【RocketMQ 生产者和消费者】- 消费者重平衡(2)- 分配策略
文章目录
- 1. 前言
- 2. 入口
- 3. 分配策略
- 3.1 AllocateMessageQueueAveragely 平均分配
- 3.2 AllocateMessageQueueAveragelyByCircle 负载均衡分配队列, 环形分配
- 3.3 AllocateMessageQueueByConfig 根据配置分配消息队列
- 3.4 AllocateMessageQueueConsistentHash 一致性 hash 分配
- 3.5 AllocateMachineRoomNearby 通过机房分组
- 3.6 AllocateMachineRoomNearby 通过机房分组
- 4. 小结
本文章基于 RocketMQ 4.9.3
1. 前言
- 【RocketMQ】- 源码系列目录
- 【RocketMQ 生产者消费者】- 同步、异步、单向发送消费消息
- 【RocketMQ 生产者和消费者】- 消费者启动源码
- 【RocketMQ 生产者和消费者】- 消费者重平衡(1)
上一篇讲解了消费者重平衡的入口和大致源码,还剩下一点 RocketMQ 的几个重平衡策略。
2. 入口
在 rebalanceByTopic 方法中,当消费模式是集群模式的时候,会基于负载均衡策略确定分配给当前消费者的 MessageQueue,分配的方法是 strategy.allocate。

要想知道 allocateMessageQueueStrategy 到底是什么策略,就需要知道 allocateMessageQueueStrategy 是在哪初始化的,这就要回到 Consumer 的构造器了。
在创建 DefaultMQPushConsumer 的时候我们是只设置了一个 consumerGroup,其他参数都没有设置,所以默认创建的就是 AllocateMessageQueueAveragely 策略,也就是平均分配策略。


可以看到最后也是将这个策略设置到了 allocateMessageQueueStrategy 中,而在消费者的 start 方法中又把这个属性设置到了重平衡服务中。

所以最终重平衡默认就是用的 allocateMessageQueueStrategy,那么下面就来看下除了这个默认策略之外,RocketMQ 还提供了哪些策略。
3. 分配策略
分配的接口是 allocate,接收四个传参,可以看下面接口定义,就能得知消费者负载均衡是根据消费者 ID 来负载的。
/*** Allocating by consumer id** @param 消费者组* @param 当前消费者 ID* @param 订阅的 topic 下面的所有消息队列* @param 消费者组下面的所有消费者的 clientID 集合* @return The allocate result of given strategy*/
List<MessageQueue> allocate(final String consumerGroup,final String currentCID,final List<MessageQueue> mqAll,final List<String> cidAll
);
3.1 AllocateMessageQueueAveragely 平均分配
/*** 负载均衡分配队列, 平均分配* @param consumerGroup 当前消费者组* @param currentCID 当前消费者的 clientID* @param mqAll 当前 topic 的所有队列* @param cidAll 当前消费者组的所有消费者的 clientID* @return*/
@Override
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll,List<String> cidAll) {// 参数校验if (currentCID == null || currentCID.length() < 1) {throw new IllegalArgumentException("currentCID is empty");}if (mqAll == null || mqAll.isEmpty()) {throw new IllegalArgumentException("mqAll is null or mqAll empty");}if (cidAll == null || cidAll.isEmpty()) {throw new IllegalArgumentException("cidAll is null or cidAll empty");}// 分配结果List<MessageQueue> result = new ArrayList<MessageQueue>();if (!cidAll.contains(currentCID)) {// 如果这个消费者不是传入的消费者组下的, 有可能是刚启动没注册到 brokerlog.info("[BUG] ConsumerGroup: {} The consumerId: {} not in cidAll: {}",consumerGroup,currentCID,cidAll);// 就不分配队列处理了return result;}// 假设现在有 8 个队列, 要负载均衡给 3 个消费者 [0, 1, 2], 而当前消费者[1]的 index = 1// 那么在分配的时候三个消费者分配的队列标号就是 [0, 1, 2], [3, 4, 5], [6, 7]// 这里就是求出来当前消费者 ID 所在的位置 = 1int index = cidAll.indexOf(currentCID);// 队列数 % 消费者数 = 剩余队列数 = 2int mod = mqAll.size() % cidAll.size();// 这里求平均数, 求出来的结果就是 8 / 3 + 1 = 3// 1.