SQL Server基础语句2:表连接与集合操作、子查询与CET、高级查询
文章目录
- 五、表连接(水平合并)
- 5.1 表连接方式
- 5.2 内连接(Inner Join)
- 5.2.1 两表连接
- 5.2.2 多表连接
- 5.3 左连接
- 5.5.1 左连接:左表所有行+右表匹配行
- 5.5.2 左反连接:右表不匹配行
- 5.5.3 多表连接
- 5.5.4 `ON` 子句与 `WHERE` 子句的区别
- 5.4 外连接:左表所有行+右表所有行
- 5.4.1 准备示例数据
- 5.4.2 外连接示例
- 5.4.3 使用 `WHERE` 子句过滤结果
- 5.5 交叉连接
- 5.5.2 示例 :生成所有 商店/产品 组合
- 5.5.2 示例 :查找无销售记录的 商店/产品 组合
- 5.6 自连接
- 5.6.1 自连接语法
- 5.6.2 查询层次化数据
- 5.6.3 比较表内的行
- 5.6.5.1 基础示例
- 5.6.5.2 `>` 与 `<>`的区别
- 六、集合操作(垂直合并)
- 6.1 UNION:追加查询
- 6.1.2 UNION 与 JOIN 的区别
- 6.1.3 UNION 使用示例
- 6.1.4 使用ORDER BY排序
- 6.2 EXCEPT:求差集
- 6.3 INTERSECT:求交集
- 七、子查询与公共表表达式(CTE)
- 7.1 子查询简介
- 7.1.1 子查询的概念
- 7.1.2 嵌套子查询
- 7.1.3 相关子查询
- 7.2 子查询常见使用场景
- 7.2.1 作为表达式使用
- 7.2.2 与 `IN` 或 `NOT IN` 操作符一起使用
- 7.2.3 ANY操作符:多值比较
- 7.2.4 与`ALL`操作符一起使用
- 7.2.5 与 `EXISTS` 或 `NOT EXISTS` 操作符一起使用
- 7.2.5.1 基础示例
- 7.2.5.2 EXISTS 与 IN 的比较
- 7.2.5.3 EXISTS 与 JOIN 的比较
- 7.2.6 在 `FROM` 子句中使用
- 7.3 公共表表达式(CTE)
- 7.3.1 CTE 基础语法与用法
- 7.3.2 使用多个CTE
- 7.4递归公共表表达式(Recursive CTE)
- 7.4.1 递归 CTE 语法
- 7.4.2 简单示例
- 7.4.3 查询层次化数据
- 八、高级查询
- 8.1 CASE:实现条件逻辑
- 8.1.1 简单 `CASE` 表达式(等值判断)
- 8.1.2 搜索 `CASE` 表达式
- 8.2 COALESCE 表达式:处理查询中的 NULL 值
- 8.2.1 COALESCE基础功能
- 8.2.2 替换 NULL 值
- 8.2.3 选择可用数据
- 8.2.4 COALESCE表达式 VS CASE表达式
- 8.3 `NULLIF` 表达式:条件性返回 NULL
- 8.3.1`NULLIF` 基础语法
- 8.3.2 将空字符串转换为 `NULL`
- 8.3.3 条件查询
- 8.3.4 `NULLIF` 表达式VS `CASE` 表达式
- 8.4 PIVOT :透视表
- 8.4.1 业务背景
- 8.4.2 直接转换
- 8.4.3 动态生成列值
- 8.4.4 动态 PIVOT 表
- 8.5 UNPIVOT:逆透视表
- 8.5.1 UNPIVOT语法
- 8.5.2 简单示例
- 8.5.3 动态 UNPIVOT
参考 《SQL Server Basics》
五、表连接(水平合并)
5.1 表连接方式
在关系型数据库中,数据通常被分散存储在多个表中。为了获取完整且有意义的数据集,我们需要通过连接(Joins)操作从这些表中查询数据。表连接方式有以下几种:
| 连接方式 | 语句 | 描述 |
|---|---|---|
| 内连接 | INNER JOIN(INNER可省略) | 返回左表和右表中匹配的行。 |
| 左连接 | LEFT OUTER JOIN(OUTER可省略) | 返回左表所有行+右表匹配行;右表不匹配的列返回空值。 |
| 右连接 | RIGHT OUTER JOIN(OUTER可省略) | 返回右表所有行+左表匹配行;左表不匹配的列返回空值。 |
| 外连接 | FULL OUTER JOIN(OUTER可省略) | 返回左表和右表中的所有行。不匹配的列返回空值。 |
| 交叉连接 | CROSS JOIN | 返回左表和右表的笛卡尔积,即左表的每一行与右表的每一行组合。 |


5.2 内连接(Inner Join)
INNER JOIN 的语法如下:
SELECTselect_list
FROMT1
INNER JOIN T2 ON join_predicate;
-
T1和T2是需要连接的两个表。 -
join_predicate是连接条件,用于指定如何匹配两个表中的行。只有满足连接条件的行才会被包含在结果集中。 -
INNER关键字是可选的,即最后一句可以写成:JOIN T2 ON join_predicate;

5.2.1 两表连接
假设我们有以下两个表:products 和 categories,它们的结构和数据如下所示:

通过 INNER JOIN,可以将 products 表和 categories 表连接起来,根据 category_id 列的值匹配行:
SELECTproduct_name,category_name,list_price
FROMproduction.products p
INNER JOIN production.categories cON c.category_id = p.category_id
ORDER BYproduct_name DESC;

在这个查询中:
p和c分别是production.products和production.categories表的别名。 使用别名可以简化列的引用,例如c.category_id代替production.categories.category_id。INNER JOIN根据category_id列的值匹配products表和categories表中的行。- 如果两个表中的行在
category_id列的值相同,则将它们组合成一条新行,并将其包含在结果集中。
5.2.2 多表连接
INNER JOIN 也可以用于连接多个表。假设我们有以下三个表:products、categories 和 brands,它们的结构和数据如下所示:

如果需要从这三个表中查询数据,可以使用多个 INNER JOIN:
SELECTproduct_name,category_name,brand_name,list_price
FROMproduction.products p
INNER JOIN production.categories c ON c.category_id = p.category_id
INNER JOIN production.brands b ON b.brand_id = p.brand_id
ORDER BYproduct_name DESC;

在这个查询中:
products表通过category_id列与categories表连接,通过brand_id列与brands表连接。- 查询结果中包含了产品名称、分类名称、品牌名称和价格。
- 只有在三个表中都有匹配的行才会被包含在结果集中。
5.3 左连接
5.5.1 左连接:左表所有行+右表匹配行
左连接(Left Join)返回左表中的所有行以及右表中匹配的行。如果右表中没有匹配的行,则右表的列将返回 NULL。

假设我们有以下两个表:products 和 order_items,它们的结构和数据如下所示,两个表通过 product_id 列关联。

以下查询使用 LEFT JOIN 从 products 和 order_items 表中查询数据:
SELECTproduct_name,order_id
FROMproduction.products p
LEFT JOIN sales.order_items o ON o.product_id = p.product_id
ORDER BYorder_id;
从结果中可以看出,order_id 列中包含 NULL 的行表示这些产品尚未被销售给任何客户:

