Mysql
1 Sql编写
count(*) //是对行数目进行计数
count(column_name) //是对列中不为空的行进行计数
SELECT COUNT( DISTINCT id ) FROM tablename; //计算表中id不同的记录有多少条
SELECT DISTINCT id, type FROM tablename; //返回表中id与type同时不同的结果X.1 连表子查询
select后面的查询
"查询所有部门的员工个数":
# 以前的写法:使用inner内连接两个表,分组部门
select 部门表.部门,count(*)
from 员工表
inner join 部门表
on 员工表.部门id = 部门表.部门id
group by 部门表.部门# 子查询:select后面只能跟一行一列的数据
select 部门,(select count(*)from 表员工where 表员工.部门id = 表部门.部门id;
)
from 部门表;
from后面的查询
"查询每个部门的平均工资,部门id和部门名字":
select jo.*,(select 部门名字 # select后面的子查询不能多个列,只能一列且一行from 部门表where jo.部门id = 部门表.部门id #有筛选条件,就变成单个数据,没有where就变成一列是不对的,且slect只能查询一列
)
from (select 部门id,avg(工资) avgfrom 员工表group by 部门id
) jo
连接两个表的查询

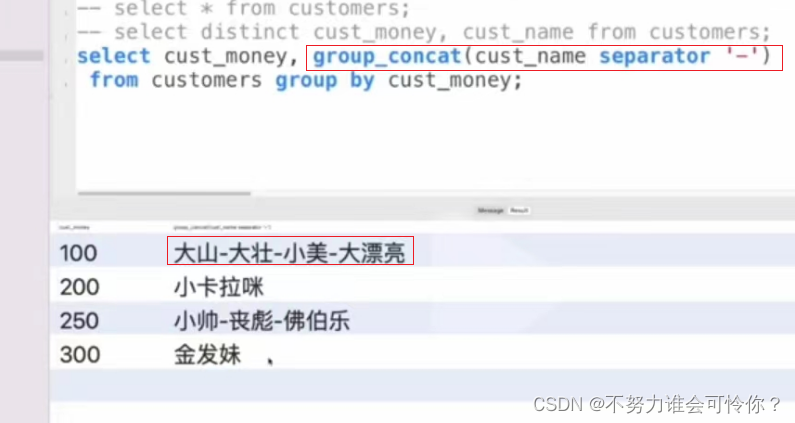
X.2 分组:group by
将具有相同字段值的数据归到一组,每组数据都会到聚合函数中去参与计算得到聚合结果。如max()、min()、sum()、AVG()、COUNT()。注意:select中的字段必须出现在group by后面,不然统计的字段没意义是随机取的,可以用group concat连接显示出这个分组下的所有字段即可。

用一条sql解决复杂的查询:多字段分组group by A,B,C,D将具有相同A和B和C和D字段值的数据归到一组,每组数据都会到聚合函数中去参与计算得到聚合结果。先查A表再查B表,然后关联(没有关联条件的可以建立关联条件),最后提取查询结果。
X.3 过滤:having
只有满足条件的分组才会被显示。没分组前可随便放,分组后必须紧随order by之后。


X.4 限制:limit
只取结果集中的x条记录,必须放在句尾。
limit 0查不到数据。
limit 10 = limit 0,10查询前10条数据。
limit 10,2从10的位置(不包含10)向后取2条数据即取到的数据是第11条和第12条。

X.5 排序:order by
排序的方法是先按第一个字段排序,如果有相同的再按后续的字段依次排序,如果字段不指明排序方式,默认是增序ASC(降序为DESC)。

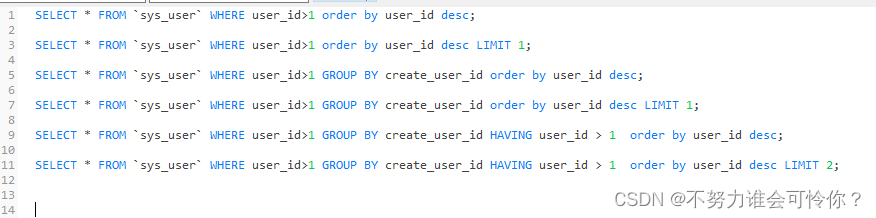
多字段order by 是先按第一个字段排序,如果有相同的再按后续的字段依次排序,如果字段不指明排序方式。

X.6 case when(相当于if-elseif-else)
①值映射
满足条件就返回值到select后面字段

②分情况统计
满足条件就返回值到sum中继续运算
X.8 子查询:in和exist
子查询数据量小用in,即in中的数据少。子查询数据量大用exist,即exist中数据量大。
in中有2个值,外层有3个数据,此时in中的数据会一个一个的到外层中找匹配的数据,即只需遍历2次,而如果外层为3个时要遍历3次。exist同理,小数据量的表驱动大表。
-- exists引导的子句有结果集返回,那么exists这个条件就算成立了,
-- 而返回的字段始终为1这个数字没有意义。
-- 所以exists子句不在乎返回什么,而是在乎是不是有结果集返回。select name from student where sex = 'm' and mark
exists(select 1 from grade where ...) X.9 结果集联合:union 和 union all
它们都是用于对多个select查询结果进行联合,性能高于in。
- union all是直接连接,取到得是所有值,记录可能有重复;union 是取唯一值,记录没有重复。所以union在进行表链接后会筛选掉重复的记录,union all不会去除重复记录。
- union将会按照字段的顺序进行排序;union all只是简单的将两个结果合并后就返回。从效率上说,union all 要比union快很多,所以,如果可以确认合并的两个结果集中不包含重复数据且不需要排序时的话,那么就使用union all。
- union 和 union all都可以将多个结果集合并,而不仅仅是两个,所以可将多个结果集串起来。
- 使用union和union all必须保证各个select 集合的结果有相同个数的列,并且每个列的类型是一样的。但列名则不一定需要相同,oracle会将第一个结果的列名作为结果集的列名。
SELECT * FROM `zl_customer_base` where wx_channel_id = '1001' union all SELECT * FROM `zl_customer_base` where wx_channel_id = '1004'union all SELECT * FROM `zl_customer_base` where wx_channel_id = '1008'union all SELECT * FROM `zl_customer_base` where wx_channel_id = '1001'
;X.10 数值函数
-- 获取序列号 = 前缀 + 年月日时分秒 + 随机数
-- 如:D202203231000000000
select CONCAT('D', CONCAT(DATE_FORMAT(now(), '%Y%m%d%h%i%s'), FLOOR((RAND()*1000))));获取整数
ceil(x):返回大于x的最小整数值。
floor(x) :返回小于x的最大整数值。
select ceil(28.55); -- 29select floor(28.55) -- 28四舍五入
round(x):返回最接近于参数x的整数,对参数x进行四舍五入。
round(x,y):返回最接近于参数x的数,其值保留到小数点后面的y位,若y为负值,则将保留x值到小数点左边y位。
select round(28.55) -- 29
select round(28.55,1), round(28.55,0), round(28.55,-1) -- 28.6 29 30截断
truncate(x,y):返回被舍去至小数点后y未的数字x。若y值为0则结果为整数。若y值为负数则截去x小数点左边起第y未开始后面所有低位的值。
SELECT truncate(28.55,1) ; -- 28.5
SELECT truncate(28.55,0) ; -- 28
SELECT truncate(28.55,-1) ; -- 20
SELECT truncate(2888.55,-3) ; -- 2000
取模
mod(x,y):返回x被y除后的余数。
SELECT mod(11,2); -- 1格式化
format(x,n):将数字x格式化,并以四舍五入的方式保留小数点后n位,结果以字符串的形式返回。若n为0则返回结果不含小数的部分。
select format(1234.5678, 2); -- 1234.57
select format(1234.5, 2); -- 1234.50
select format(1234.5678, 0); -- 1235X.11 字符函数
连接字符
concat(s1,s2,..):返回s1和s2连接后的结果,如果任何一个参数为null则返回值为null。
concat_ws(x,s1,s2,...):返回s1和s2连接后的结果,x是参数间的分隔符为null则返回null。
SELECT concat('b','c') ;
SELECT concat_ws('-','b','c') ;
大小写转换
select lower('STR'); -- str
select upper('str'); -- STR字符串长度
select length('_hello_'); -- 7删除空格
select ltrim(' hello '); -- 截去左边空格
select rtrim(' hello '); -- 截去右边空格
select trim(' hello '); -- 截去两边空格截取字符串
select substring('hello world', 1, 5); --hello
select substring('hello world', -3, 2); --rlselect left('hello world'); -- hello
select right('hello world'); -- world替换
select replace('hello world', 'world', 'mysql'); -- hello mysqlX.12 时间日期函数
-- 获取当前日期
select curdate(); -- 2022-08-10
select current_date(); -- 2022-08-10-- 获取当前时间
select curtime(); -- 08:03:42
select current_time(); -- 08:03:42-- 获取当前时间和日期
select now(); -- 2022-08-10 08:04:52
时间的加/减运算
DATE_SUB()
计算两日期时间之间相差的天数,秒数,分钟数,周数,小时数
返回日期或日期时间表达式datetime_expr1 和datetime_expr2the 之间的整数差。其中unit单位有如下几种:FRAC_SECOND表示间隔是毫秒、SECOND秒、MINUTE分钟、HOUR小时、DAY天、WEEK星期、MONTH月、QUARTER季度、YEAR年
-- 计算两日期之间相差多少周
select timestampdiff(week,'2011-09-30','2015-05-04');
-- 计算两日期之间相差多少天
select timestampdiff(day,'2011-09-30','2015-05-04');
select datediff('2017-02-01', '2017-01-01') -- 31
-- 计算两日期/时间之间相差的秒数
select timestampdiff(SECOND,'2011-09-30','2015-05-04');
-- 另外还可以使用 MySql 内置函数 UNIX_TIMESTAMP 实现,如下:
SELECT UNIX_TIMESTAMP(end_time) - UNIX_TIMESTAMP(start_time);时间日期格式化
select date_format('2017-02-01','%Y-%c-%e %h:%i:%s'); -- 2017-2-1 12:00:00 年月日 时分秒 
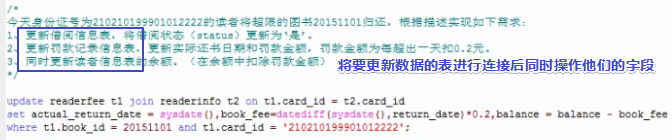
X.13 多表更新
先用多表连接的方式查出需要修改的数据,找到修改条件的规律即可。
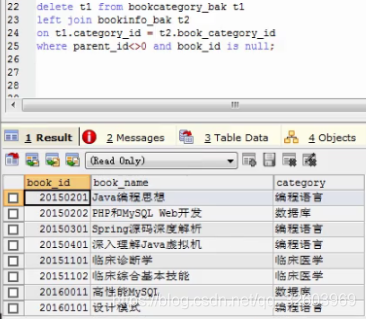
X.14 多表删除
先用多表连接的方式查出需要删除的数据,找到删除条件的规律即可。

找到删除条件后,写删除语句,最后把上面的多表连接趴下来,再加上删除条件即可。(删除t1表满足条件的行数据)
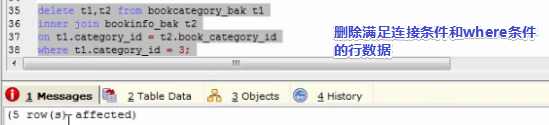
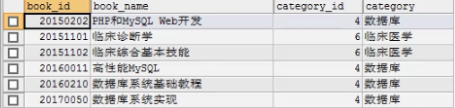
先用多表连接的方式查出需要删除的数据,找到删除条件的规律即可。(删除t1和t2表满足条件的行数据)
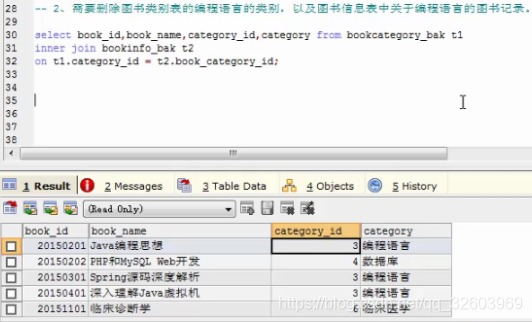
找到删除条件后,写删除语句,最后把上面的多表连接趴下来,再加上删除条件即可。
X.15 实际案例
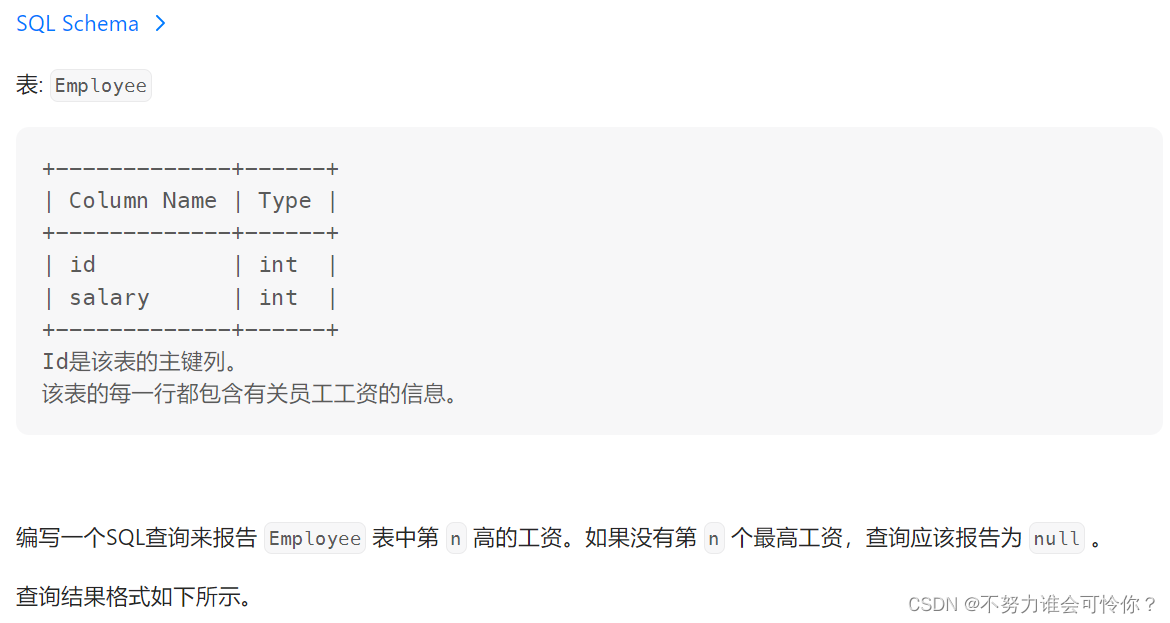
第N高的薪水
存储过程