如果队列数小于消费者数, 平均数就是 1// 2.如果队列数大于消费者数, 并且当前队列的下标在 (0, mod) 这个范围, 那么平均数就是 mqAll.size() / cidAll.size() + 1// 3.如果队列数大于消费者数, 并且当前队列的下标在 [mod, cidAll.size()) 这个范围, 那么平均数就是 mqAll.size() / cidAll.size()int averageSize =mqAll.size() <= cidAll.size() ? 1 : (mod > 0 && index < mod ? mqAll.size() / cidAll.size()+ 1 : mqAll.size() / cidAll.size());// 计算当前消费者从哪里开始分配队列, 这里求出来的就是 1 * 3 = 3int startIndex = (mod > 0 && index < mod) ? index * averageSize : index * averageSize + mod;// 这里求出来当前消费者要分配多少个队列, 比如当前就是分配 3 个队列int range = Math.min(averageSize, mqAll.size() - startIndex);for (int i = 0; i < range; i++) {// 开始分配队列, 分配的起始位是是 startIndex, 分配的队列数量是 rangeresult.add(mqAll.get((startIndex + i) % mqAll.size()));}return result;
}
平均分配的策略就是就是将队列数量按照消费者数量平均分配,假设现在有 8 个队列,要负载均衡给 3 个消费者 [0, 1, 2],而当前消费者 [1] 的 index = 1,那么在分配的时候三个消费者分配的队列标号就是 [0, 1, 2],[3, 4, 5],[6, 7]。
根据下面几个步骤分配:
- 首先就是求出当前消费者 ID 所在的下标,也就是上面的 1。
- 求出余数,也就是 8 % 3 = 2,余数是用来求下面的消息队列数量和范围的。
- 求出当前消费者可以分配到的消息队列数量 averageSize,过程如下:
- 如果队列数小于消费者数,平均数就是
1,队列会从前往后分配给消费者。 - 如果队列数大于消费者数,并且当前队列的下标在 (0, mod) 这个范围,那么平均数就是
mqAll.size() / cidAll.size() + 1,比如当前 index = 1,那么就可以分配到 3 个队列。 - 如果队列数大于消费者数,并且当前队列的下标在
[mod, cidAll.size())这个范围, 那么平均数就是mqAll.size() / cidAll.size(),说明当前消费者在靠后的位置。。
- 如果队列数小于消费者数,平均数就是
算出来当前消费者可以分配多少个消息队列之后,计算当前消费者从哪里开始分配队列,计算方式就是如果 index 在 mod 之前,就通过 index * averageSize,否则就是 index * averageSize + mod,range 就是要分配多少个队列,求一个最小值,因为如果是靠后的有可能 startIndex + averageSize 超过了数组,就越界了,最终遍历分配。
可能看着有点绕,总之记住就是平均分配,只是这种平均分配是求出分配的消息队列整体数量,然后求出分配的起始下标,再从原集合中去获取。

下面我们自己写一个 main 方法测试下。
public static void main(String[] args) {AllocateMessageQueueAveragely allocateMessageQueueAveragely = new AllocateMessageQueueAveragely();List<MessageQueue> queues = new ArrayList<MessageQueue>();for(int i = 0; i < 8; i++){queues.add(new MessageQueue("topic-test", "broker-a", i));}System.out.println(allocateMessageQueueAveragely.allocate("group", "0", queues, Arrays.asList("0", "1", "2")));System.out.println(allocateMessageQueueAveragely.allocate("group", "1", queues, Arrays.asList("0", "1", "2")));System.out.println(allocateMessageQueueAveragely.allocate("group", "2", queues, Arrays.asList("0", "1", "2")));
}
输出结果如下:
[MessageQueue [topic=topic-test, brokerName=broker-a, queueId=0], MessageQueue [topic=topic-test, brokerName=broker-a, queueId=1], MessageQueue [topic=topic-test, brokerName=broker-a, queueId=2]]
[MessageQueue [topic=topic-test, brokerName=broker-a, queueId=3], MessageQueue [topic=topic-test, brokerName=broker-a, queueId=4], MessageQueue [topic=topic-test, brokerName=broker-a, queueId=5]]
