秒的形式在网络上传输,包括所有协议头。
对于实施网络带宽限制(资源控制)的环境,如某些云计算环境中所发生的,网络利用率可能需要根据所施加的限制来衡量,而不仅仅是物理限制。
网络接口的饱和度很难测量。一些网络缓冲是正常的,因为应用程序可以比接口更快地发送数据。可能可以将其测量为应用程序线程在网络发送上被阻塞的时间,随着饱和度增加,这个时间可能会增加。此外,还要检查是否有与接口饱和度更密切相关的其他内核统计信息,例如,Linux的“overruns”或Solaris的“nocanputs”。
在TCP级别上的重传通常作为统计数据很容易获得,并且可以作为网络饱和度的指标。但是,它们是在服务器与其客户端之间的网络上测量的,可能发生在任何跳跃点。
USE方法也可以应用于网络控制器及其与处理器之间的传输。由于这些组件的可观察性工具稀少,根据网络接口统计信息和拓扑推断指标可能更容易。例如,如果网络控制器A包含端口A0和A1,则可以将网络控制器吞吐量计算为接口吞吐量A0 + A1的总和。有了已知的最大吞吐量,然后可以计算网络控制器的利用率。
10.5.3 Workload Characterization
对应用的负载进行表征是容量规划、基准测试和模拟工作负载的重要练习。通过识别可以消除的不必要工作,它还可以带来一些最大的性能增益。以下是用于表征网络工作负载的基本属性,它们可以共同提供对网络被要求执行的近似描述:
- 网络接口吞吐量:接收(RX)和发送(TX),每秒字节数
- 网络接口IOPS(每秒输入/输出操作数):接收(RX)和发送(TX),每秒帧数
- TCP连接速率:活动和被动连接,每秒连接数
"活动"和"被动"这两个术语在“三次握手”章节中有描述。
这些特性随着时间的推移可能会发生变化,因为一天中的使用模式会发生变化。关于随时间的监控在"性能监控"章节中有描述。以下是一个示例工作负载描述,展示了如何将这些属性结合在一起表达:
网络吞吐量基于用户的不同而变化,执行更多的写入(TX)比读取(RX)。峰值写入速率为每秒200兆字节和每秒210,000个数据包,峰值读取速率为每秒10兆字节和每秒70,000个数据包。入站(被动)TCP连接速率达到每秒3,000个连接。
除了对系统范围内描述这些特性外,它们也可以针对每个接口进行表达。如果观察到吞吐量已达到线路速率,这允许确定接口瓶颈。如果存在网络带宽限制(资源控制),则可能在达到线路速率之前会限制网络吞吐量。
高级工作负载表征/检查清单还可以包含其他细节以表征工作负载。这些被列为考虑的问题,也可以在彻底研究CPU问题时作为检查清单:
- 平均数据包大小是多少?RX、TX?
- 协议分布是什么?TCP与UDP?
- 活动的TCP/UDP端口是哪些?每秒字节数、每秒连接数?
- 哪些进程正在积极使用网络?
随后的章节回答了其中一些问题。有关此方法论和要测量的特性的更高级别摘要,请参阅第2章“方法论”。
10.5.4 Latency Analysis
有各种不同的时间(延迟)可以研究,以帮助理解和表达网络性能。它们包括网络延迟——一个稍微模糊的术语,通常用来指代连接初始化时间。各种网络延迟总结如表10.3所示。

其中一些延迟在第10.3节“概念”中有详细描述。延迟可以呈现为:
- 每个时间间隔的平均值:最好针对每个客户端/服务器对执行,以隔离中间网络中的差异
- 完整分布:作为直方图或热力图
- 每个操作的延迟:列出每个事件的详细信息,包括源和目标IP地址
问题的常见来源是由TCP重传引起的延迟异常值。这些可以使用完整分布或每个操作的延迟跟踪来识别,包括通过过滤最小延迟阈值来进行。
10.5.5 Performance Monitoring
性能监控可以识别出时间上的活动问题和行为模式。它将捕获活跃终端用户数量的变化,计时活动,包括分布式系统监控,以及通过网络进行的应用活动,包括备份。
网络监控的关键指标包括:
- 吞吐量:每秒接收和发送的网络接口字节数,最好是针对每个接口
- 连接:每秒TCP连接数,作为网络负载的另一个指标
- 错误:包括丢包计数器
- TCP重传:也有助于记录以与网络问题进行相关性分析
- TCP乱序数据包:也可能导致性能问题
对于实施网络带宽限制(资源控制)的环境,例如某些云计算环境,还可以收集与施加的限制相关的统计信息。
10.5.6 Packet Sniffing
数据包嗅探(又称数据包捕获)涉及从网络中捕获数据包,以便可以逐个数据包地检查其协议头和数据。对于观察性分析而言,这可能是最后的手段,因为从CPU和存储开销方面来看,执行起来可能会很昂贵。网络内核代码路径通常经过循环优化,因为它们需要处理每秒高达数百万个数据包,并且对任何额外的开销都很敏感。为了尝试减少这种开销,内核可能会使用环形缓冲区通过共享内存映射将数据包数据传递给用户级别的跟踪工具,例如,Linux的PF_RING选项而不是每个数据包的PF_PACKET [Deri 04]。
可以在服务器上创建一个数据包捕获日志,然后使用其他工具进行分析。有些工具仅打印内容;其他工具对数据包数据执行更高级别的分析。虽然阅读数据包捕获日志可能会耗费时间,但也可能会非常有启发性——准确显示了网络上正在发生的事情,以及数据包之间的延迟。这使得可以应用工作负载特征化和延迟分析方法。
数据包捕获日志可以包含以下内容:
- 时间戳
- 整个数据包,包括
- 所有协议头(例如以太网、IP、TCP)
- 部分或完整的有效载荷数据
- 元数据:数据包数量、丢包数量
作为数据包捕获的示例,以下显示了tcpdump工具的默认输出。

该输出包含一行总结每个数据包,包括IP地址、TCP端口和其他TCP头部详情的细节。
由于数据包捕获可能是一项消耗CPU资源的活动,大多数实现都包括在负载过重时放弃捕获事件而不是捕获它们的能力。丢弃数据包的计数可能会包含在日志中。
除了使用环形缓冲区外,数据包捕获实现通常允许用户提供过滤表达式,并在内核中执行此过滤。这通过不将不需要的数据包传输到用户级别来减少开销。
10.5.7 TCP Analysis
除了在第10.5.4节“延迟分析”中讨论的内容外,还可以调查其他特定的TCP行为,包括:
- TCP发送/接收缓冲区的使用情况
- TCP后台队列(backlog queues)的使用情况
- 由于后台队列已满而导致内核丢弃的数据包
- 拥塞窗口大小,包括零大小的广告(zero-size advertisements)
- 在TCP TIME-WAIT1间隔期间收到的SYN包
在同一目标端口上频繁连接到另一个服务器时,这些行为可能会成为可探究的问题,使用相同的源和目标IP地址。每个连接的唯一区分因素是客户端源端口(临时端口),对于TCP来说,这是一个16位值,并且可能会受到操作系统参数(最小和最大值)的进一步限制。
结合TCP TIME-WAIT间隔(可能为60秒),在60秒内高速连接的数量(超过65,536个)可能会遇到新连接的冲突。在这种情况下,当临时端口仍然与处于TIME-WAIT状态的先前TCP会话关联时发送了SYN包,如果新的SYN包被误识别为旧连接的一部分(发生冲突),则可能会被拒绝。为了避免这个问题,Linux内核会尝试快速重用或回收连接(通常效果良好)。
10.5.8 Drill-Down Analysis
可以根据需要调查内核网络堆栈的内部情况,通过逐层深入到处理数据包的网络接口驱动程序。内部结构复杂,这是一项耗时的活动。进行此活动的原因包括:
- 检查是否需要调整网络可调参数(而不是进行实验性修改)
- 确认内核网络性能特性是否生效,包括例如CPU分流和中断合并
- 解释内核丢弃的数据包
通常涉及使用动态跟踪来检查内核网络堆栈函数的执行情况。
10.5.9 Static Performance Tuning
静态性能调优侧重于已配置环境的问题。对于网络性能,要检查静态配置的以下方面:
- 可供使用的网络接口数量是多少?当前有多少在使用中?
- 网络接口的最大速度是多少?
- 网络接口的当前协商速度是多少?
- 网络接口是半双工还是全双工协商的?
- 网络接口配置了什么MTU?
- 网络接口是否进行了干线聚合(trunked)?
- 设备驱动程序、IP层和TCP层存在哪些可调参数?
- 是否有任何可调参数已从默认值更改?
- 路由是如何配置的?默认网关是什么?
- 数据路径中网络组件的最大吞吐量是多少(所有组件,包括交换机和路由器背板)?
- 转发是否已启用?系统是否作为路由器运行?
- DNS配置是如何的?服务器距离有多远?
- 网络接口固件的版本是否已知存在性能问题(bug)?
- 网络设备驱动程序或内核TCP/IP堆栈的版本是否已知存在性能问题(bug)?
- 是否存在软件实施的网络吞吐量限制(资源控制)?它们是什么?
这些问题的答案可能会揭示被忽视的配置选择。最后一个问题尤其适用于云计算环境,因为网络吞吐量可能受到限制。
10.5.10 Resource Controls
操作系统可能提供控制,以限制连接类型、进程或进程组的网络资源。这些控制可能包括以下类型:
- 网络带宽限制:由内核应用于不同协议或应用程序的允许带宽(最大吞吐量)。
- IP服务质量(QoS):网络流量的优先级排序,由网络组件(例如路由器)执行。这可以通过不同方式实现:IP头包含服务类型(ToS)位,包括一个优先级;这些位已经被重新定义,用于新的QoS方案,包括区分服务[RFC 2474]。其他协议层可能实现了其他优先级,以实现相同的目的。
你的网络可能有各种流量,可以分类为低优先级或高优先级。低优先级可能包括备份传输和性能监控流量。高优先级可能是生产服务器与客户端之间的流量。任何资源控制方案都可以用于限制低优先级流量,从而为高优先级流量提供更好的性能。
这些控制的工作方式因实现而异,将在第10.8节“调优”中讨论。
10.5.11 Micro-Benchmarking
有许多用于网络的基准测试工具。它们在调查分布式应用环境的吞吐量问题时特别有用,以确认网络至少可以达到预期的网络吞吐量。如果不能达到预期吞吐量,可以使用网络微基准测试工具来调查网络性能,这通常比应用程序更简单且更容易调试。
在网络调优到期望速度之后,可以重新关注应用程序。可能被测试的典型因素包括:
- 方向:发送或接收
- 协议:TCP或UDP,以及端口
- 线程数
- 缓冲区大小
- 接口MTU大小
更快的网络接口,例如10 Gbit/s,可能需要驱动多个客户端线程以达到最大带宽。一个示例网络微基准测试工具是iperf,在第10.7.1节“iperf”中介绍。
10.6 Analysis
本节介绍了基于Linux和Solaris操作系统的网络性能分析工具。请参阅前一节以了解在使用它们时要遵循的策略。本节中的工具列在表10.4中。

这是一些工具和功能的选择,用于支持第10.5节《方法论》,从系统范围的统计信息开始,然后深入到数据包嗅探和事件跟踪。查看工具文档,包括man手册,以获取其功能的完整参考资料。
10.6.1 netstat
这是一些工具和功能的选择,用于支持第10.5节《方法论》,从系统范围的统计信息开始,然后深入到数据包嗅探和事件跟踪。查看工具文档,包括man手册,以获取其功能的完整参考资料。
netstat(8)命令根据所使用的选项报告各种类型的网络统计信息。它类似于一个具有多种不同功能的多工具。这些功能包括以下内容:
- (默认):列出连接的套接字
- -a:列出所有套接字的信息
- -s:网络堆栈统计信息
- -i:网络接口统计信息
- -r:列出路由表
其他选项可以修改输出,包括-n以不将IP地址解析为主机名,以及-v用于提供详细信息的情况下的详细输出。
netstat(8)的输出在不同操作系统之间略有不同。
Linux
以下是netstat(8)接口统计信息的示例:

这些列包括网络接口(Iface)、MTU以及一系列接收(RX-)和发送(TX-)的指标:
- OK:成功传输的数据包
- ERR:数据包错误
- DRP:数据包丢失
- OVR:数据包溢出
数据包丢失和溢出是网络接口饱和的指示,可以与错误一起作为USE方法的一部分进行检查。
可以在-i选项中使用-c连续模式,它会每秒打印这些累积计数器。这提供了计算数据包速率的数据。
以下是netstat(8)网络堆栈统计信息的示例(已截断):


输出列出了各种网络统计信息,主要来自TCP,按其协议分组。幸运的是,其中许多具有长的描述性名称,因此它们的含义可能很明显。不幸的是,输出不一致,并包含拼写错误,这在以编程方式处理此文本时会带来麻烦。一些与性能相关的指标已用粗体突出显示,以显示可用的信息类型。其中许多需要对TCP行为有深入理解,包括近年来引入的新功能和算法。以下是一些要查找的示例指标:
- 转发数据包与接收到的总数据包的高比率:检查服务器是否应该转发(路由)数据包。
- 被动连接打开次数:这可以监视客户端连接方面的负载。
- 重传的段与发送出去的段的高比率:可能显示网络不可靠。这可能是预期的(Internet客户端)。
- 因套接字缓冲区溢出而从接收队列中剪切的数据包:这是网络饱和的迹象,可以通过增加套接字缓冲区来修复——前提是系统资源足够,可以维持应用程序的运行。
部分统计名称中包含有拼写错误。如果其他监控工具是基于相同的输出构建的,简单修复这些错误可能会带来问题。这样的工具最好通过阅读这些统计数据的/proc源文件来提供服务,这些源文件是/proc/net/snmp和/proc/net/netstat。例如:

这些/proc/net/snmp统计信息也用于SNMP管理信息库(MIB),为每个统计量提供了进一步的文档说明。扩展统计信息位于/proc/net/netstat中。
netstat(8)可以使用一个以秒为单位的间隔,以便每个间隔持续打印累积计数器。然后可以对此输出进行后处理,以计算每个计数器的速率。
Solaris
这里是netstat(1M)接口统计的一个示例:

列包括网络接口(名称)、MTU、网络(Net/Dest)、接口地址(Address)以及一系列指标:
- Ipkts:输入数据包(接收)
- Ierrs:输入数据包错误
- Opkts:输出数据包(发送)
- Oerrs:输出数据包错误(例如,迟到的碰撞)
- Collis:数据包碰撞(现在不太可能发生,因为有缓冲交换机)
- Queue:始终为零(硬编码,历史遗留)
如果提供了一个间隔(以秒为单位)作为参数,则输出会随时间总结单个接口的情况。可以使用-I选项指定要显示的接口。
以下是netstat(1M)网络堆栈统计的一个示例(截断):


输出按协议分组列出了各种网络统计信息。许多这些统计信息的名称都基于SNMP网络MIB,这些MIB解释了它们的用途。一些与性能相关的指标已经以粗体突出显示,以展示可用的信息类型。其中许多需要对现代TCP行为有深入的理解。要查找的指标包括与之前提到的Linux指标类似的指标,以及:
- tcpListenDrop和tcpListenDropQ0:它们分别显示套接字监听队列和SYN队列中丢弃的数据包数量。tcpListenDrops的增加表示应用程序无法接受的连接请求越来越多。可以通过两种方式来解决这个问题:增加监听队列的长度(tcp_conn_req_max_q),允许更大的连接突发队列;和/或为应用程序配置更大的系统资源。
报告的指标是从kstat中读取的,可以使用libkstat接口访问。
还可以提供一个间隔,它打印自启动以来的摘要,然后是间隔摘要。每个摘要显示该间隔的统计信息(不像Linux版本那样),因此速率是明显的。例如:

这显示了每秒的TCP连接速率,包括活动连接和被动连接。
10.6.2 sar
系统活动报告工具sar(1)可用于观察当前活动,并可配置以存档和报告历史统计信息。它在第4章“可观察性工具”中介绍,并在其他章节中适当提及。Linux版本通过以下选项提供网络统计信息:
- -n DEV:网络接口统计信息
- -n EDEV:网络接口错误
- -n IP:IP数据报统计信息
- -n EIP:IP错误统计信息
- -n TCP:TCP统计信息
- -n ETCP:TCP错误统计信息
- -n SOCK:套接字使用情况
提供的统计信息包括表10.5中显示的内容。
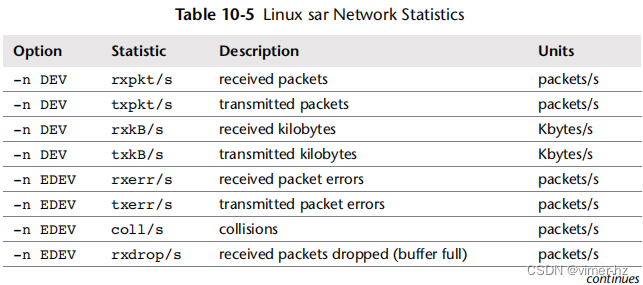

许多统计名称包括方向和所测量的单位:例如,rx表示“接收”,i表示“输入”,seg表示“段”等。请参阅man页面获取完整列表,其中包括ICMP、UDP、NFS和IPv6的统计信息,还注明了一些等效的SNMP名称(例如,ipInReceives对应irec/s)。以下示例每秒打印一次TCP统计信息:

输出显示了每秒大约30个的被动连接率(入站)。网络接口统计列(NET)列出了所有接口;然而,通常只有一个是感兴趣的。以下示例使用了一点awk(1)来过滤输出:

这显示了传输和接收的网络吞吐量。在这种情况下,两个方向的速率都超过了2兆字节/秒。
Solaris版本的sar(1)目前不提供网络统计信息(可以使用netstat(1M)、nicstat(1)和dladm(1M))。
10.6.3 ifconfig
ifconfig(8)命令允许手动配置网络接口。它还可以列出所有接口的当前配置,这在静态性能调整期间很有用,可以检查系统、网络和路由的配置情况。Linux版本的输出包含统计信息。

这些计数器与先前的netstat -i命令描述的相同。txqueuelen是接口传输队列的长度。调整此值的方法在man页面中有描述:
对于传输速度较慢且延迟较高的设备(例如调制解调器链接、ISDN),将此值设置为较小值是有用的,以防止快速大量传输过程对交互式流量(如telnet)造成过多干扰。
在Linux上,ifconfig(8)现在被认为已过时,被ip(8)命令取代。在Solaris上,ifconfig(1M)的各种功能也已经过时,被ipadm(1M)和dladm(1M)命令取代。
10.6.4 ip
Linux的ip(8)命令可用于配置网络接口和路由,以及观察它们的状态和统计信息。例如,显示链接统计信息:

这些计数器与先前描述的netstat -i命令相同,额外增加了接收(RX)和发送(TX)字节。这将允许轻松观察吞吐量;然而,ip(8)目前没有提供打印每个间隔报告的方法(请使用sar(1))。
10.6.5 nicstat
最初为基于Solaris的系统编写的开源工具nicstat(1)可打印网络接口统计信息,包括吞吐量和利用率。nicstat(1)遵循传统资源统计工具iostat(1M)和mpstat(1M)的风格。已经编写了C和Perl版本,适用于基于Solaris的系统和Linux [3]。
例如,以下是在Linux上版本1.92的输出:

第一个输出是自启动以来的总结,接着是间隔摘要。间隔摘要显示eth4接口的利用率为35%(这报告了来自RX或TX方向的最高当前利用率),读取速度为42兆字节/秒。
字段包括接口名称(Int)、最大利用率(%Util)、反映接口饱和统计的值(Sat),以及一系列以r表示“读取”(接收)和w表示“写入”(发送)为前缀的统计信息:
- KB/s:每秒字节数
- Pk/s:每秒数据包数
- Avs/s:平均数据包大小,字节
此版本支持各种选项,包括使用-z跳过零行(空闲接口)和-t用于TCP统计。
nicstat(1)对于使用USE方法特别有用,因为它提供了利用率和饱和度值。
10.6.6 dladm
在基于Solaris的系统上,dladm(1M)命令可以提供接口统计信息,包括数据包和字节速率、错误率和利用率,并且还可以显示物理接口的状态。
每秒显示ixgbe0接口上的网络流量:

输出的第一行是自启动以来的总和,接着是每秒摘要(-i 1)。输出显示该接口目前的接收和发送速率约为500千字节/秒。dladm show-link -S提供了另一种输出,显示了千字节速率、数据包速率和%Util列。
列出物理接口的状态:

这对于静态性能调优非常有用,可以检查接口是否已协商到最快速度。
在dladm(1M)之前,这些属性是使用ndd(1M)来检查的。
10.6.7 ping
ping(8)命令通过发送ICMP回显请求数据包来测试网络连接。例如:

输出包括每个数据包的往返时间(rtt),并显示各种统计摘要。由于时间戳是由ping(8)命令本身测量的,它们包含了在获取时间戳和执行网络I/O之间的一些CPU代码路径执行时间。
Solaris版本需要使用-s选项以这种方式发送连续的数据包。路由器可能会将使用的ICMP数据包视为比应用程序协议更低优先级的数据包,并且延迟可能显示比通常更高的变化。
10.6.8 traceroute
traceroute(8)命令发送一系列测试数据包,实验性地确定到主机的当前路由。这是通过每个数据包增加IP协议的生存时间(TTL)一个来完成的,导致路由到主机的网关序列通过发送ICMP生存时间过期响应消息来显露自己(前提是防火墙没有阻止它们)。
例如,测试加利福尼亚州主机与弗吉尼亚州目标之间的当前路由:

每个跳跃都显示了一系列三个RTT,可以用作粗略的网络延迟统计来源。与ping(8)一样,使用的数据包是低优先级的,可能比其他应用程序协议显示出更高的延迟。
路径也可以作为静态性能调优的一部分进行研究。网络被设计成动态的,并对故障做出响应。随着路径的改变,性能可能已经下降。
traceroute(8)最初由Van Jacobson编写。他后来创建了一个令人惊叹的工具称为pathchar。
10.6.9 pathchar
pathchar类似于traceroute(8),但包括跳跃之间的带宽[4]。这是通过多次发送一系列网络数据包大小并进行统计分析来确定的。以下是示例输出:

不幸的是,pathchar在某种程度上并没有变得流行(也许是因为据我所知,源代码没有发布),而且很难找到适用于现代操作系统的工作版本。它也非常耗时,根据跳数不同可能需要花费几十分钟来运行,尽管已经提出了减少此时间的方法[Downey 99]。
10.6.10 tcpdump
可以使用tcpdump(8)实用程序捕获和检查网络数据包。这可以在STDOUT上打印数据包摘要,也可以将数据包写入文件以供以后分析。后者通常更实用:数据包速率可能太高,无法实时跟踪它们的摘要。
将来自eth4接口的数据包转储到/tmp目录中的文件中:

输出记录了内核放弃传递给tcpdump(8)的数据包数量,这种情况发生在数据包速率过高时。
从转储文件中检查数据包:

输出的每一行显示了数据包的时间(以微秒为分辨率)、源和目标IP地址以及TCP头的值。通过研究这些内容,可以详细了解TCP的运作,包括高级功能如何为您的工作负载提供服务。
使用了-n选项来不将IP地址解析为主机名。还有各种其他选项可用,包括在可用时打印详细信息(-v)、链路层头部(-e)和十六进制地址转储(-x或-X)。例如:

在性能分析过程中,将时间戳列更改为显示数据包之间的增量时间(-ttt)或自第一个数据包以来的经过时间(-ttttt)可能很有用。
还可以提供一个表达式来描述如何过滤数据包(请参阅pcapfilter(7)),以便集中在感兴趣的数据包上。这在内核中执行以提高效率(除了Linux 2.0及更早版本)。
数据包捕获在CPU成本和存储方面都很昂贵。如果可能的话,尽量仅在短时间内使用tcpdump(8)以限制性能成本。
如果有理由不使用snoop(1M)实用程序,可以将tcpdump(8)添加到基于Solaris的系统中。
10.6.11 snoop
虽然tcpdump(8)已经移植到基于Solaris的系统中,但用于数据包捕获和检查的默认工具是snoop(1M)。它的行为类似于tcpdump(8),也可以创建数据包捕获文件以供以后检查。使用snoop(1M),数据包捕获文件遵循[RFC 1761]标准。
例如,在ixgbe0接口上捕获数据包并将其写入/tmp中的文件:

输出包括到目前为止接收到的数据包。使用安静模式(-q)可以将此内容抑制,以便在通过网络会话执行时不会导致额外的网络数据包。
检查来自转储文件的数据包:

输出每个数据包包含一行,以数据包ID编号开头,接着是时间戳(以秒为单位,微秒分辨率)、源和目标IP地址,以及其他协议细节。使用-r选项禁用了将IP地址解析为主机名。
对于性能调查,可以根据需要修改时间戳。默认情况下,它们是增量时间戳,显示数据包之间的时间。-ta选项打印绝对时间:挂钟时间。-tr选项打印相对时间:与第一个数据包的时间差。
-V选项打印半详细输出,包括每个协议栈层的一行:

小写的 -v 选项打印完整详细输出,通常为每个数据包产生一页的输出:

此示例仅包含了第一个数据包。snoop(1M)已经编程实现了解析多种协议的功能,可以快速进行命令行调查以处理各种网络流量。
还可以提供表达式来描述如何过滤数据包(请参阅snoop(1M)的man页面),以便专注于感兴趣的数据包。尽可能地,过滤是在内核中执行以提高效率。
请注意,默认情况下,snoop(1M)捕获整个数据包,包括所有有效负载数据。可以使用-s选项设置截取长度来在捕获时截断。许多版本的tcpdump(8)默认会截断。
10.6.12 Wireshark
虽然tcpdump(8)和snoop(1M)在日常调查中表现良好,但对于深入分析来说,在命令行中使用它们可能会耗费大量时间。Wireshark工具(以前称为Ethereal)提供了一个图形界面,用于数据包捕获和检查,并且还可以从tcpdump(8)或snoop(1M)导入数据包转储文件。其有用的功能包括识别网络连接及其相关数据包,以便可以分开研究,还可以翻译数百种协议头。
10.6.13 DTrace
DTrace可以用于检查内核和应用程序中的网络事件,包括套接字连接、套接字I/O、TCP事件、数据包传输、积压丢弃、TCP重传以及其他细节。这些功能支持工作负载特征化和延迟分析。
以下部分介绍了用于网络分析的DTrace,演示了适用于Linux和Solaris系统的功能。其中许多示例来自基于Solaris系统,也包括一些来自Linux。在第4章“可观测性工具”中包含了DTrace入门。
用于跟踪网络栈的DTrace提供程序包括表10.6中列出的那些。

最好使用稳定的提供程序,但它们可能尚未在您的操作系统和DTrace版本中可用。如果没有,可以使用不稳定的接口提供程序,尽管脚本需要更新以匹配软件更改。
套接字连接
套接字活动可以通过执行网络操作的应用程序函数、系统套接字库、系统调用层或内核进行跟踪。系统调用层通常是首选,因为它有良好的文档、低开销(基于内核)且适用于整个系统。通过connect()计算出站连接的数量:

这个一行命令用于统计connect()系统调用的次数。在这种情况下,调用connect()最多的是名为haproxy的进程,它调用了22次connect()。如果需要,输出中可以包括其他详细信息,包括PID、进程参数和connect()参数。
通过accept()计算入站连接的数量:

在这种情况下,名为node的进程接受了最多的连接,总共有24个。
在套接字事件期间,可以检查内核和用户级堆栈,以显示执行它们的原因,作为工作负载特征化的一部分。例如,以下跟踪连接()用户级堆栈的进程名为ssh:


这些系统调用的参数也可以被检查。这需要DTrace比平常更多的工作,因为有趣的信息位于一个结构体中,必须从用户空间复制到内核空间,然后进行解引用。这由soconnect.d脚本执行(来自[Gregg 11])。


以下是示例输出:

这跟踪connect()系统调用,并打印一行输出来总结它们。系统调用的延迟包括在内,并且系统调用返回的错误代码(errno)被转换为字符串。错误代码通常是“进行中”,这发生在非阻塞连接()中。
除了connect()和accept()之外,还可以跟踪socket()和close()系统调用。这允许在创建时查看文件描述符(FD),并通过时间差来测量套接字的持续时间。
套接字I/O
在建立套接字之后,可以基于文件描述符在系统调用层跟踪后续的读取和写入事件。这可以通过以下两种方式之一来执行:
关联数组的套接字FD:这涉及跟踪syscall::socket:return并构建一个关联数组,例如,is_socket[pid,arg1] = 1;。在谓词中可以检查数组以识别将来的I/O系统调用中的哪些FD是套接字。记得在syscall::close:entry上清除值。
如果在您的DTrace版本中可用,则使用fds[].fi_fs的状态。这是文件系统类型的文本字符串描述。由于套接字映射到VFS,它们的I/O与虚拟套接字文件系统关联。
以下一行命令使用了后一种方法。
通过execname计算通过read()或recv()读取的套接字数:

这个输出显示,在跟踪过程中,名为 node 的进程使用这些系统调用中的任何一个从套接字读取了 1,218 次。
通过 execname 计算通过 write() 或 send() 写入套接字的次数,是以下一行命令:

请注意,您的操作系统可能会使用这些系统调用的变体(例如,readv()),这些变体也应该被跟踪。
I/O 的大小也可以通过跟踪每个系统调用的返回探测来检查。
套接字延迟
鉴于可以在系统调用层跟踪套接字事件,以下测量可以作为延迟分析的一部分进行:
连接延迟:对于同步系统调用,连接(connect())的时间。对于非阻塞 I/O,从发出 connect() 到 poll() 或 select() (或其他系统调用) 报告套接字准备就绪的时间。
首字节延迟:从发出 connect() 或 accept() 返回的时间,到通过该套接字的任何 I/O 系统调用接收到第一个数据字节的时间。
套接字持续时间:从相同文件描述符的 socket() 到 close() 的时间。为了更专注于连接持续时间,可以从 connect() 或 accept() 计时。
这些可以作为长一行命令或脚本来执行。它们也可以从其他网络堆栈层次执行,包括 TCP。
套接字内部
可以使用 fbt 提供程序跟踪套接字的内部内核。例如,在 Linux 上,列出以 sock_ 开头的函数:

输出已被截断——它列出了超过 100 个探测点。可以单独跟踪每一个探测点,以及其参数和时间戳,以回答关于套接字行为的任意问题。
TCP 事件
与套接字类似,可以使用 fbt 提供程序跟踪 TCP 的内部内核。但是,已经开发了一个稳定的 tcp 提供程序(最初由我开发),并且可能已经在您的系统上可用。这些探测点如表 10.7 所示。


其中大多数提供了显示协议头详细信息和内部内核状态的参数,包括“缓存”的进程ID。通常使用 DTrace 内置的 execname 跟踪的进程名称可能无效,因为内核 TCP 事件可能会异步发生于进程。频率统计接受的 TCP 连接(被动)与远程 IP 地址和本地端口:

在跟踪过程中,主机 10.2.204.30 连接到 TCP 本地端口 636 五次。类似的延迟可以使用 TCP 探针进行跟踪,如前面套接字延迟部分所述,使用 TCP 探针的组合。
列出 TCP 探针:

MODULE 和 FUNCTION 字段显示了探测点在内核代码中的(不稳定)位置,可以使用 fbt 提供程序跟踪以获取更多详细信息。
数据包传输
要研究 TCP 提供程序以外的内核内部情况,以及当 TCP 提供程序不可用时,可以使用 fbt 提供程序。这是动态跟踪使某些事情成为可能的情况之一——这比不可能要好,但不一定容易!网络堆栈的内部结构很复杂,初学者可能需要花费多天的时间来熟悉代码路径。
浏览堆栈的快速方法是跟踪一个深度事件,然后检查其堆栈回溯。例如,在 Linux 上,跟踪 ip_output() 并使用堆栈:

每行标识了一个可以单独跟踪的内核函数。这需要检查源代码以确定每个函数及其参数的作用。
例如,考虑到 tcp_sendmsg() 的第四个参数是以字节为单位的大小,可以使用跟踪它:


这个一行命令使用 quantize() 动作将 TCP 发送段的大小总结为二的幂分布图。大多数段的大小在 128 到 511 字节之间。
可以编写更长的一行命令和复杂的脚本,比如用于调查 TCP 重传和积压丢弃的脚本。
重传跟踪
研究 TCP 重传对于调查网络健康状态是一项有用的活动。虽然以往通常通过使用嗅探工具将所有数据包转储到文件中进行事后检查来执行此操作,但是 DTrace 可以实时检查重传,并且开销很低。以下脚本适用于 Linux 3.2.6 内核,跟踪 tcp_retransmit_skb() 函数并打印有用的细节:


这包括时间、目标 IP 地址和内核堆栈跟踪,有助于解释为什么发生了重传。为了获得更详细的信息,可以单独跟踪内核堆栈中的每个函数。
类似的脚本已经为 SmartOS 开发,作为云运营商工具包的一部分。其中包括 tcpretranssnoop.d,其输出如下:

这显示了 TCP 重传的目标 IP 地址(在此输出中已编辑),并包括内核 TCP 状态。
积压丢弃
这个最后的示例脚本也来自 SmartOS 的 TCP 脚本工具包,用于估算是否需要进行积压调优以及其是否有效。这是一个较长的脚本,提供为高级分析的示例。


该脚本同时使用不稳定的 fbt 提供程序获取 TCP 状态,并使用 mib 提供程序计算发生丢弃的次数。
以下是示例输出:

当按下 Ctrl-C 键时,将打印一个摘要,显示缓存的进程 ID(cpid)、套接字积压的当前最大长度(max_q),以及一个分布图,显示在添加新连接时测量的积压长度。输出显示,PID 11504 发生了 34 次积压丢弃,最大积压长度为 128。分布图显示,大部分时间积压长度为 0,只有一小部分将队列推到了最大值。这是增加队列长度的候选方案。
通常只有在发生丢弃时才调整这个积压队列,可以通过 netstat -s 命令的 tcpListenDrops 计数器看到这一点。这个 DTrace 脚本允许在丢弃成为问题之前预测丢弃并应用调整。以下是另一个示例输出:
在这种情况下,积压通常达到了其 128 的限制。这表明应用程序负载过重,没有足够的资源(通常是 CPU)来跟上。
更多追踪
在需要时,动态追踪可以以其他方式和更详细的方式探索网络。为了提供对其功能的一个概念,表10.8 显示了来自 DTrace 的《网络底层协议》章节(158 页)中的脚本[Gregg 11]。这些脚本也可以在线查阅 [7]。


DTrace 书中还有一个关于应用层协议的章节,提供了许多用于跟踪 NFS、CIFS、HTTP、DNS、FTP、iSCSI、FC、SSH、NIS 和 LDAP 的更多脚本。尽管这种可观测性的程度令人难以置信,但其中一些动态跟踪脚本与特定的内核内部绑定在一起,需要进行维护以适应较新内核版本中的更改。另一些基于特定的 DTrace 提供程序,这些提供程序可能尚未在您的操作系统上可用。
10.6.14 SystemTap
SystemTap 也可以在 Linux 系统上用于动态跟踪文件系统事件。有关将先前的 DTrace 脚本转换的帮助,请参阅第 4 章“可观测性工具”的第 4.4 节“SystemTap”,以及附录 E。
10.6.15 perf
在第6章“CPU”中介绍的LPE工具集也可以提供一些网络事件的静态和动态跟踪。它可以用于识别在内核中导致网络活动的堆栈跟踪,就像以前使用DTrace进行数据包传输和重传跟踪一样。更高级的工具也可以使用后处理来开发。
例如,以下示例使用perf(1)为tcp_sendmsg()内核函数创建一个动态跟踪点,然后在5秒内跟踪它以及调用图(堆栈跟踪):

输出显示了导致内核调用tcp_sendmsg()发送数据的sshd的堆栈跟踪,以便通过TCP连接发送数据。
还有一些预定义的用于网络的跟踪点事件:

skb跟踪点用于套接字缓冲区事件,net用于网络设备。
这些也可以用于网络调查。
10.6.16 Other Tools
其他 Linux 网络性能工具包括:
- strace(1):用于跟踪与套接字相关的系统调用并检查所使用的选项(注意,strace(1)的开销较大)。
- lsof(8):按进程ID列出打开的文件,包括套接字详细信息。
- ss(8):套接字统计信息。
- nfsstat(8):NFS 服务器和客户端统计信息。
- iftop(8):按主机汇总网络接口吞吐量(嗅探器)。
- /proc/net:包含许多网络统计文件。
对于 Solaris:
- truss(1):用于跟踪与套接字相关的系统调用并检查所使用的选项(注意,truss(1)的开销较大)。
- pfiles(1):用于检查进程正在使用的套接字,包括选项和套接字缓冲区大小。
- routeadm(1M):用于检查路由和 IP 转发的状态。
- nfsstat(1M):NFS 服务器和客户端统计信息。
- kstat:提供来自网络堆栈和网络设备驱动程序的更多统计信息(其中许多在源代码之外未记录)。
还有许多网络监控解决方案,要么基于 SNMP,要么运行其自己的定制代理。
10.7 Experimentation
除了ping(8)、traceroute(8)和之前介绍过的pathchar之外,用于网络性能分析的其他实验性工具包括微基准测试。这些工具可以用于确定主机之间的最大吞吐量,有助于在调试应用程序性能问题时确定端到端网络吞吐量是否存在问题。
可以选择许多网络微基准测试工具。本节演示了流行且易于使用的iperf。另一个值得一提的是netperf,它也可以测试请求/响应性能。
10.7.1 iperf
iperf是一个用于测试最大TCP和UDP吞吐量的开源工具。它支持各种选项,包括并行模式:可以使用多个客户端线程,这可能对将网络推向极限是必要的。iperf必须在服务器和客户端上都执行。
例如,在服务器上执行iperf:

这将套接字缓冲区大小增加到128 KB(-l 128k),默认值为8 KB。
在客户端上执行以下操作:

这使用了以下选项:
-c host:连接到主机名或IP地址
-l 128k:使用128 KB套接字缓冲区
-P 2:以两个客户端线程并行模式运行
-i 1:每秒打印间隔摘要
-t 60:测试的总持续时间:60秒
最后一行显示了测试期间的平均吞吐量,总和计算了所有并行线程:244 Mbits/s。
可以检查每个间隔摘要以查看随时间的变化。--reportstyle C选项可用于输出CSV格式,以便其他工具(如绘图软件)导入数据。
10.8 Tuning
网络可调参数通常已经调优,以提供高性能。网络栈通常也设计成能够动态响应不同的工作负载,从而提供最佳性能。
在尝试调整可调参数之前,首先了解网络使用情况是值得的。这可能还会识别出可以消除的不必要工作,从而带来更大的性能提升。尝试使用前一节中介绍的工具进行工作负载特性化和静态性能调优方法。
可用的可调参数在操作系统的不同版本之间会有所不同。请参阅它们的文档。接下来的各节提供了可能可用的内容以及它们如何进行调整的想法;它们应被视为根据您的工作负载和环境进行修订的起点。
10.8.1 Linux
可调参数可以使用sysctl(8)命令进行查看和设置,并写入/etc/sysctl.conf。它们也可以从/proc文件系统的/proc/sys/net目录下进行读取和写入。
例如,要查看当前TCP可用的参数,可以从sysctl(8)中搜索包含文本tcp的参数:


在这个内核(3.2.6-3)中,有63个包含tcp的参数,以及更多位于net目录下的参数,包括IP、以太网、路由和网络接口的参数。
具体调优的例子将在以下各节中进行介绍。
套接字和TCP缓冲区
所有协议类型的最大套接字缓冲区大小,包括读取(rmem_max)和写入(wmem_max),可以通过以下方式进行设置:

该值以字节为单位。为了支持全速的10 GbE连接,可能需要将其设置为16兆字节或更高。
启用TCP接收缓冲区的自动调优:
![]()
设置TCP读取和写入缓冲区的自动调优参数:

每个参数都有三个值:使用的字节数的最小值、默认值和最大值。使用的大小是根据默认值自动调整的。为了提高TCP吞吐量,尝试增加最大值。增加最小值和默认值将会消耗更多的内存每个连接,这可能是不必要的。
TCP队列
第一个队列是用于半开放连接的backlog队列:
![]()
第二个队列是用于传递连接到accept()的监听backlog队列:
![]()
这两个队列的大小可能需要从它们的默认值增加,例如,增加到4,096和1,024,或更高,以更好地处理负载突发情况。
设备队列
增加每个CPU的网络设备backlog队列的长度:
![]()
这可能需要增加,例如,对于10 GbE网卡,可以增加到10,000。
TCP拥塞控制
Linux支持可插拔的拥塞控制算法。列出当前可用的算法:

有些可能是可用的,但当前没有加载。例如,添加htcp算法:

当前的算法可以使用以下方式进行选择:
![]()
TCP选项
其他可以设置的TCP参数包括

SACK和FACK扩展,它们可以在高延迟网络上提高吞吐性能,但会增加一些CPU成本。
tcp_tw_reuse参数允许在看起来安全时重用TIME-WAIT会话。这可以允许两个主机之间的连接速率更高,例如在Web服务器和数据库之间,而不会因为TIME-WAIT状态的会话达到16位临时端口限制。
tcp_tw_recycle是另一种重用TIME-WAIT会话的方法,虽然不像tcp_tw_reuse那样安全。
网络接口
可以使用ifconfig(8)来增加TX队列长度,例如:
![]()
这对于10 GbE网卡可能是必要的。该设置可以添加到/etc/rc.local中,以便在启动时应用。
资源控制
容器组(cgroups)网络优先级(net_prio)子系统可用于为出站网络流量的进程或进程组应用优先级。
这可以用于优先处理高优先级的网络流量,例如生产负载,而不是低优先级的流量,例如备份或监控。配置的优先级值被转换为IP ToS级别(或使用相同位的更新方案)并包含在数据包中。
10.8.3 Configuration
除了可调参数之外,以下配置选项也可以用于调整网络性能:
以太网巨帧:将默认的MTU从1,500增加到约9,000可以提高网络吞吐量性能,如果网络基础设施支持巨帧。
链路聚合:多个网络接口可以组合在一起,以使它们作为一个单一的接口,并具有组合的带宽。这需要交换机的支持和配置才能正常工作。
套接字选项:应用程序可以使用setsockopt()来调整缓冲区大小,增加它(最多达到先前描述的系统限制)以提高吞吐量性能。这些对于两种操作系统类型都是通用的。
11 Cloud Computing
云计算的兴起解决了性能领域中的一些问题,同时也带来了其他问题。云通常建立在虚拟化技术之上,允许多个操作系统实例或租户共享一个物理服务器。这意味着可能存在资源争用:不仅来自其他进程,这在Unix中是常见的,而且还来自其他整个操作系统。隔离每个租户的性能影响至关重要,同样重要的是识别由其他租户引起的性能不佳。
本章讨论了云计算环境的性能,并分为三个部分:
背景介绍了一般云计算架构及其性能影响。
操作系统虚拟化是指由单个内核管理系统,创建相互隔离的虚拟操作系统实例。本节以SmartOS Zones为例进行了实现。
硬件虚拟化是指由一个虚拟机管理程序管理多个客户操作系统,每个操作系统都运行自己的内核,并具有虚拟化设备。本节以Xen和KVM为例进行了介绍。
示例技术用于讨论不同类型虚拟化的性能特性。关于它们的使用的完整文档以及其他虚拟化技术的使用,请参阅它们各自的在线文档。
不使用虚拟化的云环境(仅裸机系统)可以视为分布式系统,并使用前面章节描述的技术进行分析。对于虚拟化系统,本章补充了之前介绍的材料。
11.1 Background
云计算允许将计算资源作为服务交付,从服务器的小部分扩展到多服务器系统。根据安装和配置的软件堆栈量的不同,有各种类型的云计算。本章重点介绍最基本的类型:基础设施即服务(IaaS),它提供操作系统作为服务器实例。示例IaaS提供商包括亚马逊网络服务(AWS)、Rackspace和Joyent。
服务器实例通常是虚拟化系统,可以在几分钟内(或分钟的一部分)创建和销毁,并立即投入生产使用。通常提供云API,以便可以通过另一个程序自动进行这种配置。
总结云术语,云计算描述了一个动态配置框架,用于服务器实例。多个服务器实例作为物理主机系统的客户运行。这些客户也称为租户,术语“多租户”用于描述它们对邻居的影响。主机由云运营商管理。租户由购买它们的客户管理。
云计算对于许多性能主题具有影响:价格/性能比、架构、容量规划、存储和多租户。这些在以下各节中进行了总结。
11.1.1 Price/Performance Ratio
有许多公共云提供商销售云服务器实例,通常按小时计价,价格基于实例的内存(DRAM)大小,8 G字节实例的成本大约是1 G字节实例的八倍。其他资源,如CPU,按内存大小进行调整和定价。结果可能是一个具有一致价格/性能比的价格,一些折扣可以鼓励使用更大的系统。
一些提供商允许您支付额外费用以获得更大的CPU资源分配(“高CPU实例”)。其他资源使用情况也可能被货币化,例如网络吞吐量和存储。
11.1.2 Scalable Architecture
传统上,企业环境使用垂直可扩展性方法来处理负载:构建更大的单一系统(大型机)。这种方法有其局限性。计算机可以构建到的物理大小存在实际限制(可能受到电梯门或货柜的大小限制),随着CPU数量的增加,CPU缓存一致性的困难也在增加。解决这些限制的方法是在许多(也许是小型)系统之间分散负载,这称为水平可扩展性。在企业中,它已经被用于计算机农场和集群,特别是高性能计算(HPC)领域。
云计算也基于水平可扩展性。图11.1显示了一个示例环境,其中包括负载均衡器、Web服务器、应用服务器和数据库。

每个环境层由一个或多个并行运行的服务器实例组成,可以添加更多实例来处理负载。实例可以单独添加,或者架构可以划分为垂直分区,其中由数据库服务器、应用服务器和Web服务器组成的一组作为单个单元添加。
在并行执行中最难的层是数据库层,这是由于传统的数据库模型,其中一个数据库实例必须是主数据库。这些数据库的数据,例如MySQL,可以逻辑上分割成称为分片的组,每个分片由自己的数据库(或主/备份对)管理。更近期的数据库架构,例如Riak,可以动态处理并行执行,将负载分散到可用的实例上。
由于每个服务器实例的大小通常很小,例如,1 G字节(在具有128 G字节及更多DRAM的物理主机上),可以使用细粒度的缩放来实现最佳的价格/性能,而不是事先投资于可能大部分闲置的庞大系统。
11.1.3 Capacity Planning
在企业环境中,服务器可能是一个重要的基础设施成本,无论是硬件成本还是可能持续多年的服务合同费用。新服务器投入生产可能需要数月时间:审批、等待零件供应、运输、安装机架、安装和测试等过程都需要耗费时间。容量规划非常重要,这样可以购买适当大小的系统:容量太小会导致失败,容量太大则成本高昂(而且,对于服务合同而言,可能会成本高昂多年)。容量规划还可以帮助提前预测需求增长,以便及时完成冗长的采购程序。
云计算则大不相同。服务器实例价格低廉,几乎可以立即创建和销毁。公司可以根据实际负载需要增加服务器实例,而不是花费时间规划可能需要的内容。这也可以通过云API自动完成,根据性能监控软件的指标进行。小型企业或初创企业可以从一个小实例发展到数千个,而无需像在企业环境中一样进行详细的容量规划研究。
对于不断增长的初创企业,另一个要考虑的因素是代码变更的速度。网站通常每周或甚至每天更新生产代码。一个需要数周时间的容量规划研究,因为它是基于性能指标的快照,可能在完成时已经过时。这与运行商业软件的企业环境不同,后者可能每年只变更几次。
在云中进行容量规划的活动包括:
- 动态大小调整:自动添加和删除服务器实例
- 可扩展性测试:购买一个大型云环境,以便测试可扩展性与合成负载(这是一个基准测试活动)
在考虑时间限制的同时,还有潜力进行可伸缩性建模(类似于企业研究),以估计实际可伸缩性如何达不到理论水平。
动态调整大小
自动添加服务器实例可以解决对负载快速响应的需求,但也存在过度配置的风险,如图11.2所示。例如,DoS攻击可能会表现为负载增加,触发昂贵的服务器实例增加。应用程序更改可能导致性能回退,需要更多实例来处理相同的负载,这也存在类似的风险。监控是验证这些增加是否合理的重要手段。

一些云服务在负载下降时也可以缩减其规模。例如,2012年12月,Pinterest报告称通过在非工作时间自动关闭其云系统,将成本从每小时54美元降低到每小时20美元[1]。类似的即时节约也可能是性能调优的结果,其中减少了处理负载所需实例的数量。
一些云架构(参见第11.2节,操作系统虚拟化)可以在有空闲资源的情况下即时分配更多CPU资源,采用一种称为突发的策略。这可以不增加额外费用,并旨在通过在此期间提供缓冲区来帮助防止过度配置,以检查增加的负载是否真实且可能持续。如果是这样,可以提供更多实例,以便未来保证资源。
这些技术中的任何一种应该比企业环境要高效得多,特别是那些选择处理服务器寿命内预期峰值负载的固定大小的环境;这样的服务器可能大部分时间处于空闲状态。
11.1.4 Storage
一个云服务器实例通常具有一些本地存储,从本地磁盘提供临时文件。这种本地存储是易失性的,在服务器实例被销毁时会被销毁。对于持久性存储,通常会使用独立的服务,该服务以以下形式为实例提供存储:
- 文件存储:例如,通过NFS协议的文件
- 块存储:例如,通过iSCSI协议的块
- 对象存储:通过API提供,通常基于HTTP协议
这些存储都是网络附加的,网络基础设施和存储设备都与其他租户共享。因此,性能可能比使用本地磁盘要不可靠得多。这两种设置都在图11.3中示出。

通常通过使用内存缓存经常访问的数据来减轻网络存储访问的增加延迟。
一些存储服务允许在需要可靠性能时购买IOPS速率(例如,AWS EBS Provisioned IOPS卷)。
11.1.5 Multitenancy
Unix是一种多任务操作系统,旨在处理多个用户和进程访问相同资源的情况。由BSD、Solaris和Linux后续添加的功能提供了资源限制和控制,以更公平地共享这些资源,并提供了可观察性,以便在涉及资源争用的性能问题时进行识别和量化。
云计算不同之处在于整个操作系统实例共存于同一物理系统上。每个客户端都是其自己独立的操作系统:客户端无法观察到同一主机上其他客户端的用户和进程——这将是一种信息泄露——尽管它们共享相同的物理资源。由于资源是在租户之间共享的,性能问题可能是由于有噪声的邻居而引起的。例如,同一主机上的另一个客户端可能在您的高峰负载期间执行完整的数据库转储,从而干扰您的磁盘和网络I/O。更糟糕的是,邻居可能正在通过执行故意饱和资源的微基准测试来评估云提供商,以找到它们的极限。
针对这个问题有一些解决方案。多租户效应可以通过资源管理来控制:设置提供性能隔离(也称为资源隔离)的操作系统资源控制。这就是针对系统资源的每租户限制或优先级的设置:CPU、内存、磁盘或文件系统I/O以及网络吞吐量的使用。并非所有的云技术都提供了所有这些功能,尤其是磁盘I/O限制。ZFS I/O调节是专门为Joyent公有云开发的,用于解决有噪声的磁盘邻居问题。
除了限制资源使用外,能够观察多租户争用可以帮助云运营商调整限制,并更好地平衡可用主机上的租户。可观察性程度取决于虚拟化类型:操作系统虚拟化或硬件虚拟化。
11.2 OS Virtualization
操作系统虚拟化将操作系统分区为行为类似于独立客户端服务器的实例,并且可以独立于主机进行管理和重启。这些为云客户提供高性能的服务器实例,为云运营商提供高密度的服务器。操作系统虚拟化的客户端示例如图11.4所示,使用Solaris Zones的术语。

这个图中显示了全局区域;这指的是主机操作系统,它可以看到所有的客户区域(也称为非全局区域)。
这种方法起源于Unix的chroot(8)命令,该命令将一个进程隔离到Unix全局文件系统的子树中(改变顶级目录,“/”)。1998年,FreeBSD将其进一步发展为FreeBSD jails,提供作为其自己服务器的安全隔间。2005年,Solaris 10包括了一个名为Solaris Zones的版本,具有各种资源控制。通过OpenSolaris和后来的SmartOS,区域已经投入到Joyent公共云的生产中。最近,对Linux进行了操作系统虚拟化项目,包括lxc Linux容器和OpenVirtuozzo(OpenVZ)。OpenVZ由Parallels, Inc.支持,并需要一个修改过的Linux内核。
与硬件虚拟化技术的关键区别在于只运行一个内核。这具有以下优点:
- 对于客户端应用I/O几乎没有性能开销,因为客户端应用可以直接对主机内核执行系统调用。
- 分配给客户端的内存可以完全用于客户端应用程序——没有额外的内核税,无论是来自操作系统的hypervisor还是其他客户端内核。
- 有统一的文件系统缓存——主机和客户端不会进行双重缓存。
- 所有客户端进程都可以从主机进行观察,允许调试它们之间的交互(包括资源争用)的性能问题。
- CPU是真正的CPU;自适应互斥锁的假设仍然有效。
但也存在缺点:
- 任何内核恐慌都会影响所有客户端。
- 客户端无法运行不同的内核版本。
为了运行不同的内核版本和不同的操作系统,您需要硬件虚拟化(在第11.3节,硬件虚拟化中有介绍)。操作系统虚拟化可以在一定程度上满足这种需求,通过提供替代的系统调用接口。一个例子是Solaris lx Branded Zones,它在Solaris内核下提供了Linux系统调用接口和应用环境。
以下部分描述了操作系统虚拟化的具体内容:开销、资源控制和可观察性。这些内容基于一个经历了多年生产使用的公共云(也很可能是全球最大的操作系统虚拟化云):Joyent SmartOS 实现的 Zones。这些信息通常适用于所有操作系统虚拟化的实现,大部分差异在于资源控制的配置方式。例如,Linux lxc 容器可以使用 cgroups,用法类似于这里描述的用法。
11.2.1 Overhead
了解何时可以期望虚拟化引入性能开销,何时不可以,对于调查云性能问题至关重要。这种性能开销可以通过描述 CPU 执行开销、执行 I/O 的开销以及来自其他租户的影响来概括。
CPU
当线程在用户模式下运行时,CPU 执行开销为零。不需要同步仿真或模拟——线程直接在 CPU 上运行,直到它们被让出或被抢占。
虽然不经常调用——因此不受性能影响——从内核中列出系统状态等活动可能会产生一些额外的 CPU 开销,因为其他租户的统计信息被过滤。这包括通过状态工具(例如,prstat(1M)、top(1))读取 /proc,这些工具遍历所有进程条目,包括其他租户,但仅返回过滤后的列表。这项工作的内核代码,来自 pr_readdir_procdir(),如下所示:

这是在当前系统上进行的测量,发现每 1,000 个进程条目额外花费 40 微秒。对于不经常发生的活动,这个成本是可以忽略的。(如果成本更高,内核代码将被更改。)
I/O
I/O 开销为零,除非已配置了额外的功能。为了让虚拟化的基本功能正常工作,软件栈中不需要额外的层次。这在图 11.5 中有所体现,该图比较了 Unix 进程和 Zones 的 I/O 路径。

以下显示了两个内核堆栈跟踪(使用 DTrace 获取)以传输网络数据包为例,分别是主机(裸机)和一个客户端(虚拟机)的:

这两者是相同的。如果有额外的层次,通常会在堆栈中出现额外的帧。
对于文件系统访问,可以配置区域挂载在回环文件系统上,而回环文件系统本身则挂载在主机文件系统上。这种策略用于稀疏根区域模型:一种在区域之间共享只读文件(例如,/usr/bin)的方法。如果使用回环文件系统,会产生一小部分文件系统 I/O 的 CPU 开销。
其他租户
其他正在运行的租户的存在可能会对性能产生一些影响,这些影响与虚拟化技术无关:
- CPU 缓存的命中率可能较低,因为其他租户正在使用和逐出缓存条目。
- CPU 执行可能会被中断,因为其他租户设备(例如,网络 I/O)正在执行中断服务例程。
- 其他租户可能会争夺系统资源(例如,磁盘、网络接口),这些资源正在被其他租户使用。
最后一个因素由资源控制进行管理。尽管这些因素在传统的多用户环境中存在,但它们在云计算中更为普遍。
11.2.2 Resource Controls
虽然操作系统虚拟化基础设施管理邻居之间的安全性,但资源控制则管理性能。表11.1描述了资源控制的范围,并以 Joyent 公共云配置的 SmartOS Zones 作为示例。这些被分类为限制和优先级,由云运营商或软件按照每个客户的要求进行设置。
限制是资源消耗的上限值。优先级引导资源消耗,根据重要性值平衡邻居之间的使用情况。根据需要使用其中任何一个——对于某些资源,这意味着两者都使用。

CPU
由于 OS 虚拟化的客户端可以直接“看到”系统上的所有物理 CPU,因此有时可以允许其使用 100% 的 CPU 资源。对于大部分处于空闲状态的 CPU 的系统而言,这使得其他客户端可以利用该 CPU,特别是用于处理短暂的需求高峰。Joyent 将这种能力称为 bursting;它帮助云客户在不需要昂贵的过度配置的情况下应对短期的高需求。
CPU 上限
上限可以限制客户端的 CPU 使用,防止 bursting,并以总 CPU 百分比的形式表达。一些客户端更倾向于使用此功能,因为它提供了一种一致的性能预期,可以简化容量规划。
对于其他客户端,根据 Joyent 的默认设置,CPU 上限会自动增加到客户端预期份额的多倍(例如,增加到八倍)。这允许客户端在 CPU 资源可用时进行 bursting。如果客户端持续进行 bursting 几小时或几天(通过监控确定),则可以鼓励客户端升级客户端规模,以便可靠地分配已消耗的 CPU,而不是依赖 bursting。
当客户端不知道自己正在进行 bursting 并可能持续数周时,这可能会导致问题。在某个时刻,另一个需要大量 CPU 的租户到来,也利用了空闲的 CPU,给第一个租户留下的可用资源减少,这将导致性能下降,可能会让第一个租户感到不满。这种情况类似于连续一个月乘坐经济舱,但幸运地总是有整排座位给自己使用,然后你登上一趟满员的航班。
可以通过禁用 bursting 来控制期望,就像在空余座位上放置土豆袋一样,以确保没有乘客习惯于有额外的空间。您的客户可能更希望您通过告知他们正在进行 bursting,而不是禁用此功能来管理期望。
CPU份额
份额可以通过公平份额调度器(FSS)来合理分配 CPU 资源。份额可以任意分配,用于计算在给定时间内繁忙客户端将获得的 CPU 量,计算公式如下:
客户端 CPU = 所有 CPU × 客户端份额 / 系统上总的繁忙份额
考虑一个系统,有 100 份额分配给几个客户端。在某一时刻,只有客户端 A 和 B 需要 CPU 资源。客户端 A 有 10 份额,客户端 B 有 30 份额。因此,客户端 A 可以使用系统上总 CPU 资源的 25%:所有 CPU × 10 /(10 + 30)。
对于 Joyent,每个客户端被分配的份额数量等于其内存大小(以 MB 为单位,因此与支付的价格相关)。大小翻倍的系统成本是之前的两倍,因此获得两倍的 CPU 份额。这确保了 CPU 资源在需要它们并为其支付的人之间公平分配。
CPU 上限也用于限制 bursting,以防期望过高。
内存容量
有两种类型的内存资源,每种都有自己的资源控制策略:主内存(RSS)和虚拟内存(VM)。这些也使用资源控制设施,由 resource_controls(5) man 页面描述,提供了一组可调参数用于资源控制。
主内存
限制主内存比听起来更棘手——强加硬限制与期望相违背。一旦 Unix 系统使用的主内存超过可用量,它就会开始分页(参见第七章,内存)。
在 SmartOS 中,这种行为通过 per-zone 管理守护进程 zoneadmd 中的一个线程来复制到客户端。它根据其内存资源控制 zone.max-physical-memory 提前分页客户端。它还通过延迟限制页入,以允许页出进行追赶来维持目标内存大小。
这个功能之前是由资源限制守护进程 rcapd 执行的,它是所有区域的单个进程(在有许多区域时无法扩展)。
虚拟内存
虚拟内存的资源控制属性是 zone.max-swap,在分配(malloc())期间同步检查。对于 Joyent,这设置为主内存大小的两倍。一旦达到限制,分配将失败(“内存不足”错误)。
文件系统I/O
为了解决来自吵闹邻居的磁盘I/O问题,在ZFS中通过一项名为I/O限制的功能来控制I/O,该功能由Joyent的Bill Pijewski开发。这类似于针对CPU的FSS,它为区域分配份额,更公平地在租户之间平衡I/O资源。
它的工作原理是按比例限制正在执行最多磁盘I/O的租户,以减少他们与其他租户的竞争。实际的限制机制是在I/O完成之前向用户空间注入延迟。在这个时间点,线程通常已经阻塞等待I/O完成,额外延迟的注入会导致稍微较慢的I/O。
文件系统容量
本地文件系统有一个硬容量限制:由映射存储设备提供的总可用空间。通常希望将此容量划分给系统上的客户端,可以通过以下方式实现:
有限大小的虚拟卷
支持配额的文件系统(例如ZFS)
网络文件系统和存储也可以为文件系统容量提供限制,对于云服务提供商来说,这通常与定价挂钩。
磁盘I/O
当前的SmartOS区域通过对文件系统的访问来控制磁盘I/O。请参阅前文的文件系统I/O部分。
网络I/O
由于每个区域都配置有自己的虚拟网络接口,因此可以使用dladm(1M)中的maxbw(最大带宽)链路属性来限制吞吐量。通过flowadm(1M)可以更精细地控制网络I/O,它可以设置maxbw和优先级值,并且可以根据传输类型和端口匹配流量。Joyent目前不限制网络I/O(所有基础设施均为10 GbE,并且通常有大量带宽可用),因此只在网络中存在滥用者时手动设置这些资源控制。
11.2.3 Observability
使用操作系统虚拟化技术,默认情况下允许每个人都可以看到一切;必须施加限制以防止意外的安全泄漏。这些限制至少包括:
作为客户端,/proc仅显示客户端中的进程。
作为客户端,netstat仅列出客户端拥有的会话信息。
作为客户端,文件系统工具仅显示客户端拥有的文件系统。
作为客户端,无法通过区域管理工具列出其他区域。
作为客户端,无法检查内核内部(没有DTrace fbt提供者或mdb -k)。
主机操作员可以查看一切:主机操作系统和所有客户端中的进程、TCP会话和文件系统。而从主机上,可以直接观察客户端活动 —— 而无需登录到每个客户端。
以下部分演示了主机和客户端可用的可观测工具,并描述了分析性能的策略。SmartOS及其可观测工具用于展示操作系统虚拟化应该提供的信息类型。
主机
当登录到主机时,可以使用前几章介绍的工具检查所有系统资源(CPU、内存、文件系统、磁盘、网络)。在使用区域时,有两个额外因素需要考虑:
每个区域的统计信息
资源控制的影响
检查每个区域的统计信息有时会提供一个-Z选项。例如:

第一列显示区域名称(被截断以适应)。
prstat(1M)命令也支持-Z选项:


顶部部分(被截断)通常显示一个进程列表,最消耗CPU的进程在顶部。底部部分是每个区域的摘要,显示以下信息:
SWAP:区域虚拟内存大小总计
RSS:区域驻留集大小总计(主内存使用量)
MEMORY:主内存消耗,作为系统范围资源的百分比
CPU:CPU消耗,作为系统范围资源的百分比
ZONE:区域名称
这是一个用于云计算的系统(称为计算节点),托管了超过十几个动态创建的区域。每个区域都有一个自动生成的UUID作为其区域名称(如b8b2464c……)。
zonememstat(1M)工具显示每个区域的内存使用情况:

这包括:
CAP(MB):配置的资源控制限制
NOVER:区域超出限制的次数
POUT(MB):已分页出的数据总量,用于保持区域处于其限制之内
POUT(MB)中的值增加通常表明客户端的应用程序配置错误,尝试使用超出客户端可用内存的内存量,因此应用程序正在被rcapd或zoneadmd分页出去。
其他资源控制(CPU、ZFS I/O限制和网络限制)的信息可以从kstat(1M)和prctl(1)中获取。
如果需要,还可以从主机执行进一步的分析,包括检查客户端应用程序的调用堆栈和内部。主机管理员可以识别任何性能问题的根本原因,而无需登录客户端。
客户端
客户端应仅看到其进程和活动的特定详细信息。经过修改以实现此功能的可观察性工具被称为“区域感知”。/proc文件系统,如ps(1)和prstat(1M)所使用的,仅包含该区域的进程,使这些工具成为区域感知的工具。
只要不泄漏私有细节,客户端可以观察共享系统资源。例如,客户端可以直接观察所有物理CPU和磁盘(mpstat(1M)、iostat(1M)),以及系统范围的内存使用情况(vmstat(1M))。
例如,在查看空闲区域的磁盘I/O时:

对于刚接触操作系统虚拟化的人来说,这可能有些令人困惑——为什么磁盘忙碌?这是因为iostat(1)显示的是物理磁盘,包括其他租户的活动。此类命令称为系统范围命令(即不是区域感知的)。
要仅检查此区域引起的磁盘使用情况,可以检查来自VFS级别的统计信息:

这证实了该区域(几乎)处于空闲状态——每秒读取4.5K字节(这可能是由文件系统缓存,不引起任何磁盘I/O)。
mpstat(1M)也是系统范围的:

它显示所有物理CPU,包括其他租户的活动。
prstat -Z 摘要是显示客户端 CPU 使用情况的一种方法(当从非全局区域运行时,其他客户端不会列出):

还有来自 kstat 的计数器,显示 CPU 使用情况以及限制。
最终,这种物理资源的可观察性为客户端提供了有用的性能分析统计信息,这些信息可能有助于排除某些类型的问题(包括嘈杂的邻居)。这与硬件虚拟化有着重要的区别,后者将物理资源隐藏在客户端中。
策略
前几章介绍了针对物理系统资源的分析技术,包括各种方法论。这些可以供主机操作员遵循,而在一定程度上也适用于客户端,但要记住之前提到的限制。对于客户端来说,通常可以观察到高级资源使用情况,但无法深入到内核中。
除了物理资源外,资源控制所施加的云限制也应由主机操作员和客户端租户检查。由于这些限制在物理限制之前就出现了,因此更有可能生效,可以首先进行检查。
由于许多传统的可观测性工具是在资源控制出现之前创建的(例如,top(1) 和 prstat(1M)),它们默认不包含资源控制信息,用户可能会忘记用其他包含这些信息的工具来检查它们。下面是检查每种资源控制的一些评论和策略:
CPU:对于容量,可以将当前 CPU 使用情况与容量值进行比较。遇到容量时,线程在可运行状态时会等待,这可以观察到作业调度的延迟。一开始可能会感到困惑,因为物理系统可能有大量空闲 CPU。
内存:对于主内存,检查当前使用量是否超过限制。一旦达到限制,将从 zoneadmd 进行页面出。这可能会被注意到为匿名页面和线程在数据错误中花费的时间。一开始也可能会感到困惑,因为系统页面调度器可能没有激活(vmstat 中看不到 sr),而物理系统可能有大量空闲内存。
文件系统 I/O:高 I/O 率可能会被限制,导致平均延迟略微增加。可以通过使用 vfsstat(1M) 工具观察到这一点。
文件系统容量:这应该与任何其他文件系统一样可观察(包括使用 df(1M))。
磁盘 I/O:参见文件系统 I/O。
网络 I/O:检查当前网络吞吐量是否超过带宽限制,如果已配置。遇到限制会导致网络 I/O 延迟增加,因为租户会被限制到其容量。
对于 SmartOS Zones,已开发了一种 USE 方法清单,首先分析资源控制,然后是物理资源。
监控软件
应该注意的是,许多为独立系统编写的监控工具尚未开发支持操作系统虚拟化。试图在客户端中使用这些工具的客户可能会发现,它们似乎可以工作,但实际上显示的是物理系统资源,基于这些工具一直以来所基于的相同计数器。在没有支持观察云资源控制的情况下,这些工具可能会错误地报告系统有余地,而实际上它们已经达到了资源限制。它们也可能显示高资源使用率,实际上是由于其他租户所致。
11.3 Hardware Virtualization
硬件虚拟化创建系统虚拟机实例,可以运行完整的操作系统,包括它们的内核。硬件虚拟化的类型包括以下几种:
全虚拟化 - 二进制翻译:提供一个完整的虚拟系统,由虚拟化的硬件组件组成,可以安装未修改的操作系统。VMware 在 1998 年为 x86 平台率先实现了这一技术,它在需要时使用直接处理器执行和二进制指令翻译的混合方式。通常情况下,由于服务器整合带来的节省,性能开销是可以接受的。
全虚拟化 - 硬件辅助:提供一个完整的虚拟系统,由虚拟化的硬件组件组成,可以安装未修改的操作系统。这使用处理器支持更有效地执行虚拟机,特别是在 2005-2006 年引入的 AMD-V 和 Intel VT-x 扩展。
半虚拟化:提供一个虚拟系统,其中包含一个接口,供客户操作系统通过超级调用有效地使用主机资源,而无需对所有组件进行全虚拟化。例如,启用定时器通常涉及多个特权指令,必须由超级调用器模拟。这可以简化为半虚拟化客户机的单个超级调用。半虚拟化可能包括客户操作系统使用半虚拟化网络设备驱动程序,以更有效地将数据包传递给主机中的物理网络接口。虽然性能有所提高,但这取决于客户操作系统对半虚拟化的支持(历史上 Windows 并未提供)。
另一种类型,混合虚拟化,当某些情况下半虚拟化调用更有效时,同时使用硬件辅助虚拟化,旨在提供最佳性能。半虚拟化最常见的目标是虚拟设备,例如网络卡和存储控制器。
虚拟机由 hypervisor 创建和执行,hypervisor 可以是软件、固件或硬件实现。
硬件虚拟化的客户机如图 11.6 所示。

这显示了两种类型的hypervisors [Goldberg 73]:
Type 1 直接在处理器上执行,而不是作为另一主机的内核级或用户级软件。Hypervisor管理可以由特权客户(在此系统中表示为第一个:编号为0)执行,该客户可以创建和启动新的客户机。Type 1 也被称为本地hypervisor或裸金属hypervisor。这个hypervisor包含了自己的CPU调度器用于客户机VMs。
Type 2 由主机操作系统内核执行,可能由内核级模块和用户级进程组成。主机操作系统具有管理hypervisor和启动新客户机的权限。这个hypervisor由主机内核调度器调度。
硬件虚拟化有许多不同的实现。关键示例包括:
VMware ESX:首次发布于2001年,VMware ESX是用于服务器整合的企业产品,并且是VMware vSphere云计算产品的关键组件。其hypervisor是在裸金属上运行的微内核,第一个虚拟机被称为服务控制台,可以管理hypervisor和新的虚拟机。
Xen:于2003年首次发布,Xen起源于剑桥大学的一个研究项目,后来被Citrix收购。Xen是一种类型1的hypervisor,为了高性能而运行paravirtualized客户机;后来增加了对硬件辅助客户机的支持,以支持未修改的操作系统(Windows)。虚拟机被称为域,最高权限的是dom0,从中管理hypervisor并启动新域。Xen是开源的,可以从Linux启动。(曾经存在适用于Solaris的版本;但是,Oracle现在更倾向于Oracle VM Server。)亚马逊弹性计算云(EC2)和Rackspace Cloud基于Xen。
KVM:由Qumranet开发,2008年被Red Hat收购。KVM是一种类型2的hypervisor,作为内核模块执行。它支持硬件辅助扩展,并且为某些设备(在客户操作系统支持的情况下)使用para虚拟化以获得高性能。为了创建完整的硬件辅助虚拟机实例,它与一个名为QEMU(Quick Emulator)的用户进程配对。QEMU最初是由Fabrice Bellard编写的高质量开源类型2的hypervisor,通过二进制翻译。KVM是开源的,并已移植到illumos和FreeBSD。Joyent公共云的Linux和Windows实例使用KVM(SmartOS实例使用OS虚拟化)。Google还使用KVM驱动Google计算引擎。
以下各节描述了硬件虚拟化的主题:开销、资源控制和可观测性。这些因实现方式而异,而不仅限于先前列出的三种。请查看您的实现以了解具体情况。
11.3.1 Overhead
硬件虚拟化是由hypervisor以各种方式实现的。这些硬件虚拟化技术在客户操作系统尝试访问硬件时会增加开销:命令必须从虚拟设备转换为物理设备。在研究性能时必须理解这些转换;它们可能因硬件虚拟化的类型和实现方式而异。这些差异可以通过描述CPU执行、内存映射、执行I/O以及其他租户的影响来概括。
CPU
总的来说,客户应用程序直接在处理器上执行,CPU密集型应用程序接近裸金属系统的性能。在进行特权处理器调用、访问硬件和映射主内存时可能会遇到开销。
以下是不同的硬件虚拟化类型:
二进制翻译:识别并翻译在物理资源上运行的客户内核指令。在硬件辅助虚拟化出现之前,使用了二进制翻译。在没有硬件虚拟化支持的情况下,VMware采用的方案涉及在处理器ring 0中运行虚拟机监视器(VMM),并将客户内核移动到以前未使用的ring 1中(应用程序在ring 3中运行,大多数处理器提供四个ring)。由于一些客户内核指令假设它们在ring 0中运行,因此为了从ring 1中执行,它们需要被翻译,调用VMM以应用虚拟化。这种翻译是在运行时执行的。
Para虚拟化:在客户操作系统中必须虚拟化的指令被替换为对hypervisor的超级调用。如果客户操作系统被修改以优化超级调用,使其意识到自己正在虚拟化的硬件上运行,性能可以得到提升。
硬件辅助:在硬件上运行的未修改的客户内核指令由hypervisor处理,后者在低于ring 0的ring级别运行VMM。与翻译二进制指令不同,客户内核特权指令被强制转移到更高特权的VMM,后者可以模拟特权以支持虚拟化。硬件辅助虚拟化通常是首选的,取决于实现和工作负载,而Para虚拟化用于提高某些工作负载的性能(特别是I/O),如果客户操作系统支持的话。
作为实现差异的示例,VMware的二进制翻译模型经过多年的优化,正如他们在2007年所写的那样:
由于高的hypervisor到客户机转换开销和严格的编程模型,VMware的二进制翻译方法目前在大多数情况下优于第一代硬件辅助实现。第一代实现中的严格编程模型几乎没有余地来灵活管理hypervisor到客户机转换的频率或成本。
可以将客户和hypervisor之间的转换率以及在hypervisor中花费的时间作为CPU开销的度量进行研究。这些事件通常被称为客户退出,因为虚拟CPU在发生这种情况时必须停止在客户内部执行。图11.7显示了与在KVM中的客户退出相关的CPU开销。

该图显示了客户退出在用户进程、主机内核和客户之间的流动。在处理退出时花费在客户之外的时间是硬件虚拟化的CPU开销;处理退出所花费的时间越多,开销就越大。当客户退出时,一部分事件可以直接在内核中处理。那些无法处理的事件必须离开内核并返回到用户进程;这与内核可以处理的退出相比,会引发更大的开销。
例如,在Joyent使用的KVM实现中,这些开销可以通过其客户退出进行研究,这些退出在源代码中映射到以下函数(来自kvm_vmx.c):

虽然这些名称简洁,但它们可能提供了客户调用到hypervisor的原因,从而产生CPU开销的想法。
一个常见的客户退出是halt指令,通常由空闲线程调用,当内核找不到更多工作要执行时(这允许处理器在被中断之前以低功耗模式运行)。它由handle_halt()(kvm_vmx.c)处理,这里包含了相关代码的概念:

该代码调用kvm_emulate_halt() (kvm_x86.c):

与许多客户退出类型一样,代码保持简洁以最小化CPU开销。
这个示例从KVM_VCPU_KSTAT_INC()宏开始,该宏设置了一个kstat计数器,以便观察halt的频率。(这是从Linux版本移植过来的,该版本设置了一个内置计数器用于相同的目的。)剩余的代码执行了这个特权指令所需的硬件仿真。这些函数可以在hypervisor上使用DTrace进行研究,以跟踪它们的类型和退出的持续时间。
虚拟化硬件设备,如中断控制器和高分辨率定时器,也会产生一些CPU(和少量DRAM)开销。
Memory Mapping
如第7章内存所述,操作系统与MMU合作,从虚拟内存到物理内存创建页面映射,并将其缓存在TLB中以提高性能。对于虚拟化,将来自客户机到硬件的新内存页面映射(页面错误)涉及两个步骤:
1. 由客户机内核执行的虚拟到客户机物理的转换
2. 由hypervisor VMM执行的客户机物理到主机物理(实际)转换
然后,从客户机虚拟到主机物理的映射可以被缓存到TLB中,这样后续访问就可以以正常速度运行,而不需要额外的转换。现代处理器支持MMU虚拟化,以便已经离开TLB的映射可以在硬件中更快地被回收(页面漫游),而无需调用到hypervisor。支持这一功能的特性称为Intel上的扩展页表(EPT)和AMD上的嵌套页表(NPT)[9]。
如果没有EPT/NPT,提高性能的另一种方法是维护客户机虚拟到主机物理映射的影子页表,由hypervisor管理,然后在客户执行期间通过覆盖guest的CR3寄存器进行访问。采用这种策略,客户机内核维护其自己的页表,将其从客户机虚拟到客户机物理进行映射,就像正常情况下一样。hypervisor拦截对这些页表的更改,并在影子页中创建等效的映射到主机物理页面。然后,在客户执行期间,hypervisor将CR3寄存器重写为指向影子页。
内存大小
与操作系统虚拟化不同,使用硬件虚拟化时会有一些额外的内存消耗者。每个客户机运行自己的内核,消耗了一小部分内存。存储架构也可能导致双重缓存,即客户机和主机都缓存相同的数据。
I/O
虚拟化的一个关键成本是执行设备I/O的开销。与CPU和内存I/O不同,其中可以设置共同路径以以裸金属方式执行,每个设备I/O必须由hypervisor进行转换。对于高频率的I/O,例如10 Gbit/s的网络,每个I/O(数据包)的一小部分开销可能会导致性能的显著总体降低。
使用para虚拟化可以在一定程度上缓解I/O开销,其中客户机内核驱动程序已经修改以在虚拟化环境中有效运行,合并I/O并执行更少的设备中断以减少hypervisor的开销。
另一种技术是PCI直通,它直接将PCI设备分配给客户机,因此可以像在裸金属系统上一样使用。PCI直通可以提供可用选项中的最佳性能,但在配置具有多个租户的系统时会降低灵活性,因为某些设备现在由客户机拥有并且不能共享。这也可能使在线迁移复杂化。
有一些技术可以提高使用虚拟化的PCI设备的灵活性,包括单根I/O虚拟化(SR-IOV)和多根I/O虚拟化(MR-IOV)。这些术语指的是暴露的根复杂PCI拓扑的数量,以不同的方式提供硬件虚拟化。它们的使用取决于硬件和hypervisor的支持。
作为设备I/O的示例,Xen(类型1 hypervisor)和KVM(类型2 hypervisor)如图11.8所示。

GK是“guest kernel”,在Xen上的domU运行客户机操作系统。其中一些箭头表示控制路径,其中组件彼此通知更多数据已准备好传输,可以同步或异步地进行。数据路径在某些情况下可以通过共享内存和环形缓冲区实现。这些技术有各种变化。在此图中,两者都使用I/O代理进程(通常为QEMU软件),为每个客户机VM创建。
I/O路径中的步骤数,无论是控制还是数据,对性能至关重要:步骤越少越好。2006年,KVM开发人员将特权客户系统(如Xen)与KVM进行了比较,并发现KVM可以使用更少的步骤进行I/O(五个步骤对比十个步骤,尽管该测试是在没有para虚拟化的情况下进行的,因此不反映大多数现代配置)。
Xen通过设备通道提高其I/O性能——这是dom0和客户域(domU)之间的异步共享内存传输。这避免了在dom之间传递I/O数据时执行额外拷贝的CPU和总线开销。它还可以使用单独的dom来执行I/O,如第11.3.2节“资源控制”所述。
在任一情况下,可以使用para虚拟化的客户机驱动程序来改善I/O性能,该驱动程序可以为虚拟化的I/O路径应用最佳缓冲和I/O合并。
其他租户
与操作系统虚拟化类似,存在其他租户可能会导致CPU缓存变得不够热,当其他租户被调度和服务时,可能会发生客户机运行时的中断,包括设备中断。资源争用可以通过资源控制来管理。
11.3.2 Resource Controls
作为客户机配置的一部分,CPU和主内存通常会配置资源限制。Hypervisor软件也可能提供网络和磁盘I/O的资源控制。
对于类型2的Hypervisor,主机操作系统最终控制物理资源,并且除了Hypervisor提供的控制外,还可以应用来自操作系统的资源控制(如果有的话)到客户机上。
例如,Joyent配置KVM客户机在SmartOS Zones内运行,允许应用第11.2节“操作系统虚拟化”中列出的资源控制,包括ZFS I/O限制。这是KVM限制的补充,为控制资源使用提供了更多的选项和灵活性。它还将每个KVM实例封装在自己的高度安全的区域中,提供多重边界的安全保护,这种技术被称为双层虚拟化。
可用的选项取决于Hypervisor软件、类型以及对于类型2的Hypervisor,主机操作系统。请参阅第11.2节“操作系统虚拟化”,了解主机操作系统可能提供的资源控制类型。下面的部分将以Xen和KVM Hypervisor为例,描述资源控制。
CPU
CPU资源通常被分配给客户机作为虚拟CPU(vCPU)。然后由Hypervisor进行调度。分配的vCPU数量粗略地限制了CPU资源的使用。
对于Xen,可以通过Hypervisor的CPU调度器应用细粒度的客户机CPU配额。调度器包括([Cherkasova 07],[Matthews 08])
- 借用虚拟时间(BVT):基于虚拟时间分配的公平共享调度器,可以提前借用虚拟时间,以提供低延迟的实时和交互式应用程序执行
- 简单最早截止期优先(SEDF):实时调度器,允许配置运行时保证,调度器优先考虑最早的截止期
- 基于信用的:支持CPU使用的优先级(权重)和上限,并在多个CPU间进行负载均衡
对于KVM,可以通过主机操作系统应用细粒度的CPU配额,例如,在先前描述的主机内核公平共享调度器中使用。在Linux上,这可以使用cgroup CPU带宽控制来实现。
无论是哪种技术,都存在对客户机优先级的限制。客户机的CPU使用通常对Hypervisor不透明,客户机内核线程优先级通常无法被看到或受到尊重。例如,Solaris内核定期使用后台fsflush守护进程扫描内存的情况可能与另一个客户机中的关键应用服务器具有相同的Hypervisor优先级。
对于Xen,CPU资源的使用可能会因在dom0中消耗额外CPU资源的高I/O工作负载而变得更加复杂。客户机域中的后端驱动程序和I/O代理可能单独消耗超过它们的CPU分配的资源,但这些资源没有被计入[Cherkasova 05]。一个解决方案是创建隔离的驱动程序域(IDDs),这将I/O服务隔离出来,以实现安全性、性能隔离和计费。这在图11.9中有所描述。

