爬虫002-----urllib标准库
PS:蓝字是我的批注,可以就是瞎哔哔,也有可能是经验总结和实际遇到的问题整理,牛皮癣没跑了
PS:我实际只是一名点点点工程师,初学爬虫,有问题后续修改
1. 介绍
参见ChatGPT给出的标准介绍如下:叭叭叭☑️
urllib 是 Python 的一个标准库,主要用于处理 URL(统一资源定位符)相关的任务,例如访问网络资源、解析和处理 URL 等。urllib 模块可以方便地执行 HTTP 请求、处理响应以及处理一些 URL 操作。以下是 urllib 的一些常用模块和功能的简要介绍。
2. 官方文档
urllib接口好像并不是很多,参加下图,就读取、异常、解析URL、解析robots.txt,robot协议文件暂时可以扔一边,这样看常用接口就仨,感觉很爽 ♪٩(´ω`)و♪
- 官方文档地址:https://docs.python.org/zh-cn/3.11/library/urllib.html
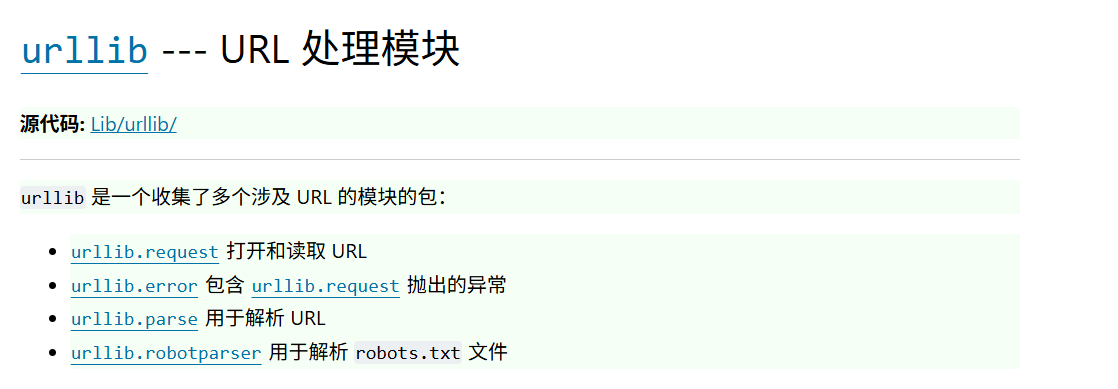
3. urllib常用模块和函数
使用之前需导包
import urllib.request
3.1 urllib.request
最常用接口了属于是,但为啥官方文档都推荐Requests库??看来还是因为接口太少,有些功能实现不了哈(我猜的)

3.1.1 urllib.request.openurl(url)
打开url,它可以是一个包含有效的、被正确编码的 URL 的字符串,或是一个 Request 对象。
import urllib.request# 定义一个url
url = "https://www.baidu.com"# 模拟浏览器发送请求
response = urllib.request.urlopen(url)# 获取响应中的源码并编码
content = response.read().decode("utf-8")# 打印出结果
print(content)
返回了我们一个网页的html,如果出现二进制乱码的话,记得加编码utf-8,就成中文了

可怜的百度啊,无论是测试还是爬虫,或者只要是与web相关的,感觉每每第一个压的就是他
3.1.2 六个方法
概括为1️⃣按字节读html;2️⃣按行读html;3️⃣全读html;4️⃣获取响应状态码;5️⃣获取请求url;6️⃣获取请求头(根据结果来看,请求头是按list嵌套tuple格式输出的)
import urllib.requesturl = 'https://www.baidu.com'
response = urllib.request.urlopen(url)# 方法1
content = response.read()
# 方法2
content = response.readline()
# 方法3
content = response.readlines()
# 方法4
content = response.getcode()
# 方法5
content = response.geturl()
# 方法6
content = response.getheaders()

3.1.3 urllib.request.urlretrieve(url, filename)
实现下载功能:包括图片、网页、文档、音频、视频、压缩文件等
- url: 请求url地址
- filename: 文件保存路径
官方文档显示将来可能会停用,但实际测试,目前还可继续使用,先用着吧,以后再换,而且requests库不香吗??
import urllib.request# 下载一个网页
url = "https://www.baidu.com"
urllib.request.urlretrieve(url, ./page/test.html)# 下载一个图片
url_img = "https://bj.bcebos.com/bjh-pixel/17069355091002918372_7_ainote_new.jpg"
urllib.request.urlretrieve(url_img, "./page/lise.png")
就可以完成下载了!!至于下载的图片是啥玩意?俺也不晓得🤣