[MessageQueue [topic=topic-test, brokerName=broker-a, queueId=6], MessageQueue [topic=topic-test, brokerName=broker-a, queueId=7]]
3.2 AllocateMessageQueueAveragelyByCircle 负载均衡分配队列, 环形分配
这个也是平均分配,但是跟上面的不同,这个是一个一个分配,啥意思呢,看下面源码。
/*** 负载均衡分配队列, 环形分配* @param consumerGroup 当前消费者组* @param currentCID 当前消费者的 clientID* @param mqAll 当前 topic 的所有队列* @param cidAll 当前消费者组的所有消费者的 clientID* @return*/
@Override
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll,List<String> cidAll) {// 参数校验if (currentCID == null || currentCID.length() < 1) {throw new IllegalArgumentException("currentCID is empty");}if (mqAll == null || mqAll.isEmpty()) {throw new IllegalArgumentException("mqAll is null or mqAll empty");}if (cidAll == null || cidAll.isEmpty()) {throw new IllegalArgumentException("cidAll is null or cidAll empty");}// 分配结果List<MessageQueue> result = new ArrayList<MessageQueue>();if (!cidAll.contains(currentCID)) {// 如果这个消费者不是传入的消费者组下的, 有可能是刚启动没注册到 brokerlog.info("[BUG] ConsumerGroup: {} The consumerId: {} not in cidAll: {}",consumerGroup,currentCID,cidAll);// 直接返回, 不分配了return result;}// 获取当前消费者的下标int index = cidAll.indexOf(currentCID);for (int i = index; i < mqAll.size(); i++) {// 比如当前消息队列是 0, 1, 2, 3, 4, 5, 6, 7, 8// 当前消费者是 1// 那么分配的队列就是 1, 4, 7if (i % cidAll.size() == index) {result.add(mqAll.get(i));}}return result;
}
这个分配策略的源码不多,可以看到分配就直接求出当前消费者的下标,然后开始遍历,只要符合 i % cidAll.size() == index 就说明这个队列可以分配给当前消费者,其实从 0 开始遍历也可以,不过从 index 开始会少几次判断。

同样的,我们使用一个 main 方法来测试下:
public static void main(String[] args) {AllocateMessageQueueAveragelyByCircle averagelyByCircle = new AllocateMessageQueueAveragelyByCircle();List<MessageQueue> queues = new ArrayList<MessageQueue>();for(int i = 0; i < 8; i++){queues.add(new MessageQueue("topic-test", "broker-a", i));}System.out.println(averagelyByCircle.allocate("group", "0", queues, Arrays.asList("0", "1", "2")));System.out.println(averagelyByCircle.allocate("group", "1", queues, Arrays.asList("0", "1", "2")));System.out.println(averagelyByCircle.allocate("group", "2", queues, Arrays.asList("0", "1", "2")));
}
输出结果如下:
[MessageQueue [topic=topic-test, brokerName=broker-a, queueId=0], MessageQueue [topic=topic-test, brokerName=broker-a, queueId=3], MessageQueue [topic=topic-test, brokerName=broker-a, queueId=6]]
[MessageQueue [topic=topic-test, brokerName=broker-a, queueId=1], MessageQueue [topic=topic-test, brokerName=broker-a, queueId=4], MessageQueue [topic=topic-test, brokerName=broker-a, queueId=7]]
[MessageQueue [topic=topic-test, brokerName=broker-a, queueId=2], MessageQueue [topic=topic-test, brokerName=broker-a, queueId=5]]
