【JAVA】io流之缓冲流
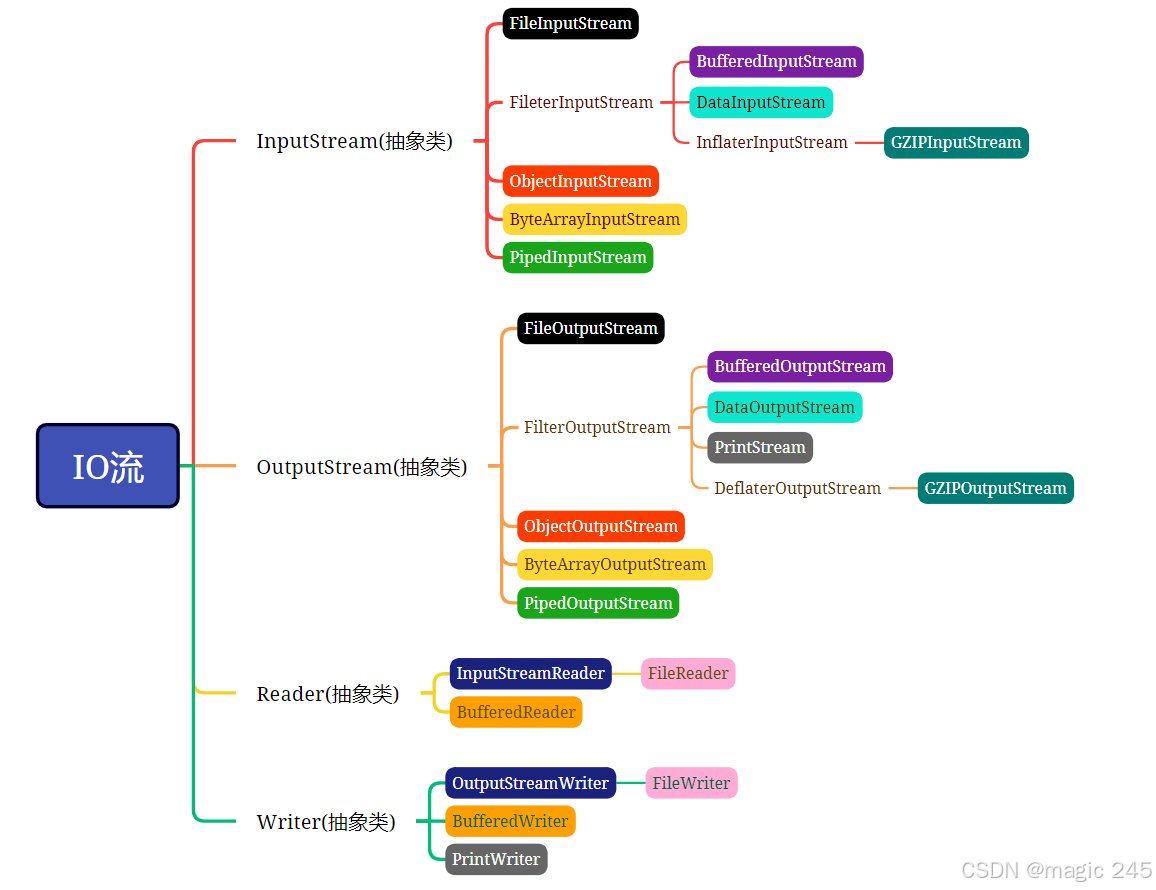
①BufferedInputStream、BufferedOutputStream(适合读写非普通文本文件)
②BufferedReader、BufferedWriter(适合读写普通文本文件。)
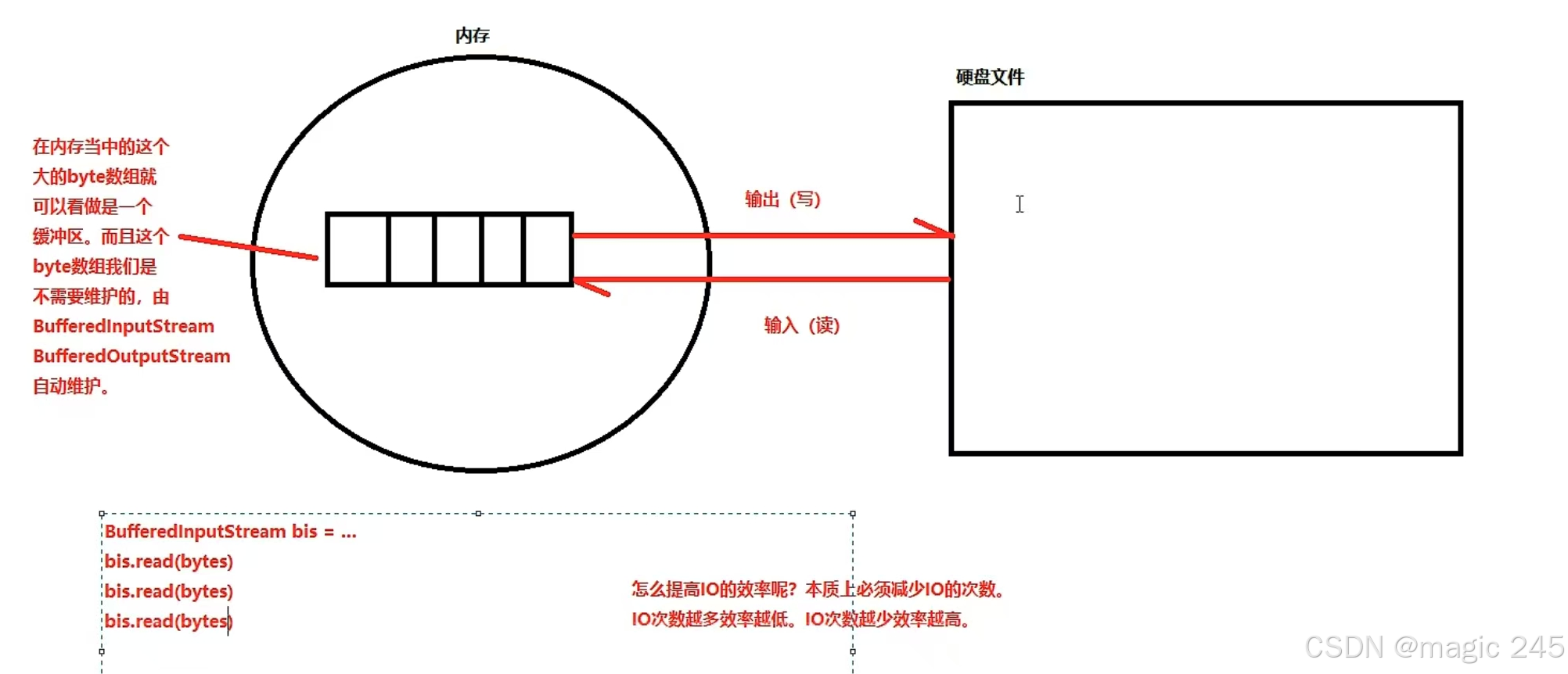
缓冲流的读写速度快,原理是:在内存中准备了一个缓存。读的时候从缓存中读。写的时候将缓存中的数据一次写出。都是在减少和磁盘的交互次数。
一、如何理解缓冲区?
家里盖房子,有一堆砖头要搬在工地100米外,单字节的读取就好比你一个人每次搬一块砖头,从堆砖头的地方搬到工地,这样肯定效率低下。
然而聪明的人类会用小推车,每次先搬砖头搬到小车上,再利用小推车运到工地上去,这样你再从小推车上取砖头是不是方便多了呀!这样效率就会大大提高,缓冲流就好比我们的小推车,给数据暂时提供一个可存放的空间。
二·、BufferedInputStream
FileInputStream/FileOutputStream是节点流
BufferedInputStream是缓冲流(包装流/处理流)。这个流的效率高。自带缓冲区。并且自己维护这个缓冲区。读大文件的时候建议采用这个缓冲流来读取。
关闭流只需要关闭最外层的处理流即可,通过源码就可以看到,当关闭处理流时,底层节点流也会关闭。
1.概述
BufferedInputStream为另一个输入流添加了缓冲功能,它内部维护了一个缓冲区,当从流中读取数据时,会尽可能多地将数据读入缓冲区,这样后续的读取操作就可以直接从缓冲区中获取数据,而不必每次都从底层输入流中读取,从而减少了实际的 I/O 操作次数,提高了读取效率。
2.常用构造方法
BufferedInputStream(InputStream in):创建一个BufferedInputStream,并使用默认大小的缓冲区。参数in是要被缓冲的底层输入流。例如
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.IOException;/*** 1. java.io.BufferedInputStream的用法和FileInputStream用法相同。** 2. 他们的不同点是:* FileInputStream是节点流。* BufferedInputStream是缓冲流(包装流/处理流)。这个流的效率高。自带缓冲区。并且自己维护这个缓冲区。读大文件的时候建议采用这个缓冲流来读取。** 3. BufferedInputStream对 FileInputStream 进行了功能增强。增加了一个缓冲区的功能。** 4. 怎么创建一个BufferedInputStream对象呢?构造方法:* BufferedInputStream(InputStream in)**/
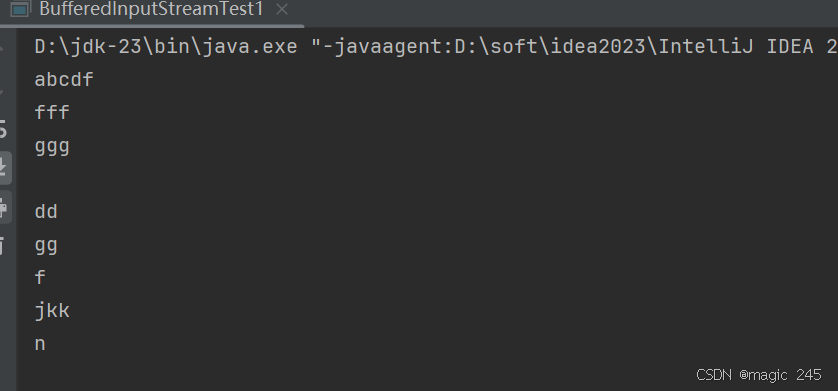
