llama_index chromadb实现RAG的简单应用
此demo是自己提的一个需求:用modelscope下载的本地大模型实现RAG应用。毕竟大模型本地化有利于微调,RAG使内容更有依据。
为什么要用RAG?
由于大模型存在一定的局限性:知识时效性不足、专业领域覆盖有限以及生成结果易出现“幻觉”问题,需要通过结合实时数据和专业知识提升生成内容的准确性、时效性和可信度。检索增强生成(RAG)的核心价值在于弥补大模型固有缺陷
一个简单样例
加载本地大语言模型和embedding模型,读取指定目录下的文档
import os
import chromadb
from modelscope import snapshot_download
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.core.node_parser import SimpleNodeParser
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.core.base.llms.types import ChatMessage
from llama_index.vector_stores.chroma import ChromaVectorStore
# llamaindex中文网站 https://www.aidoczh.com/llamaindex/module_guides/index.html
# https://docs.llamaindex.ai/en/stable/use_cases/
from dotenv import load_dotenv
load_dotenv(dotenv_path=".env")
cache_apath = os.path.join(os.getcwd(), 'cache')
os.environ["TRANSFORMERS_CACHE"] = cache_apath
os.environ["HF_HOME"] = cache_apath
os.environ["MODELSCOPE_CACHE"] = cache_apathllm_model_name = "Qwen/Qwen2.5-0.5B-Instruct" # "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B" #
llm_model_path = os.path.join(cache_apath,*llm_model_name.replace(".","___").split('/'))
# llm_model_path = snapshot_download(llm_model_name, cache_dir=cache_apath) # 从modelscope下载大模型# 下载并指定sentence-transformers模型
sentence_transformers_name = 'sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2'
embedding_model_path = os.path.join(cache_apath,*sentence_transformers_name.replace(".","___").split('/'))
# embedding_model_path = snapshot_download(sentence_transformers_name, cache_dir=cache_apath) # 从modelscope下载大模型# 初始化HuggingFaceEmbedding对象,用于文本向量转换
embed_model = HuggingFaceEmbedding(model_name=embedding_model_path)
Settings.embed_model = embed_model# 加载本地HuggingFace大模型
llm = HuggingFaceLLM(model_name=llm_model_path,tokenizer_name=llm_model_path,model_kwargs={"trust_remote_code": True},tokenizer_kwargs={"trust_remote_code": True}
)
#设置全局LLM属性
Settings.llm = llmstore_vector2Chroma = True
#从指定目录读取文档,将数据加载到内存
documents=SimpleDirectoryReader(r"source\data1").load_data()文档可以加载到内存 或者 向量数据库里(chroma或者FAISS等)
加载到内存然后检索的范例
#创建一个VectorStoreIndex,并使用之前加载的文档来构建向量索引#此索引将文档转换为向量,并存储这些向量(内存)以便于快速检索
index=VectorStoreIndex.from_documents(documents)# 创建一个查询引擎,这个引擎可以接收查询并返回相关文档的响应。
query_engine =index.as_query_engine()
rsp = query_engine.query("文章里相关的问题写在这里")
print(rsp)加载到chroma的范例
# 定义向量存储数据库
chroma_client = chromadb.PersistentClient()
chroma_collection = chroma_client.get_or_create_collection("data1vector")
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
# 创建节点解析器
node_parser = SimpleNodeParser.from_defaults(chunk_size=512, chunk_overlap=100)
# 将文档分割成节点
base_node = node_parser.get_nodes_from_documents(documents=documents)
# print(base_node)
index = VectorStoreIndex(nodes=base_node)
# index = VectorStoreIndex.from_documents(documents=documents) # 可以替代上面3句
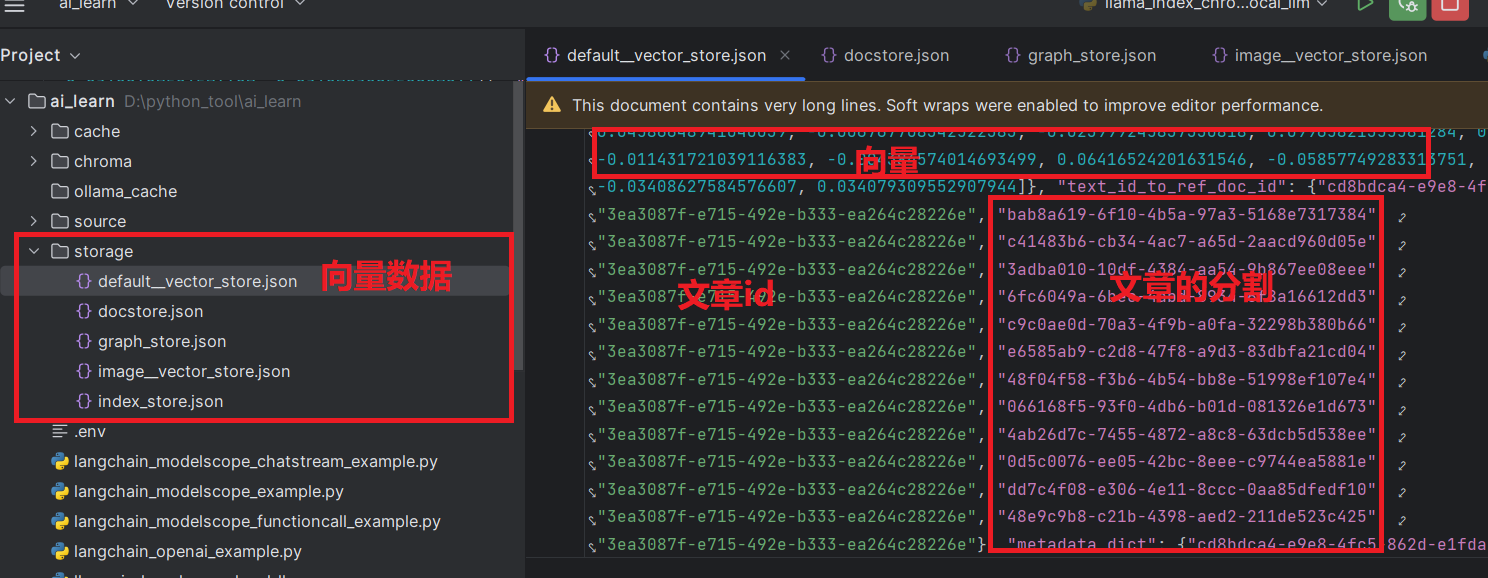
# 将索引持久化到本地的向量数据库
index.storage_context.persist()
# 创建一个查询引擎,这个引擎可以接收查询并返回相关文档的响应。
query_engine =index.as_query_engine()
rsp = query_engine.query("文章里相关的问题写在这里")
print(rsp)chroma官网提供的API不是很多,但是llama_index、langchain等进行封装,封装得很好
文档尽量按照功能分为不同的小文件,生成的向量json文件有对应每部分metadata的描述,如此query的结果可以找到对应文章的哪几部分,内容是什么