3.3 AllocateMessageQueueByConfig 根据配置分配消息队列
/*** 负载均衡分配队列, 用户自定义消费者需要消费的队列* @param consumerGroup 当前消费者组* @param currentCID 当前消费者的 clientID* @param mqAll 当前 topic 的所有队列* @param cidAll 当前消费者组的所有消费者的 clientID* @return*/
@Override
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll,List<String> cidAll) {return this.messageQueueList;
}
这个负载均衡类可以自己手动设置消息队列。
3.4 AllocateMessageQueueConsistentHash 一致性 hash 分配
/*** 负载均衡分配队列, 一致性 hash 分配* @param consumerGroup 当前消费者组* @param currentCID 当前消费者的 clientID* @param mqAll 当前 topic 的所有队列* @param cidAll 当前消费者组的所有消费者的 clientID* @return*/
@Override
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll,List<String> cidAll) {// 参数校验if (currentCID == null || currentCID.length() < 1) {throw new IllegalArgumentException("currentCID is empty");}if (mqAll == null || mqAll.isEmpty()) {throw new IllegalArgumentException("mqAll is null or mqAll empty");}if (cidAll == null || cidAll.isEmpty()) {throw new IllegalArgumentException("cidAll is null or cidAll empty");}List<MessageQueue> result = new ArrayList<MessageQueue>();// 如果这个消费者不是传入的消费者组下的, 有可能是刚启动没注册到 brokerif (!cidAll.contains(currentCID)) {log.info("[BUG] ConsumerGroup: {} The consumerId: {} not in cidAll: {}",consumerGroup,currentCID,cidAll);// 先不分配注册队列return result;}// 将所有消费者封转为 ClientNodeCollection<ClientNode> cidNodes = new ArrayList<ClientNode>();for (String cid : cidAll) {cidNodes.add(new ClientNode(cid));}// ConsistentHashRouter 就是用来根据 hash 环算法分配节点的final ConsistentHashRouter<ClientNode> router; //for building hash ringif (customHashFunction != null) {// 设置了 hash 函数, virtualNodeCnt 是虚拟节点个数, 默认 10 个router = new ConsistentHashRouter<ClientNode>(cidNodes, virtualNodeCnt, customHashFunction);} else {// 没有 hash 函数, 就用 MD5Hash 作为 hash 函数router = new ConsistentHashRouter<ClientNode>(cidNodes, virtualNodeCnt);}List<MessageQueue> results = new ArrayList<MessageQueue>();// 遍历所有消息队列for (MessageQueue mq : mqAll) {// 根据一致性 hash 算法来计算出当前这个 MessageQueue 要分配到哪个消费者ClientNode clientNode = router.routeNode(mq.toString());// 如果分配到的消费者是当前的消费者if (clientNode != null && currentCID.equals(clientNode.getKey())) {// 添加到 results 集合中results.add(mq);}}// 返回分配的队列结果return results;}
这个就是一致性 hash 算法,简单来说就是将消费者 ID 添加到 hash 环里面,每一个消费者都分配 10 个虚拟节点,避免分配不均的情况。
3.5 AllocateMachineRoomNearby 通过机房分组
这个分配策略激素hi通过将消息队列和消费者ID(CID)根据机房进行分组,然后优先分配同一机房的队列给同一机房的消费者,如果同一机房没有可用消费者,则将剩余的消息队列平均分配给其他机房的消费者。
/*** 负载均衡分配队列* @param consumerGroup 当前消费者组* @param currentCID 当前消费者的 clientID* @param mqAll 当前 topic 的所有队列* @param cidAll 当前消费者组的所有消费者的 clientID* @return*/
@Override