IDDs的CPU使用情况可以进行监控,并且可以对客户机进行收费以反映这种使用情况。来自[Gupta 06]:
我们修改的调度器,SEDF-DC(SEDF-Debt Collector),周期性地从XenMon接收有关由IDDs代表客户机域进行I/O处理而消耗的CPU的反馈。利用这些信息,SEDF-DC限制了对客户机域的CPU分配,以满足指定的组合CPU使用限制。
在Xen中使用的一种较新的技术是存根域(stub domains),这些域运行着一个迷你操作系统。
内存容量
内存限制是作为客户机配置的一部分强加的,客户机只能看到设置的内存量。然后,客户机内核执行自己的操作(分页、交换)以保持在其限制范围内。
为了增加从静态配置中的灵活性,VMware开发了所谓的气球驱动程序[Waldspurger 02]。它能够通过在其中“膨胀”一个气球模块来减少运行中客户机所消耗的内存,该模块消耗客户机内存。然后,Hypervisor会将此内存收回,供其他客户机使用。气球也可以被放气,将内存返还给客户机内核使用。在此过程中,客户机内核执行其正常的内存管理例程以释放内存(例如,分页)。VMware、Xen和KVM都支持气球驱动程序。
文件系统容量
客户机从主机处获得虚拟磁盘卷,这些卷在客户机配置期间从存储磁盘池(使用ZFS)中创建,大小由所需大小确定。从这些磁盘卷中,客户机创建文件系统并管理其自己的空间,受配置卷大小的限制。执行此操作的确切细节取决于虚拟化软件和存储配置。
设备I/O
硬件虚拟化软件的资源控制历来专注于控制CPU使用量,这可以间接控制I/O使用量。网络吞吐量可以通过外部专用设备进行限制,或者在类型2的Hypervisor中,可以通过主机内核特性进行限制。例如,illumos内核支持网络带宽资源控制,理论上可以应用于客户机虚拟网络接口。Linux具有来自cgroups的网络带宽控制,可以以类似的方式使用。
Xen的网络性能隔离已经进行了研究,得出以下结论[Adamczyk 12]:
……当考虑网络虚拟化时,Xen的弱点是其缺乏适当的性能隔离。
[Adamczyk 12]的作者还为Xen网络I/O调度提出了解决方案,其中添加了用于网络I/O优先级和速率的可调参数。如果您使用Xen,请检查是否已提供此类或类似技术。
对于硬件虚拟化,磁盘和文件系统I/O技术也正在发展中。检查您的软件版本以了解可用内容,并且对于类型2的Hypervisor,还要检查主机操作系统提供了哪些资源控制。例如,Joyent的KVM客户机使用了早期描述的ZFS I/O限制技术对磁盘I/O进行限制。
11.3.3 Observability
可观察性取决于Hypervisor的类型和启动观察工具的位置。一般来说:
从特权客户机(类型1)或主机(类型2):可以使用标准操作系统工具观察所有物理资源,并从I/O代理观察I/O。来自操作系统或虚拟化软件应提供每个客户机资源使用情况的统计数据。客户机内部,包括其进程,不能直接被观察。
从客户机:通常情况下,不可观察物理资源及其使用情况。可以看到客户机使用的虚拟化资源及其使用情况。从特权客户机或主机,可以在高级别上观察物理资源的使用情况:利用率、饱和度、错误、IOPS、吞吐量、I/O类型。这些因素通常可以按客户机进行表达,因此可以快速识别出资源使用量大的用户。不能直接观察执行I/O的客户机进程及其应用程序调用堆栈的细节。这些可以通过登录到客户机(如果授权且已配置了手段,例如SSH)并使用客户机操作系统提供的观察工具来观察。
为了确定客户机性能问题的根本原因,云操作员可能需要登录到特权客户机或主机和客户机,并从两者执行观察工具。由于涉及的步骤,追踪I/O路径变得复杂,并且可能还包括对Hypervisor和I/O代理的分析。
从客户机,物理资源使用可能根本无法观察。这可能导致客户机用户将神秘的性能问题归咎于被不可见的吵闹邻居使用的物理资源。为了让云客户放心(并减少支持工单),有关物理资源使用情况的信息(已编辑)可以通过其他手段提供,包括SNMP或云API。
以下部分展示了可以从不同位置使用的观察工具,并描述了性能分析策略。使用Xen和KVM演示虚拟化软件可能提供的信息类型。
特权客户机/主机
所有系统资源(CPU、内存、文件系统、磁盘、网络)应该可以使用前几章介绍的工具进行观察。
KVM
对于类型2的Hypervisor,客户机实例在主机操作系统中是可见的。例如,在SmartOS上使用KVM:


QEMU进程是KVM客户机,其中包括每个虚拟CPU的线程和用于I/O代理的线程。它们的CPU使用情况可以在上述prstat(1M)输出中看到,并且可以使用其他prstat(1M)选项(-mL)来检查每个虚拟CPU的使用情况。将QEMU进程映射到其客户机实例名称通常是通过检查它们的进程参数(pargs(1))以读取-name选项来完成的。
另一个重要的分析领域是客户机虚拟CPU退出。发生的退出类型可以显示客户机正在执行的操作:特定虚拟CPU是空闲的、执行I/O还是执行计算。在Linux上,这些信息被收集并且可以通过debugfs文件系统访问,并且可以使用诸如perf(1)之类的工具。在SmartOS上,这些信息被收集在kstats中,并且可以使用kvmstat(1)工具进行总结。

前两个字段标识特定虚拟机内的虚拟CPU。其余列描述了退出的总数,并将它们分解成一般类别。最后几列描述了虚拟CPU上的其他活动。kvmstat(1)在其帮助消息中描述了这些列:
- pid:控制虚拟CPU的进程标识符
- vcpu:相对于其虚拟机的虚拟CPU标识符
- exits:虚拟CPU的虚拟机退出
- haltx:由于HLT指令而导致的虚拟机退出
- irqx:由于挂起的外部中断而导致的虚拟机退出
- irqwx:由于打开的中断窗口而导致的虚拟机退出
- iox:由于I/O指令而导致的虚拟机退出
- mmiox:由于内存映射I/O而导致的虚拟机退出
- irqs:注入到虚拟CPU中的中断
- emul:在内核中模拟的指令
- eptv:扩展页面表违规
虽然操作员可能不容易直接查看到虚拟客户机内部,但检查退出可以帮助您描述硬件虚拟化的开销是否会影响租户。如果您看到退出数量较少,而其中高比例是haltx,则说明客户机CPU相当空闲。另一方面,如果您有大量I/O操作,中断既被生成又被注入到客户机中,那么很可能客户机正在通过其虚拟网卡和磁盘进行I/O操作。
Xen
对于类型1的hypervisor,客户机的虚拟CPU存在于hypervisor中,并且无法通过特权客户机(dom0)使用标准操作系统工具进行查看。对于Xen,可以使用xentop(1)工具代替:

字段包括:
- CPU(%):CPU使用率百分比(多个CPU的总和)
- MEM(k):主内存使用量(千字节)
- MEM(%):系统内存的主内存使用百分比
- MAXMEM(k):主内存限制大小(千字节)
- MAXMEM(%):主内存限制占系统内存的百分比
- VCPUS:分配的虚拟CPU数量
- NETS:虚拟化网络接口的数量
- NETTX(k):网络传输量(千字节)
- NETRX(k):网络接收量(千字节)
- VBDS:虚拟块设备的数量
- VBD_OO:虚拟块设备请求被阻塞并排队的数量(饱和度)
- VBD_RD:虚拟块设备读取请求的数量
- VBD_WR:虚拟块设备写入请求的数量
xentop输出默认每3秒更新一次,并可以使用-d delay_secs选项进行选择。
高级可观测性
对于扩展的hypervisor分析,有许多选择。在Linux上,perf(1)提供了用于KVM和Xen的tracepoints,可用于调查各种事件。以下是Xen tracepoints的示例列表:

此外,还有xentrace(8)工具,它可以从hypervisor中检索固定事件类型的日志,然后可以使用xenanalyze查看。该日志可用于调查hypervisor和CPU调度程序的调度问题。
对于KVM,可以使用DTrace以自定义方式检查hypervisor的内部,包括kvm内核主机驱动程序和QEMU进程、主机内核调度程序、主机设备驱动程序以及与其他租户的交互。例如,以下DTrace脚本(kvmexitlatency.d [12])的输出跟踪KVM客户机退出延迟,并为每种类型打印分布图:


在这个例子中,所有的退出都在64微秒及以下,大多数在2微秒到16微秒之间。
提升hypervisor的可观测性是一个持续的过程,工具如perf(1)和DTrace扩展了可见范围的极限。其中一个例子是CR3分析。
CR3分析
由于Intel的VT-x指令集支持硬件辅助虚拟化,每个虚拟CPU都有一个虚拟机控制结构(VMCS)。VMCS包含了虚拟CPU的寄存器状态的副本,DTrace可以查询这些状态。系统上的每个进程都有自己的地址空间和一组描述虚拟到物理内存转换的页表。这些页表的根存储在寄存器CR3中。通过使用DTrace的profile提供程序,您可以从客户虚拟机中对CR3寄存器进行采样。如果经常看到特定的CR3值,那么您就知道在客户虚拟机中有一个特定的进程在CPU上非常活跃。尽管目前无法将此CR3值映射为可读的内容(如进程名称),但其数值确实唯一标识了客户虚拟机中的一个进程,可以用于理解系统的一般趋势。
Joyent的Cloud Analytics中的图11.10是CR3样本的可视化示例,显示了两个CPU密集型进程的客户内核调度活动。
这种可视化是一个亚秒偏移的热度图,每秒用采样数据绘制垂直列。右侧是扭曲的棋盘格图案,显示了两个不同的CR3交替在CPU上,这是由于两个不同的客户进程。

Guest
来自虚拟机的视角,只能看到虚拟设备。最有趣的度量是延迟,显示了设备在虚拟化、限制和其他租户的情况下的响应方式。像百分比忙碌这样的度量指标在不知道底层设备是什么的情况下很难解释。
在Linux上,vmstat(8)命令包括一个用于CPU百分比被窃取(st)的列,这是一个虚拟化感知统计数据的罕见例子:

在这个例子中,测试了一个具有激进CPU限制策略的Xen虚拟机。在前4秒内,超过90%的CPU时间都在虚拟机的用户模式下,只有少部分被其他租户窃取。然后,这种行为开始迅速改变,大部分CPU时间被其他租户窃取。
策略
前几章已经介绍了针对物理系统资源的分析技术,这些技术可供物理系统管理员使用,用于寻找瓶颈和错误。还可以检查对客户虚拟机施加的资源控制,以确定客户虚拟机是否始终达到其限制,并通知并鼓励他们进行升级。如果管理员没有登录客户虚拟机,则可能无法识别更多问题,而这在进行任何严肃的性能调查时可能是必要的。
对于客户虚拟机,可以应用前几章介绍的分析资源的工具和策略,但需要记住,这种情况下的资源是虚拟的。由于虚拟化管理程序的未见资源控制或其他租户的竞争,某些资源可能没有达到其限制。理想情况下,云软件或供应商应提供一种方式,使客户能够检查修正后的物理资源使用情况,以便他们可以独立进一步调查性能问题。如果没有提供此功能,则可能需要根据I/O和CPU调度延迟的增加推断资源竞争和限制。这种延迟可以在系统调用层或客户虚拟机内核中进行测量。
11.4 Comparisons
比较技术可以帮助你更好地了解它们,即使你没有改变公司所使用技术的权力。本章讨论的三种技术在表11.2中进行了比较。


