李宏毅 《生成式人工智能导论》| 第6讲-第8讲:大语言模型修炼史
文章目录
- 背景知识
- 机器怎么学会做文字接龙
- 找参数的挑战
- 如何让机器找到比较合理的参数
- 第一阶段:自我学习,累计实力 pre-train
- 第二阶段:名师指导,发挥潜力 Instruction Fine-tuning
- Adapter适配器
- Fine-tuning
- 第三阶段:参与实战,打磨技巧 Reinforcement Learning from Human Feedback(RLHF)
- RLAIF
大语言模型的三个阶段的总结
所有的阶段都是在学习文字接龙,只是训练的资料不同。

背景知识
在文字接龙中,每次产生出来的符号被叫做token

机器怎么学会做文字接龙
模型:有大量未知参数的函数

找参数的挑战
- 寻找超参数:调参数指的是调超参数
设置超参数,寻找参数。没有寻找到参数,就换一组超参数。

- 训练成功,但测试失败
在训练资料中,找到合适的参数让训练成果。但是在测试时,使用新的图片结果识别错误。

如何让机器找到比较合理的参数
- 增加训练资料的多样性:比如增加黄色的猫,黑色的狗

- 设置合适的初始参数:可以把好的参数看作是先验知

第一阶段:自我学习,累计实力 pre-train
问题1:需要多少文字才能够学会文字接龙?
得到一个token需要多少文字呢?论文指出即使学习300亿文字还是学不会复杂多层的世界知识。

Self-supervised Learning自监督学习:非常少人工介入就可以获取训练资料的方式。
自监督学习是一种无需人工标注标签的机器学习范式,核心思想是通过设计“代理任务”(Pretext Task),从数据自身结构生成监督信号,让模型从未标注数据中学习通用特征表示。它介于监督学习和无监督学习之间,显著降低了对昂贵标注数据的依赖。

虽然使用网络上的资料,但还是需要少量人工处理。下面的论文介绍了在训练大模型时过滤掉了哪些资料。

在ChatGPT之前就开发了GPT模型,这些模型就是使用大量从网络上找到的文字训练出来的。

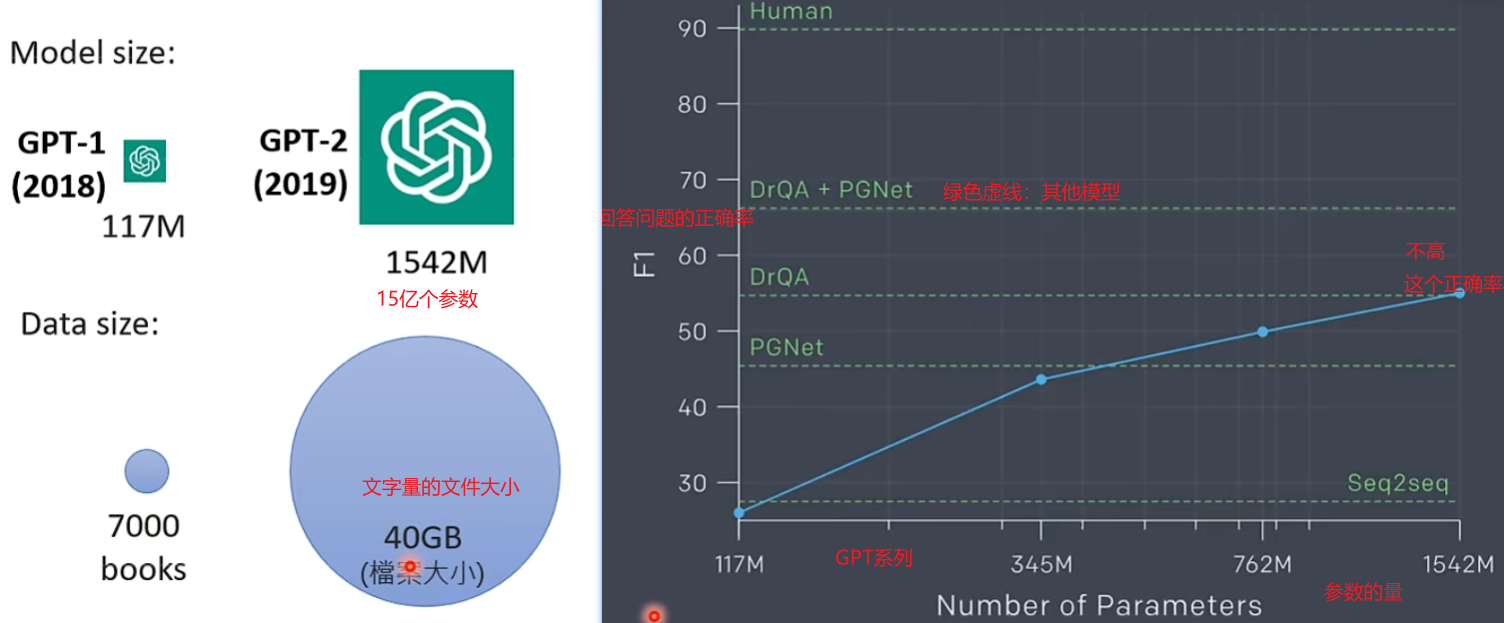
GPT-1、GPT-2没什么特别的效果,开发者猜想是模型不够大,所以改进的思路是开发一个更大的模型。
GPT-3使用了巨大的模型和巨大的训练资料,但其实模型训练出来效果也不怎么样,问题回答的正确率大概55%+。