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll,List<String> cidAll) {// 参数校验if (currentCID == null || currentCID.length() < 1) {throw new IllegalArgumentException("currentCID is empty");}if (mqAll == null || mqAll.isEmpty()) {throw new IllegalArgumentException("mqAll is null or mqAll empty");}if (cidAll == null || cidAll.isEmpty()) {throw new IllegalArgumentException("cidAll is null or cidAll empty");}// 分配给当前消费者的队列结果List<MessageQueue> result = new ArrayList<MessageQueue>();if (!cidAll.contains(currentCID)) {// 如果当前消费者不是这个消费者组下的, 就不参与分配了, 有可能刚启动还没注册到 brokerlog.info("[BUG] ConsumerGroup: {} The consumerId: {} not in cidAll: {}",consumerGroup,currentCID,cidAll);return result;}// 将所有消费队列根据机房分组Map<String/*machine room */, List<MessageQueue>> mr2Mq = new TreeMap<String, List<MessageQueue>>();// 将消息队列按照机房分组for (MessageQueue mq : mqAll) {// 消息队列可以分配到不同的 broker, 这里就是从 brokerName 中获取这个 broker 所属的机房String brokerMachineRoom = machineRoomResolver.brokerDeployIn(mq);if (StringUtils.isNoneEmpty(brokerMachineRoom)) {// 添加到集合中if (mr2Mq.get(brokerMachineRoom) == null) {mr2Mq.put(brokerMachineRoom, new ArrayList<MessageQueue>());}mr2Mq.get(brokerMachineRoom).add(mq);} else {// 没找到机房, 抛出异常, 因为这个分配策略就是根据机房分配的throw new IllegalArgumentException("Machine room is null for mq " + mq);}}// 将所有消费者按照机房分组Map<String/*machine room */, List<String/*clientId*/>> mr2c = new TreeMap<String, List<String>>();for (String cid : cidAll) {// 获取消费者所属的机房String consumerMachineRoom = machineRoomResolver.consumerDeployIn(cid);if (StringUtils.isNoneEmpty(consumerMachineRoom)) {if (mr2c.get(consumerMachineRoom) == null) {mr2c.put(consumerMachineRoom, new ArrayList<String>());}mr2c.get(consumerMachineRoom).add(cid);} else {throw new IllegalArgumentException("Machine room is null for consumer id " + cid);}}List<MessageQueue> allocateResults = new ArrayList<MessageQueue>();// 1. allocate the mq that deploy in the same machine room with the current consumer// 1. 开始分配队列, 主要就是分配和传入的消费者在同一机房的队列String currentMachineRoom = machineRoomResolver.consumerDeployIn(currentCID);// 获取当前机房下面的消息队列List<MessageQueue> mqInThisMachineRoom = mr2Mq.remove(currentMachineRoom);// 获取当前机房下面的所有消费者List<String> consumerInThisMachineRoom = mr2c.get(currentMachineRoom);if (mqInThisMachineRoom != null && !mqInThisMachineRoom.isEmpty()) {// 根据传入的策略进行分配allocateResults.addAll(allocateMessageQueueStrategy.allocate(consumerGroup, currentCID, mqInThisMachineRoom, consumerInThisMachineRoom));}// 2. allocate the rest mq to each machine room if there are no consumer alive in that machine room// 2. 