public class BufferedInputStreamTest1 {public static void main(String[] args) {BufferedInputStream bis = null;try {// 创建节点流//FileInputStream in = new FileInputStream("file.txt");// 创建包装流//bis = new BufferedInputStream(in);// 组合起来写bis = new BufferedInputStream(new FileInputStream("file.txt"));// 读,和FileInputStream用法完全相同byte[] bytes = new byte[1024];int readCount = 0;while((readCount = bis.read(bytes)) != -1){System.out.print(new String(bytes, 0, readCount));}} catch (Exception e) {e.printStackTrace();} finally {// 包装流以及节点流,你只需要关闭最外层的那个包装流即可。节点流不需要手动关闭。if (bis != null) {try {bis.close();} catch (IOException e) {e.printStackTrace();}}}}
}在根路径下创建file.txt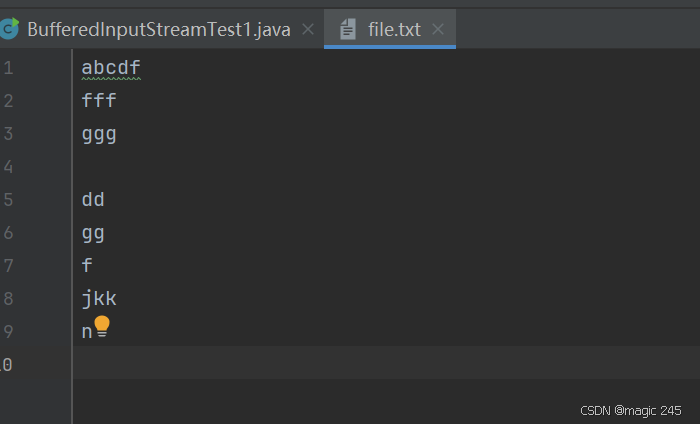
运行结果:
⑵.BufferedInputStream(InputStream in, int size):
创建一个BufferedInputStream,并指定缓冲区的大小为size字节。例如:
FileInputStream fis = new FileInputStream("test.txt");
BufferedInputStream bis = new BufferedInputStream(fis, 8192);read方法主要功能是通过预加载数据到内存缓冲区,减少底层 I/O 操作的次数
三、BufferedOutputStream
常用构造方法 BufferedOutputStream(OutputStream out):创建一个BufferedOutputStream,并使用默认大小的缓冲区。参数out是要被缓冲的底层输出流。例如:
FileOutputStream fos = new FileOutputStream("test.txt");
BufferedOutputStream bos = new BufferedOutputStream(fos);BufferedOutputStream(OutputStream out, int size):创建一个BufferedOutputStream,并指定缓冲区的大小为size字节。例如:
FileOutputStream fos = new FileOutputStream("test.txt");
BufferedOutputStream bos = new BufferedOutputStream(fos, 8192);import java.io.BufferedOutputStream;
