ReplacingMergeTree
在 MergeTree 的基础上,添加了“处理重复数据”的功能,该引擎和MergeTree的不同之处在于它会删除具有相同(区内)排序⼀样的重复项。数据的去重只会在合并的过程中出现。合并会在未知的时间在后台进⾏(⼿动合并),所以你⽆法预先作出计划。有⼀些数据可能仍未被处理。因此,ReplacingMergeTree 适⽤于在后台清除重复的数据以节省空间,但是它不保证没有重复的数据出现。
1 ⽆版本参数
根据数据的插⼊时间 , 后插⼊的数据保留
drop table if exists test_replacingMergeTree1;
create table test_replacingMergeTree1
(oid Int8,ctime DateTime,cost Decimal(10, 2)
) engine = ReplacingMergeTree()order by oidpartition by toDate(ctime);
-- 天分区 同⼀天的oid相同的数据会被去重
-- 插⼊数据
insert into test_replacingMergeTree1 values (3, '2021-01-01 11:11:11', 30);
insert into test_replacingMergeTree1 values (1, '2021-01-01 11:11:14', 40);
insert into test_replacingMergeTree1 values (1, '2021-01-01 11:11:11', 10);
insert into test_replacingMergeTree1 values (2, '2021-01-01 11:11:11', 20);
insert into test_replacingMergeTree1 values (1, '2021-01-02 11:11:11', 41);
-- 优化合并
optimize table test_replacingMergeTree1 final;select *
from test_replacingMergeTree1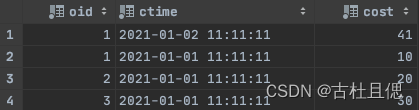
由于系统对CK的操作是多线程执⾏的, 所以不能保证数据插⼊的顺序 , 就可能出现数据删除错乱的现象
-- 主键oid 排序字段两个 验证去重规则是按主键还是排序字段
drop table if exists test_replacingMergeTree2;
create table test_replacingMergeTree2
(oid Int8,ctime DateTime,cost Decimal(10, 2)
) engine = ReplacingMergeTree()primary key oidorder by (oid, ctime)partition by toDate(ctime);
insert into test_replacingMergeTree2 values(1,'2021-01-01 11:11:11',10) ;
insert into test_replacingMergeTree2 values(1,'2021-01-01 11:11:11',20) ;
insert into test_replacingMergeTree2 values(1,'2021-01-01 11:11:11',30);
insert into test_replacingMergeTree2 values(1,'2021-01-01 11:11:12',40) ;
insert into test_replacingMergeTree2 values(1,'2021-01-01 11:11:13',50) ;
-- 由此可⻅ 去重并不是根据主键,⽽知根据区内排序相同的数据会被删除select * from test_replacingMergeTree2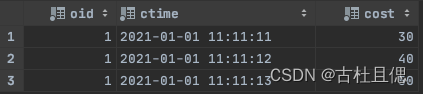
2 有版本参数
- 版本字段可以是数值
- 版本字段可以是时间
drop table if exists test_replacingMergeTree3;
create table test_replacingMergeTree3
(oid Int8,ctime DateTime,cost Decimal(10, 2)
) engine = ReplacingMergeTree(ctime)order by oidpartition by toDate(ctime);
insert into test_replacingMergeTree3 values(1,'2021-01-01 11:11:11',10) ;
insert into test_replacingMergeTree3 values(1,'2021-01-01 11:11:12',20) ;
insert into test_replacingMergeTree3 values(1,'2021-01-01 11:11:10',30);
insert into test_replacingMergeTree3 values(1,'2021-01-01 11:11:19',40) ;
insert into test_replacingMergeTree3 values(1,'2021-01-01 11:11:13',50) ;
-- 合并数据以后 保留的是时间最近的⼀条数据select * from test_replacingMergeTree3总结:
(1)使⽤ORDER BY排序键作为判断重复数据的唯⼀依据。
(2)只有在合并分区的时候才会触发删除重复数据的逻辑。
(3)以数据分区为单位删除重复数据。当分区合并时,同⼀分区内的重复数据会被删除;不同分区之间的重复数据不会被删除。
(4)在进⾏数据去重时,因为分区内的数据已经基于ORBER BY进⾏了排序,所以能够找到那些相邻的重复数据。
(5)数据去重策略有两种:
1. 如果没有设置参数,则保留同⼀组重复数据中的最后⼀⾏。
2. 如果设置了参数,则保留同⼀组重复数据中ver字段取值 最⼤的那⼀⾏。
使⽤这个引擎可以实现数据的更新。