遍历所有剩余的队列, 这些队列跟当前消费者不在同一个机房for (Entry<String, List<MessageQueue>> machineRoomEntry : mr2Mq.entrySet()) {// 如果 machineRoomEntry.getKey() 这个机房在 mr2c 中没有消费者, 也就是说这个机房下面没有消费者去消费对应的队列,// 那么这些队列就应该分配给所有的消费者去消费, 也就是在下面调用 allocate 去分配if (!mr2c.containsKey(machineRoomEntry.getKey())) { // no alive consumer in the corresponding machine room, so all consumers share these queuesallocateResults.addAll(allocateMessageQueueStrategy.allocate(consumerGroup, currentCID, machineRoomEntry.getValue(), cidAll));}}// 返回当前消费者 ID 分配的结果return allocateResults;
}
这个分配策略会先将 topic 下面的所有消息队列按照机房分组,也就是处理 mr2Mq 集合。再将所有消费者按照机房分组,也就是处理 mr2c 集合。
分好组之后,获取当前消费者所在的机房,然后获取这个机房下面的消息队列和消费者,接着调用 allocateMessageQueueStrategy.allocate 对这个机房下面的消费者进行分配,这个 allocateMessageQueueStrategy 是真正的分配策略,AllocateMachineRoomNearby 就是按机房分组后,按照这个真正的分配策略去分配。
最后遍历剩余的 mr2Mq,如果 machineRoomEntry.getKey() 这个机房在 mr2c 中没有消费者,也就是说这个机房下面没有消费者去消费对应的队列,那么这些队列就应该分配给所有的消费者去消费。
所以总的来说就是如果消费者和消息队列在同一个机房,那么就同一个机房内的就用 allocateMessageQueueStrategy 去分配,如果消息队列所在的机房没有消费者的,就分配给这个消费者组下面的所有消费者。

下面我们就来模拟一下,还是用一个 main 方法,要注意一下就是创建 AllocateMachineRoomNearby 的时候需要传入真正的分配策略以及 MachineRoomResolver 的实现类,也就是我们可以自己定义如何获取消费者以及消息队列的机房。
/*** A resolver object to determine which machine room do the message queues or clients are deployed in.** AllocateMachineRoomNearby will use the results to group the message queues and clients by machine room.** The result returned from the implemented method CANNOT be null.*/
public interface MachineRoomResolver {String brokerDeployIn(MessageQueue messageQueue);String consumerDeployIn(String clientID);
}
下面就写一个 main 方法测试下,我们设置真实的分配方式为 AllocateMessageQueueAveragelyByCircle。
public static void main(String[] args) {// 使用 - 分割, 后面的就是机房MachineRoomResolver resolver = new MachineRoomResolver() {@Overridepublic String brokerDeployIn(MessageQueue messageQueue) {return messageQueue.getBrokerName().split("-")[1];}@Overridepublic String consumerDeployIn(String clientID) {return clientID.split("-")[1];}};// 消息队列List<MessageQueue> queues = new ArrayList<MessageQueue>();// 机房 A 的queues.add(new MessageQueue("topic", "broker-A", 0));queues.add(new MessageQueue("topic", "broker-A", 1));queues.add(new MessageQueue("topic", "broker-A", 2));// 机房 B 的queues.add(new MessageQueue("topic", "broker-B", 3));queues.add(new MessageQueue("topic", "broker-B", 4));queues.add(new MessageQueue("topic", "broker-B", 5));// 机房 C 的queues.add(new MessageQueue("topic", "broker-C", 6));queues.add(new MessageQueue("topic", "broker-C", 7));// 消费者队列List<String> cidAll = new ArrayList<String>();cidAll.add("Consumer1-A");cidAll.add("Consumer2-A");cidAll.add("Consumer3-C");cidAll.add("Consumer4-D");AllocateMachineRoomNearby