5.5.2 左反连接:右表不匹配行
LEFT JOIN 的结果集可以通过 WHERE 子句进一步限制,只返回那些在右表中没有匹配行的左表记录。例如,WHERE order_id IS NULL 确保返回尚未出现在任何销售订单中的产品:
SELECTproduct_name,order_id
FROMproduction.products p
LEFT JOIN sales.order_items o ON o.product_id = p.product_id
WHERE order_id IS NULL;

5.5.3 多表连接
LEFT JOIN 也可以用于连接多个表。假设我们有以下三个表:products、orders 和 order_items,它们的结构和数据如下所示:

以下查询使用 LEFT JOIN 从这三个表中查询数据:
SELECTp.product_name,o.order_id,i.item_id,o.order_date
FROMproduction.products p
LEFT JOIN sales.order_items i ON i.product_id = p.product_id
LEFT JOIN sales.orders o ON o.order_id = i.order_id
ORDER BYorder_id;

在这个查询中:
order_items表通过order_id列与orders表连接,通过product_id列与products表连接。- 查询结果中包含了产品名称、订单 ID、订单项 ID 和订单日期。
5.5.4 ON 子句与 WHERE 子句的区别
在 LEFT JOIN 中,ON 子句和 WHERE 子句的作用有所不同。ON 子句用于指定连接条件,而 WHERE 子句用于过滤结果集。
例如,以下查询返回属于订单 ID 为 100 的产品:
SELECTproduct_name,order_id
FROMproduction.products p
LEFT JOIN sales.order_items o ON o.product_id = p.product_id
WHERE order_id = 100
ORDER BYorder_id;

如果将条件 order_id = 100 移动到 ON 子句中:
SELECTp.product_id,product_name,order_id
FROMproduction.products p
LEFT JOIN sales.order_items o ON o.product_id = p.product_id AND o.order_id = 100
ORDER BYorder_id DESC;

这个查询返回了所有产品,但只有订单 ID 为 100 的订单才包含关联的产品信息。这表明 ON 子句中的条件仅用于连接操作,而 WHERE 子句中的条件用于过滤最终结果集。
5.4 外连接:左表所有行+右表所有行
外连接返回左表和右表中的所有行。如果某一行在左表或右表中没有匹配的行,则缺失的列将返回 NULL。
5.4.1 准备示例数据
为了演示 FULL OUTER JOIN 的功能,我们首先创建一个名为 pm 的新架构:
CREATE SCHEMA pm;
GO
然后,在 pm 架构中创建两个新表:projects 和 members:
CREATE TABLE pm.projects(id INT PRIMARY KEY IDENTITY,title VARCHAR(255) NOT NULL
);CREATE TABLE pm.members(id INT PRIMARY KEY IDENTITY,name VARCHAR(120) NOT NULL,project_id INT,FOREIGN KEY (project_id)REFERENCES pm.projects(id)
);
假设每个成员只能参与一个项目,而每个项目可以有零个或多个成员。如果项目处于初始阶段,则可能没有分配任何成员。接下来,向 projects 和 members 表中插入一些数据:
INSERT INTOpm.projects(title)
VALUES('New CRM for Project Sales'),('ERP Implementation'),('Develop Mobile Sales Platform');INSERT INTOpm.members(name, project_id)
VALUES('John Doe', 1),('Lily Bush', 1),('Jane Doe', 2),('Jack Daniel', null);
查询 projects 和 members 表中的数据:
SELECT * FROM pm.projects;

SELECT * FROM pm.members;

5.4.2 外连接示例
接下来,使用 FULL OUTER JOIN 从 projects 和 members 表中查询数据:
SELECTm.name member,p.title project
FROMpm.members mFULL OUTER JOIN pm.projects pON p.id = m.project_id;

5.4.3 使用 WHERE 子句过滤结果
如果需要进一步过滤结果集,可以使用 WHERE 子句。例如,以下查询返回未参与任何项目的成员以及没有成员的项目:
SELECTm.name member,p.title project
FROMpm.members mFULL OUTER JOIN pm.projects pON p.id = m.project_id
WHEREm.id IS NULL ORp.id IS NULL;

从结果中可以看出: Jack Daniel 未参与任何项目,项目 Develop Mobile Sales Platform 没有成员。
5.5 交叉连接
CROSS JOIN 是一种特殊的连接操作,用于将两个表的每一行进行组合,生成所有可能的组合结果。换句话说,CROSS JOIN 返回的是两个表的笛卡尔积。其基本语法如下:
SELECT select_list
FROM T1
CROSS JOIN T2;
与 INNER JOIN 或 LEFT JOIN 不同,CROSS JOIN 不需要指定连接条件。如果表 T1 有 n 行,表 T2 有 m 行,那么 CROSS JOIN 的结果集将包含 n×m 行。由于 CROSS JOIN 可能会生成大量的行,因此在使用时需要谨慎,以避免性能问题。

5.5.2 示例 :生成所有 商店/产品 组合
假设我们有两个表:production.products 和 sales.stores,分别存储了产品信息和商店信息。我们希望生成所有产品与商店的组合,以便在月末或年末进行库存盘点:
SELECTproduct_id,product_name,store_id,0 AS quantity -- 初始库存都设为0
FROMproduction.products
CROSS JOIN sales.stores
ORDER BYproduct_name,store_id;

5.5.2 示例 :查找无销售记录的 商店/产品 组合
以下语句查找在商店中没有销售的产品:
SELECTs.store_id,p.product_id,ISNULL(sales, 0) AS sales
FROMsales.stores s
CROSS JOIN production.products p
LEFT JOIN (SELECTs.store_id,p.product_id,SUM(quantity * i.list_price) AS salesFROMsales.orders oINNER JOIN sales.order_items i ON i.order_id = o.order_idINNER JOIN sales.stores s ON s.store_id = o.store_idINNER JOIN production.products p ON p.product_id = i.product_idGROUP BYs.store_id,p.product_id
) c ON c.store_id = s.store_id
AND c.product_id = p.product_id
WHEREsales IS NULL
ORDER BYproduct_id,store_id;
- 使用
CROSS JOIN生成所有商店与产品的组合 - 通过
LEFT JOIN将这些组合与实际的销售记录进行对比。如果某个组合在销售记录中没有匹配的条目(即sales IS NULL),则表示该产品在该商店中没有销售记录。

5.6 自连接
5.6.1 自连接语法
在 SQL Server 中,Self Join 是一种特殊的连接操作,它允许将同一张表与自身进行连接,这种操作通常用于处理层次化数据或比较表内的行。由于查询中引用了同一张表,因此需要使用表别名来区分表的不同引用。
Self Join 可以使用 INNER JOIN 或 LEFT JOIN 来实现。其基本语法如下:
SELECT select_list
FROM T t1
[INNER | LEFT] JOIN T t2 ON join_predicate;
在上述语法中,T 是需要进行自我连接的表,t1 和 t2 是表的别名,用于在查询中区分同一张表的不同引用。如果不使用表别名,SQL Server 会抛出错误。
5.6.2 查询层次化数据
假设我们有一个 staffs 表,其中存储了员工的姓名、邮箱以及其直接上级的 ID(manager_id):

