HDFS的设计架构
HDFS 是 Hadoop 生态系统中的分布式文件系统,设计用于存储和处理超大规模数据集。它具有高可靠性、高扩展性和高吞吐量的特点,适合运行在廉价硬件上。
1. HDFS 的设计思想
HDFS 的设计目标是解决大规模数据存储和处理的问题,其核心设计思想包括:
(1)分布式存储
- 数据被分割成多个块(Block),并分布存储在集群中的多个节点上。
- 每个数据块默认大小为 128MB 或 256MB,可以根据需求配置。
(2)高容错性
- 通过数据冗余(默认 3 副本)确保数据可靠性。
- 如果某个节点故障,系统可以从其他节点的副本中恢复数据。
(3)高吞吐量
- 适合批量数据处理,而不是低延迟的随机读写。
- 通过流式数据访问模式,优化了大文件的读写性能。
(4)廉价硬件
- 设计运行在普通商用硬件上,通过软件层面的容错机制弥补硬件可靠性不足的问题。
(5)数据本地性
- 将计算任务调度到存储数据的节点上,减少数据传输开销,提高处理效率。
(6)一次写入,多次读取
- 适合写入一次、读取多次的场景,不支持文件的随机修改。
2. HDFS 的框架结构
HDFS 采用主从架构(Master-Slave),主要由以下组件组成:
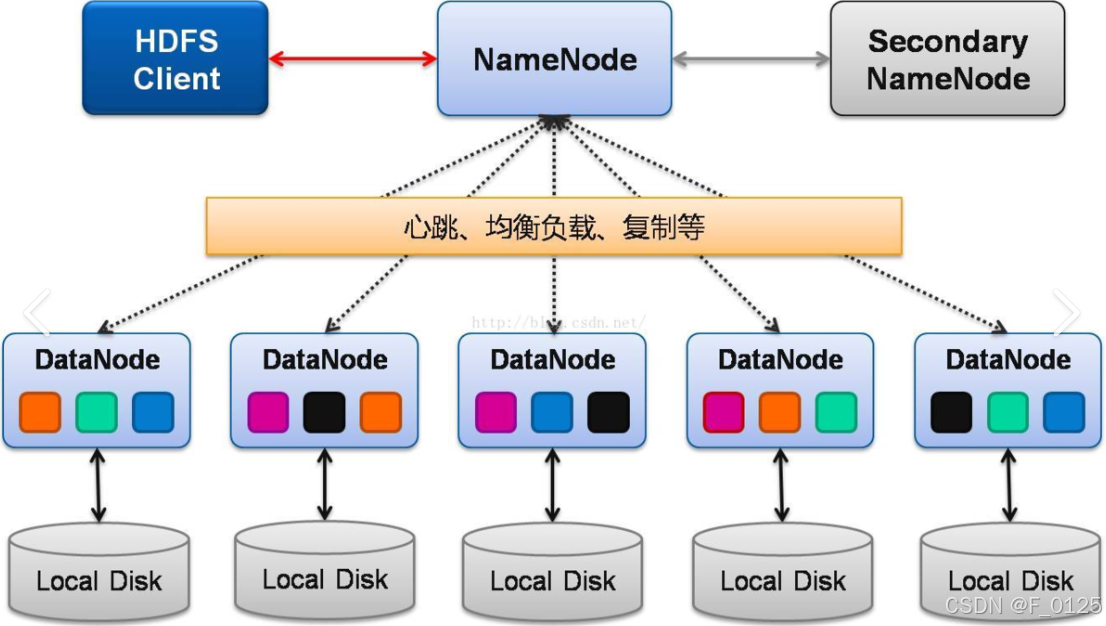
(1)NameNode(主节点)
NameNode 是 HDFS 的核心组件,负责管理文件系统的元数据。
主要职责:维护文件系统的命名空间(如目录树、文件信息)。管理数据块(Block)与 DataNode 的映射关系。处理客户端的元数据请求(如打开、关闭、重命名文件)。NameNode 是单点故障(SPOF),因此通常需要配置高可用性(HA)方案,如使用双 NameNode(Active-Standby)。
(2)DataNode(从节点)
DataNode 是工作节点,负责存储实际的数据块。
主要职责:存储和检索数据块。定期向 NameNode 发送心跳信号和数据块报告。执行数据块的创建、删除和复制操作。DataNode 通常是集群中的多个节点,共同提供分布式存储能力。
(3)Secondary NameNode(辅助节点)
Secondary NameNode 不是 NameNode 的备份,而是辅助 NameNode 完成元数据的管理。
主要职责:定期合并 NameNode 的编辑日志(EditLog)和文件系统镜像(FsImage),减少 NameNode 的启动时间。不提供故障恢复功能。
(4)客户端(Client)
客户端是与 HDFS 交互的应用程序或用户工具。
主要职责:与 NameNode 通信,获取元数据(如文件位置)。与 DataNode 通信,读写数据块。
3. HDFS 的工作流程
(1)文件写入流程
1. 客户端向 NameNode 请求写入文件。
2. NameNode 检查文件是否存在,并确定数据块存储的 DataNode 列表。
3. 客户端将数据块写入第一个 DataNode,第一个 DataNode 将数据复制到第二个 DataNode,依此类推。
4. 写入完成后,客户端通知 NameNode,NameNode 更新元数据。
(2)文件读取流程
1. 客户端向 NameNode 请求读取文件。
2. NameNode 返回文件的数据块位置(DataNode 列表)。
3. 客户端直接从 DataNode 读取数据块。
(3)数据块复制流程
当某个 DataNode 故障或数据块损坏时,NameNode 会检测到并触发数据块的复制操作,确保数据冗余。
4. HDFS 的核心特性
(1)高可靠性
- 通过数据冗余(默认 3 副本)确保数据不会丢失。
- NameNode 的高可用性(HA)方案进一步提升了系统的可靠性。
(2)高扩展性
- 可以通过增加 DataNode 节点来扩展存储容量和处理能力。
- 支持 PB 级甚至 EB 级数据存储。
(3)高吞吐量
- 适合批量数据处理,能够高效地读写大文件。
- 通过数据本地性优化计算任务的执行效率。
(4)廉价硬件支持
- 设计运行在普通商用硬件上,降低了成本。
(5)一次写入,多次读取
- 适合数据仓库、日志存储等场景,但不适合频繁修改的文件。
HDFS 是一个分布式文件系统,设计用于存储和处理超大规模数据集。其核心设计思想包括分布式存储、高容错性、高吞吐量和廉价硬件支持。HDFS 的框架结构由 NameNode、DataNode 和 Secondary NameNode 组成,采用主从架构。HDFS 适合大数据批处理场景,但不适合低延迟的随机读写和频繁修改的文件。