allocateMachineRoomNearby = new AllocateMachineRoomNearby(new AllocateMessageQueueAveragelyByCircle(), resolver);System.out.println(allocateMachineRoomNearby.allocate("groupTest", "Consumer1-A", queues, cidAll));System.out.println(allocateMachineRoomNearby.allocate("groupTest", "Consumer2-A", queues, cidAll));System.out.println(allocateMachineRoomNearby.allocate("groupTest", "Consumer3-C", queues, cidAll));System.out.println(allocateMachineRoomNearby.allocate("groupTest", "Consumer4-D", queues, cidAll));}
}

可以看到,分配的结果如下:
- Consumer1-A:0,2,3
- Consumer2-A:1,4
- Consumer3-C:6,7,5
- Consumer3-D:
符合上面的解析流程,如果同机房就平均分配给同一机房的消费者,如果找不到对应机房的消费者就平均分配给所有消息队列。

3.6 AllocateMachineRoomNearby 通过机房分组
/*** 负载均衡分配队列, 根据机房平均分配* @param consumerGroup 当前消费者组* @param currentCID 当前消费者的 clientID* @param mqAll 当前 topic 的所有队列* @param cidAll 当前消费者组的所有消费者的 clientID* @return*/
@Override
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll,List<String> cidAll) {// 参数校验if (StringUtils.isBlank(currentCID)) {throw new IllegalArgumentException("currentCID is empty");}if (CollectionUtils.isEmpty(mqAll)) {throw new IllegalArgumentException("mqAll is null or mqAll empty");}if (CollectionUtils.isEmpty(cidAll)) {throw new IllegalArgumentException("cidAll is null or cidAll empty");}List<MessageQueue> result = new ArrayList<MessageQueue>();// 如果这个消费者不在对应消费者组下, 直接返回, 有可能是刚启动没注册到 brokerint currentIndex = cidAll.indexOf(currentCID);if (currentIndex < 0) {// 直接返回空集合, 不消费了return result;}List<MessageQueue> premqAll = new ArrayList<MessageQueue>();// 遍历所有 MessageQueuefor (MessageQueue mq : mqAll) {// 将 brokerName 根据 @ 分割, 格式就是 "机房名@brokerName", 如果 broker 所在机房在用户设置的 consumeridcs 集合中String[] temp = mq.getBrokerName().split("@");if (temp.length == 2 && consumeridcs.contains(temp[0])) {// 加入 premqAll 队列, 然后开始平均分配premqAll.add(mq);}}// 假设当前机房有 [0, 1, 2, 3, 4, 5, 6, 7], 而消费者组[0, 1, 2], 当前消费者 ID = 1// 所以这个消费者分配到的队列就是 [2, 3, 7]// 是这样的, 平均分配会先分配 mod 大小的数, 比如 [0, 1, 2] 三个消费者会先分配 [0, 1], [2, 3], [4, 5] 的队列// 然后剩余 [6, 7] 两个队列再分配给 [0, 1] 两个消费者, 所以最终分配结果就是:// [0, 1, 2] => 0: [0, 1, 6], 1: [2, 3, 7], 2: [4, 5]// 当前消费者能分到多少队列, 这里是 8 / 3 = 2int mod = premqAll.size() / cidAll.size();// 剩余的队列, 这里是 8 % 3 = 2int rem = premqAll.size() % cidAll.size();// 起始位置 = 2 * 1 = 2int startIndex = mod * currentIndex;// 结束位置 = 2 + 2 = 4int endIndex = startIndex + mod;// 先把平均分配的添加到队列中, 就是 [2, 3]for (int i = startIndex; i < endIndex; i++) {result.add(premqAll.get(i));}// 如果当前队列可以多分配一个if (rem > currentIndex) {// 获取下标 (1 + 2 * 3 = 7)result.add(premqAll.get(currentIndex + mod * cidAll.size()));}// 最终结果就是 [2, 3, 7]return result;
