深度学习模型组件之优化器--基础优化器(GD、SGD、Mini-batch SGD)
深度学习模型组件之优化器–基础优化器(GD、SGD、Mini-batch SGD)
文章目录
- 深度学习模型组件之优化器--基础优化器(GD、SGD、Mini-batch SGD)
- 1. 梯度下降(Gradient Descent, GD)
- 1.1 基本原理
- 1.2 优点与缺点
- 1.3 GD代码示例
- 2. 随机梯度下降(Stochastic Gradient Descent, SGD)
- 2.1 基本原理
- 2.2 优缺点分析
- 2.3 SGD代码示例
- 3. 小批量梯度下降(Mini-batch SGD)
- 3.1 基本原理
- 3.2 优缺点分析
- 3.3 Mini-batch SGD代码示例
- 4. 总结
在深度学习的训练过程中,优化器扮演着至关重要的角色。如何高效地寻找损失函数的最小值,直接影响模型的训练速度和最终性能。今天我们就来详细探讨三种基础优化方法:梯度下降(Gradient Descent, GD)、随机梯度下降(Stochastic Gradient Descent, SGD)以及小批量梯度下降(Mini-batch SGD)。
1. 梯度下降(Gradient Descent, GD)
1.1 基本原理
梯度下降是优化算法中最直观的方法,其核心思想是沿着当前参数梯度下降的方向,更新参数以减小损失函数。具体更新公式如下:
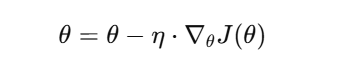
其中,
θ为模型参数,η是学习率,∇θJ(θ)表示损失函数关于参数的梯度。
1.2 优点与缺点
优点:
- 理论简单、易于理解。
- 在凸优化问题中能够保证收敛到全局最优解。
缺点:
- 每次更新都需要计算整个训练集的梯度,计算开销巨大,尤其在大规模数据集上效率低下。
- 对于非凸问题容易陷入局部最优,且对初始值比较敏感。
1.3 GD代码示例
下面是一个使用 Python 实现简单梯度下降算法的示例:
import numpy as np# 假设我们要最小化 f(x) = x^2
def f(x):return x ** 2def grad_f(x):return 2 * x# 初始化参数
x = 10.0
learning_rate = 0.1
num_iterations = 50for i in range(num_iterations):grad = grad_f(x)x = x - learning_rate * gradprint(f"Iteration {i+1}: x = {x}, f(x) = {f(x)}")
2. 随机梯度下降(Stochastic Gradient Descent, SGD)
2.1 基本原理
随机梯度下降与梯度下降的主要区别在于:SGD 每次只使用一个样本(或一小部分样本)来估计梯度,从而大大减少了每次更新所需的计算量。更新公式类似,但梯度 ∇θJ(θ) 只针对一个样本或一个样本对进行计算,即:
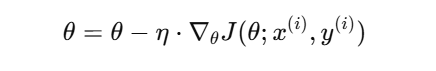
这里:
x(i)和y(i)分别表示第 i 个样本及其对应的标签;∇θJ(θ;x(i),y(i))为基于单个样本计算的梯度。
2.2 优缺点分析
优点:
- 单次更新速度快,计算量小,适合大数据量的训练;
- 更新参数更加频繁,有助于快速跳出局部最优解。
缺点:
- 由于每次更新只依赖单个样本,梯度的估计存在较大噪声,可能导致更新震荡;
- 收敛路径不够平滑,可能需要更多迭代才能达到稳定状态。
2.3 SGD代码示例
下面是一个使用 SGD 的简单实现示例:
import numpy as np# 假设我们有一个样本数据集 X 和对应标签 Y,用于线性回归
X = np.array([1, 2, 3, 4, 5])
Y = np.array([2, 4, 6, 8, 10]) # 真实关系为 y = 2x# 初始化参数
w = 0.0
learning_rate = 0.01
num_iterations = 100for i in range(num_iterations):# 随机选择一个样本idx = np.random.randint(0, len(X))x_i = X[idx]y_i = Y[idx]# 预测值与误差prediction = w * x_ierror = prediction - y_i# 梯度计算(以均方误差损失函数求导)grad = 2 * error * x_iw = w - learning_rate * gradif (i+1) % 10 == 0:print(f"Iteration {i+1}: w = {w}")
3. 小批量梯度下降(Mini-batch SGD)
3.1 基本原理
小批量梯度下降可以看作是 GD 与 SGD 的折中方案:在每次更新中,使用一小部分样本(称为 mini-batch)来估计梯度。这样既保留了梯度下降整体稳定的优势,也减少了计算量,并且在一定程度上降低了 SGD 的噪声。
更新公式仍然为:
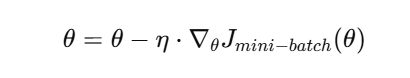
其中,∇θJmini−batch(θ) 表示基于小批量样本计算出的梯度平均值。
3.2 优缺点分析
优点:
- 兼顾了计算效率和梯度估计的稳定性。
- 利用向量化运算可以大幅提高计算效率,适合 GPU 并行计算。
缺点:
- 小批量大小的选择对训练效果有较大影响;
- 若 mini-batch 太小,噪声可能依然较大;若太大,则可能失去 SGD 的随机性优势。
3.3 Mini-batch SGD代码示例
下面是一个使用 mini-batch SGD 实现线性回归的示例代码:
import numpy as np# 数据集
X = np.linspace(1, 5, 100)
Y = 2 * X + np.random.randn(100) # 加入一定噪声# 初始化参数
w = 0.0
learning_rate = 0.001
num_iterations = 200
batch_size = 10for i in range(num_iterations):# 随机抽取 mini-batchindices = np.random.choice(len(X), batch_size, replace=False)X_batch = X[indices]Y_batch = Y[indices]# 计算预测值与误差predictions = w * X_batcherrors = predictions - Y_batch# 梯度计算(均方误差损失函数求导)grad = 2 * np.dot(errors, X_batch) / batch_sizew = w - learning_rate * gradif (i+1) % 20 == 0:mse = np.mean(errors ** 2)print(f"Iteration {i+1}: w = {w:.4f}, MSE = {mse:.4f}")
4. 总结
本文介绍了三种基本优化方法:
- 梯度下降(GD):使用整个训练集计算梯度,更新稳定,但计算量大,适合小数据集和理论研究。
- 随机梯度下降(SGD):每次只用一个样本更新,速度快、更新频繁,但容易出现噪声和波动。
- 小批量梯度下降(Mini-batch SGD):使用一小批样本计算平均梯度,兼顾了计算效率和更新稳定性,但需要合理选择批次大小。
下面是三者的对比表格:
| 方法 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 梯度下降(GD) | 用整个训练集计算梯度 | 更新稳定,理论简单 | 计算量大,速度慢 |
| 随机梯度下降(SGD) | 每次用一个样本计算梯度 | 更新快,适合大数据 | 噪声大,收敛不平滑 |
| 小批量梯度下降(Mini-batch SGD) | 用一小批样本计算平均梯度 | 兼顾速度与稳定性,适合GPU加速 | 需精心调控批次大小 |