import java.io.FileOutputStream;
import java.io.IOException;/*** 1. java.io.BufferedOutputStream也是一个缓冲流。属于输出流。* 2. 怎么创建BufferedOutputStream对象?* BufferedOutputStream(OutputStream out)* 3. FileOutputStream是节点流。 BufferedOutputStream是包装流。*/
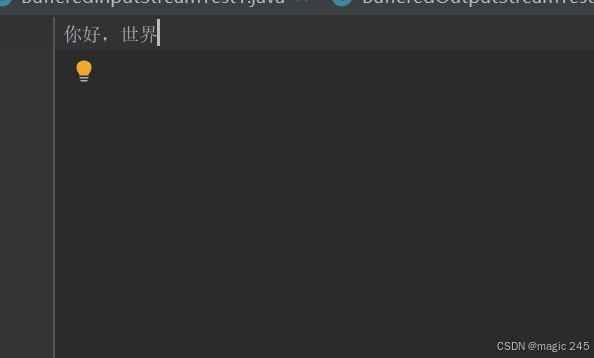
public class BufferedOutputStreamTest01 {public static void main(String[] args) {BufferedOutputStream bos = null;try {bos = new BufferedOutputStream(new FileOutputStream("file.txt"));bos.write("你好,世界".getBytes());// 缓冲流需要手动刷新。bos.flush();} catch (Exception e) {e.printStackTrace();} finally {if (bos != null) {try {// 只需要关闭最外层的包装流即可。bos.close();} catch (IOException e) {e.printStackTrace();}}}}
}运行结果:
四、使用BufferedInputStream 和BufferedOutputStream完成文件的复制
/*** 使用BufferedInputStream BufferedOutputStream完成文件的复制。*/
public class BufferedInputOutputStreamCopy {public static void main(String[] args) {long begin = System.currentTimeMillis();try(BufferedInputStream bis = new BufferedInputStream(new FileInputStream("C:\\Users\\86178\\Desktop\\2024\\test3.txt"));BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("C:\\Users\\86178\\Desktop\\2024\\testwriter.txt"))){// 一边读一边写byte[] bytes = new byte[1024];int readCount = 0;while((readCount = bis.read(bytes)) != -1){bos.write(bytes, 0, readCount);}// 手动刷新bos.flush();} catch (FileNotFoundException e) {throw new RuntimeException(e);} catch (IOException e) {throw new RuntimeException(e);}long end = System.currentTimeMillis();System.out.println("带有缓冲区的拷贝耗时"+(end - begin)+"毫秒"); // 671}