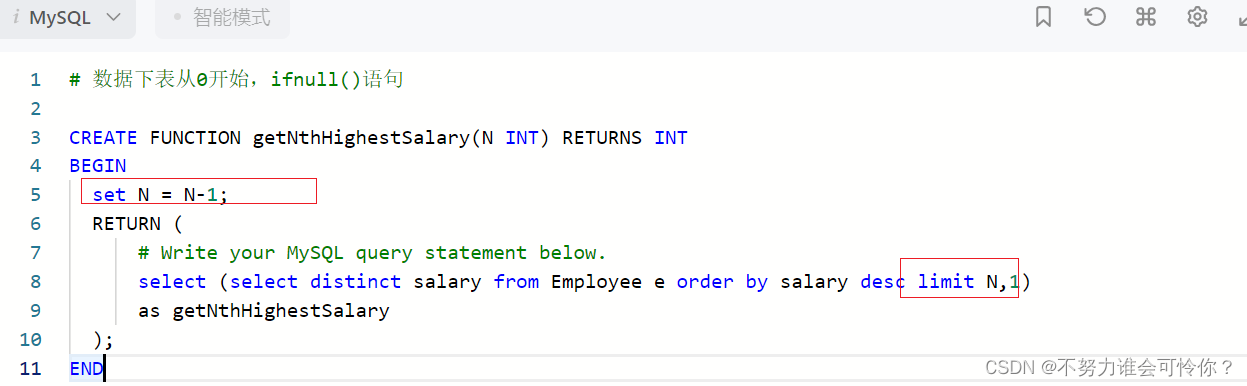 超过经理收入的员工
超过经理收入的员工
比较运算符后面的子查询

 查找重复的电子邮箱
查找重复的电子邮箱

 从不订购的客户
从不订购的客户

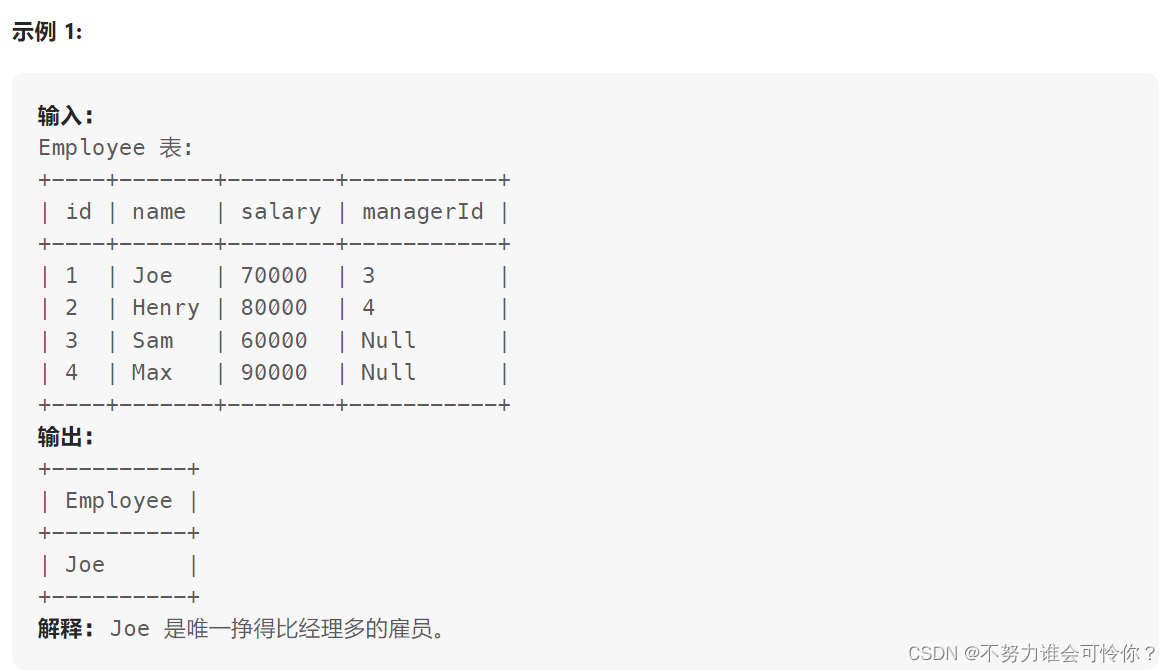
 删除重复的电子邮箱
删除重复的电子邮箱
自连接
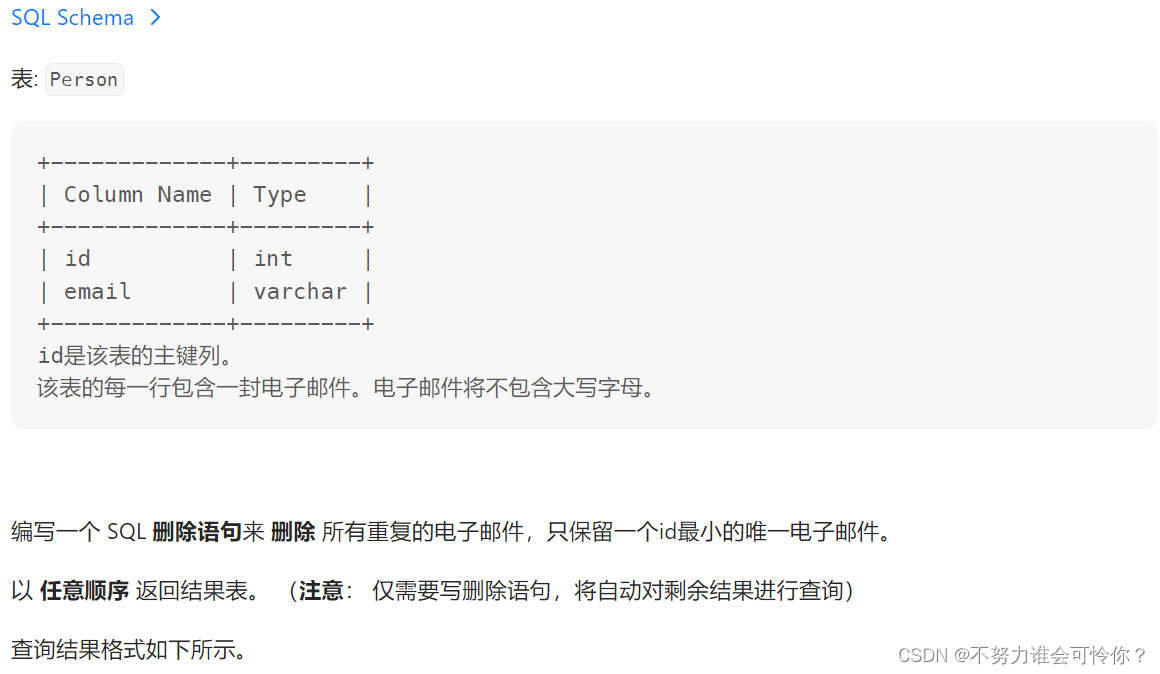

 上升的温度
上升的温度
date_add(日期字段, interval n u):n天数,u:单位

 游戏玩法分析 I
游戏玩法分析 I
min()函数
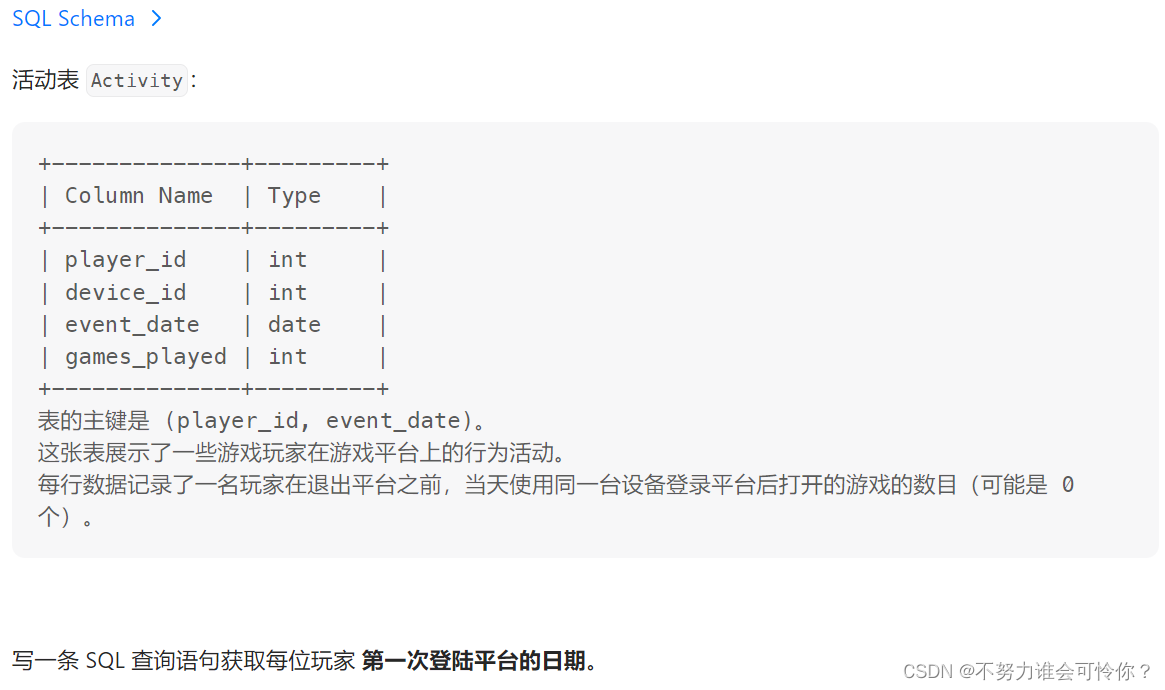
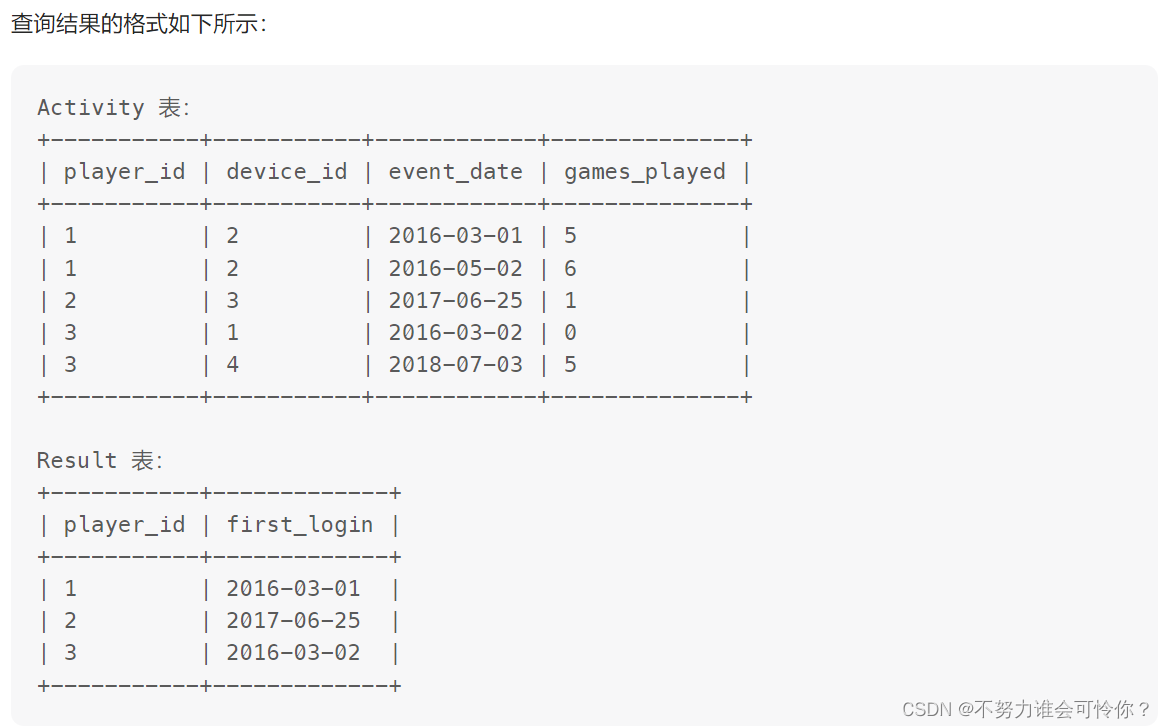
 订单最多的客户
订单最多的客户