我们可以通过 Self Join 来查询每个员工及其直接上级的信息。例如,Mireya 向 Fabiola 报告,因为 Mireya manager_id 中的值为 Fabiola。Fabiola 没有上级,因此 manager id 列为 NULL。
SELECTe.first_name + ' ' + e.last_name AS employee,m.first_name + ' ' + m.last_name AS manager
FROMsales.staffs e
INNER JOIN sales.staffs m ON m.staff_id = e.manager_id
ORDER BYmanager;
在这个查询中,我们使用了 INNER JOIN 来连接 staffs 表两次,分别用别名 e(代表员工)和 m(代表上级)。通过 e.manager_id = m.staff_id 的连接条件,我们可以找到每个员工的直接上级。

如果希望在结果中包含没有上级的员工(例如 Fabiola Jackson),可以将 INNER JOIN 替换为 LEFT JOIN:

5.6.3 比较表内的行
5.6.5.1 基础示例
假设我们有一个 customers 表,存储了客户的姓名和所在城市:

我们可以通过 Self Join 找到位于同一城市的客户。
SELECTc1.city,c1.first_name + ' ' + c1.last_name customer_1,c2.first_name + ' ' + c2.last_name customer_2
FROMsales.customers c1
INNER JOIN sales.customers c2 ON c1.customer_id > c2.customer_id
AND c1.city = c2.city
ORDER BYcity,customer_1,customer_2;
- 使用了
INNER JOIN来连接customers表两次,分别用别名c1和c2。 - 连接条件
c1.customer_id > c2.customer_id确保不会比较同一客户。如果将连接条件中的>替换为<>,则会生成更多的组合(左右互换) - c1.city = c2.city` 确保只比较位于同一城市的客户。

5.6.5.2 > 与 <>的区别
以Albany城市的客户为例:
SELECT customer_id, first_name + ' ' + last_name c, city
FROM sales.customers
WHEREcity = 'Albany'
ORDER BY c;

-
使用 > 运算符进行筛选:
SELECTc1.city,c1.first_name + ' ' + c1.last_name customer_1,c2.first_name + ' ' + c2.last_name customer_2 FROMsales.customers c1 INNER JOIN sales.customers c2 ON c1.customer_id > c2.customer_id AND c1.city = c2.city WHERE c1.city = 'Albany' ORDER BYc1.city,customer_1,customer_2;
-
使用 <> 运算符进行筛选:
... INNER JOIN sales.customers c2 ON c1.customer_id <> c2.customer_id ...
六、集合操作(垂直合并)
6.1 UNION:追加查询
UNION 是一种集合操作符,用于将两个或多个查询的结果集合并为一个单一的结果集。其基本语法如下:
query_1
UNION
query_2
使用 UNION 时,需要满足以下要求:
- 列的数量和顺序:两个查询中列的数量和顺序必须完全一致。
- 数据类型兼容性:对应列的数据类型必须相同或兼容。
UNION ALL:默认情况下,UNION操作符会自动去除结果集中的重复行。如果希望保留重复行,需要显式使用UNION ALL
以下是一个简单的 Venn 图,展示了两个表(T1 和 T2)的结果集如何通过 UNION 合并:

6.1.2 UNION 与 JOIN 的区别
JOIN(如 INNER JOIN 或 LEFT JOIN)用于将两个表的 列 进行合并,而 UNION 用于将两个查询的 行 进行合并。换句话说,JOIN 是水平合并,而 UNION 是垂直合并(追加查询)。以下是两者的区别示意图:

6.1.3 UNION 使用示例
假设我们有两个表:staffs 和 customers,其结构如下:

-
使用UNION合并查询:
SELECTfirst_name,last_name FROMsales.staffs UNION SELECTfirst_name,last_name FROMsales.customers;
该查询返回了 1,454 行数据。通过以下查询可以确认两个表的行数:
SELECT COUNT(*) FROM sales.staffs; -- 返回 10 行 SELECT COUNT(*) FROM sales.customers; -- 返回 1,445 行由于结果集中只有 1,454 行,说明有一行重复数据被
UNION自动去除了。 -
使用UNION ALL合并查询:如果希望保留重复行,可以使用
UNION ALL:SELECTfirst_name,last_name FROMsales.staffs UNION ALL SELECTfirst_name,last_name FROMsales.customers;该查询返回了 1,455 行数据,与两个表的总行数一致。
6.1.4 使用ORDER BY排序
如果需要对 UNION 的结果集进行排序,可以在最后一个查询中使用 ORDER BY 子句。例如,按姓氏和名字排序:
SELECTfirst_name,last_name
FROMsales.staffs
UNION ALL
SELECTfirst_name,last_name
FROMsales.customers
ORDER BYfirst_name,last_name;
该查询将合并后的结果集按 first_name 和 last_name 排序。

6.2 EXCEPT:求差集
EXCEPT 操作符可以从一个结果集中减去另一个结果集。
其语法如下:
query_1
EXCEPT
query_2
使用 EXCEPT 时,需要满足以下规则:
- 列的数量和顺序:两个查询中列的数量和顺序必须完全一致。
- 数据类型兼容性:对应列的数据类型必须相同或兼容。
以下图示展示了两个结果集 T1 和 T2 的 EXCEPT 操作:

- T1 结果集包含值 1、2 和 3。
- T2 结果集包含值 2、3 和 4。
T1 和 T2 的 EXCEPT 操作返回值 1,因为这是 T1 中唯一不存在于 T2 的行。
假设我们有以下两个表:products 和 order_items,其结构如下:

使用 EXCEPT 查找从未销售过的产品:
SELECTproduct_id
FROMproduction.products
EXCEPT
SELECTproduct_id
FROMsales.order_items;
ORDER BYproduct_id;
在这个例子中:
- 第一个查询返回所有产品的
product_id。 - 第二个查询返回所有已销售产品的
product_id。
因此,EXCEPT 操作的结果集只包含那些从未销售过的产品的 product_id。最后结果集按 product_id 排序。
EXCEPT:返回第一个结果集中存在但第二个结果集中不存在的唯一行。UNION:合并两个结果集,并自动去除重复行。UNION ALL:合并两个结果集,保留所有重复行。INTERSECT:返回两个结果集的交集,即两个结果集中都存在的行。
6.3 INTERSECT:求交集
INTERSECT 操作符用于求两个查询结果集的交集,即返回两个查询共有的唯一行。其语法如下:
query_1
INTERSECT
query_2
与 UNION 操作符类似,INTERSECT 的使用需要满足以下规则:
- 列的数量和顺序必须一致:两个查询必须返回相同数量的列,并且列的顺序也必须一致。
- 数据类型必须兼容:两个查询中对应列的数据类型必须相同或兼容。
下图展示了 INTERSECT 操作的原理:

假设我们有两个表:customers 和 stores,分别存储客户和商店的信息。我们希望找到客户和商店都存在的城市:
SELECTcity
FROMsales.customers
INTERSECT
SELECTcity
FROMsales.stores
ORDER BYcity;
- 第一个查询:
SELECT city FROM sales.customers,返回所有客户的所在城市。 - 第二个查询:
SELECT city FROM sales.stores,返回所有商店的所在城市。 INTERSECT操作:将两个查询的结果集进行交集操作,返回两个查询共有的城市。