}五、缓存流的mark与reset
输入流中的 mark 和 reset(以 BufferedInputStream 为例)
1. 方法说明
void mark(int readlimit):在流的当前位置设置一个标记。readlimit参数指定了在标记位置失效之前可以读取的最大字节数。也就是说,在读取了readlimit个字节之后,标记可能会失效,此时调用reset方法可能会抛出IOException。void reset():将流的位置重置到之前通过mark方法设置的标记位置。如果标记已经失效(例如,已经读取超过readlimit个字节),则会抛出IOException。
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.IOException;public class BufferedInputStreamMarkResetExample {public static void main(String[] args) {try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream("test.txt"))) {// 读取前 3 个字节int data;for (int i = 0; i < 3; i++) {data = bis.read();if (data != -1) {System.out.print((char) data);}}// 设置标记,允许在读取 10 个字节内重置到该位置bis.mark(10);// 继续读取 3 个字节for (int i = 0; i < 3; i++) {data = bis.read();if (data != -1) {System.out.print((char) data);}}// 重置到标记位置bis.reset();// 再次从标记位置读取 3 个字节for (int i = 0; i < 3; i++) {data = bis.read();if (data != -1) {System.out.print((char) data);}}} catch (IOException e) {e.printStackTrace();}}
}运行结果: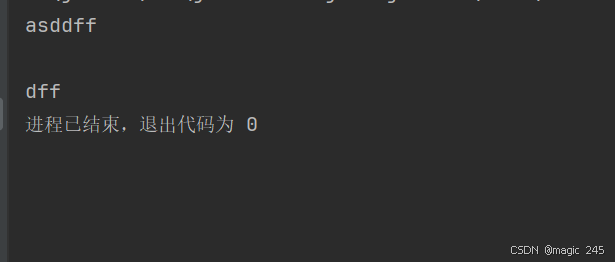
输出流中的 mark 和 reset
在 BufferedOutputStream 中,并没有直接提供 mark 和 reset 方法。这是因为输出流的主要目的是将数据写入目标,而不是像输入流那样可以灵活地回退读取。一旦数据被写入输出流,通常是不可逆的操作。
不过,如果你需要实现类似的功能,可以考虑使用一些辅助的数据结构(如 ByteArrayOutputStream)来缓存数据,然后根据需要重新写入。