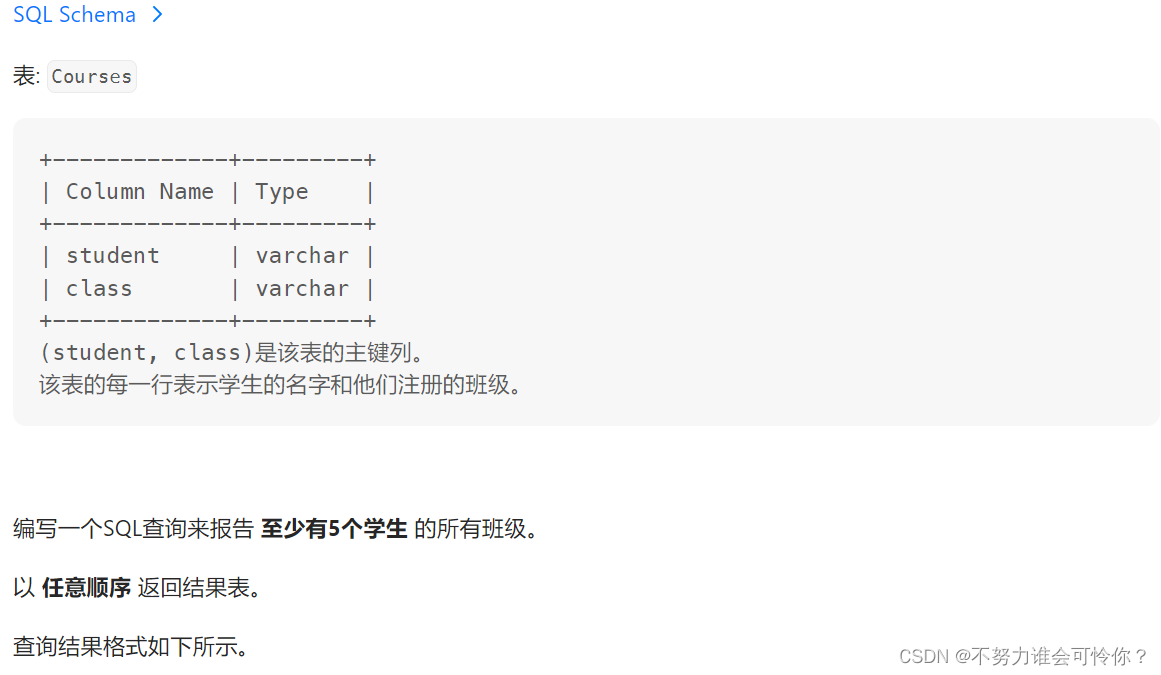
 超过5名学生的课
超过5名学生的课

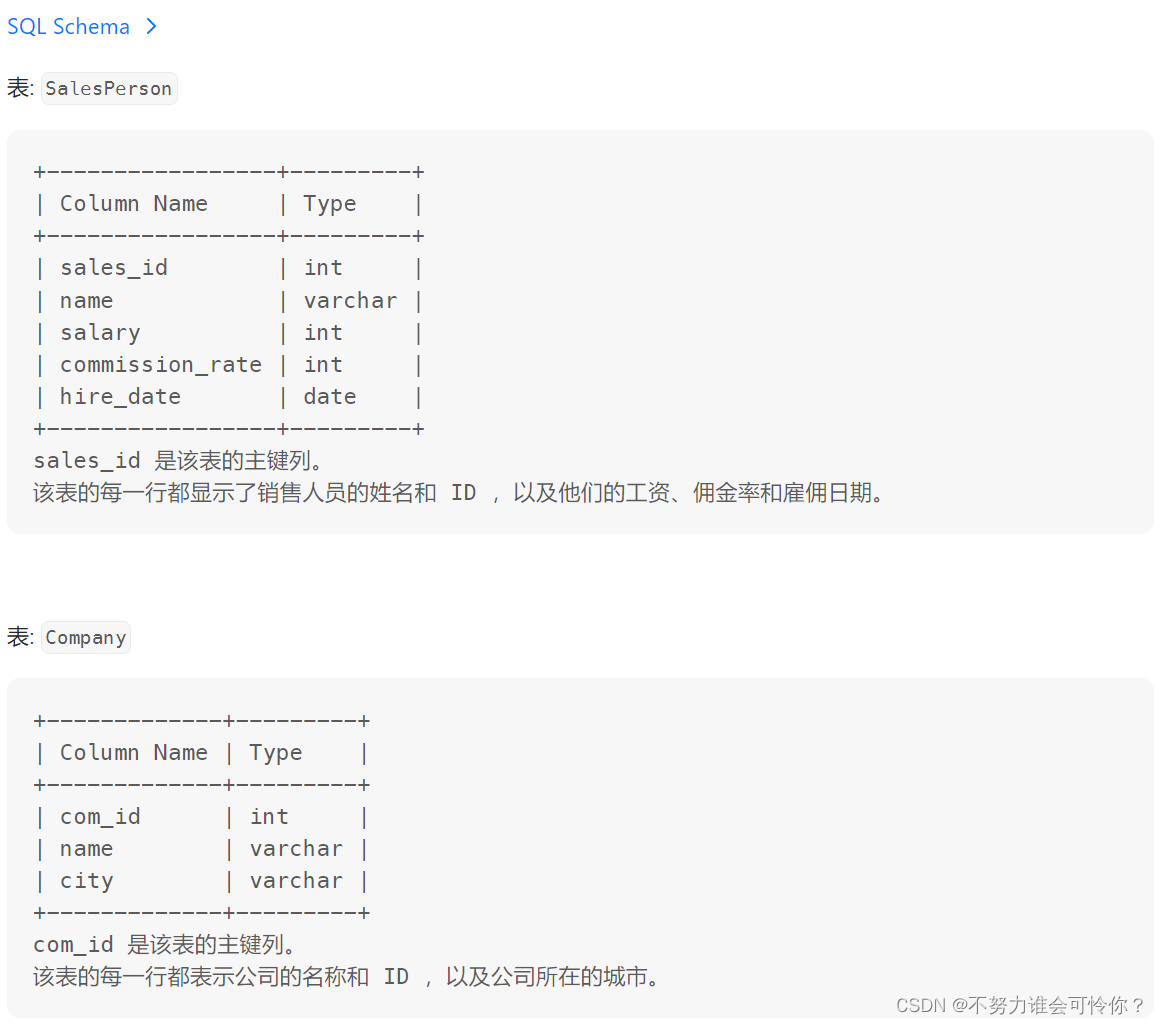
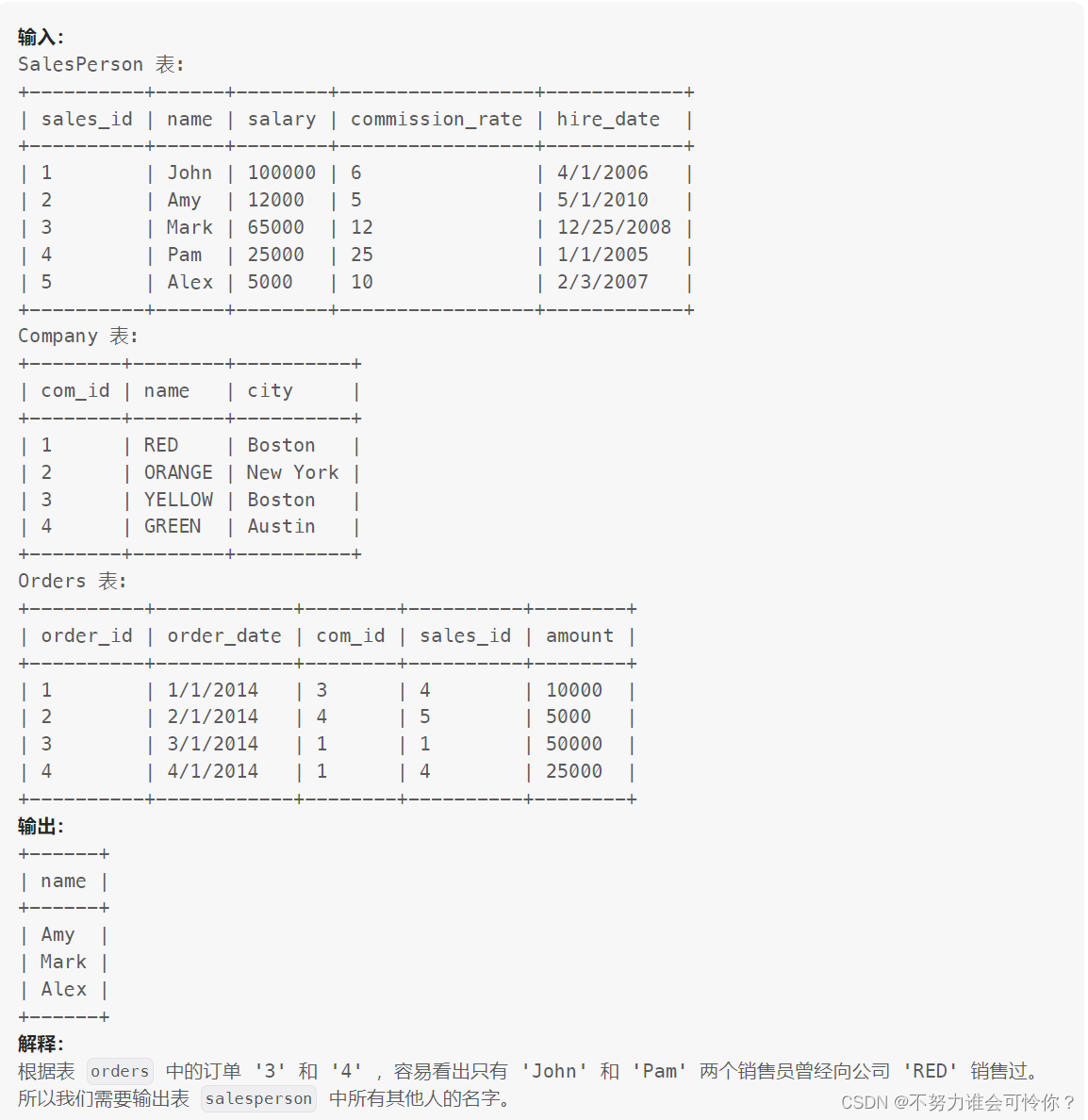
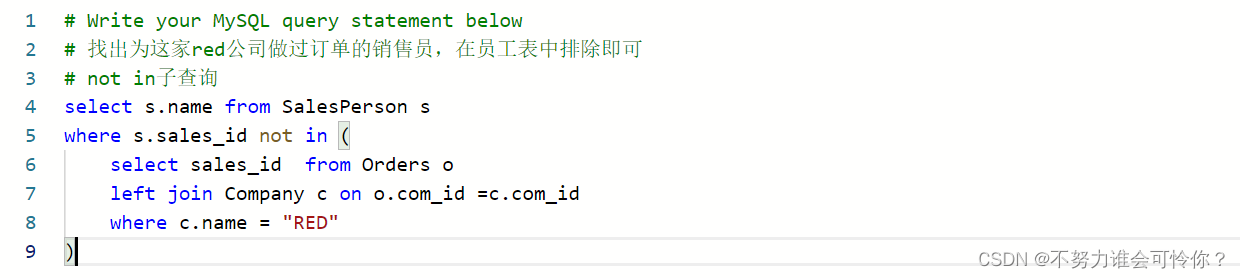
 销售员
销售员