虽然随着这些虚拟化技术的不断发展,这张表会变得过时,但它仍然可以用来展示需要注意的事项,即使是在开发了完全新的不符合这些类别的虚拟化技术时也是如此。
虚拟化技术经常使用微基准测试进行比较,以确定哪种性能最佳。不幸的是,这种方法忽视了可观察性能力,而这可能是所有性能增益中最大的(通过识别和消除不必要的工作)。考虑以下常见情景:一个新的云客户错误配置了一个应用程序,导致它消耗了过多的主内存并被分页或交换出去。通过操作系统虚拟化,云管理员可以轻松地定位到这一问题(参见早期的zonememstat(1M)命令),他们还可以查看到负责的进程、应用程序的堆栈跟踪,以及通常也可以看到配置文件,从而在不登录到客户虚拟机的情况下识别根本原因。对于硬件虚拟化,云管理员只能看到来自客户虚拟机的磁盘I/O,这可能看起来像任何其他磁盘I/O,被误认为是正常活动。客户虚拟机已经用尽内存并正在进行分页或交换这一情况无法在不登录到客户虚拟机的情况下识别,而这需要进行身份验证。
另一个需要考虑的因素是维护复杂性。在操作系统虚拟化中,维护成本最低,因为只有一个内核需要维护。对于半虚拟化,维护成本很高,因为客户虚拟机操作系统必须提供半虚拟化支持,需要进行内核更改。
对于Joyent公共云,我们更喜欢使用操作系统虚拟化(Zones),因为它提供了高性能和可观察性能力,只要我们的客户应用程序可以在SmartOS上运行。当需要其他客户虚拟机操作系统(Linux、Windows)时,我们使用带有半虚拟化的KVM,知道对于I/O密集型工作负载,性能可能会较差。我们尝试过Xen,但已经将其替换为Joyent KVM端口。
12 Benchmarking
基准测试以受控方式测试性能,使得可以比较选择并理解性能限制——在其在生产环境中遇到之前。这些限制可能是系统资源、虚拟化环境(云计算)中的软件限制,或者目标应用程序中的限制。之前的章节已经探讨了这些组件,描述了存在的限制类型以及用于分析它们的工具。
之前的章节还介绍了微基准测试的工具,这些工具使用简单的人工工作负载来研究限制。其他类型的基准测试包括客户工作负载模拟,试图复制客户使用模式,以及追踪重放。无论你使用哪种类型,都很重要分析基准测试,以便确认正在测量什么。基准测试只告诉你系统可以多快地运行基准测试;你需要理解结果,并确定它如何适用于你的环境。
本章讨论了基准测试的一般情况,提供了建议和方法,帮助你避免常见错误并准确测试你的系统。当你需要解释他人的结果时,包括供应商和行业基准测试,这也是有用的背景知识。
12.1 Background
本节描述了基准测试活动和有效的基准测试,并总结了常见的错误,称之为“基准测试的罪过”。
12.1.1 Activities
基准测试可以出于以下目的进行:
系统设计:比较不同系统、系统组件或应用程序。对于商业产品,基准测试可以提供数据,帮助做出购买决策,特别是对可用选项的价格/性能比进行比较。在某些情况下,可以使用已发布的行业基准测试结果,这样就避免了客户自己执行基准测试的需要。
调优:测试可调参数和配置选项,以确定哪些值得进一步在生产工作负载中进行调查。
开发:用于产品开发过程中的非回归测试和限制调查。非回归测试可以是定期运行的自动性能测试集,以便及早发现任何性能回归,并迅速将其匹配到产品更改。对于限制调查,基准测试可以在开发过程中驱动产品达到其极限,以确定最好投入工程努力来改善产品性能的地方。
容量规划:确定容量规划的系统和应用程序限制,可以为性能建模提供数据,也可以直接找到容量限制。
故障排除:验证组件是否仍然能够以最大性能运行,例如,在主机之间测试最大网络吞吐量,以检查是否可能存在网络问题。
营销:确定产品的最大性能供营销使用(也称为基准营销)。
在企业环境中,在投资昂贵硬件之前进行基准测试可能是一个重要的验证概念的练习,并且可能是一个持续数周的过程。这包括运输、架设和连接系统的时间,然后在测试之前安装操作系统。
在云计算环境中,资源可以根据需求提供,无需对硬件进行昂贵的初始投资。但是,选择使用哪种应用程序编程语言、哪种数据库、Web 服务器和负载均衡器时,仍然需要进行一些投资。其中一些选择未来可能很难更改。基准测试可以用来调查这些选择在需要时的扩展能力。云计算模型也使基准测试变得容易:可以在几分钟内创建一个大型环境,用于进行基准测试,然后销毁,成本非常低。
12.1.2 Effective Benchmarking
基准测试出人意料地难以做到完美,存在许多错误和疏忽的机会。正如《一个关于文件系统和存储基准测试的九年研究》[Traeger 08]一文所总结的那样:
在这篇文章中,我们调查了106篇近期论文中的415个文件系统和存储基准测试。我们发现,大多数流行的基准测试存在缺陷,许多研究论文未能清楚地指示真实性能。
该论文还提出了一些建议;特别是,基准评估应该解释测试了什么以及为什么测试这些内容,并且应该对系统的预期行为进行一些分析。
好的基准测试的本质也已经被总结为 [Smaalders 06]:
可重复:以便进行比较
可观察:以便分析和理解性能
可移植:以允许在竞争对手和不同产品发布版本之间进行基准测试
易于呈现:以便每个人都能理解结果
真实可信:以便测量反映客户经历的现实
可运行:以便开发人员可以快速测试变更
在比较不同系统并打算购买时,还必须添加另一个特征:价格/性能比。价格可以量化为设备的五年资本成本[Anon 85]。
有效的基准测试还涉及如何应用基准测试:分析和得出结论。
基准测试分析
在使用基准测试时,您需要了解以下内容:
正在测试的是什么
限制因素是什么
可能影响结果的任何干扰
可以从结果中得出什么结论
这些需求需要深入了解基准软件的运行原理,系统的响应方式以及结果与目标环境的关系。
有了基准测试工具和运行该工具的系统的访问权限,最好通过性能分析来满足这些需求,而基准测试正在运行时进行。一个常见的错误是让初级员工执行基准测试,然后在基准测试完成后请性能专家解释结果。最好在进行基准测试时就让性能专家参与进来,这样他们就可以在系统仍在运行时分析系统。这可能包括深入分析以解释和量化限制因素。
以下是一个有趣的分析示例:
作为研究结果TCP/IP实现性能的实验,我们在不同机器上的两个用户进程之间传输了4兆字节的数据。传输被分成1024字节的记录,并封装在1068字节的以太网数据包中。通过TCP/IP从我们的11/750发送数据到我们的11/780花费了28秒。这包括设置和拆除连接所需的所有时间,用户之间的吞吐量为1.2兆比特/秒。在此期间,11/750的CPU被完全占用,但11/780有大约30%的空闲时间。在系统中处理数据的时间分散在以太网处理(20%)、IP数据包处理(10%)、TCP处理(30%)、校验和(25%)和用户系统调用处理(15%)之间,没有任何一个部分在系统中占据主导地位。
这描述了检查限制因素(“11/750的CPU被完全占用”),然后解释了导致这些因素的内核组件的细节。值得一提的是,即使使用了高级工具如DTrace,能够执行这种分析并如此清晰地总结内核时间在今天仍然是一种不寻常的技能。这段引用来自1981年比尔·乔伊(Bill Joy)在开发原始的BSD TCP/IP堆栈时![1]
除了使用特定的基准测试工具外,您可能会发现开发自己的定制基准测试软件,或者至少是定制负载生成器更加有效。这些可以保持简洁,只关注您测试所需的内容,使其快速分析和调试。
在某些情况下,您可能无法访问基准测试工具或系统,比如在阅读他人的基准测试结果时。根据可用的材料考虑前述事项,并且另外询问:系统环境是什么?它是如何配置的?您可能会获准向供应商提出这些问题。有关更多供应商问题,请参阅第12.4节“基准问题”。
12.1.3 Benchmarking Sins
以下各节提供了一个特定问题的快速检查清单,以及如何避免这些问题。第12.3节“方法论”描述了如何进行基准测试。
随意的基准测试
要做好基准测试并不是一个一劳永逸的活动。基准测试工具提供了数字,但这些数字可能不反映您的想法,因此您对它们的结论可能是错误的。
随意的基准测试:您对A进行基准测试,但实际上测量的是B,并得出您已测量了C的结论。
做好基准测试需要严谨性,以检查实际测量的内容,并理解测试了什么以形成有效的结论。
例如,许多工具声称或暗示它们测量磁盘性能,但实际上测试的是文件系统性能。这两者之间的差异可能是数量级的,因为文件系统使用缓存和缓冲来替代磁盘I/O,而使用内存I/O。即使基准测试工具可能正常运行并测试文件系统,您对磁盘的结论也将大大不正确。
对于初学者来说,理解基准测试特别困难,因为他们无法判断数字是否可疑。如果您购买了一个将您所在房间的温度显示为1000华氏度的温度计,您会立即意识到有些不对劲。但基准测试并非如此,它产生的数字可能对您来说是陌生的。
盲目相信基准测试
也许会诱人地相信一个流行的基准测试工具是可信的,特别是如果它是开源的,并且已经存在很长时间。认为流行等于有效的误解被称为“广义论逻辑”(拉丁语意为“向人民呼吁”)。
分析您正在使用的基准测试工具是耗时的,并且需要专业知识来正确执行。对于一个流行的基准测试工具,分析它看似必须是有效的,可能会显得浪费时间。
问题甚至不一定在于基准测试软件本身——虽然错误确实会发生——而是在于对基准测试结果的解释。
没有分析的数字
提供了没有分析细节的简单基准测试结果可能表明作者缺乏经验,并且假设基准测试结果是可信的和最终的。通常,这只是调查的开始,而且结果可能是错误的或令人困惑的。
每个基准测试数字都应该附带对遇到的限制和执行的分析的描述。我用以下方式总结了这种风险:
如果您花了不到一周的时间研究基准测试结果,那么它很可能是错误的。
本书的很大一部分关注于分析性能,在基准测试期间应该进行这种分析。在没有时间进行仔细分析的情况下,将假设列出并包含在结果中是一个好主意,例如:
假设基准测试工具没有漏洞
假设磁盘I/O测试实际上测量了磁盘I/O
假设基准测试工具将磁盘I/O驱动到其预期的极限
假设这种类型的磁盘I/O对于这个应用程序是相关的
如果基准测试结果后来被认为很重要而值得花费更多精力,这就可以成为一个待办事项清单。
复杂的基准测试工具
基准测试工具的复杂性不应该阻碍基准分析。理想情况下,该程序是开源的,以便可以进行研究,并且足够简短,可以快速阅读和理解。
对于微基准测试,建议选择使用C编程语言编写的工具。对于客户端模拟基准测试,建议使用与客户端相同的编程语言,以减小差异。
常见问题之一是对基准测试工具本身进行基准测试,即所报告的结果受到基准软件本身的限制。由于需要理解和分析的代码量巨大,复杂的基准测试套件可能会使这一问题难以确定。
测试错误的内容
虽然有大量的基准测试工具可用于测试各种工作负载,但其中许多可能与目标应用程序无关。
例如,一个常见的错误是测试磁盘性能——基于磁盘基准测试工具的可用性——尽管目标环境工作负载预计完全在文件系统缓存中运行,与磁盘I/O无关。
同样,一个开发产品的工程团队可能会标准化一个特定的基准,并将所有性能努力都花在提高该基准衡量的性能上。然而,如果实际上与客户工作负载不符,则工程努力将优化错误的行为。基准测试可能曾经测试了一个适当的工作负载,但多年来没有更新,因此现在测试了错误的内容。文章《对一个基准的颂词》描述了SPEC SFS行业基准测试的一个版本,该基准测试常在2000年代引用,其基础是1986年的客户使用研究。
忽视错误
仅仅因为基准测试工具生成了一个结果,并不意味着该结果反映了一个成功的测试。一些,甚至全部,请求可能导致错误。虽然这个问题在前述错误中已经涵盖了,但这个问题特别普遍,值得特别指出。
最近对Web服务器性能进行基准测试时,我想起了这一点。进行测试的人报告说,Web服务器的平均延迟超出了他们的需求:平均超过一秒。一些快速的分析确定了出了什么问题:在测试期间,Web服务器根本没有做任何事情,因为所有请求都被防火墙阻止了。所有的请求。所显示的延迟是基准客户端超时和错误所花费的时间。
忽视差异
基准测试工具,尤其是微基准测试,通常会应用稳定和一致的工作负载,基于一系列实际特征的平均值,例如不同时间的特征或某个时间段的特征。例如,可以发现磁盘工作负载的平均读取速率为每秒500次,写入速率为每秒50次。然后,基准测试工具可能会模拟这个速率,或者模拟10:1读写比例,以便测试更高的速率。
这种方法忽视了差异:操作速率可能是可变的。操作类型也可能变化,一些类型可能会正交发生。例如,写入可能会每10秒进行一次突发操作(异步写回数据刷新),而同步读取则是稳定的。写入的突发操作可能会在生产环境中引发真正的问题,例如通过排队读取,但如果基准应用稳定的平均速率,则不会模拟这些情况。
忽视扰动
考虑到外部扰动可能影响结果。在基准测试运行期间,是否会执行定时的系统活动,例如系统备份?对于云环境,扰动可能由同一系统上的未见租户引起。
消除扰动的常见策略是延长基准测试的运行时间——从几秒钟延长到几分钟。作为一项规则,基准测试的持续时间不应短于一秒。短暂的测试可能会异常地受到设备中断(在执行中断服务程序时固定线程)、内核CPU调度决策(在迁移排队线程之前等待以保持CPU亲和性)和CPU缓存热效应的影响。尝试多次运行基准测试,并检查标准偏差。这应尽可能小,以确保可重复性。
还要收集数据,以便研究扰动(如果存在)。这可能包括收集操作延迟的分布——而不仅仅是基准测试的总运行时间——以便看到异常值并记录其详细信息。
改变多个因素
在比较两次测试的基准测试结果时,务必注意了解两者之间的所有不同因素。
例如,如果对两台主机进行网络基准测试,它们之间的网络是否完全相同?如果一台主机距离更远,位于一个速度较慢或拥塞较严重的网络上会怎样?任何此类额外因素都可能使基准测试结果失真。
在云环境中,有时会通过创建实例、测试它们,然后销毁它们来进行基准测试。这会产生许多未见因素的潜在问题:实例可能是在更快或更慢的系统上创建的,或者是在其他租户负载和争用更高的系统上创建的。建议测试多个实例并取平均值(或更好地记录分布),以避免由于测试一个异常快或慢的系统而引起的异常值。
竞争对手基准测试
您的营销部门希望有基准测试结果,展示您的产品如何击败竞争对手。我将要解释的原因通常是一个坏主意。
当客户选择一个产品时,他们不是使用它5分钟;他们会使用几个月。在此期间,他们会分析和调整产品性能,也许在最初的几周摆脱最糟糕的问题。
您没有几周时间来分析和调整竞争对手。在可用的时间内,您只能收集未调整的——因此不现实的——结果。竞争对手的客户——这次营销活动的目标——很可能会注意到您发布了未调整的结果,因此您的公司将失去对试图给他们留下印象的人的信誉。
如果您必须对竞争对手进行基准测试,您将希望花费大量时间来调整他们的产品。使用早期章节中描述的技术分析性能。还要搜索最佳实践、客户论坛和错误数据库。您甚至可能想要引入外部专业知识来调整系统。然后在最后进行公司内部的对比基准测试之前,为自己的公司做同样的努力。
友军误伤
在对自己的产品进行基准测试时,应尽一切努力确保已经测试了性能最佳的系统和配置,并且系统已经被推到了真正的极限。在发布之前与工程团队分享结果;他们可能会注意到您错过的配置项。如果您在工程团队中,要注意基准测试的努力——无论是来自您的公司还是来自签约的第三方——并帮助他们。
考虑这样的假设情况:一个工程团队努力开发了一个性能出色的产品。关键是一个新技术,他们开发了这个技术,但尚未记录。为产品发布,一个基准测试团队被要求提供数据。他们不了解新技术(没有文档),他们错误配置了它,然后他们发布了低估产品的数字。
有时系统可能已经正确配置,但只是还没有被推到极限。问一下这个基准测试的瓶颈是什么?这可能是一个物理资源,如CPU、磁盘或互连,已经被推到了100%,可以使用分析来识别。参见第12.3.2节,“主动基准测试”。
另一个友军误伤问题是基准测试较旧版本的软件,这些软件在后续版本中已经修复了性能问题,或者在可用的有限设备上进行测试,产生的结果不是最好的(这可能是公司基准测试所期望的)。
误导性基准测试
误导性基准测试结果在行业中很常见。通常情况下,这是由于对基准测试实际测量内容的信息受限,或者有意地省略了信息。通常情况下,基准测试结果在技术上是正确的,但却被误导性地呈现给客户。
考虑这样一个假设情况:一个供应商通过构建一款定制产品获得了出色的结果,但这款产品价格昂贵,实际上不会销售给实际客户。基准测试结果中未披露价格,而是侧重于非价格/性能指标。市场营销部门大量分享了基准测试结果的模糊摘要(“我们速度提升了2倍!”),将其与公司整体或产品线联系在客户的心中。这是一种省略细节以有利地误导产品的情况。虽然这可能不是欺骗——数字并非虚假——但却是通过遗漏来撒谎。
这种供应商基准测试结果可能仍然对您有用,作为性能的上限。这些数值是您不应该期望超过的值(在友军误伤的情况下除外)。
再考虑一个不同的假设情况:一个营销部门有预算用于推广活动,并希望获得一个好的基准测试结果来使用。他们请几家第三方进行基准测试,并从中挑选出最佳的结果。这些第三方不是因为他们的专业知识而被选中的;他们被选中是为了提供快速和廉价的结果。事实上,非专业知识可能被认为是有利的:结果与现实偏离得越大,越好。理想情况下,其中一家偏离的方向非常积极!
在使用供应商结果时,务必注意检查详细信息,包括测试了什么系统、使用了多少种类型的磁盘、使用了哪种配置的网络接口等。要注意的具体细节,请参阅第12.4节“基准测试问题”。
基准测试特殊优化
一种被一些人视为罪恶并因此被禁止的狡猾行为是开发基准测试特殊优化。这就是供应商研究流行或行业基准测试,然后设计产品使其得分良好,而不考虑实际客户性能的情况。这也被称为为基准测试进行优化。
基准测试特殊优化的概念始于1993年的TPC-A基准测试,如Transaction Processing Performance Council (TPC)历史页面所述:
马萨诸塞州的咨询公司Standish Group指责Oracle向其数据库软件添加了一个特殊选项(离散事务),目的只是为了增加Oracle的TPC-A结果。Standish Group声称Oracle“违反了TPC的精神”,因为离散事务选项是典型客户不会使用的东西,因此是基准测试特殊优化。Oracle强烈否认了这一指控,并表示他们在基准测试规范上严格遵循了法律,这在某种程度上是有道理的。Oracle辩称,由于TPC基准测试规范中既没有涉及基准测试特殊优化,也没有涉及TPC精神,因此指控他们违反任何规定都是不公平的。
TPC增加了反对基准测试特殊优化的条款:
所有改善基准测试结果但不改善实际性能或定价的“基准测试特殊”实施都是被禁止的。
由于TPC侧重于价格/性能,另一种夸大数字的策略是基于特殊定价——实际客户无法获得的深度折扣。就像特殊的软件更改一样,当真实客户购买系统时,结果与现实不符。TPC在其价格要求中解决了这个问题:
TPC规范要求总价格必须在与客户为配置支付的价格相差不超过2%的范围内。
虽然这些例子可能有助于解释基准测试特殊优化的概念,但TPC多年前就在其规范中对其进行了处理,您不必现在就期望出现这种情况。
作弊
基准测试的最后一个罪行是作弊:分享虚假结果。幸运的是,这要么很少见,要么根本不存在;即使在最激烈的基准测试战斗中,我也没有看到过纯粹捏造的数字被分享的情况。
12.2 Benchmarking Types
图12.1展示了基于测试工作负载的基准测试类型谱系。生产工作负载也包含在谱系中。

接下来的几节将描述三种基准测试类型:微基准测试、模拟和跟踪/重放。同时也会讨论行业标准基准测试。
12.2.1 Micro-Benchmarking
微基准测试使用人工工作负载,测试特定类型的操作,例如执行单一类型的文件系统I/O、数据库查询、CPU指令或系统调用。其优势在于简单性:减少涉及的组件数量和代码路径使得研究目标更容易,并且能够快速确定性能差异的根本原因。由于尽可能排除了其他组件的变化,测试通常也是可重复的。微基准测试通常也很快速,可以在不同系统上进行测试。并且由于它们是刻意人工制造的,因此微基准测试不容易与真实工作负载模拟混淆。
为了利用微基准测试结果,需要将其映射到目标工作负载。微基准测试可能会测试多个维度,但只有一两个可能是相关的。对目标系统的性能分析或建模可以帮助确定哪些微基准测试结果是适当的,以及适用程度。
在前几章提到的示例微基准测试工具包括,按资源类型,
- CPU:UnixBench,SysBench
- 内存I/O:lmbench(在第6章,CPU中)
- 文件系统:Bonnie,Bonnie++,SysBench,fio
- 磁盘:hdparm
- 网络:iperf
还有许多其他基准测试工具可用。但请记住[Traeger 08]的警告:“大多数流行的基准测试都存在缺陷。”
你也可以开发自己的基准测试。目标是尽可能简单,识别可以单独测试的工作负载属性。(有关此内容的更多信息,请参见第12.3.6节,自定义基准测试。)
设计示例
考虑设计一个文件系统微基准测试,以测试以下属性:顺序或随机I/O、I/O大小和方向(读取或写入)。表12.1显示了五个样本测试,用于研究这些维度,以及每个测试的原因。

可以根据需要添加更多测试。所有这些测试都会乘以两个额外的因素:
- 工作集大小:被访问数据的大小(例如,总文件大小):
- 远远小于主内存:以使数据完全缓存在文件系统缓存中,并可以调查文件系统软件的性能。
- 远远大于主内存:以最小化文件系统缓存的影响,并将基准测试驱动到测试磁盘I/O。
- 线程数量:假设工作集大小较小:
- 单线程测试文件系统性能,基于当前CPU时钟速度。
- 多线程 - 足以饱和所有CPU - 以测试系统的最大性能:文件系统和CPU。
这些因素很快就会相乘形成一个庞大的测试矩阵。有统计分析技术可以减少所需的测试集。
创建专注于最高速度的基准测试被称为晴天性能测试。为了不忽视问题,您还希望考虑阴天性能测试,这涉及测试非理想情况,包括争用、扰动和工作负载变化。
12.2.2 Simulation
许多基准测试模拟客户应用程序工作负载(有时称为宏基准测试)。这些可能基于对生产环境的工作负载特性进行的特征化(参见第2章,方法论),以确定要模拟的特性。例如,可能会发现生产 NFS 工作负载由以下操作类型和概率组成:读取,40%;写入,7%;获取属性,19%;读取目录,1%;等等。还可以测量和模拟其他特性。
模拟可以产生类似于客户端在真实工作负载下的性能的结果,即使不是非常接近,至少也足够有用。它们可以包含许多因素,使用微基准测试进行调查将耗费大量时间。模拟还可以包括使用微基准测试时可能完全遗漏的复杂系统交互的影响。
在第6章,CPU 中介绍的 CPU 基准测试 Whetstone 和 Dhrystone 就是模拟的示例。Whetstone 是在 1972 年开发的,用于模拟当时的科学工作负载。Dhrystone,来自 1984 年,模拟了当时基于整数的工作负载。之前提到的 SPEC SFS 基准测试是另一个工作负载模拟。
工作负载模拟可以是无状态的,其中每个服务器请求与前一个请求无关。例如,之前描述的 NFS 服务器工作负载可以通过请求一系列操作来模拟,每个操作类型根据测得的概率随机选择。
模拟也可以是有状态的,其中每个请求依赖于客户端状态,至少依赖于前一个请求。可能会发现 NFS 读取和写入倾向于成组到达,这样,如果前一个操作是写入,则写入的概率要比读取时高得多。可以使用马尔可夫模型更好地模拟这样的工作负载,通过将请求表示为状态并测量状态转换的概率[Jain 91]。
模拟的一个问题是它们可能忽略方差,如第12.1.3节“基准测试的罪过”所述。客户使用模式也可能随时间而变化,需要更新和调整这些模拟以保持相关性。然而,如果已经有基于旧基准版本发布的结果,那么可能会对这种更新存在抵制,因为这些结果将不再可用于与新版本进行比较。
12.2.3 Replay
第三种基准测试类型涉及尝试重放跟踪日志到目标系统,并通过实际捕获的客户端操作来测试其性能。这听起来理想——就像在生产环境中测试一样,对吧?然而,这种方法存在问题:当服务器的特性和交付延迟发生变化时,捕获的客户端工作负载不太可能自然地对这些差异做出反应,这可能证明并不比模拟的客户端工作负载更好。当人们对此过于信任时,情况可能变得更糟。
考虑这样一个假设情景:一个客户正在考虑升级存储基础设施。当前的生产工作负载被跟踪并重放到新硬件上。不幸的是,性能变差了,销售也失去了。问题在于:跟踪/重放操作在磁盘 I/O 层面进行。旧系统使用的是 10,000 转每分钟的磁盘,而新系统使用的是转速较慢的 7,200 转每分钟的磁盘。然而,新系统提供了 16 倍于旧系统的文件系统缓存以及更快的处理器。实际生产工作负载的性能本应会得到改善,因为它主要会从缓存中返回——而重放磁盘事件并未模拟这一点。
虽然这是一个测试错误的案例,但即使使用正确级别的跟踪/重放,其他微妙的时间效应也可能会搞乱事情。与所有基准测试一样,分析和理解正在发生的事情至关重要。
12.2.4 Industry Standards
行业标准基准测试由独立组织提供,旨在创建公平且相关的基准测试。通常这些基准测试由多个微基准测试和工作负载模拟组成,这些测试都被明确定义和文档化,并且必须根据某些指导方针执行,以确保结果如预期。厂商可以参与其中(通常需要支付费用),这为厂商提供了执行基准测试的软件。他们的结果通常需要完全披露配置环境,可能会接受审计。
对于客户来说,这些基准测试可以节省大量时间,因为可能已经为各种厂商和产品提供了基准测试结果。因此,您的任务是找到与您未来或当前的生产工作负载最相似的基准测试。对于当前的工作负载,这可能是通过工作负载特征化来确定的。
工业标准基准测试的需求在 1985 年一篇题为《事务处理能力的衡量》的论文中被明确提出,该论文由吉姆·格雷(Jim Gray)等人撰写。该论文描述了衡量价格/性能比的需求,并详细介绍了供应商可以执行的三种基准测试,称为 Sort、Scan 和 DebitCredit。它还提出了基于 DebitCredit 的工业标准事务每秒(TPS)的衡量方法,类似于汽车的每加仑英里。吉姆·格雷及其工作后来鼓励了 TPC 的创建。
除了 TPS 衡量标准之外,还有其他用于相同角色的衡量标准,包括:
- MIPS:每秒百万条指令数。虽然这是一种性能衡量标准,但执行的工作取决于指令的类型,这在不同处理器架构之间可能难以比较。
- FLOPS:每秒浮点运算次数——类似于 MIPS,但用于对浮点计算密集型工作负载进行衡量。
工业基准测试通常根据基准测试衡量一个自定义指标,仅用于与自身进行比较。
TPC
TPC 是指标准性能评估公司(TPC,The Transaction Processing Performance Council),该机构创建并管理各种行业基准测试,重点关注数据库性能。其中包括:
- TPC-C:模拟完整的计算环境,其中一组用户针对数据库执行事务。
- TPC-DS:模拟决策支持系统,包括查询和数据维护。
- TPC-E:在线事务处理(OLTP)工作负载,模拟经纪公司数据库,客户生成与交易、账户查询和市场研究相关的交易。
- TPC-H:决策支持基准测试,模拟临时查询和并发数据修改。
- TPC-VMS:TPC 虚拟测量单系统允许为虚拟化数据库收集其他基准测试。TPC 的结果在网上共享,包括价格/性能比。
SPEC
SPEC 是标准性能评估公司(SPEC,The Standard Performance Evaluation Corporation),该公司开发和发布一套标准化的行业基准测试,其中包括:
- SPEC CPU2006:计算密集型工作负载的衡量标准。包括整数性能的 CINT2006 和浮点性能的 CFP2006。
- SPECjEnterprise2010:Java Enterprise Edition(Java EE)5 或更高版本应用服务器、数据库和支持基础设施的全系统性能衡量标准。
- SPECsfs2008:用于 NFS 和常见互联网文件系统(CIFS)服务器的客户端文件访问工作负载模拟。
- SPECvirt_sc2010:针对虚拟化环境,衡量虚拟化硬件、平台以及客户操作系统和应用软件的性能。SPEC 的结果在网上共享,包括系统如何进行调优以及组件列表,但通常不包括价格信息。
12.3 Methodology
这一部分介绍了进行基准测试的方法和练习,无论是微基准测试、模拟还是重播。相关主题总结在表12.2中。