}
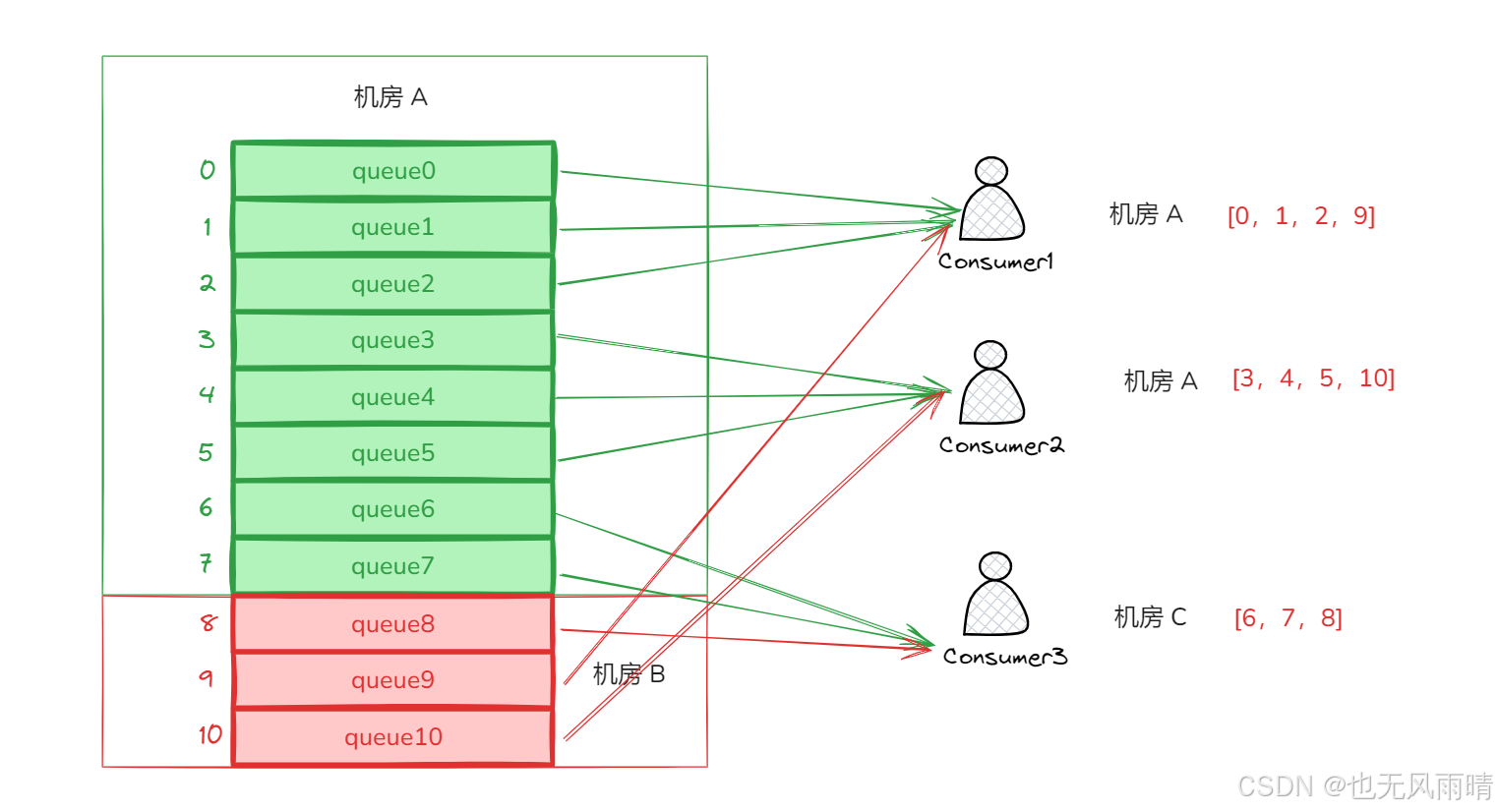
AllocateMachineRoomNearby 分配策略中用户可以设定需要分配的机房集合 consumeridcs,然后遍历所有消息队列,如果消息队列是用户设定的机房下面的,就加入 premqAll 集合等待分配。
分配的策略如下:假设当前机房有 [0,1,2,3,4,5,6,7],而消费者组 [0,1,2],当前消费者 ID = 1,所以这个消费者分配到的队列就是 [2,3,7],平均分配会先分配 mod 大小的数,比如 [0,1,2] 三个消费者会先分配 [0,1],[2,3],[4,5] 的队列,然后剩余 [6,7] 两个队列再分配给 [0,1] 两个消费者,所以最终分配结果就是: [0,1,2]。
下面写个测试用例来测试分配情况。
public static void main(String[] args) {AllocateMessageQueueByMachineRoom room = new AllocateMessageQueueByMachineRoom();// 消息队列List<MessageQueue> queues = new ArrayList<MessageQueue>();// 机房 A 的queues.add(new MessageQueue("topic", "A@broker", 0));queues.add(new MessageQueue("topic", "A@broker", 1));queues.add(new MessageQueue("topic", "A@broker", 2));queues.add(new MessageQueue("topic", "A@broker", 3));queues.add(new MessageQueue("topic", "A@broker", 4));queues.add(new MessageQueue("topic", "A@broker", 5));queues.add(new MessageQueue("topic", "A@broker", 6));queues.add(new MessageQueue("topic", "A@broker", 7));// 机房 B 的queues.add(new MessageQueue("topic", "B@broker", 8));queues.add(new MessageQueue("topic", "B@broker", 9));queues.add(new MessageQueue("topic", "B@broker", 10));// 消费者队列List<String> cidAll = new ArrayList<String>();cidAll.add("Consumer1-A");cidAll.add("Consumer2-A");cidAll.add("Consumer3-C");// 只关注 A 机房room.setConsumeridcs(new HashSet<String>(){{add("A");}});System.out.println(room.allocate("groupTest", "Consumer1-A", queues, cidAll));System.out.println(room.allocate("groupTest", "Consumer2-A", queues, cidAll));System.out.println(room.allocate("groupTest", "Consumer3-C", queues, cidAll));
}
结果如下:

可以看到,最终队列分配只会分配机房 A 的,而且分配的方式也跟我们上面说的一样。

那如果是只对 B 感兴趣呢?
// 只关注 B 机房
room.setConsumeridcs(new HashSet<String>(){{add("B");}});

可以看到这里就是只分配了机房 B,下面也可以来看下如果 A、B 全部都关注又是怎么分配的。
[MessageQueue [topic=topic, brokerName=A@broker, queueId=0], MessageQueue [topic=topic, brokerName=A@broker, queueId=1], MessageQueue [topic=topic, brokerName=A@broker, queueId=2], MessageQueue [topic=topic, brokerName=B@broker, queueId=9]]
[MessageQueue [topic=topic, brokerName=A@broker, queueId=3], MessageQueue [topic=topic, brokerName=A@broker, queueId=4], MessageQueue [topic=topic, brokerName=A@broker, queueId=5], MessageQueue [topic=topic, brokerName=B@broker, queueId=10]]
[MessageQueue [topic=topic, brokerName=A@broker, queueId=6], MessageQueue [topic=topic, brokerName=A@broker, queueId=7], MessageQueue [topic=topic, brokerName=B@broker, queueId=8]]
4. 小结
好了,这篇文章就到这里,主要讲述了 RocketMQ 的几种负载均衡策略,当然我们也可以自己写一个实现类,只要实现 AllocateMessageQueueStrategy 接口,实现里面的方法,就可以用我们自定义的分配策略。
如有错误,欢迎指出!!!!