变更性别
update语句中set后面的if语法


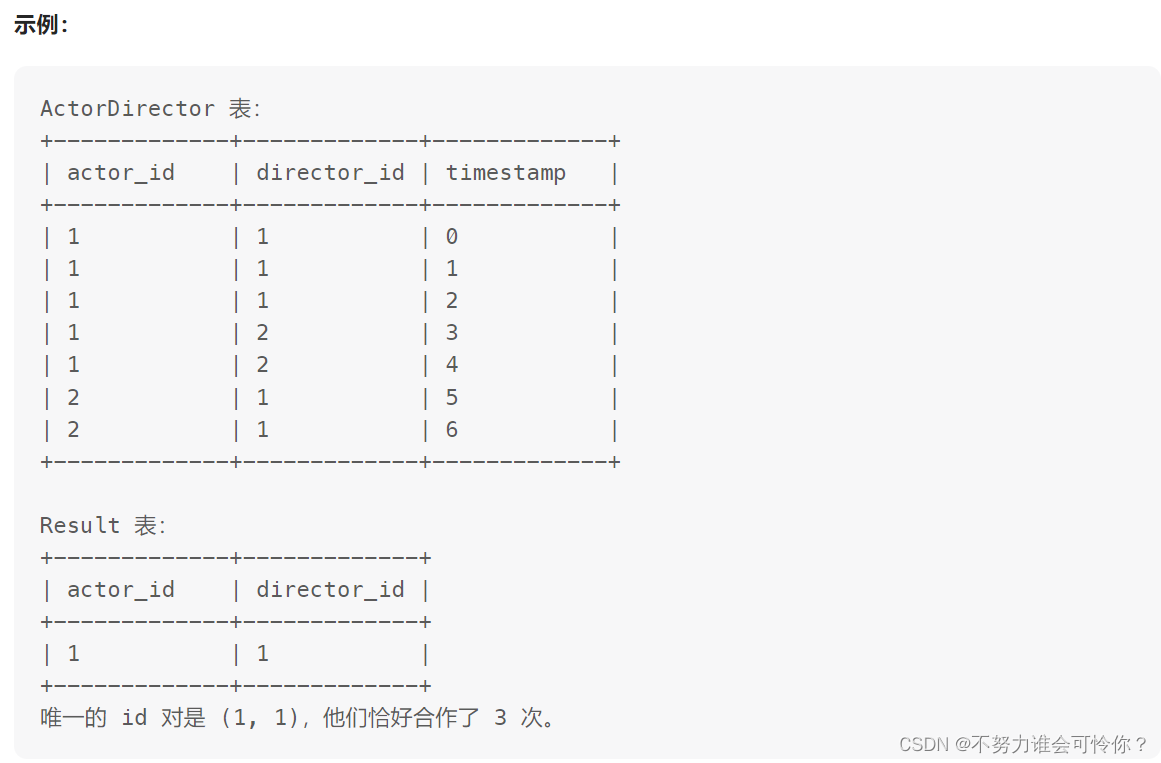
 合作过至少三次的演员和导演
合作过至少三次的演员和导演

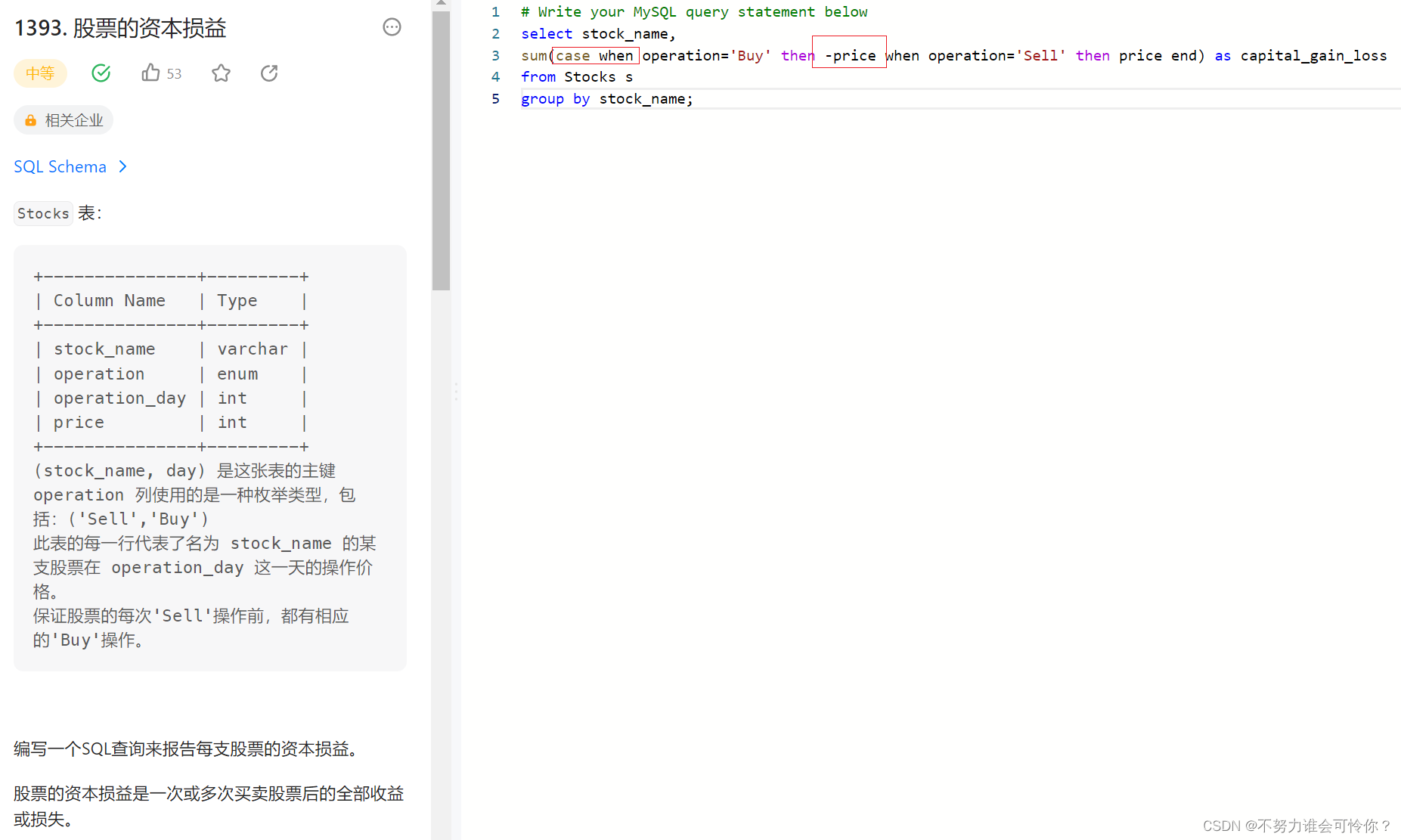
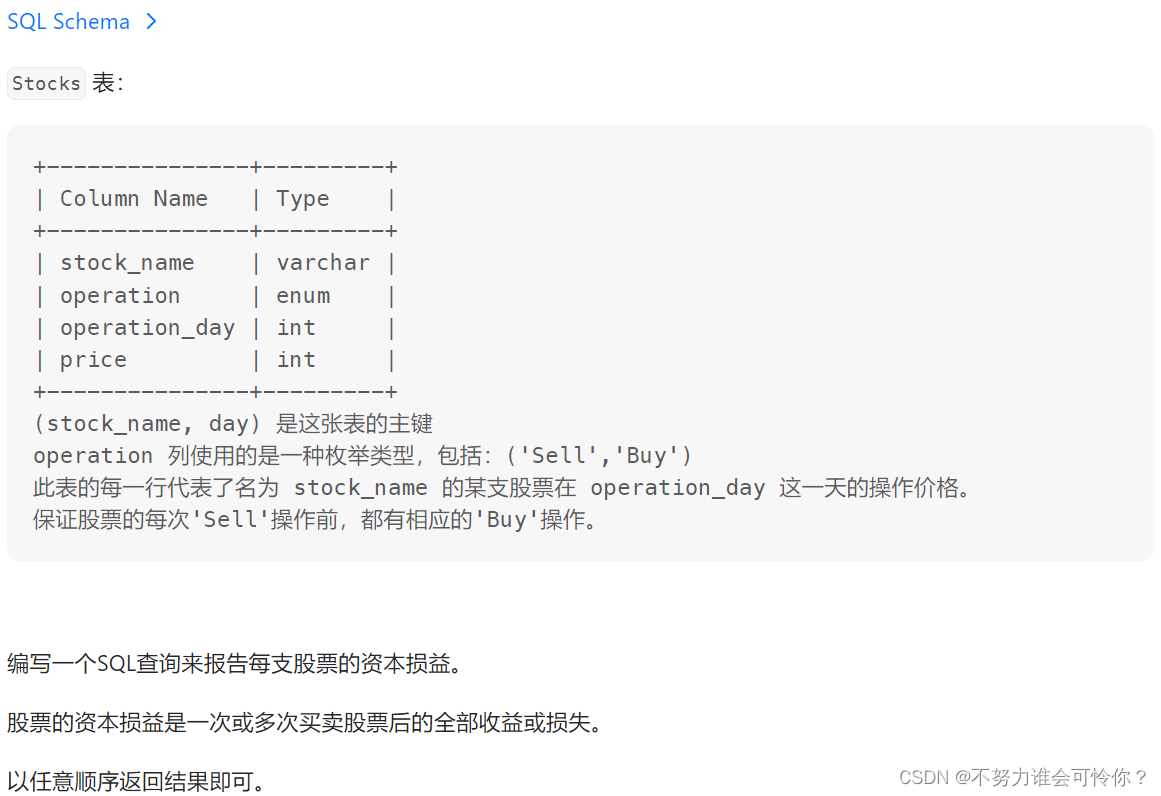
 股票的资本损益
股票的资本损益
case when

 销售分析III
销售分析III
having后面必须跟函数而不是字段,因为是分组过滤


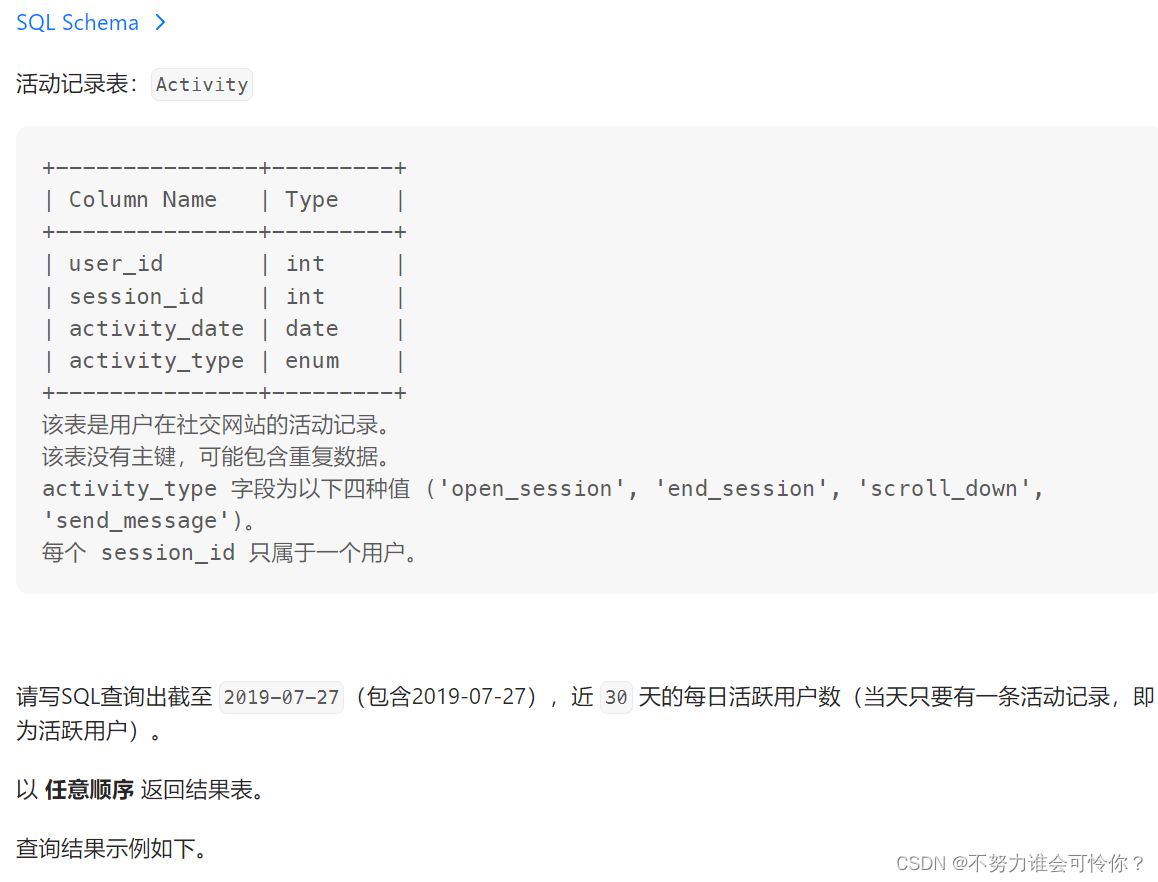
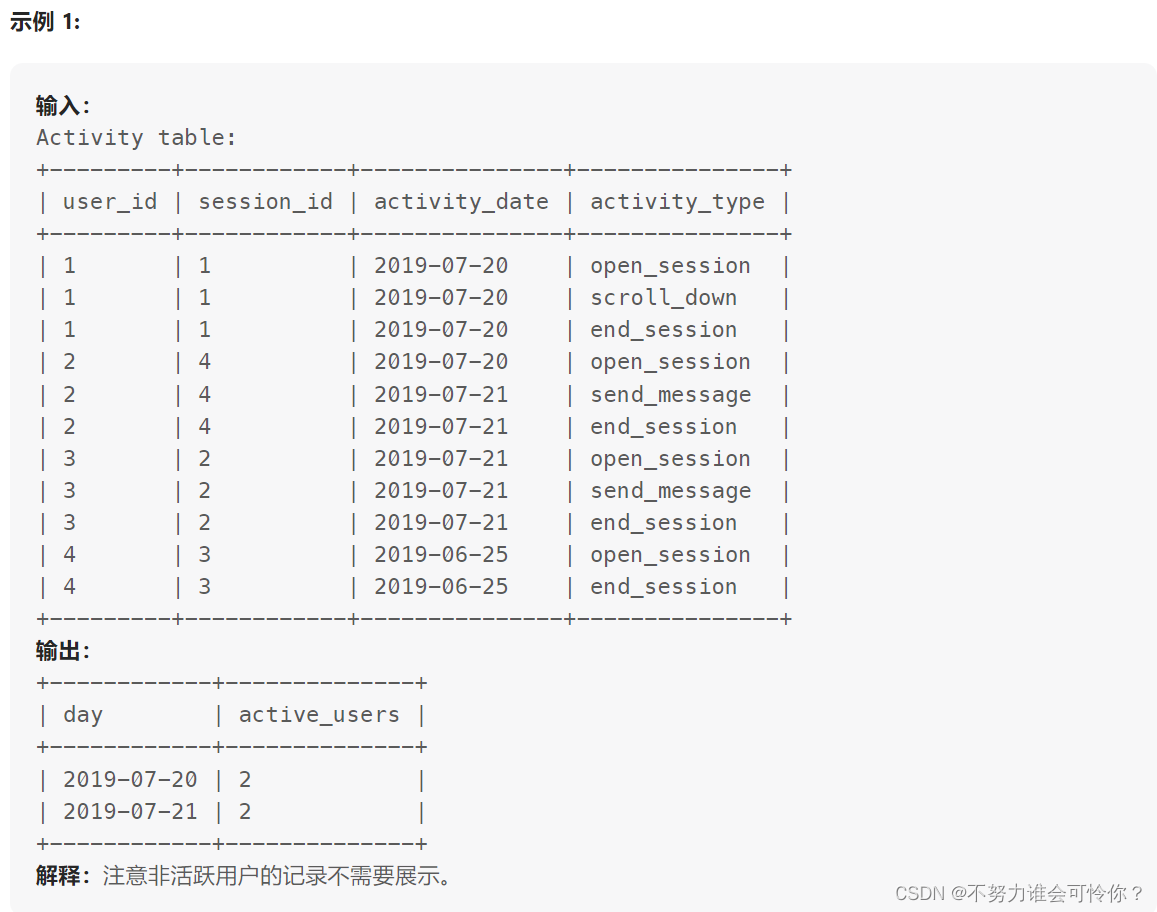
 查询近30天活跃用户数
查询近30天活跃用户数
datediff(a, b):计算a和b的相差天数
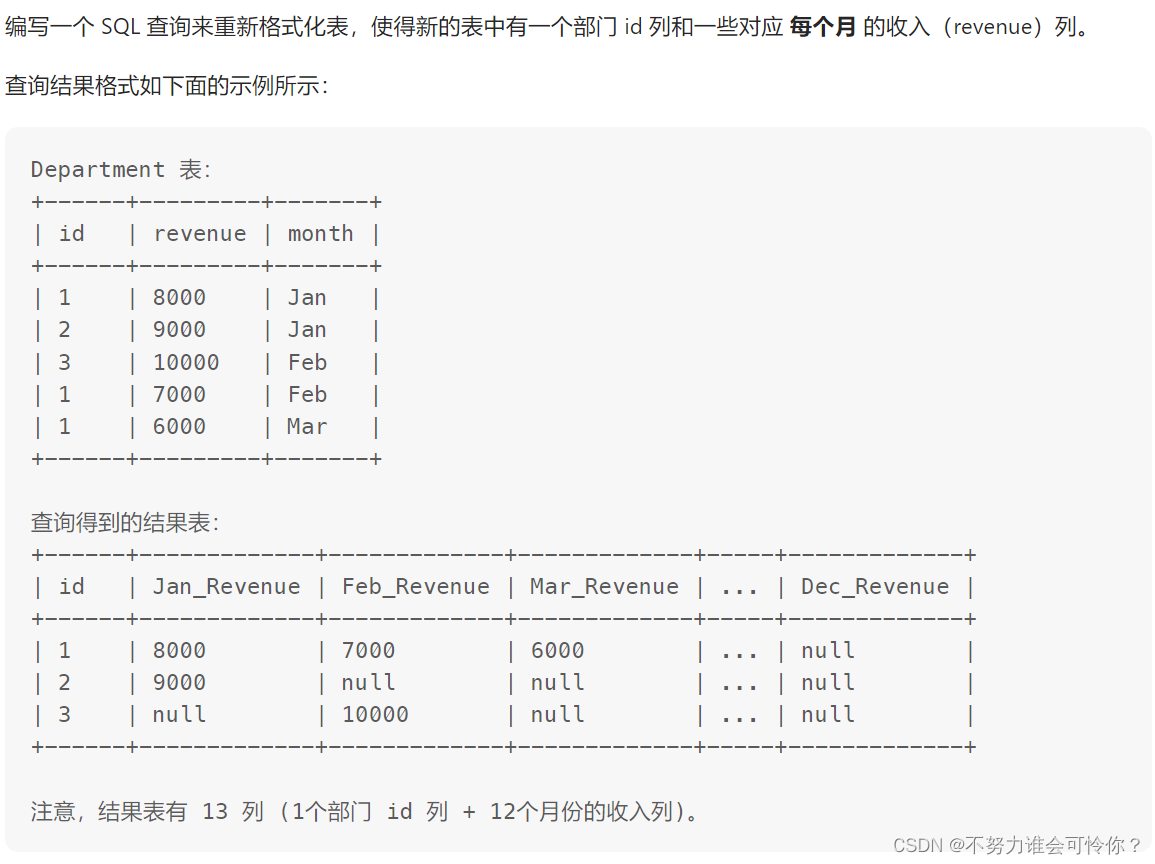
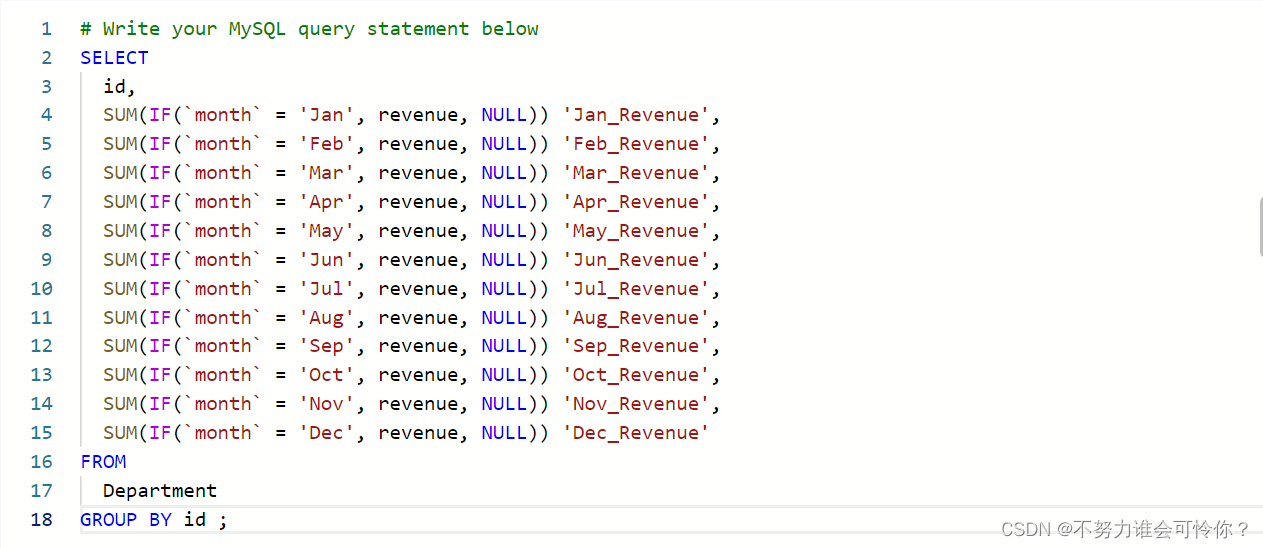
 重新格式化部门表
重新格式化部门表
if(a, b, c):如果满足a条件则返回b,否则返回c