12.3.1 Passive Benchmarking
这是基准测试的"点火忘记"策略——即执行基准测试然后忽略直到完成。主要目标是收集基准测试数据。这是基准测试常见的执行方式,并被描述为与主动基准测试进行比较的一种方法论。以下是一些被动基准测试的示例步骤:
1. 选择一个基准测试工具。
2. 使用各种选项运行它。
3. 制作结果的幻灯片。
4. 将幻灯片交给管理层。
此方法存在一些问题,之前已经讨论过。总结起来,结果可能是:
- 由于基准测试软件缺陷而无效。
- 受基准测试软件限制(例如,单线程)。
- 受与基准测试目标无关的组件限制(例如,拥塞的网络)。
- 受配置限制(性能特性未启用,不是最大配置)。
- 受干扰影响(不可重复)。
- 完全基准测试了错误的事物。
被动基准测试易于执行,但容易出错。如果由供应商执行,可能会产生错误的警报,浪费工程资源或导致销售损失。如果由客户执行,可能会导致后来选择产品时出现问题,影响公司的发展。
12.3.2 Active Benchmarking
通过主动基准测试,您可以在基准测试运行时分析性能,而不仅仅是在完成后使用其他工具。您可以确认基准测试是否测试了它所说的内容,并且您理解了测试内容。主动基准测试还可以识别受测试系统或基准测试本身限制的真实因素。在分享基准测试结果时,包含遇到的限制的具体细节非常有帮助。
作为额外的好处,这也是发展您的性能观测技能的好时机。理论上,您正在检查一个已知负载,并可以从这些工具中看到它的表现方式。
理想情况下,基准测试可以配置并保持在稳定状态下运行,以便可以在数小时或数天的时间段内进行分析。
举例来说,让我们看一下Bonnie++微基准测试工具的第一个测试。在其主页上描述如下:
Bonnie++是一个旨在执行一些简单的硬盘和文件系统性能测试的基准测试套件。
第一个测试是“顺序输出”和“每字符”,并且在两个不同的操作系统上执行以进行比较。
- Fedora/Linux(在KVM虚拟化下):

- SmartOS/illumos(在操作系统虚拟化下):


因此,SmartOS快了3.1倍。如果我们就此打住,那将是被动基准测试。
鉴于Bonnie++是一个“硬盘和文件系统性能”基准测试,我们可以从检查执行的工作负载开始。
在SmartOS上运行iostat(1M)来检查磁盘I/O:

磁盘开始处于空闲状态,然后在基准测试期间显示可变的写入吞吐量(kw/s),但远低于Bonnie++报告的K/sec结果。
在SmartOS上运行vfsstat(1M)来检查文件系统I/O(VFS级别):

现在吞吐量与Bonnie++的结果一致。然而,IOPS并不是:vfsstat(1M)显示写入大约为每个128 K字节(kw/s / w/s),而不是“每字符”。
在SmartOS上使用truss(1)来调查对文件系统的写入(暂时忽略truss(1)的开销):

这证实了Bonnie++执行的是128 K字节的文件系统写入。
在Fedora上使用strace(1)进行比较:

这显示Fedora执行的是4 K字节的文件系统写入,而SmartOS执行的是128 K字节的写入。
通过更多的分析(使用DTrace),发现这是系统库中putc()的缓冲,每个操作系统默认使用不同的缓冲大小。作为一个实验,将Fedora上的Bonnie++调整为使用128 K字节的缓冲(使用setbuffer()),其性能提高了18%。
主动性能分析确定了该测试执行的各种其他特征,从而更好地理解了结果。结论是,它最终受到单线程CPU速度的限制,并且85%的CPU时间花费在用户模式中。
Bonnie++并不是一个异常糟糕的基准测试工具;在许多情况下,它都为人们提供了帮助。我选择了它作为这个示例(并且还选择了其中最可疑的测试进行研究),因为它众所周知,我以前曾研究过它,而且像这样的发现并不少见。但这只是一个例子。
值得注意的是,Bonnie++的一个较新的实验版本已将“Per Chr”测试更改为实际执行1字节的文件系统I/O。对于此测试,比较不同版本的Bonnie++结果将显示显着差异。有关Bonnie++性能分析的更多信息,请参阅Roch Bourbonnais的文章“解码Bonnie++”。
12.3.3 CPU Profiling
CPU的性能分析是一种值得单独提出的方法论,因为它可能导致一些快速的发现。通常作为主动基准测试调查的一部分进行。
其目的是快速检查所有软件的运行情况,看看是否有什么有趣的发现。这也可以将研究范围缩小到最重要的软件组件:那些在基准测试中起作用的组件。
可以对用户级别和内核级别的堆栈进行性能分析。用户级CPU性能分析是在第5章“应用程序”中介绍的。两者都在第6章“CPU”中涵盖,其中包括在第6.6节“分析”中的示例,包括火焰图。
例子
在一个提议的新系统上进行了磁盘微基准测试,结果令人失望:磁盘吞吐量比旧系统更差。有人要求我找出问题所在,预期是磁盘或磁盘控制器要么不够好,要么应该升级。
我从使用USE方法(第2章“方法论”)开始,发现尽管这是基准测试的重点,但磁盘并不是很忙碌。在系统时间(内核)中有一些CPU使用率。
对于磁盘基准测试,你可能不会期望CPU成为有趣的分析对象。鉴于内核中有一些CPU使用率,我认为值得快速检查是否会出现任何有趣的情况,尽管我并不指望会有。我进行了性能分析,并生成了图12.2中显示的火焰图。

浏览堆栈帧显示,62.17%的CPU样本包含一个名为zfs_zone_io_throttle()的函数。我不需要阅读该函数的代码,因为其名称已经足够提示:一个资源控制,ZFS I/O限制,正在激活并人为地限制基准测试!这是新系统的默认设置(但不是旧系统),在进行基准测试时被忽略了。
12.3.4 USE Method
USE方法是在第2章“方法论”中介绍的,并且在研究其资源的章节中进行了描述。在基准测试期间应用USE方法可以确保找到一个限制。要么某些组件(硬件或软件)已经达到了100%的利用率,要么你没有将系统推向极限。
使用USE方法的一个例子在第12.3.2节“主动基准测试”中进行了描述,它帮助发现磁盘基准测试未按预期工作的问题。
12.3.5 Workload Characterization
工作负载特性也是在第2章“方法论”中介绍的,并在后续章节中进行了讨论。这种方法论可以用来确定给定基准测试与当前生产环境的关系有多好,方法是对生产负载进行特性化以进行比较。
12.3.6 Custom Benchmarks
对于简单的基准测试,自己编写软件可能是一个理想选择。尽量保持程序尽可能简短,以避免复杂性影响分析。C编程语言通常是一个不错的选择,因为它与实际执行的内容密切相关,尽管需要仔细考虑编译器优化如何影响代码:如果编译器认为输出未被使用且不必要计算,则可能会省略简单的基准测试例程。值得反汇编已编译的二进制文件以查看实际执行的内容。
涉及虚拟机、异步垃圾回收和动态运行时编译的语言可能更难以以可靠的精度进行调试和控制。如果需要模拟使用这些语言编写的客户端软件,则可能仍然需要使用这些语言。
编写自定义基准测试还可以揭示有关目标的微妙细节,这些细
12.3.7 Ramping Load
这是一种确定系统能够处理的最大吞吐量的简单方法。它涉及逐步增加负载,并测量传递的吞吐量,直到达到极限。结果可以制成图表,显示出可扩展性概况。这个概况可以通过可视化或使用可扩展性模型(参见第2章“方法论”)进行研究。
作为示例,图12.3显示了文件系统和系统随线程数量的变化情况。每个线程对一个缓存文件执行8 K字节的随机读取,并逐个添加。

该系统的峰值达到了近50万次读取每秒。通过使用VFS级别的统计数据对结果进行了检查,确认了I/O大小为8 K字节,并且在峰值时传输速率超过3.5 GB/s。
这个测试的负载生成器是用Perl编写的,而且足够简短,可以完全作为示例包含进来:

这使用sysread()直接调用read()系统调用来避免缓冲。这是为了微基准测试一个NFS服务器而编写的,并且从一组客户端并行执行,每个客户端在一个NFS挂载的文件上执行随机读取。微基准测试的结果(每秒读取次数)是在NFS服务器上使用nfsstat(1M)和其他工具进行测量的。所使用的文件数量及其组合大小受到控制(这形成了工作集大小),以便某些测试可以完全从缓存返回,而其他测试则从磁盘返回。(参见第12.2.1节“微基准测试”中的设计示例。)逐个递增在客户端农场上执行的实例数量,以逐步增加负载直到达到极限。这也被制成图表以研究可扩展性概况,以及资源利用(USE方法),确认资源已经耗尽。在这种情况下,是CPU资源,这启动了另一项调查以进一步提高性能。我使用这个程序和这种方法来找出Oracle ZFS存储设备(正式称为Sun ZFS存储设备[10])的限制。这些限制被用作官方结果,据我们所知创下了世界记录。我还有一个类似的用C语言编写的软件集,但在这种情况下并不需要:我有大量的客户端CPU,而且虽然转换到C语言减少了它们的利用率,但对于结果来说没有影响,因为目标上达到了同样的瓶颈。还尝试了其他更复杂的基准测试,以及其他语言,但它们都无法改进这些结果。在采用这种方法时,除了吞吐量外,还要测量延迟,特别是延迟分布。一旦系统接近其极限,排队延迟可能变得显著,导致延迟增加。如果负载推得太高,延迟可能会变得如此之高,以至于不再合理地考虑结果是否有效。问自己传递的延迟是否对客户可接受。例如:您使用一个大型的客户端数组来驱动一个目标系统达到990,000 IOPS,它的平均I/O延迟为5毫秒。您确实希望它突破100万IOPS,但系统已经达到饱和。通过添加更多的客户端,您设法突破了100万IOPS;然而,所有操作现在都被大量排队,平均延迟超过50毫秒(这是不可接受的)!您会向营销部门提供哪个结果?(答案:990,000 IOPS。)
12.3.8 Sanity Check
这是一个检查基准测试结果的练习,通过调查是否存在任何不合理的特征来进行。这包括检查结果是否需要某些组件超出其已知限制,例如网络带宽、控制器带宽、互连带宽或磁盘IOPS。如果超出了任何限制,值得进行更详细的调查。在大多数情况下,这种练习最终会发现基准测试结果是虚假的。
以下是一个示例:对一个NFS服务器进行基准测试,使用8 K字节读取,报告交付50,000 IOPS。它使用单个1 Gbit/s以太网端口连接到网络。驱动50,000 IOPS x 8 K字节所需的网络吞吐量为400,000 K字节/秒,加上协议头。这超过了已知的1 Gbit/s限制,超过3.2 Gbit/s。显然有些不对劲!
这样的结果通常意味着基准测试已经测试了客户端缓存,并没有将整个工作负载驱动到NFS服务器上。
我曾使用这种计算方法识别了许多虚假的基准测试,其中包括以下吞吐量超过1 Gbit/s接口的情况:
- 120兆字节/秒
- 200兆字节/秒
- 350兆字节/秒
- 800兆字节/秒
- 1.15吉字节/秒
这些都是单向吞吐量。120兆字节/秒的结果可能是正常的,因为1 Gbit/s接口的速度应该达到大约119兆字节/秒。200兆字节/秒的结果只有在两个方向上都有大量流量并且求和后才可能出现;然而,这些是单向结果。350兆字节/秒及以上的结果都是虚假的。
当你收到一个基准测试结果来检查时,看看你可以对提供的数字进行哪些简单的求和来发现这种限制。
如果你可以访问系统,可能可以通过构建新的观察或实验来进一步测试结果。这可以遵循科学方法:你现在正在测试的问题是基准测试结果是否有效。从这个问题中,可以提出假设和预测,然后进行验证测试。
12.3.9 Statistical Analysis
统计分析是收集和研究基准数据的过程,它遵循三个阶段:
1. 选择基准工具、其配置以及捕获系统性能指标。
2. 执行基准测试,收集大量结果和指标的数据集。
3. 进行统计分析来解释数据,生成报告。
与在基准测试运行时分析系统的主动基准测试不同,统计分析侧重于分析结果。它也与被动基准测试不同,在被动基准测试中根本不进行分析。这种方法在访问大型系统可能受到时间限制和成本限制的环境中使用。例如,可能只有一个“最大配置”系统可用,但许多团队同时希望访问以运行测试,包括:
- 销售团队:在概念验证期间,运行模拟客户负载以展示最大配置系统能够提供的内容。
- 市场营销团队:为了获得市场营销活动的最佳数据。
- 技术支持团队:调查仅在最大配置系统下严重负载时出现的病理情况。
- 工程团队:测试新功能和代码更改的性能。
- 质量团队:执行非回归测试和认证。
每个团队可能只有有限的时间在系统上运行其基准测试,但在之后分析结果的时间可能更多。
由于收集指标的成本很高,要额外努力确保它们可靠且值得信赖,以避免在发现问题后不得不重新进行收集。除了技术上如何生成它们的检查之外,您还可以收集更多的统计属性,以便更早地发现问题。这些属性可能包括变异性统计数据、完整分布、误差范围等(请参阅第2章“方法论”中的第2.8节“统计”)。在为代码更改或非回归测试进行基准测试时,了解变异性和误差范围至关重要,以便理解一对结果的意义。
还要尽可能多地从运行系统中收集性能数据(而不会因收集开销而影响结果),以便随后对这些数据进行法证分析。数据收集可能包括使用sar(1)、第三方产品和自定义工具来转储所有可用的统计数据。例如,在Linux上,一个自定义shell脚本可以在运行之前和之后复制/proc统计文件的内容。可以包括尽可能多的内容,以防需要。此类脚本还可以在基准测试期间定期执行,前提是性能开销可接受。还可以使用其他统计工具来创建日志。
在基于Solaris的系统上,可以使用kstat -p来转储所有内核统计数据,可以在运行之前和之后以及定期记录。这种输出易于解析,并且可以导入到数据库中进行高级分析。
对结果和指标的统计分析可以包括可扩展性分析和排队理论,以将系统建模为队列网络。这些主题在第2章“方法论”中进行了介绍,并且是独立文本的主题([Jain 91],[Gunther 97],[Gunther 07])。
12.4 Benchmark Questions
如果供应商提供了基准测试结果,你可以提出一些问题来更好地理解并将其应用到你的环境中。目标是确定实际测量了什么以及结果的真实性或可重复性如何。最困难的问题可能是:我能重现这个结果吗?基准测试结果可能来自极端的硬件配置(例如,DRAM磁盘)、特殊情况的调整(例如,条带磁盘)、偶然的运气(不可重复),或者是测量误差。如果你能在自己的数据中心运行并进行自己的分析,就可以确定其中的任何一个:主动基准测试。然而,这会消耗大量的时间。以下是可能提出的一些其他问题:
一般问题:
- 被测试系统的配置是什么?
- 是测试了单个系统,还是集群系统的结果?
- 被测试系统的成本是多少?
- 基准测试客户端的配置是什么?
- 测试的持续时间是多久?
- 结果是平均值还是峰值?平均值是多少?
- 其他分布细节是什么(标准偏差、百分位数或完整的分布细节)?
- 基准测试的限制因素是什么?
- 操作成功/失败的比率是多少?
- 操作属性是什么?
- 选择操作属性是为了模拟工作负载吗?它们是如何选择的?
- 基准测试模拟了方差还是平均工作负载?
- 基准测试结果是否使用其他分析工具进行了确认?(提供屏幕截图)
- 基准测试结果是否可以用误差范围来表达?
- 基准测试结果是否可重现?
对于与CPU/内存相关的基准测试:
- 使用了什么处理器?
- 是否禁用了任何CPU?
- 安装了多少主存?类型是什么?
- 是否使用了任何自定义BIOS设置?
对于与存储相关的基准测试:
- 存储设备的配置是什么(使用了多少个,类型是什么,RAID配置是什么)?
- 文件系统配置是什么(使用了多少个,调整是什么)?
- 工作集大小是多少?
- 工作集缓存到了什么程度?在哪里缓存了?
- 访问了多少个文件?
对于与网络相关的基准测试:
- 网络配置是什么(使用了多少个接口,类型和配置是什么)?
- 调整了哪些TCP设置?
研究行业基准测试时,许多这些问题可能可以从披露的细节中得到答案。
13 Case Study
这一章是一个系统性能案例研究:讲述了一个真实世界性能问题的故事,从最初的报告到最终解决。这个特定的问题发生在一个生产环境的云计算环境中;我选择它作为系统性能分析的一个常规示例。
我在本章的目的不是引入新的技术内容,而是利用叙事来展示工具和方法如何在实践中应用,即在真实的工作环境中。这对于那些尚未处理过真实系统性能问题的初学者应该特别有用,它提供了一个跟踪专家如何处理这些问题的视角,评论了在分析过程中专家可能会考虑的事情,以及为什么会这样。这并不一定是记录最佳可能的方法,而是为什么采取了某种方法。
所有姓名已被更改以保护无辜者。与实际服务器、在线或离线的任何相似之处纯属巧合。
13.1 Case Study: The Red Whale
你有新邮件了!
嘿,Brendan,我知道我们在这里不断切换话题,但如果你明天有时间的话,能否看一下这个NiftyFy服务器?它可能与你对性能的一些现有发现一致。Nathan看了一下,但无法确定原因。
这是来自销售代表詹姆斯的一封电子邮件,他将帮助台工单复制并粘贴到了邮件中。我有点烦躁;我正在同时解决另外两个案例,不想被打扰。
我在Joyent工作,这是一个云计算提供商。虽然我在工程部门工作,但我也是我们支持和运营团队性能问题的最终升级点。客户问题可能与任何运行在SmartOS Zones上的应用程序或数据库,或者Linux或Windows的KVM实例有关。
我决定立即着手解决这个新问题,并花大约15分钟来查看,希望能找到一些快速的答案。如果看起来可能需要更长时间,我就需要将其优先级与我正在处理的其他案例进行比较。
第一步是阅读帮助台工单,了解问题陈述。
13.1.1 Problem Statement
问题描述了软件版本和配置,并评论了CPU使用率的变化性。客户最近才转移到Joyent SmartMachines(SmartOS Zones),惊讶地发现他们可以使用系统工具观察物理CPU,包括由所有租户组合引起的利用率。
我扫描了他们的描述,找出以下信息:
- 他们认为存在性能问题的原因是什么?
- 他们的问题(如果有的话)可以用延迟或运行时间来表达吗?
对第一个问题的回答将告诉我问题可能有多真实,我可以用第二个问题来自行检查问题。许多工单最终只是关于系统度量标准的混淆,而不是真正的应用程序问题,所以尽早验证这一点可以节省时间。然而,这两个问题的答案并不总是一开始就可用。
从客户描述中,我了解到他们正在使用一个叫做Redis的应用程序,并且:
- 使用traceroute(1M)命令来测试到服务器的网络路径和延迟,并且报告了数据包丢失。
- 有时Redis的延迟超过一秒。客户怀疑这两个发现之间有关联。然而,第一个细节让我觉得问题实际上并不是真实的:在这些系统上,traceroute(1M)默认使用UDP协议,这是允许不可靠的,因此网络基础设施可能会丢弃那些数据包以优先处理更重要的TCP数据包。如果他们使用的是基于TCP的测试,数据包丢失不应该发生或者是可以忽略的。
第二点是有用的——我可以测量的东西。
根据之前具有类似细节的案例,我可以猜测我的最终结论将是以下之一,甚至可以预测每种情况的可能性:
- 60%:traceroute(1M)丢包是一个误导,而一秒的Redis延迟实际上是由某种应用程序级别的原因引起的。
- 30%:traceroute(1M)丢包是一个误导。导致一秒Redis延迟的是完全不同的问题。
- 10%:traceroute(1M)丢包与问题相关——网络实际上正在丢包。
第一个,最有可能(60%)的结果是那种以“哦,是的,它应该是这样的”结束的类型。对于客户来说可能是新的,因为他们刚学习Redis,但对于Redis专家来说是显而易见的。
13.1.2 Support
工单历史记录包含Joyent支持团队如何分析问题的详细信息。当他们得知客户正在使用第三方监控工具来分析Redis性能时,他们要求访问该工具,并确认延迟有时会像报告的那样急剧上升。他们还尝试使用traceroute(1M)来重现数据包丢失,但未能成功。他们指出,源位置可能很重要,如果traceroute(1M)采用不同的网络路径,一些路径可能比其他路径不太可靠(这是一个很好的猜测)。他们尝试从不同位置进行测试,但仍无法重现数据包丢失。然后,运维团队的Nathan接手了。他设置了curl(1)来测量延迟,使用附近的主机作为客户端,以最小化涉及的网络组件。通过在循环中调用curl(1),他最终能够捕获到一次超过200毫秒的延迟,虽然不是预期的一秒,但仍远远超过正常水平,他在测试中发现正常水平不到1毫秒。换句话说:一个异常值。他还使用自己的临时清单快速检查系统。他发现CPU正常,有足够的空闲资源,并且网络I/O是适度的,但没有引起问题。由于几个原因,问题似乎越来越不可能是由网络数据包丢失引起的:首先,Nathan在同一数据中心使用附近的客户端进行了测试。要在200毫秒的异常值中导致数据包丢失,必须存在我们数据中心内交换机和路由器的问题——考虑到它们的可靠性,这似乎不太可能发生。200毫秒的延迟对于这些系统来说太短,不足以触发TCP重传。顺便说一下,有两个特定的延迟会提示“TCP重传!”:1.125秒和3.375秒。这些奇怪的数字是由于内核TCP代码的一个怪异部分(在illumos内核的tcp_init_values()中)略微增加了1秒和3秒的值。我们可能应该修复那段代码——过去它曾让客户感到困惑,这不是一件好事。另一方面,这些奇怪的数字通常很有用,它们的奇怪值很快提示出TCP重传:“我有这些3.4秒的异常值……”然而,在这种情况下,显然不是TCP重传引起了问题——200毫秒太短了。尽管这可能排除了TCP重传(除非对于我来说,它们的操作方式有未知的未知),但并未排除网络问题。Nathan的数据中心测试意味着网络问题不太可能发生,但我意识到它们仍然是可能的。
13.1.3 Getting Started
我给詹姆斯发了一条聊天消息,告诉他我会立即查看这个问题。詹姆斯告诉我他希望我做什么:目前,怀疑是Redis本身出了问题,而我们的服务器没问题。詹姆斯准备把问题退回给客户,但希望我再次确认系统是否正常,也许可以通过我最近开发并成功使用过的一些新的DTrace脚本来实现。像以前一样,我会把我的发现交给詹姆斯,他会处理与客户和支持部门的沟通,让我专注于解决问题。
我还没有完成阅读支持历史记录,但我登录到目标系统(SmartOS)尝试运行了一些命令,以防万一是一个显而易见的问题。我的第一个命令是tail /var/adm/messages,这是我做为系统管理员以来的一个有用的习惯,因为它可以立即发现某些问题。但没有显示出什么异常。
然后我选择了一个基于已提及的丢失网络数据包的统计命令来运行:netstat -s 1 | grep tcp。这从一个屏幕显示自启动以来的摘要值统计信息,然后每秒打印另一个屏幕。自启动以来的摘要值统计信息


我花了几秒钟时间,特别关注了tcpListenDrop、tcpListenDropQ0和tcpRetransSegs。这些速率看起来并不异常。我将命令保持在窗口中运行,显示每个间隔的摘要,同时继续阅读帮助台系统中的支持票(有好几页长)。我意识到我不知道是否应该立即看到问题。我问詹姆斯高延迟的Redis请求发生频率如何。他说:“一直都有。”这不是我想要的答案!我希望这个问题能更好地量化,以帮助理解不断变化的netstat输出。我应该每秒、每分钟还是每小时都能看到它们?詹姆斯不知道,但说他会回复我。我读完支持票后,同时打开了几个终端窗口并行登录到系统中,脑海中浮现出一些想法:
“这可能不是我时间的良好利用。Nathan是一位经验丰富的性能分析师,支持团队的其他成员似乎已经进行了合理的调查。这感觉有点像钓鱼——希望我的一些特殊DTrace工具能捕捉到另一个问题。我会花,比如说,15分钟认真查看系统,如果没有发现任何问题,我就会把它交还给詹姆斯。”
“另一方面,我将有机会在另一个真实的问题上使用这些DTrace工具,并进一步开发它们。我对TCP的可观察性有很多想法,这是一个实现的机会。然而,工具开发并不比我需要解决的其他客户问题更重要,所以这可能应该等待。”
“嗯,Redis到底是什么?”我对Redis实际上是什么一无所知。我以前听说过它,但不记得它是做什么的。它是应用服务器、数据库、负载均衡器吗?我感觉自己像个白痴。我想要知道它在高层次上是做什么的,作为我即将检查的各种统计数据的背景。
我首先使用ps(1)查看系统,看看Redis进程或其参数的某些细节是否会让我想起。我找到了一个名为“redis-server”的进程,但这并没有触动我的记忆。通过快速的互联网搜索Redis(谷歌),我在不到一分钟的时间内找到了答案(来自维基百科):Redis是一个键值存储,设计用于仅在主内存中快速运行。
现在,问题描述听起来更加严重:如果这是内存中的操作,什么样的性能问题会导致它有时需要超过一秒的时间?这让我想起了不寻常的内核调度器错误,其中线程可能被阻塞在可运行状态那么长时间。我可以再次对内核调度器进行DTrace,并找出问题所在,但这需要时间。我应该检查系统是否有包含这些修复的内核版本。
13.1.4 Choose Your Own Adventure
此时我可以采取几种不同的方向:
1. 研究netstat统计数据,其中大部分我尚未阅读。此时,netstat已经运行了几分钟,并打印了约10,000个单独的统计数据。它打印的数字比我能阅读的速度还要快。我可以花大约10分钟的时间尽可能多地阅读,希望找到进一步调查的线索。
2. 使用我的DTrace网络工具并进一步发展它们。我可以从内核中挑选出感兴趣的事件,包括重传和数据包丢弃,并打印相关的细节。这可能比阅读netstat更快,并且可能会暴露netstat统计数据未涵盖的领域。我还希望进一步开发这些工具,供其他客户使用,并公开分享。
3. 浏览错误数据库,寻找以前的内核调度程序问题,并查找已修复问题的内核版本,然后检查系统是否运行了具有这些修复的内核版本。我还可以使用DTrace来调查可能的新内核调度程序问题。这种问题曾经导致数据库查询耗时一秒钟。
4. 退一步,检查整个系统的健康状况,以排除任何瓶颈。这可以使用USE方法来完成,并且对关键组合只需几分钟。
5. 创建一个Redis的理论模型,使用排队理论,用于建模延迟与负载之间的关系:以确定由于等待队列的尾部而自然发生的一秒延迟的情况。这可能很有趣,但可能非常耗时。
6. 查找在线Redis错误数据库,并搜索已知的性能问题,特别是一秒延迟的问题。也许有一个社区论坛或IRC频道我可以提问。
7. 使用DTrace深入研究Redis的内部,从读取延迟开始,然后逐步深入。我可以使用DTrace的pid提供程序,将我的zfsslower.d风格脚本应用于跟踪Redis读取操作,这样我就可以提供延迟参数,并只跟踪慢于,比如说,500毫秒的读取操作。这将是深入研究的良好起点。
我没有考虑的一个路径是对Redis的负载进行特征化,以防一秒读取只是大型读取,并且应该预计需要那么长时间。例如,客户端可能开始偶尔进行1GB的大型读取,这将显示为客户端监控软件中的延迟峰值。我排除了这个可能性,因为Nathan已经使用curl(1)进行了测试,并发现延迟可能会随着正常大小的读取而增加。
我选择了USE方法。过去它已经被证明是性能问题的一个良好起点。这也将有助于詹姆斯向客户解释,我们认真对待这个问题,并且已经完成了我们自己的系统健康检查。
13.1.5 The USE Method
正如第二章方法论中介绍的那样,USE方法是一种检查系统健康状况、识别瓶颈和错误的方式。对于每个资源,我会检查三个指标:利用率、饱和度和错误。对于关键资源(CPU、内存、磁盘、网络),只需检查几十个指标,远远少于我目前从netstat(1M)获得的10,000个。
CPU
我运行了fmdump(1M)来查看是否有任何CPU错误,以立即排除这些可能性。结果没有发现任何错误。
然后我使用vmstat(1M)的列检查了系统范围的CPU利用率和饱和度,然后使用mpstat(1M)检查了每个CPU。它们看起来都很好:有足够的空闲余量,没有单个热点CPU。
如果客户达到了云强加的CPU限制,我会使用kstat(1M)检查他们的使用情况和限制。结果显示他们远低于限制值。
Memory
物理错误类型应该已经在之前的fmdump(1M)中显示出来了,所以我转向了利用率和饱和度。
我之前在调查系统范围的CPU使用率时已经运行了vmstat 1,并注意到系统范围内有大量的空闲主存储器和虚拟存储器,并且页面扫描器未运行(一种饱和度度量)。
我运行了vmstat -p 1来检查匿名分页,这可能是由于云强加的限制而发生,即使系统具有内存余量。匿名页进入列api 不为零!

当应用程序增长过大超出了主存储器(或限制)并已被分页到物理交换设备(或者,如Linux所称,已被交换出)时,会发生匿名页进入。然后,当应用程序需要时,必须读回一个内存页。这会增加显着的磁盘I/O延迟,而不仅仅是主存储器I/O延迟,并且可能严重影响应用程序性能。一秒钟的读取,甚至更糟,很可能是由于匿名页进入造成的。
单个指标通常不会确认性能问题(除了许多错误类型)。然而,匿名页进入是一个非常好的单个指标,几乎立即确认了问题。我仍然想要再次核实,并使用prstat -mLc检查每个线程的微状态(来自线程状态分析方法):

DFL(数据错误时间)的高百分比表明,某些秒内,Redis服务器线程大部分时间都在等待来自磁盘的这些页进入操作,这些操作通常应该从主存储器中提供服务。
检查内存限制:

虽然当前内存使用量(RSS)低于限制(CAP),但其他列显示的证据表明它们频繁地超出了限制:45,091次(NOVER),导致总共有974,165兆字节的数据被分页出去(POUT)。
这看起来像是一个常规的服务器配置错误案例,特别是由于客户刚刚将Redis迁移到这个云端。也许他们没有更新配置文件以将其大小限制在新的限制之内。我给詹姆斯发送了一条消息。
尽管内存问题很严重,但我还没有证明它是导致一秒延迟的问题。理想情况下,我会测量Redis读取时间,并将同步阻塞在DFL上的时间表达为这个比例。如果一秒钟的读取花费了99%的时间被DFL阻塞,我们就确认了读取速度慢的原因,然后可以检查Redis内存配置以找出根本原因。
在此之前,我想完成运行USE方法检查表。性能问题通常是多方面的。
磁盘
运行iostat -En未显示任何错误。运行iostat -xnz 1显示利用率很低(%b),并且没有饱和(等待)现象。
我让iostat(1M)运行一段时间来寻找变化,看到了一波写入操作:

对于ZFS,它将写入操作批量处理到事务组(TXGs)中,这种行为是正常的。应用程序文件系统I/O是异步进行的,通常不受繁忙磁盘的影响。但至少通常情况下如此。在某些情况下,应用程序I/O可能会在TXG上被阻塞。
这里看到的磁盘I/O可能并不是由Redis引起的,它可能来自系统上的另一个租户,特别是因为Redis是一个内存数据库。
网络
网络接口看起来良好;我使用netstat -i和nicstat检查它们:没有错误,利用率低,没有饱和。
13.1.6 Are We Done?
由于内存使用情况非常明显,并且需要回到其他工作,我将问题交给了詹姆斯:“看起来像是一个内存配置问题——它们被匿名页进入阻塞了。”我附上了屏幕截图。看起来这个问题毕竟很快就解决了。
稍后,詹姆斯转达了客户的消息:
“你确定这与内存有关吗?内存配置看起来没问题。”
“一秒钟的读取仍然在发生。”
“大约每5分钟发生一次”(回答了我之前的问题)。
确定吗?!如果客户和我在一起,我会努力不表现出愤怒。很明显存在严重的内存问题。你的API和高达98%的DFL——系统陷入了内存地狱。是的,我确定!
嗯,仔细想想……我确信存在严重的内存问题。但我实际上还没有证明这就是导致读取延迟的问题。在这项工作中发现多个问题并不罕见。可能还有另一个问题实际上导致了读取延迟,而这个内存分页问题只是一个误导?更像是一个误导性的巨大问题!客户提到大约每5分钟发生一次的评论也与内存问题不一致。早些时候我看过,DFL时间几乎每秒都在发生。这表明可能确实存在第二个问题。
13.1.7 Take 2
理想情况下,我想要一个工具,显示以下内容:
- Redis读取延迟
- 同步时间组件的细分,显示读取过程中大部分时间都花费在哪里
我会运行这个工具,找出那些慢的一秒钟读取,然后查看这些读取中最大的组成部分是什么。如果是内存问题,这个工具会显示大部分时间都花费在等待匿名页面加载上。
我可以开始浏览Redis在线文档,看看是否存在这样的工具。如果有的话,可能需要一些时间来学习它,并得到客户的许可来运行它。通常使用全局区域的DTrace只需花费一点时间进行只读查看。
DTrace需要测量Redis的读取延迟。在Redis DTrace提供程序出现之前,我必须自己制定技术,基于Redis内部的工作方式。问题是,我不知道Redis内部是如何工作的,不久前我甚至忘记了它是什么。这种内部知识通常只有Redis开发人员或专家才能随时掌握。
如何快速了解Redis?我想到了三种方法:
- 使用DTrace syscall提供程序检查系统调用,并尝试从中找出Redis读取延迟。通常有一些巧妙的方法来找到这样的信息,例如跟踪在套接字上的accept()到close()延迟,或者检查send()和recv()数据。这将取决于使用的系统调用。
- 使用DTrace pid提供程序检查Redis内部。这将需要跟踪Redis的内部,而我对此一无所知。我可以阅读源代码,但这将耗费时间。通常更快的方法是进行堆栈搜索:从服务客户端I/O的系统调用开始,并打印用户级堆栈(DTrace ustack()操作)以查看代码路径的继承关系。与成千上万行源代码相比,这使我能够一窥正在使用的实际功能,并且我只需研究这些功能。
- 使用DTrace pid提供程序检查Redis内部,但通过在97 Hz(例如使用DTrace profile提供程序)的速率下对用户级堆栈进行分析,而不是基于I/O。我可以获取这些数据并生成火焰图,以快速了解常见的代码路径。
13.1.8 The Basics
我决定先看看有哪些系统调用可用:

有很多gtime()、pollsys()和write()。pollsys()显示Redis没有使用事件端口,因为如果是这样的话,它会使用portfs()。这让我想起了一件事。另一位工程师之前遇到过这个问题,Redis的开发人员已经推出了修复方案,提高了性能。我告诉了詹姆斯这件事,尽管我记得事件端口提供了大约20%的性能改进,而我目前正在追查一个持续一秒钟的异常值。
一个单独的forksys()看起来很奇怪,但这样的不经常出现可能是监控行为(fork一个进程然后执行系统stat命令)。来自这个输出的fdstat()和fdsync()调用更加可疑。这通常是文件系统调用;我原以为Redis只在内存中运行。如果文件系统出现了,那么磁盘也就出现了,这肯定会导致高延迟。
13.1.9 Ignoring the Red Whale
为了确认磁盘是否起作用,并暂时忽略内存问题,我决定检查系统调用的文件系统类型。这些调用可能是对伪文件系统(如sockfs)的调用,而不是基于磁盘的文件系统,如ZFS。
为了确认它们可能会增加足够的延迟,使延迟累积到一秒钟,我还会测量它们的延迟。
我迅速编写了一些DTrace单行命令。其中包括以下内容:
统计写入(write())系统调用的文件系统类型,例如进程名为“redis-server”(系统上只有一个这样的进程):

测量所有系统调用的延迟,作为总和(纳秒):

第一段代码显示大部分时间写入是到“sockfs”,即网络上。有时确实是到“zfs”。
第二个单行命令显示,有时系统调用(如write()、fdsync()和poll())会有数百毫秒的延迟。poll()的延迟可能是正常的(等待工作——我需要检查文件描述符和用户级堆栈),但其他的,特别是fdsync(),就值得怀疑了。
13.1.10 Interrogating the Kernel
在这一点上,我运行了一系列快速的自定义DTrace单行命令,以回答关于内核的各种问题。这包括从系统调用层移动到VFS层,使用fbt提供程序进行跟踪,通过探针参数可以检查其他内核内部结构。
这很快演变成了以下单行命令,它已经开始变得足够长,可以转换成脚本:


它每15秒打印一些摘要信息。第一个显示了Redis使用的VFS级别调用,它们的延迟总和以纳秒计。在15秒的摘要中,fop_poll()只花了42毫秒,fop_write()花了9毫秒。第二个摘要显示了写入的文件系统类型——在这个时间段内,它们全都是“sockfs”,即网络。
大约每5分钟,以下情况发生了:

第一个时间间隔的输出显示了fop_write()时间的增加,在15秒的时间间隔内达到了317毫秒,同时还有2,981个zfs写入操作。第二个时间间隔显示了write()耗时493毫秒,fsync()耗时625毫秒。
确定正在被写入和同步的ZFS文件非常简单,我已经使用我最喜欢的一个DTrace脚本发现了它:

输出显示了许多128 K字节大小的写入到一个名为temp-10718.rdb的文件中。在它被删除之前,我设法对其运行了ls(1)命令,以查看其大小:

如果它对ls(1)来说存活时间太短,我可以使用DTrace跟踪文件信息。(我已经编写了一个脚本来做到这一点,叫做sollife.d;请参阅DTrace书的第5章[Gregg 11]。)
这些文件名包含dump和temp-。它们的大小超过了800兆字节,并且进行了fsync()。这听起来像是一个糟糕的主意。
13.1.11 Why?
写入一个超过800兆字节的临时文件,然后进行fsync()操作,加上合并的延迟时间超过一秒,听起来肯定可能是Redis延迟的原因之一。每5分钟一次的频率与客户的描述相匹配。在互联网上搜索到了由Didier Spezia [2]撰写的有关临时文件的以下解释:
RDB类似于内存的快照,写入到磁盘上。在BGSAVE操作期间,Redis会写入一个临时文件。一旦文件完成并进行了fsync(),它就会被重命名为真实的转储文件。因此,在转储期间发生崩溃时,现有文件永远不会被修改。所有最近的更改都会丢失,但文件本身始终是安全的,永远不会损坏。
我还了解到Redis可以fork()这个BGSAVE操作,以便在后台运行。我之前看到过一个forksys(),但没有进行检查。
Redis的维基百科页面提供了更多信息[3]:
持久性可以通过两种不同的方式实现:一种称为快照,是一种半持久性耐用模式,其中数据集不时地从内存异步地传输到磁盘上。从1.1版本开始,更安全的替代方案是一个附加的只写文件(日志),在内存中修改数据集的操作被处理时会被写入。Redis能够在后台重新编写附加文件,以避免日志的无限增长。
这表明行为可以发生戏剧性的变化,从一个转储到一个日志。检查Redis配置文件:

噢,原来是5分钟间隔的起源。
还有更多内容:

我通过詹姆斯把这个问题发送给了客户,但再次没有收到关于这个问题的回复。
13.1.12 Epilogue
在处理这个问题时,我发现了三个性能问题,并成功地向客户提供了可行的建议:
内存分页:重新配置应用程序以保持在内存限制内(这样可能会发现内存问题是由fork()和BGSAVE操作引起的)。
pollsys():升级Redis软件到使用事件端口的版本,以提高性能。
BGSAVE配置:Redis每5分钟对一个800多兆字节的文件调用fsync()以进行持久化,这很可能是异常值的原因,并且可以进行调优以表现出截然不同的行为。
我仍然感到惊讶的是,存在比内存分页更糟糕的问题。通常情况下,一旦我找到了那么多的DFL时间,客户就会找到并修复配置,然后我就不再收到回复了。我还与Joyent的其他工程师交谈过,以便我们能够及时了解性能问题。其中一位已经有了与Redis相关的经验,并表示:“这只是一个糟糕的配置。Redis应该用于服务小型对象存储——比如一个名称服务——而不是800兆字节的数据库。”
我之前60%的直觉是正确的:“噢,是的,它应该这样做。”我现在对下次遇到Redis时的细节了解更多了,也许到那时我将能够执行一些我之前的想法,包括编写一个脚本来跟踪Redis的读取时间并表达同步延迟的细分。
(更新:是的,我和Redis再次见面了,并且我编写了这些脚本:redislat.d用于总结Redis延迟,redisslower.d跟踪异常值。)
13.2 Comments
这个案例研究展示了我在性能调查过程中的思维过程,以及我通常如何应用我在之前章节中描述的工具和方法,以及我使用它们的顺序。它还描述了性能分析实践的一些额外特征,包括以下几点:
-起初对目标应用程序了解很少是正常的,但你可以迅速了解更多并培养专业知识。
-犯错、走错路,然后重新找到正确方向,在性能分析过程中属于常规。
-在找到问题之前发现多个问题也是很正常的。
而且所有这些都是在时间压力下发生的!对于初学者来说,当你研究性能问题时感到迷茫可能会让人泄气。这种感觉也是正常的:你会感到迷茫,你会犯错,你经常会错误判断。引用丹麦物理学家尼尔斯·玻尔的话:
一个专家是一个在非常狭窄的领域里犯过所有可能犯的错误的人。
通过像这样的故事告诉你,我希望让你放心,错误和走错路都是正常的(即使对于最优秀的人也是如此),并向你展示一些技术和方法来帮助你找到正确的方向。
13.3 Additional Information
要了解更多系统性能分析案例,可以查看公司的错误数据库(或工单系统)以了解以前的性能相关问题,以及你使用的应用程序和操作系统的公共错误数据库。这些问题通常以问题描述开始,以最终修复结束。许多错误数据库系统还包括带有时间戳的评论历史记录,可以研究以查看分析的进展,包括探索的假设和走错的路线。
有时会定期发布一些系统性能案例研究,例如在我的博客上。重点关注实践的技术期刊,例如ACM Queue,在描述解决问题的新技术解决方案时经常使用案例研究作为背景。