当年很多人觉得OpenAI走错方向了,做文字接龙不断地接怎么可能接出人工智能。随后,研究者通过实验发现再训练更大的模型也没有用了,模型还是会乱回答问题。直觉上来讲也是正常的,因为模型所有的学习都来自于网络,并没有人工干预教学应该怎么回答问题。
第1个阶段的特征:语言模型跟网络资料学习了很多东西,但并不知道使用的方法。
第二阶段:名师指导,发挥潜力 Instruction Fine-tuning
第1个阶段的特征:语言模型跟网络资料学习了很多东西,但并不知道使用的方法。
解决办法:人类老师进行教学 - Instruction Fine-tuning
指令微调(Instruction Fine-tuning,IFT)是一种针对大型语言模型(LLM)的微调技术,旨在通过有监督训练使模型理解和执行自然语言指令,从而提升其在特定任务中的表现和泛化能力。

输入的句子需要标明哪一部分是使用者讲的,哪一部分是AI回答的


问题:如果需要人类老师教学,为什么最开始不直接让人类老师教学,还需要第一阶段的存在?
解答:人力很贵,没有办法收集太多资料。只用人类老师资料教学(即使上百万资料),模型可能会学歪。

:::tips
当前语言模型成功的关键:使用了第一阶段学习到的参数作为第二阶段的初始参数
:::
第二阶段最优化之后的参数不会和第一阶段差太多,只是针对第一阶段的参数进行微调。
如果把有用人类资料学习的过程看作真正的学习,那么称从网络中资料进行学习的过程(第一阶段)为预训练pre-train

**问题:**为什么第一阶段获取的参数作为第二阶段参数是一个好的初始参数
回答:第一阶段在pre-train的时候,语言模型看过非常大量的资料,这时学习到的参数在非常大量的资料上都可以成功的做文字接龙(学习复杂的规则做文字接龙)。那么作为初始参数对于第二阶段来说就不会学习出与初始参数差太远奇怪的模型,会学习到和初始参数比较近有道理的模型。

因为第一阶段学习到复杂的规则做文字接龙,说不定在第二阶段做最佳化后,模型具有很强的举一反三能力。
在预训练时学习第一句,在最佳化后可能学会第二句文字接龙的方法(在预训练时可能知道最高山是什么,但是不知道怎么回答)


19年的论文实验结果表明好的pre-train模型,在Instruction Fine-tuning的时候就可以有非常好的举一反三的能力

Adapter适配器
问题:会不会最佳化的过程找出来的参数和初始参数很不一样?
回答:可以使用小技巧Adapter参数高效微调技术- 通过在预训练模型的层间插入轻量级模块,仅训练新增参数以适应下游任务,同时冻结原始模型参数。 eg:LoRA
这个技术还有其他好处,比如新增参数量仅为原模型的 1%-10%,减少运算量等
具体实现:假设已经有初始参数了,在进行最佳化寻找参数的过程中,不改变初始参数,在原有的函数后面新增少量参数。

随着新增参数插入的位置、数量不同有各种不一样的Adapter
Fine-tuning
- 路线1:打造一堆专用模型,负责特定任务

- 路线2:直接打造一个通用模型

19年论文的想法:也没有办法一次性收集到大量任务的资料,但是可以一个任务一个任务去教学模型。
当时存在的问题是如果让模型连续学一大堆任务,可能会忘记旧的任务。
贡献:设计一个有趣的方法让模型可以在脑中复习学过的知识