 排名靠前的旅行者
排名靠前的旅行者
ifnull(a,b):如果a字段为nul则返回b
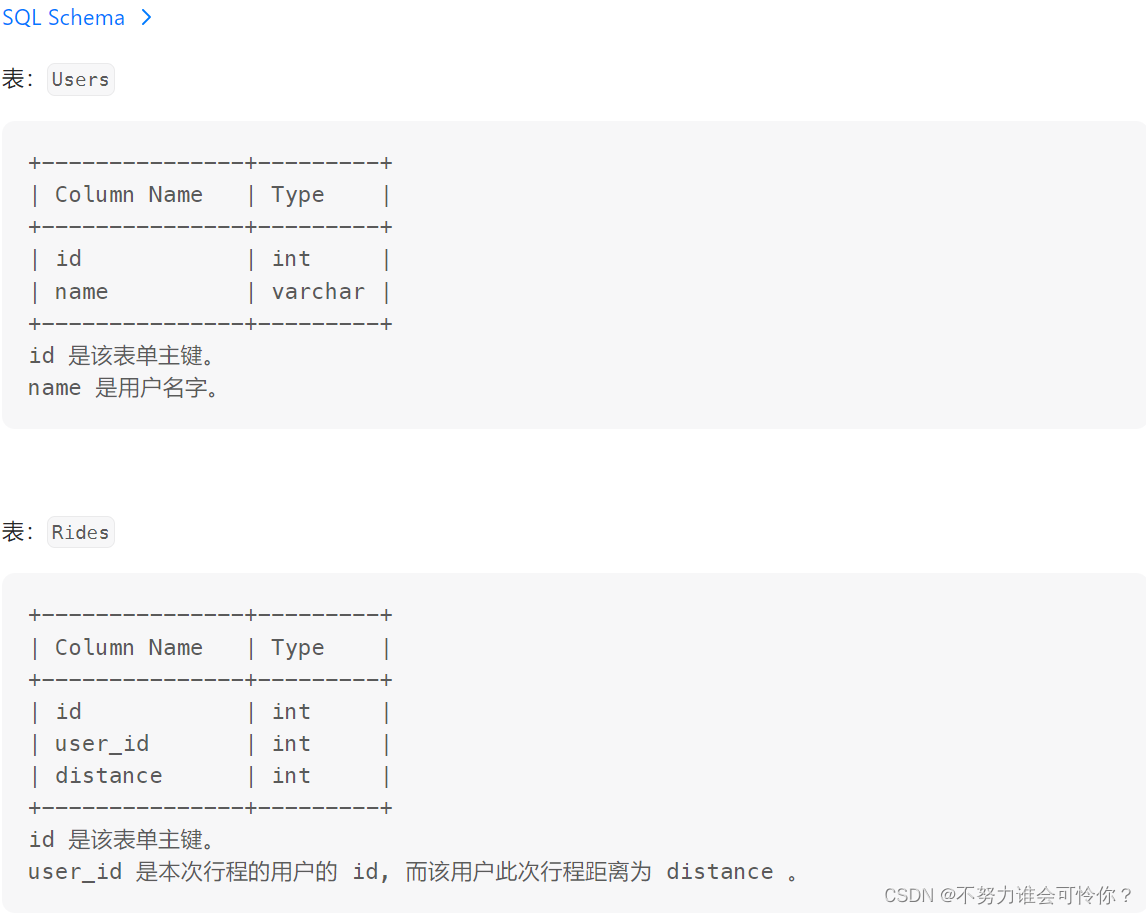
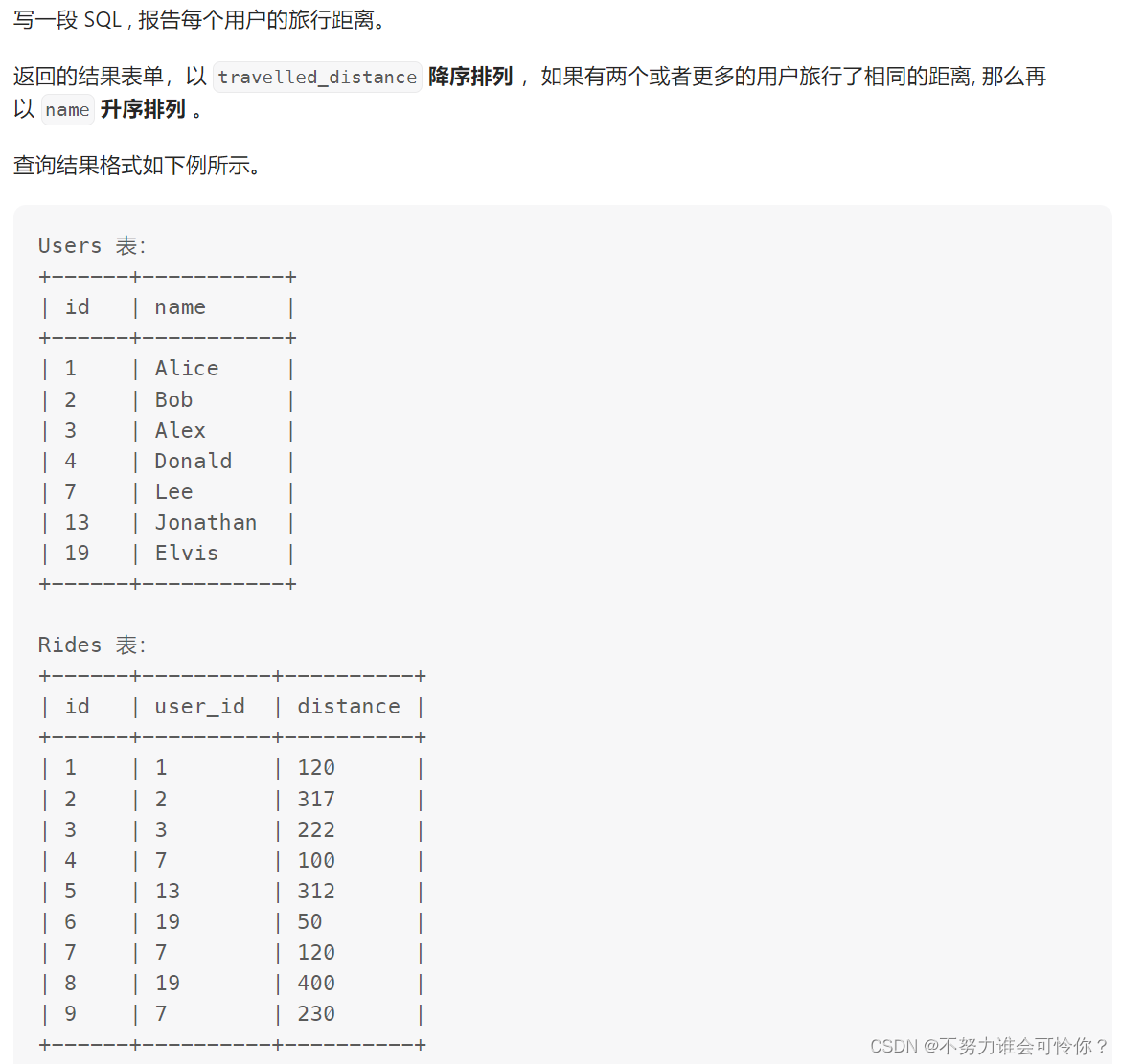


2 存储过程与存储函数
x.1 存储过程
删除存储过程

创建存储过程
案例1
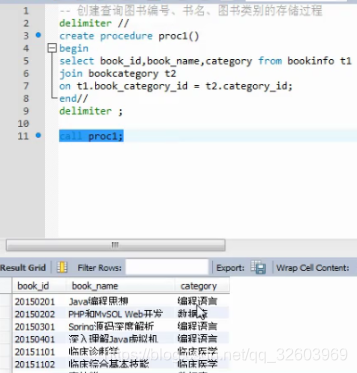
案例2
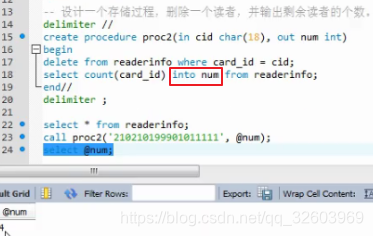
案例3
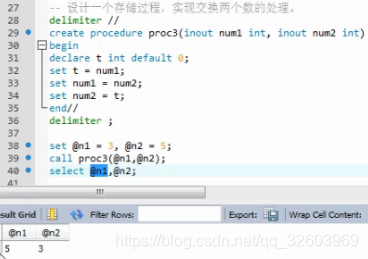
案例4

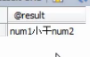
案例5
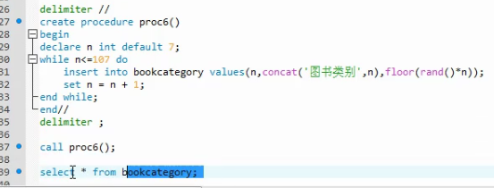
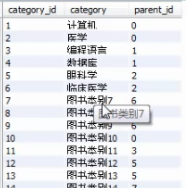
X.2 存储函数
删除存储函数
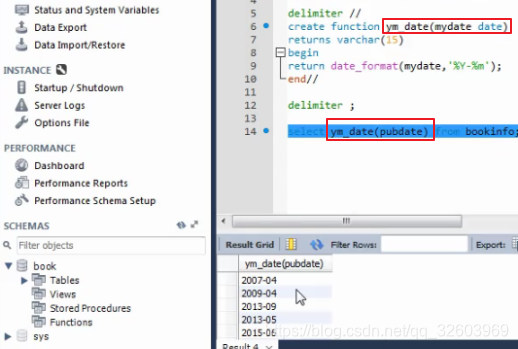
创建存储函数
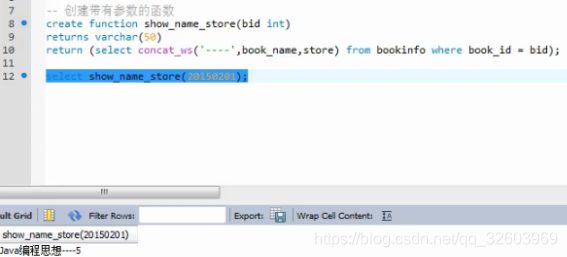
使用存储函数
X.3 存储函数/存储过程中的流程控制语句
if
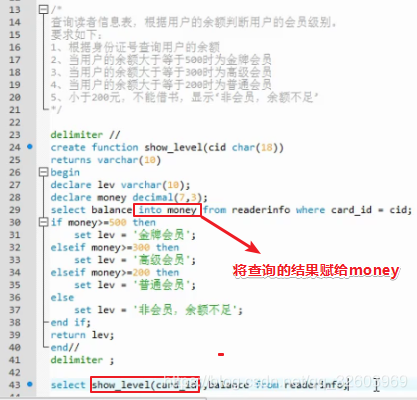
case
写法一

写法二
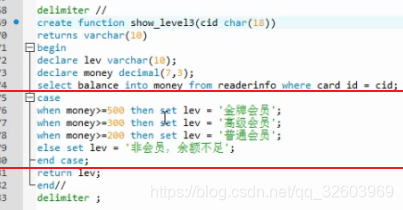
while
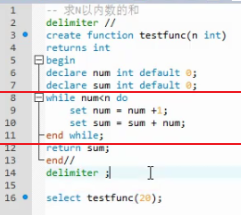
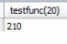
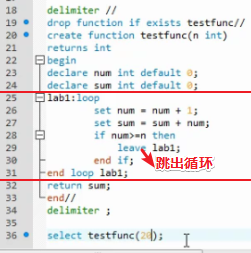
loop
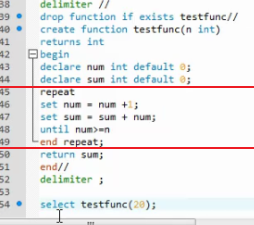
repeat
X.4 存储过程和存储函数区别?
功能:

语法:
存储过程使用procedure创建,使用call调用;存储函数使用function创建,可以嵌入select语句中执行。
存储过程的参数类型有in/out/inout;存储函数只有一种类似于in参数,调用时需要按照指定参数类型传值即可;
存储过程可以有多个返回值,也可以没有返回值;存储函数必须有返回值,而且只能有一个返回值。
3 Sql优化
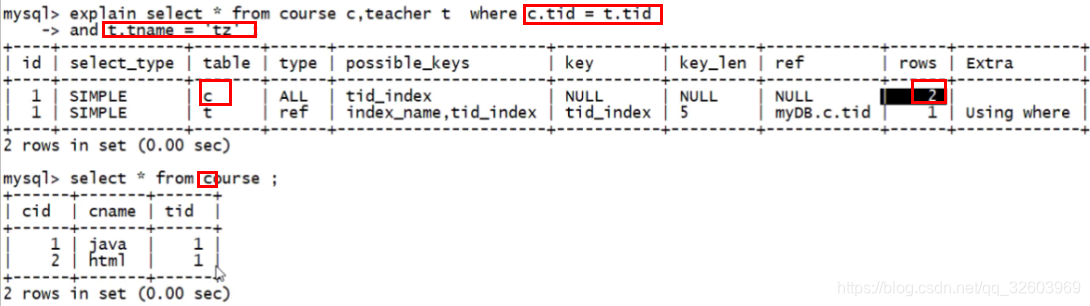
X.1 explain解释
id(编号)


结论1:id相同,从上往下顺序执行,优先执行数据条数少的表。



结论2:id值不同,id值越大越优先查询(本质:在嵌套子查询时,先查内层 再查外层)

结论3:id值有相同又有不同,id值越大越优先,id值相同从上往下顺序执行。
select_type(查询类型)
左衍右连

a.
b.
type(优化级别)
system > const > eq_ref > ref > range > index > all 要对type进行优化的前提是有索引。
(1)system(1、只有一条数据的系统表;2、衍生表只有一条数据的主查询)