3.1.4 urllib.request.Request(url, data=None, headers={}, method=None)
实现请求对象定制功能
- data: 发送的附加数据,比如post请求的参数(必须编码)
- headers: 请求头
- method: 请求方法,如get、post
3.1.4.1 发送get请求
import urllib.requesturl = "https://www.baidu.com"headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'
}# 请求对象定制
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
3.1.4.2 发送post请求
注意⚠️:urllib处理post请求,请求参数一定得进行编码!!!
import urllib.request
import urllib.parse
import jsonurl = 'https://fanyi.baidu.com/sug'headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'
}data = {"kw": "spider"
}# post请求进行参数编码
data = urllib.parse.urlencode(data).encode("utf-8")request = urllib.request.Request(url=url, data=data, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode("utf-8")
print(content)

spider: 十分精致的!!!比如说我以后的生活。。哈哈哈。。。
3.1.5 urllib.request.build_opener([handler, …])
handler处理器: 可以用于处理如 HTTP 请求、代理设置、身份验证、cookie 管理等不同的需求
3.1.5.1 添加handler三步骤
记住📒:handler重要仨参数hanlder、build_open、open
- 获取handler
handler = urllib.request.HTTPHandler() - 获取opener对象
opener = urllib.request.build_opener(handler) - 调用open方法
response = opener.open(request)
import urllib.requesturl = 'https://www.baidu.com'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'
}request = urllib.request.Request(url=url, headers=headers)# 获取handler对象
handler = urllib.request.HTTPHandler()
# 获取opener对象
opener = urllib.request.build_opener(handler)
# 调用open方法
response = opener.open(request)content = response.read().decode("utf-8")
3.1.6 代理&代理池
3.1.6.1 功能
- 突破自身的ip访问限制,访问国外的网站
- 访问一些单位和团体内部资源
- 提高访问速度
- 隐藏访问ip
国外?内部资源?真刑啊,我看刑,从入门到入狱
3.1.6.2 代理配置
- 创建Request对象
- 创建ProxyHandler对象
- 用handler对象创建opener对象
- 使用opener.open函数发送请求
3.1.6.3 urllib.request.ProxyHandler(proxies)
官方文档解释:让请求转往代理服务。 如果给出了 proxies,则它必须是一个将协议名称映射到代理 URL 的字典。 默认是从环境变量 <protocol>_proxy 中读取代理列表。 如果没有设置代理服务的环境变量,则在 Windows 环境下代理设置会从注册表的 Internet Settings 部分获取,而在 macOS 环境下代理信息会从 System Configuration Framework 获取。
官方文档真啰嗦!!就是将代理ip封装成proxies字典,然后访问url地址!如果是代理池,可以使用random函数随机调用ip进行访问呗!!!
import urllib.requesturl = 'http://www.baidu.com/s?wd=ip'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'
}request = urllib.request.Request(url=url, headers=headers)
# response = urllib.request.urlopen(request)# 代理ip地址
proxies = {'http': 'xxx.xxx.xxx:xxxx',
}
handler = urllib.request.ProxyHandler(proxies=proxies)
opener = urllib.request.build_opener(handler)
response = opener.open(request)content = response.read().decode('utf-8')
with open('ip.html','w', encoding='utf-8') as f:f.write(content)代理ip可以自己找或官网买,我没钱,买不起!!😬
3.2 urllib.parse
用于解析URL
目前用到他,好像只是做编码使用
3.2.1 urllib.parse.quote(string, safe=‘/’, encoding=None, errors=None)
使用 %xx 转义符替换 string 中的特殊字符。 字母、数字和 ‘_.-~’ 等字符一定不会被转码。 在默认情况下,此函数只对 URL 的路径部分进行转码。 可选的 safe 形参额外指定不应被转码的 ASCII 字符 — 其默认值为 ‘/’。
官方文档描述看不懂,但是一用就懂了
import urllib.request
import urllib.parse# 将周杰伦三个字变成unicode编码形式,为什么呢??见下面蓝字
name = urllib.parse.quote("周杰伦")url = "https://www.baidu.com/s?wd={0}".format(name)headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'
}request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
html = response.read().decode('utf-8')
解释文中注释👀:一般浏览器请求url见下图1,如果我们使用中文字符代入请求中,因为不识别就会报编码错误,见图2,所以使用qutoe会将中文转换成ASCII字符,这样浏览器就认识了,"周杰伦"字符串转码后打印结果见图三