很多研究者都去尝试使用大量不同任务资料(比如翻译任务的资料,摘要任务的资料…)去训练模型,从而打造一个通用模型。相关研究的论文都表明Instruction Fine-tuning不需要大量的资料,只使用了万笔资料。
问题:我们自己也可以做Instruction Fine-tuning吗?
回答:其实是不行的,因为我们没有高质量的Instruction Fine-tuning资料,有一个思路是以ChatGPT为老师,对ChatGPT做逆向工程看看能不能知道ChatGPT用了什么Instruction Fine-tuning资料。 – 常用的办法:对ChatGPT做逆向工程得到资料。
论文《The False Promise of …》表明对ChatGPT做逆向工程得到的资料可能没有那么优质,但聊聊胜于无。

假设我们已经从ChatGPT做逆向工程得到了少量资料,但是我们并没有第一阶段Pre-train的参数!!!
直到某一天,Meta开源了LLaMA,可以使用LLaMA的参数作为初始参数去微调自己的模型。

开源2周后,Stanford打造了Alpaca,又过了2周,其他学校打造了Vicuna。至此开始,大家都可以训练自己的大型语言模型。

第三阶段:参与实战,打磨技巧 Reinforcement Learning from Human Feedback(RLHF)
前两个阶段的训练资料都是输入以及下一步做文字接龙该有的输出
- 第一阶段:Pre-train
- 第二阶段:Instruction Fine-tuning
第二阶段的输出是人提供的,所以称为监督学习Supervised Learning
- 第三阶段:RLHF:训练资料是某一个答案好过另外一个答案,
强化学习:通过反馈信息学习的方法,其核心思想是让智能体(Agent)通过与环境交互,根据获得的奖励信号调整行为策略,以最大化长期累积奖励。

从人类产生训练资料的角度看:第二阶段和第三阶段都需要人类介入,RLHF的一个好处是有时人类写出正确答案不容易,但判断答案好坏比较容易。

从模型学习的角度来看:Instruction Fine-tuning只问过程,不问结果。RLHF只问结果,不问过程。

问题:人类反馈的信息是A答案比B答案好,为什么不能直接反馈模型生成的A答案好?
解答:根据实际的经验来说,其实判断答案的好坏是相对的,没办法就一个答案直接评论好坏,因为每个人的标准不一样。

问题:对语言模型的RLHF来说,如何有效利用人类的回馈。
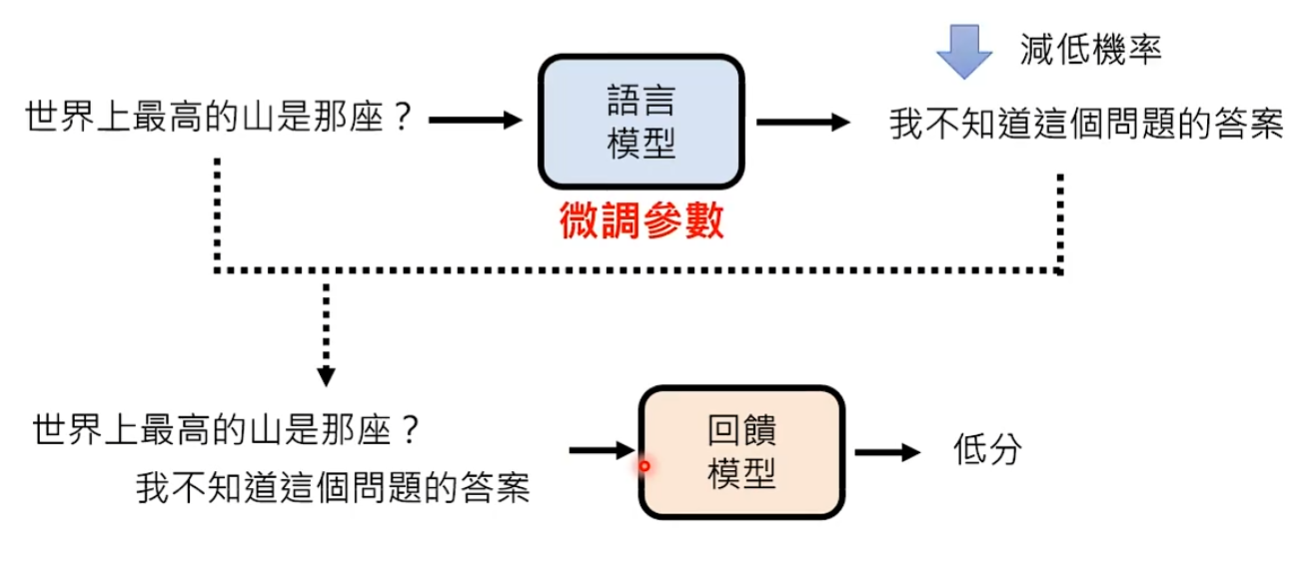
解答:训练一个奖励模型Reward Model来模仿人类喜好