(2)const(用主键当查询条件即查询到的结果只有一条匹配的数据,称之为const级别)
create table test01(id int,name char(4));
insert into test01(1,'a');
alter table test01 add primary key(id);
explain select id from test01 where id = 1;
(3)eq_ref(给一个表加上主键,给另一个表的外键加上唯一约束,将唯一约束的每个字段当做查询条件和加上主键的那个表进行数据查询匹配,并且满足有且只有一条数据与它配对,并且每个唯一约束了的字段都能找到与之配对的那条数据,此时叫eq_ref级别)


(4)ref(给该表的某个字段添加普通索引,利用普通索引字段当查询条件,去查该表字段,得到0条或多条数据就是ref级别)

![]()

(3)和(4)的区别总结:都是利用约束去查询;前者查询结果必须有且只有一条数据与添加了约束的字段对应;后者查询结果可以有一条或多条或没有数据与之对应。
(5)range(检索指定范围的行)



(6)index(只扫描索引列的所有数据)


(7)all(查询全表的每一列数据)


possible_keys and key(预测用到的索引和实际用到的索引)

key_len(用于判断复合索引是否完全使用)
char


varchar

ref(表之间的引用)

rows(实际通过索引而查询到的数据个数)

extra(额外信息)
- where哪个索引列字段就oder by哪个索引列字段;
- 复合索引时不要跨列或无序使用;(where __ order by __ 。__处要连续才不会报using filesort。)
- using filesort(排序)
- using temportary(使用了零时表查询,分组)
- using where(回表查询)
- using index(使用索引查询)
- impossible where(where条件不满足)
 a1和a2是复合索
a1和a2是复合索
X.2 索引优化
mysql的索引存储结构分b+树和hash,默认用b+树的结构来对数据索引存储。
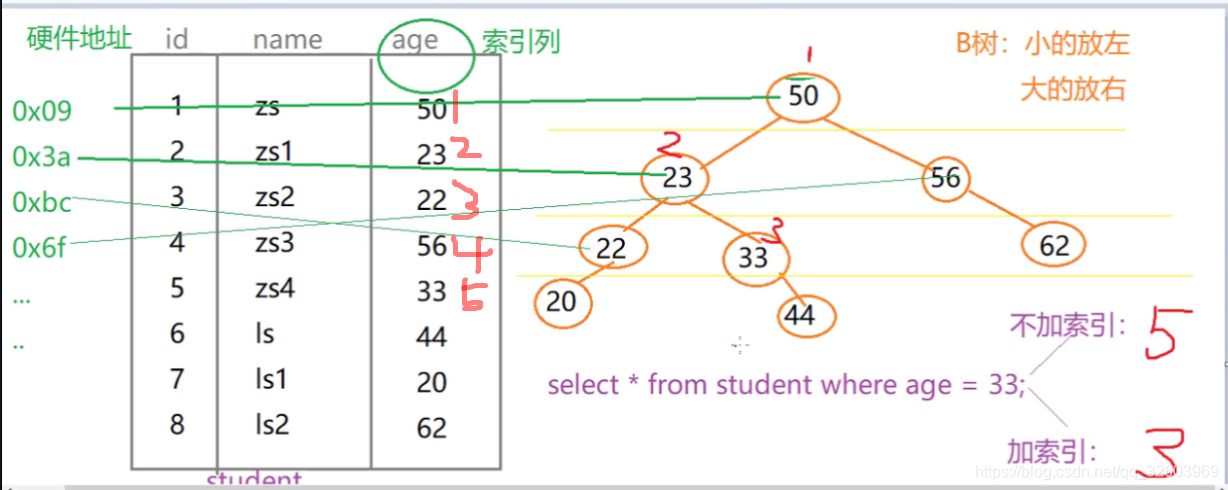

索引命名
- 主键索引:pk_字段名, 即primary key;
- 唯一索引:uk_字段名,即 unique key;
- 单值索引:idx_字段名;
- 联合索引:idx_表名_字段名;
- 集聚索引(别名聚族索引):主键和数据放在同一个节点上,如innodb引擎。
- 非集聚索引(别名非聚族索引):主键和数据放在不同节点上,如mysam引擎。
四大索引的增、删、查
单值、复合、唯一、主键



主键索引 与唯一索引区别:主键索引和唯一索引一样不能重复,只是主键索引不能用null,而唯一索引可以为null。
慢查询优化
(1).加联合索引
例如:联合索引的字段为:abc
有效:a、ab、abc、ac(用and连接),其中ab用or连接会导致索引失效;
无效:b、bc、c(用and连接);
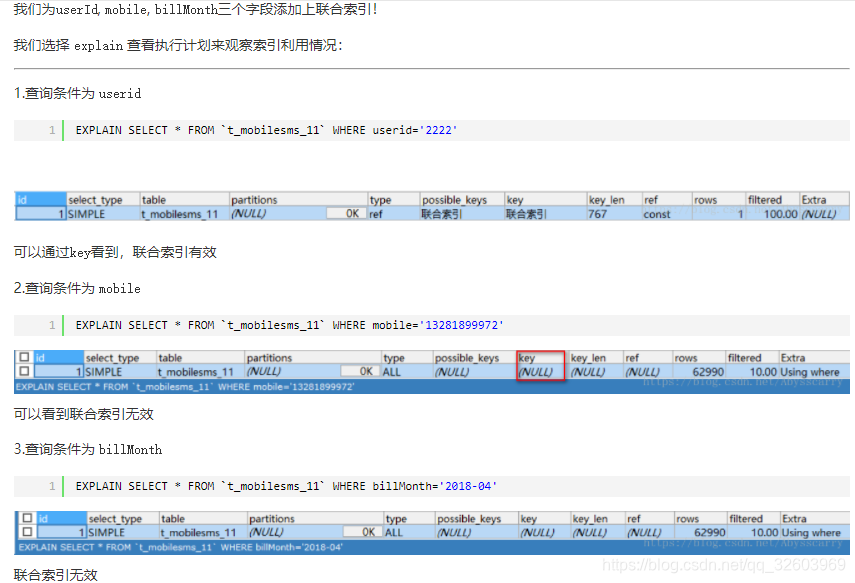
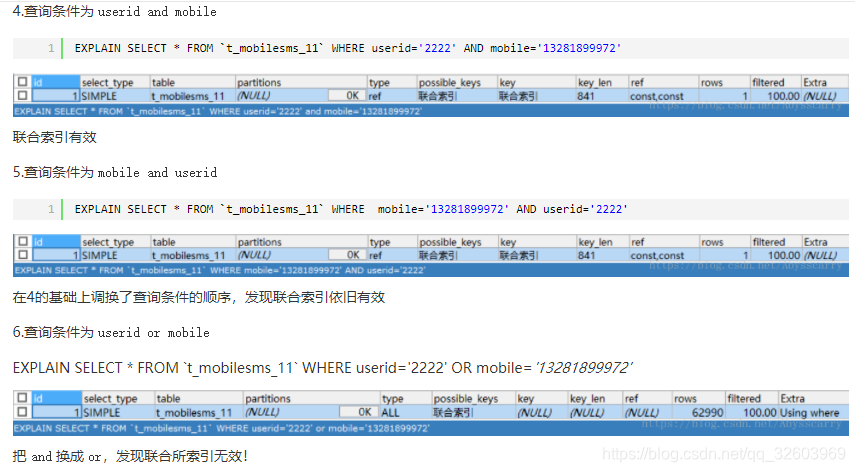
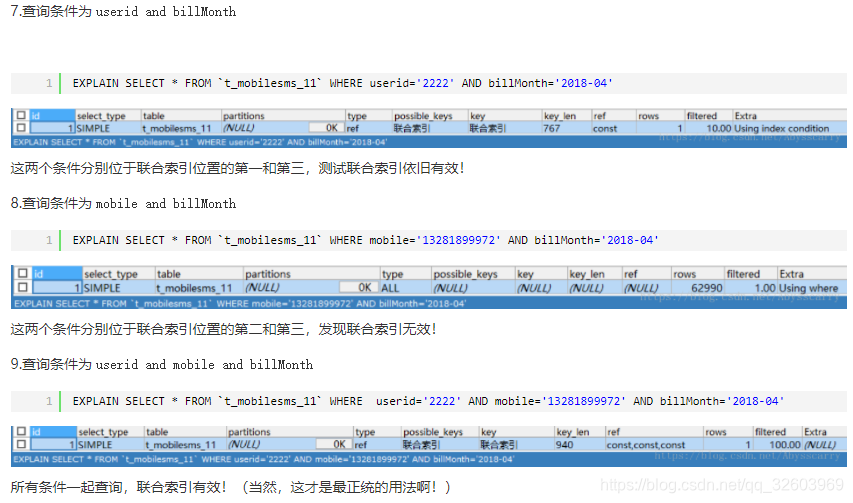
(2).避免索引失效

单值索引的字段为:a、b、c
- where a and b and c:只用到a的索引;
- where b and c:只用到b的索引;
- where a or b:此时两个索引都被用上了;
(3).双表联查优化
疑问:在进行左连接或右连接的时候,要在左表还是右表建立索引才能起到优化效果?
实验:在两张表都没有建立索引的情况下,使用explain进行测试现在有两张表,一张class、一张book,它们共有一个card字段,进行左连接查询
SELECT * FROM class LEFT JOIN book ON class.card = book.card;

在右表class建立索引
ALTER TABLE book ADD INDEX Y ('card');

右表达到了走索引的效果,type从ALL升级到ref,达到优化效果。
在左表book建立索引
ALTER TABLE class ADD INDEX Y ('card');

虽然左表建立了索引,但type为index,相比上面的ref效果差些,而且rows仍然为20
总结:LEFT JOIN条件用于确定如何从右表搜索行,左边一定都有,所以右边才是我们的关键点,一定要在右边建立索引。RIGHT JOIN同理,要在左表建立索引。索引建好了的情况下,可以通过对调左右表顺序来实现利用到索引的效果,而不是傻傻的去重建索引。
(4).多表联查优化
有class、book、phone 三张表
SQL语句
SELECT * FROM class LEFT JOIN book ON class.card=book.card LEFT JOIN phone ON book,card=phone,card;
在都没有建立索引的情况下:
在book、phone建立了card索引后:
结论:三表优化思路和双表类似,索引最好设置在需要经常查询的字段中
join语句的优化:
- 尽可能减少JOIN语句中的NestedLoop的循环总次数:“永远用小结果集驱动大的结果集”。
- 优先优化NestedLoop的内层循环;
- 保证JOIN语句中被驱动表上Join条件字段已被索引;
- 当无法保证被驱动表的JOIN条件字段被索引且内存资源充足的前提下,不要太吝啬
JoinBuffer的设置;
(4).分页优化
分页深度
当mysql表里有1万条数据时,从9000条开始查询10条数据,此时mysql原理是先找到9000的位置再取10条数据。
select * from tableName limit 9000,10; 解决方案:count总条数,假如每页显示10条数据,此时得到总页数。当查询第一页时id传0,查询第二页时id传10,以此类推。即每次查询时携带所查询的页然后将页数乘10得到{id}的值。
select * from tableName where id > {id} limit 10; 去掉count
比如手机端用户不需要知道总条数,只需要知道某年某月的订单数据即可,只需提供时间维度进行不断查询这个时间线上的历史数据,使用limit (当前页 - 1 * size) , size公式每次翻下一页时把页数传进来即可(查询第二页后size就不能改变,第一页时可以改变每页显示条数),因为在500万左右的数据量下每次count需要花费5s左右时间,取10条数据的时间既有几毫秒,工行的app查询历史订单就是按照这个思路做的。
4 mysql用户权限管理
X.1 权限表


X.2 权限表作用

X.3 账户和权限管理
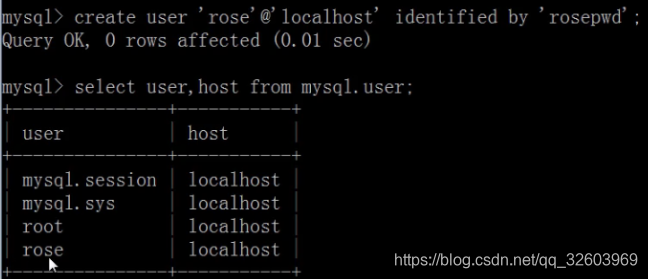
创建没有权限的用户

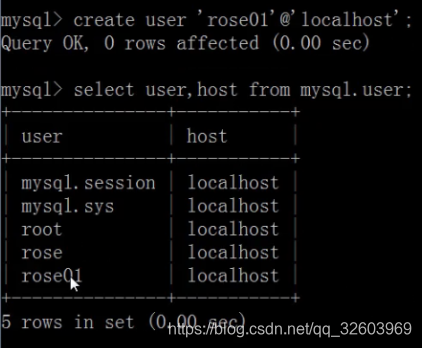
创建没有密码的用户
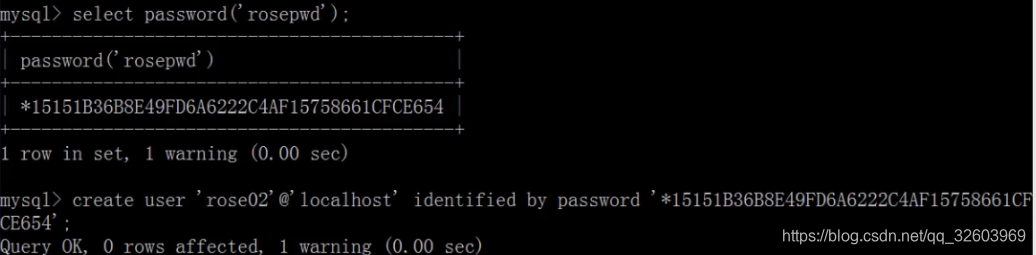
通过hash值创建用户
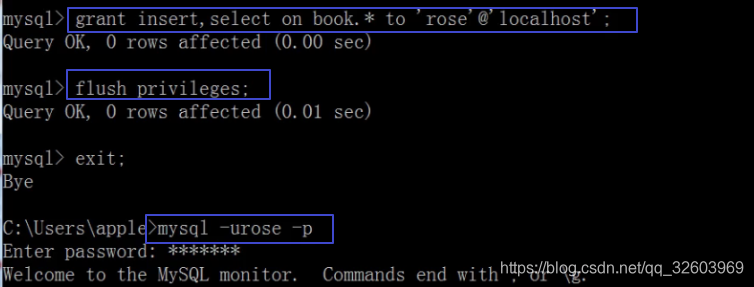
给创建的账户赋给权限