3.2.2 urllib.parse.urlencode(query)
用于解析get携带多个参数或post编码使用
import urllib.request
import urllib.parsedata = {'wd': '周杰伦','sex': '男','location': '中国台湾省'
}
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'
}url_prase = urllib.parse.urlencode(data)# 转换后拼接进url字符串中
url = "https://www.baidu.com/s?{0}".format(url_parse)request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode("utf-8")
print(content)
如果是多个get参数,把参数写成字典的格式,使用urlencode解析后会将参数字典拼接成可识别的格式,如下图

import urllib.request
import urllib.parse
import jsonurl = 'https://fanyi.baidu.com/sug'headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36'
}data = {"kw": "spider"
}# post请求必须进行参数编码
data = urllib.parse.urlencode(data).encode('utf-8')# post请求参数不会拼接在url后面的,而是需要放到请求对象参数中
request = urllib.request.Request(url=url, data=data, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')obj = json.loads(content)
print(obj)
如果是post请求,则必须进行参数解码,再将解码后的参数放到请求对象中
所以说urllib用的少来着,就光编解码都这么麻烦,requests库就方便多了,还会自动解码
3.3 urllib.error
urllib抛出异常类
3.3.1 urllib.error.URLerror
URLError 是一个基本的错误类,它用于表示在处理 URL 时出现的错误。URLError 通常在以下情况下被引发:
- 无法打开 URL,可能是由于网络问题、DNS 解析失败、连接超时等原因。
- 指定的 URL 不存在或无法访问(例如,服务器未响应)。
3.3.2 urllib.error.HTTPerror
HTTPError 是 URLError 的子类,专门用于处理 HTTP 错误。当服务器能够提供有效的 HTTP 响应,但返回了一个错误状态码(例如,404、500 等)时,会引发 HTTPError。一般来说,HTTP 错误是基于 HTTP 协议返回的状态码。
举一个例子🌰:反正知道异常就这么用就可以
import urllib.request
import urllib.errorurl = "https://blog.csdn.net/m0_73953114/article/details/14817132800"headers = {"Cookie": 'uuid_tt_dd=10_6638100670-1736416797437-267407; fid=20_02271149362-1736416797905-842318; UserName=qxj2422640226; UserInfo=16cbea3709a74efb9d8fe45e222cbcc8; UserToken=16cbea3709a74efb9d8fe45e222cbcc8; UserNick=%EC%9A%B0%EB%A6%AC%E5%B8%85%E6%9D%B0; AU=354; UN=qxj2422640226; BT=1736416850895; p_uid=U010000; FCNEC=%5B%5B%22AKsRol-S0wYyMBdTPpG4dTb5cxRQYqUt3XzK4Rhw0TkspuSuKVQR7cn_JMbn25Q6gD6ZzGEvqN2Ap0zVtKbR6uCu3NcFlYESp_q_rSliufhsgZbkTPmLIxnsVkSGaOp5MdtYfpMmngfM3z_jMjm5-ZweLMETXqktDw%3D%3D%22%5D%5D; historyList-new=%5B%5D; csdn_newcert_qxj2422640226=1; redpack_close_time=1; c_dl_fref=https://so.csdn.net/so/search; c_segment=15; dc_sid=33ad97899d9db89d8e830ec2729ed411; Hm_lvt_6bcd52f51e9b3dce32bec4a3997715ac=1749871080,1750036870,1750145891,1750213250; HMACCOUNT=14F454179BE4E8D6; c_dl_prid=1750254119794_393004; c_dl_rid=1750254156140_467859; c_dl_fpage=/download/weixin_38604330/12865480; c_dl_um=distribute.pc_search_result.none-task-download-2%7Eall%7Efirst_rank_ecpm_v1%7Erank_v31_ecpm-10-85566228-null-null.142%5Ev102%5Epc_search_result_base4; c_utm_source=cknow_so_nontop_query; fe_request_id=1750384014632_3146_9804781; creative_btn_mp=3; _clck=tz4ahr%7C2%7Cfwx%7C0%7C1835; dc_session_id=10_1750407880259.635672; c_first_ref=default; ssxmod_itna=QqAxBDym3Yq4zrD2lmYi=D7YOph2Y=WxmqTPDsbHNDSxGKidDqxBnTlr9qTKwF4W8K68DDkiO0YxaHt+4rIxARipyqDHxY=DU=Beh5D4fKGwD0eG+DD4DWDmeHDnxAQDjxGpc2LkX=DEDYpcDDoDY86RDitD4qDBzrdDKqGgFuAxR06QDDXQ/QwdYr4De8iqcbrSmWUxQW4oFqDMAeGXUAF=1nFCuiNq1P9DrEQDzL7DtutS9wdox0PyBMUDghoK4k5KQBhdWODoQGett3QoQreseojx0i+iY0o+z753RDDAmYq3tr4xD===; ssxmod_itna2=QqAxBDym3Yq4zrD2lmYi=D7YOph2Y=WxmqqikvGQDlO8Dj4BDjWIeTKdidqYRnmChyDocUWqxrw+fO7O=KcD7qN5rE8186QogOq9Fdshcpxxbl9UwER1eG2tMtmR5u/5ZgLq/jvn1+r+f9gfDZf0Sen6i+qEMKQt2YQRyijbEKldDqR=C+qUMifdoYh2RGhDRQ8GFSoaesmemUAacfgbwznuUSlLrXQXGAjt0GeioembDxx273mW4EEisOLUQ1wmBfFkpggvNhQILnm=ERgRGn/tx5/9c1qUioeEi1wKMo4cMmfLdKbtI2NQ2dKhWAhP0hW32Gzg5rwPDdOoCsaEhw2YOfqjGWChwB8QZ3dbOzji3/+G7eFq7DIWK0B4fSCrhPn7HjB+3Ew8+GCi5gjIkudQddHudNds8LiOr4K2bwgQ2xCNEa2riqED2xzceO62m31LQA7imxTdCQlO=xwPMI==tUaTNk1axt5bpSgUNf3TqC3xi+roTkbBWLqafogeD7QCQPemK0Wm6CxcRGKV7FPEo5e4QDDjKDedq4D=; tfstk=g4JI47_loy4CKC68V6maCEt8lqBWVck4wusJm3eU29BLyzKA70XPLpR1P3LAa_KrxgL62n6yY8Se5TtWDHJezDY1VE-xxH8P8F6O4MaRv8FdXABHQByP82XW2EWSuqkq3HxhnT3quRzf7EWAqMF8zMBOWTS78bsFhHxhElqayjR9xuOVTPXReUBOBisCeMBRycNOYNed2JI8Wc_GW8IReMHTBiSLeaLRectOSgBRyUCKfhh5LVsiOwKIYdIT8foDFHQ_e8pKE6_bBNIGbd_POZCOm8KBCM1CkHpjGADcXdJ1g1rrROKD_eI1hvacACKfpg9oD7_5NpX12eM0cNpBVd1H_oyXf__B6pC_28KdewL2NegQtwde5sjO6uMcbE79xpdsqPKpuw6dX1kxchCJ_pfDLVeCHIxFLQLx7W7pGgIyE-7blYV7fs25fZosf7Vun2w8r5mSO4CdjGJqfcaQZ6IGfZosf7Vl9GjN_ci_R7f..; c-sidebar-collapse=0; c_ab_test=1; log_Id_click=3; c_utm_medium=distribute.pc_feed_blog_category.none-task-blog-classify_tag-1-148171328-null-null.nonecase; c_first_page=https%3A//blog.csdn.net/m0_73953114/article/details/148171328; c_dsid=11_1750407923739.336836; creativeSetApiNew=%7B%22toolbarImg%22%3A%22https%3A//i-operation.csdnimg.cn/images/cd1b1c49ffd24f5f99e0336910392b70.png%22%2C%22publishSuccessImg%22%3A%22https%3A//img-home.csdnimg.cn/images/20240229024608.png%22%2C%22articleNum%22%3A83%2C%22type%22%3A2%2C%22oldUser%22%3Atrue%2C%22useSeven%22%3Afalse%2C%22oldFullVersion%22%3Atrue%2C%22userName%22%3A%22qxj2422640226%22%7D; __gads=ID=d92c41b8fc959887:T=1736417616:RT=1750408764:S=ALNI_MYq9tsFz_UMKm-YS7gA5Es-NNV64w; __gpi=UID=00000fe13bf95651:T=1736417616:RT=1750408764:S=ALNI_MbJp3WmFc7aCI0ONvSvfPmyqZEYbA; __eoi=ID=b11a75ea396c8e40:T=1736417616:RT=1750408764:S=AA-AfjaQvgoqTZvabWep56jDN6cF; log_Id_pv=7; c_pref=https%3A//www.csdn.net/; c_ref=https%3A//blog.csdn.net/m0_73953114/article/details/148171328%3Fspm%3D1000.2115.3001.10526%26utm_medium%3Ddistribute.pc_feed_blog_category.none-task-blog-classify_tag-1-148171328-null-null.nonecase%26depth_1-utm_source%3Ddistribute.pc_feed_blog_category.none-task-blog-classify_tag-1-148171328-null-null.nonecase; c_page_id=default; _clsk=13n6xgq%7C1750408775584%7C6%7C0%7Cy.clarity.ms%2Fcollect; Hm_lpvt_6bcd52f51e9b3dce32bec4a3997715ac=1750408776; log_Id_view=287; dc_tos=sy5c5v',"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36"
}try:request = urllib.request.Request(url=url, headers=headers)resource = urllib.request.urlopen(request)htmp = resource.read().decode('utf-8')with open('test.html', 'w', encoding='utf-8') as f:f.write(htmp)
except urllib.error.HTTPError as e:print(e)
报了521错误,虽然我💗你,但此服务器不可达。。。你是永远是我到达不了的地方

PS:python标准库urllib这就结束了,最后一个robotparser接口没太大意义,直接结束掉吧🙅♂️。是不是炒鸡🐓简单呢???