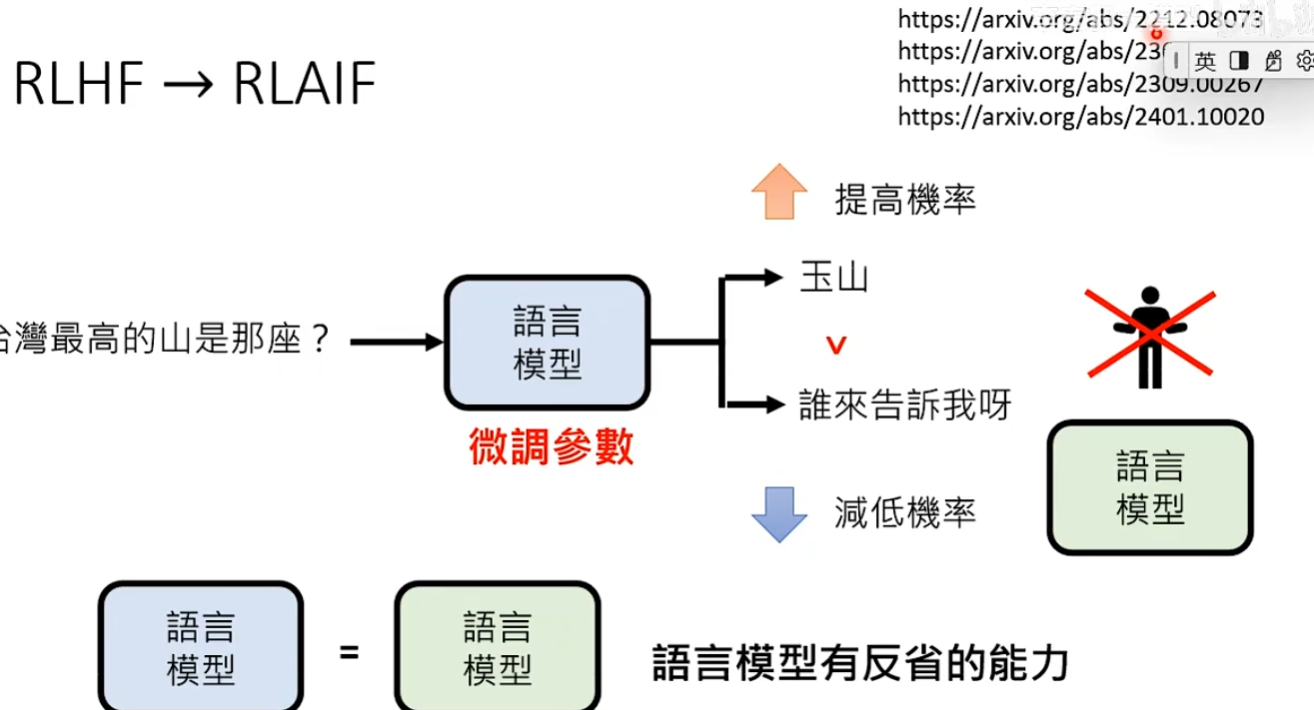
奖励模型的一种使用方式:对于一个问题,语言模型可以产生多个答案,然后将每一个答案喂给Reward Model让他评分,评分越高代表这个答案可能是人类认为最好的答案,最后只给人类看分数最高的答案。

目前最常用的方式:让语言模型直接对回馈模型进行学习。
当语言模型得到一个答案后,直接将问题+答案接起来输给回馈模型评分。如果给低分,说明这个答案是人类会觉得不好的答案,模型进行微调参数,降低这个不好答案出现的概率。如果给高分,模型就微调参数让好的答案出现的概率提高。

2020年一篇论文发现,完全向虚拟人类学习可能是有害的。比如论文中实验的模型是做摘要的模型,实验发现过度向人类学习的模型输出的答案喜欢在最后添加pls,中间添加???

向虚拟老师学习的方式存在缺点,很多研究者试图开发新的、不需要虚拟老师的算法,比如DPO(作业中会用到)、KTO等。至于这些算法最后能不能取代虚拟老师,还需要时间的验证。Deepseek使用的是自研的强化学习算法GRPO。

问题:强化学习有个难题,什么叫做好?
衍生问题:假设语言模型越来越厉害,如果他遇见的问题是连人类自己都无法判断的?


RLAIF
当AI的能力更强之后,也许下一阶段可以做RLAIF,由AI来提供语言模型回馈,直接用语言模型去评价另外一个语言模型输出的好坏。
目前有论文尝试,用GPT-4扮演人类给自己的模型提供回馈。提供回馈的语言模型甚至可以和训练的语言模型是同一个(因为语言模型有反省的能力)。