赋予所有权限到所有库下的所有表:
![]()
创建用户和赋权及一身

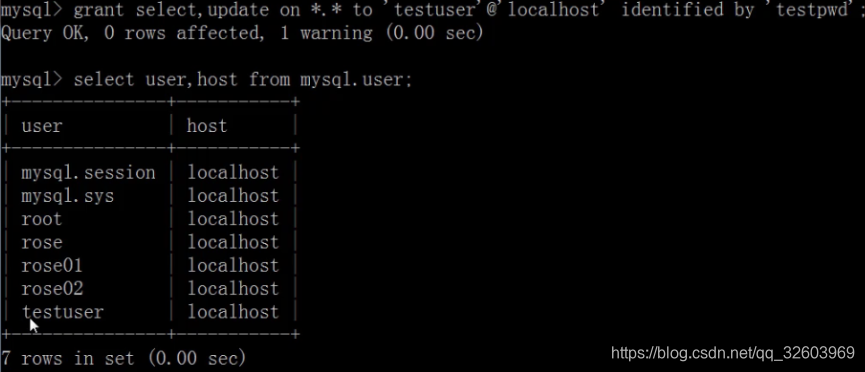
删除用户

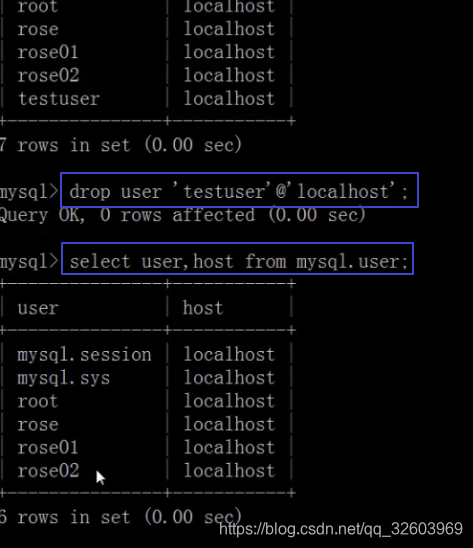
删除用户

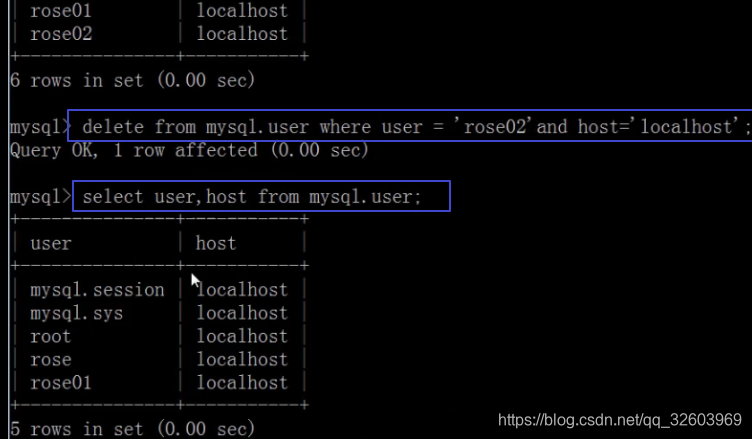
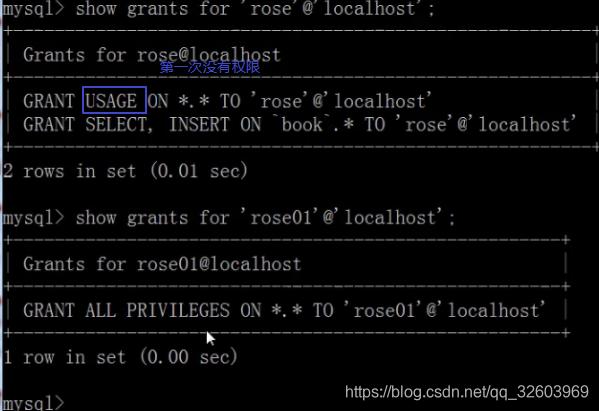
查看用户的权限
回收权限

5 敏感数据加密/模糊查询
对于敏感字段需要加密,加密后怎么做模糊匹配呢?
小数据量:like后面调用解密函数得到明文再进行模糊匹配
大数据量:用es将要搜索的字段进行分词后再加密保存到es,然后搜索时进行分词加密匹配