注意事项:
INTERSECT操作符在处理大数据集时可能会消耗较多资源。如果数据量较大,建议在查询中使用索引或其他优化手段。
七、子查询与公共表表达式(CTE)
7.1 子查询简介
7.1.1 子查询的概念
子查询(也称内查询)是嵌套在另一个查询中的查询,包含子查询的语句被称为外查询。子查询可用于 SELECT、INSERT、UPDATE 或 DELETE 语句中,从而实现复杂的查询逻辑。需要注意的是,子查询必须用括号 () 包裹。
假设我们有两个表——orders 和 customers:

我们希望找到所有来自纽约的客户的销售订单,可以通过在 SELECT 语句的 WHERE 子句中使用子查询来实现:
SELECTorder_id,order_date,customer_id
FROMsales.orders
WHEREcustomer_id IN (SELECTcustomer_idFROMsales.customersWHEREcity = 'New York')
ORDER BYorder_date DESC;

在这个例子中,子查询返回了所有位于纽约的客户的 customer_id,然后外层查询使用这些 customer_id 来获取对应的订单信息。
7.1.2 嵌套子查询
子查询可以嵌套在另一个子查询中,SQL Server 支持最多 32 层嵌套。例如,我们希望找到所有价格高于特定品牌平均价格的产品。可以通过嵌套子查询来实现:
SELECTproduct_name,list_price
FROMproduction.products
WHERElist_price > (SELECTAVG(list_price)FROMproduction.productsWHEREbrand_id IN (SELECTbrand_idFROMproduction.brandsWHEREbrand_name = 'Strider'OR brand_name = 'Trek'))
ORDER BYlist_price;
- 最内层的子查询返回了 Strider 和 Trek 品牌的
brand_id - 中间层的子查询计算这些品牌的平均价格
- 最外层查询返回所有价格高于该平均价格的产品。

7.1.3 相关子查询
相关子查询是一种依赖于外层查询的子查询。它使用外层查询的结果作为输入,因此不能独立执行。由于这种依赖关系,相关子查询会为外层查询的每一行重复执行,因此也被称为“重复子查询”。假设我们有一个 products 表:

我们希望找到每个类别中价格最高的产品,一种实现方式是:
SELECTproduct_name, list_price, category_id
FROMproduction.products p1 -- 外层查询表
WHERE-- 筛选价格等于当前类别最高价格的产品list_price IN ( SELECTMAX(p2.list_price) -- 计算当前类别的最高价格FROMproduction.products p2 -- 内层查询表WHEREp2.category_id = p1.category_id -- 关联条件:内层查询的类别与外层查询的类别相同GROUP BYp2.category_id )
ORDER BYcategory_id, product_name;
- 外层查询:首先,外层查询逐行处理表中的数据(产品)。
- 内层子查询:对于外层查询的每一行,内层子查询都会根据关联条件(如
p2.category_id = p1.category_id)执行一次。 - 结果比较:内层子查询的结果用于外层查询的条件判断。如果满足条件(当前产品的价格等于该类别的最高价格),则该行(产品)被选中。
- 重复执行:这个过程会重复进行,直到外层查询的所有行都被处理完毕。

7.2 子查询常见使用场景
7.2.1 作为表达式使用
如果子查询返回单个值,它可以作为表达式使用。例如,以下查询将子查询作为列表达式,计算每个订单的最大商品价格:
SELECTorder_id,order_date,-- 子查询用作 SELECT 语句中名为 max_list_price 的列表达式(SELECTMAX(list_price)FROMsales.order_items iWHEREi.order_id = o.order_id) AS max_list_price
FROMsales.orders o
ORDER BYorder_date DESC;

7.2.2 与 IN 或 NOT IN 操作符一起使用
子查询可以返回一组值,这些值可以用于 IN 或 NOT IN 操作符。例如,以下查询返回所有属于“Mountain Bikes”或“Road Bikes”类别的产品:
SELECTproduct_id,product_name
FROMproduction.products
WHEREcategory_id IN (-- 子查询返回Mountain Bikes和Road Bikes类别产品的category_idSELECTcategory_idFROMproduction.categoriesWHEREcategory_name = 'Mountain Bikes'OR category_name = 'Road Bikes');

7.2.3 ANY操作符:多值比较
在 SQL Server 中,ANY 操作符是一种逻辑操作符,用于将一个标量值与子查询返回的单列值集合进行比较。它的语法如下:
scalar_expression comparison_operator ANY (subquery)
- scalar_expression:可以是任何有效的表达式,例如一个字段值、常量或计算结果。
- comparison_operator:可以是任何比较运算符,如
=,>,<,>=,<=,<>等。 - subquery:是一个
SELECT语句,返回单列的结果集,且该列的数据类型必须与标量表达式的数据类型一致。
假设子查询返回的值集合为
v1,v2, …,vn,ANY操作符会在这些值中逐个与标量表达式进行比较,只要其中任何一个比较结果为TRUE,ANY操作符的结果即为TRUE;否则为FALSE。需要注意的是,SOME操作符与ANY操作符是等价的,可以互换使用。
-
检索在sales表中销售数量大于或等于 2 的产品
SELECTproduct_name,list_price FROMproduction.products WHERE-- 主查询将 products 表中的 product_id 与子查询返回的产品 ID 集合进行比较product_id = ANY (-- 子查询返回所有销售数量大于或等于 2 的产品 IDSELECTproduct_idFROMsales.order_itemsWHEREquantity >= 2) ORDER BYproduct_name;通过这种方式,
ANY操作符能够高效地将单个值与多个值进行比较,避免复杂的IN或OR条件,从而实现复杂的查询逻辑。 -
检索所有价格大于或等于任意品牌平均价格的产品
SELECTproduct_name, list_price FROMproduction.products WHERE-- 筛选出价格大于或等于任意品牌平均价格的产品list_price >= ANY ( SELECTAVG(list_price) -- 计算每个品牌的平均价格FROMproduction.products -- 从产品表中查询GROUP BYbrand_id -- 按品牌分组计算平均价格);- 子查询:计算每个品牌的平均价格,返回一个包含多个平均价格的集合。
- 主查询:检查每个产品的价格是否大于或等于子查询返回的任意一个平均价格。如果是,则该产品会被选中。

7.2.4 与ALL操作符一起使用
ALL 操作符用语法与ANY类似,只是必须所有的比较结果都为 TRUE才返回TRUE。
scalar_expression comparison_operator ALL (subquery)
查找list_price高于所有品牌平均list_price的产品:
SELECTproduct_name,list_price
FROMproduction.products
WHERElist_price > ALL (-- 子查询返回每个品牌的平均list_priceSELECTAVG(list_price) AS avg_list_priceFROMproduction.productsGROUP BYbrand_id)
ORDER BYlist_price;

7.2.5 与 EXISTS 或 NOT EXISTS 操作符一起使用
EXISTS 操作符用于检查子查询(必须是SELECT 语句)是否返回至少一行数据(包括NULL),而 NOT EXISTS 操作符用于检查子查询是否没有返回数据。
7.2.5.1 基础示例
-
返回所有在 2017 年下过订单的客户:
SELECTcustomer_id,first_name,last_name,city FROMsales.customers c WHEREEXISTS (SELECTcustomer_idFROMsales.orders oWHEREo.customer_id = c.customer_idAND YEAR(order_date) = 2017) ORDER BYfirst_name,last_name;
-
返回 customers 表中的所有行
在这个例子中,子查询SELECT NULL返回了一个包含NULL的结果集,这使得EXISTS操作符的值为TRUE。因此,整个查询返回了 customers 表中的所有行。SELECTcustomer_id,first_name,last_name FROMsales.customers WHEREEXISTS (SELECT NULL) ORDER BYfirst_name,last_name; -
使用相关子查询,查找下单数量超过两次的客户

SELECTcustomer_id,first_name,last_name FROMsales.customers c WHEREEXISTS (SELECTCOUNT (*)FROMsales.orders oWHEREcustomer_id = c.customer_idGROUP BYcustomer_idHAVINGCOUNT (*) > 2) ORDER BYfirst_name,last_name;在这个例子中,我们使用了一个相关子查询。子查询根据每个客户的
customer_id检查其订单数量是否超过两次。如果某个客户的订单数量小于或等于两次,则子查询返回空结果集,导致EXISTS操作符的值为FALSE。根据EXISTS的结果,符合条件的客户将被包含在最终结果集中。

7.2.5.2 EXISTS 与 IN 的比较
以下查询使用 IN 操作符查找来自 San Jose 的客户的订单:
SELECT*
FROMsales.orders
WHEREcustomer_id IN (SELECTcustomer_idFROMsales.customersWHEREcity = 'San Jose')
ORDER BYcustomer_id,order_date;
以下查询使用 EXISTS 操作符实现相同的结果:
SELECT*
FROMsales.orders o
WHEREEXISTS (SELECTcustomer_idFROMsales.customers cWHEREo.customer_id = c.customer_idAND city = 'San Jose')
ORDER BYo.customer_id,order_date;

7.2.5.3 EXISTS 与 JOIN 的比较
EXISTS的优势:当只需要检查数据的存在性而不需要返回数据时,EXISTS是一个更高效的选择。它会在找到第一行匹配数据后立即停止处理,从而节省资源。JOIN的优势:JOIN用于扩展结果集,将相关表的列合并到一起。如果需要从多个表中返回数据,JOIN是更合适的选择。
在实际应用中,选择 EXISTS 还是 JOIN 取决于具体的业务需求。如果只需要验证数据的存在性,推荐使用 EXISTS;如果需要从多个表中提取数据,则应使用 JOIN。
7.2.6 在 FROM 子句中使用
子查询可以作为虚拟表出现在 FROM 子句中。例如,以下查询计算所有销售员工的平均订单数量:
SELECTAVG(order_count) average_order_count_by_staff
FROM
(SELECTstaff_id,COUNT(order_id) order_countFROMsales.ordersGROUP BYstaff_id
) t;
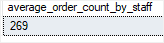
在 FROM 子句中放置的查询必须具有表别名。此示例中,我们使用 t 作为子查询的表别名。
7.3 公共表表达式(CTE)
7.3.1 CTE 基础语法与用法
公共表表达式(Common Table Expression,简称 CTE),用于定义一个临时的结果集,该结果集在查询的作用域内可用。CTE 通过 WITH 子句定义,可以显著提高子查询的可读性和可维护性,其语法如下:
WITH expression_name[(column_name [,...])]
AS(CTE_definition)
SQL_statement;
expression_name:CTE 的名称,后续查询中可以通过该名称引用 CTE。column_name:可选的列名列表,列的数量必须与CTE_definition中定义的列数量一致。AS:关键字,用于定义 CTE。CTE_definition:定义 CTE 的SELECT语句,其结果集将填充到 CTE 中。SQL_statement:引用 CTE 的查询,可以是SELECT、INSERT、UPDATE、DELETE或MERGE。
- 使用 CTE 来计算 2018 年每个销售人员的销售金额
WITH cte_sales_amounts (staff, sales, year) AS (SELECTfirst_name + ' ' + last_name AS staff,SUM(quantity * list_price * (1 - discount)) AS sales,YEAR(order_date) AS yearFROMsales.orders oINNER JOIN sales.order_items i ON i.order_id = o.order_idINNER JOIN sales.staffs s ON s.staff_id = o.staff_idGROUP BYfirst_name + ' ' + last_name,YEAR(order_date)
)
SELECTstaff,sales
FROMcte_sales_amounts
WHEREyear = 2018;
在这个示例中:
- 定义了一个名为
cte_sales_amounts的 CTE,包含staff、sales和year三列。 - 查询从
orders、order_items和staffs表中获取数据,计算每个销售人员的销售金额。 - 在外部查询中引用 CTE,并筛选出 2018 年的数据。

- 使用 CTE 计算 2018 年所有销售人员的平均订单量
WITH cte_sales AS (SELECTstaff_id,COUNT(*) AS order_countFROMsales.ordersWHEREYEAR(order_date) = 2018GROUP BYstaff_id
)
SELECTAVG(order_count) AS average_orders_by_staff
FROMcte_sales;
-- 输出结果为 48
在这个示例中:
- 定义了一个名为
cte_sales的 CTE,包含staff_id和order_count两列。 - 查询从
orders表中获取数据,计算每个销售人员在 2018 年的订单数量。 - 在外部查询中引用 CTE,并使用
AVG()函数计算平均订单数量。
7.3.2 使用多个CTE
以下示例展示了如何使用两个 CTE 来计算每个产品类别的产品数量和销售额:
WITH cte_category_counts (category_id,category_name,product_count
)
AS (SELECTc.category_id,c.category_name,COUNT(p.product_id) AS product_countFROMproduction.products pINNER JOIN production.categories c ON c.category_id = p.category_idGROUP BYc.category_id,c.category_name
),
cte_category_sales(category_id, sales) AS (SELECTp.category_id,SUM(i.quantity * i.list_price * (1 - i.discount)) AS salesFROMsales.order_items iINNER JOIN production.products p ON p.product_id = i.product_idINNER JOIN sales.orders o ON o.order_id = i.order_idWHEREorder_status = 4 -- 完成的订单GROUP BYp.category_id
)
SELECTc.category_id,c.category_name,c.product_count,s.sales
FROMcte_category_counts c
INNER JOIN cte_category_sales s ON s.category_id = c.category_id
ORDER BYc.category_name;
在这个示例中:
- 定义了两个 CTE:
cte_category_counts和cte_category_sales。cte_category_counts用于计算每个类别的产品数量。cte_category_sales用于计算每个类别的销售额。
- 在外部查询中,通过
category_id将两个 CTE 进行连接,最终输出每个类别的产品数量和销售额。
7.4递归公共表表达式(Recursive CTE)
7.4.1 递归 CTE 语法
递归 CTE 是一种特殊的公共表表达式,它通过自我引用实现递归查询,常用于查询层次化数据,例如组织结构图、多级物料清单等。递归 CTE语法如下:
WITH expression_name (column_list)
AS
(-- 锚点成员(初始查询)initial_queryUNION ALL-- 递归成员(引用表达式名称)recursive_query
)
-- 引用表达式名称
SELECT *
FROM expression_name;
一般来说,递归公共表表达式(CTE)包含三个部分:
- 初始查询:返回 CTE 的基础结果集,称为锚点成员。
- 递归查询:引用公共表表达式本身的查询,称为递归成员。递归成员通过
UNION ALL操作符与锚点成员的结果合并。 - 终止条件:在递归成员中指定的条件,用于终止递归查询的执行。
递归 CTE 的执行顺序如下:
- 执行锚点成员:生成基础结果集(记为 R0),并将其用作下一次迭代的输入。
- 执行递归成员:使用上一次迭代的结果集(记为 Ri-1)作为输入,执行递归成员,返回子结果集(记为 Ri),直到满足终止条件。
- 合并所有结果集:将所有迭代的结果集(R0, R1, …, Rn)通过
UNION ALL操作符合并,生成最终的结果集。
通过这种分步执行的方式,递归 CTE 能够高效地处理层次化数据,直到满足终止条件为止。
7.4.2 简单示例
以下示例展示了如何使用递归 CTE 返回从 Monday 到 Saturday 的工作日名称:
WITH cte_numbers(n, weekday)
AS (-- 锚点成员SELECT0,DATENAME(DW, 0)UNION ALL-- 递归成员SELECTn + 1,DATENAME(DW, n + 1)FROMcte_numbersWHERE n < 6
)
SELECTweekday
FROMcte_numbers;
输出结果如下:
| weekday |
|---|
| Monday |
| Tuesday |
| Wednesday |
| Thursday |
| Friday |
| Saturday |
在这个示例中:
- 锚点成员返回
Monday:SELECT0,DATENAME(DW, 0) - 递归成员从
Tuesday开始,逐天递增,直到Saturday:SELECTn + 1,DATENAME(DW, n + 1) FROMcte_numbers WHERE n < 6 WHERE n < 6是终止条件,当n达到 6 时,递归停止。
7.4.3 查询层次化数据
在5.6.2 章节中,我们使用自连接查询 sales.staffs 表中,每个员工及的直接上级。 sales.staffs 表结构如下所示,表中存储了员工的姓名、邮箱以及其直接上级的 ID(manager_id):

在这个表中,manager_id 为 NULL 的员工是顶级管理者,以下示例使用递归 CTE 查询顶级管理者的全部下属:
WITH cte_org AS (-- 锚点成员:获取顶级管理者SELECTstaff_id,first_name,manager_idFROMsales.staffsWHERE manager_id IS NULLUNION ALL-- 递归成员:获取下属SELECTe.staff_id,e.first_name,e.manager_idFROMsales.staffs eINNER JOIN cte_org oON o.staff_id = e.manager_id
)
SELECT * FROM cte_org;

在这个示例中:
- 锚点成员获取顶级管理者(
manager_id IS NULL)。 - 递归成员通过
INNER JOIN将每个员工与其直接上级关联,从而递归地获取所有下属。 - 递归查询会一直执行,直到没有更多的下属可以匹配。
八、高级查询
8.1 CASE:实现条件逻辑
在 SQL Server 中,CASE 表达式可以添加类似编程语言中的 if-else 逻辑,其基本语法如下:
CASE inputWHEN e1 THEN r1WHEN e2 THEN r2...WHEN en THEN rn[ ELSE re ]
END
8.1.1 简单 CASE 表达式(等值判断)
简单 CASE 表达式会直接比较输入表达式与 WHEN 子句中的值,若匹配则返回对应 THEN 子句的结果;否则返回 ELSE 的结果;若无匹配项且无 ELSE 子句,则返回 NULL。由于 CASE 是一个表达式,因此您可以在接受表达式的任何子句中使用它,例如 SELECT、WHERE、GROUP BY 和 HAVING。
-
在 SELECT 子句中使用简单 CASE 表达式
假设我们有一个名为sales.orders的表,其中包含订单状态(order_status,以数字表示)和订单日期(order_date)。我们可以通过简单CASE表达式将订单状态转换为更易理解的文本描述:SELECTCASE order_statusWHEN 1 THEN 'Pending'WHEN 2 THEN 'Processing'WHEN 3 THEN 'Rejected'WHEN 4 THEN 'Completed'END AS order_status,COUNT(order_id) AS order_count FROMsales.orders WHEREYEAR(order_date) = 2018 GROUP BYorder_status;
-
在聚合函数中使用简单 CASE 表达式
以下查询在聚合函数中使用 简单CASE表达式统计了 2018 年每种订单状态的数量:SELECTSUM(CASEWHEN order_status = 1THEN 1ELSE 0END) AS 'Pending',SUM(CASEWHEN order_status = 2THEN 1ELSE 0END) AS 'Processing',SUM(CASEWHEN order_status = 3THEN 1ELSE 0END) AS 'Rejected',SUM(CASEWHEN order_status = 4THEN 1ELSE 0END) AS 'Completed',COUNT(*) AS Total FROMsales.orders WHEREYEAR(order_date) = 2018;在这个查询中,
CASE表达式根据order_status的值返回 1 或 0,然后通过SUM()函数对每种状态的订单数量进行统计。
8.1.2 搜索 CASE 表达式
与简单 CASE 表达式不同,搜索 CASE 表达式中的 WHEN 子句包含布尔表达式,而不是简单的等值比较。它会按顺序评估每个布尔表达式,如果某个布尔表达式为 TRUE,则返回对应的 THEN 子句中的结果;否则返回 ELSE 子句中的结果,没有ELSE 子句则返回 NULL。
假设我们有一个订单表 sales.orders 和订单明细表 sales.order_items,以下查询可以根据订单金额对订单进行分类:
SELECTo.order_id,SUM(quantity * list_price) AS order_value,CASEWHEN SUM(quantity * list_price) <= 500THEN 'Very Low'WHEN SUM(quantity * list_price) > 500 ANDSUM(quantity * list_price) <= 1000THEN 'Low'WHEN SUM(quantity * list_price) > 1000 ANDSUM(quantity * list_price) <= 5000THEN 'Medium'WHEN SUM(quantity * list_price) > 5000 ANDSUM(quantity * list_price) <= 10000THEN 'High'WHEN SUM(quantity * list_price) > 10000THEN 'Very High'END AS order_priority
FROMsales.orders o
INNER JOIN sales.order_items i ON i.order_id = o.order_id
WHEREYEAR(order_date) = 2018
GROUP BYo.order_id;

8.2 COALESCE 表达式:处理查询中的 NULL 值
COALESCE 表达式是 SQL Server 中处理 NULL 值的高效工具。它能够从多个参数中选择第一个非空值,从而避免因 NULL 值导致的查询问题。无论是用于替换 NULL 值、选择可用数据,还是简化查询逻辑,COALESCE 都能提供简洁而强大的解决方案。
8.2.1 COALESCE基础功能
COALESCE 表达式语法如下:
COALESCE(e1, [e2, ..., en])
其中,e1, e2, ..., en 是标量表达式,COALESCE 会依次评估这些表达式,直到找到第一个非空值并返回。如果所有表达式都为 NULL,则返回 NULL。由于 COALESCE 是一个表达式,因此也可以在任何接受表达式的子句中使用。比如以下查询返回第一个非空字符串:
SELECTCOALESCE(NULL, 'Hi', 'Hello', NULL) AS result;
-- 输出结果为 Hi
SELECTCOALESCE(NULL, NULL, 100, 200) AS result;
-- 输出结果为 100
8.2.2 替换 NULL 值
在实际业务场景中,COALESCE 常用于将 NULL 值替换为更具意义的值。例如,假设有一个 sales.customers 表,其中某些客户的电话号码可能为空,为了使输出更具友好性,可以使用 COALESCE 将 NULL 值替换为字符串 'N/A':
SELECTfirst_name,last_name, COALESCE(phone, 'N/A') AS phone, -- 将原本的 phone 替换为这一句email
FROMsales.customers
ORDER BYfirst_name,last_name;

8.2.3 选择可用数据
假设有一个 salaries 表,存储员工的时薪、周薪或月薪,每个员工只能有一个工资标准。我们首先创建新表:
CREATE TABLE salaries (staff_id INT PRIMARY KEY,hourly_rate DECIMAL,weekly_rate DECIMAL,monthly_rate DECIMAL,CHECK(hourly_rate IS NOT NULL ORweekly_rate IS NOT NULL ORmonthly_rate IS NOT NULL)
);
插入一些数据:
INSERT INTO salaries (staff_id, hourly_rate, weekly_rate, monthly_rate)
VALUES(1, 20, NULL, NULL),(2, 30, NULL, NULL),(3, NULL, 1000, NULL),(4, NULL, NULL, 6000),(5, NULL, NULL, 6500);
直接查询,会返回很多NULL:
SELECTstaff_id, hourly_rate, weekly_rate, monthly_rate
FROMsalaries
ORDER BYstaff_id;
使用 COALESCE 可正确返回每个员工的月薪:
SELECTstaff_id,COALESCE(hourly_rate * 22 * 8,weekly_rate * 4,monthly_rate) AS monthly_salary
FROMsalaries;

在这个例子中,COALESCE 依次检查 hourly_rate、weekly_rate 和 monthly_rate,并返回第一个非空值,从而正确计算每个员工的月薪。
8.2.4 COALESCE表达式 VS CASE表达式
COALESCE 表达式实际上是 CASE 表达式的一种语法糖。以下两个表达式返回相同的结果:
COALESCE(e1, e2, e3)CASEWHEN e1 IS NOT NULL THEN e1WHEN e2 IS NOT NULL THEN e2ELSE e3
END
虽然
COALESCE的语法更简洁,但查询优化器可能会将其重写为更为通用的CASE表达式。
8.3 NULLIF 表达式:条件性返回 NULL
8.3.1NULLIF 基础语法
NULLIF 表达式接受两个参数(标量表达式),如果这两个参数相等,则返回 NULL,否则返回第一个参数的值。它在处理数据时可以有效避免因重复值导致的逻辑错误,尤其在处理遗留数据或需要清理数据时非常有用。其语法如下:
NULLIF(expression1, expression2)
不建议在
NULLIF中使用时间依赖函数,如RAND(),因为这可能导致函数被多次评估并返回不同的结果。
比如直接处理数值数据
SELECTNULLIF(10, 10) AS result;
-- 输出结果为 NULL
SELECTNULLIF(20, 10) AS result;
-- 输出结果为20
8.3.2 将空字符串转换为 NULL
在处理遗留数据时,常常会遇到某些字段中既有 NULL 值,也有空字符串。NULLIF 可以方便地将空字符串转换为 NULL,从而使数据更加一致。比如有一个sales.leads表:

使用 NULLIF 将空字符串转换为 NULL:
SELECTlead_id,first_name,last_name,NULLIF(phone, '') AS phone,email
FROMsales.leads
ORDER BYlead_id;

8.3.3 条件查询
NULLIF 还可以用于条件查询。例如,要查找没有电话号码的销售线索,可以使用以下查询:
SELECTlead_id,first_name,last_name,phone,email
FROMsales.leads
WHEREphone IS NULL;
然而,如果某些记录的 phone 字段是空字符串而不是 NULL,上述查询会遗漏这些记录。

此时可以使用 NULLIF 来解决这个问题,以下查询会正确地返回所有 phone 字段为 NULL 或空字符串的记录。
SELECTlead_id,first_name,last_name,phone,email
FROMsales.leads
WHERENULLIF(phone, '') IS NULL;

8.3.4 NULLIF 表达式VS CASE 表达式
NULLIF 表达式可以被视为 CASE 表达式的一种简化形式。以下两个表达式是等效的:
NULLIF(a, b)
等效于:
CASEWHEN a = b THEN NULLELSE a
END
例如:
DECLARE @a INT = 10, @b INT = 20;
SELECTNULLIF(@a, @b) AS result;
-- 输出结果为10
使用 CASE 表达式可以实现相同的功能:
DECLARE @a INT = 10, @b INT = 20;
SELECTCASEWHEN @a = @b THEN NULLELSE @aEND AS result;
虽然 CASE 表达式更灵活,但 NULLIF 的语法更简洁,更易于阅读。
8.4 PIVOT :透视表
使用 PIVOT 进行透视操作时,需要按照以下步骤进行:
- 选择基础数据集:确定需要进行旋转的数据。
- 创建临时结果集:通过派生表或公共表表达式(CTE)创建临时结果。
- 应用 PIVOT 操作符:将临时结果集转换为旋转后的表格。
8.4.1 业务背景
为了演示 PIVOT 操作符的用法,我们使用示例数据库中的 production.products 和 production.categories 表:

我们首先通过以下查询统计每个类别的产品数量:
SELECTcategory_name,COUNT(product_id) AS product_count
FROMproduction.products pINNER JOIN production.categories cON c.category_id = p.category_id
GROUP BYcategory_name;

我们的目标是将列转为行:

然后按model_year对类别进行分组:

8.4.2 直接转换
-
选择基础数据集:从
production.products和production.categories表中选择类别名称和产品 ID 作为基础数据:SELECTcategory_name,product_id FROMproduction.products pINNER JOIN production.categories cON c.category_id = p.category_id; -
创建临时结果集:使用派生表创建临时结果集:
SELECT * FROM (SELECTcategory_name,product_idFROMproduction.products pINNER JOIN production.categories cON c.category_id = p.category_id ) t; -
应用 PIVOT 操作符:将临时结果集转换为旋转后的表格:
SELECT * FROM (SELECTcategory_name,product_idFROMproduction.products pINNER JOIN production.categories cON c.category_id = p.category_id ) t PIVOT(COUNT(product_id)FOR category_name IN ([Children Bicycles],[Comfort Bicycles],[Cruisers Bicycles],[Cyclocross Bicycles],[Electric Bikes],[Mountain Bikes],[Road Bikes]) ) AS pivot_table;
-
添加额外列:在基础数据中添加额外列(如
model_year),可以在旋转后的表格中自动形成行分组:SELECT * FROM (SELECTcategory_name,product_id,model_yearFROMproduction.products pINNER JOIN production.categories cON c.category_id = p.category_id ) t PIVOT(COUNT(product_id)FOR category_name IN ([Children Bicycles],[Comfort Bicycles],[Cruisers Bicycles],[Cyclocross Bicycles],[Electric Bikes],[Mountain Bikes],[Road Bikes]) ) AS pivot_table;
8.4.3 动态生成列值
在上述查询中,我们需要手动输入每个类别名称作为 IN 子句的参数。为了避免手动输入,可以使用 QUOTENAME() 函数动态生成类别名称列表,然后将生成的类别名称列表复制到查询中。
DECLARE@columns NVARCHAR(MAX) = '';SELECT@columns += QUOTENAME(category_name) + ','
FROMproduction.categories
ORDER BYcategory_name;SET @columns = LEFT(@columns, LEN(@columns) - 1);PRINT @columns;
输出结果如下:
[Children Bicycles],[Comfort Bicycles],[Cruisers Bicycles],[Cyclocross Bicycles],[Electric Bikes],[Mountain Bikes],[Road Bikes]
QUOTENAME()函数将类别名称用方括号括起来,例如[Children Bicycles]。LEFT()函数移除字符串末尾的逗号。
8.4.4 动态 PIVOT 表
如果在 production.categories 表中添加新的类别名称,手动修改查询是不理想的。为了避免这种情况,可以使用动态 PIVOT 表:
-- 声明两个变量,用于存储动态生成的列名和最终的动态 SQL 查询
DECLARE@columns NVARCHAR(MAX) = '', -- 用于存储动态生成的列名列表@sql NVARCHAR(MAX) = ''; -- 用于存储最终构建的动态 SQL 查询-- 选择类别名称,并动态生成列名列表
-- 通过 QUOTENAME() 函数将每个 category_name 包裹在方括号中,确保列名符合 SQL 标准
-- 使用字符串拼接将所有列名连接起来,并用逗号分隔
SELECT@columns += QUOTENAME(category_name) + ','
FROMproduction.categories -- 从类别表中获取所有类别名称
ORDER BYcategory_name; -- 按类别名称排序,确保列的顺序一致-- 移除最后一个逗号
-- 因为在拼接列名时,每个列名后都加了一个逗号,所以需要移除最后一个多余的逗号
SET @columns = LEFT(@columns, LEN(@columns) - 1);-- 构建动态 SQL 查询
-- 使用动态生成的列名列表 @columns,构建 PIVOT 查询
SET @sql ='
SELECT * FROM
(SELECTcategory_name, -- 选择类别名称model_year, -- 选择模型年份(用于分组)product_id -- 选择产品 ID(用于聚合)FROMproduction.products p -- 从产品表中获取数据INNER JOIN production.categories c -- 通过类别表进行连接ON c.category_id = p.category_id
) t
PIVOT(COUNT(product_id) -- 对产品 ID 进行聚合,统计每个类别的产品数量FOR category_name IN (' + @columns + ') -- 使用动态生成的列名列表进行 PIVOT 操作
) AS pivot_table;'; -- 将结果命名为 pivot_table-- 执行动态 SQL 查询
-- 使用 sp_executesql 存储过程执行动态构建的 SQL 查询
EXECUTE sp_executesql @sql;
-
动态生成列名列表:
- 从
production.categories表中获取所有类别名称。 - 使用
QUOTENAME()函数将每个类别名称包裹在方括号中,确保列名符合 SQL 标准。 - 将所有列名用逗号分隔并拼接成一个字符串。
- 移除字符串末尾多余的逗号。
- 从
-
构建动态 SQL 查询:
- 从
production.products和production.categories表中选择基础数据。 - 使用
PIVOT操作符将类别名称从行转换为列,并对每个类别的产品数量进行统计。 - 动态生成的列名列表通过字符串拼接嵌入到
PIVOT查询中。
- 从
-
执行动态 SQL 查询:
- 使用
sp_executesql存储过程执行动态构建的 SQL 查询。 - 查询结果是一个旋转后的表格,其中每个类别名称对应一列,统计每个类别的产品数量。
- 使用
通过这种方式,可以实现动态生成 PIVOT 表,而无需手动修改查询中的列名。
8.5 UNPIVOT:逆透视表
在 SQL Server 中,UNPIVOT 操作符是 PIVOT 的逆操作,它用于将列数据转换为行数据。这种操作在数据转换和报表生成中也非常常见,尤其是在需要将宽表转换为长表的场景中。本文将通过实际示例,详细讲解如何使用 SQL Server 的 UNPIVOT 操作符。
8.5.1 UNPIVOT语法
UNPIVOT 将多个列的值转换为两列:一列包含原始列名,另一列包含对应的值。这种操作通常用于以下场景:
- 将宽表(包含多个列)转换为长表(包含较少列但更多行)。
- 对数据进行规范化处理,以便进行进一步的分析或处理。
UNPIVOT 的语法如下:
SELECT<非旋转列>,<新列名1> AS <列名1>,<新列名2> AS <列名2>
FROM<源表>
UNPIVOT
(<值列>FOR <列名列> IN (<列1>, <列2>, ...)
) AS <别名>;
<非旋转列>:在转换过程中保持不变的列。<新列名1>和<新列名2>:分别用于存储原始列名和对应的值。<源表>:需要进行UNPIVOT操作的表。<值列>:用于存储转换后的值。<列名列>:用于存储原始列名。<列1>, <列2>, ...:需要进行UNPIVOT操作的列。<别名>:为UNPIVOT的结果表指定一个别名。
8.5.2 简单示例
假设我们有一个销售数据表 sales,表结构如下:
| product_id | sales_q1 | sales_q2 | sales_q3 | sales_q4 |
|---|---|---|---|---|
| 1 | 100 | 150 | 200 | 250 |
| 2 | 120 | 180 | 220 | 280 |
我们的目标是将季度销售额从列转换为行,以便进行进一步分析。以下是实现步骤:
- 选择非旋转列:
product_id是非旋转列,它在转换过程中保持不变。 - 选择需要转换的列:
sales_q1,sales_q2,sales_q3,sales_q4是需要进行UNPIVOT操作的列。 - 构建 UNPIVOT 查询:
SELECTproduct_id, -- 非旋转列quarter, -- 存储原始列名sales -- 存储对应的值
FROMsales
UNPIVOT
(sales -- 值列FOR quarter IN (sales_q1, sales_q2, sales_q3, sales_q4) -- 列名列
) AS unpivot_table;
| product_id | quarter | sales |
|---|---|---|
| 1 | sales_q1 | 100 |
| 1 | sales_q2 | 150 |
| 1 | sales_q3 | 200 |
| 1 | sales_q4 | 250 |
| 2 | sales_q1 | 120 |
| 2 | sales_q2 | 180 |
| 2 | sales_q3 | 220 |
| 2 | sales_q4 | 280 |
8.5.3 动态 UNPIVOT
在实际应用中,表中的列可能不是固定的。为了使 UNPIVOT 操作更加灵活,可以使用动态 SQL 来动态生成需要转换的列名列表:
-
动态生成列名列表:
DECLARE @columns NVARCHAR(MAX) = ''; DECLARE @sql NVARCHAR(MAX) = '';-- 获取需要进行 UNPIVOT 操作的列名 SELECT@columns += QUOTENAME(column_name) + ',' FROMINFORMATION_SCHEMA.COLUMNS WHERETABLE_NAME = 'sales'AND COLUMN_NAME LIKE 'sales_q%'; -- 假设列名以 'sales_q' 开头-- 移除最后一个逗号 SET @columns = LEFT(@columns, LEN(@columns) - 1); -
构建动态 UNPIVOT 查询:
SET @sql = ' SELECTproduct_id,quarter,sales FROMsales UNPIVOT (salesFOR quarter IN (' + @columns + ') ) AS unpivot_table;';-- 执行动态 SQL EXEC sp_executesql @sql;