AES_ENCRYPT(str,key):返回用密钥key对字符串str利用高级加密标准算法加密后的结果,调用AES_ENCRYPT的结果是一个二进制字符串,以BLOB类型存储。AES_DECRYPT(str,key):返回用密钥key对字符串str利用高级加密标准算法解密后的结果。DECODE(str,key):使用key作为密钥解密加密字符串str。ENCRYPT(str,salt):使用UNIXcrypt()函数,用关键词salt(一个可以惟一确定口令的字符串,就像钥匙一样)加密字符串str。ENCODE(str,key):使用key作为密钥加密字符串str,调用ENCODE()的结果是一个二进制字符串,它以BLOB类型存储。MD5():计算字符串str的MD5校验和。PASSWORD(str):返回字符串str的加密版本,这个加密过程是不可逆转的,和UNIX密码加密过程使用不同的算法。SHA():计算字符串str的安全散列算法(SHA)校验和。
6 win10安装mysql失败的解决方案
确保安装c++的所有运行库
确保计算机名称和工作组没有中文
确保之前安装的残留删除感觉
并用360清除注册表
6 Mysql主从架构
X.1 主从同步原理
启用、拉取、回放
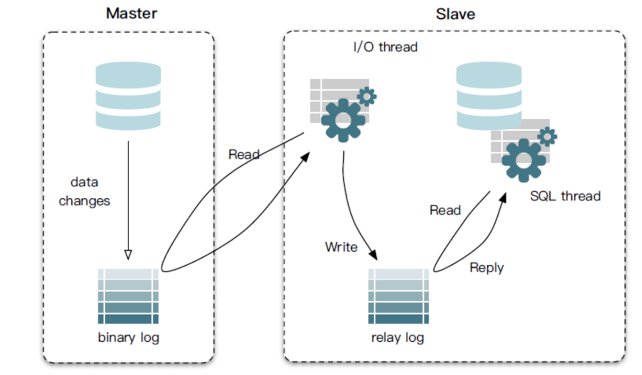
同步原理:
- Master主库,启动Binlog机制,将变更数据写入Binlog文件;
- Slave(I/O thread),从Master主库拉取binlon数据,将它拷贝到Slave的中继日志(relay log)中;
- Slave(SQL thread),回放Binlog,更新从库数据;
启用Binlog注意以下几点:
- Master主库一般会有多台Slave订阅,且Master主库要支持业务系统实时变更操作,服务器资源会有瓶颈;
- 需要同步的数据表一定要有主键;
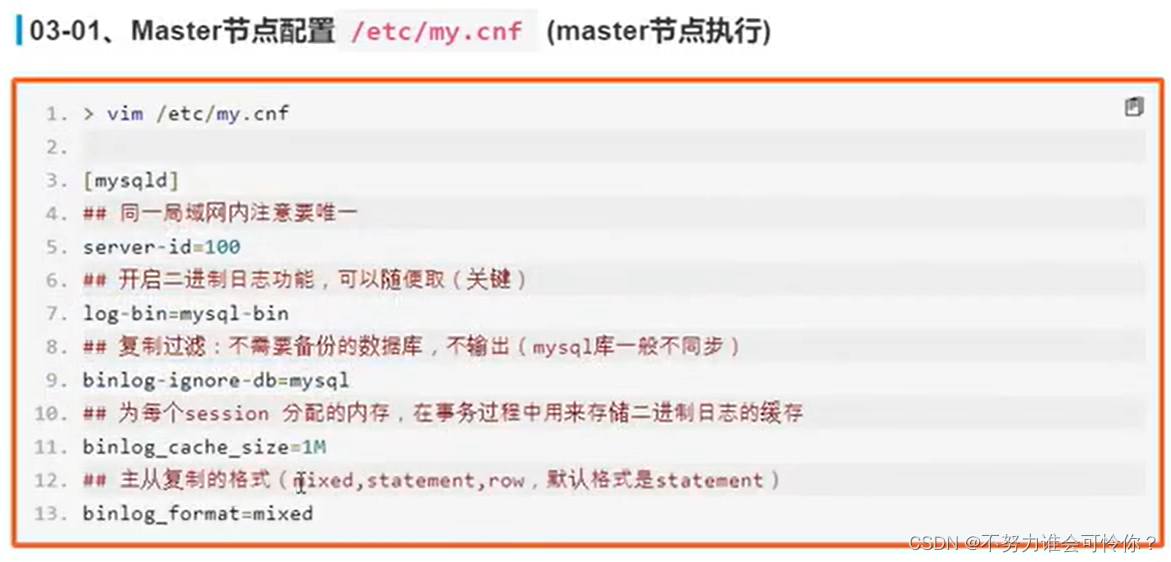
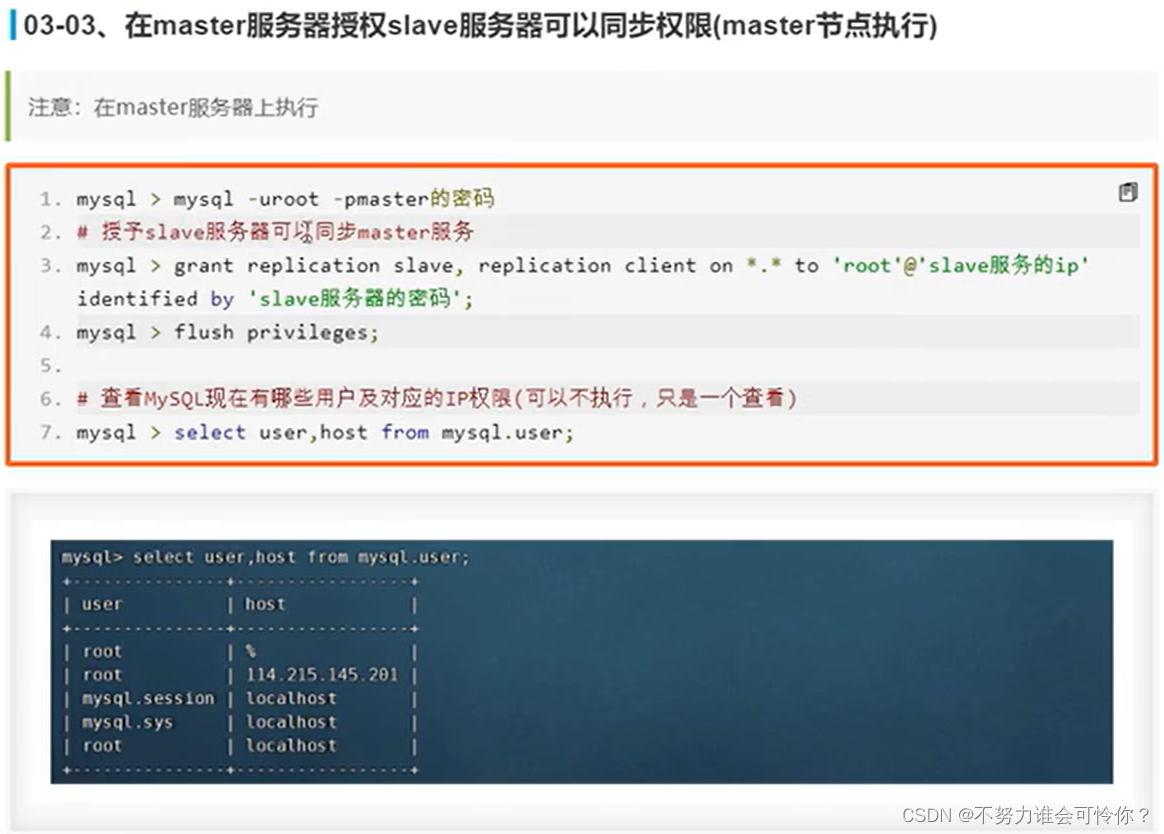
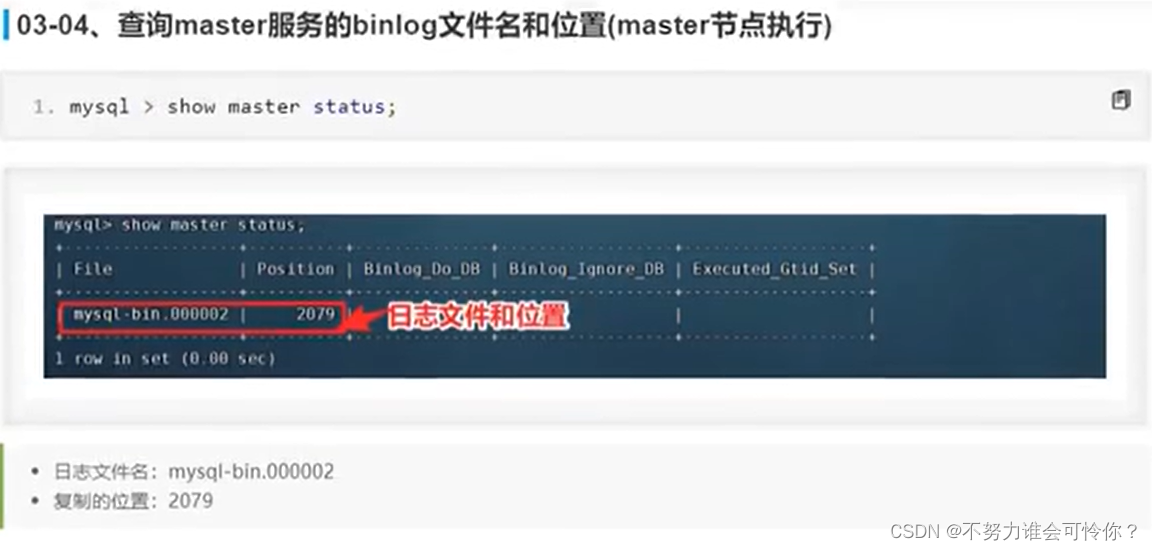
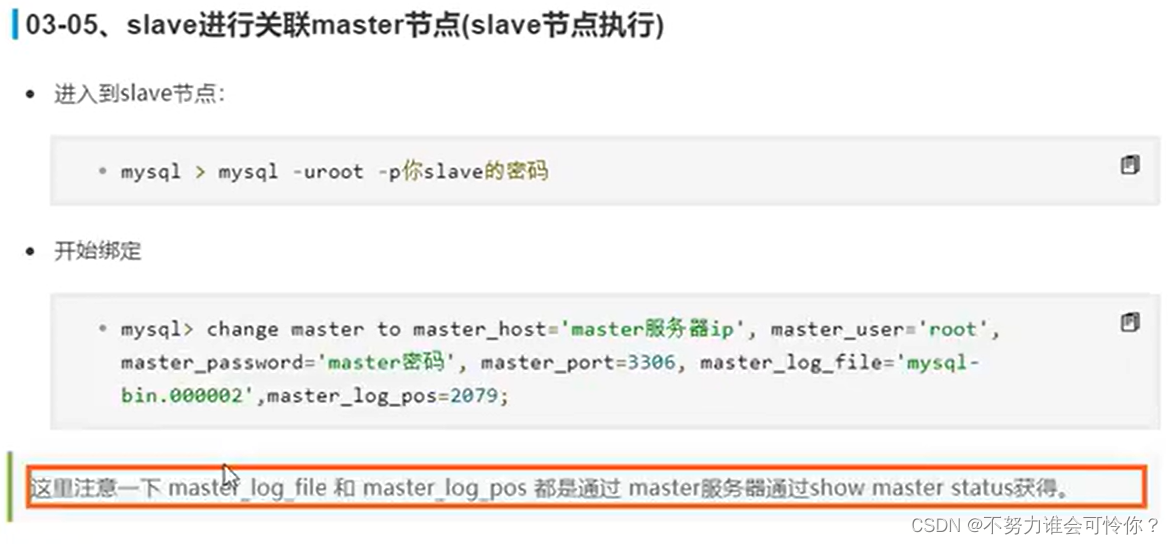
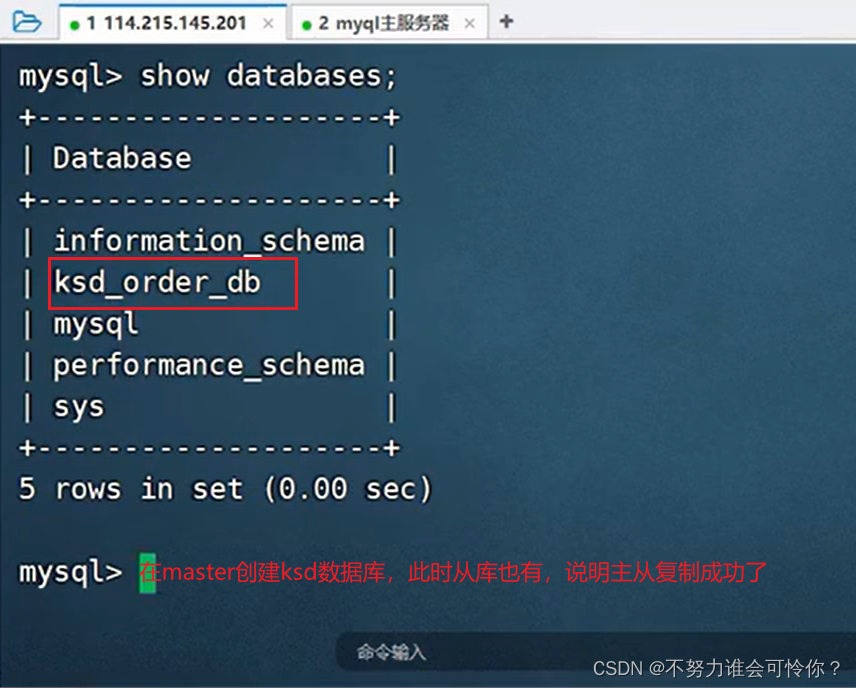
X.2 主从复制搭建
主从复制是指数据层面的东西保证数据一致性,而读写分离是指业务层面的东西,二者相辅相成
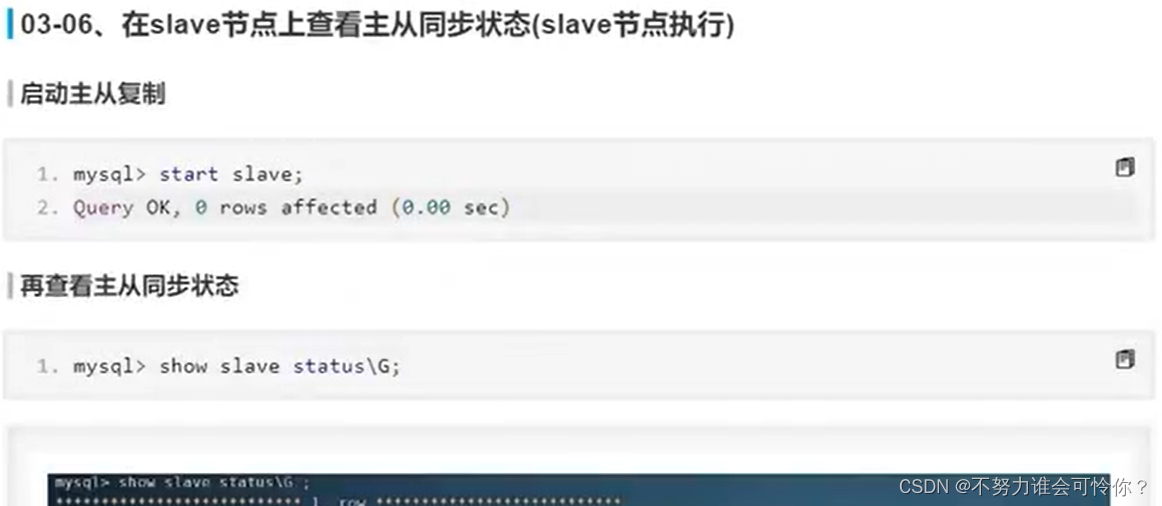
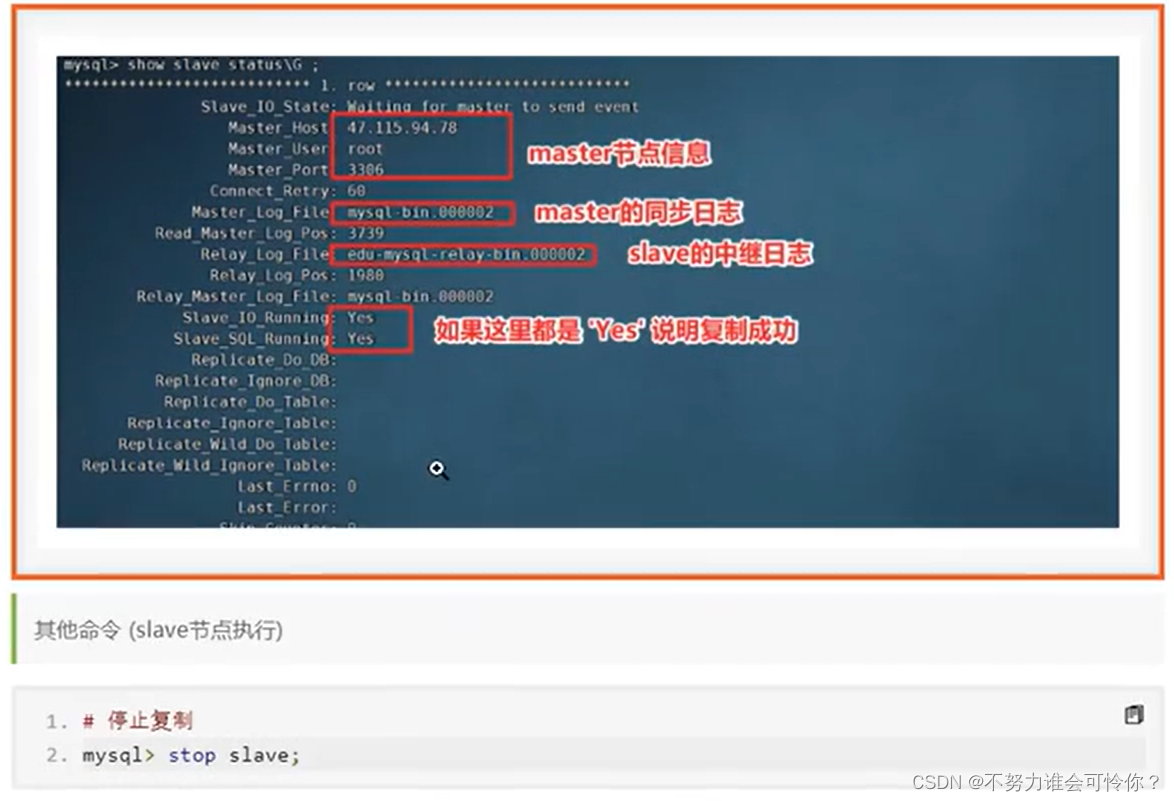
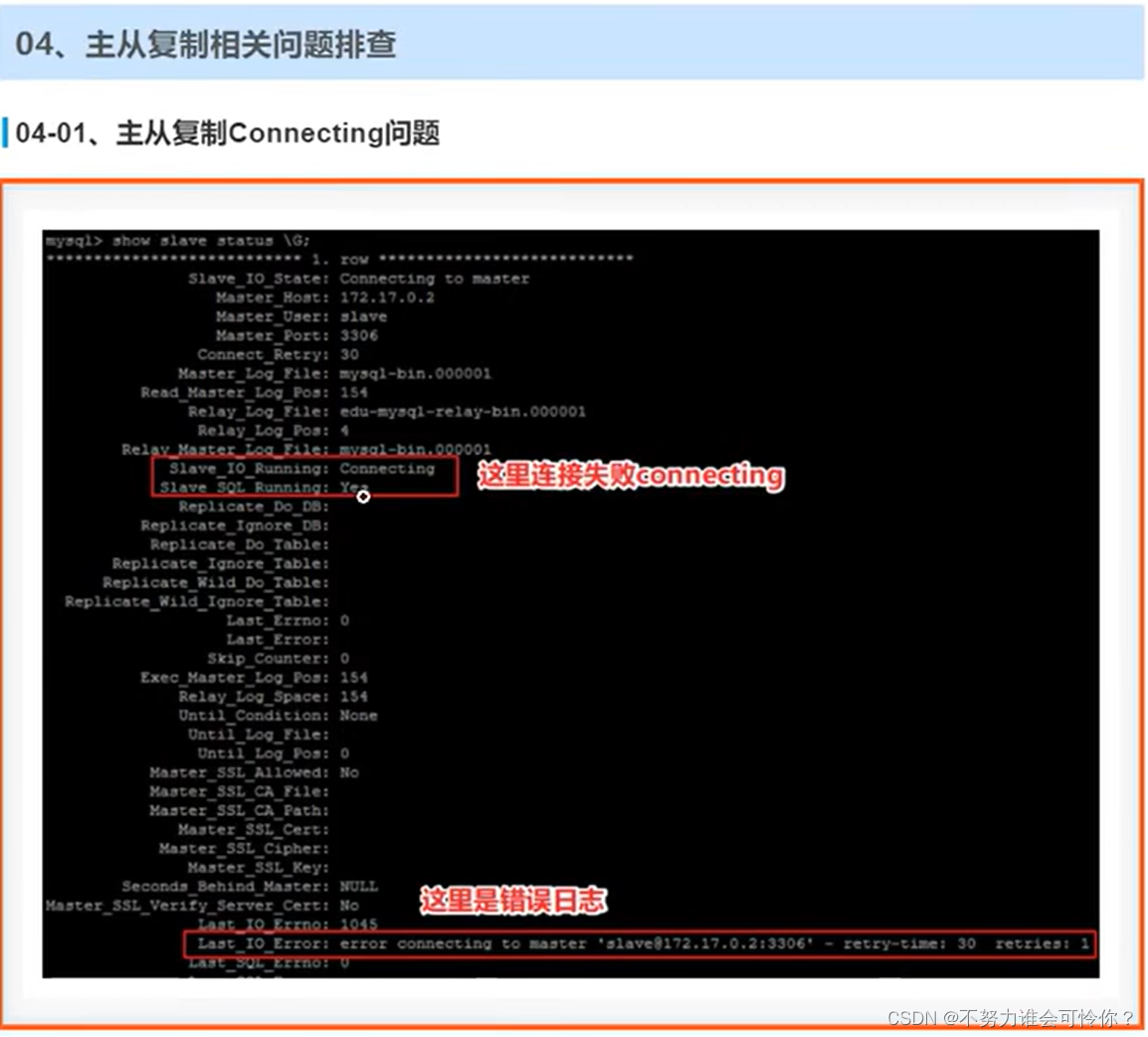
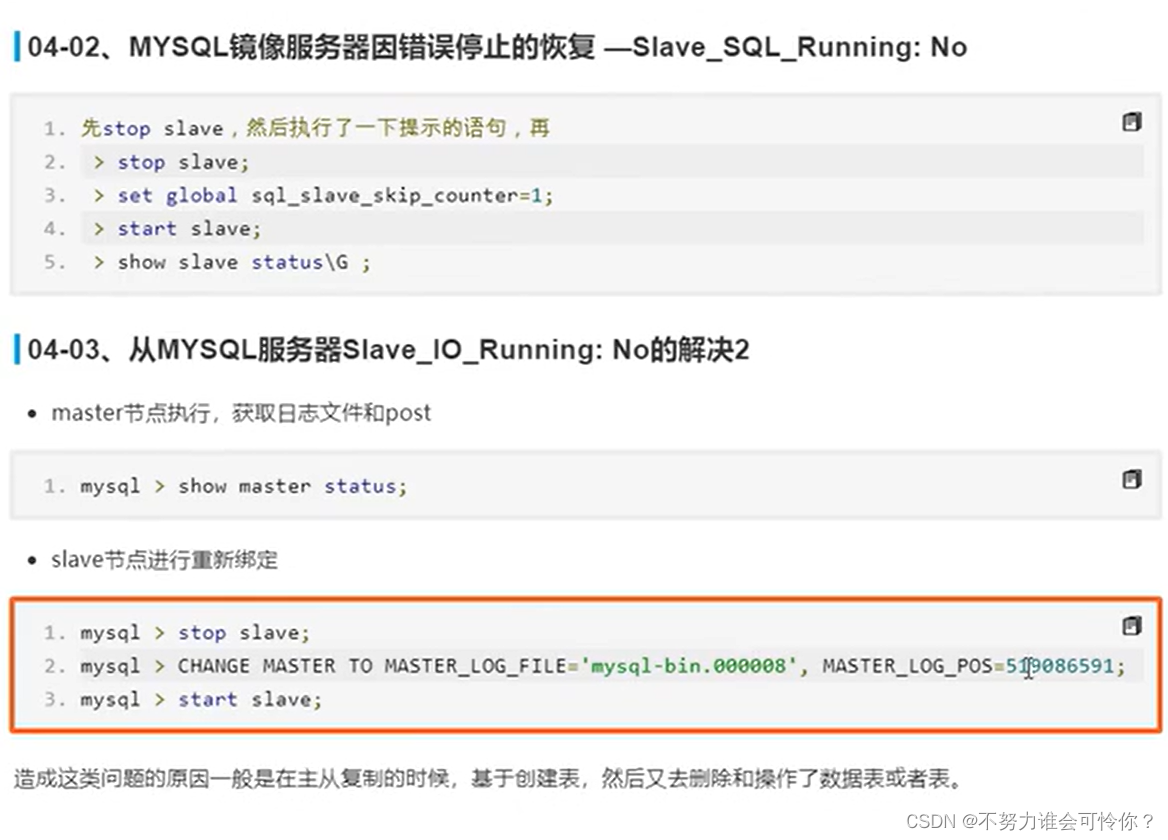
具体配置如下: